Scapy 解析 pcap 文件从HTTP流量中提取图片
Scapy 解析 pcap 文件从HTTP流量中提取图片
- 前言
- 一、网络环境示例
- 二、嗅探流量示例
- 三、pcap 文件处理
- 最后
- 参考
作者:高玉涵
时间:2023.9.17 10:25
环境:Linux kali 5.15.0-kali3-amd64,Python 3.11.4,scapy 2.5.0
只有在拿到一些数据之后事情才会变得有趣起来。
前言
通常我在网络嗅探与数据包分析中,使用 Wireshark 就可以很方便地浏览 pcap 文件的内容。但当捕获得流量很大或数据包特征不太明显,再或者数据包特征已确定,要从中进一步分析(提取)流量。以往采用人工方式可以说是种恶梦。幸运的是 Philippe Biondi 为 Python 开发的数据包处理库 Scapy 以精巧和令人惊叹,一两行代码就能解决上述问题(功能远远不止如此)。这里我会演示如何借助 Scapy 的 pcap 数据处理能力,从嗅探到的 HTTP 流量中提取图片。
建议你在 Linux 上使用 Scapy,因为它最初就是按照兼容 Linux 来设计的。最新版本的 Scapy 虽然支持 Windows,但是我假设你使用的和我一样的环境。
一、网络环境示例

图 1-1 网络架构
二、嗅探流量示例
为了感受一下 Scapy 的用法,我先给出用 Wireshark 嗅探的流量,图 2-1 是原始流量样式,图 2-2 为指定一个数据包过滤器(这里是 HTTP)表示要进一步分析的流量。

图 2-1 原始流量样式

图 2-2 HTTP 流量样式
三、pcap 文件处理
我会试着从 HTTP 流量中提取出图片文件,为此编写分析 pcap 文件的 recapper.py 程序,定位数据流中出现的所有图片,并把它们保存到磁盘上。在接下来的代码中,我将用到 namedtuple(命名元组),它是 Python 的一种数据结构,可以通过名称来访问某个字段。标准的元组(tuple)是用来存储一串不可变的值的,跟列表(list)差不多,只是没法修改里面的数据。使用标准元组时,要用数字索引来访问其内部的字段:
point = (1.1, 2.5)
print(point[0], point[1])
要命名元组跟标准元组基本相同,唯一的区别是可以通过属性名来访问它的字段。它能让你写出可读性更高的代码,却又比字典(dictionary)
消耗的内存更少。创建命名元组需要两个参数:元组本身的名字,以及由逗号分隔的若干字段名。举个例子,假设你想定义一个名为 Point 的数据结构,它有两个属性:x 和 y。你可以这样定义:
Point = namedtuple('Point', ['x', 'y'])
接着你可以创建一个,比方说叫 p 的 Point 命名元组,p = Point(35, 65),然后使用 p.x 和 p.y 来访问它的 x 和 y 属性,就像是在访问一个类的属性一样。这比使用一堆数字索引来访问标准元组要好懂得多。在接下来的示例代码中,我们将创建一个名为 Response 的命名元组:
Response = namedtuple('Response', ['header', 'payload'])
现在,无须用数字索引,直接用 Response.header 和 Response.payload 就能访问 Response 的成员数据,大大改善了代码的可读性。
接下来是 recapper.py 文件,代码如下:
from scapy.all import TCP, rdpcap
import collections
import os
import re
import sys
import zlibOUTDIR = '/home/kali/dev/python/scapy/pic'
PCAPS = '/home/kali/dev/python/scapy'Response = collections.namedtuple('Response', ['header', 'payload'])def get_header(payload):passdef extract_content(Response, content_name='image'):passclass Recapper:def __init__(self, fname):passdef get_responses(self):passdef write(self, content_name):passif __name__ == '__main__':pfile = os.path.join(PCAPS, 'face.pcap')recapper = Recapper(pfile)recapper.get_responses()recapper.write('image')
这是整个脚本的主要框架,之后我会往里面填充辅助函数。首先,导入所需的库,然后指定保存图片的目录和 pcap 文件的路径。接着,定义一个名为 Response 的命名元组,它有两个属性:数据包的头(header)和载荷(payload)。我编写两个辅助函数,分别负责获取数据包头和提取数据包内容。这两个函数将用在 Recapper 类里,而这个类负责重构在数据包流中出现过的图片。除了 __init__ 函数外,Recapper 类还有两个函数:get_responses,负责从 pcap 文件中读取响应数据;write,负责把在响应数据中找到的图片写到输出目录里。
现在我开始写 get_header函数:
def get_header(payload):try:header_raw = payload[:payload.index(b'\r\n\r\n')+2]# 切片前包后不包,+2 是为了将分隔数据行的'\r\n'也含进去except ValueError:sys.stdout.write('-')sys.stdout.flush()return Noneheader = dict(re.findall(r'(?P<name>.*?):(?P<value>.*?)\r\n', header_raw.decode()))if 'Content-Type' not in header:return Nonereturn header
get_header函数会读取原始 HTTP 流量,并把 HTTP 头数所单独切出来。我提取 HTTP 头的方式是,从数据包开头一路往下找两个连续的 “\r\n”,把这整段数据切出来。图 3-1 HTTP 报文结构。图 3-2 真实示例。

