深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]
文章目录
- 参考文章及视频
- 导言
- 梯度下降的原理、过程
- 一、什么是梯度下降?
- 二、梯度下降的运行过程
- 批量梯度下降法(BGD)
- 随机梯度下降法(SGD)
- 小批量梯度下降法(MBGD)
- 梯度算法的改进
- 梯度下降算法存在的问题
- 动量法(Momentum)
- 目标
- 改进思想
- 为什么有效
- 动量法还有什么效果?
- 自适应梯度(AdaGrad)
- AdaGrad存在的问题
- AdaGrad算法具有以下特点:
- RMSProp
- ADAM梯度下降法
- 总结
参考文章及视频
耿直哥讲AI:https://www.bilibili.com/video/BV18P4y1j7uH/?spm_id_from=333.337.search-card.all.click&vd_source=f6c19848d8193916be907d5b2e35bce8
计算机视觉与深度学习 北京邮电大学 鲁鹏 清晰版合集(完整版):https://www.bilibili.com/video/BV1V54y1B7K3?p=5&vd_source=f6c19848d8193916be907d5b2e35bce8
导言
梯度下降的原理、过程
一、什么是梯度下降?
梯度下降(Gradient Descent)是一种常用的优化算法,主要用于寻找函数的局部最小值。在机器学习和深度学习中,我们通常使用梯度下降来优化损失函数,从而找到使损失最小的模型参数。
梯度在数学上可以看作是函数在某一点的斜率,或者说是函数在该点变化最快的方向。在多维空间中,梯度是一个向量,指向函数增长最快的方向。而"梯度下降"的思想就是,如果我们想找到函数的最小值,那么从当前位置沿着梯度的负方向,即函数下降最快的方向,进行迭代更新就可能找到这个最小值。
通俗的来讲就是:
- 想象一下你置身于一个大山谷中,你的目标是找到山谷最低处的位置。但是你没有地图,也不能一下子看到整个山谷的形状。所以你只能根据自己当前所处位置的周围情况来判断往哪个方向走。
- 梯度下降法就像是你通过观察地势斜率来下山。你站在某个位置上,然后观察周围的地势斜率。地势斜率的方向指示了最陡下坡的方向,而你的目标是下到山谷的最低点。
- 开始时,你随机选择一个位置作为起点。然后你观察当前位置的地势斜率,并朝着斜率最陡的方向迈出一步。然后,你再次观察新位置的地势斜率,并再次朝着最陡的方向迈出一步。你不断重复这个过程,每次都往下坡最陡的方向前进,直到你无法再下降或者到达了山谷的最低点。
- 通过这种迭代的方式,你能够一步步地接近山谷的最低点,也就是最优解。梯度下降法通过不断地调整位置,最终找到了函数的最小值点(或者最大值点)。
如图所示:

