脑网络图谱
前言
研究人脑面临的一个挑战是其多尺度组织和系统复杂性。我们对大脑组织的认识主要来源于离体组织学检查,如细胞结构映射。通过研究全脑微观结构特征的变化,可以划分为不同的脑区。然而,这种研究大脑组织的“局部”方法非常耗时、耗资源,更重要的是,它没有考虑到脑区之间的相互作用所产生的脑组织功能性方面。神经成像扫描仪的出现使得我们能够通过观察大量个体之间的脑区间相互作用来研究活体大脑组织。因此,在过去的十年里,大量基于连接特征(特别是基于功能连接)的分区研究应运而生。由于静息态功能磁共振成像(rs-fMRI)相对容易实现,因而静息态脑功能连接(RSFC)有时也被称为“内在连接”,成为大脑分区研究的热门方法。通过对rs-fMRI数据进行矩阵分解,可以划分出许多脑网络和脑区(代表不同尺度的脑组织)。接下来,本文将介绍用于生成脑图谱的主要矩阵分解技术,然后介绍该领域科学发展的重要里程碑,并讨论了脑网络分区的主要限制、挑战和机遇。最后,本文将重点回顾功能性脑图谱的主要应用,特别是机器学习的应用,因为这些方法代表了神经影像领域未来发展的重要方向。
划分脑网络的方法
通过对rs-fMRI在感觉运动网络内的相关性观察,首次发现了可以在静息态下观察到大脑宏观组织特征的证据,因而导致了从rs-fMRI中划分大脑网络或功能系统的不同方法的发展。作为一个高度跨学科的研究领域,功能性脑网络的划分借鉴了图像分割、机器学习和信息论等方法。接下来,将简要介绍几种常用的构建功能脑图谱的方法,包括独立成分分析(ICA)、K均值和图论,并讨论了这些方法的优点和局限性,以及该领域面临的挑战。
独立成分分析(ICA)
ICA在fMRI分析中的应用可以追溯到大约25年前。从技术上讲,ICA是一种在给定的二维矩阵中检测统计独立成分的方法。在fMRI数据的应用中,每个参与者的数据可以表示为(时间点数)×(体素数)的矩阵,ICA将其分解成两个矩阵。第一个矩阵包含每个独立成分的空间映射。第二个矩阵称为混合矩阵,对应于每个成分的时间动态。
虽然ICA的数学表示可能看起来与主成分分析(PCA)和一般线性模型(GLM)相似,但大家需要了解这些模型之间的根本区别。PCA旨在检测捕捉最大数据方差的基础正交方向。然而,ICA识别的是数据中的独立方向,这意味着沿一个方向的概率分布不会影响其他方向。需要注意的是,统计独立性不保证正交性,反之亦然。尽管GLM也将原始数据矩阵建模为两个矩阵的乘积,但回归矩阵通常由研究人员预先设计,例如在任务态fMRI数据分析中的任务设计矩阵。相反,ICA中的混合矩阵是通过优化成分之间的空间独立性来估计的。此外,在rs-fMRI数据中,通常不使用GLM来划分脑网络。
ICA具有明显的优势。它完全是数据驱动的,不需要进行训练过程。人们可以轻松地将其独立应用到新的数据集中。ICA技术在fMRI研究领域相对成熟。例如,软件包FSL(FMRIB软件库)提供了一个名为MELODIC的功能,用于对fMRI体积进行ICA分析(https://fsl.fmrib.ox.ac.uk/fsl/fslwiki/MELODIC)。
然而,由于ICA可以以两种方式识别空间或时间独立成分,因此在将ICA应用于fMRI数据时,关于空间独立性或时间独立性的选择一直存在争议。由于时域ICA没有空间独立性假设,因而会生成具有空间重叠和依赖性的成分。时域ICA的这个特点也有助于检测某些类型的生理噪声,特别是在rs-fMRI中无法通过空间ICA轻易检测到的全局伪影。然而,由于fMRI数据的体素数量通常远大于时间序列的长度,因而时域ICA的计算量较大。此外,在选择空间ICA和时间ICA时需要谨慎,因为这一选择应取决于具体研究设计的假设和数据。
K均值
直观地说,K均值方法旨在将所有数据点划分到K个簇中,从而使类间距离最大化,类内距离最小化。类内距离捕获每个簇中心与该簇中每个数据点之间的平均距离,然后对所有簇进行平均,而类间距离捕获的是每个簇中心与簇的簇中心之间的平均距离。可以使用不同的距离测量方法,例如,任意两个数据点之间的距离可以通过马氏距离(一个特例是欧氏距离)、曼哈顿距离或切比雪夫距离来测量。
当使用K均值算法来识别脑功能网络时,将每个脑体素的时间序列视为一个T维数据点,其中T表示时间点的数量。分类为同一簇的体素被认为具有类似的时间波动,因此被解释为一个单一的功能网络。注意,除了时间序列之外,用于测量距离的每个脑体素的特征还可以包括频域模式或当前体素与其他脑区的功能连接等,具体取决于研究的目的。
然而,K均值算法也有一些限制。首先,需要事先设置聚类数量,这要求研究人员对真实数据结构进行明确的假设。其次,距离度量的选择可能会对聚类结果产生重要影响。最后,K均值算法是一个迭代算法。聚类中心需要初始化才能开始迭代。不幸的是,使用不同的初始化重复相同的算法通常会得到不同的聚类结果。其中一些限制可以通过下面介绍的层次聚类方法来解决。
