Hadoop生态圈中的Flume数据日志采集工具
Hadoop生态圈中的Flume数据日志采集工具
- 一、数据采集的问题
- 二、数据采集一般使用的技术
- 三、扩展:通过爬虫技术采集第三方网站数据
- 四、Flume日志采集工具概述
- 五、Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf
- 六、Flume案例实操
- 1、采集一个网络端口的数据到控制台
- 2、采集一个文件的数据控制台
- 3、采集一个文件夹下的新文件数据到控制台
- 4、采集一个网络端口的数据到HDFS中
- 5、多数据源和多目的地案例
- 6、多Flume进程组合的案例
一、数据采集的问题
数据采集一般指的是将数据采集到大数据环境下进行持久化、海量化的保存,目的主要是为了我们后期的大数据处理(数据统计分析、数据挖掘等等)沉底数据基础。
不同的来源的数据我们一般有不同的数据采集方式
1、数据来源于我们的RDBMS关系型数据库:Sqoop数据迁移工具实现数据的采集
2、数据来源于我们系统运行产生的日志文件:日志文件记录的数据量特别庞大,但是日志文件不属于大数据存储系统中东西,因此日志文件记录不了海量的数据,日志文件都会有一个定期清理规则。采集日志文件数据到大数据环境中。
一般采集日志文件数据到大数据环境使用的就是Flume技术
3、数据来源于其他网站:开发一个电影网站,电影网站应该具备哪些功能,哪些类型的电影能受用户的欢迎。分析竞品数据,这种情况竟品数据都是人家别人家网站的数据,但是我们需要分析,但是人家不给你数据,通过爬虫获取数据(一不留神就犯法)。
4、数据来源于各种传感器设备:不需要我们管
5、第三方提供、购买的第三方数据、开源数据集平台提供的(阿里云的天池数据集、kaggle数据集平台、飞浆数据集平台、各个地区的政府公开数据集平台)
二、数据采集一般使用的技术
sqoop技术:采集RDBMS的数据到大数据环境中
Flume技术:采集系统/网站产生的日志文件数据、端口数据等等到大数据环境中
爬虫技术:采集第三方的数据,爬虫一般是把采集的数据放到一个文件或者RDBMS数据库当中
三、扩展:通过爬虫技术采集第三方网站数据
爬虫技术就是通过读取网页/网站的界面结构,获取网页中嵌套的数据
爬虫目前主要有两种类型的爬虫
- 通过代码进行爬虫
python写的- 优点:在于可以定制化爬虫内容
- 缺点:
1、编写代码,代码是非常复杂
2、很多网站做了反爬虫校验,可能写了代码也无法爬取数据
- 通过可视化爬虫工具爬虫
- 优点:不需要写一行代码,只需要点点点就可以定制化数据爬虫,反爬虫问题不用担心
- 缺点:1、无法随心所欲爬取数据,2、可能会收费
- 八爪鱼爬虫工具、集搜客爬虫工具…
四、Flume日志采集工具概述
Flume也是Apache开源的顶尖项目,专门用来采集海量的日志数据到指定的目的地。
Flume采集数据采用一种流式架构思想,只要数据源有数据,就可以源源不断的采集数据源的数据到目的地
Flume的组成架构
- Flume之所以可以实现采集不同数据源(不仅仅只包含日志文件数据)到指定的目的地,源于Flume的设计机构。
- Agent:一个Flume采集数据的进程,一个Flume软件可以启动多个Flume采集进程Agent
- Source:Flume的一个数据源组件,是Flume专门用来连接数据源的组件,一个Flume采集进程Agent中,Source组件可以有一个也可以有多个
- Channel:Flume中一个类似于缓存池的组件,缓存池的主要作用就是用来临时保存source数据源采集的数据,目的地需要数据,从缓冲池中获取,防止数据源数据产生过快,而目的地消费数据过慢,导致程序崩溃的问题。一个Agent中,可以存在多个Channel组件
- Sink:Flume中一个目的地(下沉地)组件,是Flume专门用来连接目的地的组件,一个Flume进程中,sink组件也可以有多个,但是一个sink只能从一个channel中获取数据。不能一个sink从不同channel拉取数据
- event:Flume中数据传输单位。Flume采集数据源的数据时,会把数据源的数据封装为一个个的event。
- 脚本文件xxx.conf:需要用户自己编写的,Flume采集数据时,数据源和目的地有很多种,因此如果我们采集数据时,我们必须自定义一个脚本文件,在脚本文件中需要定义采集的数据源的类型、channel管道的类型、sink的目的地的类型、以及source channel sink三者之间的关系。脚本文件定义成功之后,我们才能去根据脚本文件启动Flume采集进程Agent
- 【注意】一个source只能连接一个数据源,一个sink只能连接一个目的地
Flume的采集数据的工作流程
- 首先我们先编写xx.conf脚本文件定义我们的采集的数据源、目的地、管道的类型,定义成功之后我们根据脚本启动Flume采集进程Agent。一旦当Flume采集进程启动成功,source就会去监听数据源的数据,一旦当数据源有数据产生,那么source组件会把数据源的数据封装为一个个的event,然后source把event数据单位传输到channel管道中缓存,然后sink组件会从channel中拉取指定个数的event,将event中数据发送给sink连接的目的地。
Flume安装部署:三部曲
-
1、上传解压
-
2、配置环境变量
-
export FLUME_HOME=/opt/app/flume-1.11.0 export PATH=$PATH:$FLUME_HOME/bin -