图 3-1 HTTP 报文结构

图 3-2 真实示例
如果拿到的数据里不存在两个连续的 ”\r\n“,就会产生一个 ValueError 异常,这时我只会在屏幕上输出一个横杠(-),然后返回。如果没有发生异常,我就创建一个名为 header 的字典,把 HTTP 头里的每一行以冒号分割,冒号左边的是字段名,右边的是字段值,按这样的方式存进 header 字典里。如果 HTTP 头里面没有名为 Content-Type 的字段(图 3-3 Content-Type 字段),就返回 None,表示数据包里没有我感兴趣的内容。现在写一个函数,从响应数据里提取内容:
def extract_content(Response, content_name='image'):content, content_type = None, Noneif content_name in Response.header['Content-Type']:content_type = Response.header['Content-Type'].split('/')[1]content = Response.payload[Response.payload.index(b'\r\n\r\n')+4:]if 'Content-Encoding' in Response.header:if Response.header['Content-Encoding'] == 'gzip':content = zlib.decompress(Response.payload, zlib.MAX_WBITS | 32)elif Response.header['Content-Encoding'] == 'deflate':content = zlib.decompress(Response.payload)return content, content_type
extract_content函数会接受一段 HTTP 响应数据(Response),以及我想提取的数据类型的名字作为参数。这段响应数据是一个命名元组,里面有两部分:header 和 payload。
如果检测到响应数据被 gzip 或 deflate 之类的工具压缩过,就调用 zlib 库来解压这段数据。任何一个含有图片的响应包,其数据头的 Content-Type 属性里都会有 image 字样(图 3-3)。遇到这种数据头,我就创建一个 content_type 变量,将数据头里指定的实际数据类型保存下来。我还创建另一个变量 content 来保存数据内容,也就是 payload 中 HTTP 头之后的全部数据。最后,将 content 和 content_type 打包成一个元组返回。

图 3-3 Content-Type 字段
写完这两个辅助函数后,就可以开始编写 Recapper 类了:
class Recapper:def __init__(self, fname):pcap = rdpcap(fname)self.sessions = pcap.sessions()self.responses = list()
首先,初始化这个对象,把要读取的 pcap 文件路径传给它。接着我用到 Scapy 的一个美妙功能,自动切分每个 TCP 会话,并保存到一个字典里,字典里面的每个会话都是一段完整的 TCP 数据流。最后,创建一个名为 responses 的空列表,之后我会把在 pcap 文件中读到的响应填进去。
get_responses函数会遍历整个 pcap 文件,将找到的每个单独的 Response 都填入刚才的 responses 列表:
def get_responses(self):for session in self.sessions:payload = b''for packet in self.sessions[session]:try:if packet[TCP].dport == 80 or packet[TCP].sport == 80:payload += bytes(packet[TCP].payload)except IndexError:sys.stdout.write('x')sys.stdout.flush()if payload:header = get_header(payload)if header is None:continueself.responses.append(Response(header=header, payload=payload))
get_responses函数先遍历整个 sessions 字典中的每个会话,以及每个会话中的每个数据包。然后过滤这些数据,只处理发往 80 端口或者从 80 端口接收的数据。接着,把从所有流量中读取到的数据载荷,拼接成一个单独的名为 payload 的缓冲区。这个操作相当于在 Wireshark 中右键单击一个数据包,选择”Follow TCP Stream“选项(图 3-4)。如果没能成功地拼接 payload 缓冲区(最有可能的情况是,数据包里没有出现 TCP 数据),就在屏幕上打印一个 ”x" 然后继续。

