数据结构 第二章作业 线性表 西安石油大学
在顺序表中插入和删除一个结点需平均移动多少个结点?具体的移动次数取决于 哪两个因素?
在顺序表中插入和删除一个结点时,平均移动的结点数量取决于两个因素:插入/删除位置和当前顺序表的长度。
-
插入/删除位置:如果要在顺序表的开头或末尾进行插入/删除操作,不需要移动其他结点,所以移动的结点数量较少。但是,如果要在顺序表的中间位置进行插入/删除操作,那么需要将该位置后面的所有结点向后/向前移动一个位置,移动的结点数量会更多。
-
当前顺序表的长度:随着顺序表长度的增加,插入和删除操作所需要移动的结点数量也会增加。因为随着顺序表的扩展,需要移动的结点数量与顺序表中数据的数量成正比。
在最坏情况下,在顺序表中插入或删除一个结点时,可能需要移动所有位于插入/删除位置之后的结点,所以移动的结点数量为n-m+1,其中n是顺序表的长度,m是插入/删除位置。
需要注意的是,这只是对平均情况的估计。在某些特殊情况下,可能会有特定的算法或优化技巧可以减少移动的结点数量。然而,由于顺序表的特性,插入和删除操作通常是较慢的,特别是在大型顺序表中进行频繁插入/删除操作时。如果需要高效地进行插入和删除操作,可以考虑使用其他数据结构,如链表。链表的插入和删除操作通常具有更好的性能,但在进行随机访问时相对较慢。

在线性表的链式存储结构中,说明头指针与头结点之间的根本区别,头结点与首元 结点的关系。
在线性表的链式存储结构中,头指针与头结点有着根本的区别,而头结点与首元结点之间存在特定的关系。
-
头指针(Head Pointer):头指针是指向链表的第一个结点的指针。它仅仅用于记录链表的起始位置,并不包含实际的数据。头指针可以为空(NULL),表示链表为空。
-
头结点(Head Node):头结点是为了方便链表操作而设置的一个空结点,位于头指针所指向的结点之前。头结点的作用有两个:
- 简化链表的插入和删除操作,在头结点之后进行操作,统一了对首元结点和其他结点的处理。
- 链表长度计算时,不计算头结点,使得链表为空时长度为0,非空时长度等于实际结点数。
-
首元结点(First Node):首元结点是链表中的第一个实际数据结点,也是头指针指向的结点。它包含了实际的数据和指向下一个结点的指针。
总结起来,头指针只是一个指向链表起始位置的指针,而头结点是为了方便操作而设置的一个空结点,不包含实际数据。首元结点是链表中第一个实际的数据结点,也是头指针所指向的结点。
在具体的链式存储结构中,可以根据需要选择是否使用头结点。使用头结点时,头指针指向头结点,首元结点即为头结点之后的第一个结点。不使用头结点时,头指针直接指向首元结点。
需要注意的是,在链式存储结构中,插入和删除操作通常需要操作前一个结点来修改指针的指向。而头结点的引入可以统一对待,使得处理链表的各种操作更加方便。

