Python爬虫:动态获取页面

动态网站根据用户的某些操作产生一些结果。例如,当网页仅在向下滚动或将鼠标移动到屏幕上时才完全加载时,这背后一定有一些动态编程。当您将鼠标指针悬停在某些文本上时,它会为您提供一些选项,它还包含一些动态.这是是一篇关于动态网页的非常好的详细文章。
您可以在互联网上找到许多文章来帮助您抓取动态网站。这篇文章是我抓取Doordash.com 的方法。一切都是逐步进行的。
抓取动态网页的一个必要条件是在浏览器中加载其 javascript。而且,这是通过无头浏览器完成的(稍后会解释)。
我的目标是从 Doordash.com 上抓取 5 万多个菜单。
[请记住,除了某些特定条件外,Python 区分大小写。]
让我们通过导入一些必要的库以及我们可能需要的一些辅助库来开始编码。正如标题所示,我将使用 Selenium 库
#importing required libraries
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.support.wait import WebDriverWait
from selenium_move_cursor.MouseActions import move_to_element_chrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import js
import json
import numpy as np
import time
import pandas as pd #to save CSV file
from bs4 import BeautifulSoup
import ctypes #to create text popupSelenium 的“Webdriver”模块是最重要的,因为它将控制浏览器。为了控制浏览器,有一定的要求,这些要求已经以驱动程序的形式设置,例如“google chrome”的“chromedriver”。我将使用“ chromedriver ”。而且,要使用它,我们需要告诉“webdriver”它。
让我们为“webdriver”定义这个浏览器,并将其选项设置为“--headless”。
#defining browser and adding the “ — headless” argument
opts = Options()
opts.add_argument(‘ — headless’)
driver = webdriver.Chrome(‘chromedriver’, options=opts)这个“无头”参数被设置为处理动态网页,加载它们的 javascript。
以下是 URL 以及使用“webdriver”打开 URL 的代码。
url = 'https://www.doordash.com/en-US'
driver.maximize_window() #maximize the window
driver.get(url) #open the URL
driver.implicitly_wait(220) #maximum time to load the link我将 chromedriver 放在项目目录中以保持路径简单。或者可以使用“OS”模块定义路径来代替“chromedriver”。
第一种方法:
我对 Doordash.com 进行了概述,以了解我们的结果(即菜单)的位置以及如何访问它们。
该脚本将
1-打开浏览器
#defining browser and adding the “ — headless” argument
opts = Options()
opts.add_argument(‘ — headless’)
driver = webdriver.Chrome(‘chromedriver’, options=opts)2- 搜索 URL (doordash.com)
url = 'https://www.doordash.com/en-US'
driver.maximize_window() #maximize the window
driver.get(url) #open the URL
driver.implicitly_wait(220) #maximum time to load the link3-向下滚动以加载整个页面
driver.execute_script("window.scrollTo(0, document.body.scrollHeight,)")4-导航至“您附近的热门美食”
5-点击“Pizza Near Me”(我认为这对于 50k+ 菜单来说已经足够了)
time.sleep(5)
element = driver.find_element_by_xpath(‘//h2[text()=”Top Cuisines Near You”]’).find_element_by_xpath(‘//a[@class=”sc-hrWEMg fFHnHa”]’)
time.sleep(5)
element.click()
driver.implicitly_wait(220)6-加载页面和页面范围
#define the lists
names = []
prices = []
#extract the number of pages for the searched product
driver.implicitly_wait(120)
time.sleep(3)
result = driver.page_source
soup = BeautifulSoup(result, 'html.parser')
page = list(soup.findAll('div', class_="sc-cvbbAY htjLED"))
start = int(page[2].text)
print('1st page:',start)
