Mybatis源码学习笔记(四)之Mybatis执行增删改查方法的流程解析
1 Mybatis流程解析概述
Mybatis框架在执行增伤改的流程基本相同, 很简单,这个大家只要自己写个测试demo跟一下源码,基本就能明白是怎么回事,查询操作略有不同, 这里主要通过查询操作来解析一下整个框架的流程设计实现。
2 Mybatis查询操作的基本流程
2.1 Mapper代理对象MapperProxy的创建流程

Mapper(实际上是一个代理对象)是从SqlSession中获取的, 因为SqlSession的实现类DefaultSqlSession类中存在Configuration类对象, 而我们在创建sqlSession对象的操作完成之后, configuration对象中已经存储了所有的mapper及其对应的代理对象之间的映射关系,如下图:
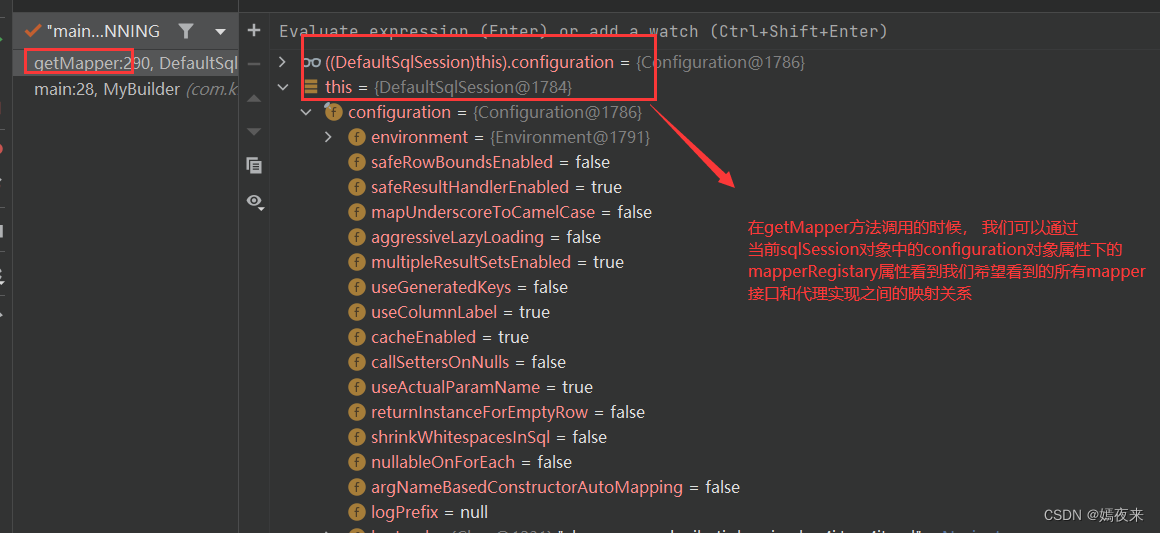
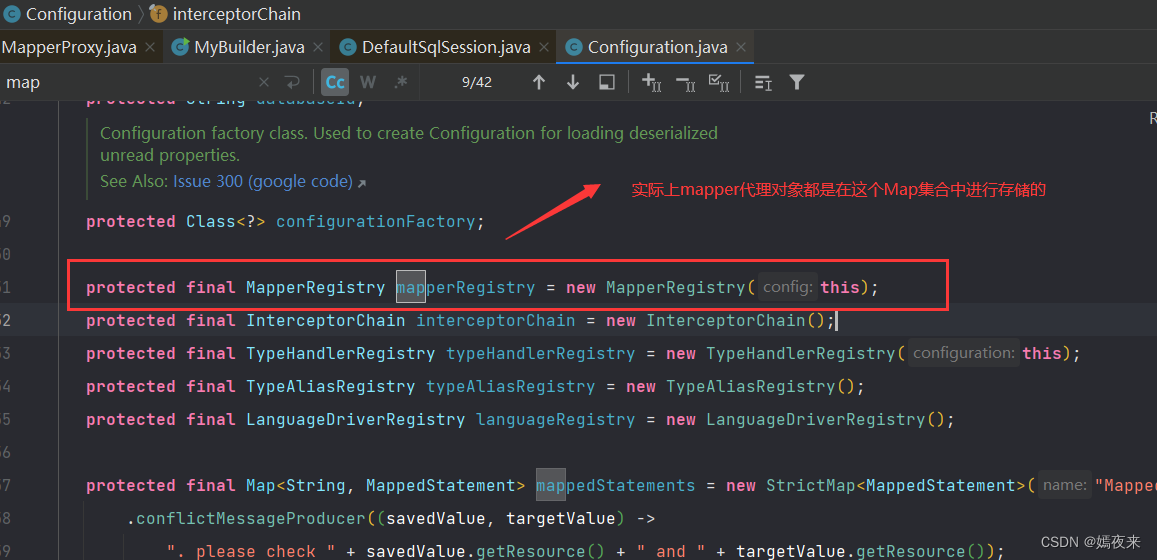
看看mapperRegistry如下图:
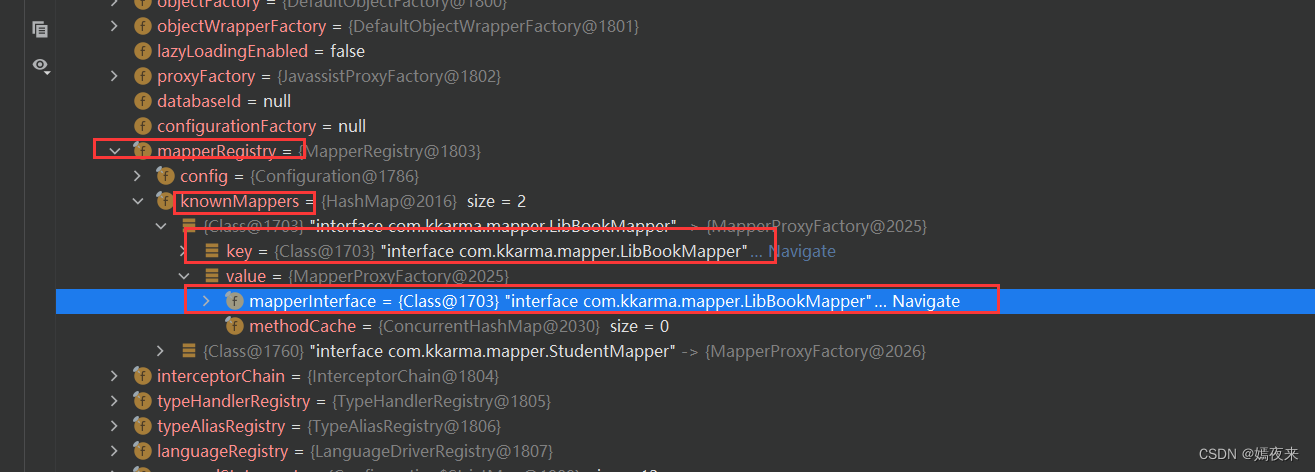
MapperRegistry类中创建代理对象的核心步骤如下
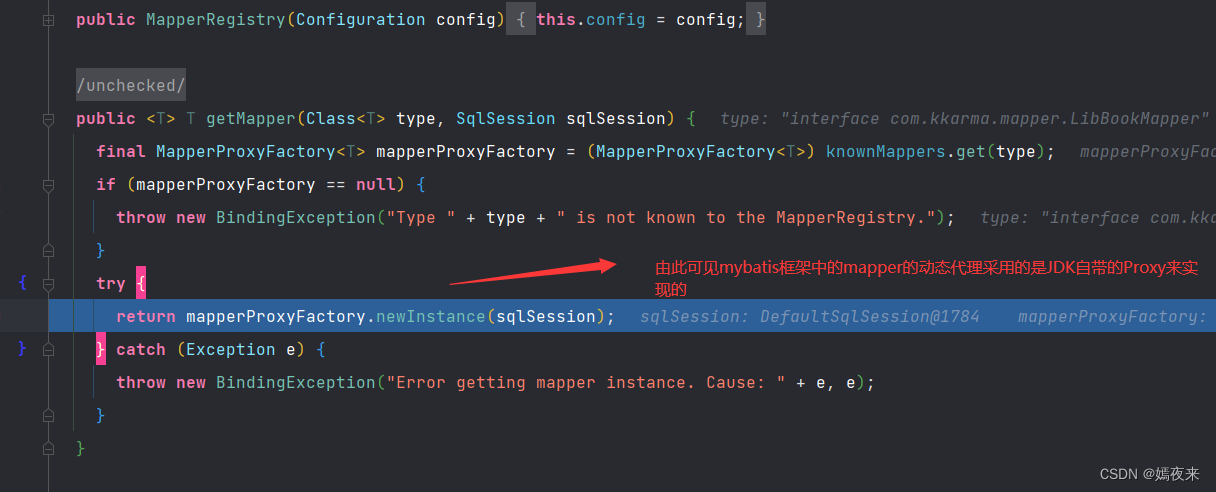
MapperProxyFactory类中的newInstance方法的调用
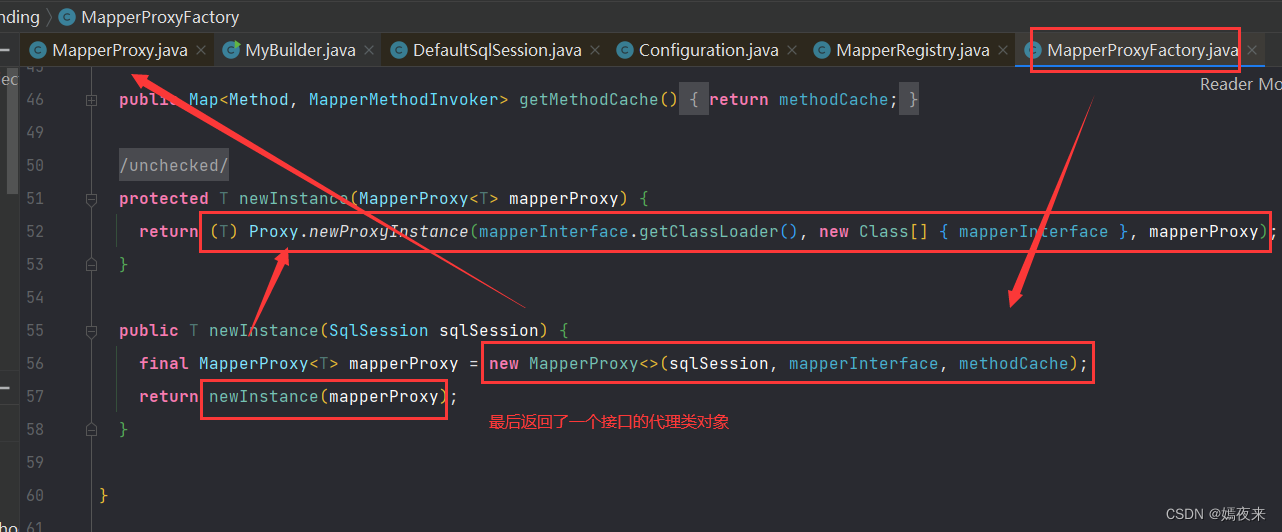
这里通过动态代理创建出目标mapper层的代理类对象并返回。
2.2 创建Mapper代理对象MapperProxy的调用流程
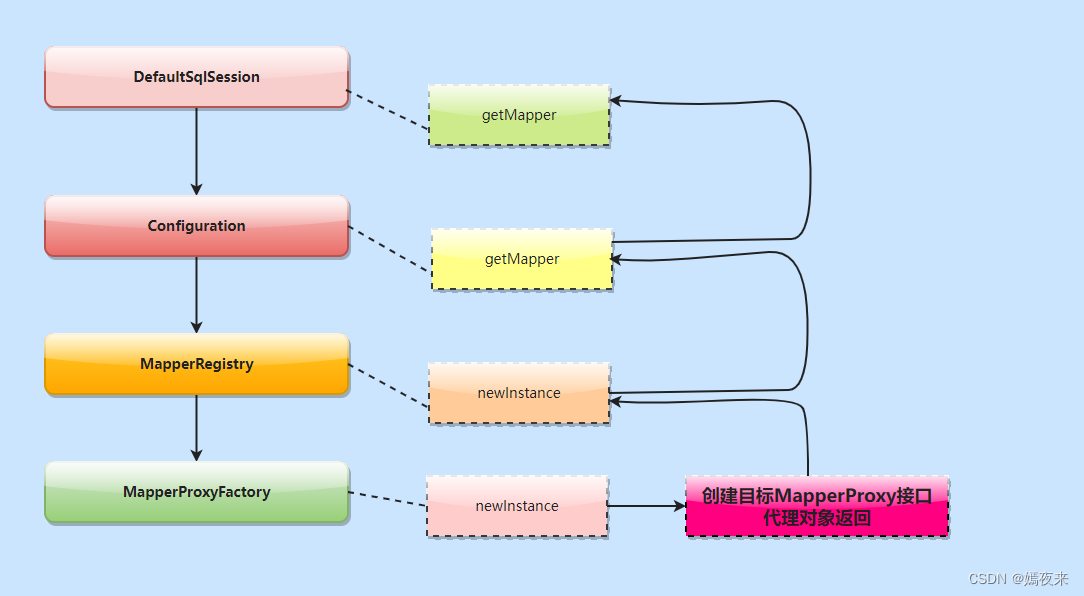
总结getMapper(Class clazz)方法创建动态代理对象的调用逻辑如下图:
2.3 动态代理对象执行增删改查的核心流程
这里我们使用查询接口来进行流程剖析
在应用层, 我们会调用下面这行代码来实现查询, 现在我们来分析一下这行代码在Mybatis的源码中是如何执行的, 它究竟是如何实现查询我们想要的数据的功能的
List<LibBook> libBooks = mapper.selectBooksByCondition("T311.5/3-1", null, null, null);
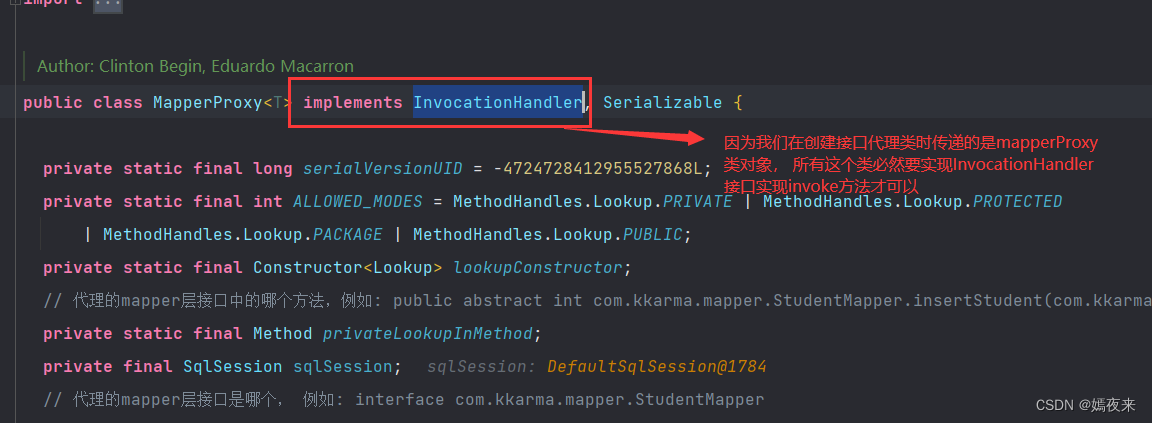
动态代理大家肯定都熟悉, 如果你要看源码, 连这点儿基础都没有, 建议不要硬看, 把java基础夯实了再来研究源码吧, 我们在使用Proxy创建动态对象时,比然要传递一个InvocationHandler接口的实现类或者匿名内部类对象,
2.1章节我们在创建动态代理类的时候,在MapperProxyFactory类中的newInstance方法中, 我们传递的InvocationHandler得实现类就是我们的MapperProxy类对象, 所以这个MapperProxy类必然实现了InvocationHandler接口, 我们验证一下是不是:
果然MapperProxy类实现了InvocationHandler接口并实现了invoke方法
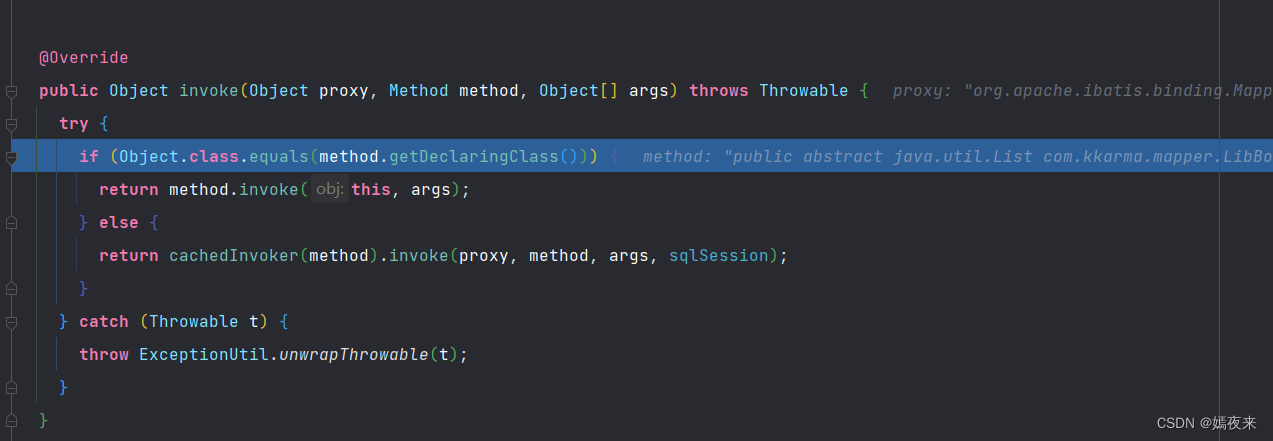
下面我们调用Mapper接口中的方法selectBooksByCondition, 实际上都是通过MapperProxy.invoke()方法去执行的。
2.3.1 MapperProxy.invoke()方法调用解析
@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {/*** 这里给大家解释一下这个invoke判断里面加这个判断的原因:* 大家都知道Object对象默认已经实现了很多方法, 我们的Mapper接口在进行定义的时候, 可能定义了静态方法、 默认方法以及抽象方法* 因此在创建了动态代理对象的时候, 这个动态代理类肯定也包含了很多的方法, 从Object类继承的方法, 从接口继承的默认方法,* 以及从接口继承抽象方法需要实现取执行SQL语句的方法** 这个if分值判断的只要目的在将无需走SQL执行流程的方法如(toString/equals/hashCode)等先过滤掉* 然后再抽象方法及默认方法中通过一个接口MapperMethodInvoker再进行一次判断,找到所有需要执行SQL的方法通过PlainMethodInvoker的invoke* 方法取执行SQL语句获取结果,能够加快获取 mapperMethod 的效率*/if (Object.class.equals(method.getDeclaringClass())) {return method.invoke(this, args);} else {return cachedInvoker(method).invoke(proxy, method, args, sqlSession);}} catch (Throwable t) {throw ExceptionUtil.unwrapThrowable(t);}}
