层次聚类分析
1、python语言
from scipy.cluster import hierarchy # 导入层次聚类算法
import matplotlib.pylab as plt
import numpy as np# 生成示例数据
np.random.seed(0)
data = np.random.random((20,1))# 使用树状图找到最佳聚类数
Z = hierarchy.linkage(data,method='weighted',metric='euclidean')
re = hierarchy.dendrogram(Z,color_threshold=0.2,above_threshold_color='#bcbddc')# 输出节点标签
print(re["ivl"])# 画图
plt.title('Dendrogram') # 标题
plt.xlabel('Customers') # 横标签
plt.ylabel('Euclidean distances') # 纵标签
plt.show()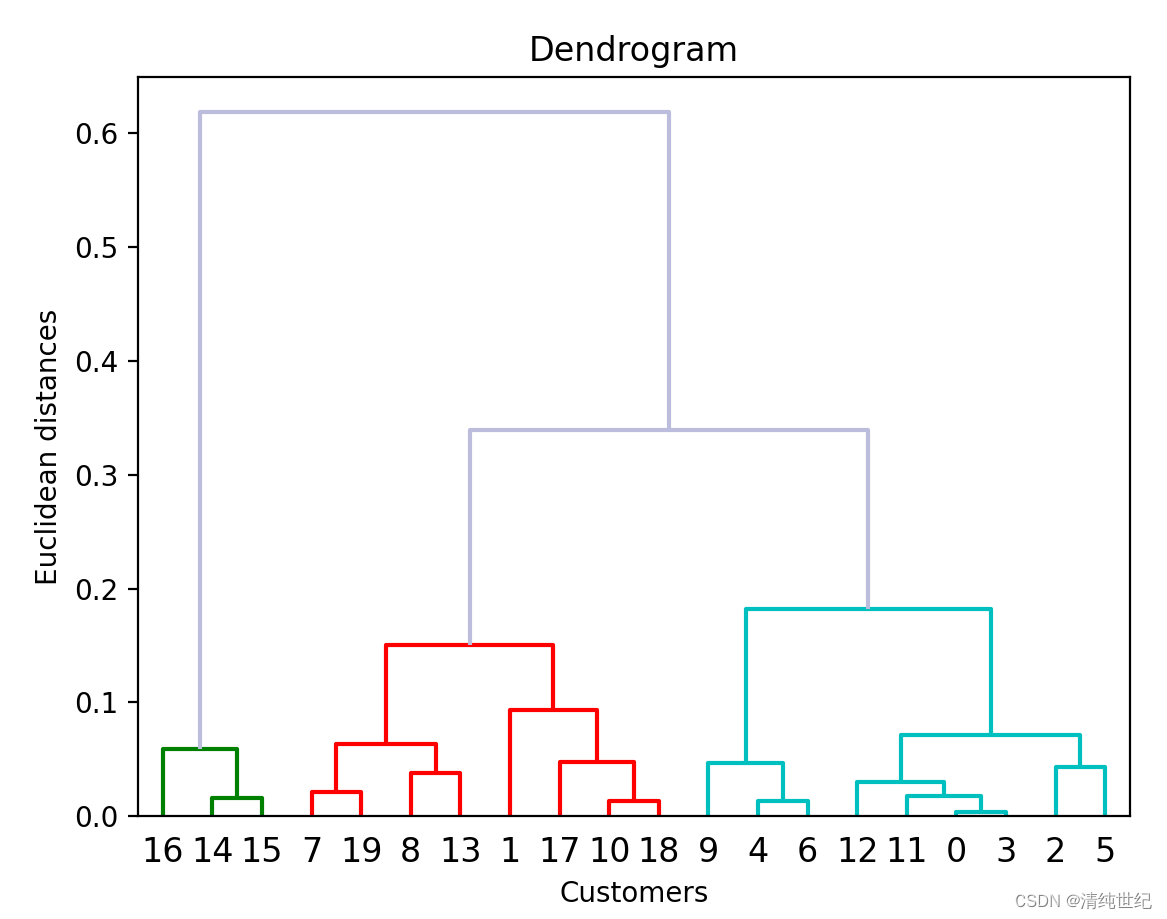
dendrogram函数参数:
Z:层次聚类的结果,即通过scipy.cluster.hierarchy.linkage()函数计算得到的链接矩阵。
p:要显示的截取高度(y轴的阈值),可以用于确定划分群集的横线位置。
truncate_mode:指定截取模式。默认为None,表示不截取,可以选择 'lastp' 或 'mlab' 来截取显示。
labels:数据点的标签,以列表形式提供。
leaf_font_size:叶节点的字体大小。
leaf_rotation:叶节点的旋转角度。
show_leaf_counts:是否显示叶节点的数量。
show_contracted:是否显示合并的群集。
color_threshold:显示不同颜色的阈值,用于将不同群集算法聚类为不同颜色。
above_threshold_color:超过阈值的线段颜色。
orientation:图形的方向,可以选择 'top'、'bottom'、'left' 或 'right'。假设我们输出Z值,获得以下结果:
from scipy.cluster import hierarchy # 导入层次聚类算法
import numpy as np
import pandas as pd# 生成示例数据
np.random.seed(0)
data = np.random.random((8,1))# 使用树状图找到最佳聚类数
