spark6. 如何设置spark 日志
spark yarn日志全解
- 一.前言
- 二.开启日志聚合是什么样的
- 2.1 开启日志聚合MapReduce history server
- 2.2 如何开启Spark history server
- 三.不开启日志聚合是什么样的
- 四.正确使用log4j.properties
一.前言
本文只讲解再yarn 模式下的日志配置。
二.开启日志聚合是什么样的
在yarn模式下,executor 进程和ApplicationMaster进程都会运行在containers中。YARN 有两种方式处理 container logs(也就是我们的spark日志)开启日志聚合和不开启日志聚合
- MapReduce history server :
是hadoop yarn的日志聚合服务,会把运行结束后的任务日志放在hdfs 上,复制完成后则每台机器上的本地日志就会被删除。 另外hdfs上 的所有日志可以设置保留一定时间,避免占用太多磁盘空间。此服务一般用19888端口 - Spark history server
是spark的 ui页面, 默认spark只运行中才可以打开ui, 要想查看所有的历史任务的ui则必须开启此服务
在Spark history server 中查看运行日志会重定向到MapReduce history server 中。 此服务一般用18080端口
2.1 开启日志聚合MapReduce history server
yarn-site.xml<property><!--开启日志聚合--><name>yarn.log-aggregation-enable</name><value>true</value></property><property><!--聚合的日志保留时间><name>yarn.log-aggregation.retain-seconds</name><value>106800</value></property><property><!--聚合的日志存储位置><name>yarn.nodemanager.remote-app-log-dir</name><value>/yarn/${yarn.resourcemanager.cluster-id}/logs</value></property><property><!-- 此配置是为了spark ui可以看到日志><name>yarn.log.server.url</name><value>http://master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:19888/jobhistory/logs</value></property>mapred-site.xml<property><!--mapreduce job日志历史日志服务地址--><name>mapreduce.jobhistory.webapp.address</name><value>master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:19888</value></property><property><name>mapreduce.jobhistory.address</name><value>master-1-1.c-ea09e2040b9f6c41.cn-shanghai.emr.aliyuncs.com:10020</value></property>
启动 MapReduce history server服务 sbin/mr-jobhistory-daemon.sh start historyserver
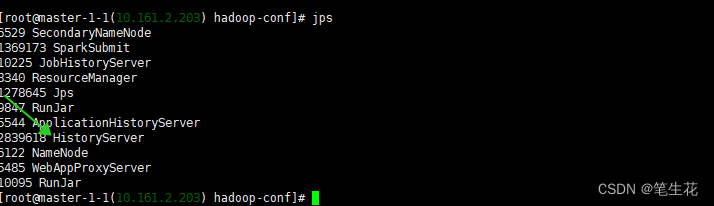
则在程序结束之后container logs 会被copy到hdfs上,此时要查看日志可以通过:yarn logs -applicationId , 要注意的是当任务是accept的时候这个命令是没有日志的,因为还未分配containers, 另一个值得注意的是这个命令会打印出当前运行的日志,但是不是实时跟踪的。也可以使用 HDFS shell or API 来查看日志,这里不做过多解释。
The logs are also available on the Spark Web UI under the Executors Tab
but you have both the Spark history server and the MapReduce history server running and configure yarn.log.server.url in yarn-site.xml properly
这句话的意思是说在spark ui也是可以看到日志,前提条件是开始Spark history server and the MapReduce history server 并在yarn-site.xml 中配置yarn.log.server.url。
值得注意的是spark本身不存储日志, 当在sparkui 查看日志的时候,也是重定向到yarn.log.server.url。
2.2 如何开启Spark history server
spark ui默认只展示正在运行的任务,如果想展示所有的任务,则需要开启Spark history server
- 打开hdfs-site.xml 找到如下配置查看端口,我的配置中是9000
dfs.namenode.rpc-address.hdfs-cluster.nn1
mast-ip:9000
- spark-default.conf 添加如下配置:
spark.eventLog.enabled truespark.eventLog.dir hdfs://mast-ip:9000/spark-history #注意端口为上面找到的端口spark.yarn.historyServer.address mast-ip:18080 #spark history 的webui- ./sbin/start-history-server.sh (进入master 的spark安装目录的sbin中执行此命令)
- 打开 mast-ip:18080 (spark的history server)