1.设计一个高效算法,将顺序表L的所有元素逆置,要求算法的空间复杂度为0(1)。 2.对长度为n的顺序表L,找出该顺序表中值最小的数据元素。 3.在带头结点的单链表L中,删除所有值为×的结点,并释放其空间,假设值为x 的结点不唯一,试编写算法实现上述操作。 4.设L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值。
- 将顺序表L逆置的高效算法如下:
def reverse_list(L):n = len(L)for i in range(n//2):L[i], L[n-i-1] = L[n-i-1], L[i]
时间复杂度为O(n),空间复杂度为O(1)。
- 找出长度为n的顺序表L中值最小的数据元素的算法如下:
def find_min(L):min_value = L[0]for i in range(1, len(L)):if L[i] < min_value:min_value = L[i]return min_value
时间复杂度为O(n)。
- 在带头结点的单链表L中删除所有值为x的结点,并释放其空间的算法如下:
def del_node(L, x):pre = Lcur = L.nextwhile cur != None:if cur.data == x:pre.next = cur.nextdel curcur = pre.nextelse:pre = curcur = cur.next
时间复杂度为O(n),空间复杂度为O(1)。
- 从头到尾输出带头结点单链表L中每个结点的值的算法如下:
def print_reverse(L):if L.next == None:returnprint_reverse(L.next)print(L.next.data)
时间复杂度为O(n),空间复杂度为O(n)(由于使用了递归)。如果要求空间复杂度为O(1),可以使用循环实现,如下:
def print_reverse(L):cur = L.nextpre = Nonewhile cur != None:next = cur.nextcur.next = prepre = curcur = nextwhile pre != None:print(pre.data)pre = pre.next
时间复杂度为O(n),空间复杂度为O(1)。1. 将顺序表L逆置的高效算法如下:
def reverse_list(L):n = len(L)for i in range(n//2):L[i], L[n-i-1] = L[n-i-1], L[i]
时间复杂度为O(n),空间复杂度为O(1)。
- 找出长度为n的顺序表L中值最小的数据元素的算法如下:
def find_min(L):min_value = L[0]for i in range(1, len(L)):if L[i] < min_value:min_value = L[i]return min_value
时间复杂度为O(n)。
- 在带头结点的单链表L中删除所有值为x的结点,并释放其空间的算法如下:
def del_node(L, x):pre = Lcur = L.nextwhile cur != None:if cur.data == x:pre.next = cur.nextdel curcur = pre.nextelse:pre = curcur = cur.next
时间复杂度为O(n),空间复杂度为O(1)。
- 从头到尾输出带头结点单链表L中每个结点的值的算法如下:
def print_reverse(L):if L.next == None:returnprint_reverse(L.next)print(L.next.data)
时间复杂度为O(n),空间复杂度为O(n)(由于使用了递归)。如果要求空间复杂度为O(1),可以使用循环实现,如下:
def print_reverse(L):cur = L.nextpre = Nonewhile cur != None:next = cur.nextcur.next = prepre = curcur = nextwhile pre != None:print(pre.data)pre = pre.next
时间复杂度为O(n),空间复杂度为O(1)。
介绍一下线性表
线性表是一种常见的数据结构,它是由一组按照顺序排列的元素组成的数据集合。线性表中的每个元素都有一个唯一的前驱元素和一个唯一的后继元素,除了第一个元素没有前驱元素,最后一个元素没有后继元素。
线性表的特点是:
- 元素之间的顺序是确定的,元素之间的关系是一对一的。
- 可以通过下标或位置来访问线性表中的元素。
- 线性表的长度可以是固定的也可以是可变的。
常见的线性表有两种实现方式:顺序表和链表。
-
顺序表:顺序表是使用一段连续的内存空间存储线性表中的元素。在顺序表中,元素在内存中的物理地址是按照其逻辑顺序依次排列的。通过元素的索引值可以直接访问到元素。插入和删除操作需要移动其他元素,时间复杂度为O(n),但读取元素的时间复杂度为O(1)。
-
链表:链表是使用一组节点(node)通过指针相互连接而成的数据结构。每个节点包含一个数据元素和指向下一个节点的指针。链表中的元素在内存中的存储位置可以是不连续的。链表的插入和删除操作只需要修改指针的指向,时间复杂度为O(1),但访问元素需要从头节点开始逐个遍历,时间复杂度为O(n)。
线性表广泛应用于各种领域,例如数组、链表、栈、队列等数据结构都是线性表的具体实现。在算法和数据结构中,线性表是最基本、最简单、也是最常用的数据结构之一。
除了顺序表和链表之外,还有其他一些常见的线性表实现方式,如下所述:
-
双向链表:双向链表在链表的基础上增加了一个指向前驱节点的指针,使得可以从任意一个节点开始往前或往后遍历。这样可以方便地进行插入、删除等操作,但相应地会增加一些额外的空间开销。
-
循环链表:循环链表是一种特殊的链表,它的尾节点指向头节点,形成一个闭环。这样可以通过任意一个节点遍历整个链表,并且可以很方便地进行插入、删除操作。
线性表的主要操作包括:
- 插入:在指定位置插入一个元素,需将该位置及其后面的元素后移。