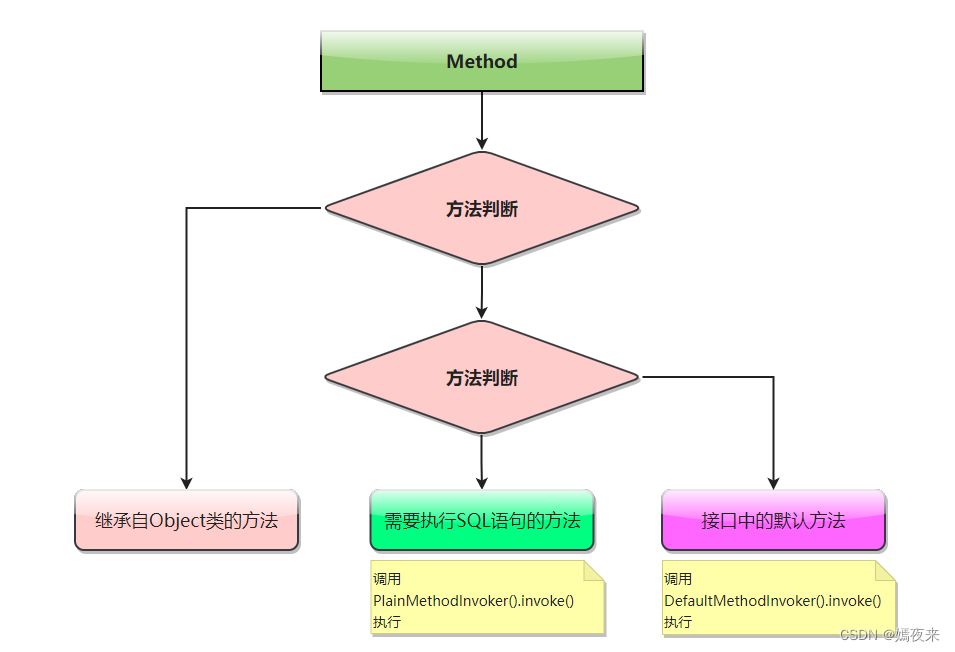
PlainMethodInvoker().invoke()方法会调用MapperMethod类中的execute()方法
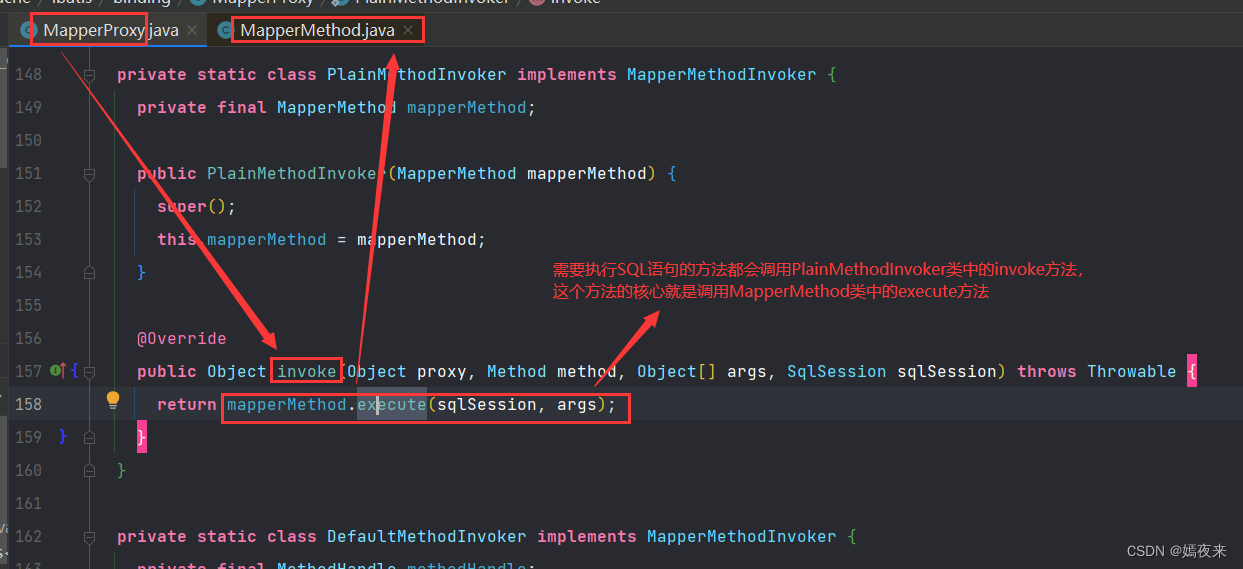
2.3.2 MapperMethod.execute()方法调用解析
MapperMethod类中的execute()方法具体执行逻辑如下
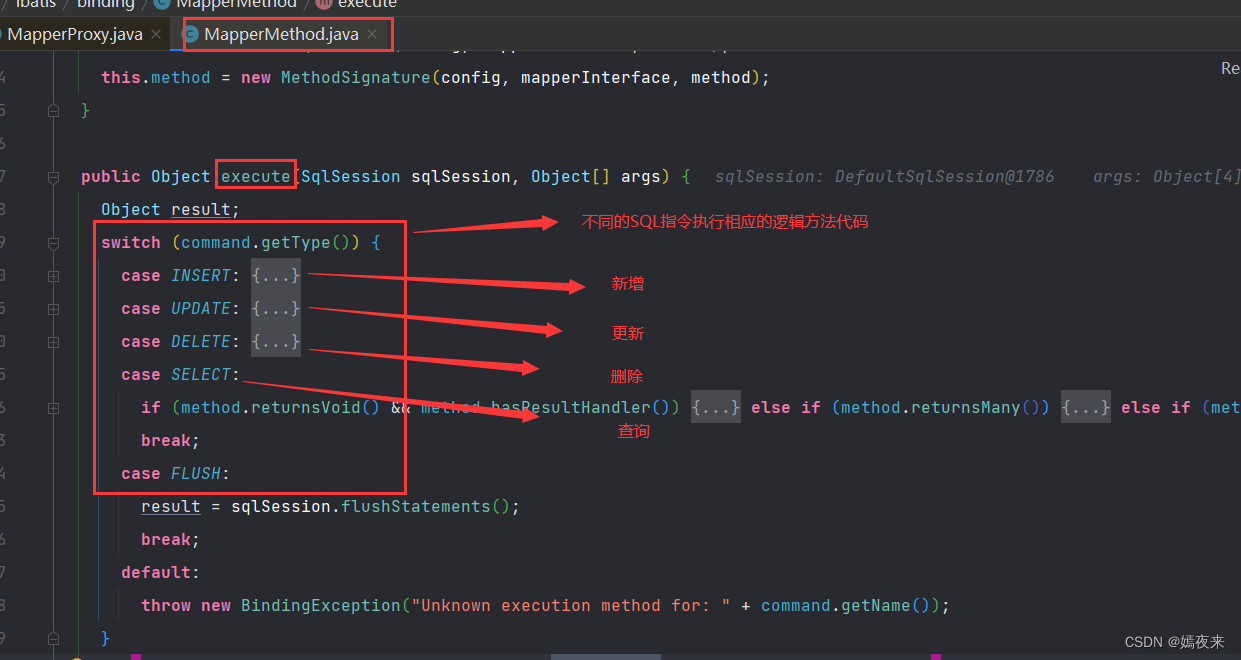
public Object execute(SqlSession sqlSession, Object[] args) {Object result;switch (command.getType()) {// 插入操作case INSERT: {// 如果你用过Mybatis的话, 你一定清楚, Mybatis的中参数传递的方式有以下几种// 第一种: [arg0,arg1,...]// 第二种: [param1,param2,...]// convertArgsToSqlCommandParam(args)方法就是实现这种映射// 举例说明:我之前传递的参数是一个Book对象{"bookId": "val1", "bookIndexNo":"val2", "bookName":"val3"}// 经过convertArgsToSqlCommandParam()方法处理之后得到{"bookId": "val1", "bookIndexNo":"val2", "bookName":"val3", "param1": "val1", "param2":"val2", "param3":"val3"}Object param = method.convertArgsToSqlCommandParam(args);// 执行SQL操作并对返回结果进行封装处理result = rowCountResult(sqlSession.insert(command.getName(), param));break;}// 更新操作case UPDATE: {Object param = method.convertArgsToSqlCommandParam(args);// 执行SQL操作并对返回结果进行封装处理result = rowCountResult(sqlSession.update(command.getName(), param));break;}// 删除操作case DELETE: {Object param = method.convertArgsToSqlCommandParam(args);// 执行SQL操作并对返回结果进行封装处理result = rowCountResult(sqlSession.delete(command.getName(), param));break;}case SELECT:// 查询操作的情况比较复杂, 需要分情况逐一处理if (method.returnsVoid() && method.hasResultHandler()) {// 如果查询操作的返回为空并且方法已经指定了结果处理器时,执行以下语句executeWithResultHandler(sqlSession, args);result = null;} else if (method.returnsMany()) {// 如果查询操作的返回返回结果为List集合, 执行以下语句result = executeForMany(sqlSession, args);} else if (method.returnsMap()) {// 如果查询操作的返回返回结果为Map集合, 执行以下语句result = executeForMap(sqlSession, args);} else if (method.returnsCursor()) {// 如果查询操作的返回返回结果为Cursor, 执行以下语句result = executeForCursor(sqlSession, args);} else {Object param = method.convertArgsToSqlCommandParam(args);result = sqlSession.selectOne(command.getName(), param);// 如果查询操作的返回返回结果为单个对象并且指定返回类型为Optional, 则将返回结果封装成Optional对象返回if (method.returnsOptional()&& (result == null || !method.getReturnType().equals(result.getClass()))) {result = Optional.ofNullable(result);}}break;case FLUSH:result = sqlSession.flushStatements();break;default:throw new BindingException("Unknown execution method for: " + command.getName());}if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {throw new BindingException("Mapper method '" + command.getName()+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");}return result;}
当前我们执行的查询语句, 返回的结果列表是一个List, 所以调用的是executeForMany(sqlSession, args);
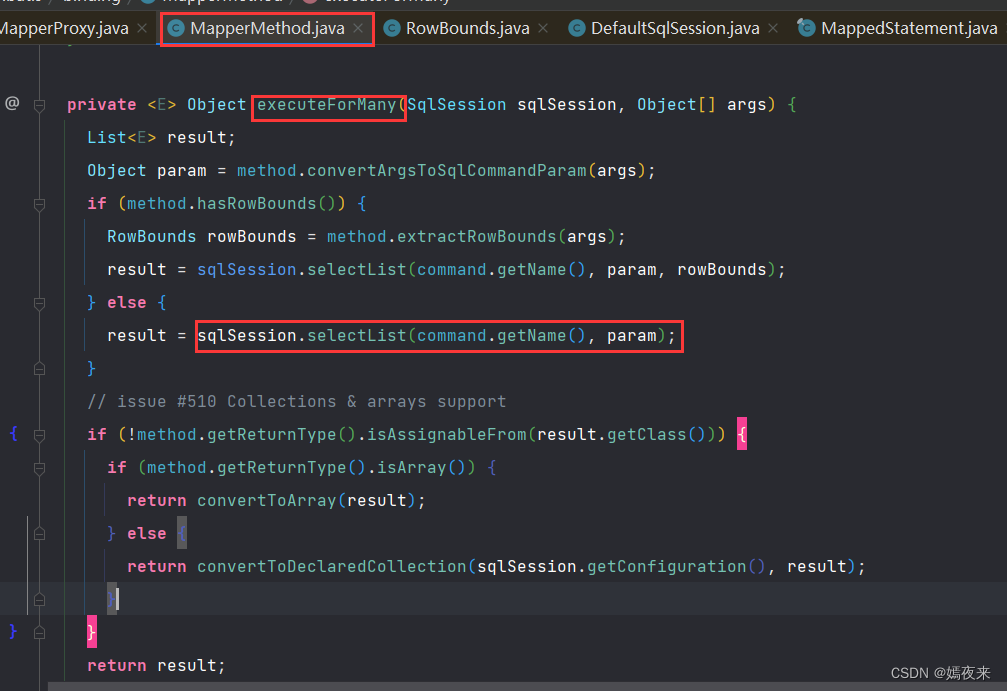
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {List<E> result;Object param = method.convertArgsToSqlCommandParam(args);// 这里是判断你的mapper层接口方法是否传递了RowBounds对象,根据是否传递了RowBounds对象来调用sqlSession对象的selectList的不同传参的重载方法// 这个RowBounds对象主要是来进行分页功能,会将所有符合条件的数据全都查询出来加载到内存中,然后在内存中再对数据进行分页(当数据量非常大的时候, 就会发生OOM, 一般不推荐使用)if (method.hasRowBounds()) {RowBounds rowBounds = method.extractRowBounds(args);result = sqlSession.selectList(command.getName(), param, rowBounds);} else {// 我们这里没有传递RowBounds对象, 所以调用的是这个方法result = sqlSession.selectList(command.getName(), param);}// issue #510 Collections & arrays supportif (!method.getReturnType().isAssignableFrom(result.getClass())) {if (method.getReturnType().isArray()) {return convertToArray(result);} else {return convertToDeclaredCollection(sqlSession.getConfiguration(), result);}}return result;}
2.3.3 executor.query()执行器执行查询的逻辑流程解析
2.3.3.1 创建PreparedStatement对象
我们在创建configuration类对象的时候,已经设置过默认的executor对象类型就是Simple
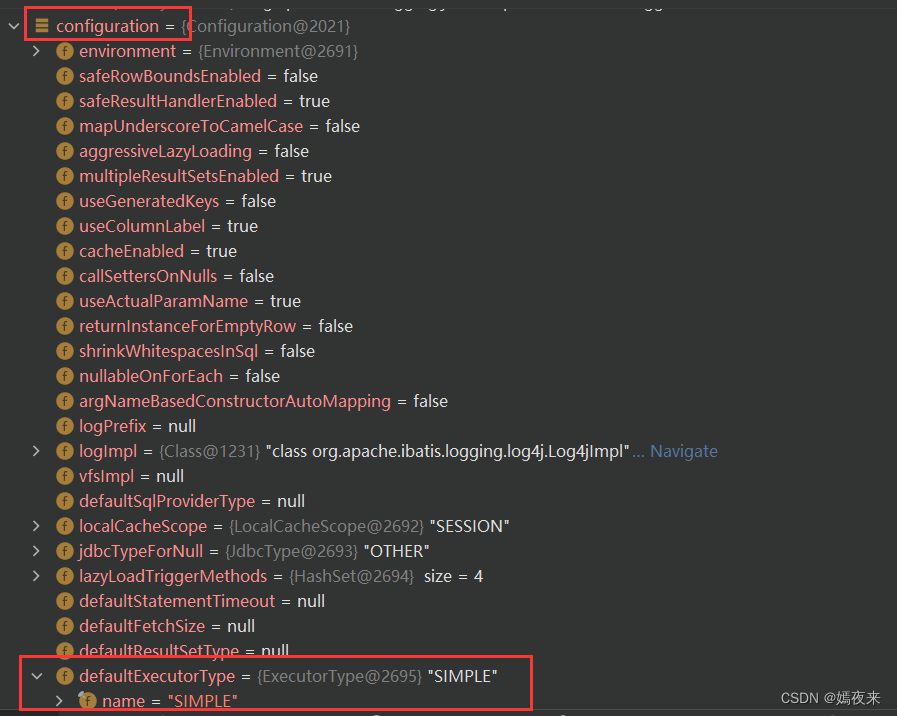
那么这里的executor应该是SimpleExecutor对象啊, 但是实际上并不是, 这里的executor对象是CachingExecutor对象 这里大家肯定会有疑问, 在debug的过程中, 我明明没有看到有创建CachingExecutor对象啊, 这个对象是啥时候创建的? 为啥不是SimpleExecutor对象对象啊?
