spark withColumn的使用(笔记)
目录
前言:
spark withColumn的语法及使用:
准备源数据演示:
完整实例代码:
前言:
withColumn():是Apache Spark中用于DataFrame操作的函数之一,它的作用是在DataFrame中添加或替换列,或者对现有列进行转换操作和更新等等
spark withColumn的语法及使用:
1. 添加新列(用withColumn为Dataframe)
2. 改变现有列
3. 将现有列派生出新列
4 .更改数据类型(可以在改变该列的同时进行类型转换)
5 .重命名列名(需要使用DataFrame的withColumnRenamed)
6. 删除一个列 (使用drop)
准备源数据进行演示:
import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.sql.functions.{col, lit, rand, round}object text {def main(args: Array[String]): Unit = {//新建sparkval spark = new SparkConf().setMaster("local[*]").setAppName("text")val sc = SparkSession.builder().config(spark).getOrCreate()//准备源数据val tuples = Seq(("小白", 19, "江西"),("小红", 20, "安徽"),("小兰", 21, "河北"))val frame = sc.createDataFrame(tuples).toDF("name","age","address")frame.show()输出结果为:
+------+------+---------+
|name |age |address|
+------+-------+--------+
|小白 | 19 | 江西|
|小红 | 20 | 安徽|
|小兰 | 21 | 河北|
+-------+-------+-------+
1.添加新列
//语法withColumn(colName : String, col : Column) : DataFrame例子:
//1. 用withColumn为dataframe 添加新列 val seq = Seq("小新", 22, "北京") val frame1 : DataFrame= frame.withColumn("new",round(rand()*100,1) ) frame1.show() //打印输出结果为:
+------+-----+-------+---------+
|name|age|address| new|
+------+------+-------+-------+
|小白 | 19 | 江西|27.7 |
|小红 | 20 | 安徽|98.2 |
|小兰 | 21 | 河北|51.0 |
+------+------+-------+-------+
2. 改变现有列
//2. 改变现有列 val frame2: DataFrame = frame.withColumn("age", col("age") - 5)frame2.show() // 打印输出结果为:
+------+------+-------+
|name|age|address|
+-------+------+------+
|小白 | 14| 江西|
|小红 | 15| 安徽|
|小兰 | 16| 河北|
+------+------+-------+
3.将现有列派生出新列
//3.将现有列派生出新列 val frame3 : DataFrame= frame.withColumn("newCol", col("age")*10)frame3.show()输出结果为:
+------+--------+--------+--------+
|name|age|address|newCol|
+-------+-------+--------+--------+
|小白 | 19 | 江西| 190|
|小红 | 20 | 安徽| 200|
|小兰 | 21 | 河北| 210|
+--------+------+-------+-------+
4.更改数据类型(可以在改变该列的同时进行类型转换)
//4.更改数据类型(可以在改变该列的同时进行类型转换) val frame4 : DataFrame = frame.withColumn("age", col("age").cast("float"))frame4.show输出结果为:
+-------+-------+-------+
|name | age | address|
+-------+-------+-------+
|小白 |19.0 | 江西|
|小红 |20.0 | 安徽|
|小兰 |21.0 | 河北|
+-------+-------+-------+
5.重命名列名(需要使用DataFrame的withColumnRenamed)
// 5.重命名列名(需要使用DataFrame的withColumnRenamed)val frame5: DataFrame = frame.withColumnRenamed("address", "省份")frame5.show()输出结果为:
+------+------+------+
|name|age|省份|
+------+------+----+
|小白 | 19 |江西|
|小红 | 20 |安徽|
|小兰 | 21 |河北|
+------+-----+------+
6. 删除一个列 (使用drop)
// 6. 删除一个列 (使用drop)val frame6: DataFrame = frame.drop("age")frame6.show输出结果为:
|name|address|
+-------+-------+
|小白 | 江西|
|小红 | 安徽|
|小兰 | 河北|
+-------+-------+
完整实例代码:
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions.{col, lit, rand, round}object text {def main(args: Array[String]): Unit = {//新建sparkval spark = new SparkConf().setMaster("local[*]").setAppName("text")val sc = SparkSession.builder().config(spark).getOrCreate()//准备源数据val tuples = Seq(("小白", 19, "江西"),("小红", 20, "安徽"),("小兰", 21, "河北"))val frame = sc.createDataFrame(tuples).toDF("name","age","address")frame.show()//1. 用withColumn为dataframe 添加新列val seq = Seq("小新", 22, "北京")val frame1 : DataFrame= frame.withColumn("new",round(rand()*100,1) )frame1.show()//2. 改变现有列
val frame2: DataFrame = frame.withColumn("age", col("age") - 5)frame2.show() // 打印//3.将现有列派生出新列var a = "省"
val frame3 : DataFrame= frame.withColumn("newCol", col("age")*10)frame3.show()//4.更改数据类型(可以在改变该列的同时进行类型转换)
val frame4 : DataFrame = frame.withColumn("age", col("age").cast("float"))frame4.show// 5.重命名列名(需要使用DataFrame的withColumnRenamed)val frame5: DataFrame = frame.withColumnRenamed("address", "省份")frame5.show()// 6. 删除一个列 (使用drop)val frame6: DataFrame = frame.drop("age")frame6.show()}
}
相关文章:
)
spark withColumn的使用(笔记)
目录 前言: spark withColumn的语法及使用: 准备源数据演示: 完整实例代码: 前言: withColumn():是Apache Spark中用于DataFrame操作的函数之一,它的作用是在DataFrame中添加或替换列ÿ…...
PTA:7-1 线性表的合并
线性表的合并 题目输入样例输出样例 代码解析 题目 输入样例 4 7 5 3 11 3 2 6 3输出样例 7 5 3 11 2 6 代码 #include<iostream> #include<vector> using namespace std;bool checkrep(const vector<int>& arr, int x) {for (int element : arr) {i…...