陡峭度=梯度
需要注意的是,梯度下降法中的步长(学习率)很重要。
如果步长太大,你可能会错过最低点;
如果步长太小,你会花费很长的时间才能到达最低点。
所以选择一个合适的步长是梯度下降法的一个关键因素。
二、梯度下降的运行过程
梯度下降的过程很直观,可以分为以下几个步骤:
- 初始化参数:给定一个初始点。
- 计算梯度:在当前点,计算函数的梯度,即各个参数的偏导数。
- 更新参数:按照以下公式更新参数:θ = θ - α * ∇f(θ)。其中,θ代表当前的参数,α是学习率(决定了步长的大小),∇f(θ)是函数在θ处的梯度。
- 迭代更新:重复步骤2和步骤3,直到梯度接近0,或者达到预设的迭代次数。
这个过程会持续进行,直到找到一个足够好的解,或者达到预设的迭代次
批量梯度下降法(BGD)
批量梯度下降(Batch Gradient Descent)是梯度下降算法的一种变体,用于优化机器学习模型的参数。与其他梯度下降算法相比,批量梯度下降在每次迭代中使用整个训练数据集来计算梯度和更新参数。
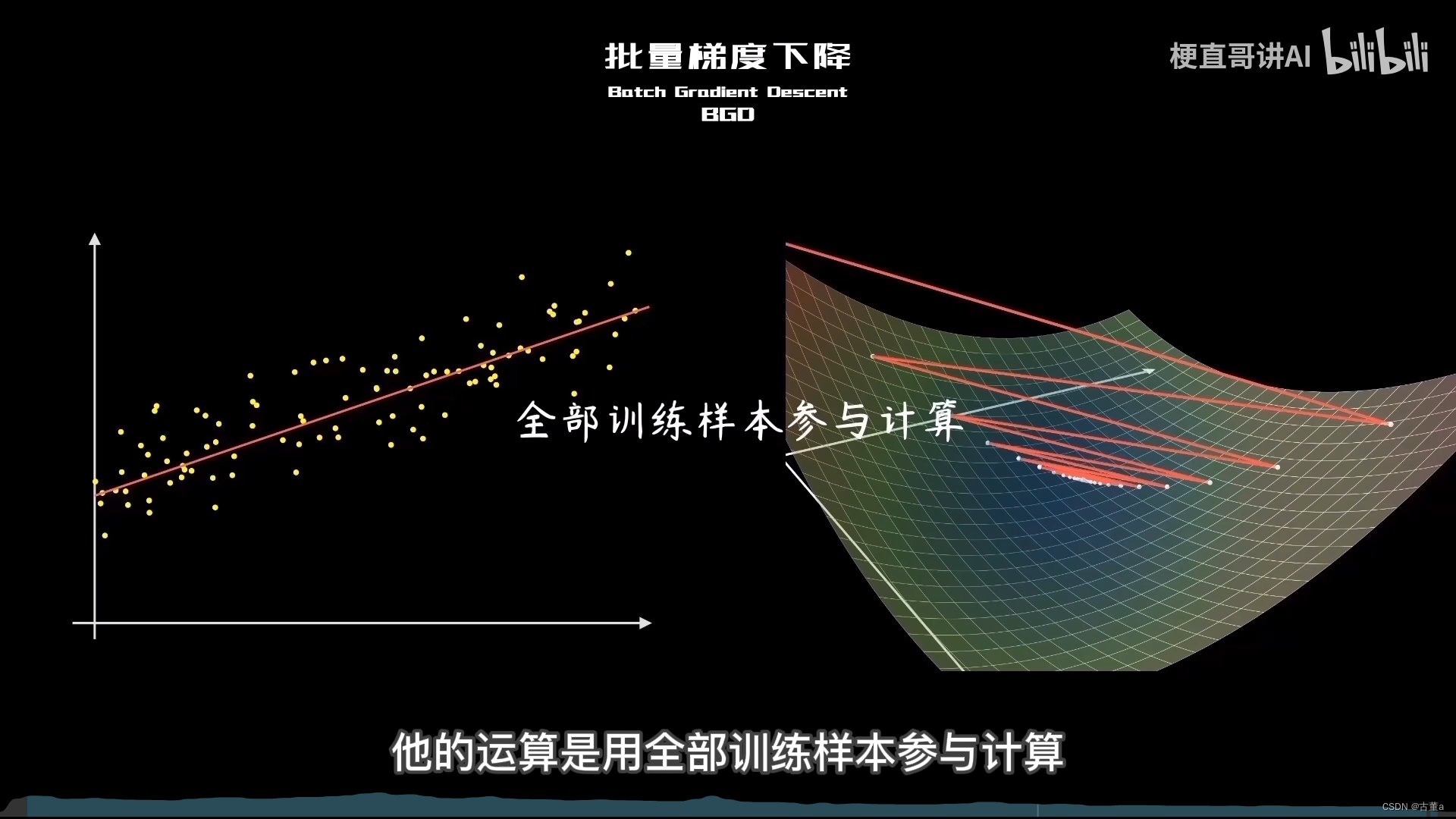
批量梯度下降通常用于小型数据集或参数空间较小的模型。
- 它的优点是能够更准确地收敛到全局最优解(如果存在),并且在参数更新方向上相对稳定。
- 然而,由于每次迭代时都要使用整个数据集,因此它的计算成本较高。尤其是在大规模数据集上。
随机梯度下降法(SGD)
随机梯度下降(Stochastic Gradient Descent,SGD)是一种梯度下降算法的变体,用于优化机器学习模型的参数。与批量梯度下降不同,随机梯度下降在每次迭代中仅使用一个样本来计算梯度和更新参数。
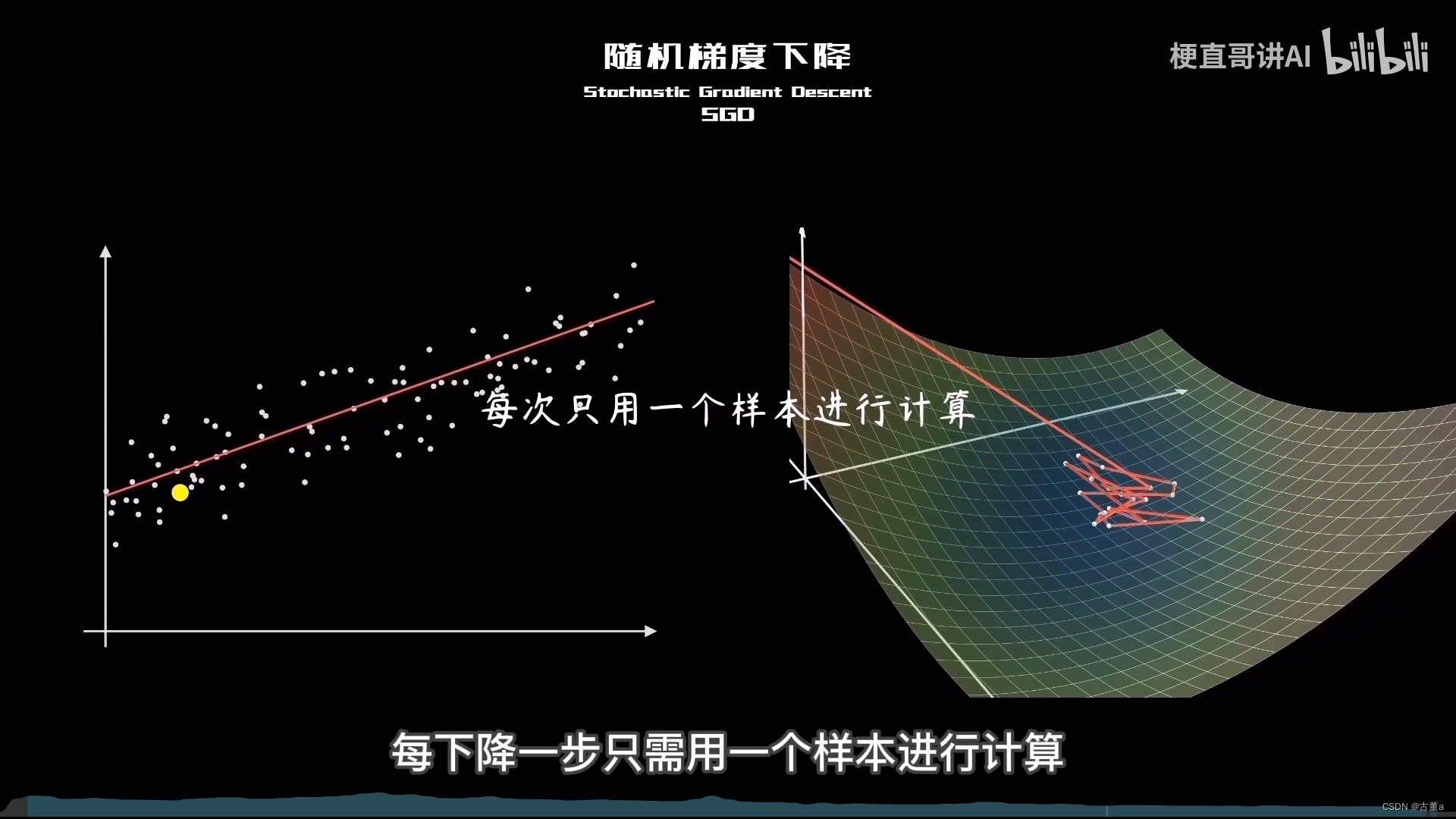
随机梯度下降是一种每次迭代仅使用一个样本来计算梯度并更新参数的梯度下降算法。
- 它的优点是计算代价较低,适用于大规模数据集,这一特性有助于算法逃离局部最小值,并具有一定的探索性。
- 然而,由于梯度估计存在噪音,参数更新可能不稳定。
小批量梯度下降法(MBGD)
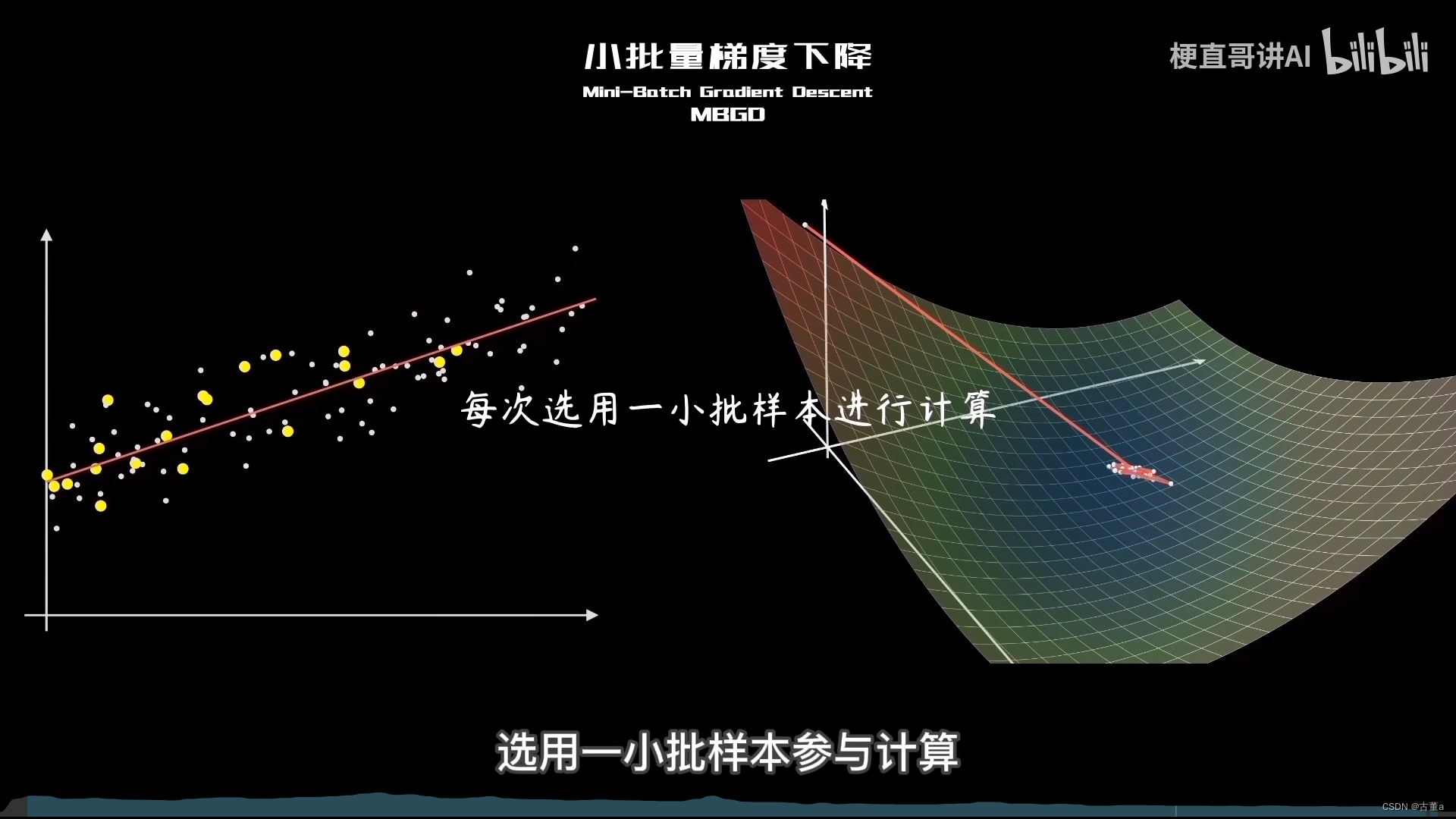
小批量梯度下降(Mini-Batch Gradient Descent)是梯度下降算法的一种变体,介于批量梯度下降(Batch Gradient Descent)和随机梯度下降(Stochastic Gradient Descent)之间。
它在每次迭代中使用一小批次(mini-batch)的样本来计算梯度和更新参数。
梯度算法的改进
梯度下降算法存在的问题
损失函数特性:一个方向上变化迅速而在另一个方向上变化缓慢。
优化目标:从起点处走到底端笑脸处。
梯度下降算法存在的问题:山壁间振荡,往谷底方向的行进较慢。
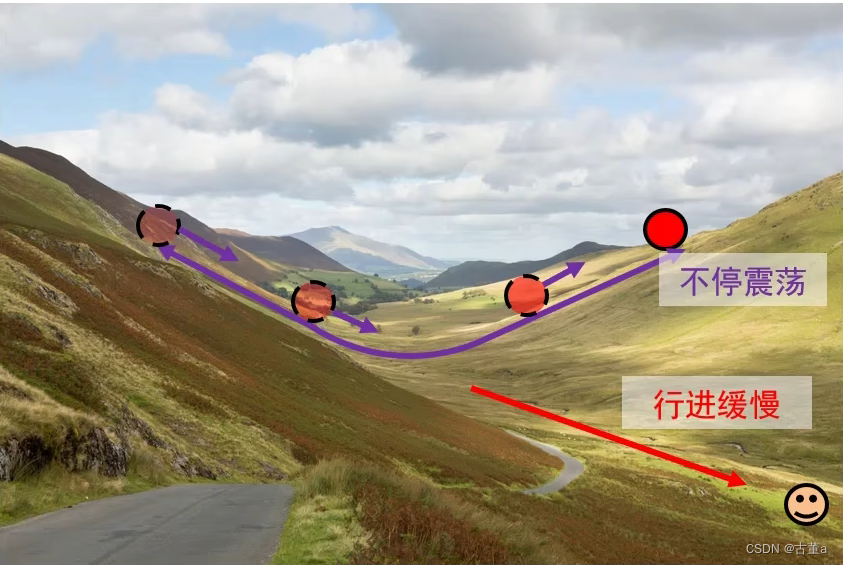
仅增大步长并不能加快算法收敛速度:相当于在振荡方向加了一个更大的速度,往山谷方向也加了,但是很小。
动量法(Momentum)
动量法梯度(Momentum Gradient Descent)下降通过引入动量变量,可以在更新过程中积累之前的梯度信息,并根据历史梯度的趋势来调整参数更新的方向和幅度。这样可以使参数更新在梯度方向上更加稳定,并且可以加速学习过程,尤其在目标函数存在大体量或弯曲的情况下。
目标
改进梯度下降算法存在的问题,即减少震荡,加速通往谷底
改进思想
利用累加历史梯度信息更新梯度