- 删除:删除指定位置的元素,需将该位置后面的元素前移。
- 查找:根据元素值或索引查找对应的元素。
- 修改:修改指定位置的元素值。
- 遍历:依次访问线性表中的所有元素。
线性表的应用场景很广泛,例如:
- 数组:用于存储和操作一组相同类型的数据元素。
- 队列:用于实现先进先出(FIFO)的数据结构,比如任务调度、消息传递等。
- 栈:用于实现后进先出(LIFO)的数据结构,比如函数调用栈、表达式求值等。
- 哈希表:使用数组和链表实现的数据结构,用于高效地存储和查找键值对。
- 字符串:可以将字符串看作是由字符组成的线性表。
线性表作为一种简单且常见的数据结构,为我们解决各种实际问题提供了便利和基础。在实际应用中,选择适合的线性表实现方式能够提高算法的效率和代码的可维护性。
当涉及到线性表的操作时,还有一些常见的算法和技巧可以提高效率和解决特定问题:
-
线性表的合并:当需要将两个线性表进行合并时,可以利用顺序表的特性,在时间复杂度为O(m+n)的情况下,将一个线性表的元素逐个复制到另一个线性表的末尾。
-
反转线性表:可以通过遍历线性表,依次将元素从原位置移动到新位置,实现线性表的反转。这个操作的时间复杂度为O(n),其中n是线性表的长度。
-
快慢指针:在链表中,可以使用快慢指针技巧解决一些问题。快指针每次移动两步,慢指针每次移动一步,通过比较快慢指针的位置,可以判断链表是否存在环或者找到链表的中间节点。
-
双指针法:双指针法是指使用两个指针在线性表中同时进行遍历、查找或处理。常见的应用有快慢指针、左右指针等。例如,在查找一个有序数组中是否存在目标元素时,可以使用两个指针从数组的头尾同时进行遍历,根据比较结果移动指针,从而提高查找效率。
-
环形缓冲区:环形缓冲区是一种特殊的线性表实现,可以循环使用固定大小的缓冲区。通过维护一个读指针和写指针,可以实现高效的数据插入和删除操作。环形缓冲区广泛应用于数据流处理、循环队列等场景。
以上是一些常见的线性表操作算法和技巧,它们可以根据具体问题的需求选择合适的方法。在实际应用中,结合具体情况选择适当的数据结构和算法,可以提高程序的效率和性能。
当涉及线性表的应用时,还有一些常见的问题和算法可以考虑:
-
查找最大值和最小值:遍历线性表并记录当前最大值和最小值,即可找到线性表中的最大元素和最小元素。时间复杂度为O(n)。
-
线性表的排序:常见的排序算法如冒泡排序、插入排序、选择排序、快速排序、归并排序等都可以应用于线性表的排序操作。根据具体需求和数据规模选择合适的排序算法。
-
线性表的去重:如果线性表中存在重复元素,可以使用哈希表或排序的方式进行去重操作。使用哈希表可以将元素存储在哈希表中,判断是否已经出现过;使用排序可以通过遍历删除重复元素。
-
子串匹配:对于字符串类型的线性表,可以使用KMP算法、Boyer-Moore算法等进行高效的子串匹配操作。
-
线性表的倒置:将线性表中的元素逆序排列,可以使用双指针法或栈来实现。
-
线性表的切片:从线性表中截取一段连续的元素组成新的线性表。可以使用截取操作符或者在链表中使用快慢指针来实现。
-
线性表的拼接:将两个线性表连接起来形成一个新的线性表。可以在顺序表中直接将第二个线性表的元素逐个复制到第一个线性表的末尾,或者在链表中将第一个链表的尾节点指向第二个链表的头节点。
以上是一些常见的线性表应用问题和算法。根据具体需求和场景选择合适的算法和数据结构,可以解决各种实际问题。
当涉及线性表的应用时,还有一些常见的算法和技巧可以考虑:
-
子数组和的问题:给定一个整数数组,要求找到和最大的子数组。可以使用动态规划算法或者贪心算法来解决该问题。
-
求解两个有序数组的中位数:给定两个有序数组,要求找到两个数组合并后的中位数。可以使用归并排序的思想,在合并的过程中找到中位数。
-
线性表的旋转:将线性表中的元素按照指定的步长进行循环右移或左移操作。可以使用数组翻转的思路实现。
-
线性表的交集与并集:给定两个线性表,求它们的交集和并集。可以使用哈希表来记录元素的出现次数,然后根据需求得到交集和并集。
-
最长递增子序列:给定一个序列,要求找到其中的一个最长递增子序列。可以使用动态规划算法来解决该问题。
-
环检测:判断一个链表是否存在环。可以使用快慢指针来判断,如果存在环,则快指针最终会追上慢指针。
-
求解字符串编辑距离:给定两个字符串,要求通过插入、删除和替换操作将一个字符串转换为另一个字符串,求解最小的操作次数。可以使用动态规划算法来解决该问题。
以上是一些常见的线性表应用的算法和技巧。这些算法和技巧在解决实际问题时非常有用,可以根据具体的需求选择合适的方法。同时,不同的问题可能需要结合多种算法和技巧来解决,灵活运用可以提高效率和解决问题的准确性。
线性表应用举例
线性表是计算机科学中最基本的数据结构之一,在实际应用中有很多不同的场景和问题可以使用线性表来解决。下面是一些常见的线性表应用举例:
-
路径规划:在地图应用中,路径规划是一种常见的使用线性表的场景。可以将地图上的路网转换成一个图,然后使用图的遍历算法(如广度优先搜索、Dijkstra算法等)来找到两个地点之间的最短路径。
-
排序和查找:对于大量数据的排序和查找操作,可以使用线性表来实现。例如,快速排序算法和归并排序算法都可以应用于顺序表的排序操作,而二分查找算法可以应用于有序顺序表的查找操作。
-
缓存管理:在计算机系统中,缓存管理是一种重要的问题。可以使用线性表来实现缓存队列的管理,从而提高访问效率。
-
字符串处理:字符串操作是计算机应用中非常常见的问题。例如,在文本编辑器中,可以使用线性表存储文本内容,并使用字符串匹配算法来查找和替换文本中的特定字符或词汇。
-
电商推荐系统:在电商平台中,推荐系统是一种关键功能。可以使用线性表来存储用户的浏览历史和购买历史,并根据用户的兴趣爱好和行为数据推荐相应的商品。
-
游戏开发:在游戏开发中,角色属性、物品背包等信息可以使用线性表来存储和管理。例如,在角色升级时需要修改角色的经验值、等级、生命值等属性,这些属性可以存储在线性表中。
以上是一些常见的线性表应用举例。由于线性表具有简单易懂、易实现等特点,因此在实际应用中非常广泛,并衍生出许多相关的算法和技术。

