实训笔记——Spark计算框架
实训笔记——Spark计算框架
- Spark计算框架
- 一、Spark的概述
- 二、Spark的特点
- 三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
- 3.1 本地安装--无资源管理器
- 3.2 Spark的自带独立调度器Standalone
- 3.2.1 主从架构的软件
- 3.2.2 Master/worker
- 3.2.3 伪分布、完全分布、HA高可用
- 3.3 Hadoop的YARN
- 3.4 Apache的Mesos
- 3.5 K8S容器技术
- 四、Spark程序的部署运行
- 五、Spark集群运行中三个核心角色
- 5.1 Driver驱动程序
- 5.2 Cluster Manager(资源管理器)
- 5.3 Executor(执行器)
- 六、Spark的核心基础Spark Core
- 6.1 Spark Core中最核心的有两个概念
- 6.1.1 SparkContext
- 6.1.2 RDD
- 6.2 RDD的属性(RDD具备的一些特征)
- 6.2.1 一组分区(一组切片)
- 6.2.2 一个计算每一个分区(切片)数据的compute函数
- 6.2.3 一个用来记录RDD依赖关系的列表
- 6.2.4 一个分区机制(RDD必须得是键值对类型的RDD)
- 6.2.5 一个用来记录分区位置的列表
- 6.3 RDD的弹性的体现
- 6.3.1 存储的弹性
- 6.3.2 计算的弹性
- 6.3.3 容错的弹性
- 6.3.4 分片的弹性
- 6.4 RDD的特点
- 6.4.1 分区
- 6.4.2 只读
- 6.4.3 依赖
- 6.4.4 缓存
- 6.4.5 检查点
- 6.5 RDD的分类
- 6.6 RDD的编程
- 6.6.1 RDD的创建操作
- 6.6.2 RDD的转换操作(转换算子)
Spark计算框架
一、Spark的概述
Spark是一个分布式的计算框架,是Hadoop的MapReduce的优化解决方案。Hadoop的MR存在两大核心问题:1、无法进行迭代式计算 2、MR程序是基于磁盘运算,运算效率不高
Spark主要解决了Hadoop的MR存在的问题,Spark是基于内存运算的一种迭代式计算框架
Spark还有一个思想 one stack to rule them all(一栈式解决方案),Spark内置了很多子组件,子组件可以应用于不同的计算场景下,Spark SQL(结构化数据查询)、Spark Streaming(准实时计算)、Spark MLlib(算法)、Spark GraphX(图计算)、Spark R,以上这些子组计都是基于Spark Core开发的。
Spark之所以可以实现基于内存的迭代式计算,主要也是因为Spark Core中的一个核心数据抽象RDD
二、Spark的特点
- 计算快速
- 易用
- 通用
- 兼容
三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
3.1 本地安装–无资源管理器
3.2 Spark的自带独立调度器Standalone
3.2.1 主从架构的软件
3.2.2 Master/worker
3.2.3 伪分布、完全分布、HA高可用
3.3 Hadoop的YARN
3.4 Apache的Mesos
3.5 K8S容器技术
【注意】:我们在安装部署Spark的资源管理器的同时,也可以安装一个Spark的job history
四、Spark程序的部署运行
Spark部署运行和MR程序的部署运行方式一致的,需要将我们编写的Spark程序打包成为一个jar包,放到我们的Spark集群中,然后通过Spark相关命令启动运行Spark程序即可
spark-submit --class 全限定类名 --master 运行的资源管理器 --deploy-mode 部署运行的模式 --num-executors 只在yarn模式下使用 指定executor的数量 --executor-cores 指定每一个executor具备多少个CPU内核,一个内核可以运行一个TASK --executor-memory 每一个executor占用的内存 jar包路径 main函数的args参数列表
五、Spark集群运行中三个核心角色
5.1 Driver驱动程序
5.2 Cluster Manager(资源管理器)
5.3 Executor(执行器)
六、Spark的核心基础Spark Core
Spark Core是Spark计算框架的核心基础,Spark中子组件都是基于Spark Core封装而来的。
Spark Core中包含了Spark的运行调度机制、Spark的迭代式计算、基于内存的运算机制