图 3-4 Follow TCP Steram
重组 HTTP 数据后,如果 payload 缓冲区里有数据,就把它交给解析 HTTP 头的函数 get_header,它能帮我逐个检查 HTTP 头的内容。然后,把构造出的 Response 对象附加到 responses 列表里。
最后,遍历整个 responses 列表,如果发现任何含有图片的响应,就用 write 函数将这些图片写到磁盘上:
def write(self, content_name):for i, response in enumerate(self.responses):content, content_type = extract_content(response, content_name)if content and content_type:fname = os.path.join(OUTDIR, f'ex_{i}.{content_type}')print(f'Writeing {fname}')with open(fname, 'wb') as f:f.write(content)
由于我已经提取完所有响应,所以 write 函数只需要遍历这些响应,提取其中的内容,并将内容写到一个文件里就可以了。这个文件会被创建到指定的输出目录里,文件名由 enumerate 函数提供的计数和 content_type 两个值拼接而成,例如 ex_2.jpg 就是一个可能出现的图片文件名。当我运行这个程序时,会创建一个 Recapper 对象,调用它的 get_responses 函数来搜索 pcap 文件中的所有响应,然后将提取出的图片写入磁盘。图 3-5。图 3-6.

图 3-5 程序执行样式

图 3-5 提取的图片
最后
当然,你也可以进一步拓展这个程序,让它不仅能从 pcap 文件中提取图片。
参考
- Scapy
- HTTP 标头
相关文章:
Scapy 解析 pcap 文件从HTTP流量中提取图片
Scapy 解析 pcap 文件从HTTP流量中提取图片 前言一、网络环境示例二、嗅探流量示例三、pcap 文件处理最后参考 作者:高玉涵 时间:2023.9.17 10:25 环境:Linux kali 5.15.0-kali3-amd64,Python 3.11.4,scapy…...
难得有个冷静的程序员发言了:纯编码开发实施的项目,失败的案例也有很多
难得有个冷静的程序员发言了:纯编码开发实施的项目,失败的案例也有很多。假如用低代码实施,能达到不失败或提高成功率,对软件开发项目交付,会是重大的价值。 我的观点:两者都可能失败,不同的是&…...

Leetcode.146 LRU 缓存
题目链接 Leetcode.146 LRU 缓存 mid 题目描述 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 c a p a c i t y capacity capacity 初始化 LRU 缓存int get(int key) 如果关键…...

科技资讯|Canalys发布全球可穿戴腕带设备报告,智能可穿戴增长将持续
市场调查机构 Canalys 近日发布报告,表示 2023 年第 2 季度全球可穿戴腕带设备出货量达 4400 万台,同比增长了 6%。 主要归功于其亲民的价格以及消费者对价位较高的替代品仍持谨慎态度,基础手环市场尽管与去年同期相比有所下降,…...

使用https接口,无法调通接口响应不安全
网页pc使用不安全https 页面提示不安全–点击高级–跳过 接口使用部安全https 无法像页面一样可以跳过 方法:安装证书 还是无法响应报错不安全: 1、确定证书绑定ip还是域名(ip和域名都可以绑定) 使用的是httpsip,报…...

uniapp开发h5,解决项目启动时,Network: unavailable问题
网上搜了很多,发现都说是要禁用掉电脑多余的网卡,这方法我试了没有好,不晓得为啥子,之后在网上看,uniapp的devServer vue2的话对标的就是webpack4的devserver(除了复杂的函数配置项),…...

9.17 校招 实习 内推 面经
绿泡*泡: neituijunsir 交流裙 ,内推/实习/校招汇总表格 1、自动驾驶一周资讯 - 一汽与Mobileye 签署战略合作,小鹏汽车将用经销商销售逐渐替换直营模式,原小鹏汽车副总裁加盟赛力斯 自动驾驶一周资讯 - 一汽与Mobileye 签署战…...