仔细看途中的绿色箭头,点击之后会重定向到:mast-ip:19888, 这正是hadoop yarn 的history server 地址。这也证明了spark本身不存储日志。
三.不开启日志聚合是什么样的
当日志聚合不打开的时候,再yarn运行的任务日志被保留在每个container所在的机器上,这个日志目录由以下参数决定:
<property><name>yarn.nodemanager.log-dirs</name><value>/mnt/disk1/yarn/userlogs,/mnt/disk2/yarn/userlogs</value></property>
这些日志路径中包含applicationID 和containerID,很容易找到,这些日志再 Spark Web UI也能看到 并且不需要启动hadoop的
MapReduce history server。
在本地不止有日志,为了方便追溯历史任务的执行信息,还缓存了任务执行的需要的各种信息,比如filecache,
甚至还可以找到曾经任务的启动脚本(如下) 缓存时间通过:yarn.nodemanager.delete.debug-delay-sec设置( 在任务结束多长时间后,删除本地化的日志缓存【缓存包含启动命令脚本文件, jar缓存文件,日志等】) 此设置需要重启集群。
缓存时间通过:yarn.nodemanager.delete.debug-delay-sec设置( 在任务结束多长时间后,删除本地化的日志缓存【缓存包含启动命令脚本文件, jar缓存文件,日志等】) 此设置需要重启集群。
四.正确使用log4j.properties
- 配置全局log4j.properties
意思是所有的任务用同一个log4j.properties - 独立配置log4j.properties
考虑一个使用场景,比如我们想每个任务使用独立的log4j.proprtties, 且再log4j.properties中用自定义变量定义一个路径,
这样可以达到每个任务 输出到独立的文件中,方便我们做日志采集。
上面的场景就不适合用默认的log4j.properties了
如果想要使用自定义的log4j日志配置,需要下面几个步骤:
第一种写法带 –file
- 使用spark-submit的–files参数,上传自定义 log4j-driver.properties(名字随便)和log4j-executor.properties(名字随便)
- 使用 --conf spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j-driver.propertie
- 使用 --conf spark.executor.extraJavaOptions=-Dlog4j.configuration=log4j-executor.properties
第二种写法不带 –file, 要求配置文件在每台机器上都存在,且必须以file: 开头,意思是本地路径协议
- 使用 --conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:/…/…/…/log4j-driver.propertie
- 使用 --conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:/…/…/…/log4j-executor.properties
下面附上我自己用的一个例子:
spark-submit \
--master yarn \
--deploy-mode cluster \
--class alg.test.SparSocketDemo \
--conf spark.driver.extraJavaOptions="-Dlog4j2.formatMsgNoLookups=true -Ddriver.path=/driver/mm/ -Dlog4j.configuration=dr.log4j.properties -noverify -javaagent:/opt/apps/TAIHAODOCTOR/taihaodoctor-current/emr-agent/btrace-agent.jar=libs=spark-3.2" \
--conf spark.executor.extraJavaOptions="-Dlog4j2.formatMsgNoLookups=true -Dexecutor.path=/executor/mm/ -Dlog4j.configuration=ex.log4j.properties -noverify -javaagent:/opt/apps/TAIHAODOCTOR/taihaodoctor-current/emr-agent/btrace-agent.jar=libs=spark-3.2" \
--files /root/dr.log4j.properties,/root/ex.log4j.properties \
/root/JavaAndScala-1.0-SNAPSHOT.jar 下面是dr.log4j.properties ,仅供参考
# Set everything to be logged to the console
log4j.rootCategory=INFO, console, LOGFILElog4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p [%t] %c{1}: %m%n# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERRORlog4j.logger.org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver=WARN# For deploying Spark ThriftServer
# SPARK-34128: Suppress undesirable TTransportException warnings involved in THRIFT-4805
log4j.appender.console.filter.1=org.apache.log4j.varia.StringMatchFilter
log4j.appender.console.filter.1.StringToMatch=Thrift error occurred during processing of message
log4j.appender.console.filter.1.AcceptOnMatch=falselog4j.appender.LOGFILE = org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File = /tmp/${driver.path}/driver.log
log4j.appender.LOGFILE.Append = true
log4j.appender.LOGFILE.layout = org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n注意我的LOGFILE 中有个 ${driver.path}, 这会接收启动命令中的 -Ddriver.path=/driver/mm/
这意味着 我的每次启动都通过-Ddriver.path=XXX 传递不同的路径,这样我的每个任务都会在不同的目录下生成日志文件。
我可以自定义appName 并将appName 凭借在上面的路径上,这在实际开发中很有意义。
大家可能会注意到上面的启动命令driver和executor分别用的不i同的log4j 配置文件, 这是为了防止driver的日志和executor混杂在一起。spark官网推荐我们这么做,这种自定义的方式还可以吧。并且我们只是在原来的基础加了一个 LOGFILE appender, 并未修log4j.properties本省的配置, 不会影响原本的日志聚合, 以及原本的日志采集。
相关文章:
spark6. 如何设置spark 日志
spark yarn日志全解 一.前言二.开启日志聚合是什么样的2.1 开启日志聚合MapReduce history server2.2 如何开启Spark history server 三.不开启日志聚合是什么样的四.正确使用log4j.properties 一.前言 本文只讲解再yarn 模式下的日志配置。 二.开启日志聚合是什么样的 在ya…...