6.1 Spark Core中最核心的有两个概念
6.1.1 SparkContext
SparkContext:Spark的上下文对象,Spark程序的提交运行,任务分配等等都是由SparkContext来完成的。
6.1.2 RDD
RDD:也是Spark最核心最重要的概念,也是Spark中最基础的数据抽象(spark处理的所有数据都会封装称为RDD然后进行处理)
6.2 RDD的属性(RDD具备的一些特征)
6.2.1 一组分区(一组切片)
6.2.2 一个计算每一个分区(切片)数据的compute函数
6.2.3 一个用来记录RDD依赖关系的列表
6.2.4 一个分区机制(RDD必须得是键值对类型的RDD)
6.2.5 一个用来记录分区位置的列表
6.3 RDD的弹性的体现
6.3.1 存储的弹性
6.3.2 计算的弹性
6.3.3 容错的弹性
6.3.4 分片的弹性
6.4 RDD的特点
6.4.1 分区
6.4.2 只读
6.4.3 依赖
-
宽依赖:父RDD的一个分区数据被子RDD的多个分区同时使用,一般在shuffle算子中才会出现
-
窄依赖:父RDD的分区数据只能给子RDD的一个分区
依赖是Spark程序划分stage的核心依据,stage划分规则是从上一个宽依赖算子到下一个宽依赖算子之间的操作都属于同一个stage.
6.4.4 缓存
6.4.5 检查点
6.5 RDD的分类
RDD数据集,内部可以存放各种各样的数据类型,根据存储的数据类型不同,将RDD分为两类:数值类型的RDD(RDD)、键值对类型的RDD(PairRDD)
数值类型的RDD存放的数据类型可以是任何类型,包括键值对类型 RDD[String]、RDD[People]
键值对类型的RDD指的是数据集中存放的数据类型是一个二元组 是一种比较特殊的数值类型的RDD RDD[(String,Int)]、RDD[(Int,(String,Int))],
键值对类型的RDD有它自己独特的一些算子操作,同时键值对类型的RDD可以使用数值类型RDD的所有操作
6.6 RDD的编程
在Spark中,对数据操作其实就是对RDD的操作,对RDD的操作无外乎三种:1、创建RDD 2、从已有的RDD转换得到一个新的RDD 3、从已有的RDD得到相应的结果
RDD的编程方式主要分为两种:命令行编程方式(spark-shell–数据科学、算法研究)、API编程方法(数据处理 java scala python R)
6.6.1 RDD的创建操作
将数据源的数据转换称为Spark中的RDD,RDD的创建主要分为三种:1、从外部存储设备创建RDD(HDFS、Hive、HBase、Kafka、本地文件系统…)2、Scala|Java集合中创建RDD 3、从已有的RDD转换成为一个新的RDD(RDD的转换算子)
-
从集合中创建RDD
函数名 说明 parallelize(Seq[T],num)makeRDD(Seq[T],num)底层就是parallelize函数的实现了 makeRDD(Seq[(T, Seq[String])])这种方式创建的RDD是带有分区编号的 ,集合创建的RDD的分区数就是指定的分区数 1~2:都可以传递一个第二个参数,第二个参数代表的是RDD的并行度(RDD的分区数),默认分区数就是master中设置的cpu核数
-
从外部存储创建RDD
textFile()
wholeTextFile()
6.6.2 RDD的转换操作(转换算子)
RDD之所以可以实现迭代式操作,就是因为RDD中提供了很多算子,算子之间进行操作时,会记录算子之间的依赖关系
RDD中具备一个转换操作的算子,转换算子是用来从一个已有的RDD经过某种操作得到一个新的RDD的,转换算子是惰性计算规则,只有当RDD遇到行动算子,转换算子才会去执行。
算子:就是Spark已经给我们封装好的一些计算规则,只不过这些计算规则内部还需要传入计算逻辑,代码层面上,算子就是需要传入函数的函数。Spark提供了80+个算子。
数值型RDD的转换算子(通用算子)
| 函数名 | 说明 |
|---|---|
| map(f:T=>U) | 算子–一对一算子 |
| mapPartitions(f:Iterator[T]=>Iterator[U]) | 算子—一对一算子,一个分区的数据统一执行一次map操作 |
| mapPartitionsWithIndex(f:(Index,Iterator[T])=>Iterator[U]) | 一对一算子,和mapPartitions算子的逻辑一模一样的,只不过就是多了一个分区编号。 |
| filter(f:T=>Boolean) | 算子—过滤算子,对原有RDD的每一个算子应用一个f函数,如果函数返回true,那么数据保留,如果返回false,那么数据舍弃 |
键值对类型RDD的转换算子
相关文章:

实训笔记——Spark计算框架
实训笔记——Spark计算框架 Spark计算框架一、Spark的概述二、Spark的特点三、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)3.1 本地安装--无资源管理器3.2 Spark的自带独立调度器Standalone3.2.1 主从架构的软件3.2.2 Master/wor…...
自定义类型:结构体
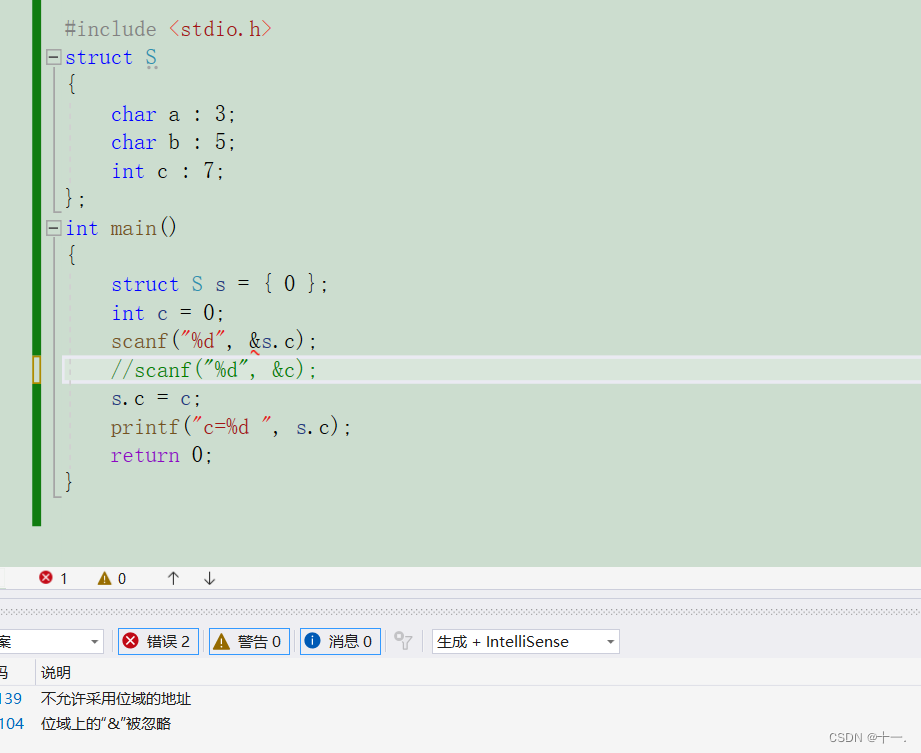
自定义类型:结构体 一:引入二:结构体类型的声明1:正常声明2:特殊声明 三:结构体变量的创建和初始化1:结构体变量的创建2:结构体变量的初始化 三:结构体访问操作符四:结构…...
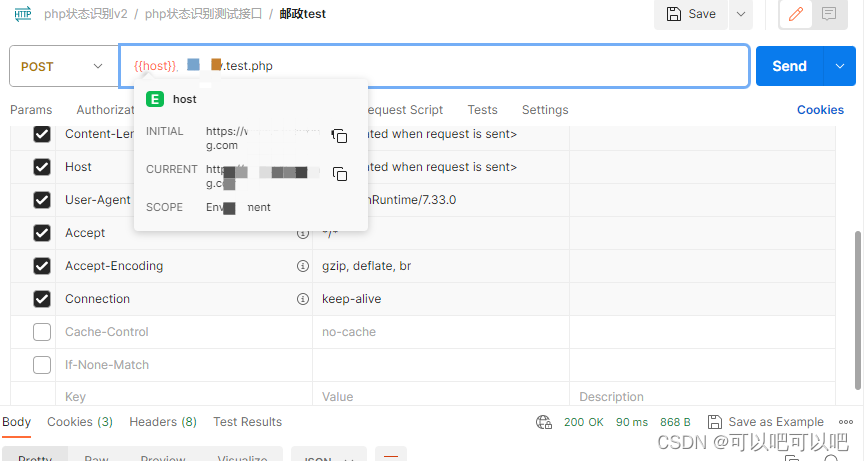
postman如何设置才能SwitchHosts切换host无缓存请求到指定ip服务
开发测试中,遇到多版本同域名的服务使用postman进行测试,一般会搭配SwitchHosts切换host类似工具进行请求,postman缓存比较重,如何做到无缓存请求呢,下面简单记录一下如何实现 首先要知道如何当前请求服务的ip是哪个 打开postman 依次点击/menu/view/show postman console 就…...

