netty报文解析之粘包半包问题
粘包问题
Netty 的粘包问题是指在网络传输过程中,由于 TCP 协议本身的特点,导致发送方发送的若干个小数据包被接收方合并成了一个大数据包。这种情况称为粘包。
TCP 协议是面向流的协议,没有数据边界,发送方发送的数据可能会被分成多个数据包进行发送,接收方则需要将这些数据包重新组装为原始数据。当接收方处理不当时,就可能会发生粘包等问题。
造成粘包问题的原因主要有以下几点:
- 传输的数据量过大或者传输速度过快。
- 数据包长度不固定,或者协议自定义导致变长。
- 接收方的读取缓存区大小设置不当。
解决粘包问题的方法有很多种,其中比较常用的方式包括以下几点:
- 定长解码器:针对长度固定的数据包,采用定长的编码和解码方式,可以有效避免粘包问题。
- 分隔符解码器:使用特定字符或字符串作为数据包的分隔符,在接收方收到分隔符时进行消息的解码。
- 消息头加长度字段:在数据包中添加一部分用来表示数据包长度的信息,以便于接收方进行消息的解码和切割。
- 自定义协议:设计自己的消息传输协议,包括消息格式、头部、长度字段等,来解决粘包问题。
半包问题
半包问题是指在网络传输过程中,接收方无法完整地接收到一个数据包,而只接收到了部分数据包的情况。这种情况称为半包。
造成半包问题的主要原因是数据包的长度超过了接收方的缓存区大小,导致接收方无法一次性接收完整的数据包。协议设计不合理、网络延迟等也可能引起半包问题。
解决半包问题方法和解决粘包问题基本一致。
下面看下具体的例子
定长报文
定长报文就是收发双方约定一次通信的报文长度是固定长度的,服务端按照规定长度接收,客户端按照固定长度返送。这里主要用到FixedLengthFrameDecoder解码器,其构造函数有一个入参来指定报文的长度。
server:
pipeline.addLast(new FixedLengthFrameDecoder(1024))
发送数据
// 消息解析
ByteBuf buf = (ByteBuf) msg;
byte[] bytes = new byte[buf.readableBytes()];
buf.readBytes(bytes);
String receivedMessage = new String(bytes, "UTF-8");
System.out.println("接收到消息:" + receivedMessage);
// 发送响应
String responseMessage = "Response";
byte[] responseBytes = responseMessage.getBytes("UTF-8");
ByteBuf responseBuf = ctx.alloc().buffer(responseBytes.length);
responseBuf.writeBytes(responseBytes);
ctx.writeAndFlush(responseBuf);// 释放资源
buf.release();
client:
客户端只要每次发送按约定长度组装报文即可
固定长度头
固定长度头就是报文整体有两部分组成:报文头+报文体。齐总报文头是固定位置长度,里面会表明报文体长度,消息接收方先定长读取报文头,然后根据报文头指定的报文体长度来定量读取报文体。
这里用到了LengthFieldBasedFrameDecoder解码器。
该解析其有几个重要参数:
maxFrameLength:最大消息长度,报文最大长度
lengthFieldOffset:长度字段的偏移量,如有些报文可能报文头上还有一些其它的标识位,可以将这些标识位跳过
lengthFieldLength:长度字段的长度
lengthAdjustment:长度调整值,这个值也有一定的用处。有些情况长度标识的是包含header头的长度,这个时候可以将该值配置成负数,最后继续往后解析的长度是:lengthFieldLength+lengthAdjustment
initialBytesToStrip:从开始位置截取掉的字节长度,可以把header去掉再往后传给下一个handler,不过一般会保留报文头,业务代理再去解析。LengthFieldBasedFrameDecoder只负责报文接收完整。
整个处理流程:
当接收到来自网络的字节流时,LengthFieldBasedFrameDecoder 首先根据指定的 lengthFieldOffset 和 lengthFieldLength 定位长度字段的位置,并读取长度字段的值。
接下来,根据读取到的长度字段值计算出消息的长度。如果消息的长度超过了指定的 maxFrameLength,则会触发异常处理机制。
如果消息的长度合法,则 LengthFieldBasedFrameDecoder 会读取接下来的指定长度的字节,构成一个完整的消息。
最后,根据配置的 initialBytesToStrip 参数,可以选择是否去除消息长度头。
解码器完成后,将解析出的完整消息传递给下一个处理器进行进一步的处理。
用例:
如我们定义以下一种报文:
长度头(4字节,只是报文体长度)+标识位(1字节)+报文体长度。
则创建LengthFieldBasedFrameDecoder要指定。
lengthFieldOffset=0,lengthFieldLength=4,lengthAdjustment=1,initialBytesToStrip=0(保留报文头)
具体代码:
server端pipeline添加LengthFieldBasedFrameDecoder解码器和FixedLengthServerHandler
pipeline.addLast(new LengthFieldBasedFrameDecoder(1024,0,4,1,0));