层次聚类
层次聚类是一类迭代方法,用于构建聚类的层次结构。最常见的聚类算法是从单个数据点开始,在每次迭代中,通过合并上一次迭代中距离最小的一对簇,形成一个新的簇。整个过程通常用树状图来表示(图1B)。树状图中的高度表示连接的聚类可以被分离的程度。换句话说,我们可以通过在树状图中选择一个截止距离来确定聚类的数目。例如,通过将距离阈值设定为4,我们可以从这7个数据点中得到3个聚类:{D,E},{A,B,C}和{F,G}。因此,这种方法绕过了K均值算法的两个问题:初始化聚类中心和预先指定聚类数目。
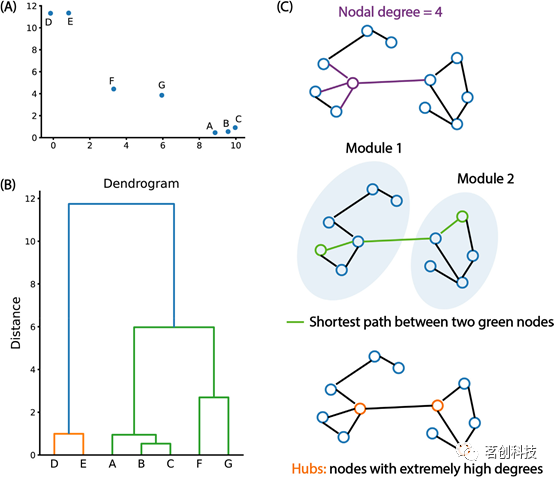
图1.层次聚类示意图。
图论和谱聚类
与其他类型的网络(如社交网络)一样,脑网络也可以采用基于图论的网络科学理论和方法来研究。在网络科学或图论领域,感兴趣的数据被视为由边连接的节点组成的图(图1C)。然后可以研究有关节点连接方式的多种网络属性,例如节点度、聚类系数、最短路径长度、局部/全局效率、模块化、中心性和小世界性。
当图论应用于fMRI数据时,通常将脑区视为图中的节点,而边对应于二值化的功能连接,表示两个区域是否连接。可以使用多种图论方法来划分脑功能网络,例如模块最大化和Infomap算法。模块是一个由相互之间有强连接的节点组成的集合,但与其他模块中的节点连接较弱。相比之下,Infomap算法根据随机游走器在网络中访问每个节点的频率将网络分解为模块。在每一步中,节点转换的方向取决于每对节点之间的连接强度。除了识别功能网络外,图论还被用于研究疾病和发育中的大脑网络变化。
许多研究在功能映射中使用了与图论密切相关的谱聚类。它基于图特征矩阵(如拉普拉斯矩阵)的特征值(即谱)和特征向量对图进行划分。一种常用的谱聚类技术是归一化切割,最初是用于自然图像分割。该算法旨在通过分解最少的边来切割图。谱聚类的一个优点是它能够捕获形状复杂和不连续的聚类,其缺点是分解后的聚类往往大小相等。
该领域的其他方法和挑战
除了上述常用的方法之外,功能图谱还可以使用其他方法来构建,例如区域生长和边缘检测方法。区域生长方法从种子位置(例如,每个皮层体素)开始,并迭代地合并最同质的邻居(例如,那些在fMRI时间序列中具有相似波动的邻居),直到达到预定义的阈值。边缘检测方法基于功能连接的局部梯度来绘制区域边界。这两种方法都生成了空间上不重叠的脑区,这些脑区可以使用其他方法进一步组合成网络。
从机器学习的角度来看,上述模型(例如K均值)被认为是判别模型,其通过构建簇边界来判别观测数据点。相反,生成模型可以通过估计输入(例如fMRI时间序列或功能连接)和输出(例如聚类标签)变量之间的联合概率分布来生成新的数据实例。此外,还使用潜在狄利克雷分配(LDA)来估计允许空间重叠的皮层网络。因此,单个皮层区域可能参与多个网络。LDA最初是为解决文本挖掘问题而开发的,它是一个包含文档、主题和词的三层模型。每对层之间的关系以概率分布为特征,因此一个文档可以包含多个主题,而主题又可以进一步由多个词组成。在大脑分区应用中,这三层对应于整个皮层、网络和皮层区域。
几乎所有这些方法都存在一个共同的问题,即选择“正确”的聚类数/成分数。如果只选择了少数聚类,可能会忽略关键信息。相反,高阶模型可能会过拟合噪声。选择最佳模型阶数的一种方法是采用信息论中的方法,如赤池信息准则和贝叶斯信息准则。这些准则计算了模型复杂度与模型拟合优度之间的权衡,同时考虑了过拟合和欠拟合。另外,还可以使用再现性/稳定性或可靠性测量来选择聚类/成分的数量。类内相关系数是一种常用的可靠性测量指标,常用于估计ICA成分的数量。再现性可以通过调整Rand指数、调整互信息和Dice重叠系数等指标来评估,这些指标可以是通过自举法(或交叉验证)获得的重采样数据,也可以是跨独立数据集的数据。在缺乏“真实分区”的情况下,在不同的数据收集和预处理流程以及聚类技术中,稳定性和再现性对于刻画潜在的神经生物学有效性至关重要。
从个体网络到脑网络图谱
静息态信号中典型网络的搜索
任务正向网络和任务负向网络
根据默认网络的证据,任务正向网络和任务负向网络之间存在反相关关系(见图2)。这是通过检查六个预定义种子区域之间静息态信号的相关性发现的。其中三个区域被指定为“任务正向区域”,因为它们在需要注意力的认知任务中通常显示出活动增加:顶内沟(IPS)、额叶眼区(FEF)和颞中区域(MT+)。相反,内侧前额叶皮层(MPF)、后扣带回/楔前叶(PCC)和外侧顶叶皮层(LP)被认为是“任务负向”区域,因为它们通常在注意力需求任务中表现为活动减少。虽然这些网络的反相关性质引发了激烈的争论,但这项开创性研究为从静息态功能磁共振成像信号中识别支持人类认知的主要功能系统铺平了道路。因此,后续的一些研究旨在利用静息态功能连接脑图(RSFC)来进一步描绘典型网络。