-
-
3、修改配置文件
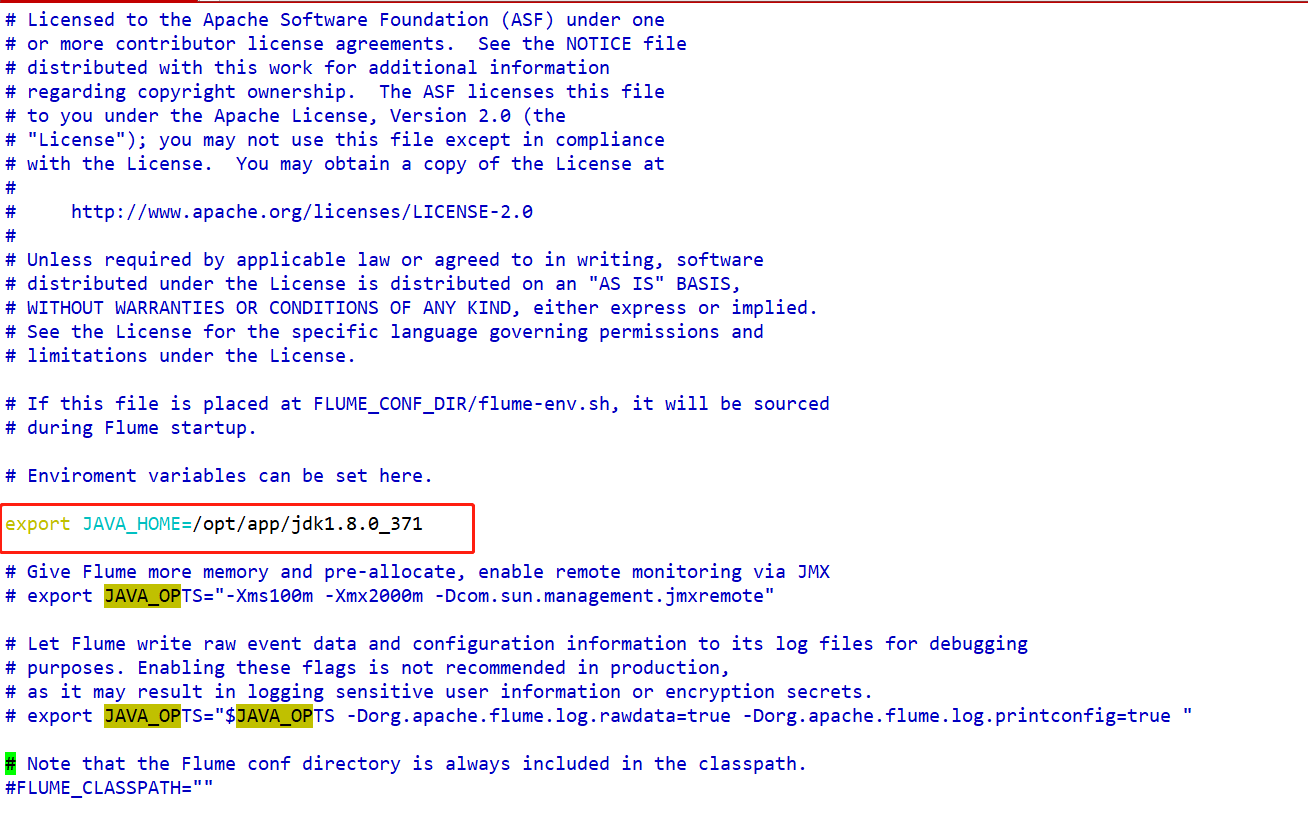
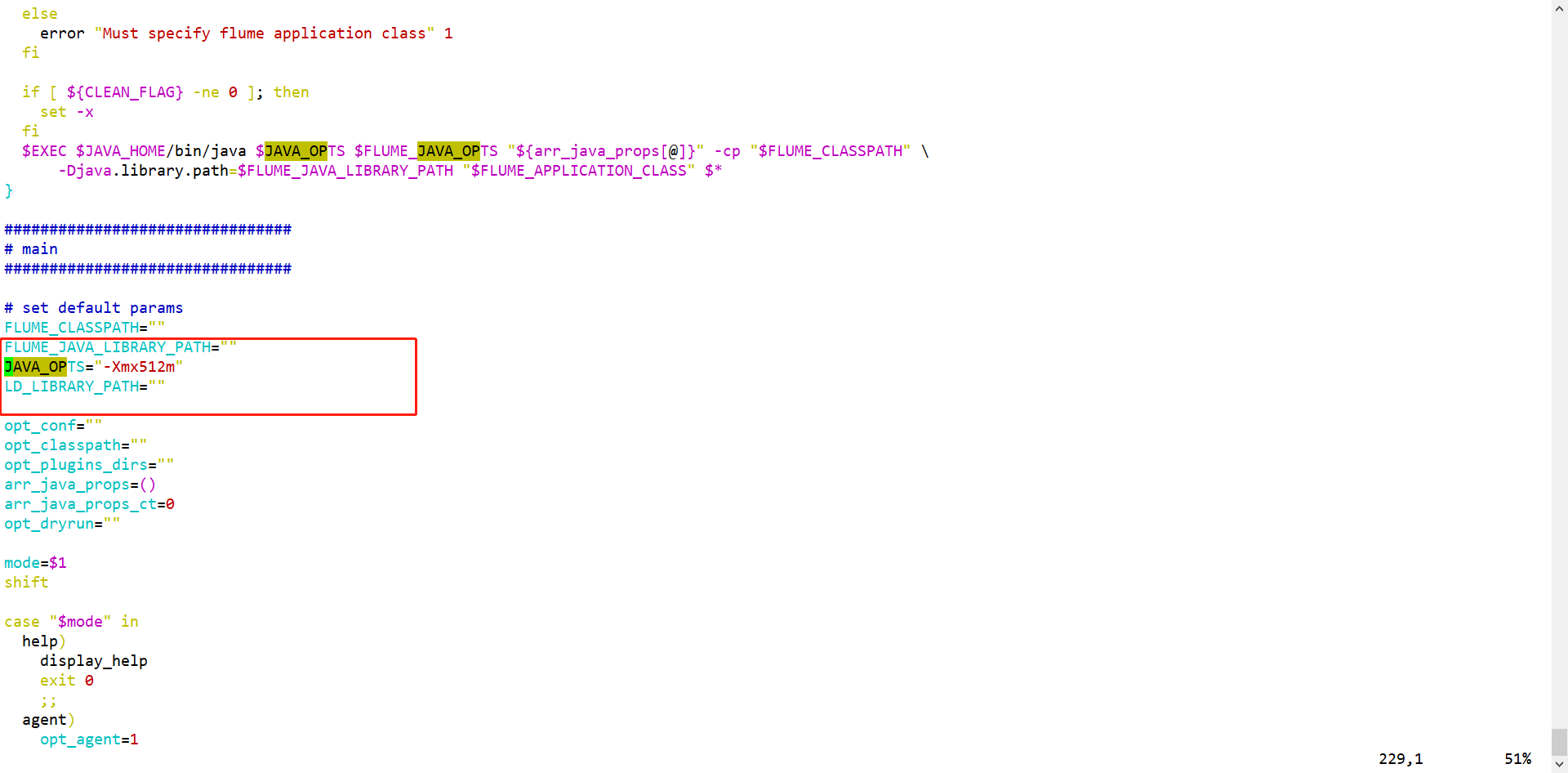
- conf/flume-env.sh
- bin/flume-ng
flume运行需要Java环境,文件中需要指定Flume运行需要的内存容量
- conf/flume-env.sh
五、Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf
Flume支持多种数据源、管道、目的地,我们采集数据的时候,并不是所有的数据源和目的地都要使用,而是使用我们需要的源头和目的地。但是Flume不知道你需要什么数据源、需要什么目的地。
通过脚本文件指定我们采集的数据源、目的地、管道
脚本文件主要由五部分组成:
- 1、起别名
- 我们可以根据采集脚本启动一个Flume进程Agent,一个Flume支持启动多个Agent,Flume要求每一个Agent必须有自己的一个别名,Flume启动的多个Agent的别名不能重复。
- 同时Flume一个Agent进程中,可以有多个source、多个channel、多个sink,如何区分多个组件?
我们还需要多Agent进程中的source、channel、sink起别名的 - Agent、source、channel、sink起别名
- 2、配置Source组件
- 我们一个Flume进程中,可能存在1个或者多个数据源,每一个source组件需要连接一个数据源,但是数据源到底是谁,如何连接,我们需要配置。
- 3、配置channel组件
- 一个Agent中,可能存在一个或者多个channel,channel也有很多种类型的,因此我们需要配置我们channel的类型以及channel的容量。
- 4、配置Sink组件
- 一个Agent,可以同时将数据下沉到多个目的地,一个sink只能连接一个目的地,目的地到底是谁,如何连接,需要配置sink。
- 5、组装source、channel、sink(核心)
- 一个source的数据可以发送给多个channel,一个sink只能读取一个channel的数据。因此我们需要根据业务逻辑配置source、channel、sink的连接关系。
六、Flume案例实操
1、采集一个网络端口的数据到控制台
1、分析案例的组件类型
- source:网络端口 netcat
- channel:基于内存的管道即可memory
- sink:控制台–Flume的日志输出logger
2、编写脚本文件portToConsole.conf
# 1、配置agent、source、channel、sink的别名
demo.sources=s1
demo.channels=c1
demo.sinks=k1# 2、配置source组件连接的数据源--不同数据源的配置项都不一样 监听netcat type bind port
demo.sources.s1.type=netcat
demo.sources.s1.bind=localhost
demo.sources.s1.port=44444# 3、配置channel组件的类型--不同类型的管道配置项也不一样 基于内存memory的管道
demo.channels.c1.type=memory
demo.channels.c1.capacity=1000
demo.channels.c1.transactionCapacity=200# 4、配置sink组件连接的目的地--不同类型的sink配置项不一样 基于logger的下沉地
demo.sinks.k1.type=logger# 5、配置source channel sink之间的连接 source 连接channel sink也要连接channel
# 一个source的数据可以发送给多个channel 一个sink只能拉去一个channel的数据
demo.sources.s1.channels=c1
demo.sinks.k1.channel=c1
3、根据脚本文件启动Flume采集程序
- flume-ng agent -n agent的别名(必须和文件中别名保持一致) -f xxx.conf的路径 -Dflume.root.logger=INFO,console
4、测试
- 我们只需要给本地的44444端口发送数据,看看Flume的控制台能否把数据输出即可
- 需要新建一个和Linux的连接窗口,然后使用
telnet localhost 44444 命令连接本地的44444端口发送数据 - telnet软件linux默认没有安装,需要使用yum安装一下
yum install -y telnet - 必须先启动flume采集程序,再telnet连接网络端口发送数据
2、采集一个文件的数据控制台
1、案例需求
- 现在有一个文件,文件源源不断的记录用户的访问日志信息,我们现在想通过Flume去监听这个文件,一旦当这个文件有新的用户数据产生,把数据采集到flume的控制台上
2、案例分析
- source:exec(将一个linux命令的输出当作数据源、自己写监听命令) 、taildir
- channel:memory
- sink:logger
3、编写脚本文件
# 1、起别名
demo01.sources=s1
demo01.channels=c1
demo01.sinks=k1# 2、定义数据源 exec linux命令 监听一个文件 tail -f|-F 文件路径
demo01.sources.s1.type=exec
demo01.sources.s1.command=tail -F /root/a.log
# 3、定义管道
demo01.channels.c1.type=memory
demo01.channels.c1.capacity=1000
demo01.channels.c1.transactionCapacity=200# 4、配置sink目的地 logger
demo01.sinks.k1.type=logger# 5、关联组件
demo01.sources.s1.channels=c1
demo01.sinks.k1.channel=c1
4、启动
flume-ng agent -n demo01 -f /root/fileToConsole.cong -Dflume.root.logger=INFO,consoleecho "zs" >> a.log
5、测试
3、采集一个文件夹下的新文件数据到控制台
1、案例需求
- 有一个文件夹,文件夹下记录着网站产生的很多日志数据,而且日志文件不止一个,就想把文件夹下所有的文件数据采集到控制台,同时如果这个文件夹下有新的数据文件产生,也会把新文件的数据全部采集到控制台上。