以下是使用C语言实现线性表应用的代码示例:
- 动态数组实现线性表:
#include <stdio.h>
#include <stdlib.h>typedef struct {int* data;int length;int capacity;
} ArrayList;ArrayList* createArrayList(int capacity) {ArrayList* list = (ArrayList*)malloc(sizeof(ArrayList));list->data = (int*)malloc(sizeof(int) * capacity);list->length = 0;list->capacity = capacity;return list;
}void destroyArrayList(ArrayList* list) {free(list->data);free(list);
}void addElement(ArrayList* list, int element) {if (list->length >= list->capacity) {// 超出容量时,扩展动态数组int newCapacity = list->capacity * 2;list->data = (int*)realloc(list->data, sizeof(int) * newCapacity);list->capacity = newCapacity;}list->data[list->length] = element;list->length++;
}int getElement(ArrayList* list, int index) {if (index >= 0 && index < list->length) {return list->data[index];}return -1; // 返回-1表示索引越界或数据不存在
}void printArrayList(ArrayList* list) {for (int i = 0; i < list->length; i++) {printf("%d ", list->data[i]);}printf("\n");
}int main() {ArrayList* list = createArrayList(5);addElement(list, 1);addElement(list, 2);addElement(list, 3);addElement(list, 4);addElement(list, 5);printf("Elements in the list: ");printArrayList(list);int element = getElement(list, 2);printf("Element at index 2: %d\n", element);destroyArrayList(list);return 0;
}
- 单链表实现线性表:
#include <stdio.h>
#include <stdlib.h>typedef struct Node {int data;struct Node* next;
} Node;typedef struct {Node* head;int length;
} LinkedList;LinkedList* createLinkedList() {LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));list->head = NULL;list->length = 0;return list;
}void destroyLinkedList(LinkedList* list) {Node* current = list->head;while (current != NULL) {Node* temp = current->next;free(current);current = temp;}free(list);
}void addElement(LinkedList* list, int element) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->data = element;newNode->next = NULL;if (list->head == NULL) {list->head = newNode;} else {Node* current = list->head;while (current->next != NULL) {current = current->next;}current->next = newNode;}list->length++;
}int getElement(LinkedList* list, int index) {if (index >= 0 && index < list->length) {Node* current = list->head;for (int i = 0; i < index; i++) {current = current->next;}return current->data;}return -1; // 返回-1表示索引越界或数据不存在
}void printLinkedList(LinkedList* list) {Node* current = list->head;while (current != NULL) {printf("%d ", current->data);current = current->next;}printf("\n");
}int main() {LinkedList* list = createLinkedList();addElement(list, 1);addElement(list, 2);addElement(list, 3);addElement(list, 4);addElement(list, 5);printf("Elements in the list: ");printLinkedList(list);int element = getElement(list, 2);printf("Element at index 2: %d\n", element);destroyLinkedList(list);return 0;
}
以上是使用C语言实现线性表应用的代码示例。这些示例演示了基于动态数组和单链表两种不同数据结构的线性表实现,请根据需要选择适合的实现方式。在实际使用中,记得释放内存,并考虑边界条件和异常处理等情况。
相关文章:
数据结构 第二章作业 线性表 西安石油大学
在顺序表中插入和删除一个结点需平均移动多少个结点?具体的移动次数取决于 哪两个因素? 在顺序表中插入和删除一个结点时,平均移动的结点数量取决于两个因素:插入/删除位置和当前顺序表的长度。 插入/删除位置:如果要…...