这里解答一下, 下面这两行代码,只要你使用过Mybatis框架, 肯定不陌生
SqlSessionFactory factory = factoryBuilder.build(ins);
SqlSession sqlSession = factory.openSession(true);
factory.openSession(true)这个方法调用我们跟进去看看
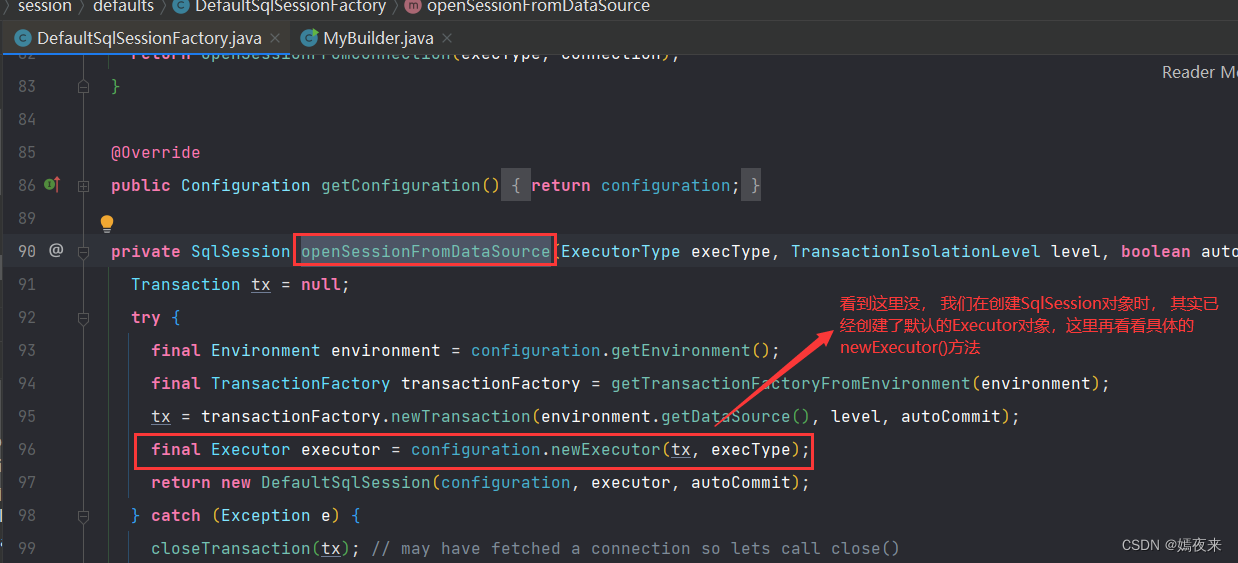
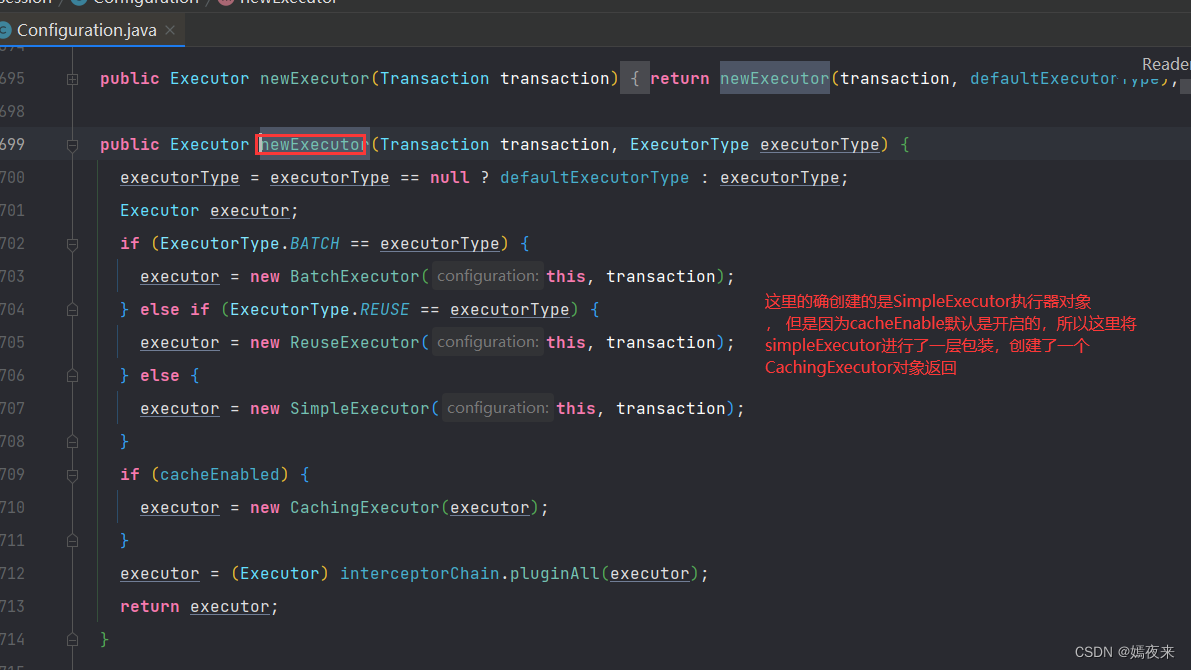
好了以上就是executor是什么时候创建的以及为什么明明应该是simpleExecutor,但是实际却是cachingExecutor对象的原因。
下面接着说查询方法的执行过程
sqlsession对象会调用执行器的查询方法开始查询
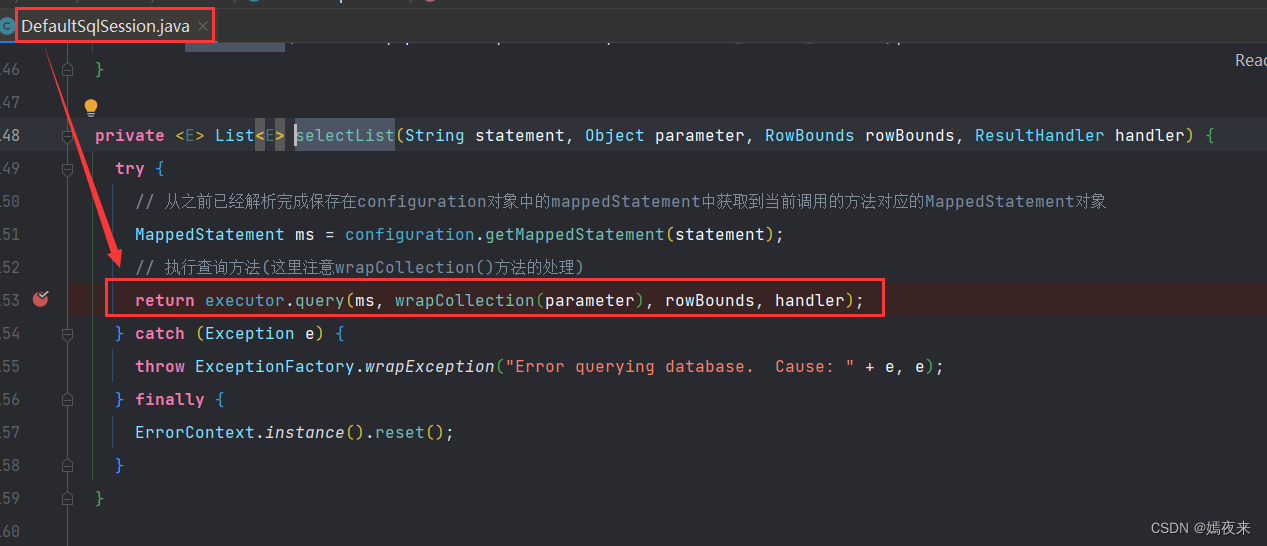
这里调用了委托者SimpleExecutor对象的query()方法,但是SimpleExecutor对象没有query方法, 就调用了父类BaseExecutor里面query()方法
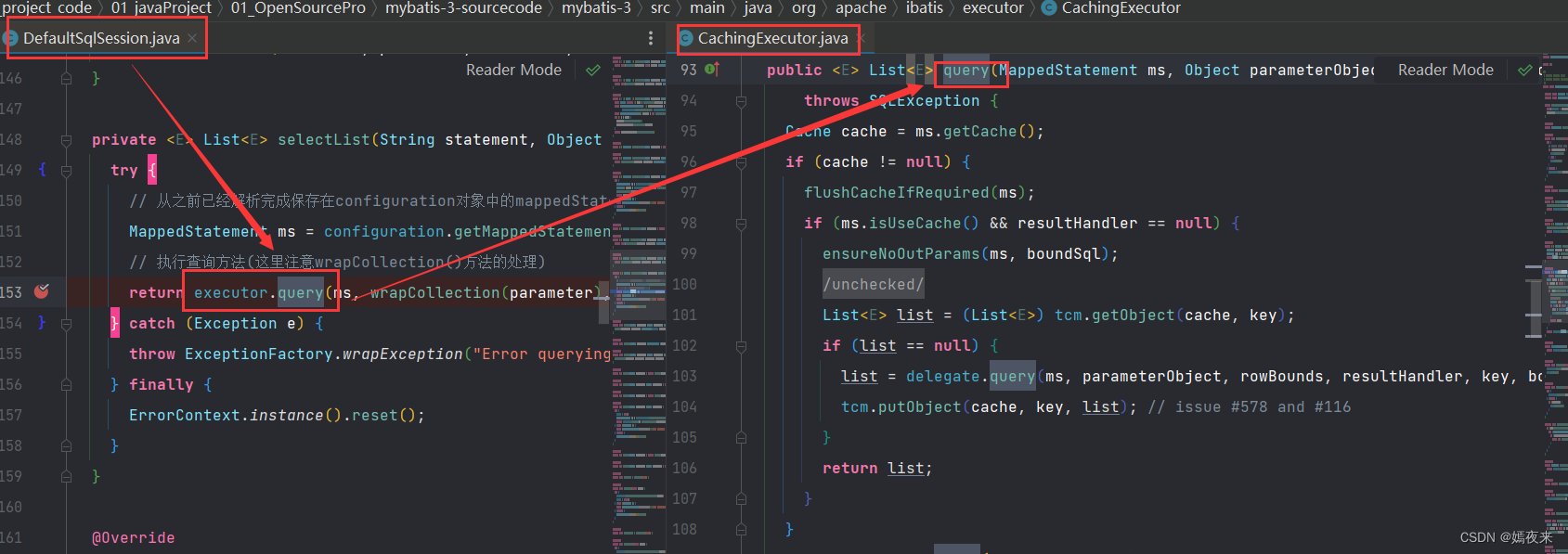
query()方法中又调用了父类BaseExecutor里面queryFromDatabase()方法
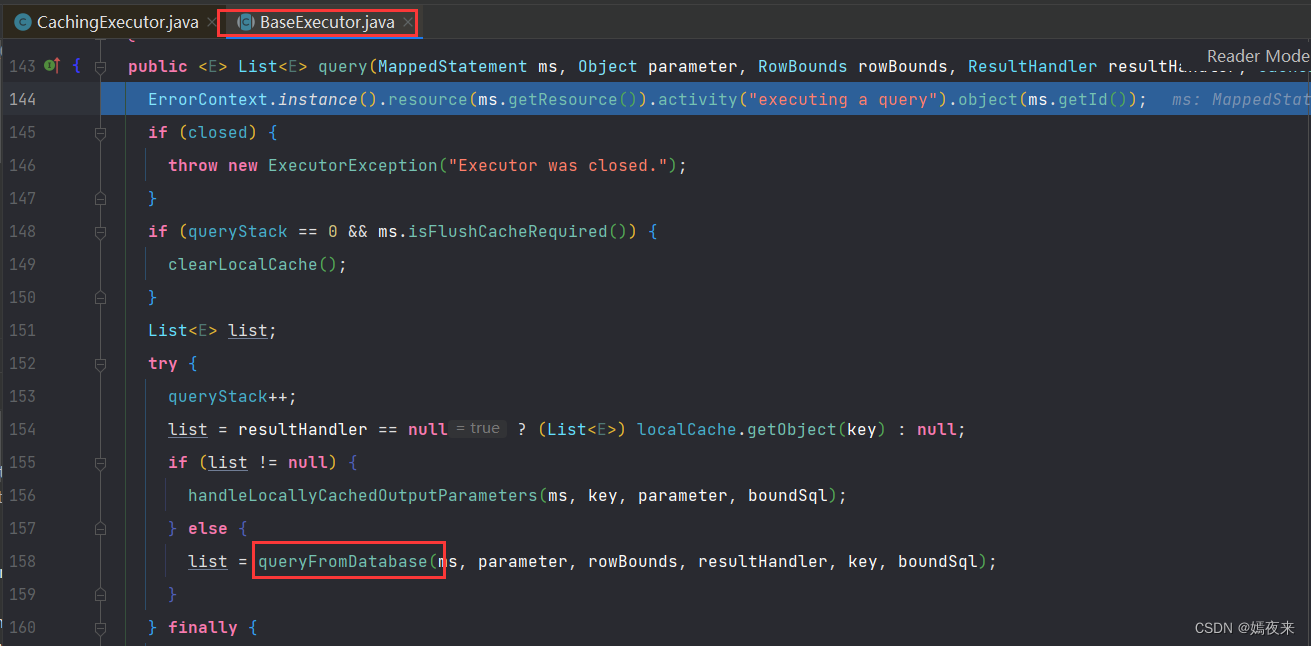
queryFromDatabase()()方法中又调用了父类BaseExecutor的抽象方法doQuery()方法,父类中没有实现该方法,但是子类SimpleExecutor对该方法进行了重写, 调用子类SimpleExecutor中的doQuery()方法执行
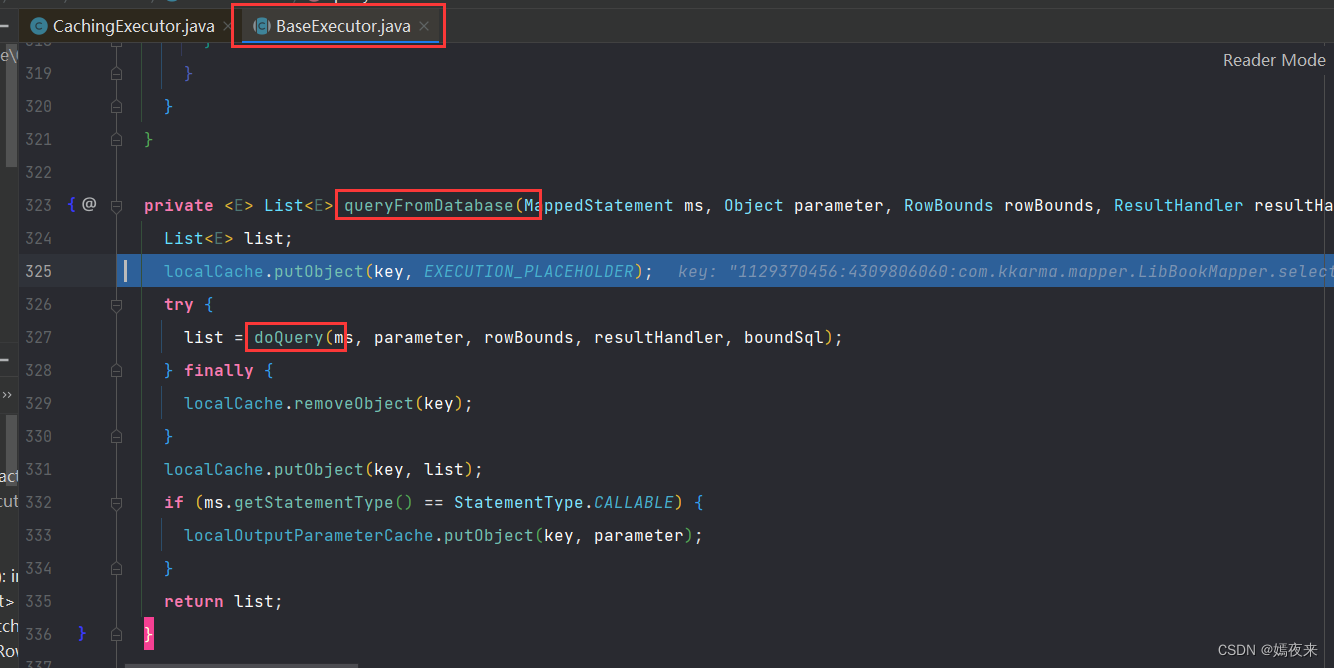
子类SimpleExecutor中的doQuery()方法如下图:
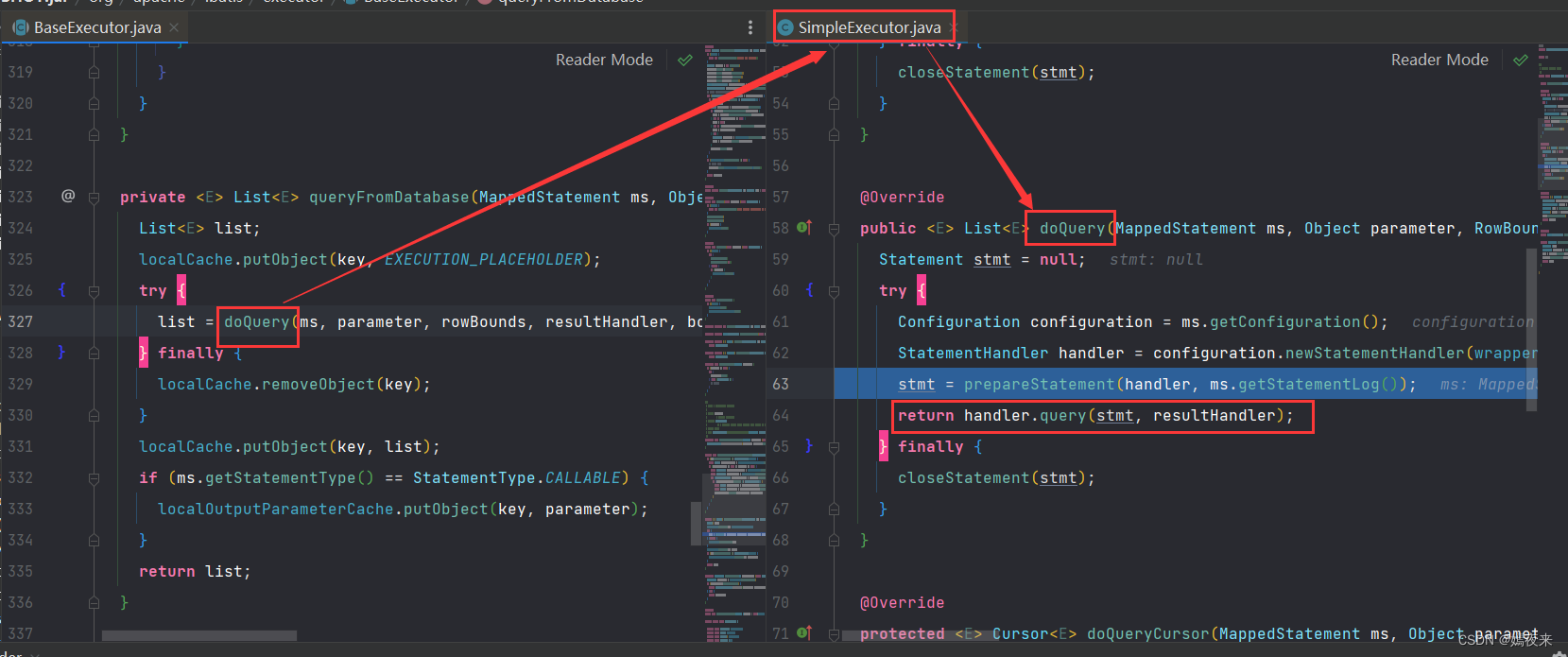
在SimpleExecutor类中的doQuery()方法中StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);这行代码执行完成的时候,当前代理方法的ParameterHandler对象和ResultSetHandler对象也会创建并扩展完成,如果我们又在配置文件中自定义ParameterHandler、ResultSetHandler、StatementHandler在这个过程都会被通过拦截器注册并依次调用。
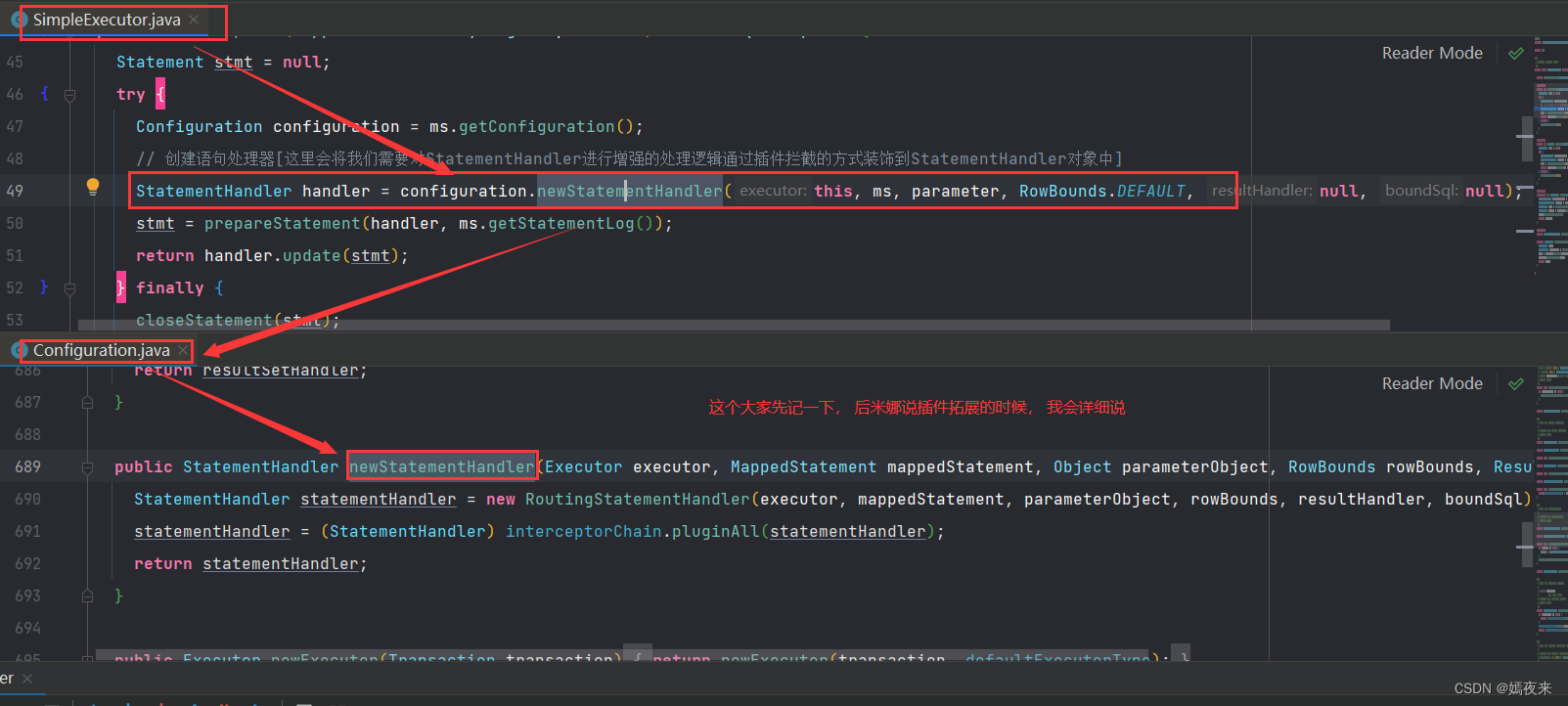
RoutingStatementHandler里面没有任何的实现,是用来创建基本的StatementHandler的。这里会根据MappedStatement里面的statementType(一共有三种:STATEMENT、PREPARED、CALLABLE))决定StatementHandler的类型,MappedStatement对象默认是PREPARED。
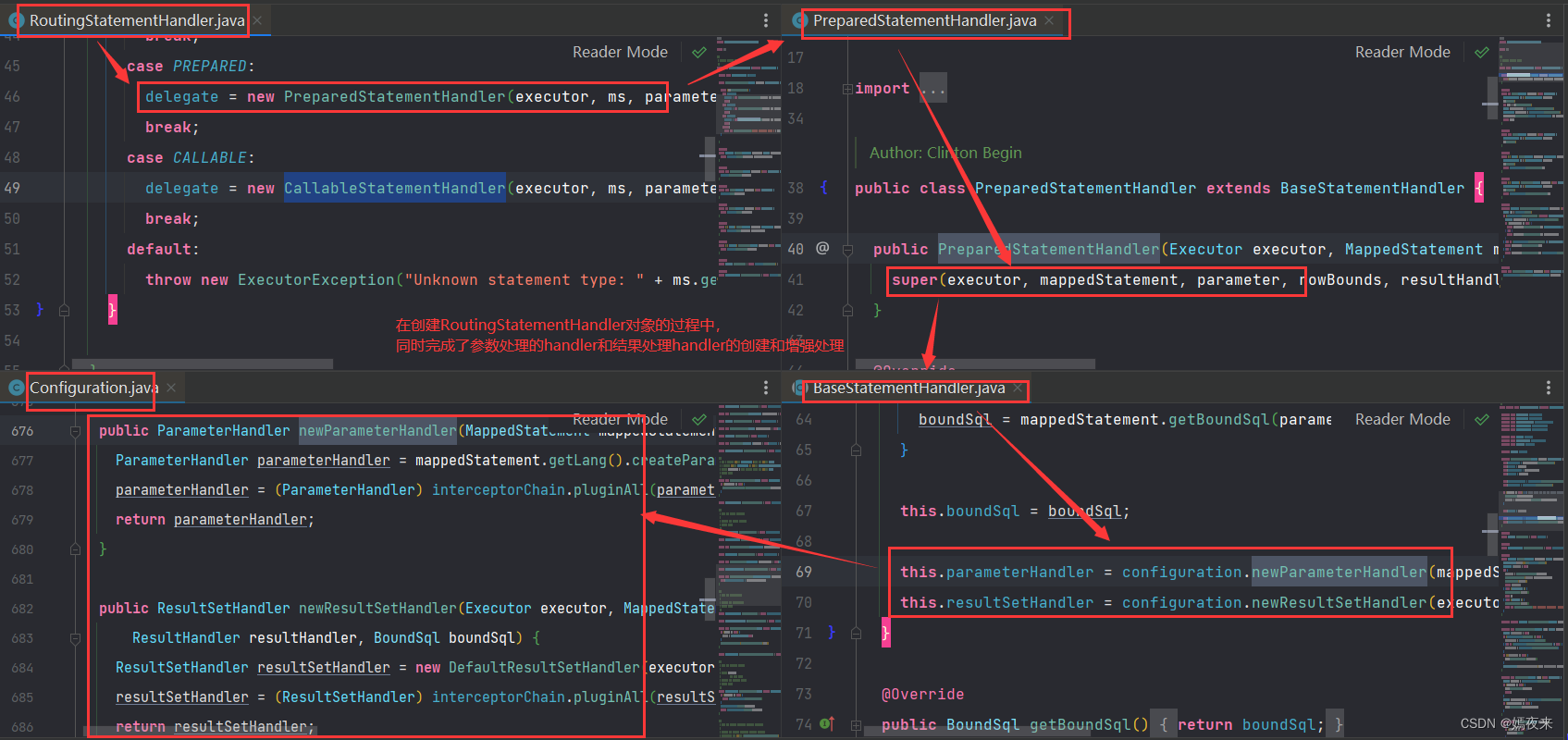
在SimpleExecutor类中的doQuery()方法中StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);Configuration类中的如下方法将被调用
/** 拦截参数处理器:通过拦截器拓展插件功能对ParameterHandler的基础功能进行增强 */
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);return parameterHandler;}/** 拦截结果映射处理器:通过拦截器拓展插件功能对ResultSetHandler的基础功能进行增强 */