μ取值范围[0,1)
- 当动量系数μ等于0时,动量法梯度下降变为普通的梯度下降算法。在这种情况下,动量变量v的更新公式简化为:
v = 0 * v + g = g
也就是说,动量变量v只受当前梯度的影响,而不考虑历史梯度信息。参数更新时,只使用当前梯度乘以学习率进行更新。这样的更新方式使得参数更新的方向和幅度完全依赖于当前的梯度值。 - 当动量系数μ等于1时,动量法梯度下降完全依赖于历史梯度信息。动量变量v的更新公式为:
v = 1 * v + g = v + g
动量变量v实际上就是历史梯度的累积,因为历史梯度乘以1之后仍然是历史梯度本身。在参数更新时,只使用动量变量v进行更新,而不再考虑当前梯度的贡献。 即使g走到平坦局域了为0 了,可是v不为0,则权值θ还在持续更新。
建议取0.9,可以将其理解为摩擦系数 v = 0.9v 多次迭代后,v会接近于0
为什么有效
累加过程中震荡方向相互抵消,平坦方向得到加强
动量法还有什么效果?
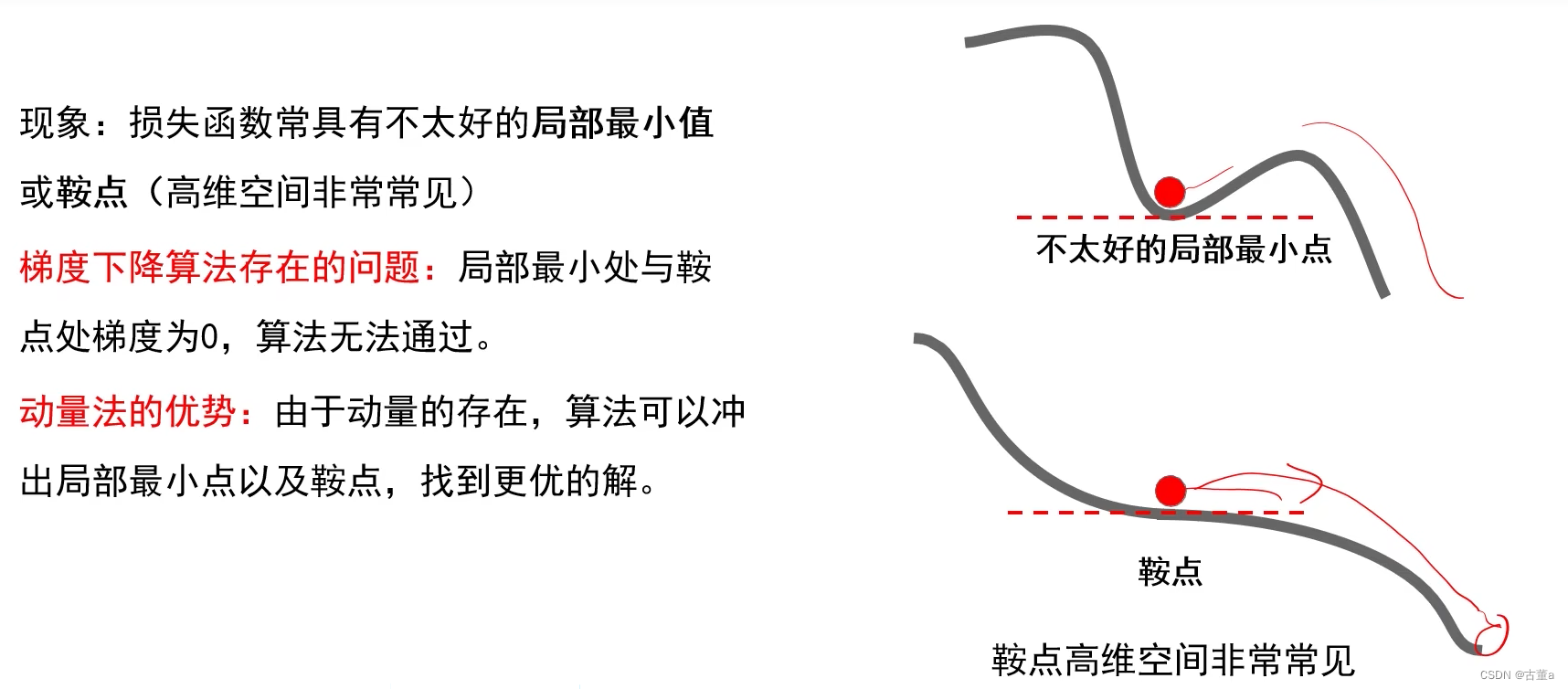
它在参数更新中引入了动量概念,以加速学习过程并帮助跳出局部最优解和鞍点。
自适应梯度(AdaGrad)
AdaGrad(Adaptive Gradient Algorithm)是一种自适应梯度算法,用于在机器学习中优化模型的参数。它根据参数的梯度历史信息自适应地调整学习率,使得在训练过程中较大的梯度得到较小的学习率,而较小的梯度得到较大的学习率。
AdaGrad算法的核心思想是为每个参数维护一个梯度的累积平方和,并在参数更新时将学习率除以这个累积平方和的平方根。

