国庆中秋特辑(一)浪漫祝福方式 用循环神经网络(RNN)或长短时记忆网络(LSTM)生成祝福诗词
目录
- 一、使用深度学习中的循环神经网络(RNN)或长短时记忆网络(LSTM)生成诗词
- 二、优化:使用双向 LSTM 或 GRU 单元来更好地捕捉上下文信息
- 三、优化:使用生成对抗网络(GAN)或其他技术以提高生成结果的质量和多样性

为了使用人工智能技术生成诗词,我们可以使用深度学习中的循环神经网络(RNN)或长短时记忆网络(LSTM)来学习诗词的结构和语义。下面是一个使用 Python 和 Keras 搭建的简单示例:
一、使用深度学习中的循环神经网络(RNN)或长短时记忆网络(LSTM)生成诗词
- 首先,我们需要安装必要的库。在此示例中,我们将使用 Keras 和 TensorFlow。
pip install keras tensorflow
- 准备数据。为了创建一个简单的数据集,我们可以使用以下四句诗词:
明月几时有?把酒问青天。
不知天上宫阙,今夕是何年。
我欲乘风归去,又恐琼楼玉宇,高处不胜寒。
起舞弄清影,何似在人间?
我们需要将这些诗词转换为适合模型输入的格式。我们可以将每个汉字作为一个时间步(time step),并使用一个 one-hot 编码的整数序列表示每个汉字。
import numpy as np
# 创建一个字符到整数的映射字典
char_to_int = {char: i for i, char in enumerate(sorted(set(诗词)))}
int_to_char = {i: char for i, char in enumerate(sorted(set(诗词)))}
# 准备数据
data = [ [char_to_int[char] for char in line.split(',')] for line in 诗词
]
# one-hot 编码
data = np.array(data).astype('float32')
data = np.log(data + 1)
- 定义模型。在这个例子中,我们将使用一个简单的 LSTM 模型。我们将输入数据分成批量,并使用一个 LSTM 层来处理它们。
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(128, input_shape=(len(word_index) + 1,)))
model.add(Dense(len(word_index), activation='softmax'))
- 编译模型。我们需要指定优化器、损失函数和评估指标。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 训练模型。我们将使用前 3 句诗词作为训练数据,第 4 句诗词作为测试数据。
model.fit(data[:-1], data[-1], epochs=10, batch_size=64)
- 生成诗词。使用训练好的模型生成第 5 句诗词。
predicted = np.argmax(model.predict(data[:-1], verbose=0), axis=-1)
predicted = [int_to_char[i] for i in predicted]
generated_poem = ','.join(predicted)
print(generated_poem)
这是一个简化的例子,你可以在此基础上进行优化以提高诗词质量。例如:
- 使用双向 LSTM 或 GRU 单元来更好地捕捉上下文信息。
- 增加隐藏层数量和神经元数量以提高模型的表达能力。
- 使用更复杂的数据预处理方法,如 word2vec 或 char2vec,以获得更丰富的词汇表示。
- 在生成诗词时使用生成对抗网络(GAN)或其他技术以提高生成结果的质量和多样性。
- 使用更大的数据集进行训练,以提高模型的泛化能力。
通过以上方法,你可以提高使用人工智能技术生成诗词的质量。但请注意,这些方法并非孤立的,你可以结合使用它们以获得更好的效果。同时,实际应用中可能需要进行更多的尝试和调整。
二、优化:使用双向 LSTM 或 GRU 单元来更好地捕捉上下文信息
为了使用双向 LSTM 或 GRU 单元来更好地捕捉上下文信息,我们需要修改之前的模型定义。下面是一个使用双向 LSTM 的示例:
- 定义双向 LSTM 模型。
from keras.models import Sequential
from keras.layers import LSTM, Bidirectional
from keras.layers import Dense
model = Sequential()
model.add(Bidirectional(LSTM(64)))
model.add(Dense(len(word_index), activation='softmax'))
在这个例子中,我们使用了一个双向 LSTM 层,包含两个独立的 LSTM 层(一个正向和一个反向),以更好地捕捉上下文信息。
2. 编译模型。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 训练模型。
model.fit(data[:-1], data[-1], epochs=10, batch_size=64)