Spring 的创建和日志框架的整合
目录 一、第一个 Spring 项目 1、配置环境 2、Spring 的 jar 包 Maven 项目导入 jar 包和设置国内源的方法: 3、Spring 的配置文件 4、Spring 的核心 API ApplicationContext 4、程序开发 5、细节分析 (1)名词解释 (2&…...

11-集合和学生管理系统
1.ArrayList 集合和数组的优势对比: 长度可变添加数据的时候不需要考虑索引,默认将数据添加到末尾 1.1 ArrayList类概述 什么是集合 提供一种存储空间可变的存储模型,存储的数据容量可以发生改变 ArrayList集合的特点 长度可以变化…...

C语言进阶指针(3) ——qsort的实现
大家好,我们今天来学习回调函数qsort的实现。 首先让我们打开cplusplus.com找到qsort函数。 我们看到这个函数就可以看到它的头文件和参数信息。 #include<stdlib.h> void qsort (void* base, size_t num, size_t size, int (*compar)(const void*,const voi…...

Rust源码分析——Rc 和 Weak 源码详解
Rc 和 Weak 源码详解 一个值需要被多个所有者拥有 rust中所有权机制在图这种数据结构中,一个节点可能被多个其它节点所指向。那么如何表示图这种数据结构?在多线程中,多个线程可能会持有同一个数据?如何解决这个问题。 Rc rus…...
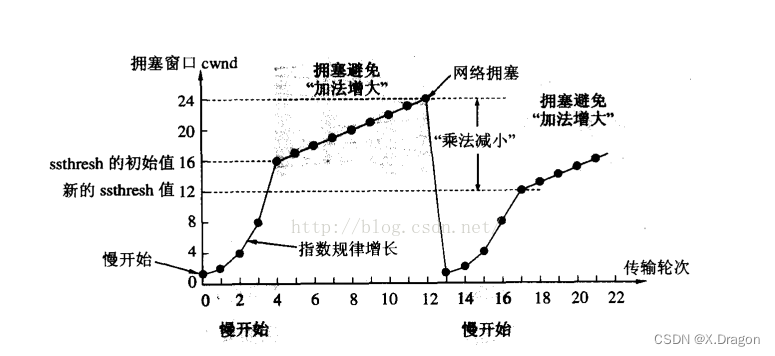
【网络编程】深入理解TCP协议二(连接管理机制、WAIT_TIME、滑动窗口、流量控制、拥塞控制)
TCP协议 1.连接管理机制2.再谈WAIT_TIME状态2.1理解WAIT_TIME状态2.2解决TIME_WAIT状态引起的bind失败的方法2.3监听套接字listen第二个参数介绍 3.滑动窗口3.1介绍3.2丢包情况分析 4.流量控制5.拥塞控制5.1介绍5.2慢启动 6.捎带应答、延时应答 1.连接管理机制 正常情况下&…...