2、案例分析
- source:Spooling Directory Source
- channel:memory
- sink:logger
3、编写配置文件
# 1、起别名
demo01.sources=s1
demo01.channels=c1
demo01.sinks=k1# 2、定义数据源 Spooling Directory Source
demo01.sources.s1.type=spooldir
demo01.sources.s1.spoolDir=/root/demo
# 3、定义管道
demo01.channels.c1.type=memory
demo01.channels.c1.capacity=1000
demo01.channels.c1.transactionCapacity=200# 4、配置sink目的地 logger
demo01.sinks.k1.type=logger# 5、关联组件
demo01.sources.s1.channels=c1
demo01.sinks.k1.channel=c1
4、运行
5、测试
4、采集一个网络端口的数据到HDFS中
1、案例需求
- 监控一个网络端口产生的数据,一旦当端口产生新的数据,就把数据采集到HDFS上以文件的形式进行存放
2、案例分析
- source:网络端口netcat
- channel:基于内存的管道 memory
- sink:HDFS
3、编写脚本文件
# 1、配置agent、source、channel、sink的别名
demo.sources=s1
demo.channels=c1
demo.sinks=k1# 2、配置source组件连接的数据源--不同数据源的配置项都不一样 监听netcat type bind port
demo.sources.s1.type=netcat
demo.sources.s1.bind=localhost
demo.sources.s1.port=44444# 3、配置channel组件的类型--不同类型的管道配置项也不一样 基于内存memory的管道
demo.channels.c1.type=memory
demo.channels.c1.capacity=1000
demo.channels.c1.transactionCapacity=200# 4、配置sink组件连接的目的地--基于HDFS的
demo.sinks.k1.type=hdfs
# 配置采集到HDFS上的目录 数据在目录下以文件的形式进行存放 文件的格式 FlumeData.时间戳
demo.sinks.k1.hdfs.path=hdfs://single:9000/flume
# 目录下生成的文件的前缀 如果没有配置 默认就是FlumeData
demo.sinks.k1.hdfs.filePrefix=collect
# 指定生成的文件的后缀 默认是没有后缀的 生成的文件的格式collect.时间戳.txt
demo.sinks.k1.hdfs.fileSuffix=txt
# 目录下采集的数据并不是记录到一个文件中,文件是会滚动生成新的文件的
# 滚动的规则有三种:1、基于时间 2、基于文件的容量滚动 3、基于文件的记录的event数量进行滚动
# 默认值: 时间30s 容量 1024b event 10
# 时间滚动规则 如果值设置为0 那么就代表不基于时间生成新的文件
demo.sinks.k1.hdfs.rollInterval=60
# 文件容量的滚动规则 单位b 如果设置为0 代表不基于容量滚动生成新的文件
demo.sinks.k1.hdfs.rollSize=100
# event数量的滚动规则 一般设置为0 代表不急于event数量滚动生成新的文件
demo.sinks.k1.hdfs.rollCount=0
# 文件在HDFS上的默认的存储格式是SequenceFile文件格式
demo.sinks.k1.hdfs.fileType=DataStream
# 设置event的头部使用本地时间戳作为header
demo.sinks.k1.hdfs.useLocalTimeStamp=true# 5、配置source channel sink之间的连接 source 连接channel sink也要连接channel
# 一个source的数据可以发送给多个channel 一个sink只能拉去一个channel的数据
demo.sources.s1.channels=c1
demo.sinks.k1.channel=c1
4、启动采集进程(必须先启动HDFS)
【注意】flume的依赖的guava和hadoop的guava有冲突,需要将flume的lib目录下的guava依赖删除,同时将hadoop的share/common/lib/guava依赖复制到flume的lib目录下
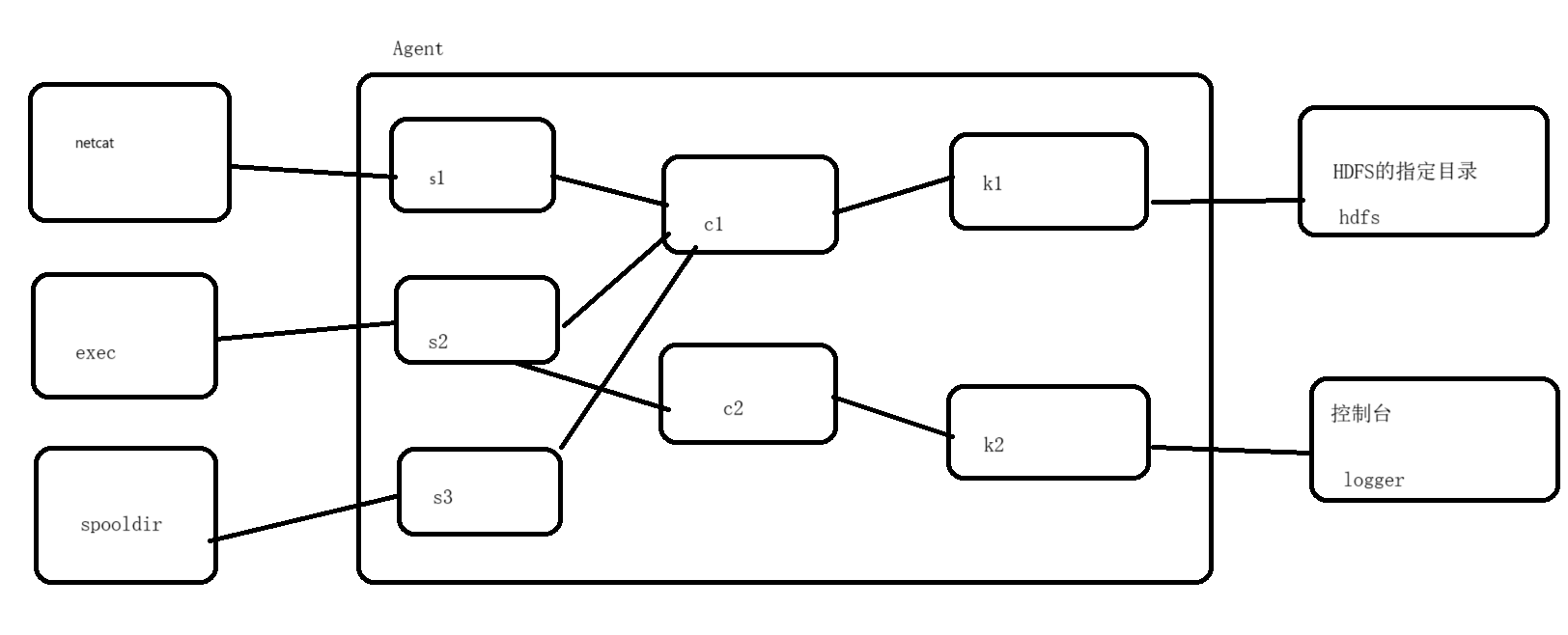
5、多数据源和多目的地案例
1、案例需求
- 现在有三个数据源:1、网络端口 2、文件 3、文件夹
想把这三个数据源的数据全部采集到HDFS的指定目录下,同时还要求把文件数据源的数据在控制台上同步进行展示
2、案例分析
- source:netcat exec spooldir
- channel:两个基于内存的
- sink:1、hdfs 2、logger
3、编写脚本文件
# 1、起别名 三个数据源 两个管道 两个sink
more.sources=s1 s2 s3
more.channels=c1 c2
more.sinks=k1 k2# 2、定义数据源 三个
# 定义s1数据源 s1连接的是网络端口
more.sources.s1.type=netcat
more.sources.s1.bind=localhost
more.sources.s1.port=44444
# 定义s2的数据源 s2连接的是文件 /root/more.log文件
more.sources.s2.type=exec
more.sources.s2.command=tail -F /root/more.log
# 定义s3的数据源 s3监控的是一个文件夹 /root/more
more.sources.s3.type=spooldir
more.sources.s3.spoolDir=/root/more# 3、定义channel管道 两个 基于内存的
# 定义c1管道 c1管道需要接受三个数据源的数据
more.channels.c1.type=memory
more.channels.c1.capacity=20000
more.channels.c1.transactionCapacity=5000