图2.rs-fMRI信号中出现的任务正向网络和任务负向网络以及腹侧和背侧注意网络。
腹侧注意网络、背侧注意网络和额顶控制网络
紧接着,Fox等人(2006)进一步证明在健康参与者的静息态功能磁共振成像(rs-fMRI)数据中可以观察到两种不同的注意系统(见图2),即腹侧和背侧注意系统。这两个系统先前是基于一系列行为学、神经影像学、病变和电生理学研究提出的。因此,该模型指出,在感觉定向过程中的不同注意操作是由两个独立的额顶系统执行的,一个是参与自上而下注意定向的双侧背侧注意系统,另一个是对显著感觉刺激进行注意重定向的右侧腹侧注意系统。Fox等人证明了这些系统可以在静息态信号的自发波动中观察到。他们的研究还揭示了前额叶皮层区域与这两个系统都相关,这表明了调节系统之间功能相互作用的潜在机制。同样,Vincent等人(2008)证明了内在功能连接中存在额顶控制系统,该网络位于背侧注意系统和海马-皮质记忆系统之间。因此,在对健康参与者样本的内在连接研究中,出现了关于大脑控制和注意网络组织的略有不同但密切相关的概念化。
默认模式网络
同样,默认模式网络(DMN)的概念也可以通过检查健康参与者中DMN区域的图论和聚类功能连接属性来进一步细化。这样一来,Andrews-Hanna等人(2010)提出了两个DMN子网络。与先前的研究一致(例如Buckner等人(2009)),PCC和aMPFC(前内侧前额叶皮层)是具有高中心性的关键枢纽,而其他DMN区域可以分为两个不同的子系统。一个由dMPFC(背内侧前额叶皮层)、颞顶交界处(TPJ)、外侧颞皮层(LTC)和颞极(TempP)组成的“背内侧前额叶(dMPFC)子系统”,另一个是由腹侧MPFC(vMPFC)、后下顶叶(pIPL)、脾后皮层(Rsp)、海马旁回(PHC)和海马结构(HF+)组成的“内侧颞叶(MTL)子系统”。通过任务fMRI实验进一步证明了这两个子网络与人类认知的相关性。
数据驱动的RSFC网络分区
典型网络分区
通过证实和进一步表征核心脑网络,静息态功能磁共振成像(rs-fMRI)确立了其在脑组织研究中的有效性。继相对假设驱动的研究之后,通过将大脑皮层划分为一定数量的网络,开发了若干脑网络图谱。其中最受欢迎和广泛使用的图谱之一是Yeo等人(2011)研究中的图谱。作者确定了7个主要网络(见图3),包括相对局部的网络(如视觉和躯体运动网络),以及相对分布式的一般关联网络。后者包括边缘网络,以及旁边缘网络(如DMN、背侧注意、腹侧注意和额顶叶网络),这与先前的研究报告一致。
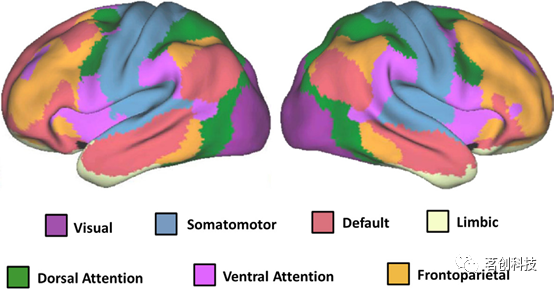
图3.七大典型网络。
在类似的观点中,Power等人(2011)研究了脑区之间高RSFC分布模式中对应于功能网络的图和子图。他们表明先前报告的“任务正向系统”实际上由多个子图组成,包括背侧注意力网络、额顶任务控制网络和扣带-岛盖任务控制网络。因此,尽管使用不同的方法和样本,这两项里程碑式的研究显示了高度一致的结果,从而强调了RSFC模式中存在稳健的功能网络,如双侧分布的视觉、感觉运动、默认模式和注意力网络。
脑网络图谱的应用
通过提供大规模网络和脑区的可靠定义,功能图谱已被广泛应用于各种研究中。而且,一些主要的功能图谱已被用于临床研究,以确定患者的特定功能障碍,以及研究儿童时期的脑组织和衰老过程中的功能连接变化。这些图谱也被广泛应用于认知神经科学中,以更好地理解脑网络和区域的功能以及个体的行为差异。同样,它们也被用来更好地了解大脑组织的遗传负荷,以及研究特定环境条件对大脑功能的影响,如睡眠剥夺的影响。使用这些图谱的优势是它提供了一个共同的框架来比较不同研究中的发现,并在不同研究领域中进行整合。
机器学习方法与典型网络
当利用具有严格交叉验证的机器学习方法时,从应用研究问题的同一数据集中推导网络变得更加棘手。在交叉验证中,数据集被划分为训练集和测试集。模型(例如,使用线性模型从RSFC预测智力得分)是在训练数据上进行开发的,并在测试样本中进行测试(从而检验在未知样本中智力分数预测的准确性)。这个将数据随机分割成训练集和测试集的过程通常重复有限次。然后通过汇总(例如平均)在测试集上的样本外精度来评估模型的泛化能力。在这样的框架下,训练集和测试集不应共享任何信息。因此,用于预测模型的特征的网络在交叉验证之前不应该作为过早的特征提取计算出来。换句话说,不能在将用于测试模型的数据集上定义网络。在这种情况下,功能性大脑图谱代表了一种宝贵的资源,提供了稳定且经过验证的网络,可用于机器学习模型中。
从教学的角度来看,可以区分两种类型的机器学习方法:预测方法和多元关联方法(或“双重多元方法”)。脑网络图谱经常被用于这两种方法。在预测方法的框架下,脑网络图谱可用于将参与者分组,例如基于脑功能连接将患者进行分类。此外,一些研究使用这些图谱来预测RSFC的行为指标。此外,一些研究使用“双重多元方法”将脑功能连接与一系列非脑变量(特别是行为变量)进行了关联研究。
健康和临床人群中基于连接的预测方法