vue.mixin全局混合选项
在Vue.js中,Vue.mixin 是一个用来全局混合(mixin)选项的方法。它允许你在多个组件中共享相同的选项,例如数据、方法、生命周期钩子等。这可以用来在组件之间重复使用一些逻辑或共享一些通用的功能 Vue.mixin({// 在这里定义混合的选项data() {return {s…...
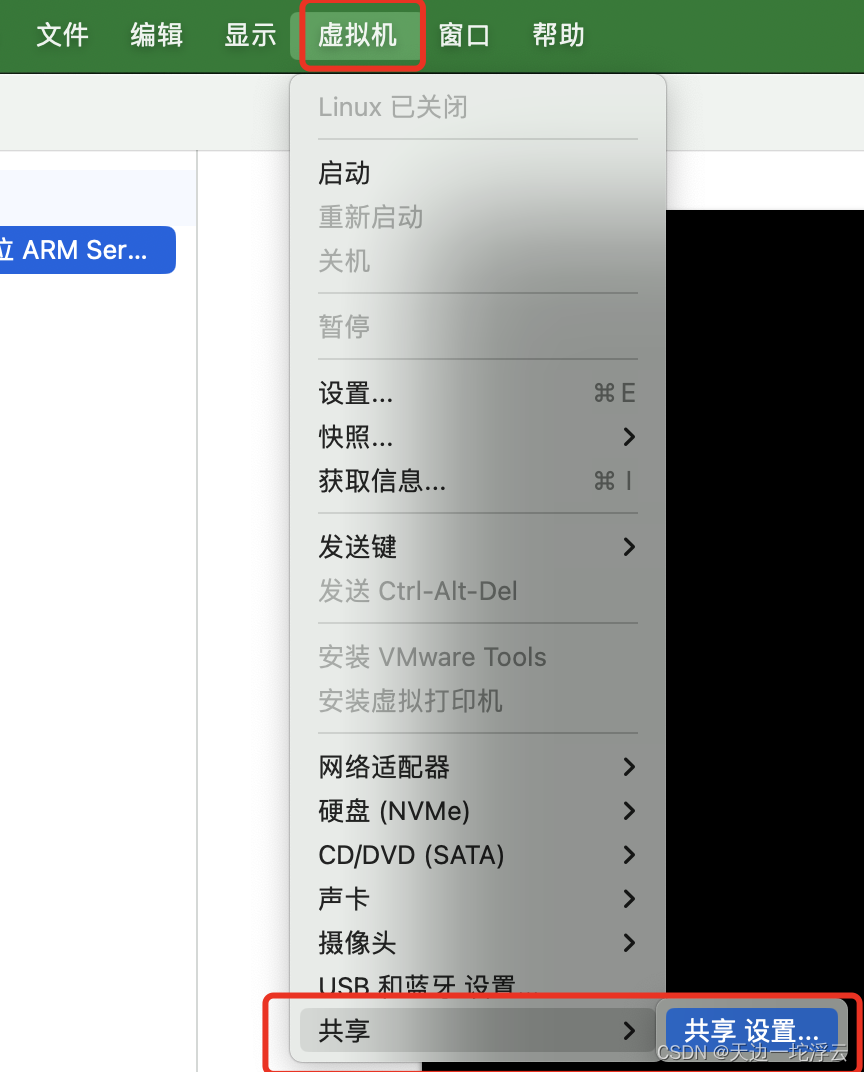
VMware Fusion 13+Ubuntu ARM Server 22.04.3在M2芯片的Mac上共享文件夹
因为Server版没有桌面,VMware Tools不能直接装,导致没办法共享文件。 Ubuntu中的包如果需要更新,先执行下面的步骤 sudo apt update 再执行 sudo apt upgrade 不需要更新的话,直接执行下面的步骤 先把open-vm-tools卸载了 …...