社区团购商城小程序v18.1开源独立版+前端
新增后台清理缓存功能 修复定位权限 修复无法删除手机端管理员 11月新登录接口修复! 修复商家付款到零钱, 修复会员登陆不显示头像, 修复无法修改会员开添加绑定...
MATLAB入门-字符串操作
MATLAB入门-字符串操作 注:本篇文章是学习笔记,课程链接是:link MATLAB中的字符串特性: 无论是字符还是字符串,都要使用单引号来‘’表示;在MATLAB中,字符都是在矩阵中存储的,无论…...

Kong Learning
一、Kong Kong是由Mashape公司开源的可扩展的Api GateWay项目。它运行在调用Api之前,以插件的扩展方式为Api提供了管理。比如,鉴权、限流、监控、健康检查等,Kong是基于lua语言、nginx以及openResty开发的,所有拥有动态路由、负载…...

Python怎样写桌面程序
要编写Python桌面应用程序,可以使用以下几种方法: 1.使用Tkinter模块:Tkinter是Python自带的GUI工具包之一,可以使用它来创建基本的GUI界面。例如,可以创建一个简单的窗口,添加按钮、文本框等控件…...

蓝桥杯2023年第十四届省赛真题-平方差--题解
蓝桥杯2023年第十四届省赛真题-平方差 时间限制: 3s 内存限制: 320MB 提交: 2379 解决: 469 题目描述 给定 L, R,问 L ≤ x ≤ R 中有多少个数 x 满足存在整数 y,z 使得 x y2 − z2。 输入格式 输入一行包含两个整数 L, R,用一个空格分隔。 输出格…...

iText实战--根据绝对位置添加内容
3.1 direct content 概念简介 pdf内容的4个层级 层级1:在text和graphics底下,PdfWriter.getDirectContentUnder() 层级2:graphics层,Chunk, Images背景,PdfPCell的边界等 层级3:text层,Chun…...
使用navicat for mongodb连接mongodb
使用navicat for mongodb连接mongodb 安装navicat for mongodb连接mongodb 安装navicat for mongodb 上文mongodb7.0安装全过程详解我们说过,在安装的时候并没有勾选install mongodb compass 我们使用navicat去进行可视化的数据库管理 navicat for mongodb下载地址…...
Qt ffmpeg音视频转换工具
Qt ffmpeg音视频转换工具,QProcess方式调用ffmpeg,对音视频文件进行格式转换,支持常见的音视频格式,主要在于QProcess的输出处理以及转换的文件名和后缀的处理,可以进一步加上音视频剪切合并和音视频文件属性查询修改的…...

机器学习笔记 - 视频分析和人类活动识别技术路线简述
一、理解人类活动识别 首先了解什么是人类活动识别,简而言之,是对某人正在执行的活动/动作进行分类或预测的任务称为活动识别。 我们可能会有一个问题:这与普通的分类任务有什么不同?这里的问题是,在人类活动识别中,您实际上需要一系列数据点来预测正确执行的动作。 看看…...
)
Redis从入门到精通(三:常用指令)
前边我们介绍了redis存储的四种基本数据类型,并纵向介绍了这四种数据类型的各种指令操作,现在我们这个章节从横向来总结一下关于key的常用指令和数据库常用指令 key常用指令 删除指定key del key 获取key是否存在 exists key 获取key的类型 type …...