# 定义c2管道 c2管道只需要接收一个数据源 s2的数据
more.channels.c2.type=memory
more.channels.c2.capacity=5000
more.channels.c2.transactionCapacity=500# 4、定义sink 两个 HDFS logger
# 定义k1这个sink 基于hdfs
more.sinks.k1.type=hdfs
# hdfs支持生成动态目录--基于时间的 /more/2023-08-25
more.sinks.k1.hdfs.path=hdfs://single:9000/more/%Y-%m-%d
# 如果设置了动态目录,那么必须指定动态目录的滚动规则-多长时间生成一个新的目录
more.sinks.k1.hdfs.round=true
more.sinks.k1.hdfs.roundValue=24
more.sinks.k1.hdfs.roundUnit=hourmore.sinks.k1.hdfs.filePrefix=collect
more.sinks.k1.hdfs.fileSuffix=.txt
more.sinks.k1.hdfs.rollInterval=0
more.sinks.k1.hdfs.rollSize=134217728
more.sinks.k1.hdfs.rollCount=0
more.sinks.k1.hdfs.fileType=DataStream
more.sinks.k1.hdfs.useLocalTimeStamp=true
# 定义k2 logger
more.sinks.k2.type=logger# 5、组合agent的组件
more.sources.s1.channels=c1
more.sources.s2.channels=c1 c2
more.sources.s3.channels=c1
more.sinks.k1.channel=c1
more.sinks.k2.channel=c2
6、多Flume进程组合的案例
1、案例需求
- 三个Flume进程,其中第一个Flume采集端口的数据,第二个Flume采集文件的数据,要求第一个Flume进程和第二个Flume进程将采集到的数据发送给第三个Flume进程,第三个Flume进程将接受到的数据采集到控制台上。
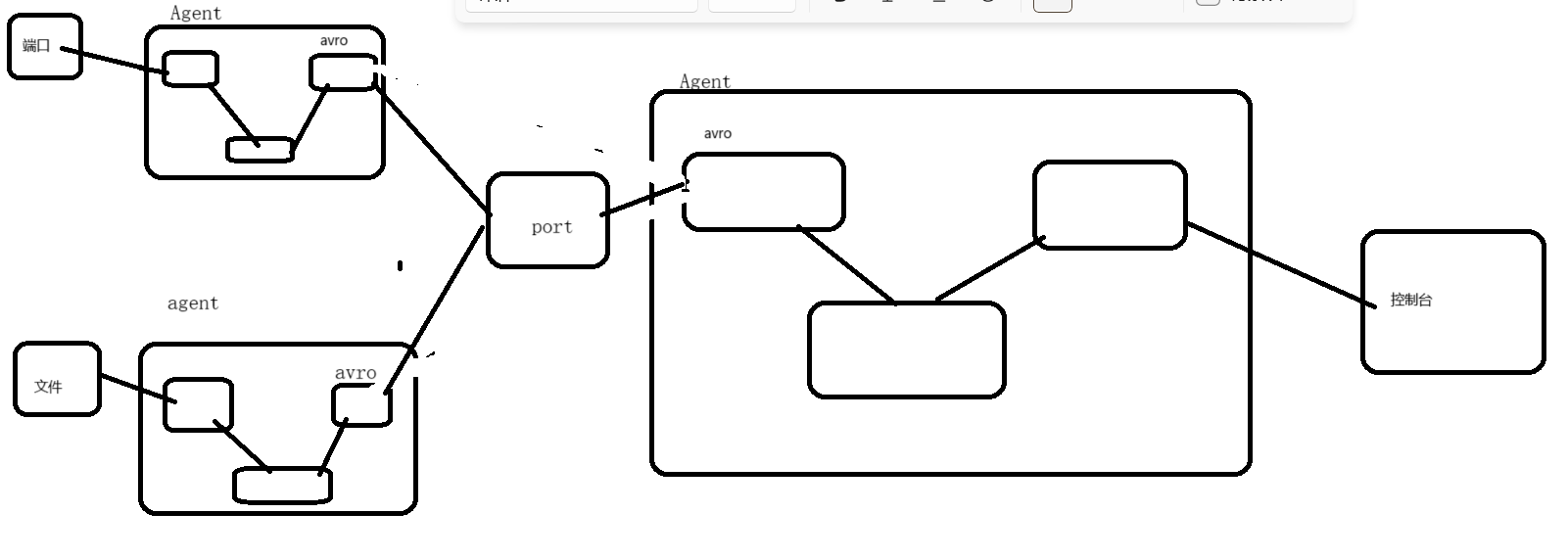
2、案例分析
- first agent
- source :netcat
- channel:memory
- sink:avro
- second agent
- source:exec
- channel:memory
- sink:avro
- third agent
- source:avro
- channel:memory
- sink:logger
3、编写脚本文件
-
第一个脚本监听端口到avro的
-
first.sources=s1 first.channels=c1 first.sinks=k1first.sources.s1.type=netcat first.sources.s1.bind=localhost first.sources.s1.port=44444first.channels.c1.type=memory first.channels.c1.capacity=1000 first.channels.c1.transactionCapacity=500first.sinks.k1.type=avro first.sinks.k1.hostname=localhost first.sinks.k1.port=60000first.sources.s1.channels=c1 first.sinks.k1.channel=c1
-
-
第二脚本文件监听文件数据到avro的
-
second.sources=s1 second.channels=c1 second.sinks=k1second.sources.s1.type=exec second.sources.s1.command=tail -F /root/second.txtsecond.channels.c1.type=memory second.channels.c1.capacity=1000 second.channels.c1.transactionCapacity=500second.sinks.k1.type=avro second.sinks.k1.hostname=localhost second.sinks.k1.port=60000second.sources.s1.channels=c1 second.sinks.k1.channel=c1
-
-
第三个脚本文件监听avro汇总的数据到logger的
-
third.sources=s1 third.channels=c1 third.sinks=k1# avro类型当作source 需要bind和port参数 如果当作sink使用 需要hostname port third.sources.s1.type=avro third.sources.s1.bind=localhost third.sources.s1.port=60000third.channels.c1.type=memory third.channels.c1.capacity=1000 third.channels.c1.transactionCapacity=500third.sinks.k1.type=loggerthird.sources.s1.channels=c1 third.sinks.k1.channel=c1
-
4、启动脚本程序
-
先启动第三个脚本,再启动第一个和第二脚本
-
flume-ng agent -n third -f /root/third.conf -Dflume.root.logger=INFO,console flume-ng agent -n first -f /root/first.conf -Dflume.root.logger=INFO,console flume-ng agent -n second -f /root/second.conf -Dflume.root.logger=INFO,console
-
相关文章:
Hadoop生态圈中的Flume数据日志采集工具
Hadoop生态圈中的Flume数据日志采集工具 一、数据采集的问题二、数据采集一般使用的技术三、扩展:通过爬虫技术采集第三方网站数据四、Flume日志采集工具概述五、Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf六、Flume案例实操1、采集一个网络…...