pipeline.addLast(new FixedLengthServerHandler());
FixedLengthServerHandler处理方法如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {ByteBuf buf = (ByteBuf) msg;//消息解析int length = buf.readInt();byte[] bytes = new byte[length];char flag = (char) buf.readByte();buf.readBytes(bytes);String receivedMessage = new String(bytes, "UTF-8");System.out.println("接收到消息:" + receivedMessage+",消息标识:"+flag);// 发送响应String responseMessage = "SUCC";byte[] responseBytes = responseMessage.getBytes("UTF-8");int responseLength = responseBytes.length;ByteBuf responseBuf = ctx.alloc().buffer(4 +1+ responseLength);responseBuf.writeInt(responseLength);responseBuf.writeBytes("Y".getBytes());responseBuf.writeBytes(responseBytes);ctx.writeAndFlush(responseBuf);buf.release();
}
client端:
同样的pipeline添加两个handler
pipeline.addLast(new LengthFieldBasedFrameDecoder(1024,0,4,1,0));
pipeline.addLast(new FixedLengthClientHandler());
构造消息发送:
ByteBuf buffer = Unpooled.buffer();
byte[] bytes = "hello".getBytes();
buffer.writeInt(bytes.length);
buffer.writeBytes("X".getBytes());
buffer.writeBytes(bytes);
channel.writeAndFlush(buffer);
FixedLengthClientHandler处理响应报文:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {ByteBuf buf = (ByteBuf) msg;// 消息处理int length = buf.readInt();char flag = (char) buf.readByte();byte[] bytes = new byte[length];buf.readBytes(bytes);String receivedMessage = new String(bytes, "UTF-8");System.out.println("接收到消息:" + receivedMessage+",flag="+flag);buf.release();
}
另外这里处理的都是字节流数据,使用原先阻塞BIO socket也是可以的,不局限于ByteBuf。
如socket发送接收上面定长报文头数据:
Socket socket = new Socket("localhost", 8080);
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream();// 发送消息
String message = "Hello";
byte[] data = message.getBytes();ByteBuffer buffer = ByteBuffer.allocate(4);
buffer.putInt(data.length);outputStream.write(buffer.array());
outputStream.write("X".getBytes());
outputStream.write(data);
outputStream.flush();
//接收响应
byte[] lenB = new byte[4];
inputStream.read(lenB);
char flag = (char) inputStream.read();
ByteBuffer buff = ByteBuffer.wrap(lenB);
int len = buff.getInt();byte[] resp = new byte[len];
inputStream.read(resp);
System.out.println("响应:"+new String(resp) +",flag="+flag);outputStream.close();
inputStream.close();
socket.close();
分隔符报文
分隔符报文就是将报文按固定字符进行分割,这里使用DelimiterBasedFrameDecoder 解析器。
入参可指定分隔符及最大报文长度。
与之相似的还有LineBasedFrameDecoder按行读取,就是以 '\n’换行符当作分隔符。
自定义报文
基本上LengthFieldBasedFrameDecoder解码器已经满足解决报文粘包问题,如果还有其它比较复杂的报文,可以自定义协议报文格式进行处理,一个基本原则还是要有一个报文长度标识,然后按具体长度进行读取。
相关文章:

netty报文解析之粘包半包问题
粘包问题 Netty 的粘包问题是指在网络传输过程中,由于 TCP 协议本身的特点,导致发送方发送的若干个小数据包被接收方合并成了一个大数据包。这种情况称为粘包。 TCP 协议是面向流的协议,没有数据边界,发送方发送的数据可能会被分…...

EasyCode整合mybatis-plus的配置
文章目录 entitymapper.javamapper.xmlserviceserviceImplcontroller 这篇文章不教你如何安装和使用EasyCode,只是贴出可以使用的配置。 具体EasyCode的使用可以查看其它的文章。 entity ##导入宏定义 $!{define.vm}##保存文件(宏定义) #sa…...

实施预测性维护解决方案的挑战及PreMaint的应对方法
前面我们介绍了企业选择预测性维护解决方案的常见问题和PreMaint的策略,本期我们将带来实施过程中可能会遇到的挑战,以及如何通过PreMaint来应对这些挑战,以实现可靠的预测性维护。 随着工业技术的不断进步,预测性维护作为一种先进…...

1. js中let、var、const定义变量区别与方式
1 声明语法 var upperA A; let upperB B; const upperC C; 只声明不初始化的结果,【 const定义的常量不可以修改,而且必须初始化】 // var 声明变量 var upperA; console.log(打印大写的A:%s, upperA); // 结果:打印大写的A&am…...

【STM32学习】I2C通信协议 | OLED屏
🐱作者:一只大喵咪1201 🐱专栏:《STM32学习》 🔥格言:你只管努力,剩下的交给时间! 今天需要将代码烧录到开发板中,本喵默认大家都会创建工程,以及进行基本的…...

Nvme Spec 第一章节学习
Nvme Express Base Specification 第一章 简介 1.1概述 NVM ExpressTM(NVMeTM)接口允许主机软件与非易失性存储器子系统通信。 此接口针对企业和客户端固态驱动器进行了优化,通常作为寄存器级接口连接到PCI Express接口。 注:在…...
)
第一章:最新版零基础学习 PYTHON 教程(第九节 - Python 语句中的 – 多行语句)
Python 中的语句: 在Python中,语句是Python解释器可以读取和执行的逻辑命令。它可能是Python 中的赋值语句或表达式。 Python 中的多行语句: 在Python中,语句通常写成一行,每行的最后一个字符是换行符。要将语句扩展到一行或多行,我们可以使用大括号 {}、圆括号 ()、方…...

kafka 3.0 离线安装
1.安装zookeeper 解压apache-zookeeper-3.8.0-bin.tar.gz到指定目录,复制conf目录下zoo_sample.cfg到zoo.cfg,并修改配置。 # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit…...

MySQL数据库入门到精通2--基础篇(函数,约束,多表查询,事务)
3. 函数 函数 是指一段可以直接被另一段程序调用的程序或代码。MySQL中的函数主要分为以下四类: 字符串函数、数值函数、日期函数、流程函数。 3.1 字符串函数 MySQL中内置了很多字符串函数,常用的几个如下: 演示如下: A. con…...
c-数据在内存中的存储-day7
...
3D大模型如何轻量化?试试HOOPS Communicator,轻松读取10G超大模型!
随着计算机技术的不断发展,3D模型在各行各业中的应用越来越广泛。然而,随着模型的复杂性和规模不断增加,处理和浏览超大型3D模型变得越来越具有挑战性。本文将探讨如何轻量化3D大模型,以及如何使用HOOPS Communicator来读取和浏览…...

go并发操作且限制数量
使用管道chan func returnNum() int64 {return time.Now().Unix() } func main() {threadAmount : runtime.GOMAXPROCS(0)if threadAmount < 2 {threadAmount 2}fmt.Println(threadAmount)threadChan : make(chan int, threadAmount)defer close(threadChan)for {for i :…...

AI深度学习-卷积神经网络000
文章目录 前言1.什么是深度学习2.语义分割与实例分割概述3.什么是卷积?4.Unet网络 前言 本栏目,主要为深度学习保姆教程。 主要通过B站视频整理而来: 深度学习保姆级教学 Unet语义分割视觉三维重建算法 1.什么是深度学习 深度学习保姆级教…...