预定义的脑图谱和网络结构表征了人脑的功能组织,为下游分析提供了实用工具,包括预测健康人群的心理测量指标以及预测精神障碍患者的症状等。一项利用RSFC在健康人群中预测个体行为得分(如流体智力)的开创性研究使用了Shen图谱和Yeo等人(2011)推导的网络。后来提出了一种基于跨预定义功能区域计算的连接组的行为预测协议,并变得非常流行。受这些工作的启发,出现了一系列研究,主要是持续注意力和创造力等特定认知测量的预测,研究不同预处理策略和算法对预测能力的影响,探索特征对预测不同类别心理测量的重要性,或比较休息、任务和自然模式下fMRI的预测能力。重要的是,这些研究利用了来自rs-fMRI或包括fMRI在内的多模态数据的几个预定义的脑图谱,以计算功能连接作为脑特征。
此外,这些脑图谱不仅在预测健康个体的行为上发挥了重要作用,而且在预测患者的疾病症状上起到了关键作用。例如,基于Power图谱,功能连接能够在孤独症谱系障碍(例如,社交自闭症特征)的纵向预测结果中提供额外的预测能力。利用从相同脑图谱计算出的功能连接,研究人员还考察了强迫症患者治疗反应的可预测性。这对于识别出哪些患者可能从治疗中获益更多的能力对于个性化医疗具有重要意义。此外,从Craddock图谱中提取的背内侧前额叶皮层区域的功能连接能够预测重复经颅磁刺激治疗抑郁症的效果。总的来说,功能图谱是提取功能脑特征、预测症状严重程度和治疗结果的重要工具,这有助于未来精准医疗的发展。
多元关联方法中的连接性
除了基于机器学习算法的预测模型外,还可以使用多元关联模型(如典型相关分析(CCA)和偏最小二乘(PLS))来探索大脑与行为、心理测量或人口统计学指标之间的关系。这些研究可以称为“全脑关联研究”(BWAS)。在健康参与者和精神分裂症、分裂情感性障碍、双相情感障碍和注意缺陷/多动障碍患者中,观察到与一般精神病理学、认知功能障碍和冲动相对应的三个跨诊断成分与根据Schaefer图谱计算出的全脑功能连接模式相关,尤其是在躯体感觉-运动网络中(见图4)。此外,基于Gordon图谱提取功能连接的研究也检验了BWAS的重现性。因此,在全脑关联研究中,脑网络图谱是表征神经影像特征的重要资源。
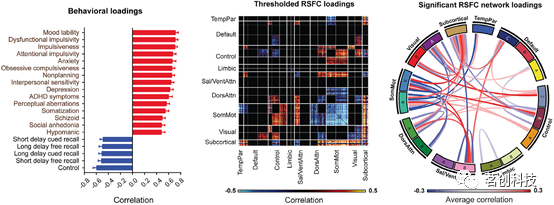
图4
脑网络图谱的特征降维和其他方法
正如前文所述,一系列利用机器学习方法将功能连接与临床和行为特征联系起来的研究都利用了从rs-fMRI数据中获得的功能图谱。无论这些图谱是表示主要的典型网络还是局部脑区,它们都可以在比原始体素或顶点数据更低的维度空间中表示RSFC数据,这对于上述任何多变量分析都至关重要。换句话说,它们提供了一种独立于分析数据的特征降维方法。对于神经成像数据来说,这种特征降维通常是必需的(例如,在体素水平计算功能连接将导致数十万个体素的成对连接矩阵)。除了计算复杂度高之外,这种高维数据对许多机器学习模型来说也是个问题。例如,特征数量与观测数量之间的比例已被证明会显著影响双重多元分析(如典型相关分析)的可靠性。因此,功能图谱对于神经影像中的机器学习研究非常重要,它提供了一种已被广泛评估的神经生物学特性的数据表征,因此可以作为各项研究的参考框架。
除了基于静息态功能连接(RSFC)的功能图谱之外,基于任务相关的功能磁共振成像(fMRI)和正电子发射断层扫描(PET)研究的元分析方法也提供了稳健的功能网络。元分析连接建模提供了在一系列神经影像学研究中一致共激活的脑区网络。此外,元分析方法也可以应用于神经成像研究,以识别与特定认知概念相关的常见激活脑区。因此,可以假设所得到的脑区集合形成了支持所研究的认知过程或功能的网络(例如自传体记忆、工作记忆或运动功能)。因此,这些网络可以用于研究RSFC和行为表型之间的关系。因此,利用元分析网络的研究可以与利用RSFC的经典网络的研究相结合,从而更好地理解RSFC的个体间变异与行为个体间变异之间的关系。
结论
目前已有多种技术基于静息态功能磁共振成像(rs-fMRI)数据来描绘脑网络和划分脑功能区域。这些技术很好地补充了以前从宏观组织特征的组织学研究中获得的局部组织知识,从而有助于更好地理解大脑的组织和功能。然而,无论使用何种技术,在考虑大脑的多尺度组织时,如何选择数据分解的最佳成分数量仍然是一个挑战。考虑到这种复杂性,目前已有多个不同细分级别的图谱可用。然而,常用功能图谱中提供的典型网络仍然是神经影像研究中的一个重要资源,它为跨研究的可重复性和更好地理解健康和临床人群的大脑和行为之间的关系提供了一个参考框架。此外,这些图谱为机器学习方法的应用提供了有用的大脑特征表示,从而有助于基于大脑的个性化医疗预测的发展。在这一框架下,更好地理解和解决脑功能组织以及脑图谱的个体差异是未来研究的一个重要方向。
参考文献:Sarah Genona,b & Jingwei Li., Brain networks atlases.(2023) P:59-85.
相关文章:
脑网络图谱
前言 研究人脑面临的一个挑战是其多尺度组织和系统复杂性。我们对大脑组织的认识主要来源于离体组织学检查,如细胞结构映射。通过研究全脑微观结构特征的变化,可以划分为不同的脑区。然而,这种研究大脑组织的“局部”方法非常耗时、耗资源&a…...