【Python小项目之Tkinter应用】随机点名/抽奖工具大优化:新增查看历史记录窗口!语音播报功能!修复预览文件按钮等之前版本的bug!
文章目录 前言一、实现思路二、关键代码查看历史记录按钮语音播报按钮三、完整代码总结前言 老生常谈,先看效果:(订阅专栏可获取完整代码) 初始状态下,我们为除了【设置】外的按钮添加弹窗,提示用户在使用工具之前要先【设置】。在设置界面,我们主要修改了【预览文件】…...
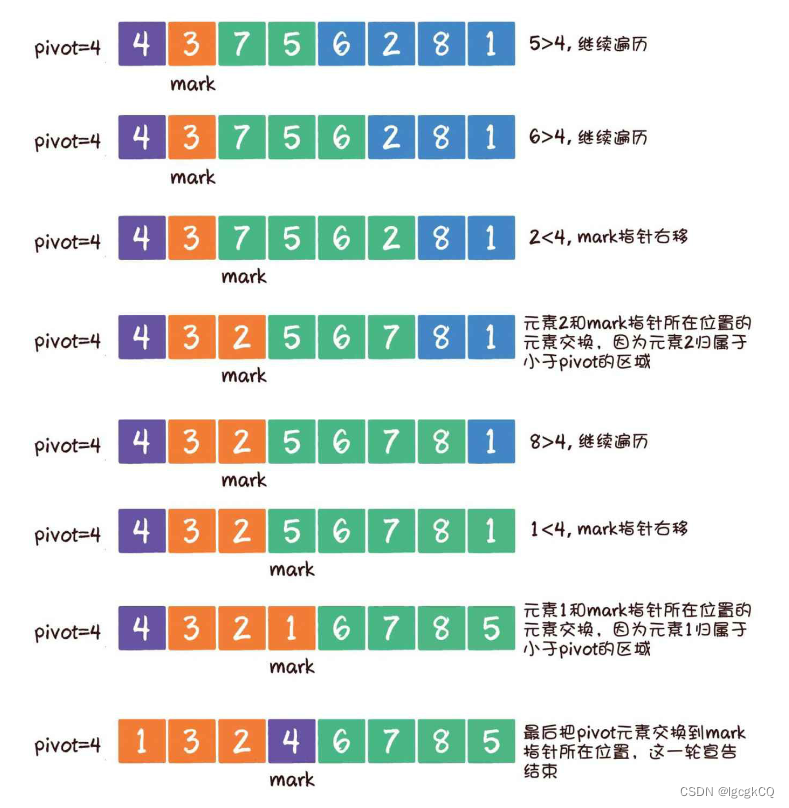
数据结构与算法:排序算法(1)
目录 冒泡排序 思想 代码实现 优化 鸡尾酒排序 优缺点 适用场景 快速排序 介绍 流程 基准元素选择 元素交换 1.双边循环法 使用流程 代码实现 2.单边循环法 使用流程 代码实现 3.非递归实现 排序在生活中无处不在,看似简单,背后却隐藏…...
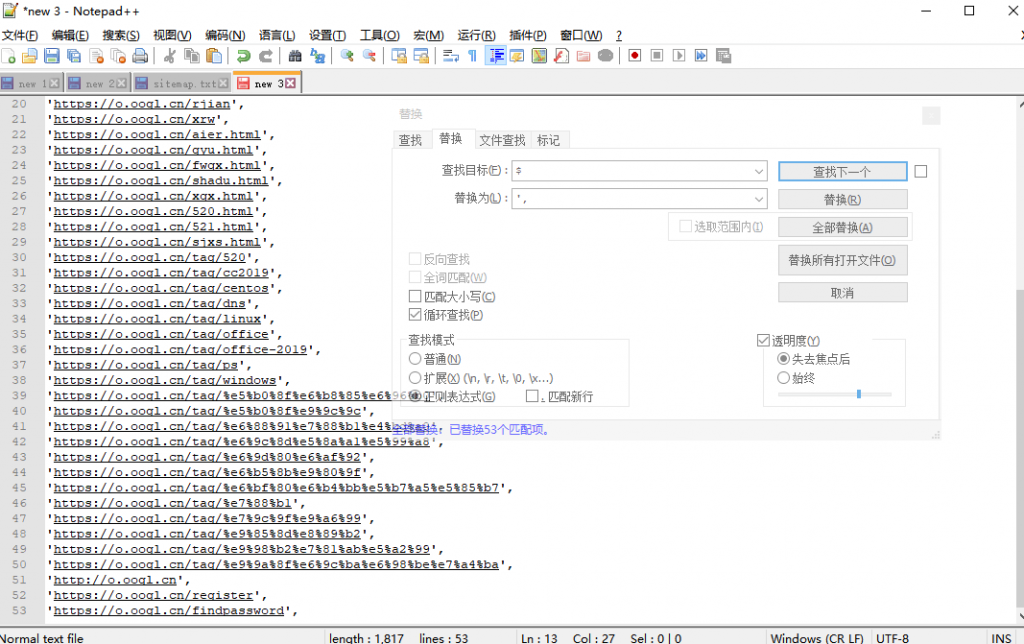
NotePad++ 在行前/行后添加特殊字符内容方法
我们在处理数据时,会遇到需要在每行数据前面、后面、开头、结尾添加各种不一样的字符 如果数据不多,我们可以自己手动的去添加,但如果达到了成百上千行,此时再机械的手动添加是不现实的 这里教给大家如何快速的在数据每行的前后…...
【JavaEE】多线程案例-线程池
文章目录 1. 什么是线程池2. 为什么要使用线程池(线程池有什么优点)3. 如何使用Java标准库提供的线程池3.1 创建一个线程池对象3.2 什么是工厂模式3.3 为什么要使用工厂模式3.4 Executors 创建不同具有不同特性的线程池3.5 ThreadPool 类的构造方法3.6 线…...
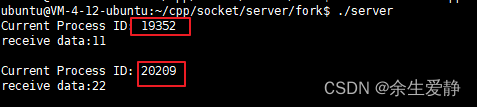
服务器搭建(TCP套接字)-fork版(服务端)
基础版的服务端虽然基本实现了服务器的基本功能,但是如果客户端的并发量比较大的话,服务端的压力和性能就会大打折扣,为了提升服务端的并发性能,可以通过fork子进程的方式,为每一个连接成功的客户端fork一个子进程,这样…...