- 使用训练好的模型生成诗词。
predicted = np.argmax(model.predict(data[:-1], verbose=0), axis=-1)
predicted = [int_to_char[i] for i in predicted]
generated_poem = ','.join(predicted)
print(generated_poem)
通过使用双向 LSTM 单元,模型将更好地理解上下文信息,从而提高生成诗词的质量。同样,你可以尝试其他优化方法,如增加隐藏层数量和神经元数量,使用更复杂的数据预处理方法,引入生成对抗网络(GAN)等,以进一步提高生成结果的质量和多样性。
三、优化:使用生成对抗网络(GAN)或其他技术以提高生成结果的质量和多样性
要在生成诗词时使用生成对抗网络(GAN)或其他技术以提高生成结果的质量和多样性,我们可以在原有模型的基础上进行修改。下面是一个使用 GAN 的示例:
- 定义生成器(Generator)和判别器(Discriminator)。
from keras.models import Sequential
from keras.layers import Dense, Bidirectional, LSTM, Input
def build_generator(latent_dim): model = Sequential() model.add(Input(latent_dim)) model.add(Bidirectional(LSTM(64))) model.add(Dense(len(word_index), activation='softmax')) return model
def build_discriminator(): model = Sequential() model.add(Input(len(word_index))) model.add(LSTM(64, return_sequences=True)) model.add(LSTM(32)) model.add(Dense(1, activation='sigmoid')) return model
- 实例化生成器和判别器。
generator = build_generator(latent_dim=100)
discriminator = build_discriminator()
- 定义 GAN 训练函数。
def train_gan(generator, discriminator, data, epochs=100, batch_size=64): for epoch in range(epochs): for real_data in data: # 训练判别器 real_labels = tf.ones((batch_size, 1)) noise = tf.random_normal(0, 1, (batch_size, latent_dim)) fake_data = generator(noise) fake_labels = tf.zeros((batch_size, 1)) all_data = tf.concat((real_data, fake_data), axis=0) all_labels = tf.concat((real_labels, fake_labels), axis=0) discriminator.train_on_batch(all_data, all_labels)# 训练生成器 noise = tf.random_normal(0, 1, (batch_size, latent_dim)) generator.train_on_batch(noise, real_labels) print(f'Epoch {epoch + 1} finished.')
- 训练 GAN。
latent_dim = 100
data =... # 训练数据
epochs = 100
batch_size = 64
generator = build_generator(latent_dim)
discriminator = build_discriminator()
generator.compile(optimizer='adam', loss='categorical_crossentropy')
discriminator.compile(optimizer='adam', loss='binary_crossentropy')
train_gan(generator, discriminator, data, epochs, batch_size)
通过使用 GAN 技术,模型将能够在训练过程中生成更加多样化和高质量的诗词。同时,你还可以尝试其他技术,如使用更高级的损失函数,如 WGAN 或 CycleGAN,以进一步提高生成结果的质量。
相关文章:
国庆中秋特辑(一)浪漫祝福方式 用循环神经网络(RNN)或长短时记忆网络(LSTM)生成祝福诗词
目录 一、使用深度学习中的循环神经网络(RNN)或长短时记忆网络(LSTM)生成诗词二、优化:使用双向 LSTM 或 GRU 单元来更好地捕捉上下文信息三、优化:使用生成对抗网络(GAN)或其他技术…...