无涯教程-JavaScript - SQRTPI函数
描述 SQRTPI函数返回(number * pi)的平方根。 语法 SQRTPI (number)争论 Argument描述Required/OptionalNumberThe number by which pi is multiplied.Required Notes If the specified number < 0, SQRTPI returns the #NUM! error value.如果指定的数字为非数字,则S…...
——命名空间(Namespace)、配置分组(Group)和配置集ID(Data ID))
Nacos使用教程(四)——命名空间(Namespace)、配置分组(Group)和配置集ID(Data ID)
文章目录 Nacos命名空间(Namespace)一、什么是命名空间二、命名空间的作用1. 隔离环境2. 分类管理3. 权限控制 三、命名空间的使用四、总结 Nacos配置分组(Group)一、什么是配置分组二、配置分组的作用1. 分类管理2. 隔离控制3. 动…...

三、双指针(two-point)
文章目录 一、算法核心思想二、算法模型(一)对撞指针1.[704.二分查找](https://leetcode.cn/problems/binary-search/)(1)思路(2)代码(3)复杂度分析 2.[15.三数之和](https://leetco…...

Redis 是什么和使用场景概述(技术选型)
一、Redis 是什么 Redis是一款开源的高性能键值存储系统。它支持多种数据结构,如字符串、列表、集合、哈希表、有序集合等,并提供了丰富的操作命令和功能。Redis的主要特点包括: 内存存储:Redis将数据存储在内存中,因此…...