PostgreSQL serial类型
serial类型和序列 postgresql序列号(SERIAL)类型包括 smallserial(smallint,short),serial(int)bigserial(bigint,long long int) 不管是smallserial,serial还是bigserial,其范围都是(1,9223372036854775807)&#…...

[创业之路-76] - 创业公司如何在长期坚持中顺势而为?诚迈科技参观交流有感
目录 一、创业环境 1.1. VUCA乌卡时代:易变、复杂、不确定性、模糊的时代 1.2. 中国用了四十年的时间完成了三次工业革命:机械化、电气化、数字化 1.3. 中国正在经历着第四次工业革命:智能化、生态化、拟人化 1.4 国产替代:国…...

人脸修复祛马赛克算法CodeFormer——C++与Python模型部署
一、人脸修复算法 1.算法简介 CodeFormer是一种基于AI技术深度学习的人脸复原模型,由南洋理工大学和商汤科技联合研究中心联合开发,它能够接收模糊或马赛克图像作为输入,并生成更清晰的原始图像。算法源码地址:https://github.c…...

linux入门到精通-第三章-vi(vim)编辑器
目录 文本编辑器gedit介绍vi(vim)命令模式命令模式编辑模式末行模式 帮助教程保存文件切换到编辑模式光标移动(命令模式下)复制粘贴删除撤销恢复保存退出查找替换可视模式替换模式分屏其他用法配置文件 文本编辑器 gedit介绍 gedit是一个GNOME桌面环境下兼容UTF-8的文本编辑器…...
)
Mybatis面试题(三)
文章目录 前言一、Xml 映射文件中,除了常见的 select|insert|updae|delete 标签之外,还有哪些标签?二、当实体类中的属性名和表中的字段名不一样,如果将查询的结果封装到指定 pojo?三、模糊查询 like 语句该怎么写四、…...
Qt扩展-KDDockWidgets 简介及配置
Qt扩展-KDDockWidgets 简介及配置] 一、概述二、编译 KDDockWidgets 库1. Cmake Gui 中选择源文件和编译后的路径2. 点击Config,配置好编译器3. 点击Generate4. 在存放编译的文件夹输入如下命令开始编译 三、qmake 配置 一、概述 kdockwidgets是一个由KDAB组织编写…...

Vue3搭配Element Plus 实现候选搜索框效果
直接上代码 <el-col :span"14" class"ipt-col"><el-input v-model"projectName" class"w-50 m-2" input"inputChange" focus"inputFocusFn" blur"inputBlurFn" placeholder"请输入项目名…...

进程间的通信方式
文章目录 1.简单介绍2.管道2.1管道的基础概念**管道读写规则**:**管道特点** 2.2匿名管道匿名管道父子进程间通信的经典案例: 2.3命名管道基本概念:命名管道的创建:命名管道的打开规则:匿名管道与普通管道的区别**例子:用命名管道…...

