大数据-Spark-Spark开发高频面试题
一、spark的内存分布
堆内内存:在这使用堆内内存的时候,如果我们设置了堆内内存2个g的话,读取的数据也是两个g,此时又来两个g的数据,这样就会产生OOM溢出,因为处理完两个g的数据,并不会马上进行GC。
堆外内存:这样我们就可以使用堆外内存,也就是物理内存,堆外内存可以精准的申请和释放空间,不需要Gc,性能比较高,提升了任务的效率。
二、Spark的宽窄依赖
宽依赖:一个父RDD分区中的数据划分到多个子RDD分区的过程,也就说明有shuffle的过程。如GroupByKey,reduceByKey,join,sortByKey等。
窄依赖:一个父RDD分区中的数据被一个子RDD分区所使用,map,filter。
三、Spark中reduceByKey和groupByKey的区别
reduceByKey:按照key进行聚合,在shuffle之前有个combine预聚合的操作,返回的结果是RDD(K,V)
groupByKEy:直接按照key进行进行分组,直接进行shuffle
建议使用reduceByKey 但注意是否会影响最终的业务逻辑
四、Spark的缓存
将频繁使用的RDD进行缓存到内存中,后面RDD用到的时候去内存中区就不需要重复了,提高任务的执行效率
cache时间数据保存在内存中
程序结束后会被清除或手动调用unpersist方法清除
会记录RDD的血缘关系
五、什么是RDD
一个弹性分布式的数据集
数据可以保存在内存中也可以保存在磁盘中
他是一个分布式的计算的集合
RDD有3个特征分区、不可变、并行操作
RDD是有好多分区组成的,操作RDD的时候,对RDD里的每个分区进行操作
RDD使用算子进行操作
算子分为转换算子与行动算子
六、Spark落盘场景
在shuffle中会进行落盘的操作
shuffle分为shuffle write和shuffle read
在这期间会进行一次落盘操作
七、Spark的shffle
Spark使用涉及到一些shuffle算子的时候就会进行shuffle
shuffle的过程:
八、Spark内存OOM的情况
1. map过程中产生大量对象导致内存溢出
2. 数据不平衡导致内存溢出
3. coalesce调用导致内存溢出
4. shuffle后内存溢出
5. standalone模式下资源分配不均匀导致内存溢出
6. 在RDD中,公用对象能减少OOM的情况
九、怎样避免SparkOOM
1. 使用mapPartition代替部分map操作,或者连续使用map的操作
2. broadcast join和普通join
3. 先filter在join
4. partitionBy优化
5. combineDyKey的使用
6. 参数优化
十、Spark shuffle的默认并行度
由spark.sql.shuffle.partitions决定默认并行度为200,数据量比较的是并且集群性能可以的时候也已适当的加大
十一、Coalesce和Repartition的区别
Coalesce和Repartition两个都是用来改变分区的,Coalesce用来缩减分区但不会进行shuffle,Repartition用来增加分区会进行shuffle的操作,在spark中减少文件个数会使用coalesce来减少分区,但如果分区量过大,分区数过少就会出现OOM,所以coalesce缩小分区个数也需合理。
十二、如何使用spark实现TopN的操作
方法一:(1)按照key对数据进行聚合(reduceByKey)(2)将value转换为数组,利用scala中sortBy或者sortWith进行排序(mapValues)数据量太大,会OOM。
方法二:(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区中(2)对每个分区运用spark的排序算子进行排序
十三、spark中的共享变量
累加器是spark中提供的一种分布式变量机制,其原理类似与mapreduce先分后合,累加器的一个常用用途在对作业执行中的事件进行计数。而广播变量用来搞笑分发较大的对象。
十四、Coalesce和Repartition的关系与区别
关系:都是用来修改RDD的partition数量的,repartiotion底层调用的就是coalesce()方法coalesce(numPaitition,shuffle=true)
区别:repartiotion一定会发生shuffle,coalesce根据传入的参数来判断是否会发生shuffle一般情况下增大rdd的partition的数量使用repartition,减少partition数量使用coalesce
十五、Spark的调优
遵循几个原则
原则一:避免重复使用的RDD
原则二:尽可能复用一个RDD
原则三:对多次使用的RDD进行持久化
原则四:尽量避免使用shuffle类的算子
原则五:使用map-side预聚合的shuffle操作
原则六:使用高性能的算子
原则七:广播大变量
原则八:使用Kryo优化序列化性能
原则九;优化数据结构
十六、Spark中RDD与DataFream及DataSet之间的关系
宏观:RDD:弹性分布式数据集Datafream在RDD上多了一层schemaDataset在datafream之上多了一个数据结构
微观:RDD:优点 编译时:编译时可以检查类型是否安全面向对象的风格:可以通过直接点方法对数据进行操作缺点 序列化与反序列化消耗资源太大,反序列化时会将数据结构与数据内容都序列化GC操作频繁,RDD要频繁的创建和销毁,务必会产生很多的GC操作Datafream:在RDD之上引入一层schema与off-head多个RDD每行的数据结构都一致,spark就可以通过schema来识别数据结构在反序列化的时候可以只反序列化数据而结构就可以省略掉了Dataset:综合了RDD与Datafream的优点,并引入encoding数据再进行序列化时ancoding出来的字节码和off-head互通,这样就可以按需读取数据
三者之间的转换:rdd - df = toDFrdd - ds = toDSdf - ds = as[]ds - df = toDFds - rdd = RDDdf - rdd = RDD
十七、简述介绍sparkStreaming窗口函数的原理
窗口函数就是在原来定义的sparkStreaming计算批次大小的基础上在进行封转,每次计算多个批次的数据,同时还需要传递一个滑动步长的参数,用来设置当前任务完成之后下次从什么地方开始计算。
十八、SparkStreaming精准一次消费
1. 手动维护偏移量
2. 处理完业务数据后,在进行提交偏移量的操作
极端条件下,如果在提交偏移量断网或停电会造成spark程序第二次启动时重复消费问题,所以在涉及到金额或精确度非常高的场景会使用事务保持精准一次消费。
相关文章:

大数据-Spark-Spark开发高频面试题
一、spark的内存分布 堆内内存:在这使用堆内内存的时候,如果我们设置了堆内内存2个g的话,读取的数据也是两个g,此时又来两个g的数据,这样就会产生OOM溢出,因为处理完两个g的数据,并不会马上进行…...

云原生容器平台——新华资产数字化转型加速器
新华资产管理股份有限公司(以下简称“新华资产”)于2006年5月经中国保险监督管理委员会批准、7月3日正式挂牌成立,是国内首批专业保险资产管理机构。2020年上半年,公司管理的资产规模突破万亿元人民币,投资收益水平居行…...
ubuntu 22.04运行opencv4的c++程序遇到的问题
摘要:本文介绍一下在ubuntu系统中,运行一个最简单的opencv4程序都出问题的解决方法,并对其基本原理作简单阐述。解决问题的方法有很多,本文只提供其中一种。 opencv版本是4.2.0,ubuntu版本是20.04 查询opencv版本的指…...

MDPI模板报错的问题---提示缺少sty文件
MDPI模板报错的问题—提示缺少sty文件 平时大多数提交IEEE trans模板时大多使用CTEX编译,然而,MDPI模板需要用texlive,二者之间如果先安装CTEX后安装texlive将会导致库文件的冲突。结果将会报缺少sty的文件错。网上提供了很多解决方案&#…...

【教程】微信小程序导入外部字体详细流程
前言 在微信小程序中,我们在wxss文件中通过font-family这一CSS属性来设置文本的字体,并且微信小程序有自身支持的内置字体,可以通过代码提示查看微信小程序支持字体: 这些字体具体是什么样式可以参考: 微信小程序--字…...
关于Kali部署OneForAll,不能运行问题
问题描述 运行OneForAll后,出现了如下报错 问题: importterror:无法从’re’导入名称’sre_parse’ (/usr/lib/python3.11/re/init.py) Traceback (most recent call last):File "/home/kali/桌面/App/OneForAll/oneforall.py", line 16, in…...

vue3中使用el-upload + tui-image-editor进行图片处理
效果如下 看之前请先看上一篇《vue3中使用组件tui-image-editor进行图片处理》中的 1、第一步安装 2、第二部封装组件 本篇只是在这基础上结合el-upload使用组件 3、第三步结合el-upload使用组件 <template><el-dialog:title"dialogTitle":modelValue&qu…...
二叉树顺序结构及实现
👉二叉树顺序结构及实现 1.二叉树的顺序结构2.堆的概念及结构3.堆的实现3.1堆向下调整算法3.2堆向上调整算法 4.堆的创建4.1堆创建方法14.1.1构建堆结构体4.1.2堆的初始化4.1.3堆数据添加向上调整4.1.4主函数内容 4.2堆的创建方法24.2.1堆数据添加向下调整 4.3堆数据…...