LeetCode LCR 103. 零钱兑换【完全背包,恰好装满背包的最小问题】中等
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

竞赛 基于深度学习的人脸专注度检测计算系统 - opencv python cnn
文章目录 1 前言2 相关技术2.1CNN简介2.2 人脸识别算法2.3专注检测原理2.4 OpenCV 3 功能介绍3.1人脸录入功能3.2 人脸识别3.3 人脸专注度检测3.4 识别记录 4 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的人脸专注度…...

supervisord 进程管理器 Laravel执行队列
supervisord 进程管理器 执行队列 安装 yum install supervisor修改配置文件 /etc/supervisord.conf 最后一行 ini改为conf files=/etc/supervisor.d/*.conf vim /etc/supervisord.conf/etc/supervisord.d目录下新增配置文件 vim laravel-worker.conf 修改i 粘贴内容 退出修…...

Lnmp架构之mysql数据库实战1
1、mysql数据库编译 编译成功 2、mysql数据库初始化 配置数据目录 全局文件修改内容 生成初始化密码并进行初始化设定 3、mysql主从复制 什么是mysql的主从复制? MySQL的主从复制是一种常见的数据库复制技术,用于将一个数据库服务器(称为主…...

ChatGLM 大模型炼丹手册-理论篇
序言一)大还丹的崛起 在修真界,人们一直渴望拥有一种神奇的「万能型丹药」,可包治百病。 但遗憾的是,在很长的一段时间里,炼丹师们只能对症炼药。每一枚丹药,都是特效药,专治一种病。这样就导致,每遇到一个新的问题,都需要针对性的炼制,炼丹师们苦不堪言,修真者们吐…...
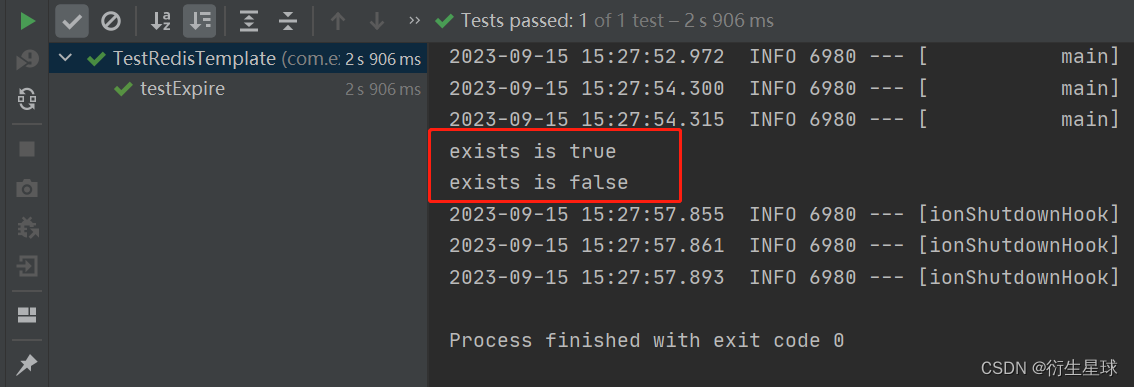
Spring Boot集成Redis实现数据缓存
🌿欢迎来到衍生星球的CSDN博文🌿 🍁本文主要学习Spring Boot集成Redis实现数据缓存 🍁 🌱我是衍生星球,一个从事集成开发的打工人🌱 ⭐️喜欢的朋友可以关注一下🫰🫰&…...
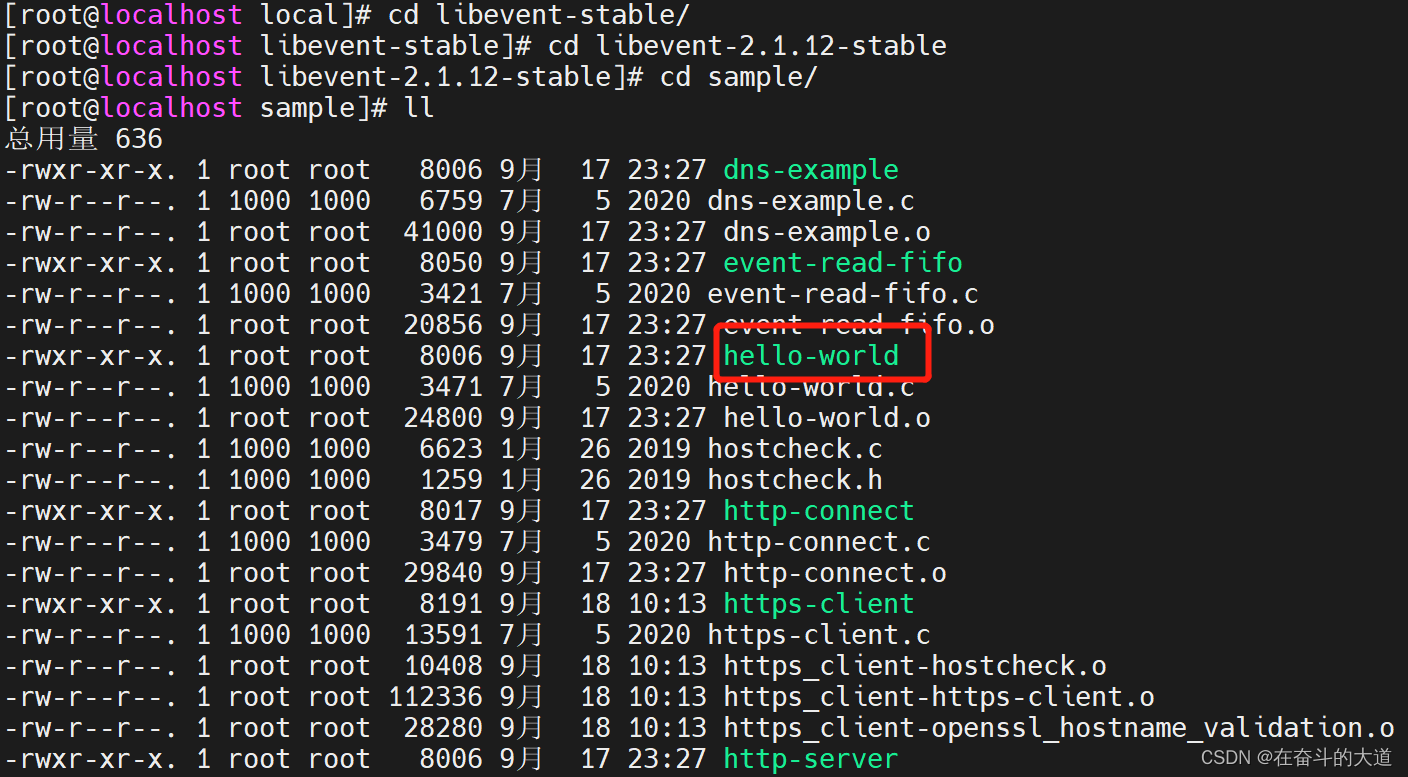
CentOS 7 安装Libevent
CentOS 7 安装Libevent 1.下载安装包 新版本是libevent-2.1.12-stable.tar.gz。(如果你的系统已经安装了libevent,可以不用安装) 官网:http://www.monkey.org/~provos/libevent/ 2.创建目录 # mkdir libevent-stable 3.解压 …...