如何区分震荡方式与平坦方向?
梯度幅度的平方较大的方向是震荡方向;
梯度幅度的平方较小的方向是平坦方向。

震荡方向和平坦方向的梯度的平方和不断累加
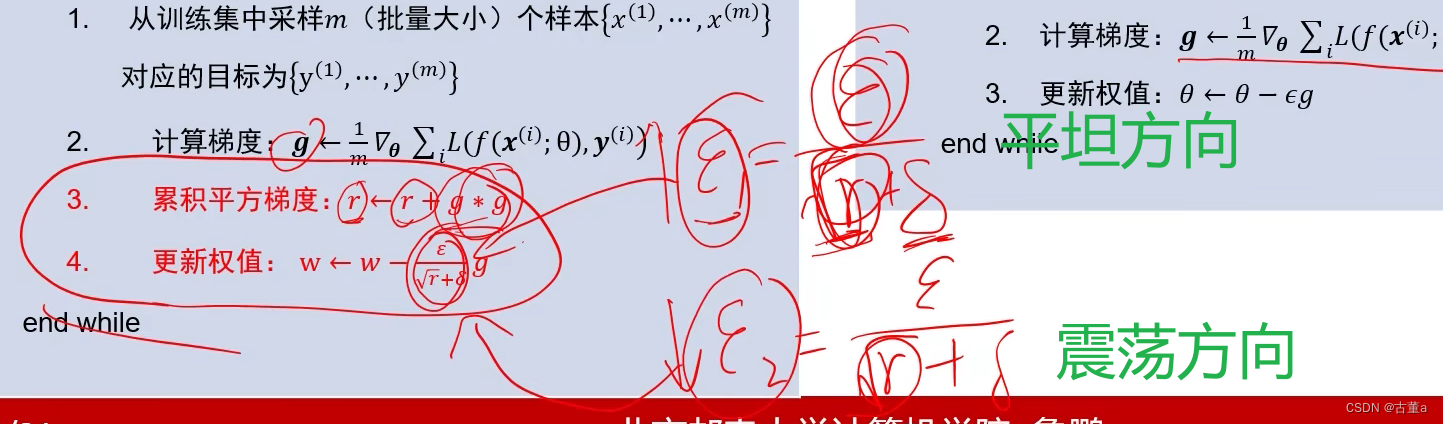
因为震荡方向的梯度大,因此累加平方梯度r不断变大,所以ε1不断减小
因为平坦方向的梯度小,因此累加平方梯度r不断变肖,所以ε2不断增大
AdaGrad存在的问题
由于累加平方梯度r在不断的变大,在多次迭代后,r会变得非常大,则ε1和ε2都会变成一个非常小的值。失去调节作用。
AdaGrad算法具有以下特点:
-
自适应学习率:AdaGrad算法根据参数的梯度历史信息自适应地调整学习率。当某个参数的梯度较大时,其累积平方和较大,学习率较小;当梯度较小时,累积平方和较小,学习率较大。这样可以保证在训练早期参数更新幅度较大,而在训练后期逐渐减小。
-
处理稀疏梯度:AdaGrad算法在处理稀疏数据集时表现良好。由于累积平方和的累加,较少出现的参数梯度将获得更大的学习率,从而更快地进行参数更新。
-
累积平方和的增长:AdaGrad算法累积了梯度的平方和,随着训练的进行,累积平方和会逐渐增大。这可能导致学习率过度下降,使得训练过程变得缓慢。为了解决这个问题,后续的优化算法如RMSprop和Adam引入了衰减系数,对累积平方和进行平滑衰减。
RMSProp
RMSprop(Root Mean Square Propagation)是一种自适应梯度算法,用于在机器学习中优化模型的参数。它是对AdaGrad算法的改进,主要解决AdaGrad算法累积平方梯度过度增大的问题。
RMSprop算法的核心思想是为每个参数维护一个梯度平方的移动平均,并在参数更新时使用这个移动平均来调整学习率。
算法思路:

当ρ等于0:不考虑历史梯度 ,r = 0 * r + (1 - 0)g * g = g * g 仅依靠当前的的梯度
- 就把梯度大的降低一些,梯度小的增大一些
当ρ等于1:即所有的历史梯度都考虑进来,r = 1 * r + (1 - 1) g * g = r
- 权值一直不会变了
建议取0.999, v = 0.999v + 0.001 * g * g 多次迭代后,v会不断减小
ADAM梯度下降法
Adam(Adaptive Moment Estimation)是一种自适应梯度算法,结合了动量法和RMSprop算法的优点,用于在机器学习中优化模型的参数。它在训练过程中自适应地调整学习率
算法思路:

修正偏差为什么可以缓解冷启动?
在进行第1次更新的时候:
v初始值为0,μ初始值为0.9
v ( 1 ) = 0 + 0.1 g v^{(1)} = 0 + 0.1 g v(1)=0+0.1g
则通过修正偏差
v ^ 1 = 0.1 g / 1 − ( 0.9 ) 1 = g \hat{v}^1 = 0.1 g / 1 - (0.9)^1= g v^1=0.1g/1−(0.9)1=g
解决了开始的梯度被减少10倍的问题
在进行第10次更新的时候:
修正偏差项就不起作用了
v ^ 10 = v 9 g / 1 − ( 0.9 ) 10 = v \hat{v}^{10} = v^9 g / 1 - (0.9)^{10} = v v^10=v9g/1−(0.9)10=v
所以修正项仅在初期为了解决冷启动的时候起作用,来防止初期r = v = 0,更新特别慢的问题
总结
分享一个动态查看各种梯度梯度算法下降过程的图的网站https://www.ruder.io/optimizing-gradient-descent/
这个博主写的更多更详细:https://blog.csdn.net/oppo62258801/article/details/103175179?ydreferer=aHR0cHM6Ly93d3cuYmluZy5jb20v

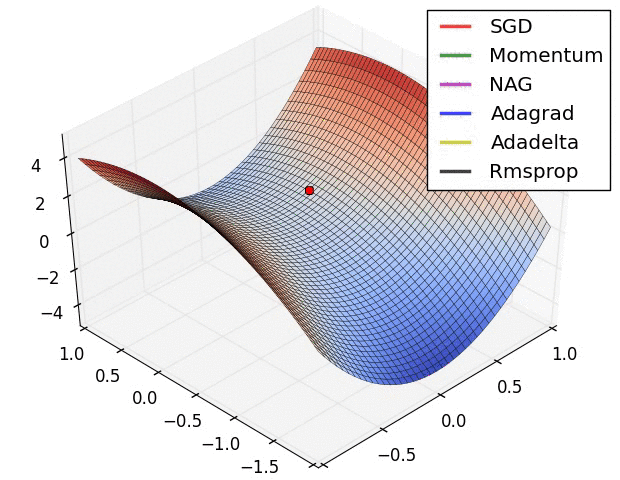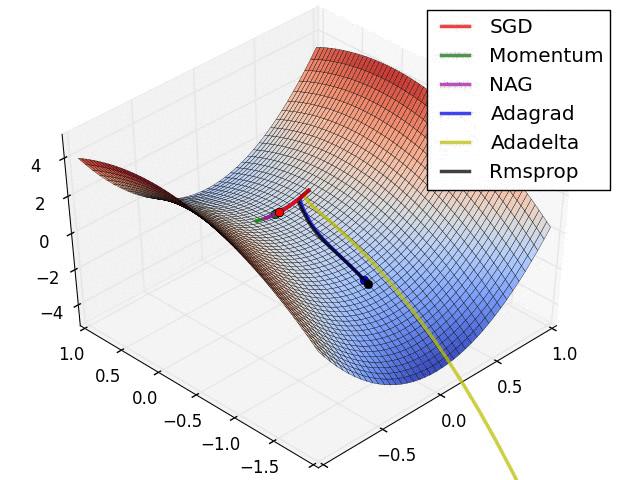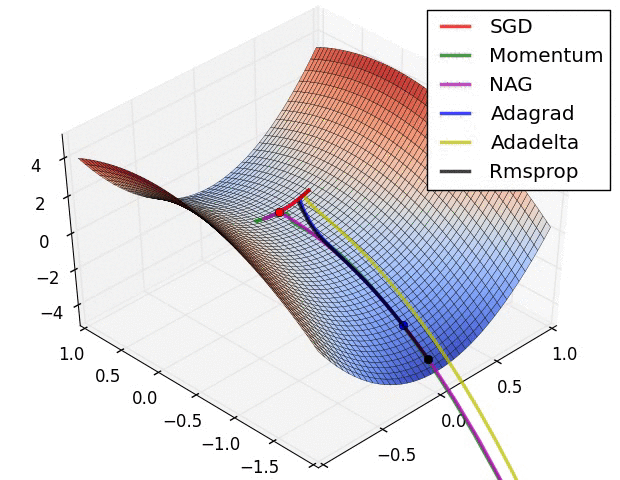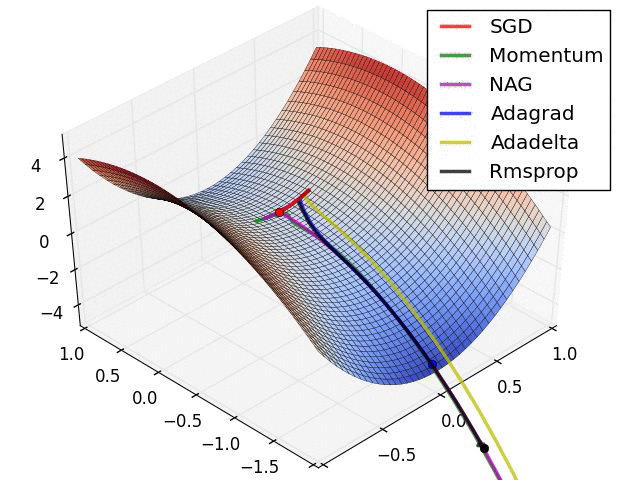
同时可以学习一下算法的实现:https://zhuanlan.zhihu.com/p/77380412
相关文章:
深度学习-全连接神经网络-详解梯度下降从BGD到ADAM - [北邮鲁鹏]
文章目录 参考文章及视频导言梯度下降的原理、过程一、什么是梯度下降?二、梯度下降的运行过程 批量梯度下降法(BGD)随机梯度下降法(SGD)小批量梯度下降法(MBGD)梯度算法的改进梯度下降算法存在的问题动量法(Momentum)目标改进思想为什么有效动量法还有什么效果&…...
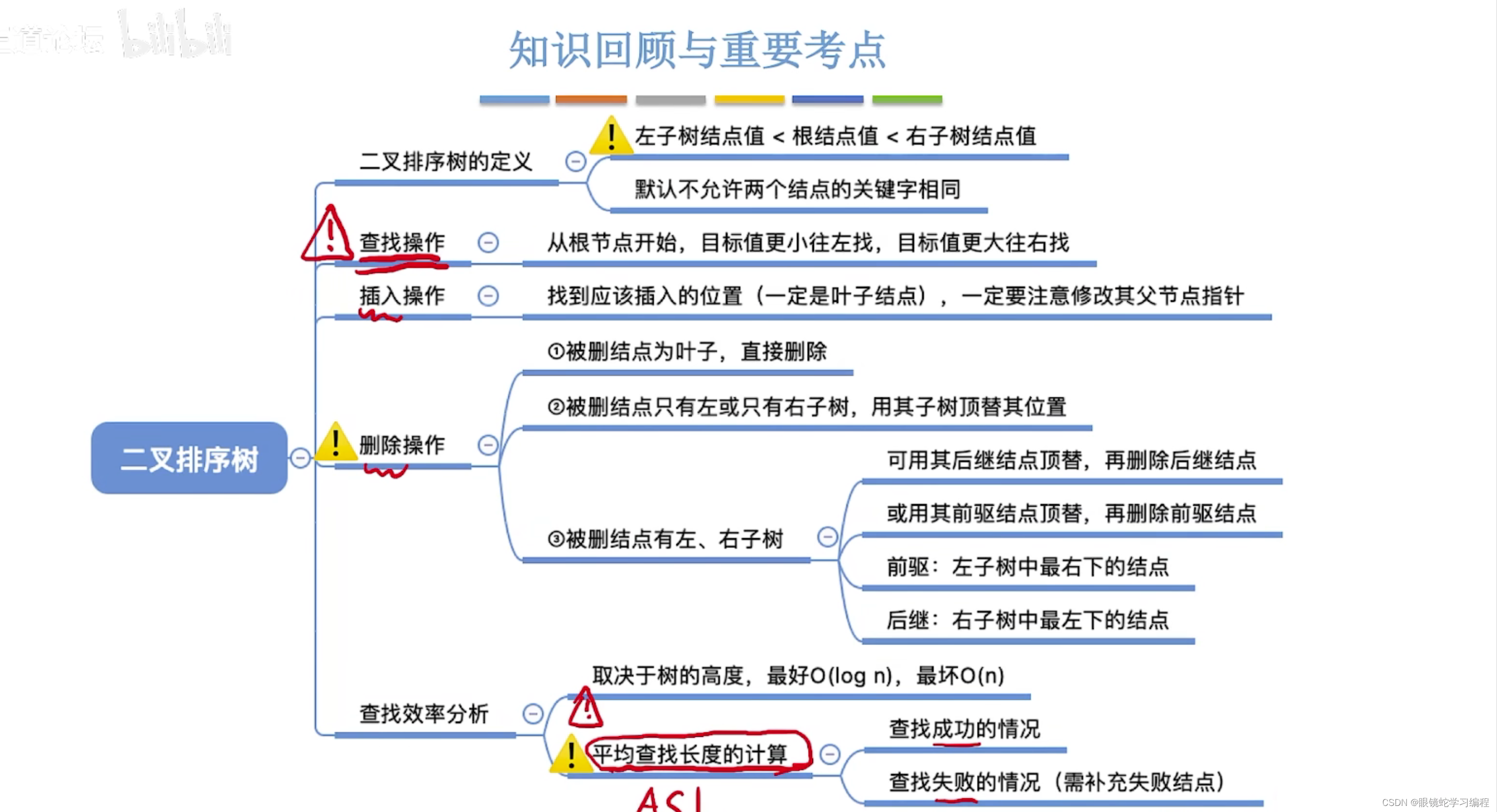
数据结构--二叉排序树
目录 二叉排序树的定义 二叉排序树的查找 二叉排序树的插入 二叉排序树的构造 二叉排序树的删除 查找效率分析 回顾 二叉排序树的定义 二叉排序树的查找 查找成功的情况 查找失败的情况 二叉排序树的插入 注意 (1)二叉排序树不允许出现重复的值…...