last = int(page[-2].text)
final = last +1
print('last page:',final)
#getting numbers out of string of pages
print(f'first page:{start}, and last page with + 1: {final}')7-点击各个商店(页面已设置默认位置中国,因此无需担心位置)
#set the page_range And
#lloop all the pages of store
for i in range(start, final, 1):time.sleep(7)#find the number of stores per pagelist_length = len(driver.find_elements_by_xpath(“//div[@class=’StoreCard_root___1p3uN’]”))products_per_page = list_length+1#loop through the menues of each store on a pagefor x in range(0, list_length, 1):time.sleep(7)driver.execute_script(“window.scrollTo({top:75, behavior:’smooth’,})”) store_name = driver.find_elements_by_xpath(‘//div[@class=”StoreCard_storeDetail___3C0TX”]’)strnm = store_name[x]print(f’{x}- ‘, strnm.text)time.sleep(4)element=driver.find_elements_by_xpath(“//div[@class=’StoreCard_storeDetail___3C0TX’]”)click = element[x]move_to_element_chrome(driver, click, display_scaling=100)time.sleep(7)click.click()driver.implicitly_wait(360)8-抓取菜单并抓取后返回商店页面
time.sleep(20)result = driver.page_sourcetime.sleep(11)soup = BeautifulSoup(result, ‘html.parser’)div = soup.find(‘div’, class_=”sc-jwJjzT kjdEnq”)if div is not None:time.sleep(25)for i in div.findAll(‘div’, class_=”sc-htpNat Ieerz”):pros = i.find(‘div’, class_=”sc-jEdsij hukZqW”)print(‘writing (‘, pros.text, ‘) to disk’)names.append(pros.text)rates = i.find(‘span’, class_=”sc-bdVaJa eEdxFA”)#if there is no price for the food, append ‘N/A’ in the list of ‘prices’if rates is not None:print(‘price: ‘, rates.text)rate = rates.textelse:print(‘N/A’)rate = ‘N/A’prices.append(rate)driver.back()9-检查名称列表中的菜单数量
length = len(names)
完成列表中大约 10000 个菜单后中断循环,并通过弹出窗口通知我们,否则重复循环
#if menu record reaches the target, exit the script and produce target completion message boxif ((length > 10000) and (length <10050)):ctypes.windll.user32.MessageBoxW(0, f”Congratulations! We have succefully scraped {length} menues.”, “Project Completion”, 1)breakelse:driver.back()continue10-整个过程将保持循环,直到我们得到大约 10000 个菜单。
11-如果在抓取一页上的所有商店时未达到 10000 目标,请单击“下一步”按钮进行抓取
#after scraping each store on a page, it will tell that it is going to next pageprint(f’Now moving to page number {i}’)#click next page buttondriver.find_elements_by_xpath(‘//div[@class=”sc-gGBfsJ jFaVNA”]’)[1].click()12-将结果保存为 CSV 文件。
#save to dataframe
df = pd.DataFrame({‘Name’:names, ‘Price’:prices})
#export as csv file
df.to_csv(‘doordash_menues.csv’)
相关文章:
Python爬虫:动态获取页面
动态网站根据用户的某些操作产生一些结果。例如,当网页仅在向下滚动或将鼠标移动到屏幕上时才完全加载时,这背后一定有一些动态编程。当您将鼠标指针悬停在某些文本上时,它会为您提供一些选项,它还包含一些动态.这是是一篇关于动态…...