python读取influxdb中数据
示例代码一:从infludb中获取指定时间段time和value值,并作图保存 from influxdb_client import InfluxDBClient import matplotlib.pyplot as plt# InfluxDB连接信息 url "http://localhost:8086" token "your_token" org "…...
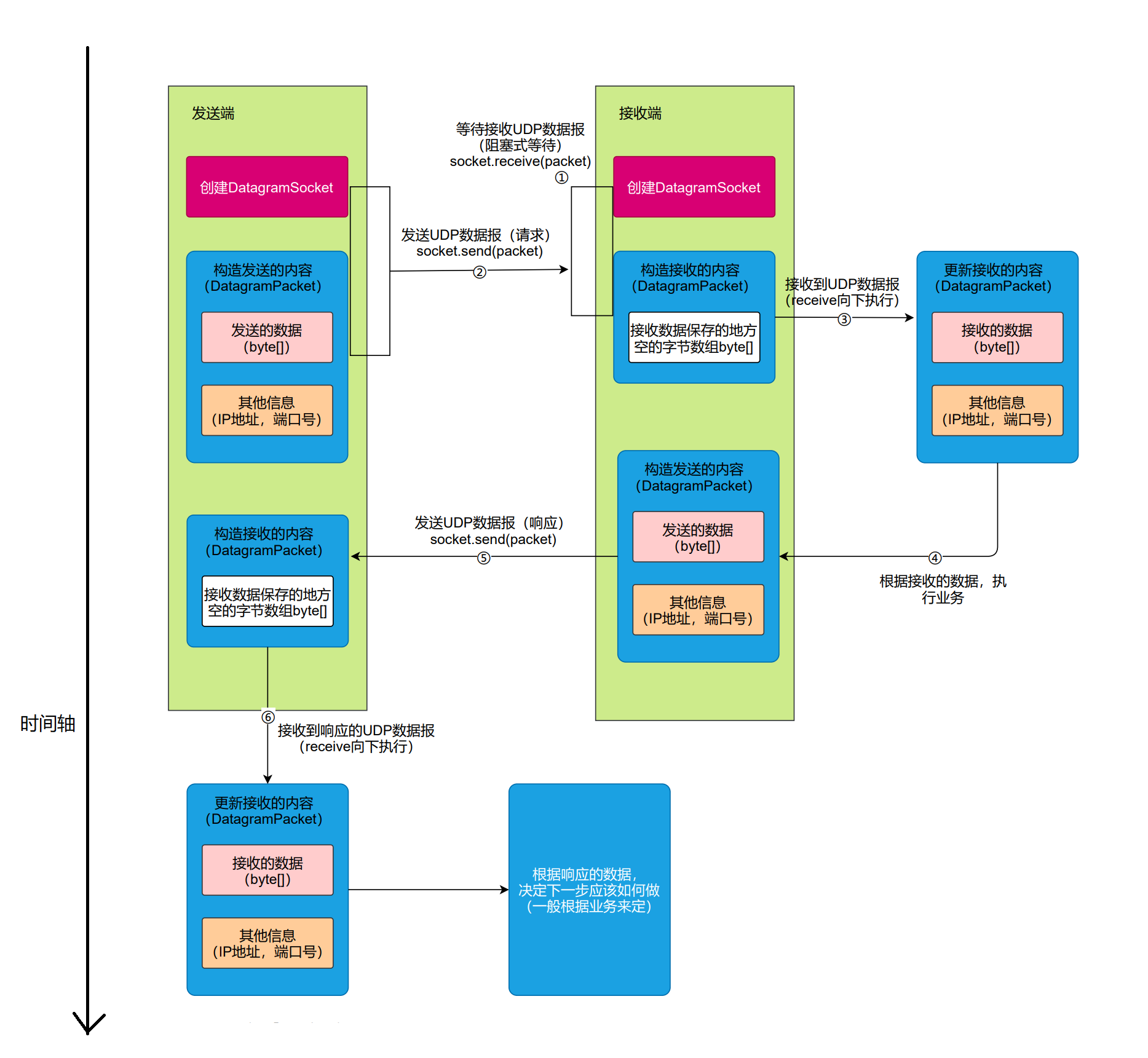
【网络编程】UDP Socket编程
UDP Socket编程 一. DatagramSocket二. DatagramPacket三. InetSocketAddress四. 执行流程五. 代码示例: UDP 回显服务器 数据报套接字: 使用传输层 UDP 协议 UDP: 即 User Datagram Protocol(用户数据报协议),传输层协议。 UDP…...