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,ResultHandler resultHandler, BoundSql boundSql) {ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);return resultSetHandler;}/** 拦截SQL语句处理器:通过拦截器拓展插件功能对StatementHandler的基础功能进行增强 */
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);return statementHandler;}
RoutingStatementHandler对象创建完成之后会调用prepareStatement()方法创建Statement对象
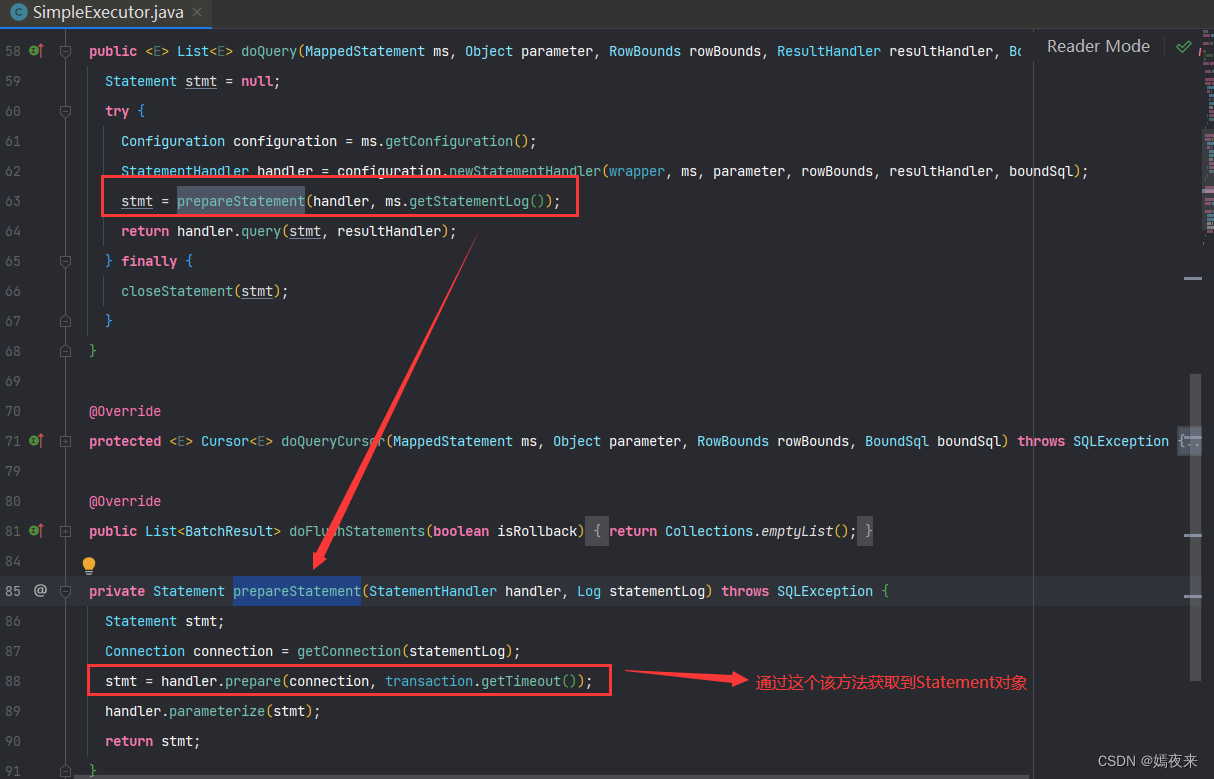
2.3.3.2 Statement中的入参处理
在SimpleExecutor对象中再创建出最终要执行的Statement对象之后, 就是处理入库真实替换SQL语句中的占位符了,主要是通过statementHandler.parameterize(stmt)来实现的, 具体的还是调用了PreparedStatementHandler类中的.parameterize(stmt)方法来处理
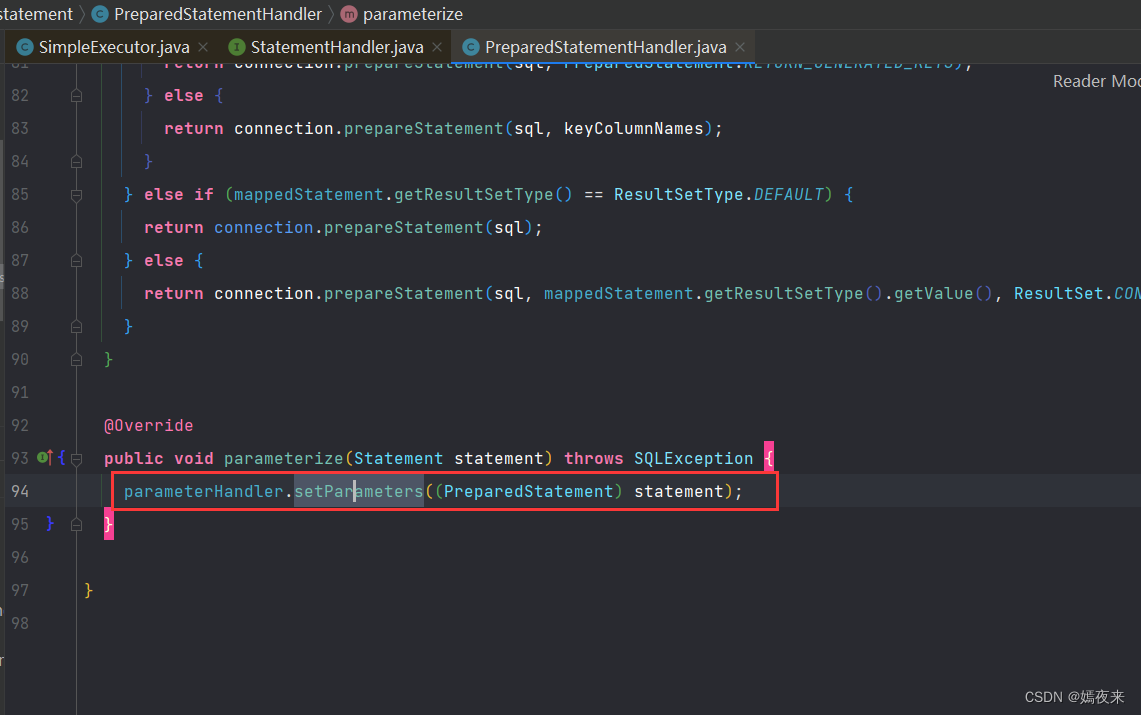
这里就用到了我们的ParameterHandler对象了, 通过setParameters()方法完成参数替换。
具体的方法实现有兴趣可以自行研究
2.3.3.3 ResultSet结果及处理
SimpleExecutor类的handler.query(stmt, resultHandler)方法最终会调用PreparedStatementHandler的query方法执行SQL语句并返回结果
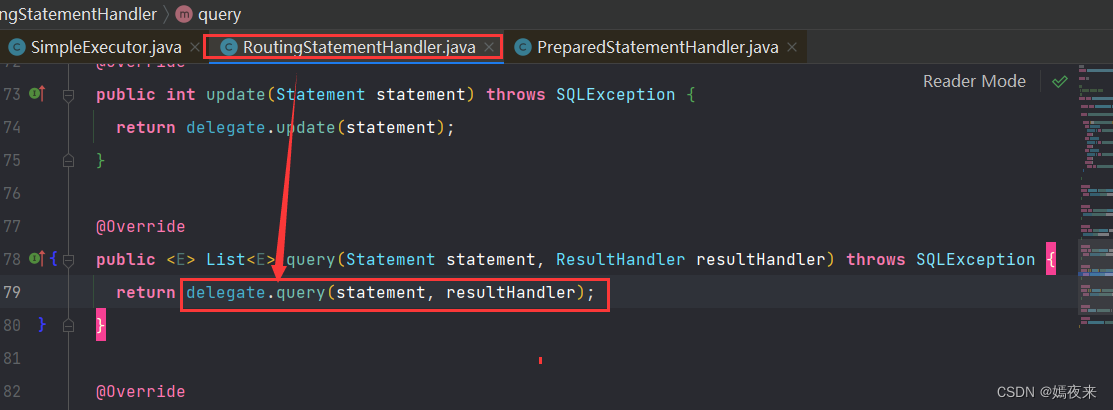
PreparedStatementHandler的query方法会调用PreparedStatement.execute()执行SQL语句,返回查询结果集
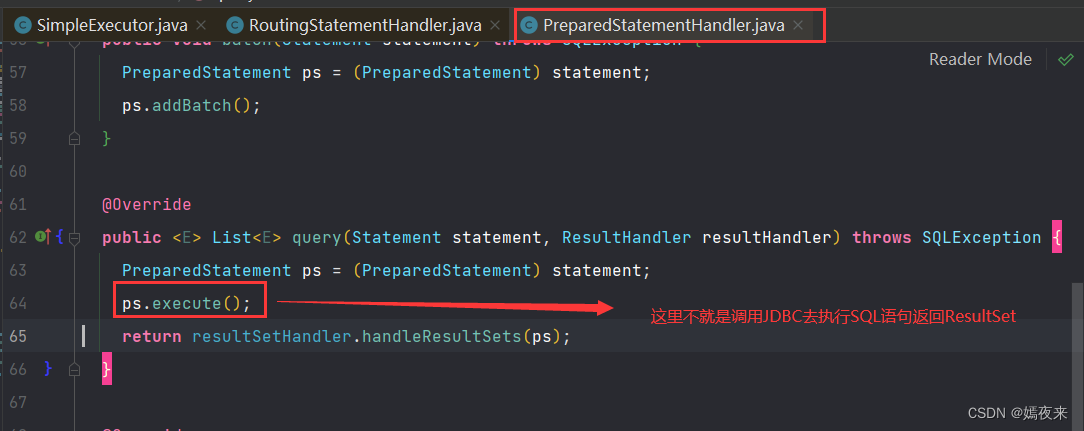
DefaultResultSetHandler.handleResultSets()方法会将查询结果集处理成Java中的List对象返回。
3 查询方法的调用逻辑图

4 源码阅读过程中的笔记
MapperProxyinvokeMapperMethodexecute()executeForMany()DefaultSqlSessionselectList()CachingExecutorquery()1、生成二级缓存KEYcreateCacheKey()1、将缓存KEY作为参数传递,调用重载query()方法query()1、从MappedStatement对象中获取Cache对象2、如果Cache对象不是null, 说明有二级缓存2.1、判断MappedStatement对象的isFlushCacheRequired属性是为true, 如果为true,刷新缓存2.2、判断MappedStatement对象是否使用缓存(isUseCache属性是否为true),并且resultHandler属性默认为null, 如果两者都满足, 直接从Cache对象中通过缓存KEY查询结果数据list2.3、判断结果数据list是否为空,如果为空,从数据库中查询出结果,然后将查询结果放置到Cache对象中的缓存KEY下,最后把查询结果list返回3、如果Cache对象是null, 