大数据平台迁移后yarn连接zookeeper 异常分析
大数据平台迁移后yarn连接zookeeper 异常分析 XX保险HDP大数据平台机房迁移异常分析。 异常现象: 机房迁移后大部分组件都能正常启动Yarn 启动后8088 8042等端口无法访问Hive spark 作业提交到yarn会出现卡死。 【备注】虽然迁移,但IP不变。 1. Yarn连…...

Ubuntu Nginx 配置 SSL 证书
首先需要在 Ubuntu 中安装 Nginx 服务, 打开终端执行以下命令: $ sudo apt update $ sudo apt install nginx -y然后启动 Nginx 服务并设置为开机时自动启动, 执行以下命令: $ sudo systemctl start nginx $ sudo systemctl enable nginx最后再验证一下 Nginx 服务的当前状态…...
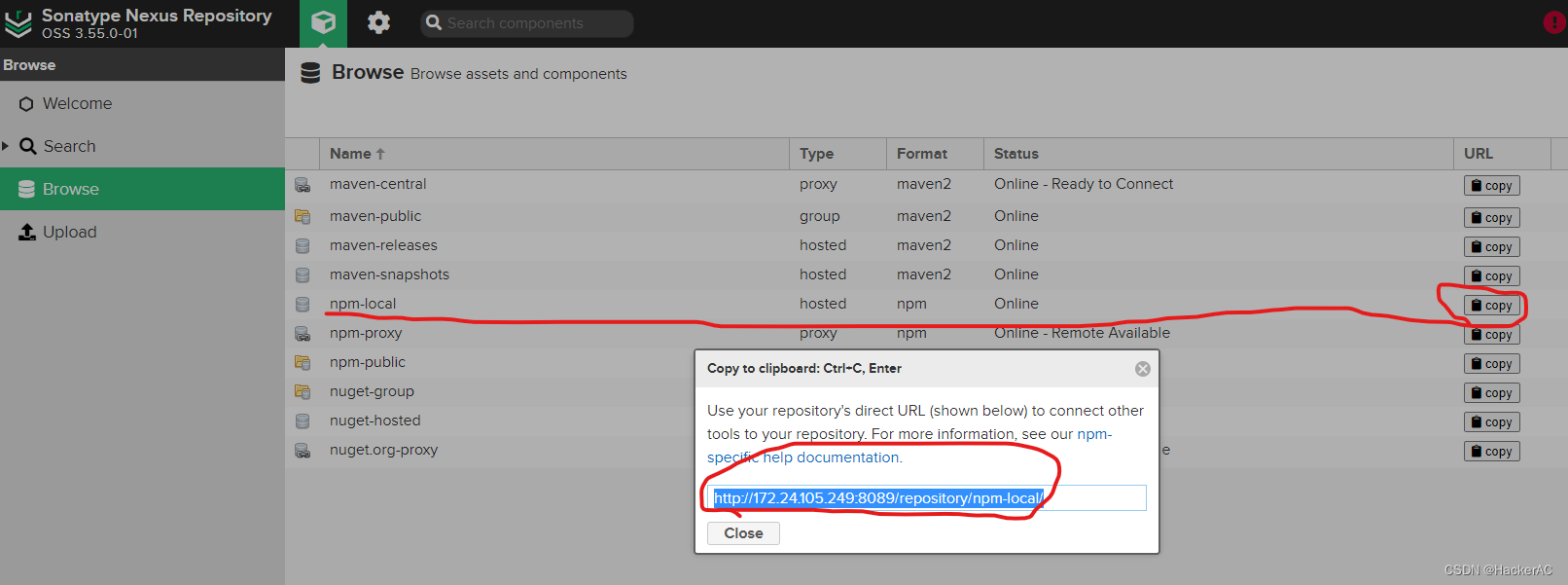
将本地前端工程中的npm依赖上传到Nexus
【问题背景】 用Nexus搭建了内网的依赖仓库,需要将前端工程中node_modules中的依赖上传到Nexus上,但是node_modules中的依赖已经是解压后的状态,如果直接机械地将其简单地打包上传到Nexus,那么无法通过npm install下载使用。故有…...
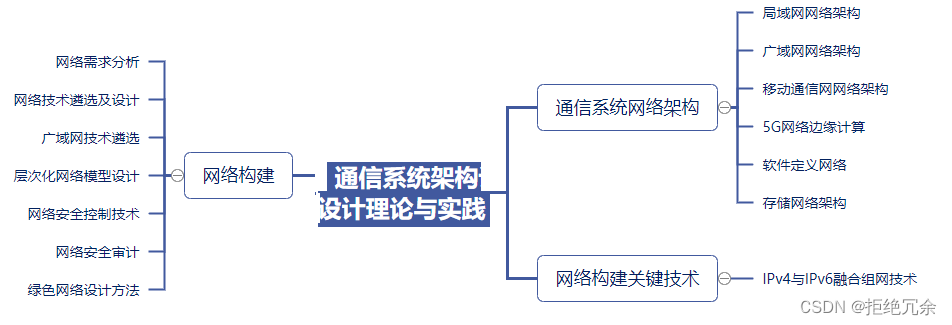
软考高级架构师下篇-16通信系统架构设计理论与实践
目录 1. 引言2. 通信系统网络架构3. 网络构建关键技术4. 网络构建5. 前文回顾1. 引言 此章节主要学习通信系统架构设计的理论和工作中的实践。根据新版考试大纲,本节知识点会涉及案例分析题(25分),而在历年考试中,案例题对该部分内容的考查并不多,虽在综合知识选择题目中…...

国庆中秋特辑(二)浪漫祝福方式 使用生成对抗网络(GAN)生成具有节日氛围的画作
要用人工智能技术来庆祝国庆中秋,我们可以使用生成对抗网络(GAN)生成具有节日氛围的画作。这里将使用深度学习框架 TensorFlow 和 Keras 来实现。 一、生成对抗网络(GAN) 生成对抗网络(GANs,…...

stm32 串口发送和接收
串口发送 #include "stm32f10x.h" // Device header #include <stdio.h> #include <stdarg.h>//初始化串口 void Serial_Init() {//开启时钟RCC_APB2PeriphClockCmd(RCC_APB2Periph_USART1,ENABLE);RCC_APB2PeriphClockCmd(RCC_APB2Pe…...