线性代数的本质——几何角度理解
B站网课来自 3Blue1Brown的翻译版,看完醍醐灌顶,强烈推荐: 线性代数的本质 本课程从几何的角度翻译了线代中各种核心的概念及性质,对做题和练习效果有实质性的提高,下面博主来总结一下自己的理解 1.向量的本质 在物…...

SSH key 运作方式
1、本地创建SSH key pairs 2、把public key上传到网站服务器(如GitHub 3、当使用ssh方式连接时 本地SSH client向远端请求ssh连接远端发来random data要求加密本地ssh client用private key加密,把加密的data发送过去(不发送private key远端接…...

【基于MBD开发模式的matlab持续集成(一)】
基于MBD开发模式的matlab持续集成 引言 或许是感受到行业内卷的愈加激烈,在传统制造和高新技术相结合的新能源领域对软件工程开发的要求也愈加提高,尤其在互联网已经大行 其道的敏捷开发,便顺其自然的被新能源的老板们所看重。 概述 本文…...
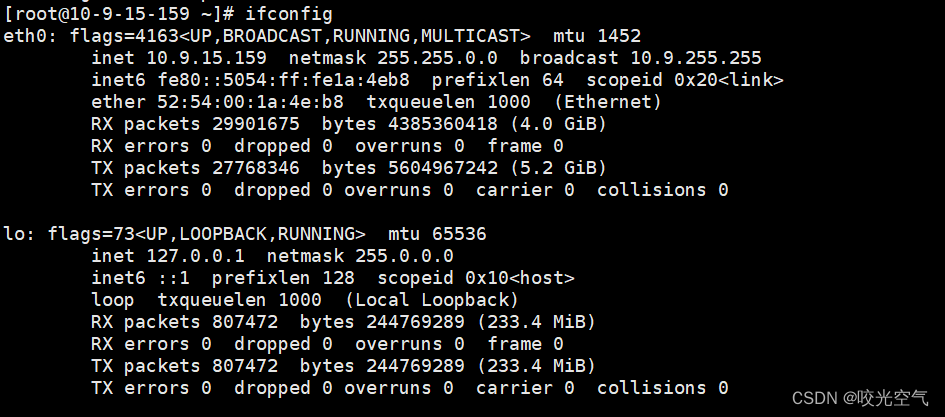
Linux学习记录——이십팔 网络基础(1)
文章目录 1、了解2、网络协议栈3、TCP/IP模型4、网络传输1、同一局域网(子网)2、局域网通信原理3、跨一个路由器的两个子网4、其它 详细的网络发展历史就不写了 1、了解 为什么会出现网络?一开始多个计算机之间想要共享文件,就得…...

CSS动效合集之实现气泡发散动画
前言 👏CSS动效合集之实现气泡发散动画,速速来Get吧~ 🥇文末分享源代码。记得点赞关注收藏! 1.实现效果 2.实现步骤 定义一个数组bubbles,用来存储气泡列表的基本新,w表示宽高,x表示绝对定位…...
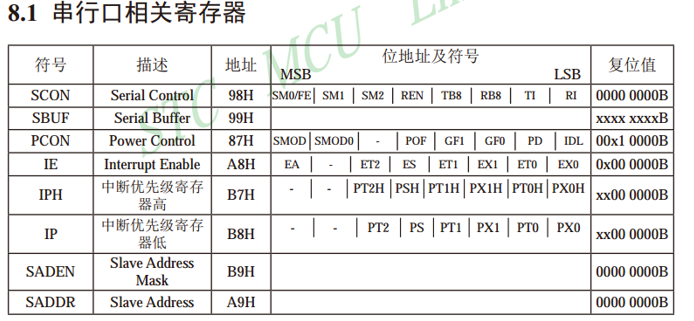
六、串口通信
六、串口通信 串口接口介绍使用串口向电脑发送数据电脑发送数据控制LED灯 串口接口介绍 SBUF是串口数据缓存器,物理上是两个独立的寄存器,但占用相同的地址。写操作时,写入的是发送寄存器;读操作时,读出的是接收寄存器…...