分类预测 | Matlab实现基于MIC-BP-Adaboost最大互信息系数数据特征选择算法结合Adaboost-BP神经网络的数据分类预测
分类预测 | Matlab实现基于MIC-BP-Adaboost最大互信息系数数据特征选择算法结合Adaboost-BP神经网络的数据分类预测 目录 分类预测 | Matlab实现基于MIC-BP-Adaboost最大互信息系数数据特征选择算法结合Adaboost-BP神经网络的数据分类预测效果一览基本介绍研究内容程序设计参考…...

phpcms v9对联广告关闭左侧广告
修改目录“\caches\poster_js”下的文件“53.js”,修改函数“showADContent()” 将代码: str "<div idPCMSAD_"this.PosID"_"i" style"align_b":"x"px;top:"y"px;width:"this.Width&…...

7.2.4 【MySQL】匹配范围值
回头看我们 idx_name_birthday_phone_number 索引的 B 树示意图,所有记录都是按照索引列的值从小到大的顺序排好序的,所以这极大的方便我们查找索引列的值在某个范围内的记录。比方说下边这个查询语句: SELECT * FROM person_info WHERE nam…...
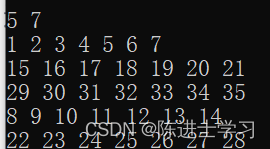
1400*C. No Prime Differences(找规律数学)
解析: 由于 1 不是质数,所以我们令每一行的数都相差 1 对于行间,分为 n、m之中有存在偶数和都为奇数两种情况。 如果n、m存在偶数,假设m为偶数。 如果都为奇数,则: #include<bits/stdc.h> using name…...

Python基础之装饰器
文章目录 1 装饰器1.1 定义1.2 使用示例1.2.1 使用类中实例装饰器1.2.2 使用类方法装饰器1.2.3 使用类中静态装饰器1.2.4 使用类中普通装饰器 1.3 内部装饰器1.3.1 property 2 常用装饰器2.1 timer:测量执行时间2.2 memoize:缓存结果2.3 validate_input:数据验证2.4 log_result…...
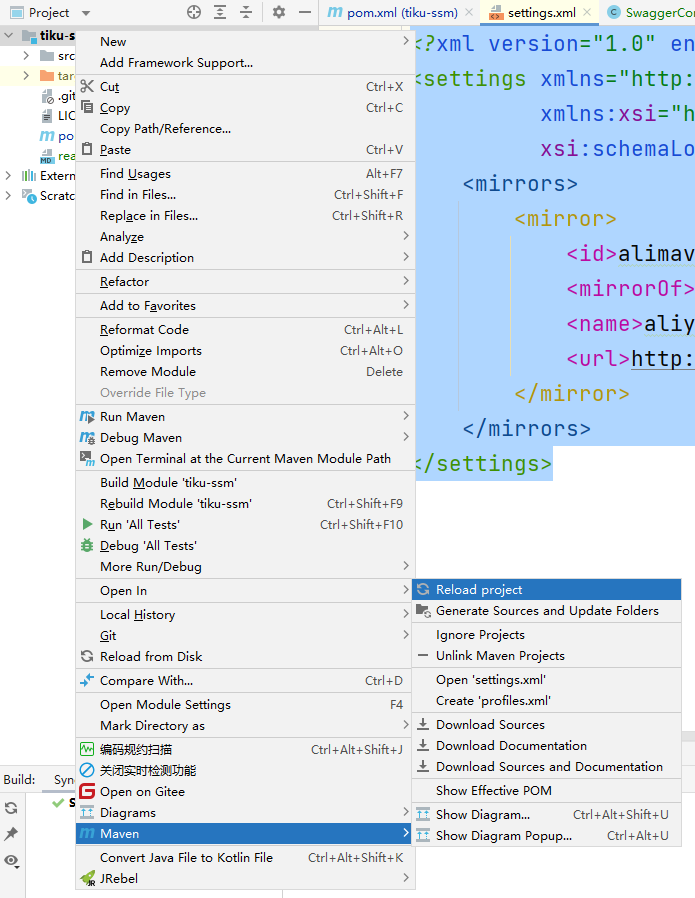
IDEA设置Maven 镜像
第一步:右键项目,选择Maven->Create ‘settings.xml’ 已经存在的话是Open ‘settings.xml’: 第二步:在settings.xml文件中增加阿里云镜像地址,代码如下: <?xml version"1.0" encodin…...