Vite + Vue3 实现前端项目工程化
通过官方脚手架初始化项目 第一种方式,这是使用vite命令创建,这种方式除了可以创建vue项目,还可以创建其他类型的项目,比如react项目 npm init vitelatest 第二种方式,这种方式是vite专门为vue做的配置,…...

Java动态代理Aop的好处
1. 预备知识-动态代理 1.1 什么是动态代理 动态代理利用Java的反射技术(Java Reflection)生成字节码,在运行时创建一个实现某些给定接口的新类(也称"动态代理类")及其实例。 1.2 动态代理的优势 动态代理的优势是实现无侵入式的代…...
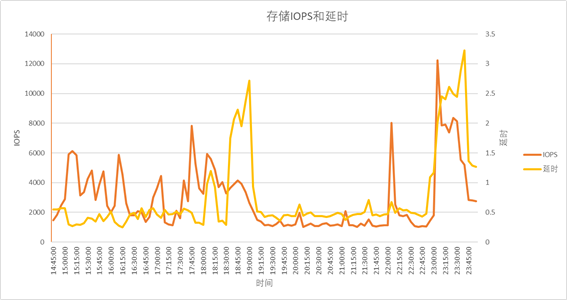
各种存储性能瓶颈如何分析与优化?
【摘要】本文结合实践剖析存储系统的架构及运行原理,深入分析各种存储性能瓶颈场景,并提出相应的性能优化手段,希望对同行有一定的借鉴和参考价值。 【作者】陈萍春,现就职于保险行业,拥有多年的系统、存储以及数据备…...
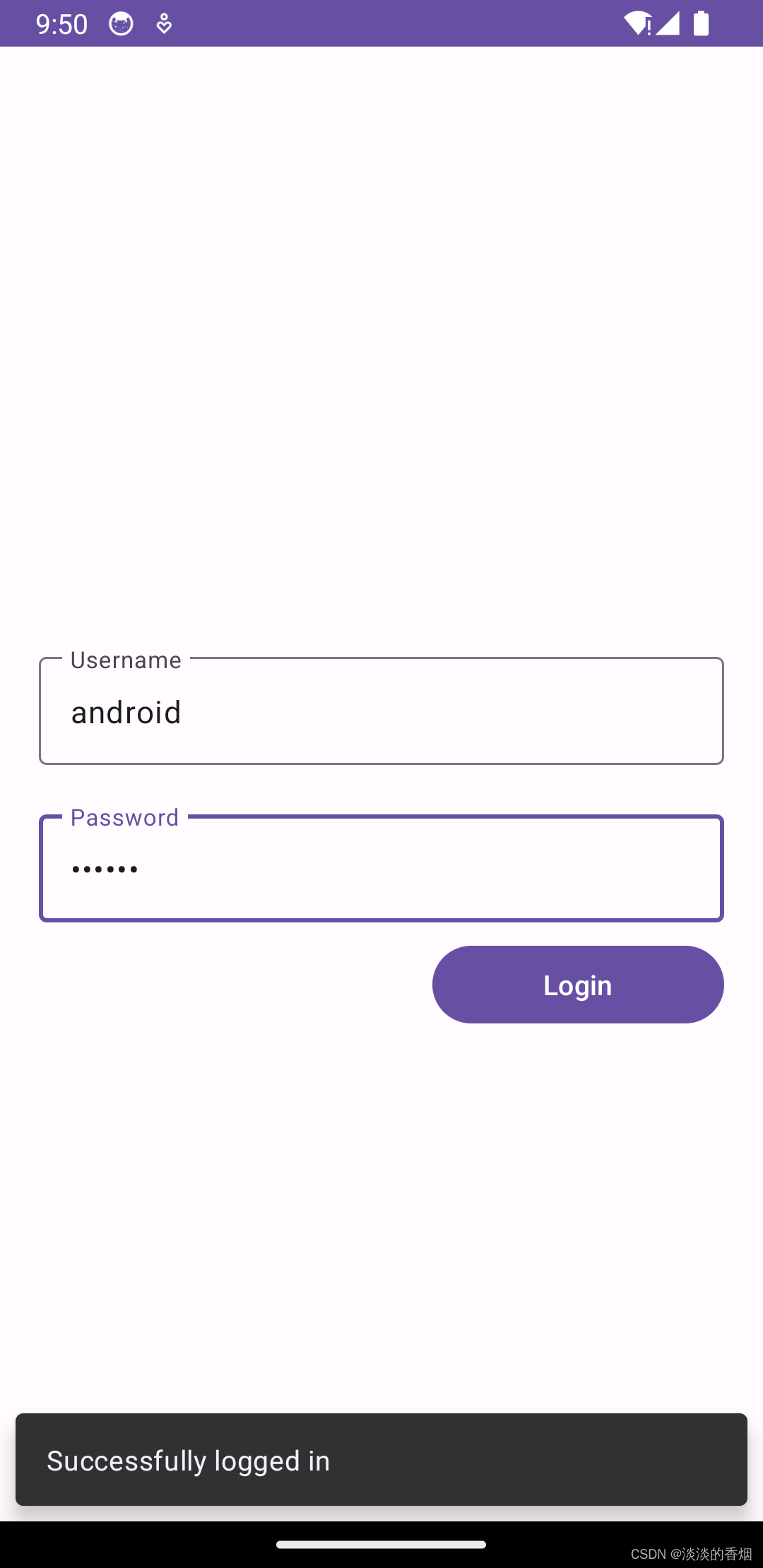
Android StateFlow初探