直接从数据库中查询出结果(调用BaseExecutor.query())BaseExecutorcreateCacheKey()query()1、判断当前的queryStack是否为0,并且MappedStatement对象的isFlushCacheRequired属性是为true,满足条件就清空一级缓存,否则跳过2、判断MappedStatement对象的resultHandler属性是否为null,满足条件就直接从一级缓存中通过缓存KEY查询结果数据list2.1、如果结果数据list不为空,调用handleLocallyCachedOutputParameters()方法对结果进行处理(主要是因为如果调用的是存储过程,执行的结果需要接受并处理)2.2、如果结果数据list为空,调用queryFromDatabase()直接从数据库中进行查询结果3、处理嵌套查询if (queryStack == 0) {for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();// 嵌套查询会借助一级缓存,所以一级缓存不能关闭// 嵌套查询是肯定会延迟加载的,存入DeferredLoad类,避免重复的查询执行// 执行嵌套查询时,当有结果值就直接存入,没有就存入一个占位符,这样相同的嵌套查询,在一级缓存中只会存在一个,当所有的都处理完成以后,然后再最终处理所有的延迟加载4、返回最终结果queryFromDatabase()1、首先通过缓存KEY在缓存对象中先开辟空间,因为缓存结果还没有从数据库中查询,先设置一个占位符告诉其他人这个坑已经有人占了2、调用doQuery()方法查询数据3、将第一步的缓存对象清除(因为它没有真正的保存数据对象,只是在我查询数据还没有返回数据结果的这段时间假装已经有缓存了)4、将真正从数据中查询出来的数据对象放入一级缓存,然后然后结果list
SimpleExecutordoQuery()1、创建StatementHandler对象1.1 MappedStatement对象中默认的statementType对象是"PREPARED", 这里会执行new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);1.2 new PreparedStatementHandler的构造方法中调用了父类BaseStatementHandler的构造方法1.3 父类BaseStatementHandler的构造方法中做了parameterHandler和resultSetHandler的初始化操作,调用了configuration.newParameterHandler()和configuration.newResultSetHandler()方法进行对象创建,这里默认都是创建的DefaultParameterHandler和DefaultResultSetHandler对象2、prepareStatement() 2.1 创建Connection连接对象2.2 执行statementHandler对象的prepare()方法,返回Statement对象// 2.2.1 调用RoutingStatementHandler类下的prepare()方法,返回Statement对象// 2.2.2 调用BaseStatementHandler类下的prepare()方法,返回Statement对象2.3 执行statementHandler对象的parameterize()方法// 2.3.1 调用RoutingStatementHandler类下的parameterize()方法// 2.3.2 调用PreparedStatementHandler类下的parameterize()方法2.4 