Z = hierarchy.linkage(data,method='weighted',metric='euclidean')
row_dist_linkage = pd.DataFrame(Z,columns=['Row Label 1','Row Label 2','Distance','Item Number in Cluster'],index=['Cluster %d' % (i+1) for i in range(Z.shape[0])])
print("\nData Distance via Linkage: \n",row_dist_linkage)
其中,第一列和第二列代表节点标签,包含叶子和枝子;第三列代表叶叶(或叶枝,枝枝)之间的距离;第四列代表该层次类中含有的样本数(记录数)。注:因此,我们可以第三列距离结合图来确定不同簇的样本数量。这里的数量为(n-1),即样本总数减1。
2、R语言
setwd("D:/Desktop/0000/R") #更改路径df <- read.csv("iris.csv",header = T, row.names = 1) #读取工作路径文件
head(df) #查看前6行
hc <- hclust(dist(df))library(ggtree)ggtree(hc,layout="circular",branch.length = "daylight")+xlim(NA,3)+geom_tiplab2(offset=0.1,size=2)+#geom_text(aes(label=node))+geom_highlight(node = 152,fill="red")+geom_highlight(node=154,fill="steelblue")+geom_highlight(node=155,fill="green")+geom_cladelabel(node=152,label="virginica",offset=1.2,barsize = 2,vjust=-0.5,color="red")+geom_cladelabel(node=154,label="versicolor",offset=1.2,barsize = 2,hjust=1.2,color="steelblue")+geom_cladelabel(node=155,label="setosa",offset=1.2,barsize = 2,hjust=-1,color="green")如果没有安装ggtree则先安装
install.packages("BiocManager")