如何将 JavaScript Excel XLSX 查看器添加到Web应用程序
在 JavaScript 中创建 Excel 查看器可能是一项艰巨的任务,但使用 SpreadJS JavaScript 电子表格,创建过程要简单得多。在本教程博客中,我们将向您展示如何使用 SpreadJS 的强大功能来创建一个查看器,该查看器允许您在 Web 浏览器中…...

网安周报|CISA发布增强开源安全性的计划
1、CISA发布增强开源安全性的计划 美国一家领先的安全机构发布了一项期待已久的计划,详细说明了它将如何增强联邦政府和整个生态系统的开源安全性。美国网络安全和基础设施安全局(CISA)开源软件安全路线图在安全开源峰会上发布。据估计&#…...
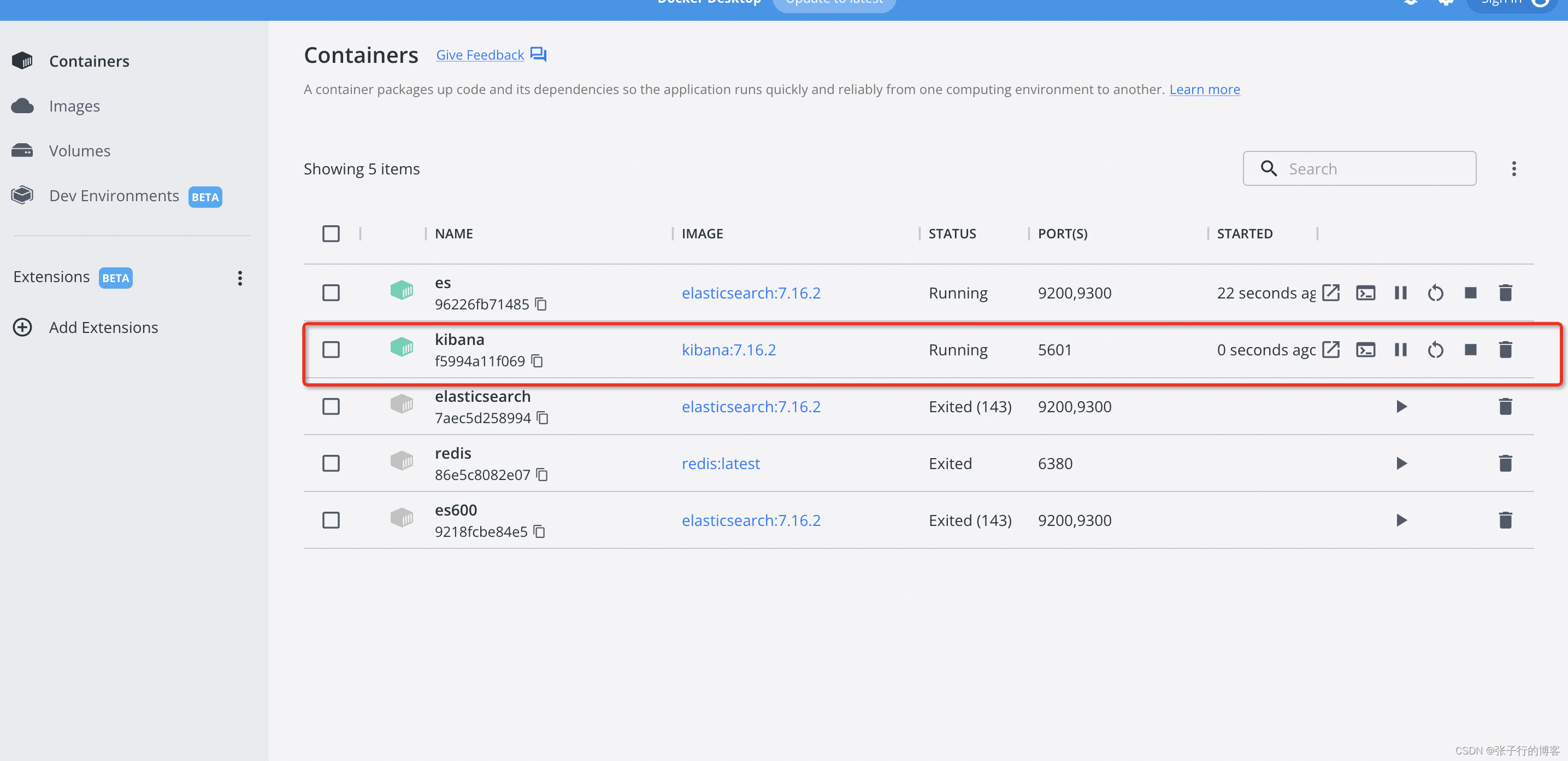
使用 Docker 安装 Elasticsearch (本地环境 M1 Mac)
Elasticsearchkibana下载安装 docker pull elasticsearch:7.16.2docker run --name es -d -e ES_JAVA_OPTS“-Xms512m -Xmx512m” -e “discovery.typesingle-node” -p 9200:9200 -p 9300:9300 elasticsearch:7.16.2docker pull kibana:7.16.2docker run --name kibana -e EL…...