Android StateFlow初探 前言: 最近在学习StateFlow,感觉很好用,也很神奇,于是记录了一下. 1.简介: StateFlow 是一个状态容器式可观察数据流,可以向其收集器发出当前状态更新和新状态更新。还可通过其 …...
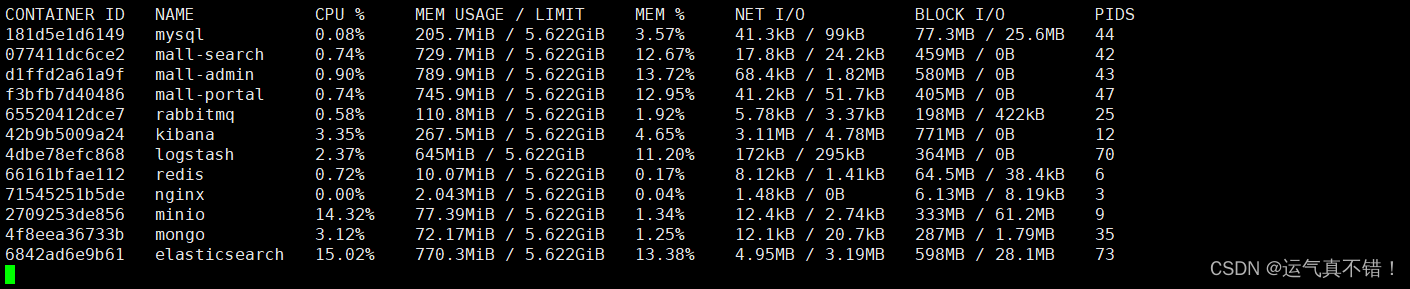
Docker Compose初使用
简介 Docker-Compose项目是Docker官方的开源项目,负责实现对Docker容器集群的快速编排。 Docker-Compose将所管理的容器分为三层,分别是 工程(project),服务(service)以及容器(cont…...
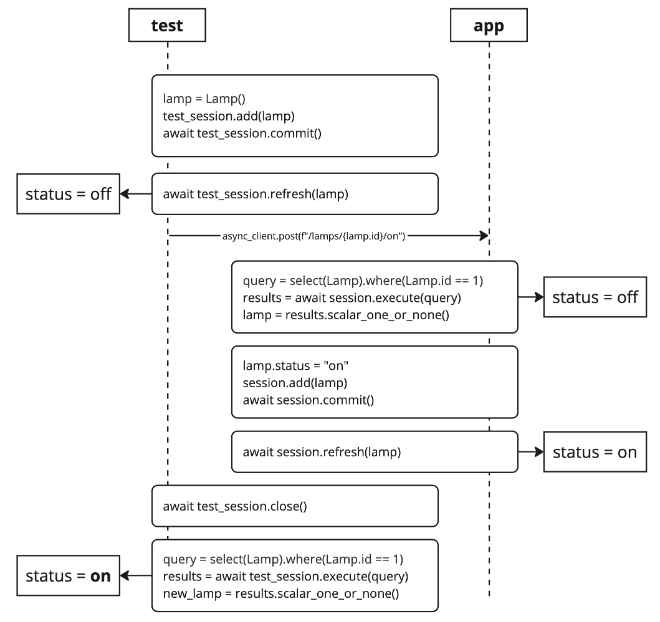
测试与FastAPI应用数据之间的差异
【squids.cn】 全网zui低价RDS,免费的迁移工具DBMotion、数据库备份工具DBTwin、SQL开发工具等 当使用两个不同的异步会话来测试FastAPI应用程序与数据库的连接时,可能会出现以下错误: 在测试中,在数据库中创建了一个对象&#x…...