FFmpeg获取媒体文件的视频信息
视频包标志位 代码 printf("index:%d\n", in_stream->index);结果 index:0视频帧率 // avg_frame_rate: 视频帧率,单位为fps,表示每秒出现多少帧 printf("fps:%lffps\n", av_q2d(in_stream->avg_frame_rate));结果 fps:29.970070fps…...
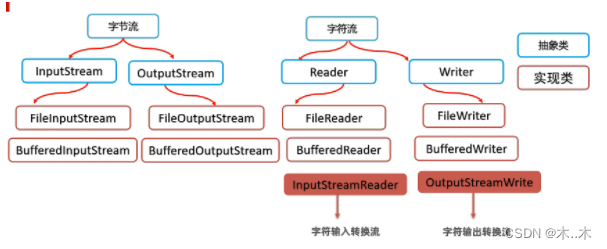
io概述及其分类
一、IO概念 • I/O 即输入Input/ 输出Output的缩写,其实就是计算机调度把各个存储中(包括内存和外部存储)的数据写入写出的过程; I : Input O : Output 通过IO可以完成硬盘文件的读和写。 • java中用“流(stream&am…...
)
前端面试话术集锦第 14 篇:高频考点(React常考基础知识点)
这是记录前端面试的话术集锦第十四篇博文——高频考点(React常考基础知识点),我会不断更新该博文。❗❗❗ 1. 生命周期 在V16版本中引入了Fiber机制。这个机制一定程度上的影响了部分生命周期的调用,并且也引入了新的2个API来解决问题。 在之前的版本中,如果你拥有一个很…...