[GIT]版本控制工具
[GIT]版本控制工具 Git 的命令Git 的配置信息查看现有 Git 配置信息设置 Git 配置信息用户信息配置文本编辑器配置差异分析工具配置 编辑 Git 配置文件 Git 仓库操作初始化 Git 仓库克隆 Git 仓库Git 分支仓库创建Git 远程仓库命令 Git 提交历史Git 标签添加标签查看已有标签删…...

Linux文件管理命令
Linux命令行 命令空格参数(可写可不写)空格文件(可写可不写)ls/opt 根目录下的opt文件夹ls-a 显示所有文件及隐藏文件/optls -l 详细输出文件夹内容 ls -h 输出文件大小(MB...)ls--full-time 完整时间格式输出ls-d 显示文件夹本身信息,不输出内容ls-t 根据最后修改…...
)
Netty面试题(三)
文章目录 前言一、如何选择序列化协议?二、Netty 的零拷贝实现?总结 前言 如何选择序列化协议?Netty 的零拷贝实现? 一、如何选择序列化协议? 具体场景 对于公司间的系统调用,如果性能要求在 100ms 以上的…...
risc-v dv源代码分析
地址为 GitHub - chipsalliance/riscv-dv: Random instruction generator for RISC-V processor verificationRandom instruction generator for RISC-V processor verification - GitHub - chipsalliance/riscv-dv: Random instruction generator for RISC-V processor verif…...

C语言基础语法复习07-c语言关键字的解释
对前一篇文章写点随笔:https://blog.csdn.net/weixin_43172531/article/details/132893176 基本数据类型(8种)和类型修饰符(4种): void与指针*组合在一起才有具体实体意义。 void本身代表没有类型、没有实体,例如void main(void)。 char c…...
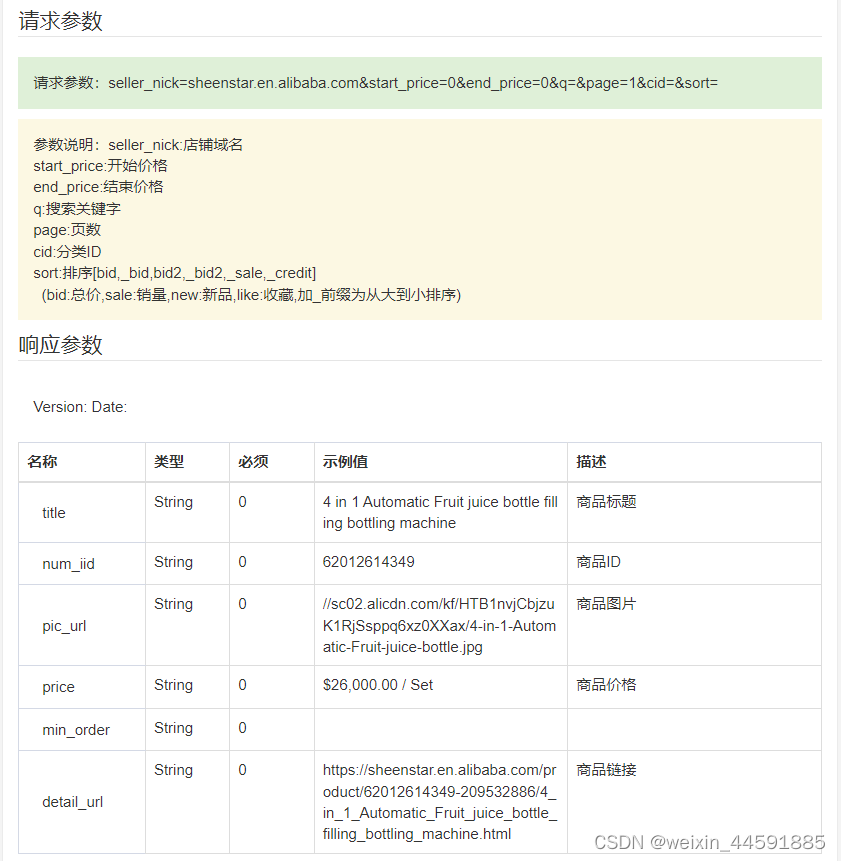
阿里巴巴全店商品采集教程,阿里巴巴店铺所有商品接口(详解阿里巴巴店铺所有商品数据采集步骤方法和代码示例)
随着电商行业的快速发展,阿里巴巴已成为国内的电商平台之一,拥有着海量的商品资源。对于一些需要大量商品数据的商家或者需求方来说,阿里巴巴全店采集是非常必要的。本文将详细介绍阿里巴巴全店采集的步骤和技巧,帮助大家更好地完…...