BiocManager::install('ggtree')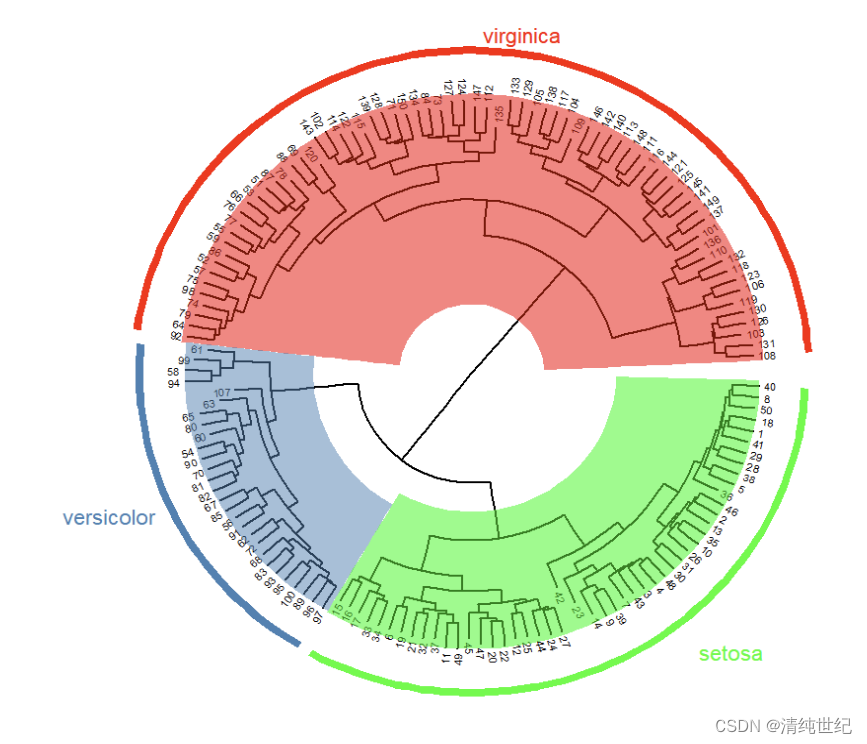
除了上面这种方式外,我们还可以使用下面的方式获取(节点对齐):
setwd("D:/Desktop/0000/R") #更改路径
library(dendextend) #install.packages("dendextend")
library(circlize) #install.packages("circlize")df <- read.csv("iris.csv",header = T, row.names = 1) #读取工作路径文件
head(df) #查看前6行
aa <- hclust(dist(df))# 设置画布大小为4英寸宽,4英寸高
par(mar = c(4, 4, 2, 2) + 0.1)
png("output.png", width = 4, height = 4, units = "in", res = 600)hc <- as.dendrogram(aa) %>%set("branches_lwd", c(1.5)) %>% # 线条粗细set("labels_cex", c(.9)) # 字体大小# 颜色
hc <- hc %>%color_branches(k = 10) %>% #树状分支线条颜色color_labels(k = 10) #文字标签颜色# Fan tree plot with colored labels
circlize_dendrogram(hc,labels_track_height = NA,dend_track_height = 0.7)
# 结束绘图并关闭设备
dev.off()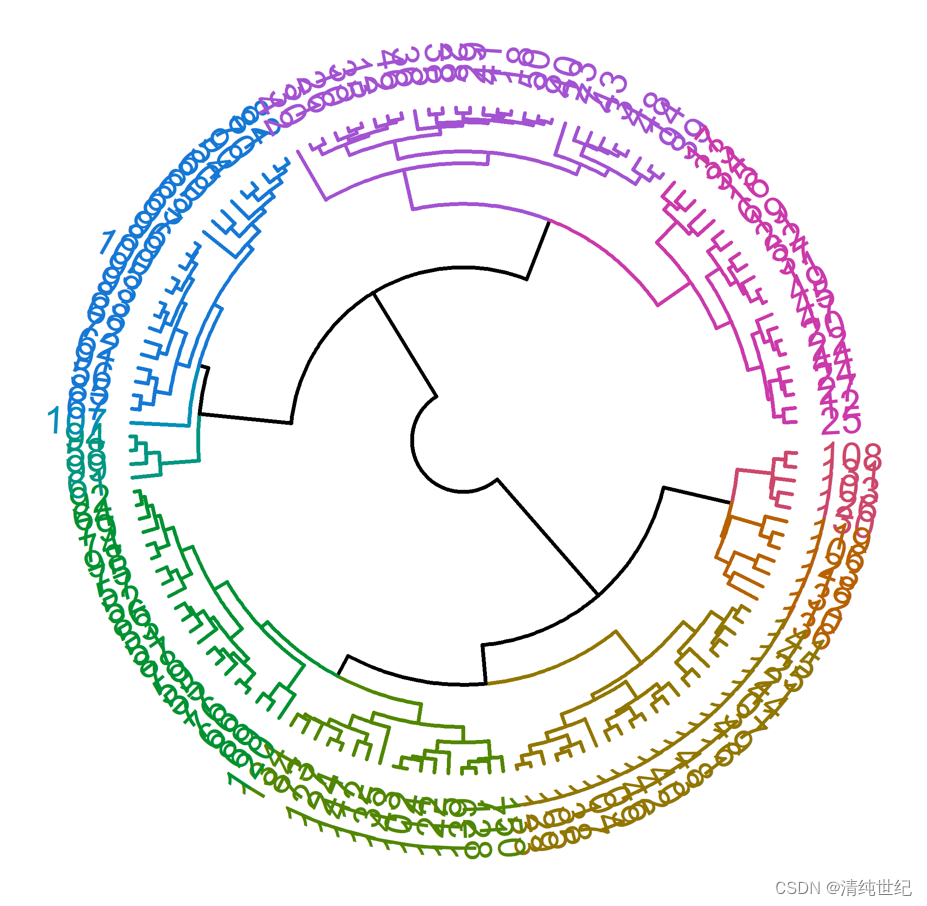
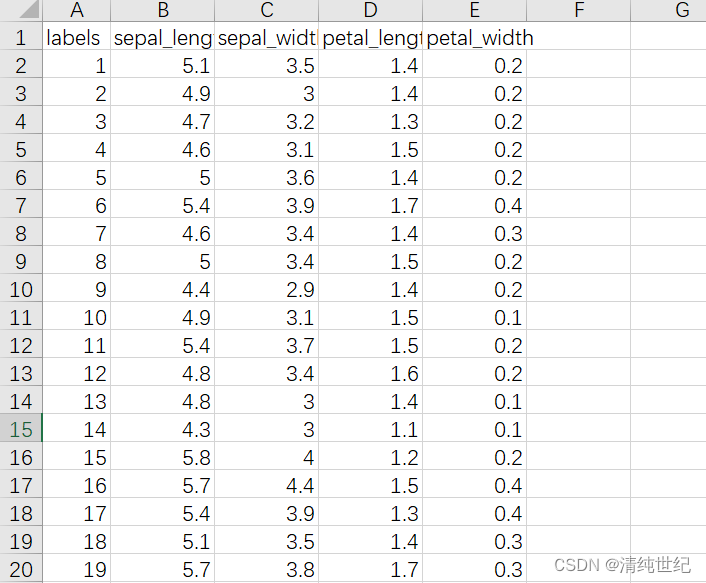
文件数据样式:
更多学习视频:【R包使用】ggtree美化树状图_哔哩哔哩_bilibili、树状图展示聚类分析的结果_哔哩哔哩_bilibili
相关文章:
层次聚类分析
1、python语言 from scipy.cluster import hierarchy # 导入层次聚类算法 import matplotlib.pylab as plt import numpy as np# 生成示例数据 np.random.seed(0) data np.random.random((20,1))# 使用树状图找到最佳聚类数 Z hierarchy.linkage(data,methodweighted,metric…...