【入门篇】ClickHouse 的安装与配置
文章目录 0. 前言ClickHouse的安装1. 添加 ClickHouse 的仓库2. 安装 ClickHouse3. 启动 ClickHouse 服务器4. 使用 ClickHouse 客户端 ClickHouse的配置 1. 详细安装教程1.1. 系统要求1.1. 可用安装包 {#install-from-deb-packages}1.1.1. DEB安装包1.1.1. RPM安装包 {#from-r…...

为了工作刷题
1.同步通信和异步通信有什么区别?UART、SPI和I2C分别属于什么类型的通信方式? 同步通信:在同步通信中,发送方和接收方之间使用共享的时钟信号来同步数据传输。发送方按照时钟信号的边沿(上升沿或下降沿)将数…...
linux jenkins2.414.1-1.1版本安装
文章目录 前言一、rpm文件下载二、安装jenkins2.1.升级jdk1.82.2安装jenkins2.3 启动服务2.4 使用密码登录2.5 修改插件源2.6 汉化插件安装演示 总结 前言 之前也安装过jenkins,但是那个版本是2.1的,太老了很多插件都不支持,现在安装目前为止…...

嵌入式学习笔记(33)S5PV210的第二阶段处理过程
(1)第一个过程,怎么找到具体是哪个中断:S5PV210中因为支持的中断源很多,所以直接设计了4个中断寄存器,每个32位,每位对应一个中断源。(理论上210最多可以支持128个中断源,…...

学校项目培训之Carla仿真平台之安装Carla
官网:http://carla.org/ 写在前面 由于安装都写了很多东西,所以我单独将安装弄出来记录一下。 如果你在安装9.12版本的时候遇到了很多问题,你可以考虑以下几点: - 楼梯可能不太行,需要更换,这是我实践得到的…...

什么是MQ消息队列及四大主流MQ的优缺点(个人网站复习搬运)
什么是MQ消息队列及四大主流MQ的优缺点 小程序要上一个限时活动模块,需要有延时队列,从网上了解到用RabbitMQ可以解决,就了解了下 MQ 并以此做记录。 一、为什么要用 MQ 核心就是解耦、异步和…...
Learn Prompt-什么是ChatGPT?
ChatGPT(生成式预训练变换器)是由 OpenAI 在2022年11月推出的聊天机器人。它建立在 OpenAI 的 GPT-3.5 大型语言模型之上,并采用了监督学习和强化学习技术进行了微调。 ChatGPT 是一种聊天机器人,允许用户与基于计算机的代理进行对…...
高德地图实现-微信小程序地图导航
效果图: 一、准备阶段 1、在高德开放平台注册成为开发者2、申请开发者密钥(key)。3、下载并解压高德地图微信小程序SDK 高德开放平台: 注册账号(https://lbs.amap.com/)) 申请小程序应用的 key 应用管理(https://console.ama…...

你已经应用了哪种服务注册和发现的模式呢?
前面历史文章中我们有说过关于微服务的注册和发现,并以 etcd 作为简单例子简单阐述了关于服务注册和发现的应用 那么日常工作中,你已经使用了服务注册和发现的哪些模式呢? 服务注册和发现的作用 首先,简单说明一下服务注册和发…...

Python爬虫技术在SEO优化中的关键应用和最佳实践
大家好!今天我要和大家分享一个关于SEO优化的秘密武器:Python爬虫技术。在这篇文章中,我们将探讨Python爬虫在SEO优化中的关键应用和最佳实践。无论您是一名SEO专家、网站管理员,还是对优化网站曝光度感兴趣的初学者,都…...

基于支持向量机的试剂条图像识别,基于SVM的图像识别,SVM的详细原理,Libsvm工具箱使用注意事项
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 Libsvm工具箱详解 简介 参数说明 易错及常见问题 代码下载链接: 基于支持向量机SVM的试剂条图像自动识别,基于SVM的试剂条图像自动读取资源-CSDN文库 https://download.csdn.net/download/abc991835105/88215944 SVM应用实例…...

PbootCMS在搭建网站
1、打开网站 https://www.pbootcms.com/ 2、点击 “本站” 下载最新的网站代码 3、在本地laragon/www下创建目录(hejuwuye),并将代码放进去 4、创建本地数据库,数据库名称为: hejuwuye,然后将static/bac…...
C语言经典100例题(56-60)--画圆;画方;画线
目录 【程序56】题目:画图,学用circle画圆形 【程序57】题目:画图,学用line画直线。 【程序58】题目:画图,学用rectangle画方形。 【程序59】题目:画图,综合例子。 【程序60】题…...
linux相关知识以及有关指令3
在linux的世界中我们首先要有万物皆文件的概念,那么在系统中有那么多的文件,我们该怎么区分呢?文章目录 1. 文件分类2. 文件的权限1). 拥有者和所属组以及other2). 文件的权限3). 粘滞位4). 对于权限修改的拓展知识点a.修改权限b.修改拥有者所…...