代码随想录day39 || 动态规划 || 不同路径
62.不同路径 ● 力扣题目链接 ● 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 ● 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 ● 问总共有…...

电商平台API接口采集电商平台淘宝天猫京东拼多多数据获取产品详情信息,销量,价格,sku案例
淘宝SKU详情接口是指,获取指定商品的SKU(Stock Keeping Unit,即库存量单位)的详细信息。SKU是指提供不同的商品参数组合的一个机制,通过不同的SKU来标识商品的不同组合形式,如颜色、尺寸等。SKU详情接口可以…...

The ‘<‘ operator is reserved for future use. 错误解决
The < operator is reserved for future use. 错误解决 在 PowerShell 终端执行 python learnstock.py < ldata.txt 发生错误, The < operator is reserved for future use.解决方法, cmd /c python learnstock.py < ldata.txt完结&#x…...

全球供应链重塑下的半导体与PC板行业:工程师的挑战与韧性构建
1. 从“分裂的联盟”到工程师的十字路口 最近翻看行业旧闻,读到一篇2019年EE Times上Rick Merritt的评论文章,标题叫“State of the Disunion”。文章本身探讨的是当时科技行业在政治与全球化张力下的处境,但最让我印象深刻的,是评…...

VINS-Mono跑EUROC数据集实战:如何解读Rviz可视化结果与评估轨迹精度?
VINS-Mono EUROC数据集实战:Rviz可视化与轨迹精度评估全解析 当你第一次在Rviz中看到VINS-Mono处理EUROC数据集生成的复杂点云和轨迹时,那种既兴奋又困惑的感觉我完全理解。作为一款开源的视觉惯性里程计(VIO)系统,VINS-Mono在无人机、移动机…...

js脚本翻页自用
版本 1:按键停止(推荐)// 按 ESC 键随时停止let count 0;let running true;const stop () > {running false;console.log(⏹️ 已停止,共点击 count 次);};const interval setInterval(() > {if (!running) {clear…...

物联网标准演进与云平台破局:从M2M到IoT的实战路径
1. 从M2M到IoT:一场迟来的标准革命十多年前,当我第一次接触“机器对机器”这个概念时,感觉它就像个被锁在工厂车间里的幽灵——功能强大,但离普通人的生活无比遥远。那时的M2M,谈论的是专用网络、私有协议和封闭的垂直…...

LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读
LLMs之Benchmarks:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》翻译与解读 导读:ProgramBench 把软件工程 agent 的评测从“局部修补”推进到“从零重建程序”,通过程序文档、行为级测试和 agent-driven fuzzing …...

AI赋能区域创新评估:融合记分板与政策文本分析的协同框架与实践
1. 项目概述与核心价值 最近在梳理区域创新政策与人工智能应用交叉领域的工作时,我深度实践了一个项目,核心是探讨如何将欧盟的“区域创新记分板”这套成熟的评估体系,与新兴的AI政策分析工具进行深度融合与协同应用。这听起来可能有些学术化…...

有一种同事,领导再信任也要小心提防
◆你好。 职场上有这么一类人,他们精于伪装,表面上能力出众、忠心耿耿,实则暗地里拉帮结派、打压异己,甚至一步步架空领导。 这种人最可怕的地方在于,他们往往深得领导信任,成为团队里的"红人"。…...

kasetto:用SQL思维操作本地CSV/JSON文件的命令行利器
1. 项目概述:一个被低估的本地化数据管理利器如果你经常需要在本地处理一些结构化的数据,比如从网页上抓取的信息、日常记账的记录、项目进度的跟踪,或者只是想把一些零散的笔记整理成表格,你可能会面临一个选择:是用E…...

3大技术突破重塑抢购体验:JDspyder如何让秒杀从运气变成技术活
3大技术突破重塑抢购体验:JDspyder如何让秒杀从运气变成技术活 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 你是否也曾遇到过这样的场景:盯着手机屏幕…...

学术研究项目中利用taotoken便捷调用多种模型进行实验对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 学术研究项目中利用Taotoken便捷调用多种模型进行实验对比 在算法研究、自然语言处理或人工智能相关领域的学术项目中,…...