UI/UX+前端架构:设计和开发高质量的用户界面和用户体验
引言 随着数字化和互联网的普及,越来越多的企业和组织需要高质量的用户界面和用户体验,以及可靠、高效的前端架构。UI/UX设计师和前端架构师可以为这些企业和组织提供所需的技术和创意支持。本文将介绍UI/UX前端架构这个方向,包括设计原则、…...

长尾关键词挖掘软件-免费的百度搜索关键词挖掘
嗨,大家好!今天,我想和大家聊一聊长尾关键词挖掘工具。作为一个在网络世界里摸爬滚打多年的人,我对这个话题有着一些个人的感悟和见解,希望能与大家分享。 首先,让我坦白一点,长尾关键词挖掘工具…...

React Native 环境配置(mac)
React Native 环境配置(mac) 1.Homebrew2.Node.js、WatchMan3.Yarn4.Android环境配置1.安装JDK2.下载AndroidStudio1.国内配置 Http Proxy2.安装SDK1.首先配置sdk的路径2.SDK 下载 3.创建模拟器4.配置 ANDROID_HOME 环境变量 5.IOS环境1.升级ruby&#x…...
CAD for JS:VectorDraw web library 10.1004.1 Crack
VectorDraw web library经过几年的研究,通过互联网展示或工作的可能性并拒绝了各种项目,我们最终得出的结论是,在 javascript 的帮助下,我们将能够在 Microsoft IE 以外的互联网浏览器中通过网络演示矢量图形(支持 ocx…...