WebStorm 2023年下载、安装教程、亲测有效
文章目录 简介安装步骤常用快捷键 简介 WebStorm 是JetBrains公司旗下一款JavaScript 开发工具。已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的…...

k8s储存卷
卷的类型 In-Tree存储卷插件 ◼ 临时存储卷 ◆emptyDir ◼ 节点本地存储卷 ◆hostPath, local ◼ 网络存储卷 ◆文件系统:NFS、GlusterFS、CephFS和Cinder ◆块设备:iSCSI、FC、RBD和vSphereVolume ◆存储平台:Quobyte、PortworxVolume、Sto…...
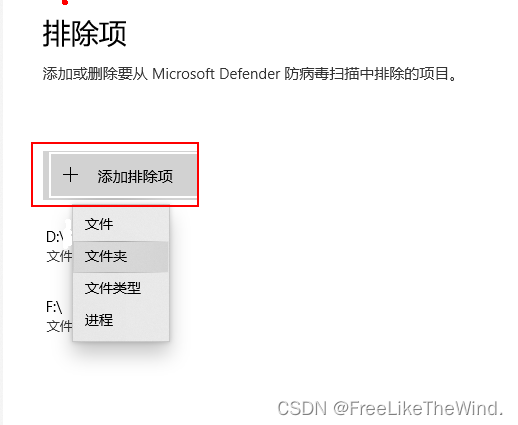
【解决Win】“ 无法打开某exe提示无法成功完成操作,因为文件包含病毒或潜在的垃圾软件“
在下载某个应用程序,打开时出现了“无法成功完成操作因为文件包含病毒或潜在垃圾”的提示,遇到这个情况怎么解决? 下面为大家分享故障原因及具体的处理方法。 故障原因 是由于杀毒 防护等原因引起的。 解决方案 打开Windows 安全中心 选择…...

SpringBoot调用ChatGPT-API实现智能对话
目录 一、说明 二、代码 2.1、对话测试 2.2、单次对话 2.3、连续对话 2.4、AI绘画 一、说明 我们在登录chatgpt官网进行对话是不收费的,但需要魔法。在调用官网的API时,在代码层面上使用,通过API KEY进行对话是收费的,不过刚…...
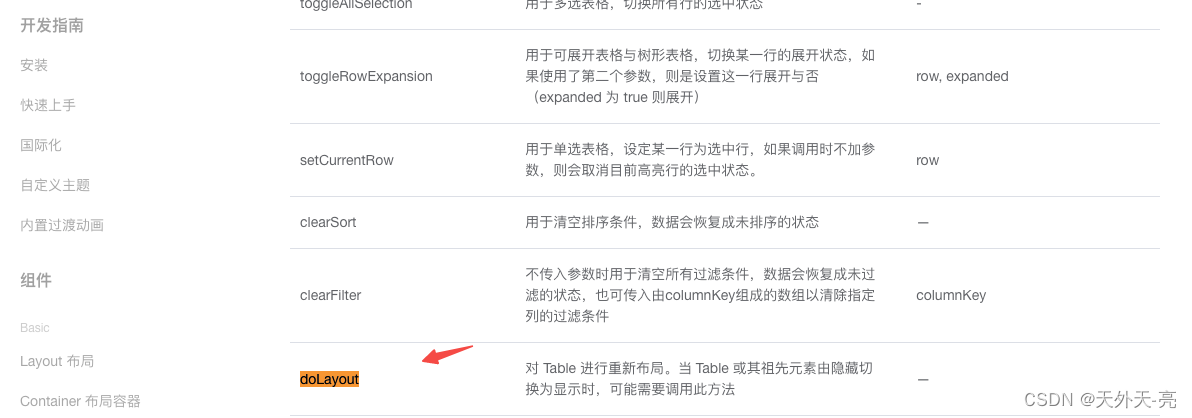
element-table出现错位解决方法
先看示例图,这个在开发中还是很常遇到的,在table切换不同数据时或者切换页面时,容易出现: 解决方法很简单,官方有提供方法: 我们可以在重新渲染数据后: this.$nextTick(() > {this.$refs.…...