Python | 根据子列表中的第二个元素对列表进行排序
在本文中,我们将学习如何根据主列表中存在的子列表的第二个元素对任何列表进行排序。 比如 Input : [[‘rishav’, 10], [‘akash’, 5], [‘ram’, 20], [‘gaurav’, 15]] Output : [[‘akash’, 5], [‘rishav’, 10], [‘gaurav’, 15], [‘ram’, 20]] Input …...

qsort函数详细讲解以及利用冒泡排序模拟实现qsort函数
个人主页:点我进入主页 专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶 C语言刷题 欢迎大家点赞,评论,收藏。 一起努力,一起奔赴大厂。 目录 1.qsort函数 1.1qsort函数的参数 …...

C++QT day6
1> 将之前定义的栈类和队列类都实现成模板类 栈: #include <iostream> #define MAX 128 using namespace std; template<typename T> class Stack_s { private:T *pnew T[MAX];//栈的数组int top;//记录栈顶的变量 public://构造函数Stack_s(int t…...
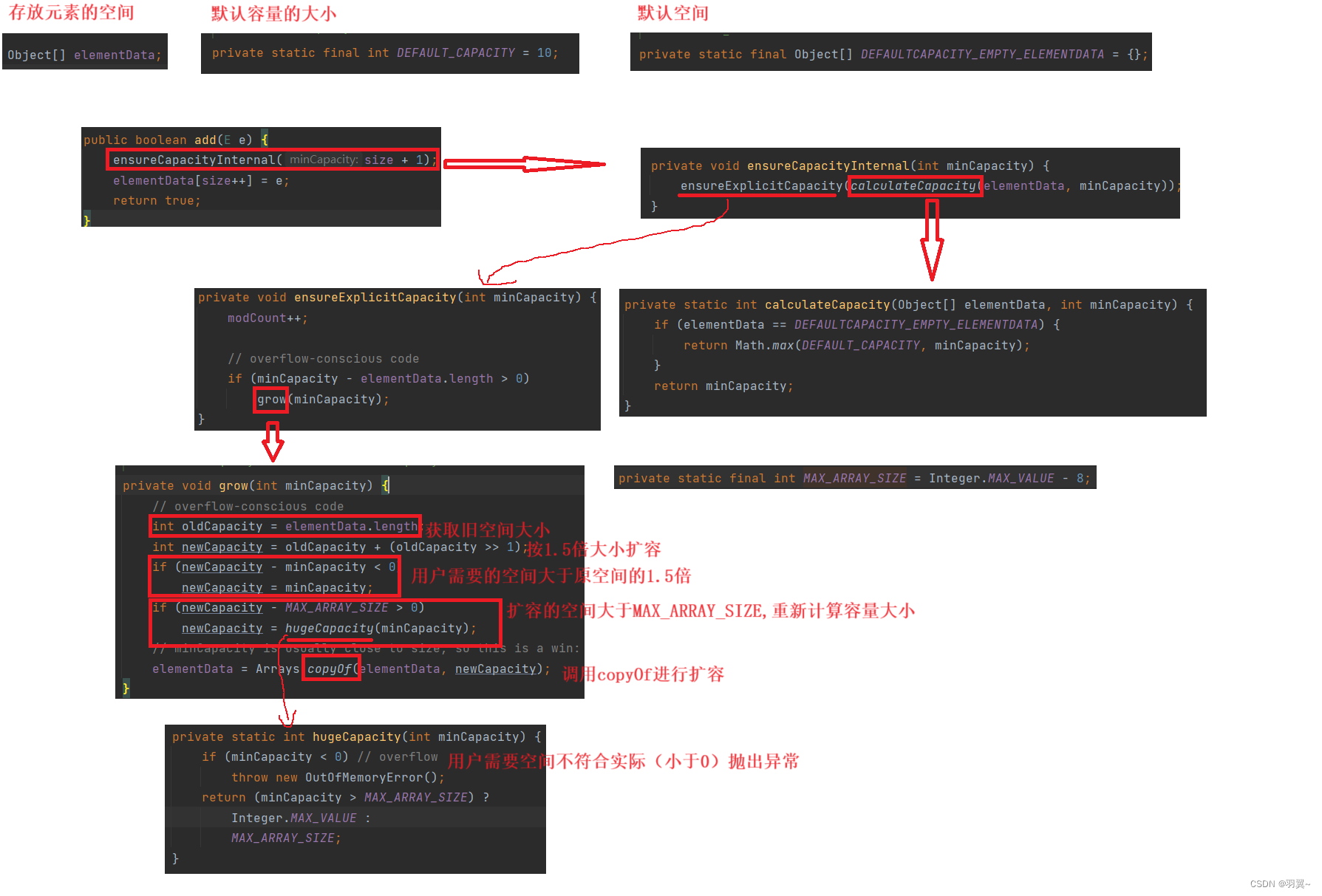
List与ArrayList
目录 一、List及其使用 1.1 List的概念 1.2 常见接口的介绍 1.3 List的使用 二、线性表和顺序表 2.1 线性表 2.2 顺序表 三、ArrayList介绍 四、ArrayList的使用 4.1 ArrayList构造 4.2 ArrayList的常用方法 4.3 ArrayList的遍历 4.4 ArrayList的扩容机制 五、ArrayList的具…...
【C++】特殊类的设计
文章目录 1. 设计一个类, 不能被拷贝2. 设计一个类, 不能被继承3. 设计一个类, 只能在堆上创建对象3. 设计一个类, 只能在栈上创建对象4. 创建一个类, 只能创建一个对象(单例模式)饿汉模式懒汉模式 1. 设计一个类, 不能被拷贝 💕 C98方式: 在C11之前&a…...
机器学习:PCA(Principal Component Analysis主成分)降维
参考:PCA降维原理 操作步骤与优缺点_TranSad的博客-CSDN博客 PCA降维算法_偶尔努力翻身的咸鱼的博客-CSDN博客 需要提前了解的数学知识: 一、PCA的主要思想 PCA,即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想…...