代码管理工具git1
ctrl 加滚轮 放大字体 在计算机任意位置单击右键,选择::Git Bash Here git version git清屏命令:ctrl L查看用户名和邮箱地址: $ git config user.name$ git config user.email修改用户名和邮箱地址:$ git…...
层次聚类分析
1、python语言 from scipy.cluster import hierarchy # 导入层次聚类算法 import matplotlib.pylab as plt import numpy as np# 生成示例数据 np.random.seed(0) data np.random.random((20,1))# 使用树状图找到最佳聚类数 Z hierarchy.linkage(data,methodweighted,metric…...

Jmeter性能实战之分布式压测
分布式执行原理 1、JMeter分布式测试时,选择其中一台作为调度机(master),其它机器作为执行机(slave)。 2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI࿰…...
学信息系统项目管理师第4版系列08_管理科学基础
1. 科学管理的实质 1.1. 反对凭经验、直觉、主观判断进行管理 1.2. 主张用最好的方法、最少的时间和支出,达到最高的工作效率和最大的效果 2. 资金的时间价值与等值计算 2.1. 资金的时间价值是指不同时间发生的等额资金在价值上的差别 2.2. 把资金存入银行&…...

从2023蓝帽杯0解题heapSpary入门堆喷
关于堆喷 堆喷射(Heap Spraying)是一种计算机安全攻击技术,它旨在在进程的堆中创建多个包含恶意负载的内存块。这种技术允许攻击者避免需要知道负载确切的内存地址,因为通过广泛地“喷射”堆,攻击者可以提高恶意负载被…...