glibc: strlcpy
https://zine.dev/2023/07/strlcpy-and-strlcat-added-to-glibc/ https://sourceware.org/git/?pglibc.git;acommit;h454a20c8756c9c1d55419153255fc7692b3d2199 https://linux.die.net/man/3/strlcpy https://lwn.net/Articles/612244/ 从这里看,这个strlcpy、st…...

如何在 Buildroot 中配置 Samba
在 Buildroot 中配置 Samba 在 Buildroot 中配置 Samba 可以通过以下步骤完成: 1. 进入 Buildroot 的根目录。 2. 执行 make menuconfig 命令,打开 Buildroot 的配置菜单。 3. 在配置菜单中,使用键盘导航到 "Target packages" 选…...

SSM02
SSM02 此时我们已经做好了登录模块接下来可以做一下学生管理系统的增删改查操作 首先,我们应当有一个登录成功后的主界面 在webapp下新建 1.main.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"&…...
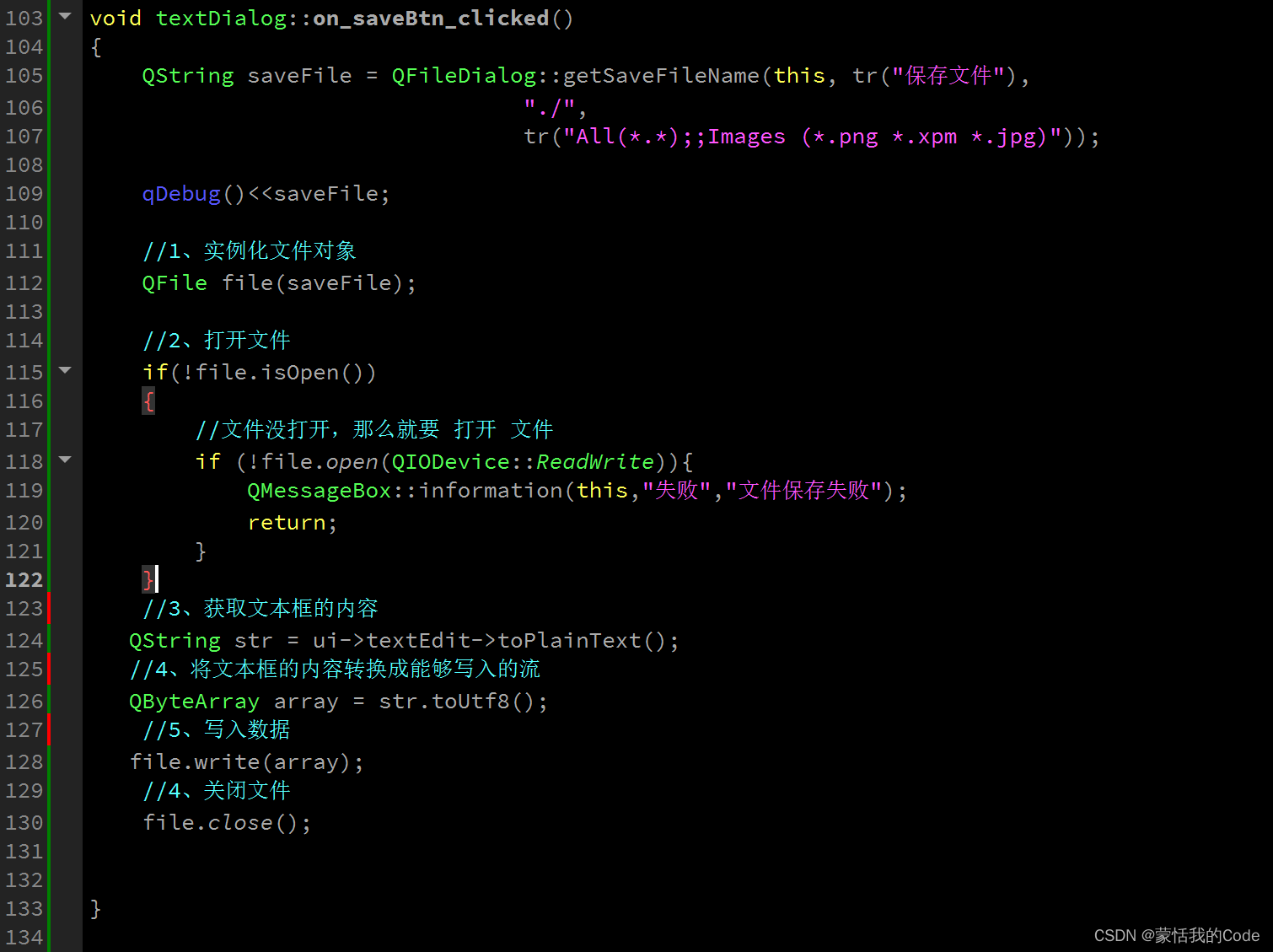
day3_QT