linux服务器slab缓存回收方案设计
背景 自己写的回收slab内存ko,insmod报错“shrink_slab:unknown symbol _x86_indirect_thunk_rax(err 0)””; 分析 1.名词解释 在 x86 架构中,函数调用通常使用 call 指令来直接跳转到目标函数的地址。但是,当需要通过函数指针或动态链接调用函数时,就需要使用__x86_…...

Apache Spark 的基本概念
Apache Spark 是一种快速、可扩展、通用的数据处理引擎。它是一种基于内存的计算框架,支持分布式数据处理、机器学习、图形计算等多种计算任务。与传统的 Hadoop MapReduce 相比,Spark 具有更高的性能和更广泛的应用场景。 Spark 中的基本概念包括&…...
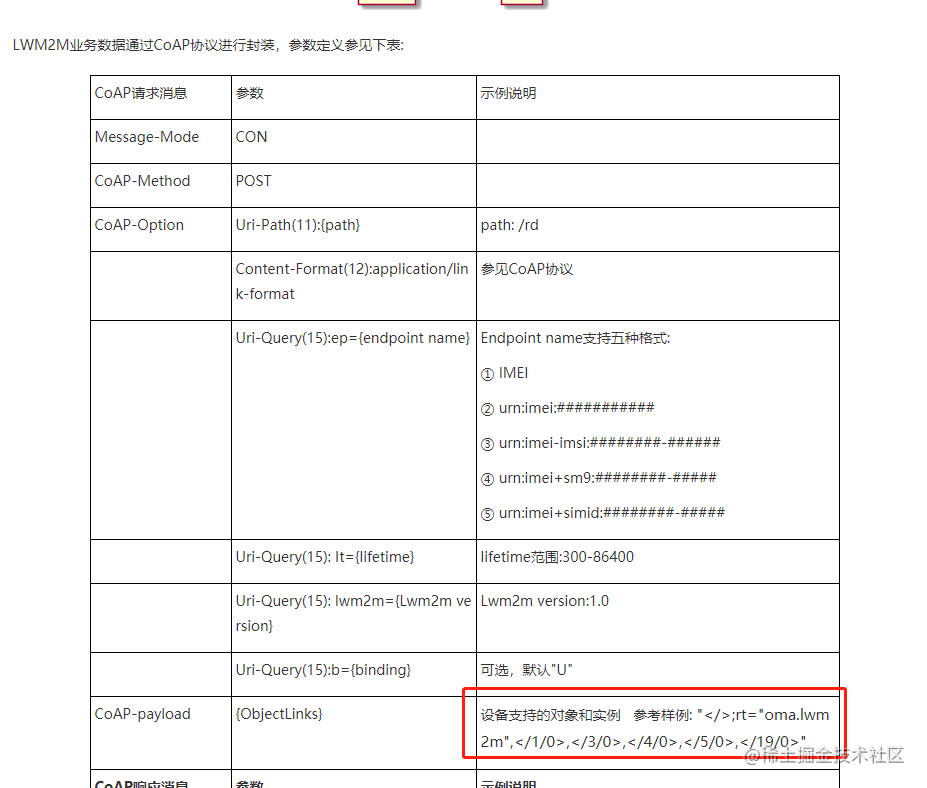
通讯协议介绍CoAP 协议解析
目录 1 通讯协议 2 TCP/IP 网络模型 2.1 TCP协议 2.1.1 TCP 连接过程 2.1.2 TCP 断开连接 2.1.3 TCP协议特点 2.2 UDP协议 2.2.1 UDP 协议特点 3 应用层协议简介 3.1 HTTP 协议 3.2 CoAP 协议 3.3 MQTT 协议 4 CoAP 协议详解 4.1 REST 风格 4.2 CoAP 首部分析 4…...
React 开发一个移动端项目(2)
配置基础路由 目标:配置登录页面的路由并显示在页面中 步骤: 安装路由: yarn add react-router-dom5.3.0 5 和 6 两个版本对组件类型的兼容性和函数组件支持有所改变,在这里使用的是 5。 和路由的类型声明文件 yarn add types…...

51单片机 点阵矩阵 坤坤代码
真正的黑子 #include <REGX52.H>void Delay(unsigned int xms); void _74HC595_WriteByte(unsigned char byte); void LED(unsigned char Y,DATA); void LED_Init();sbit RCKP3^5; //RCLK sbit SCKP3^6; //SRCL sbit SERP3^4; //SER //坤坤矩阵 unsigned char code D…...