Jmeter性能实战之分布式压测
分布式执行原理 1、JMeter分布式测试时,选择其中一台作为调度机(master),其它机器作为执行机(slave)。 2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI࿰…...
学信息系统项目管理师第4版系列08_管理科学基础
1. 科学管理的实质 1.1. 反对凭经验、直觉、主观判断进行管理 1.2. 主张用最好的方法、最少的时间和支出,达到最高的工作效率和最大的效果 2. 资金的时间价值与等值计算 2.1. 资金的时间价值是指不同时间发生的等额资金在价值上的差别 2.2. 把资金存入银行&…...

从2023蓝帽杯0解题heapSpary入门堆喷
关于堆喷 堆喷射(Heap Spraying)是一种计算机安全攻击技术,它旨在在进程的堆中创建多个包含恶意负载的内存块。这种技术允许攻击者避免需要知道负载确切的内存地址,因为通过广泛地“喷射”堆,攻击者可以提高恶意负载被…...

基于SSM的学生宿舍管理系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

jvm 内存模型介绍
一、类加载子系统 1、类加载的过程:装载、链接、初始化,其中,链接又分为验证、准备和解析 装载:加载class文件 验证:确保字节流中包含信息符合当前虚拟机要求 准备:分配内存,设置初始值 解析&a…...