day3_QT 1、文件保存2、始终事件 -闹钟 1、文件保存 2、始终事件 -闹钟 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTimerEvent> #include <QTime> #include <QTextToSpeech>QT_BEGIN_NAMESPACE namespace Ui { clas…...

js-map方法中调用服务器接口
在 Array.prototype.map() 方法中调用服务器接口时,可以使用异步函数来处理。 示例: async function fetchData() {try {const response await fetch(https://api.example.com/data); // 通过 fetch 发送请求const data await response.json(); // 解…...

docker 已经配置了国内镜像源,但是拉取镜像速度还是很慢(gcr.io、quay.io、ghcr.io)
前言 国内用户在使用 docker 时,想必都遇到过镜像拉取慢的问题,那是因为 docker 默认指向的镜像下载地址是 https://hub.docker.com,服务器在国外。 网上有关配置 docker 国内镜像源的教程很多,像 腾讯、阿里、网易 等等都会提供…...
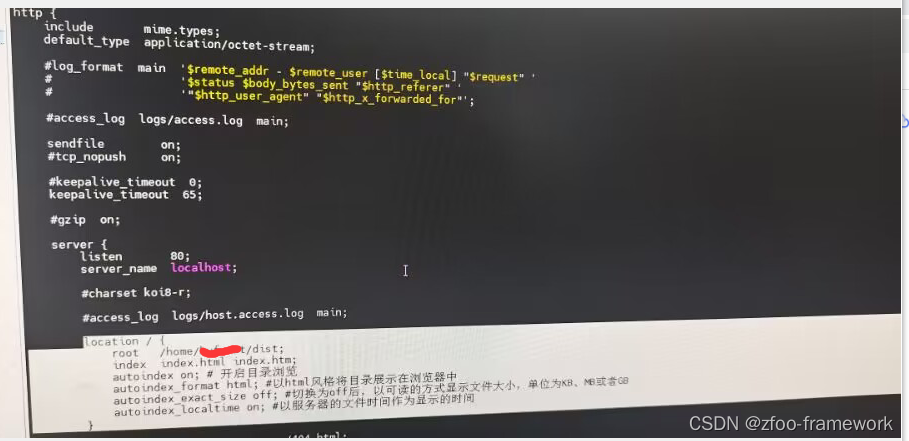
[linux(静态文件服务)] 部署vue发布后的dist网页到nginx
所以说: 1.windows下把开发好的vue工程打包为dist文件然后配置下nginx目录即可。 2.linux上不需要安装node.js环境。 3.这样子默认访问服务器ip地址,就可以打开,毕竟默认就是:80端口。...