【数据结构】七大排序
文章目录 💐1. 插入排序🌼1.1 直接插入排序🌼1.2 希尔排序 💐2. 选择排序🌼2.1 直接选择排序🌼2.2 堆排序 💐3. 交换排序🌼3.1 冒泡排序🌼3.2 快速排序🌼3.2.…...

区块链实验室(24) - FISCO网络重构
若干次实验以后,FISCO网络中100个节点堆积了不少交易记录,消耗不少磁盘空间,见下图所示,100个节点累计消耗了10G空间。 观察每个节点的磁盘消耗,以node88为例,消耗了107MB,见下图所示。在该节点…...
AI智能写作工具有哪些?永久免费的AI智能写作工具你使用过吗?
AI智能写作是指借助人工智能技术,计算机程序可以自动生成各种文本内容,包括新闻报道、广告文案、科技文章、小说等等。这些AI写作工具通过大数据和深度学习模型,能够分析和模仿人类的写作风格,生成高质量的文本,甚至有…...

23.8.15 杭电暑期多校9部分题解
1002 - Shortest path 题目大意 对于一个数 x x x,可以进行以下三种操作: 1.将 x x x 变成 2 ∗ x 2*x 2∗x 2.将 x x x 变成 3 ∗ x 3*x 3∗x 3.将 x x x 变成 x 1 x1 x1 给定一个数 n n n,问最少操作几次才能将 1 1 1 变成…...

四个BY的区别 HIVE中
在Hive中,有四个BY比较:Order By、Sort By、Distribute By和Cluster By。 Order By是全局排序,只有一个Reducer。它可以按照升序(ASC)或降序(DESC)对结果进行排序。Order By子句通常用在SELECT语…...

计时函数与float32 float16 int8 数据转换
个人整理常用 部分来自 ncnn 计时函数 // window 平台 #include <windows.h>double get_current_time() {LARGE_INTEGER freq; // 频率LARGE_INTEGER pc; // 计数QueryPerformanceFrequency(&freq);QueryPerformanceCounter(&pc);return pc.QuadPart * 1000…...

自身免疫疾病诊断原料——博迈伦
自身免疫疾病是一类由免疫系统攻击正常组织和器官而引起的疾病。为了准确地诊断和监测自身免疫疾病,需要使用特定的诊断原料来进行实验室检测。这些诊断原料主要包括抗体试剂、抗原试剂和试剂盒等。 抗体试剂是用于检测和定量分析体内免疫系统产生的抗体的化学试剂。…...
cpu温度监测 Turbo Boost Switcher Pro for mac最新
Turbo Boost Switcher Pro是一款Mac电脑上的应用程序,旨在帮助用户控制和管理CPU的Turbo Boost功能。Turbo Boost是Intel处理器中的一项技术,可以在需要更高性能时自动提高处理器的频率。然而,这可能会导致电池消耗更快和温度升高。 以下是T…...

spring 请求 出现实体类大小写不一致 出现的问题
目录 1.问题背景 2.解决方法 但是会存在返回的既有大写也有小写的问题,需要在get方法也添加对应的注解 3.相关资料 1.问题背景 因数据库某字段存储的为json 格式,且数据库字段要求都有客户指定,因为该功能需要和其他项目进行对接。然后出现…...

zaabix实现对nginx监控
本文使用监控模板net.tcp.listen[port]实现监听端口 实验环境: 首先搭建好zabbix-server ,zabbix-agenthttps://mp.csdn.net/mp_blog/creation/editor/132622769?spm1001.2014.3001.9457 而后在zabbix-agent主机上下载一个nginx 登录zabbix网站创建主…...

基于AI视觉的表面缺陷检测设备优势显著,加速制造业数智化转型
作为生产制造过程中不可缺少的一步,表面缺陷检测广泛应用于工业领域,包括3C电子、芯片半导体、食品医药、木材等行业。但随着智能化进程加快,制造工厂生产线的质量检测压力加剧,传统人工表面缺陷检测已经无法满足当前社会较高的检…...
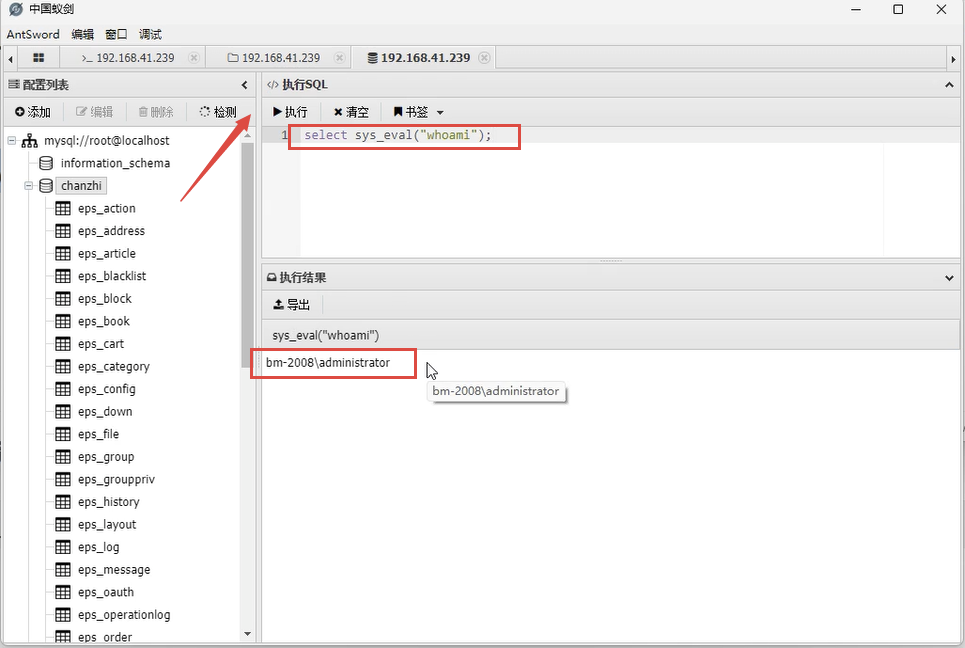
操作系统权限提升(二十六)之数据库提权-MySQL UDF提权
MySQL UDF提权 MySQL介绍 MySQL是最流行的开放源码SQL数据库管理系统,相对于Oracle,DB2等大型数据库系统,MySQL由于其开源性、易用性、稳定性等特点,受到个人使用者、中小型企业甚至一些大型企业的广泛欢迎,MySQL具有…...