用Jmeter进行压测详解
简介: 1.概述 一款工具,功能往往是很多的,细枝末节的地方也很多,实际的测试工作中,绝大多数场景会用到的也就是一些核心功能,根本不需要我们事无巨细的去掌握工具的所有功能。所以本文将用带价最小的方式讲…...
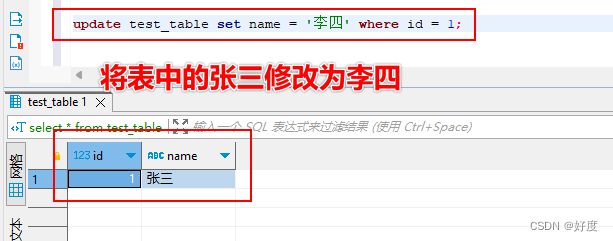
Mysql001:(库和表)操作SQL语句
目录: 》SQL通用规则说明 SQL分类: 》DDL(数据定义:用于操作数据库、表、字段) 》DML(数据编辑:用于对表中的数据进行增删改) 》DQL(数据查询:用于对表中的数…...

甲骨文全区登录地址
日本东部 东京 https://console.ap-tokyo-1.oraclecloud.com https://console.ap-tokyo-1.oraclecloud.com 日本中部 大阪 https://console.ap-osaka-1.oraclecloud.com https://console.ap-osaka-1.oraclecloud.com 韩国中部 首尔 https://console.ap-seoul-1.oraclecloud.c…...

Java面试题第八天
一、Java面试题第八天 1.如何实现对象克隆? 浅克隆 浅克隆就是我们可以通过实现Cloneable接口,重写clone,这种方式就叫浅克隆,浅克隆 引用类型的属性,是指向同一个内存地址,但是如果引用类型的属性也进行浅克隆就是深…...

什么是同步容器和并发容器的实现?
同步容器和并发容器都是用于在多线程环境中管理数据的容器,但它们在实现和用法上有很大的区别。 同步容器: 同步容器是使用传统的同步机制(如synchronized关键字或锁)来保护容器内部数据结构的线程安全容器。同步容器通常是单线…...
学Python的漫画漫步进阶 -- 第十六步
学Python的漫画漫步进阶 -- 第十六步 十六、多线程16.1 线程相关的知识16.1.1 进程16.1.2 线程16.1.3 主线程 16.2 线程模块——threading16.3 创建子线程16.3.1 自定义函数实现线程体16.3.2 自定义线程类实现线程体 16.4 线程管理16.4.1 等待线程结束16.4.2 线程停止 16.5 动动…...
 考点精析-架构考点5:数据字典(Data Dictionary))
MySQL 8.0 OCP (1Z0-908) 考点精析-架构考点5:数据字典(Data Dictionary)
文章目录 MySQL 8.0 OCP (1Z0-908) 考点精析-架构考点5:数据字典(Data Dictionary)File-based Metadata Storage (基于文件的元数据存储)Transactional Data Dictionary (事务数据字典)Serialized Dictionary Informat…...

7分钟了解ChatGPT是如何运作的
ChatGPT是现在最为热门的聊天助手应用,它使用了一个大型语言模型(LLM),即GPT-3.5。它通过大量的文本数据进行训练,以理解和生成人类语言。但是,你是否有了解过ChatGPT是如何运作的吗? 下面我们就一起通过这个视频来一起…...

蓝桥杯打卡Day8
文章目录 C翻转矩阵幂 一、C翻转IO链接 本题思路:本题需要找出顺时针旋转和逆时针旋转的规律,然后就可以解决该问题。 矩阵顺时针90旋转规律:列号变为行号,(n-行号-1)变为列号 规律:a[i][j]b[j][n-i1]; 矩阵逆时针90旋转规律:行号变为列号࿰…...