智华计算机终端保护检查系统使用笔记
使用说明 【智华保密检查右键管理员运行后粘贴密码】—— 点击脚本更改系统时间【智华计算机终端保护检查系统】—— 打开检测软件进行保密检查 检测文件格式 .pdf .doc .docx .xls .pptx 检测时间日志 2023年9月14日A:【34:03秒】2023年9月14日B:【…...
)
前端面试话术集锦第 15 篇:高频考点(React常考进阶知识点)
这是记录前端面试的话术集锦第十五篇博文——高频考点(React常考进阶知识点),我会不断更新该博文。❗❗❗ 1. HOC 是什么?相比 mixins 有什么优点? 很多人看到高阶组件(HOC)这个概念就被吓到了,认为这东西很难,其实这东西概念真的很简单,我们先来看一个例子: func…...

汽车电子——产品标准规范汇总和梳理(适应可靠性)
文章目录 前言 一、电气性能要求 二、机械性能要求 三、气候性能要求 四、材料性能要求 五、耐久性能要求 六、防护性能要求 总结 前言 见《汽车电子——产品标准规范汇总和梳理》 一、电气性能要求 《GB/T 28046.2-2019(ISO 16750-2:2012&#…...
计算机是如何工作的(上篇)
计算机发展史 世界上很多的高科技发明,来自于军事领域 计算机最初是用来计算弹道导弹轨迹的 弹道导弹 ~~国之重器,非常重要 两弹一星 原子弹,氢弹,卫星(背后的火箭发射技术) 计算弹道导弹轨迹的计算过程非常复杂,计算量也很大 ~~ 但是可以手动计算出来的(当年我国研究两弹一…...

数学建模| 优化入门+多目标规划
优化入门多目标规划 优化入门知识什么是优化问题如何判断是不是优化问题优化模型建模求解器优化问题的分类 多目标规划 优化入门知识 什么是优化问题 优化问题:求最优,例如获利最大、最少损失、最短路径、最小化风险等等。 例如:之前文章提…...

SSM整合Thymeleaf时,抽取公共页面并向其传递参数
第一步 创建一个名为 header.html 的公共头部页面模板,放在 WEB-INF 目录下的 common 文件夹中。在 header.html 中可以编写头部页面的HTML代码,并通过Thymeleaf的语法来接收参数,如下所示: <!DOCTYPE html> <html xml…...

接口测试 —— requests 的基本了解
● requests介绍及安装 ● requests原理及源码介绍 ● 使用requests发送请求 ● 使用requests处理响应 ● get请求参数 ● 发送post请求参数 ● 请求header设置 ● cookie的处理 ● https证书的处理 ● 文件上传、下载 requests介绍 ● requests是python第三方的HTT…...