返回Statement对象3、调用StatementHandler的query()方法3.1 调用RoutingStatementHandler类的query()方法3.2 调用PreparedStatementHandler类的query()方法BaseStatementHandler这个方法在创建prepare()1、调用instantiateStatement()创建Statement对象1.1 调用PreparedStatementHandler类下的instantiateStatement()方法创建Statement对象2、调用setStatementTimeout()设置执行和事务的超时时间3、调用setFetchSize()设置驱动的结果集获取数量(fetchSize)4、最后返回Statement对象PreparedStatementHandlerinstantiateStatement()1、调用JDBC的connection.prepareStatement(sql)方法创建出一个PreparedStatement对象返回parameterize()1、调用parameterHandler对象的setParameters()方法将PrepareStatement对象中的SQL语句中的参数占位符都替换成传入的参数值1.1 调用DefaultParameterHandler类的setParameters()方法1.2 遍历所有的ParameterMapping对象,依次替换所有的占位符为实际的传入的参数值query()1、获取到PreparedStatement对象2、调用PreparedStatement。execute()执行SQL语句3、调用DefaultResultSetHandler类的handleResultSets()方法处理查询结果集DefaultResultSetHandlerhandleResultSets()handleResultSet()handleRowValues()handleRowValuesForSimpleResultMapgetRowValue()applyPropertyMappings()方法完成从ResultSet结果集中的每一个行数据和Java对象之间的映射storeObject() 将getRowValue()处理完成的Objcet数据添加到List集合
相关文章:
Mybatis源码学习笔记(四)之Mybatis执行增删改查方法的流程解析
1 Mybatis流程解析概述 Mybatis框架在执行增伤改的流程基本相同, 很简单,这个大家只要自己写个测试demo跟一下源码,基本就能明白是怎么回事,查询操作略有不同, 这里主要通过查询操作来解析一下整个框架的流程设计实现。 2 Mybat…...

浅谈测试用例设计
前言 最近干的最多的事情就是设计测试用例、评审测试用例了,于是我不禁又想到了一个经典的问题:如何设计出优秀的测试用例? 可能有些童鞋看到这个问题会有些不以为然,这有什么好想的?干个测试谁还不会设计测试用例&a…...
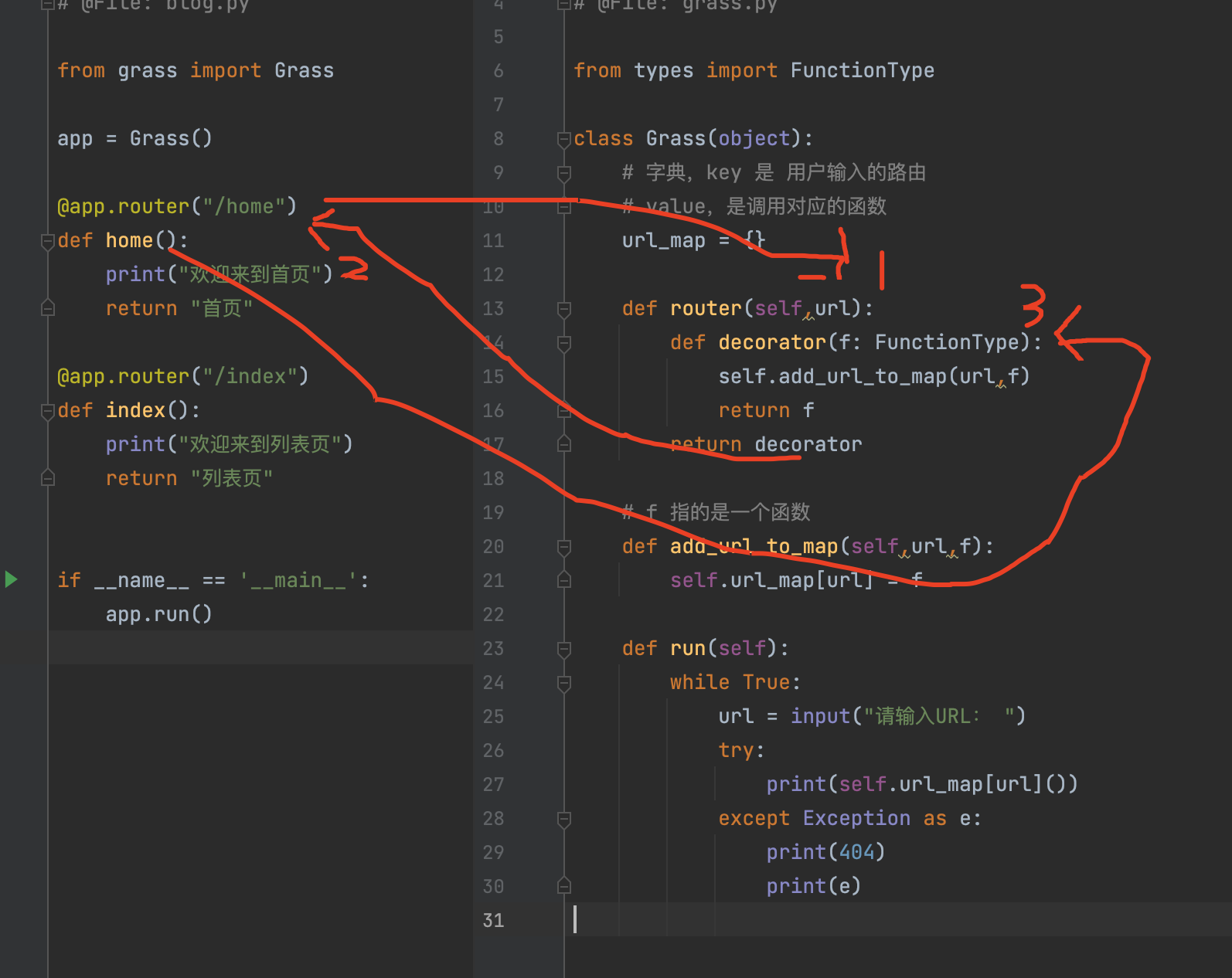
python 利用装饰器实现类似于flask路由
例子1: def f1():print(1111)def f2():print(2222)if __name__ __main__:print(33)打印结果: 33 在例子1中,f1() 与f2() 都没有被调用,只执行了print(33) f1与f2,是没有被调用的,但是如果f1 和 f2 上面…...
git 拉取远程分支到本地
目录:***!本小作者,是将终端和Git的可视化插件结合使用,刚接触的可以自习看一下,内容简单,避免弯路!***一,简单了解远程分支1,连接远程:2,提交&am…...