React 学习笔记目录
学习使用的开发工具 编译器 VSCode 开发语言工具 TypeScript /JavaScript 重要程度分类 一般 这个程度的知识点主要是达到熟练掌握即可,不用太深入研究和学习。 重要 这个程度的知识点主要是达到熟练掌握,并且内部的原理切要熟记,因为会关…...
)
一起Talk Android吧(第五百五十一回:如何自定义SplashScreen)
文章目录 概念介绍实现方法修改启动页中的内容修改启动页显示时间修改启动面消失时的页面各位看官们大家好,上一回中咱们说的例子是"如何适配SplashScreen",本章回中介绍的例子是" 如何自定义SplashScreen"。闲话休提,言归正转,让我们一起Talk Android…...

PYTHON-模拟练习题目集合
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
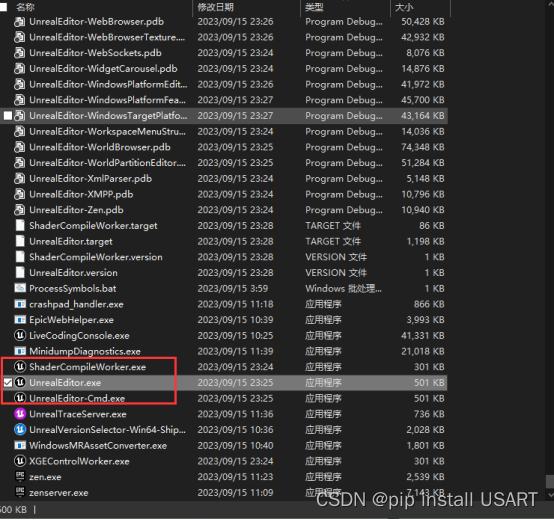
UE5学习笔记(1)——从源码开始编译安装UE5
目录 0. 前期准备1. Git bash here2. 克隆官方源码。3. 选择安装分支4. 运行Setup.bat,下载依赖文件5. 运行GenerateProjectFiles.bat生成工程文件6. 生成完成,找到UE5.sln/UE4.sln7. 大功告成 0. 前期准备 0.1 在windows的话,建议装一个Git…...
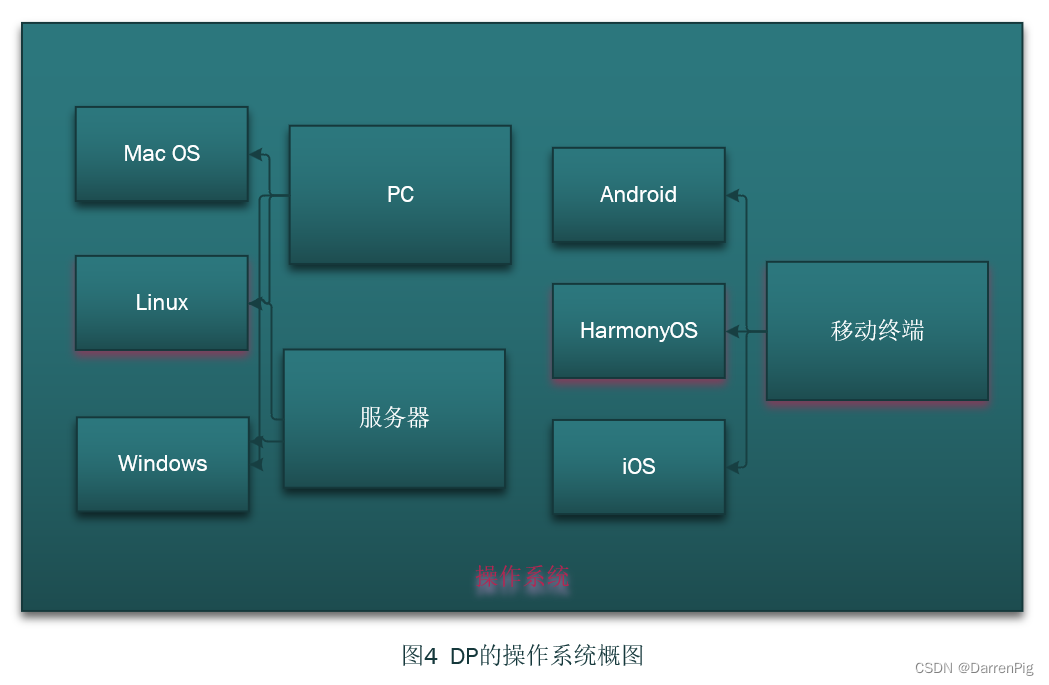
DP读书:《openEuler操作系统》(二)操作系统的发展史
操作系统的发展历史 操作系统的发展历史手工操作时代批处理系统多道程序系统分时操作系统CTSSMULTICS的历史UNIX和Linux的历史Debian系列Red Hat系列 DOS和Windows的历史DOS的历史:Windows的历史: Android和iOS的历史Android:iOS:…...