Android13-图片视频选择器
在compileSDK 33 时,谷歌在安卓新增了 图片选择器 功能,支持单选、多选、选图片、视频等操作,并且不需要额外获取照片/音频权限。 具体实现如下: 1:请求 Log.d(TAG, "Build.VERSION.SDK_INT" Build.VERS…...
【问题处理】GIT合并解决冲突后,导致其他人代码遗失的排查
GIT合并解决冲突后,导致其他人代码遗失的排查 项目场景问题描述分析与处理:1. 警告分析2. 文件分析3. 问题关键4. 验证 解决策略总结 📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验ÿ…...
H264视频压缩格式
H264简介 H.264从1999年开始,到2003年形成草案,最后在2007年定稿有待核实。在ITU的标准里称为H.264, 在MPEG的标准里是MPEG-4的一个组成部分-MPEG-4 Part 10,又叫Advanced Video Codec,因此常常称为MPEG-4AVC或直接叫AVC。 压缩算…...

动态的中秋爱心演示送女友用python生成爱心软件文末附c++语言写法
用python生成爱心软件 用python生成动态爱心软件 目录 用python生成爱心软件 完整代码 代码解释 逐句解释 效果展示: 如何打包 c写法 完整代码 import turtledef draw_heart():love turtle.Turtle()love.getscreen().bgcolor("black")love.…...
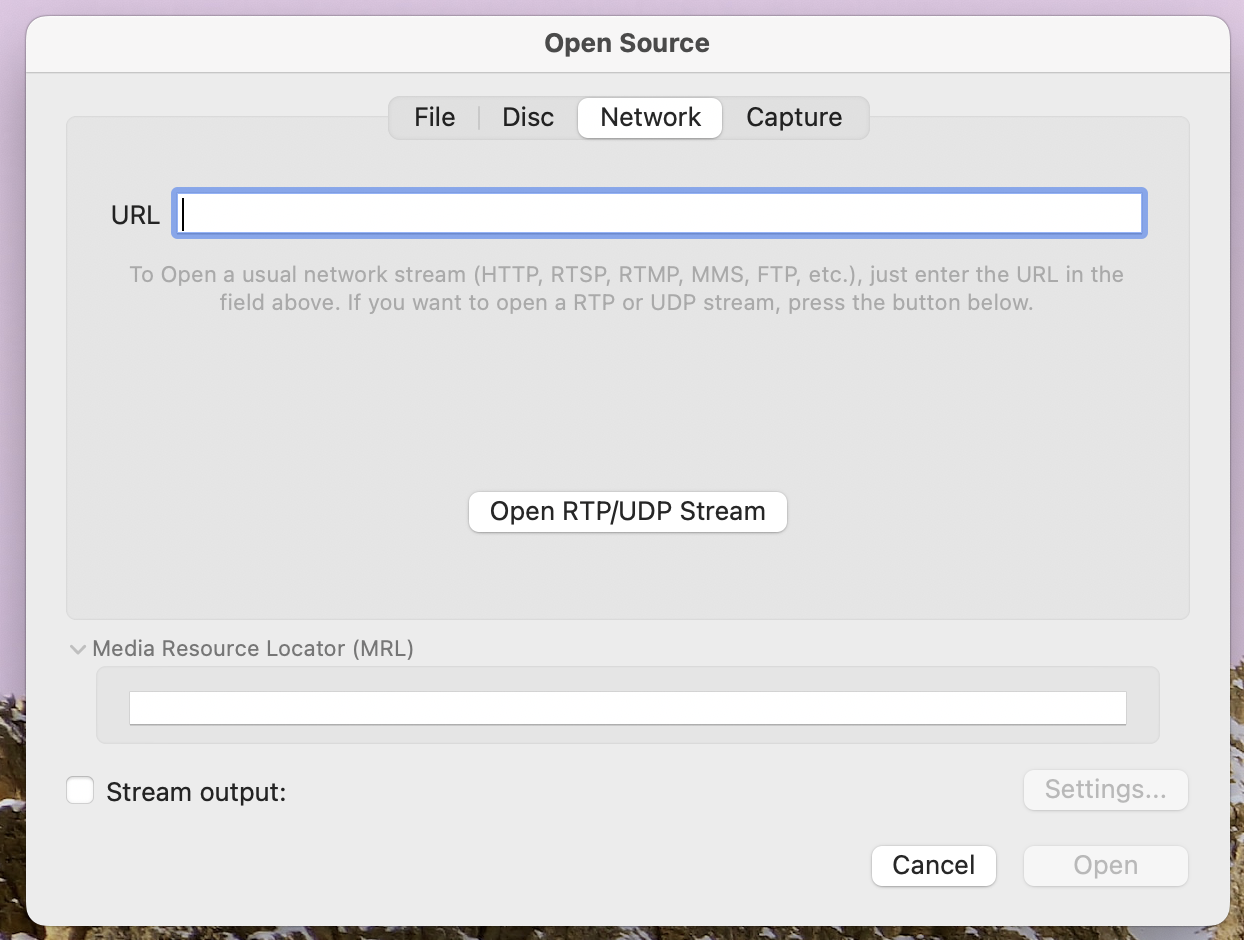
macOS - 使用VLC
文章目录 关于 VLC安装查看帮助流媒体 MRL 语法:URL 语法:主程序 (core)音频视频截图:窗口属性: 子画面屏幕显示(OSD):字幕:覆盖:轨道设置:播放控制:默认设备:高级: 输入播放列表性能选项: 热键跳跃大小: 关于 VLC VLC media player VLC 是一款自由、开…...
java微服务项目整合skywalking链路追踪框架
skywalking官网网址:Apache SkyWalking 目录 1、安装skywalking 2、微服务接入skywalking 3、skywalking数据持久化 1、安装skywalking 下载skywalking,本篇文章使用的skywalking版本是8.5.0 Index of /dist/skywalkinghttps://archive.apache.org/…...

pandas 笔记: interpolate
一个用于填充 NaN 值的工具 1 基本用法 DataFrame.interpolate(methodlinear, *, axis0, limitNone, inplaceFalse, limit_directionNone, limit_areaNone, downcast_NoDefault.no_default, **kwargs) 2 主要参数 method 多种插值技术 linear: 默认值,使用线性插…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

Python PIL 画矩形框
基础代码 from PIL import Image, ImageDraw# 打开图片 img Image.open(your_image.jpg)# 创建绘图对象 draw ImageDraw.Draw(img)# 矩形坐标 (x1, y1, x2, y2) coords (23, 21, 69, 76)# 画矩形框(红色,线宽2) draw.rectangle(coords, ou…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

第5章 薪资重构——AI时代的程序员价值重估
第5章 薪资重构——AI时代的程序员价值重估 核心问题:AI时代,程序员的薪资会发生怎样的变化?哪些人在涨薪?哪些人在降薪? 5.1 问题定义:薪资分化的真相是什么? 5.1.1 一个令人震惊的数据 2026年第一季度,一个对比让整个技术圈哗然: 同一家公司内部: - 一个AI方向…...

城通网盘直链解析终极指南:3分钟告别广告等待
城通网盘直链解析终极指南:3分钟告别广告等待 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载而烦恼吗?每次下载都要面对烦人的广告等待,还要输入…...