Answering Multi-Dimensional Range Queries under Local Differential Privacy
文章目录AbstractIntroduction2 PRELIMINARIES2.12.2 Categorical Frequency Oracles4 GRID APPROACHES4.1概述Abstract 在本文中,我们解决了在局部差异隐私下回答多维范围查询的问题。有三个关键的技术挑战:捕捉属性之间的相关性,避免维度的…...

手把手搭建springboot项目05-springboot整合Redis及其业务场景
目录前言一、食用步骤1.1 安装步骤1.1.1 客户端安装1.2 添加依赖1.3 修改配置1.4 项目使用1.5 序列化二、应用场景2.1 缓存2.2.分布式锁2.2.1 redis实现2.2.2 使用Redisson 作为分布式锁2.3 全局ID、计数器、限流2.4 购物车2.5 消息队列 (List)2.6 点赞、签到、打卡 (Set)2.7 筛…...
var、final、const、late)
Flutter基础语法(六)var、final、const、late
Flutter基础 第六章 Flutter关键字var、final、const、late的区别与使用 文章目录Flutter基础前言一、var1.var是什么?2.var如何使用3.var自动推断类型4.var可以再次赋值5.var指定类型二、final1.final是什么?2.final声明但不赋值3.final赋值多次4.final正常使用三、const1.…...
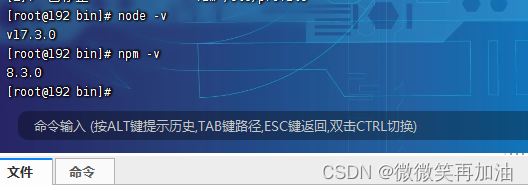
Linux之安装node
Linux之安装node步骤如下 1.去网站下载node 下载地址: https://npm.taobao.org/mirrors/ 2.上传到指定目录下 3.解压 tar -zxvf node-v17.3.0-linux-x644.配置node环境变量 //执行以下命令 vim /etc/profile //在path中加入以下内容 /usr/local/node-v15.14.0/b…...
二叉树、二叉搜索树、二叉树的最近祖先、二叉树的层序遍历【零神基础精讲】
来源0x3f:https://space.bilibili.com/206214 文章目录二叉树[104. 二叉树的最大深度](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)[111. 二叉树的最小深度](https://leetcode.cn/problems/minimum-depth-of-binary-tree/)[129. 求根节点到叶节点…...

【算法】【数组与矩阵模块】求最长可整合子数组和子数组的长度
目录前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本思考感悟写在最后前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介绍 …...

数据结构:循环队列的实现(leetcode622.设计循环队列)
目录 一.循环队列简单介绍 二.用静态数组实现循环队列 1.数组循环队列结构设计 2.数组循环队列的堆区内存申请接口 3.数据出队和入队的接口实现 4.其他操作接口 5.数组循环队列的实现代码总览 三.静态单向循环链表实现循环队列 1.链表循环队列的结构设计 2.创建静…...

[qiankun]实战问题汇总
[qiankun]实战问题汇总ERROR SyntaxError: Cannot use import statement outside a module问题分析解决方案子应用命名问题问题分析解决方案jsonpFunction详细错误信息问题分析解决方案微应用的注册问题Uncaught Error: application cli5-beta6-test-name died in status LOADI…...
:服务端常用参数配置)
Kafka(6):服务端常用参数配置
参数配置:config/server.properties # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership.…...

2023爱分析·云原生智能运维中台市场厂商评估报告:秒云(miaoyun.io)
目录 1. 研究范围定义 2. 云原生智能运维中台市场定义 3. 厂商评估:秒云(miaoyun.io) 4. 入选证书 1. 研究范围定义 数字化时代,应用成为企业开展各项业务的落脚点。随着业务的快速发展,应用的功能迭代变得越…...

hadoop容器化部署
1、原容器 java:openjdk-8u111-jre jre路径: /usr/lib/jvm/java-8-openjdk-amd64 /usr/lib/jvm/java-1.8.0-openjdk-amd64 2、安装ssh docker run -it --name hadoop-test java:openjdk-8u111-jre bash apt-get update apt-get install openssh service ssh start …...
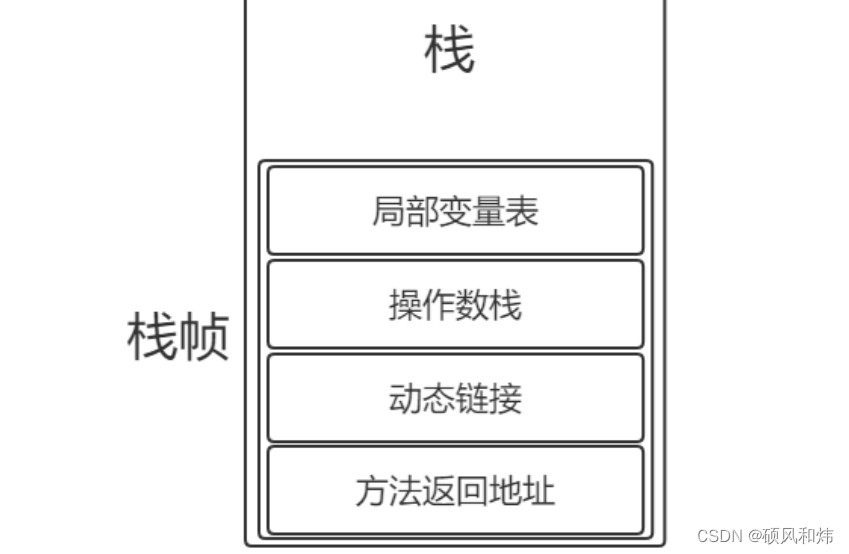
【07-JVM面试专题-JVM运行时数据区的虚拟机栈你知道吗?它的基本结构是什么呢?你知道栈帧的结构吗?那你说说动态链接吧?】
JVM运行时数据区的虚拟机栈你知道吗?它的基本结构是什么呢?你知道栈帧的结构吗?那你说说动态链接吧? JVM运行时数据区的虚拟机栈你知道吗?它的基本结构是什么呢?你知道栈帧的结构吗?那你说说动态…...

Java性能优化-GC优化基础
GC优化基础 调整堆大小 如果在FULL GC系统进行了交换,停顿时间会增长几个数量级,OS 如果G1 GC和后台进程处理堆,将会出现等待数据从磁盘复制到主内存时间较长,速度和下降并且并发模式可能失效 linux 关闭交换区 swapoff -a linu…...
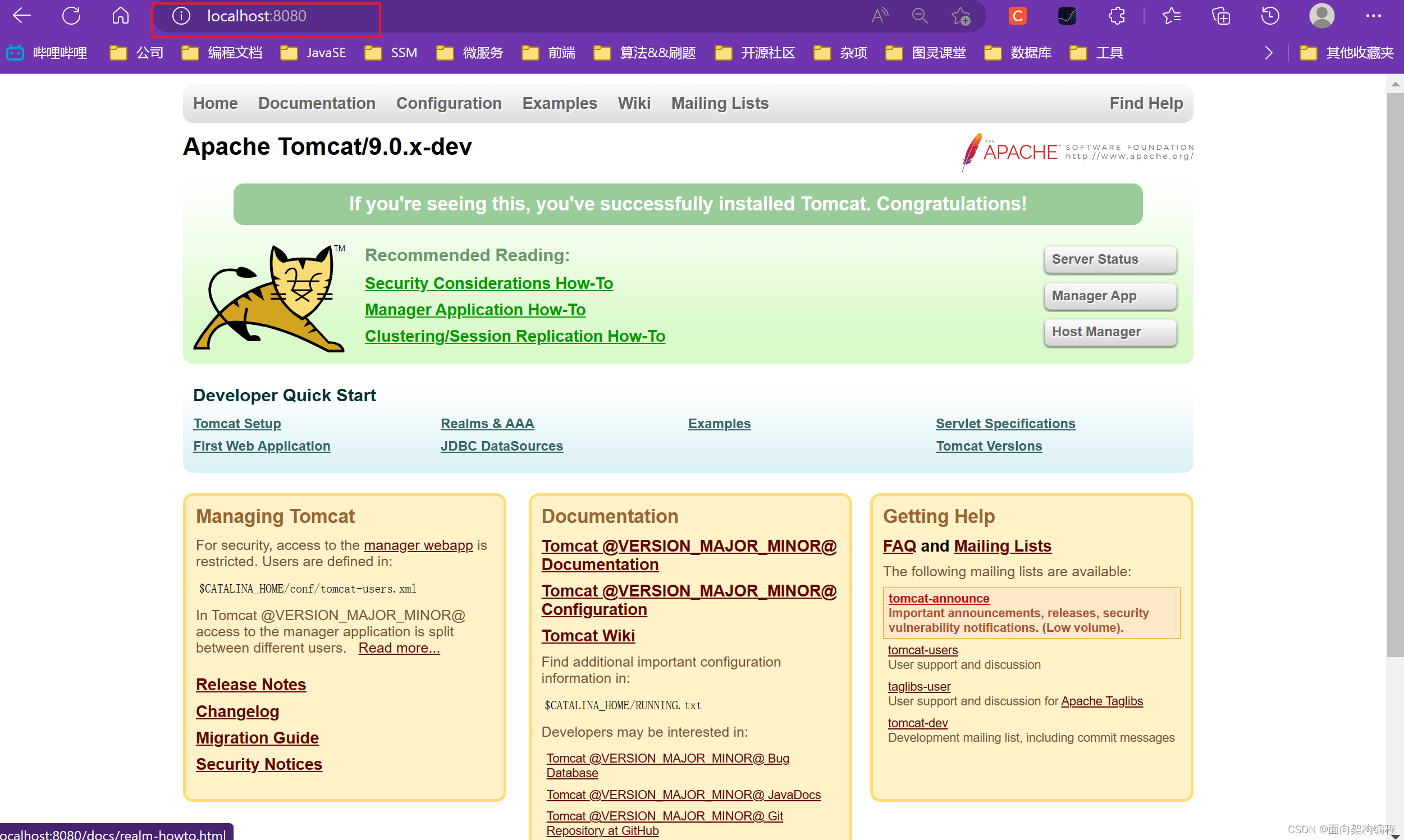
【Tomcat】IDEA编译Tomcat源码-手把手教程
一、环境准备Tomcat不同版本之间有一定的兼容性问题~如下图所示:官网地址:https://tomcat.apache.org/whichversion.html下载tomcat9官网上面的源码:这一篇文章主要是带着大家在自己的IDEA跑起来一个Tomcat。使用的版本是Tomcat9.0.55 和 JDK…...
如何弄小程序?公司企业可以这样做小程序
公司企业现在对于小程序的需求已经是刚需了,即使已经有官网的情况下,也会考虑再弄一个小程序来做小程序官网。那么公司企业如何弄小程序呢?下面跟大家说说方法。 流程一、找小程序服务商 由于一些公司企业并不像现在的互联网公司企业那样有…...
【Git】IDEA集合Git和码云
目录 7、IDEA集合Git 7.1 配置Git忽略文件-IDEA特定文件 7.2 定位 Git 程序 7.3 初始化本地库 7.4 添加到暂存区 7.5 提交到本地库 7.6 切换版本 7.7 创建分支 7.8 切换分支 7.9 合并分支 7.10 解决冲突 8、 Idea集成码云 8.1 IDEA 安装码云插件 8.2 分析工程到码…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...
和Python脚本,5分钟批量生成你的分割数据集)
告别手动标注!用SAM(Segment Anything)和Python脚本,5分钟批量生成你的分割数据集
5分钟批量生成分割数据集:SAM自动化标注全流程实战 在计算机视觉领域,数据标注一直是制约模型开发效率的瓶颈。传统手工标注不仅耗时费力,还容易引入人为误差。Meta开源的Segment Anything Model(SAM)彻底改变了这一局…...