DC电源模块具有不同的安装方式和安全规范
BOSHIDA DC电源模块具有不同的安装方式和安全规范 DC电源模块是将低压直流电转换为需要的输出电压的装置。它们广泛应用于各种领域和行业,如通信、医疗、工业、家用电器等。安装DC电源模块应严格按照相关的安全规范进行,以确保其正常运行和安全使用。 D…...
zabbix自定义监控、钉钉、邮箱报警
目录 一、实验准备 二、安装 三、添加监控对象 四、添加自定义监控项 五、监控mariadb 1、添加模版查看要求 2、安装mariadb、创建用户 3、创建用户文件 4、修改监控模版 5、在上述文件中配置路径 6、重启zabbix-agent验证 六、监控NGINX 1、安装NGINX,…...

SAP BW的一些点/常用命令
这是角色需要,字段不用1.请求号:在单子那里创建请求,请求号,此前单子相关数据需要修改;2.用这个请求号,到PFCG角色维护开发,生成参数文件,包入前面的定制请求传输(返回到…...
)
告别MATLAB依赖:手把手教你用Python实现GCC-PHAT时延估计(附完整代码与对比测试)
告别MATLAB依赖:手把手教你用Python实现GCC-PHAT时延估计(附完整代码与对比测试) 在声学信号处理领域,时延估计(Time Delay Estimation, TDE)是许多实际应用的核心技术,从智能音箱的声源定位到工…...

QtScrcpy:解锁跨设备协同的终极方案,实现30ms低延迟投屏
QtScrcpy:解锁跨设备协同的终极方案,实现30ms低延迟投屏 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经遇到过这样的困扰:想要在电脑…...

Windows网络调试神器:5分钟掌握socat-windows端口转发与数据流处理
Windows网络调试神器:5分钟掌握socat-windows端口转发与数据流处理 【免费下载链接】socat-windows unofficial windows build of socat http://www.dest-unreach.org/socat/ 项目地址: https://gitcode.com/gh_mirrors/so/socat-windows 核心关键词…...

5分钟掌握RePKG:轻松提取Wallpaper Engine壁纸资源的开源神器
5分钟掌握RePKG:轻松提取Wallpaper Engine壁纸资源的开源神器 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经为无法提取Wallpaper Engine壁纸包中的精美图片…...

新手首次在Taotoken平台获取API Key并完成模型调用的全指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手首次在Taotoken平台获取API Key并完成模型调用的全指南 对于初次接触大模型API的开发者来说,从注册平台到成功发出…...
)
【独家首发】AISMM模型中文增强版下载:集成工信部AI能力图谱+27项合规性检查项(非公开渠道流出)
更多请点击: https://intelliparadigm.com 第一章:AI成熟度评估工具:AISMM模型下载 AISMM(Artificial Intelligence Software Maturity Model)是由IEEE标准协会支持的开源AI工程化评估框架,聚焦于组织在数…...

如何高效处理大型JSON文件:专业工具使用完整指南
如何高效处理大型JSON文件:专业工具使用完整指南 【免费下载链接】HugeJsonViewer Viewer for JSON files that can be GBs large. 项目地址: https://gitcode.com/gh_mirrors/hu/HugeJsonViewer 在处理数据分析和开发工作中,JSON文件已经成为数据…...

AI专著撰写必备!揭秘高效工具,一键生成20万字专著不是梦!
学术专著写作困境与AI工具解决方案 学术专著的严谨性依赖于大量资料和数据的支持,但资料收集和数据整合常常是写作中最耗时、最艰巨的部分。研究者必须全面查阅国内外的最新文献,确保选用的文献既权威又相关,同时还需追溯到原始资料…...

LookScanned.io终极指南:5分钟学会制作专业扫描PDF的免费神器
LookScanned.io终极指南:5分钟学会制作专业扫描PDF的免费神器 【免费下载链接】lookscanned.io 📚 LookScanned.io - Make your PDFs look scanned 项目地址: https://gitcode.com/gh_mirrors/lo/lookscanned.io 还在为制作扫描版PDF而烦恼吗&…...