2023年华为杯数学建模研赛D题思路解析+代码+论文
下文包含:2023华为杯研究生数学建模竞赛(研赛)D题思路解析代码参考论文等及如何准备数学建模竞赛(22号比赛开始后逐步更新) C君将会第一时间发布选题建议、所有题目的思路解析、相关代码、参考文献、参考论文等多项资…...
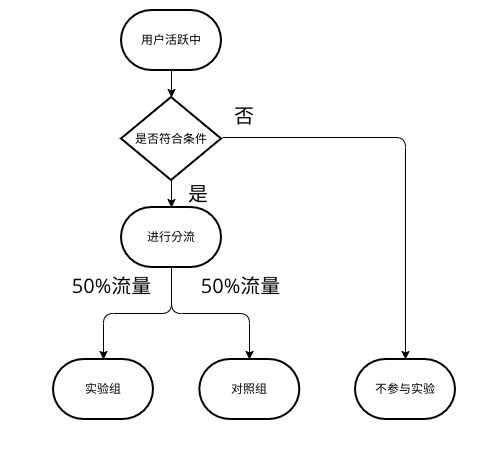
AB试验(三)一次试验的规范流程
AB试验(三)一次试验的规范流程 一次完整且规范的A/B试验可参考下图: 确定目标和假设 核心:A/B测试是因果推断,所以我们首先要确定原因和结果。目标决定了结果,而假设又决定了原因。 如何确定 分析问题&am…...
ROI tracking by using OpenCV
目录 source code: source code: import cv2tracker cv2.TrackerKCF_create() video cv2.VideoCapture(1)while True:ret,frame video.read()cv2.imshow("source frame",frame)k cv2.waitKey(30)if k q:break bbox cv2.selectROI(frame, False) ok tracker.i…...

(leetcode)二叉树最大深度
个人主页:Lei宝啊 愿所有美好如期而遇 目录 题目: 思路: 代码: 图解: 题目: 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数…...
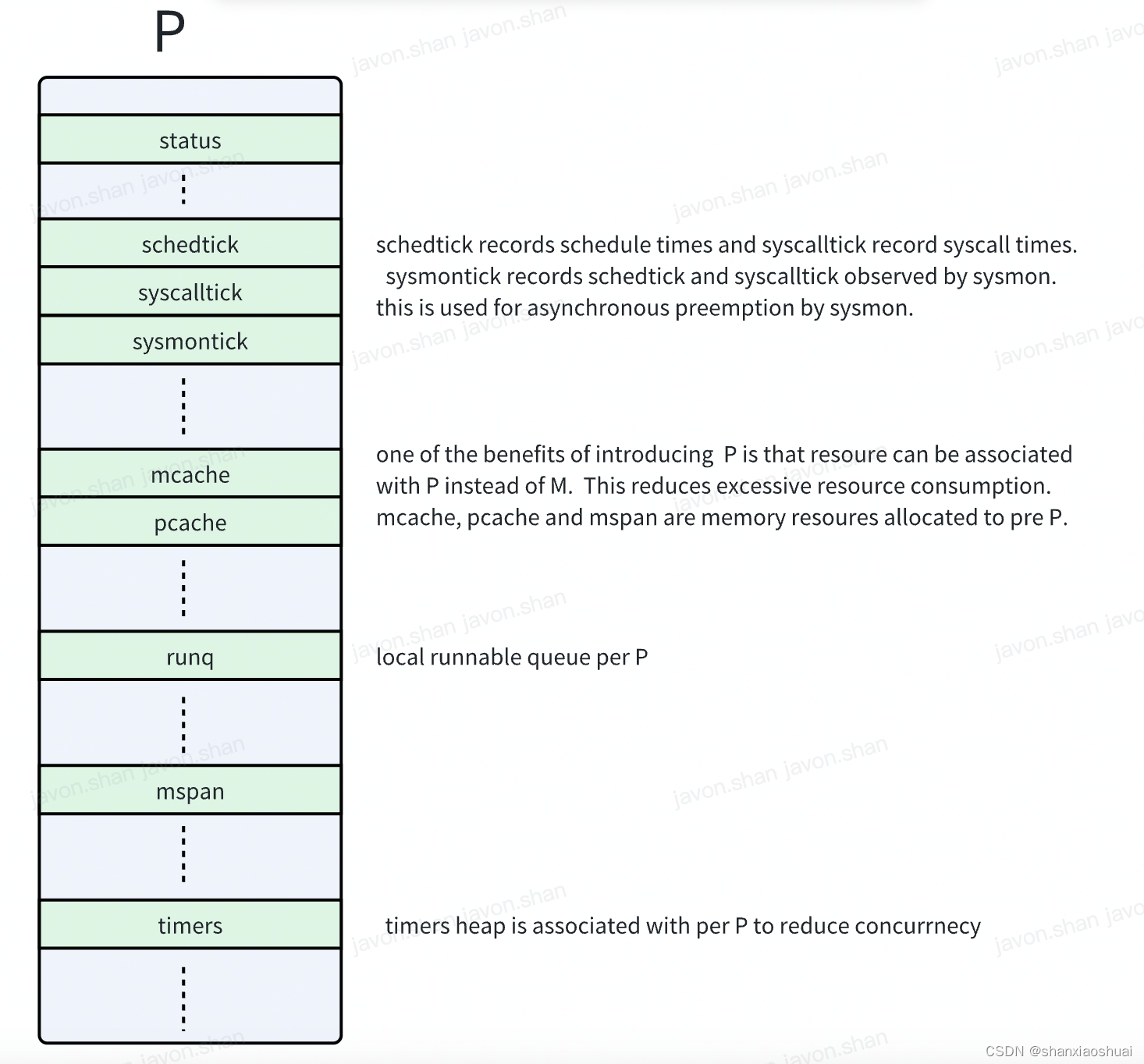
【golang】调度系列之P
调度系列 调度系列之goroutine 调度系列之m 在前面两篇中,分别介绍了G和M,当然介绍的不够全面(在写后面的文章时我也在不断地完善前面的文章,后面可能也会有更加汇总的文章来统筹介绍GMP)。但是,抛开技术细…...