Visual Studio中MD与MT的区别及运行库类型选择
MT与MD的区别 /MT:是multithread-static version,是多线程静态版本的意思,项目会使用运行时库的多线程静态版本,编译器会将LIBCMT.lib放入.obj文件中,以便链接器使用LIBCMT.lib解析外部符号;/MTdÿ…...

如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存
如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

OBS多平台直播终极指南:obs-multi-rtmp插件让你一键同步推流到各大平台
OBS多平台直播终极指南:obs-multi-rtmp插件让你一键同步推流到各大平台 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 还在为多平台直播的繁琐配置而烦恼吗?obs…...

别再用示波器死磕了!用Python+RC积分电路,5分钟搞定充放电曲线模拟与可视化
别再用示波器死磕了!用PythonRC积分电路,5分钟搞定充放电曲线模拟与可视化 在电子工程实践中,RC积分电路的充放电特性分析是基础中的基础。传统方法往往依赖示波器观测,不仅耗时耗力,还受限于硬件条件。今天ÿ…...

基于MCP协议与Playwright的AI智能体网页抓取工具部署与实战
1. 项目概述:一个为AI智能体打造的“网页抓取工具箱” 如果你正在开发或使用基于MCP(Model Context Protocol)的AI智能体,并且经常需要让它们从网页上获取结构化数据,那么你很可能已经遇到了一个核心痛点: …...

目标检测算法——史上最全遥感数据集汇总附下载链接【速速收藏】
🚀🚀🚀 近期,小海带在空闲之余收集整理了一批遥感检测数据集供大家参考。 整理不易,小伙伴们记得一键三连喔!!!🎈 🖥️ 专注开源数据集分享与深度学习科研思路…...
)
Java数据结构6(队列和二叉树初步)
目录1,队列的性质2,循环队列3,队列链式存储4,树的性质5,二叉树的遍历6,代码实现一,队列的性质同样是线性表,队列有线性表的相关操作,不过不同的是队列的性质为先进先出&a…...

量子门净化:突破2槽限制的3槽架构实现
1. 量子门净化:从理论到实践的关键突破量子计算领域面临的核心挑战之一是如何在噪声环境下保持量子门操作的精度。传统量子态净化技术虽然能提升静态量子资源的保真度,但对于动态执行的量子算法而言,我们需要更高阶的方法来直接处理操作本身的…...

AI推理延迟超标?资源利用率不足35%?SITS2026动态编排引擎实测压测报告:单节点吞吐提升4.8倍,,附YAML配置模板
更多请点击: https://intelliparadigm.com 第一章:AI原生应用部署方案:SITS2026 SITS2026(Scalable Intelligent Training & Serving 2026)是一套面向生产环境的AI原生应用部署框架,专为大模型微服务…...

CANN/asc-devkit向量最小值函数
asc_min 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

Ironclaw:基于Rust的现代化命令行工具集,重塑开发效率
1. 项目概述:一个面向开发者的现代化命令行工具集在当今的软件开发工作流中,命令行界面(CLI)依然是开发者与系统、服务交互的核心桥梁。无论是进行本地开发、自动化部署、系统运维还是数据处理,一个高效、可靠、符合直…...