基于 IntelliJ 的 IDE 将提供 Wayland 支持
导读对于使用 IntelliJ 开发环境的用户,JetBrains 一直致力于提供原生 Wayland 支持。 JetBrains 正在致力于为基于 IntelliJ 的 IDE 提供 Wayland 支持,以增强 Linux 桌面体验以及在 Windows Subsystem for Linux 下运行。 Wayland 支持功能尚未完成&…...
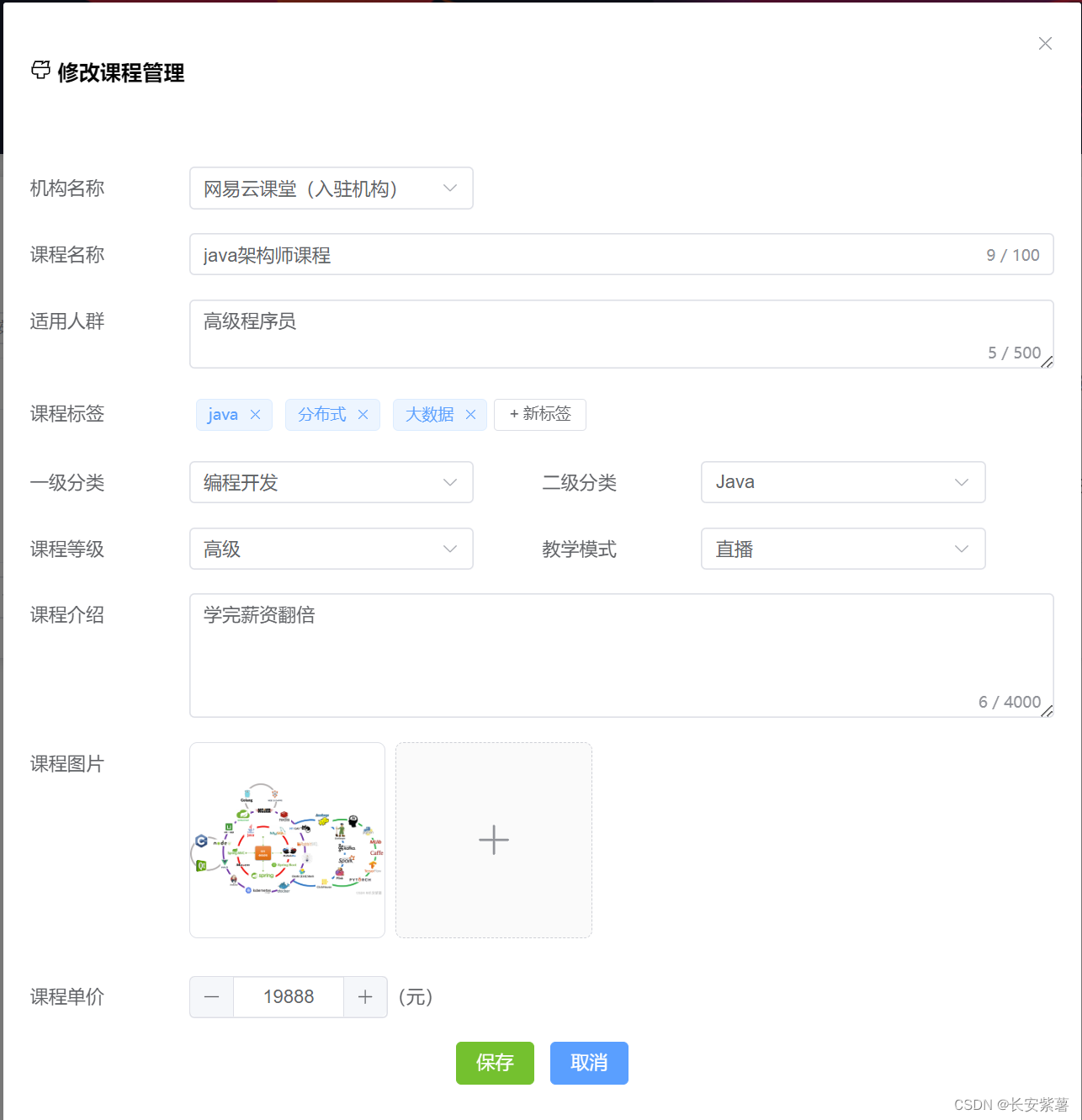
誉天在线项目~ElementPlus Tag标签用法
效果图 页面展现 <el-form-item label"课程标签"><el-tagv-for"tag in dynamicTags":key"tag"class"mx-1"closable:disable-transitions"false"close"handleClose(tag)"style"margin:5px;">…...