项目评定等级L1、L2、L3、L4
软件项目评定等级的数量可以因不同的评定体系和标准而异。一般情况下,项目评定等级通常按照项目的规模、复杂性和风险等因素来划分,可以有多个等级,常见的包括: L1(Level 1):通常表示较小规模、…...
一个基于SpringBoot+Vue前后端分离学生宿舍管理系统详细设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
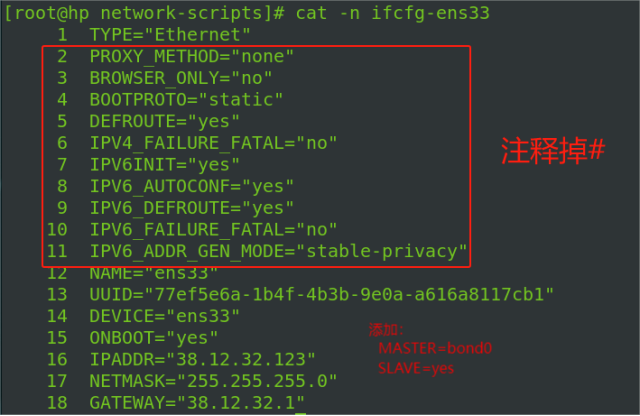
工作相关----《配置bond》
进入到/etc/sysconfig/network-scripts,按照要求配置主备关系 vim ifcfg-bond0,编写主要内容如下: /*mode1 表示主备份策略,miimon100 系统每100毫秒监测一次链路连接状态, 如果有一条线路不通就转入另一条线路*/ BOND…...

多目标粒子群混合储能优化配置【附算法】
✨ 长期致力于混合储能、优化配置、风光互补微电网、多目标粒子群算法、CRITIC-TOPSIS研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)风光-负荷多场景…...

终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器
终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Etcher(BalenaEtcher&am…...

大模型提示词驱动的工业图像标注流水线实战
1. 这不是“打标签”,而是让大模型替你做标注决策的整套工作流“Prompt-Based Automated Data Labeling and Annotation”——光看这个标题,很多人第一反应是:“哦,用大模型自动打标签”。但干过三年以上NLP数据工程、带过两个以上…...

AI如何重塑科学创新:从构思成本坍塌到知识组合爆炸
1. 科学创新的范式转移:从“不确定性”到“风险”在过去的科研实践中,我们常常面临一个根本性的困境:不确定性。这并非指我们不知道某个实验的结果,而是指我们连可能的结果是什么、其发生的概率有多大,都无从知晓。这就…...

Cursor Pro激活器:终极解决方案告别API限制,实现无限免费使用
Cursor Pro激活器:终极解决方案告别API限制,实现无限免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

VisualCppRedist AIO 深度解析:从MSI自动化处理到系统注册表管理的完整解决方案
VisualCppRedist AIO 深度解析:从MSI自动化处理到系统注册表管理的完整解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 在Windows系统开发和…...

从CANdb++到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换
从CANdb到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换 在汽车电子和嵌入式系统开发中,DBC文件作为CAN总线通信的"字典",承载着整车网络通信的核心协议。对于刚接触汽车网络通信的工程师来说,面对DBC文件中密…...

Antigravity AI 助手“装死”?一招解决 Git 配置引发的无响应崩溃
我们在使用 Antigravity AI IDE 进行开发时,有时会遇到一个令人头疼的现象:在对话框输入任何 Prompt 后,AI 助手仿佛“装死”一般毫无反应。没有生成提示,也没有错误弹窗,即使重启 IDE 或清理对话历史也无济于事。这不…...

Perplexity学术模式到底有多“实时”?我们用NIST标准测试集连续监控72小时,结果让3所常春藤图书馆紧急更新采购清单…
更多请点击: https://intelliparadigm.com 第一章:Perplexity学术模式到底有多“实时”?我们用NIST标准测试集连续监控72小时,结果让3所常春藤图书馆紧急更新采购清单… 实时性验证方法论 我们采用 NIST TREC 2023 Dynamic Filt…...

3个维度重新定义Cursor使用体验:如何突破免费试用限制
3个维度重新定义Cursor使用体验:如何突破免费试用限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...