缺失的第一个正数:高效解法与技术
缺失的第一个正数:高效解法与技术 背景 在计算机编程中,有时候需要寻找一个未排序整数数组中没有出现的最小的正整数。这篇技术博客将详细讨论这个问题,并提供一个时间复杂度为 O(n) 且只使用常数级别额外空间的解决方案。 问题描述 leet…...
)
常用的辅助网站(持续更新)
标题 一、uni-app方向二、H5方向 一、uni-app方向 1、uni-app官网 地址:https://uniapp.dcloud.net.cn/ 2、香蕉云编 地址:https://www.yunedit.com/ 描述:一般用来配置ios证书或安卓证书、上传ios包至商店 3、uView 地址:http…...

LeetCode 75 - 01 : 最小面积矩形
type pair struct{x, y int }func minAreaRect(points [][]int)int{mp : map[pair]struct{}{}// 将二维数组中的坐标映射到map中for i : range points{mp[pair{points[i][0], points[i][1]}] struct{}{}}// 将结果设置为一个最大值,防止影响求最小值的逻辑res : ma…...
每日一题:请解释什么是闭包(Closure)?并举一个实际的例子来说明。(前端初级)
今天继续在前端初级笔试题中被AI虐: 碱面的答案,问题:初级,回答:初级https://bs.rongapi.cn/1702510598371151872/14我的回答如下: 闭包是指由大括号包裹的一个区域,这个区域代表了一个变量生效…...

广告主必看!NetMarvel五大优势驱动出海App投放增长
App出海走到今天,流量红利早就不存在,摆在广告主面前最棘手的两个问题,一是不起量,二是买量成本太高,得不偿失。 如何在确保出海应用用户规模有所增长的同时,也保证整体ROI处在较高水平?NetMar…...

数据结构与算法之复杂度
时间复杂度 1.抓大头 2.常数用o(1),低阶函数也用o(1)代替(直接去掉) 3.取最坏情况 对数相关写法的规定...