iText实战--Table、cell 和 page event
5.1 使用表和单元格事件装饰表 实现PdfPTableEvent 接口 实现PdfPCellEvent 接口 合并表格和单元格事件 5.2 基本构建块的事件 通用块(Chunk)功能 段落(Paragraph)事件 章节(Chapter)和 区域(…...
)
手把手教你用STM32的编码器模式,精准读取JGB37-520电机转速(附TB6612驱动配置)
基于STM32编码器模式实现JGB37-520电机闭环控制实战指南 在智能硬件开发领域,精确控制电机转速和位置是实现高质量运动控制的基础。JGB37-520作为一款带有霍尔编码器的减速电机,配合TB6612驱动模块,可以构建完整的闭环控制系统。本文将深入解…...

6G通信中的HMA天线技术:原理、优势与应用
1. HMA天线技术概述在6G通信和大规模MIMO系统的发展背景下,Huygens Metasurface Antennas(HMA)技术正逐渐成为无线通信领域的研究热点。作为一名长期从事天线系统设计的工程师,我见证了从传统相控阵到现代超表面天线的技术演进历程…...

Prodigal基因预测工具:3天快速掌握原核生物基因发现终极指南
Prodigal基因预测工具:3天快速掌握原核生物基因发现终极指南 【免费下载链接】Prodigal Prodigal Gene Prediction Software 项目地址: https://gitcode.com/gh_mirrors/pr/Prodigal 你是否正在寻找一款快速、准确的原核生物基因预测工具?Prodiga…...

Vue-clipboard2 错误处理指南:如何优雅处理复制失败情况
Vue-clipboard2 错误处理指南:如何优雅处理复制失败情况 【免费下载链接】vue-clipboard2 A simple vue2 binding to clipboard.js 项目地址: https://gitcode.com/gh_mirrors/vu/vue-clipboard2 Vue-clipboard2 是一款简单的 Vue2 绑定 clipboard.js 的插件…...

NovelReader插件化扩展指南:如何添加新的翻页效果
NovelReader插件化扩展指南:如何添加新的翻页效果 【免费下载链接】NovelReader 仿照"任阅"的追书、看书的小说阅读器。重写"任阅"的代码,优化代码逻辑和代码结构,降低内存使用率。重写小说阅读器,支持网络阅…...

Tunasync镜像同步工具:清华大学TUNA团队的高效解决方案
Tunasync镜像同步工具:清华大学TUNA团队的高效解决方案 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync是清华大学TUNA团队开发的一款专业镜像同步管理工具,为开源社区提…...

BetterDiscord Installer完全指南:如何一键安装和优化Discord插件
BetterDiscord Installer完全指南:如何一键安装和优化Discord插件 【免费下载链接】Installer A simple standalone program which automates the installation, removal and maintenance of BetterDiscord. 项目地址: https://gitcode.com/gh_mirrors/ins/Instal…...
)
【C++】类和对象( 类的定义、实例化、 this指针、 C++和C语言实现Stack对比)
小编主页详情<-请点击 小编gitee代码仓库<-请点击 本文主要介绍了类和对象( 类的定义、实例化、 this指针、 C和C语言实现Stack对比),内容全由作者原创(无AI),并带有配图帮助博友们更好的理解&#x…...
)
用Python和Matplotlib搞定高光谱图像可视化:从.mat文件到伪彩色图(附完整代码)
PythonMatplotlib高光谱图像可视化实战:从.mat文件到伪彩色合成 高光谱图像处理正逐渐从专业遥感领域走向更广泛的工业应用场景。当一位农业科技公司的算法工程师第一次拿到作物生长监测的高光谱数据时,面对.mat格式文件中那个神秘的三维矩阵,…...

TI AM64x 5路原生千兆网口:工业物联网确定性网络与多核异构计算实战
1. 项目概述:为什么我们需要5路原生千兆网口?在工业现场摸爬滚打十几年,我见过太多因为网络接口“捉襟见肘”而导致的尴尬局面。想象一下,一个产线控制柜里,PLC、视觉系统、多台伺服驱动器、HMI触摸屏,还有…...