关于Synchronized
Synchronized用于实现线程间的同步。它可以被用于方法或代码块上,确保同一时间只有一个线程可以访问被 synchronized 修饰的代码,也就是常说的锁,synchronized有三点作用 1)实现线程安全:通过使用 synchronized&#x…...
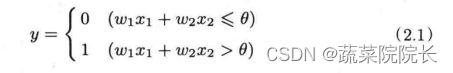
深度学习(Python)学习笔记2
第二章 感知机 2.1 感知机是什么 感知机接收多个输入信号,输出一个信号。 感知机的信号会形成流,向前方输送信息。 感知机的信号只有“流/不流”(1/0)两种取值。 本学习笔记中,0对应“不传递信号”,1对应“传递信号”。 图中、是输入信号,是输出信号,、是权重。图…...

gitlab操作
1. 配置ssh 点击访问 2. 创建新分支与切换新分支 git branch 新分支名 // 创建 git checkout 新分支名 // 切换到新分支3. 查看当前分支 git branch*所指的就是当前所在分支 4. 本地删除文件后与远程git同步 git add -A git commit -m "del" git push...

docker day04
Dockerfile: - FORM: 1.指定基础镜像,可以起别名,也可以指定多个FROM指令,用于多阶段构建; 2.加载触发器,加载ONBUILD指令; 3.不指定基础镜像,声明当前镜像不依赖任何镜像,官方…...

任意区域的色彩一致性处理方法
影像任意感兴趣区域的色彩一致性处理方法,主要是针对掩膜后的影像,类似下图,对非背景区域的像素进行处理 其中非黑色部分我们叫待匀色区域。 这种处理 对于wallis 和直方图匹配 很容易实现,但是颜色转移就相对而言 困难点。 颜…...

5个场景告诉你:为什么你需要这款免费的窗口分辨率神器
5个场景告诉你:为什么你需要这款免费的窗口分辨率神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾遇到过这些困扰?游戏内分辨率选项有限,无法满足你对极致画质的…...

Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧
Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧 Kubescape是一款开源的Kubernetes安全平台,专为IDE、CI/CD管道和集群设计,提供风险分析、安全合规检查和错误配置扫描功能,帮助Kubernetes用户和管理员节省宝…...

终极指南:如何免费使用Umi-OCR实现高效离线文字识别
终极指南:如何免费使用Umi-OCR实现高效离线文字识别 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

别再为本科毕业论文熬大夜!Paperxie 智能写作,一键搞定终稿的正确姿势
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 又到了本科毕业论文冲刺的季节,多少同学还在对着空白文档发呆?选题纠结半天定不下来&…...

权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区
更多请点击: https://intelliparadigm.com 第一章:权限割裂、数据延迟、协同断点——Gemini Workspace整合失败的90%源于这4个配置盲区 在企业级部署 Gemini Workspace 时,大量团队遭遇“功能可登录但协作不可用”的隐性故障。根本原因并非 …...

Godot开发者必备:awesome-godot资源库高效使用指南
1. 项目概述:一个开源游戏引擎的“宝藏库” 如果你正在使用或考虑使用 Godot 引擎进行游戏开发,那么你很可能已经听说过 awesome-godot 这个项目。它不是一个可以直接运行的软件,也不是一个插件,而是一个由社区共同维护的、结构…...

codebase-digest:自动化代码库分析工具的设计原理与工程实践
1. 项目概述:当代码库变成“黑盒”,我们如何快速理解它?你有没有接手过一个庞大而陌生的代码库?面对成千上万的文件和错综复杂的依赖关系,那种感觉就像被扔进了一个没有地图的迷宫。传统的做法是,你得像考古…...
)
【仅开放72小时】:Gemini Workspace与Microsoft Entra ID双向同步的密钥轮换脚本(含自动审计日志生成器)
更多请点击: https://intelliparadigm.com 第一章:Gemini Workspace整合方案概述 Gemini Workspace 是 Google 推出的面向企业级 AI 协作的统一平台,其核心价值在于将 Gemini 模型能力深度嵌入办公套件(如 Gmail、Drive、Docs、M…...

WindowResizer:轻松掌控Windows窗口的终极解决方案
WindowResizer:轻松掌控Windows窗口的终极解决方案 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为Windows应用程序窗口尺寸无法调整而烦恼吗?Window…...
)
Sora 2与3D Gaussian结合实战指南(工业级部署避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian结合的工业级部署全景图 Sora 2作为OpenAI新一代视频生成模型,在长时序建模与物理一致性方面取得显著突破;而3D Gaussian Splatting(3DGS&#x…...