Android 白天黑夜模式设置
白天黑夜模式是一种动态的UI模式,根据当前时间或用户设置的偏好,在白天和黑夜之间进行切换。它通过调整应用程序的颜色、亮度和其他可视化元素来提供更加舒适和易读的用户界面。 一、简单设置 UiModeManager 是用于管理和控制用户界面模式(UI Mode)。它提供了一组方法,允…...

FFMpeg zoompan 镜头聚焦和移动走位
案例 原始图片 # 输出帧数,默认25帧/秒,25*4 代表4秒 # s1280x80 # 输出视频比例,可以设置和输入图片大小一致 # zoom0.002 表示每帧放大的倍数,下面代码是25帧/每秒 * 4秒,共1000帧 # 最终是 0.002*25*4 0.2&…...
利用hutool工具类实现验证码功能
hutool工具类实现验证码 一.生成验证码二.校验验证码三.使用案例1.引入hutool工具类2.VerifyCodeResp接口响应体3.VerifyCodeController验证码工具类4.测试验证5.项目结构及源码下载 利用hutool工具类,可以很方便生成不同类型的验证码。这里简单记录下使用过程。 一…...

前端面试题: 请解释什么是函数的作用域?
今天做到了一道题:请解释什么是函数的作用域? 我给的答案是: 函数的作用域是指函数执行到内部后创建的数据空间,在函数的作用域内,let定义的变量的有效期为函数作用域 AI觉得我答得比较简单:回答基本正确&…...

如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南
如何快速掌握91160-cli:面向新手的医院全自动挂号完整指南 【免费下载链接】91160-cli 健康160全自动挂号脚本,捡漏神器 项目地址: https://gitcode.com/gh_mirrors/91/91160-cli 还在为医院挂号难而烦恼吗?91160-cli是一款专为医疗预…...

FanControl终极指南:5步解决Windows风扇噪音与过热难题
FanControl终极指南:5步解决Windows风扇噪音与过热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

PLC编程入门学习路径
PLC编程入门学习路径基础概念理解PLC(可编程逻辑控制器)是一种工业自动化控制设备。需要理解其工作原理、硬件组成(CPU、I/O模块、电源等)以及常见的品牌(如西门子、三菱、欧姆龙)。编程语言学习PLC常用编程…...
)
MathType 快捷键实战指南——数学建模效率飙升的秘诀(从入门到精通)
1. 为什么你需要掌握MathType快捷键? 如果你经常需要处理数学公式,肯定遇到过这样的场景:为了输入一个简单的积分符号,不得不从工具栏里翻找半天;调整公式对齐时反复用鼠标拖动;修改矩阵维度时逐个单元格调…...

别再盲目刷LeetCode了!先把这5个编程基础打牢
文章目录前言一、代码规范:不是“洁癖”,是保命的底线二、函数式编程:不是玄学,是现代开发的通用语言三、Python基础工具:sys模块与可变参数,效率提升10倍的利器四、任务拆解能力:从“写代码”到…...

大模型对话的端到端加密与隐私计算实战:基于CipherChat与TEE的架构解析
1. 项目概述:当大模型对话遇上“密码学”的硬核保护最近在折腾大语言模型(LLM)应用落地的朋友,估计都绕不开一个核心痛点:安全与隐私。无论是企业内部的知识库问答,还是面向用户的个性化AI助手,…...

犬种识别实战:细粒度CNN模型从训练到ONNX部署
1. 项目概述:用一张照片,让模型告诉你这是什么狗 “Deep Learning (CNN) — Discover the Breed of a Dog in an Image”这个标题看起来像一句教科书里的课后习题,但实际落地时,它是一条从数据噪声里硬生生凿出来的技术路径——不…...

FreeRTOS CPU使用率统计的坑:为什么你的数据跑了1小时就不准了?
FreeRTOS CPU使用率统计的陷阱与高精度优化方案 当你在嵌入式系统中集成FreeRTOS的CPU使用率统计功能时,可能会遇到一个令人困惑的现象:系统运行约1小时后,统计数值突然出现明显偏差。这不是你的代码出了问题,而是隐藏在32位变量和…...

MTKClient终极指南:解锁联发科设备的完整刷机与调试解决方案
MTKClient终极指南:解锁联发科设备的完整刷机与调试解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 你是否曾经遇到过联发科设备变砖无法启动的困境?或者想…...

ctf show web 入门43
打开靶场代码逻辑如下: if(!preg_match(“/\ |/|cat/i”, $c)) 它过滤了三个关键内容: \ (空格):你不能直接在命令中使用空格(例如 ls -l 或 cat flag 都会失败)。 / (正斜杠):你不能使用路径符号…...