会话搜索服务器实战:从架构设计到生产部署的完整指南
1. 项目概述与核心价值最近在折腾一个挺有意思的玩意儿,叫session_search_server。这名字乍一看有点抽象,但如果你做过聊天机器人、客服系统,或者任何需要处理多轮对话、历史记录查询的应用,那你肯定遇到过类似的痛点:…...

Windows动态光标优化:LuumaCursorHelper工具包详解与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的小工具,起因是发现很多朋友在用LuumaCursor这款动态光标主题时,总会遇到一些“小麻烦”。比如,安装后光标在某些应用里不显示、动画卡顿,或者想自定义一下效果却无从下手。我自己也…...

VCSA 7.0 报 vAPI Endpoint 黄灯告警?别慌,这份保姆级排查与修复指南帮你搞定
VCSA 7.0 vAPI Endpoint黄灯告警全流程诊断手册 凌晨三点,监控系统突然弹出一条告警——vCenter Server的vAPI Endpoint服务状态由绿转黄。作为运维负责人,你需要在最短时间内判断这是需要立即处理的严重故障,还是可以暂缓的偶发异常。本文将…...

制造业备品备件管理痛点破解:磐石电气无人仓库解决方案
在制造业设备自动化、产线连续化运行需求日益提升的当下,备品备件、工装夹具、维修耗材及易损件等物资,已成为保障设备稳定运转、快速处置故障、降低非计划停机损失的核心支撑。尤其在电子制造、半导体、新能源、汽车零部件、电力电气等技术密集型行业&a…...

AI技能文件管理工具agent-skills-lint:多助手环境下的统一质检方案
1. 项目概述:为什么我们需要一个AI技能文件“质检员”如果你和我一样,同时在使用Claude Code、Cursor、Aider这些AI编程助手,那你一定遇到过这个烦人的问题:每个助手都有自己的“技能”(Skills)系统&#x…...

Linux终端美化:cmatrix屏保的安装与个性化配置指南
1. 初识cmatrix:从黑客帝国到你的终端 第一次看到cmatrix运行效果时,我正窝在咖啡馆调试服务器。黑色背景上不断下落的绿色字符,瞬间让我想起《黑客帝国》里尼奥看到的数字雨。这个诞生于2002年的开源项目,最初只是开发者Chris Al…...

别再死记硬背CTL公式了!用UPPAAL模拟器手把手带你理解A[]和E<>的区别
别再死记硬背CTL公式了!用UPPAAL模拟器手把手带你理解A[]和E<>的区别 刚接触形式化验证工具UPPAAL时,最令人头疼的莫过于那些晦涩难懂的CTL(计算树逻辑)公式。A[]、E<>这些符号组合看起来像天书,教科书上的…...

3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南
3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英…...
用C++实现信奥题 P8563 Magenta Potion)
打卡信奥刷题(3245)用C++实现信奥题 P8563 Magenta Potion
P8563 Magenta Potion 题目描述 给定一个长为 nnn 的整数序列 aaa,其中所有数的绝对值均大于等于 222。有 qqq 次操作,格式如下: 1 i k\texttt{1 i k}1 i k,表示将 aia_iai 修改为 kkk。保证 $k $ 的绝对值大于等于 222。 2 l r…...

5步掌握Betaflight 2025升级:从配置到飞行的完整解决方案
5步掌握Betaflight 2025升级:从配置到飞行的完整解决方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 还在为穿越机飞行抖动和信号不稳定而烦恼吗?Betaflight …...