使用Taotoken管理控制台进行APIKey的权限划分与审计日志查看
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken管理控制台进行APIKey的权限划分与审计日志查看 在团队协作开发或构建多应用服务时,统一管理大模型API的访…...

2025届必备的六大AI辅助论文网站推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek系列模型相关的论文,全方位细致地阐述了其技术架构以及训练的方式方法。…...

JPlag代码抄袭检测工具:如何高效识别17种编程语言的代码抄袭行为
JPlag代码抄袭检测工具:如何高效识别17种编程语言的代码抄袭行为 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag …...

Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析
Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在现代化教育信息化环境中ÿ…...
)
别再只盯着VGA线了!手把手教你用示波器看懂RGBHV时序图(附绿同步电路分析)
数字示波器实战:解码RGBHV信号与绿同步电路设计全指南 在复古游戏机改造、CRT显示器维修或视频转换板设计的场景中,RGBHV信号的理解与测量往往是硬件工程师和电子爱好者面临的第一道技术门槛。不同于现代数字接口的标准化协议,模拟视频信号时…...

北京AGG聚砂吸声板哪家性价比高
在选择AGG聚砂吸声板时,“性价比”往往不只是看价格,而是综合考量声学性能、施工服务、材料稳定性和后期维护的平衡。北京市场上的供应商不少,但真正能长期稳定输出成熟产品的,需要从几个实际角度去判断。首先,要优先看…...

AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用
AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

AI决策公平性:司法审查下的技术实践与算法治理
1. 项目概述:当算法成为“法官”,公平如何被审查?最近几年,我参与和观察了不少涉及算法决策的项目,从信贷审批到招聘筛选,再到内容推荐。一个越来越无法回避的问题是:当AI系统代替人类做出影响个…...

通过用量看板与透明账单有效控制大模型 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与透明账单有效控制大模型 API 调用成本 对于依赖大模型 API 进行开发的团队而言,成本控制是一个贯穿始终…...

从灰度图到粉彩叙事,全程可复现:5个精准Prompt模板+3类LUT预设,零基础速产美术馆级Pastel印相
更多请点击: https://intelliparadigm.com 第一章:从灰度图到粉彩叙事:Pastel印相的美学本质与技术边界 Pastel印相并非简单的色彩叠加,而是一种基于人眼感知非线性响应与胶片化学特性的数字模拟范式。其核心在于将灰度图像的亮度…...