ATECLOUD电源测试软件平台如何测试电源纹波?
电源纹波是影响电源稳定性的重要因素,过大的纹波会导致电源模块的工作效率降低,可能使电源模块直接损坏。使用ATECLOUD碘盐测试软件平台对纹波进行测试,检测其工作情况,以确保其稳定性和性能。 电源纹波的产生 电源的纹波通俗的来…...
数据结构与算法:排序算法(2)
目录 堆排序 使用步骤 代码实现 计数排序 适用范围 过程 代码实现 排序优化 桶排序 工作原理 代码实现 堆排序 二叉堆的特性: 1. 最大堆的堆顶是整个堆中的最大元素 2. 最小堆的堆顶是整个堆中的最小元素 以最大堆为例,如果删除一个最大堆的…...

Azure Quickstart Templates 多区域部署高可用架构设计终极指南:5步构建企业级灾难恢复方案
Azure Quickstart Templates 多区域部署高可用架构设计终极指南:5步构建企业级灾难恢复方案 【免费下载链接】azure-quickstart-templates Azure Quickstart Templates 项目地址: https://gitcode.com/gh_mirrors/az/azure-quickstart-templates 在当今数字化…...

欧盟单一电信市场:技术规则重塑与产业影响分析
1. 项目概述:一场迟来的电信革命作为一名在通信行业摸爬滚打了十几年的工程师,我经历过从2G到5G的每一次技术迭代,也见证过不同市场间因政策壁垒而导致的种种怪象。比如,你带着一部手机在欧洲大陆旅行,从德国到法国不过…...

FastAPI部署演进:从Gunicorn+Uvicorn镜像到原生多进程的迁移指南
1. 项目背景与演进:从“黄金搭档”到“历史遗产”如果你在过去几年里用 FastAPI 部署过 Web 服务,大概率听说过或者用过tiangolo/uvicorn-gunicorn-fastapi-docker这个 Docker 镜像。它一度是 FastAPI 官方文档里推荐的部署方案之一,由 FastA…...

中国半导体产业崛起:资本驱动下的存储器攻坚与全产业链布局
1. 行业格局的十字路口:当西方整合遇上东方崛起最近几年,半导体行业的头条新闻几乎被一系列重磅并购案所占据:恩智浦收购飞思卡尔、安华高并购博通、英特尔鲸吞阿尔特拉。这些动辄数百亿美元的巨无霸交易,背后传递出一个清晰的信号…...

在株洲如何选择护脊透气的床垫?
引言在现代社会,随着生活节奏的加快和工作压力的增加,越来越多的人开始关注睡眠质量。而床垫作为影响睡眠质量的重要因素之一,其选择显得尤为重要。特别是对于需要护脊和透气功能的床垫,如何选择成为了一个关键问题。本文将结合德…...

ClawGuard:为Clawdbot AI智能体打造的安全监控与熔断防护系统
1. 项目概述:ClawGuard 是什么,以及为什么你需要它如果你正在使用或开发基于 Clawdbot 框架的 AI 智能体,那么“安全”和“可控”这两个词,大概率已经在你脑海里盘旋过无数次了。我接触过不少团队,从最初的兴奋于 AI 智…...

这家头部智能家居品牌是如何让全渠道电商闭环运营落地?
在电商渠道愈发多元的当下,让很多企业陷入 “数据多却用不好” 的困境。这不是个别现象,而是绝大多数全渠道电商企业正在经历的“成长烦恼”。今天,我们用一个真实案例,带您看看如何用一套系统,彻底告别这些噩梦。这家…...

技术奇点之后,人类程序员的历史角色
当人工智能越过技术奇点,代码生成、测试用例设计乃至系统运维都将发生质变。本文从软件测试从业者的视角出发,系统探讨人类程序员在奇点之后可能扮演的六种核心角色:系统守护者、需求翻译官、质量伦理法官、人机交互设计师、持续学习组织者与…...

3分钟掌握Windows任务栏投资助手:打造你的桌面股票监控中心
3分钟掌握Windows任务栏投资助手:打造你的桌面股票监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 想在Windows任务栏上实时监控股票行情,又不想…...

Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值
Avogadro 2:3分钟掌握跨平台分子建模的5大核心价值 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related a…...