基于SSM的学生宿舍管理系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

jvm 内存模型介绍
一、类加载子系统 1、类加载的过程:装载、链接、初始化,其中,链接又分为验证、准备和解析 装载:加载class文件 验证:确保字节流中包含信息符合当前虚拟机要求 准备:分配内存,设置初始值 解析&a…...

用Jmeter进行压测详解
简介: 1.概述 一款工具,功能往往是很多的,细枝末节的地方也很多,实际的测试工作中,绝大多数场景会用到的也就是一些核心功能,根本不需要我们事无巨细的去掌握工具的所有功能。所以本文将用带价最小的方式讲…...
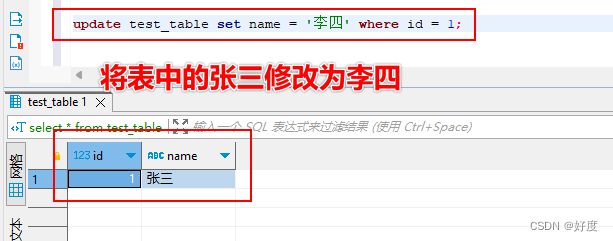
Mysql001:(库和表)操作SQL语句
目录: 》SQL通用规则说明 SQL分类: 》DDL(数据定义:用于操作数据库、表、字段) 》DML(数据编辑:用于对表中的数据进行增删改) 》DQL(数据查询:用于对表中的数…...

甲骨文全区登录地址
日本东部 东京 https://console.ap-tokyo-1.oraclecloud.com https://console.ap-tokyo-1.oraclecloud.com 日本中部 大阪 https://console.ap-osaka-1.oraclecloud.com https://console.ap-osaka-1.oraclecloud.com 韩国中部 首尔 https://console.ap-seoul-1.oraclecloud.c…...

Java面试题第八天
一、Java面试题第八天 1.如何实现对象克隆? 浅克隆 浅克隆就是我们可以通过实现Cloneable接口,重写clone,这种方式就叫浅克隆,浅克隆 引用类型的属性,是指向同一个内存地址,但是如果引用类型的属性也进行浅克隆就是深…...

什么是同步容器和并发容器的实现?
同步容器和并发容器都是用于在多线程环境中管理数据的容器,但它们在实现和用法上有很大的区别。 同步容器: 同步容器是使用传统的同步机制(如synchronized关键字或锁)来保护容器内部数据结构的线程安全容器。同步容器通常是单线…...

会话搜索服务器实战:从架构设计到生产部署的完整指南
1. 项目概述与核心价值最近在折腾一个挺有意思的玩意儿,叫session_search_server。这名字乍一看有点抽象,但如果你做过聊天机器人、客服系统,或者任何需要处理多轮对话、历史记录查询的应用,那你肯定遇到过类似的痛点:…...

告别IDEA编译警告:深入解析JDK版本过时问题与多维度解决方案
1. 当IDEA开始"抱怨":那些烦人的编译警告从哪来? 每次打开老项目,总能看到那个熟悉的黄色警告:"Warning:java: 源值1.5已过时,将在未来所有发行版中删除"。这个提示就像个唠叨的老朋友,…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...

Tabletop Simulator备份神器:3分钟学会永久保存你的桌游资产
Tabletop Simulator备份神器:3分钟学会永久保存你的桌游资产 【免费下载链接】tts-backup Backup Tabletop Simulator saves and assets into comprehensive Zip files. 项目地址: https://gitcode.com/gh_mirrors/tt/tts-backup 还在担心辛苦创建的Tabletop…...

reverse-shell在企业安全测试中的最佳实践:风险评估与合规使用
reverse-shell在企业安全测试中的最佳实践:风险评估与合规使用 【免费下载链接】reverse-shell Reverse Shell as a Service 项目地址: https://gitcode.com/gh_mirrors/re/reverse-shell reverse-shell作为一款开源的"Reverse Shell as a Service"…...

Windows掌机游戏体验终极优化指南:HandheldCompanion完全教程
Windows掌机游戏体验终极优化指南:HandheldCompanion完全教程 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否曾经在Windows掌机上玩游戏时,因为缺乏原生控制器支持…...

Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南
Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 深…...

ArcGIS实战:从DEM数据到精美立体晕渲图的调色与渲染全流程
1. 认识DEM数据与立体晕渲图 第一次接触DEM数据时,我完全被那些密密麻麻的数字搞懵了。后来才发现,这些数字其实就是地形的"指纹"。DEM(Digital Elevation Model)就像是用数字搭建的微缩景观,每个像素点都记…...

还在手动整理ai会议纪要浪费宝贵下班时间?2026年这4款真香AI工具3分钟搞定3小时会议
作为挖了快三年AI效率工具的爱好者,我上周刚被3小时项目复盘会的纪要搞到加班到九点,试了一圈新出的工具,直接给大家上结论:听脑AI是目前同类会议纪要工具里最值得用的,没有之一。 直达链接:https://iting…...

Python实战:三大曲线平滑技术对比与场景选型指南
1. 曲线平滑处理的必要性 当你处理传感器数据、金融时间序列或任何带有噪声的曲线时,原始数据往往像一条暴躁的蚯蚓——上下乱窜让人抓狂。我在处理工业传感器数据时就遇到过这种情况:一条本该平滑的温度曲线,因为电磁干扰变成了"心电图…...