网站有反爬机制就爬不了数据?那是你不会【反】反爬
目录 前言 一、什么是代理IP 二、使用代理IP反反爬 1.获取代理IP 2.设置代理IP 3.验证代理IP 4.设置代理池 5.定时更新代理IP 三、反反爬案例 1.分析目标网站 2.爬取目标网站 四、总结 前言 爬虫技术的不断发展,使得许多网站都采取了反爬机制ÿ…...
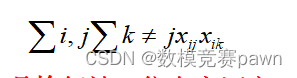
2023华为杯研究生数学建模C题分析
完整的分析查看文末名片获取! 问题一 在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作品集合之间应有一些交集。但有的交集大了,则…...
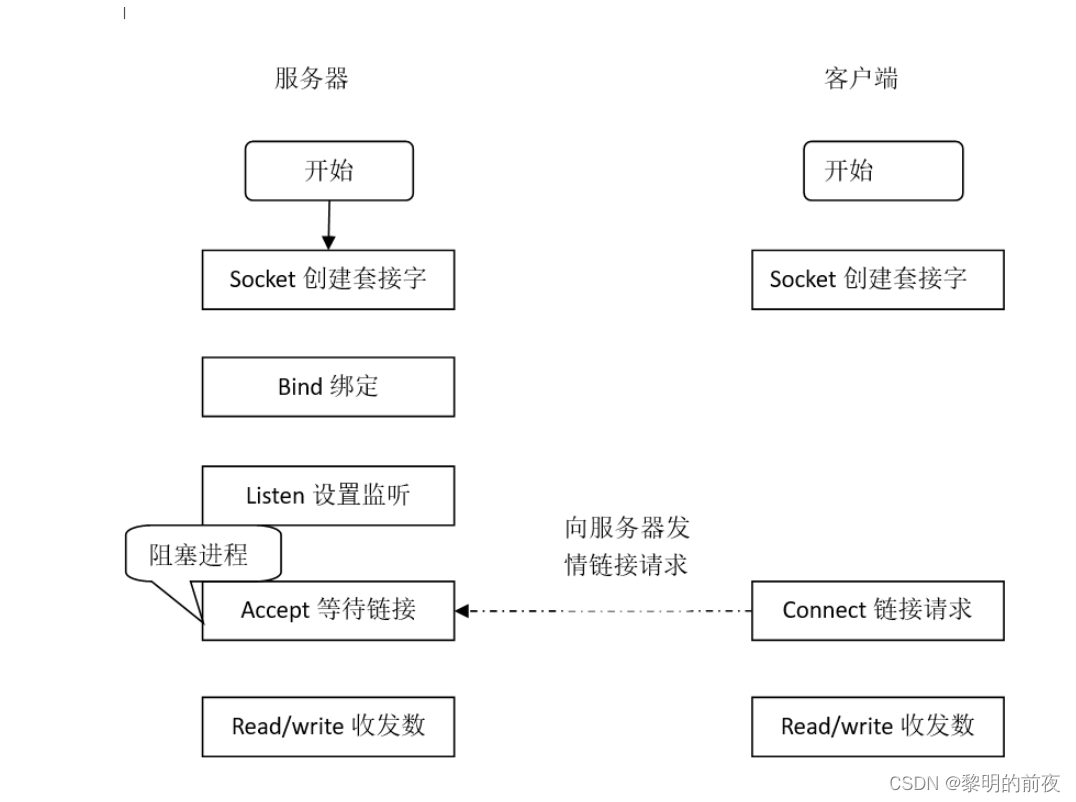
第三天:实现网络编程基于tcp/udp协议在Ubuntu与gec6818开发板之间双向通信
互联网地址 每一台设备接入互联网后,都会举报一个唯一的地址编号 IP地址 INTERNET地址 internet地址 :它是协议上的一个逻辑地址 目前来说,我们主要的IP地址有两类 IPV4 IPV6 IPV4 其实就是使用一个32bit整数作为IP IPV6 其实就是使用一…...
【MediaSoup---源码篇】(三)Transport
概述 RTC::Transport是mediasoup中的一个重要概念,它用于在mediasoup与客户端之间传输实时音视频数据。 Transport继承着众多的类,主要用于Transport的整体感知 class Transport : public RTC::Producer::Listener,public RTC::Consumer::Listener,publ…...

爱分析《商业智能最佳实践案例》
近日,国内知名数字化市场研究咨询机构爱分析发布《2023爱分析商业智能最佳实践案例》,此评选活动面向落地商业智能的各行企业和商业智能厂商,以第三方专业视角深入调研,评选出具有参考价值的创新案例。永达汽车集团与数聚股份合作…...

golang:context
context作用 goroutine的退出机制 多个goroutine都是平行的被调度的,多个goroutine如何协调工作涉及通信、同步、通知和退出 通信:goroutine之间的通信同步chan通道 同步:不带缓冲的chan提供了一个天然的同步等待机制。通过WaitGroup也可以…...

探讨代理IP与Socks5代理在跨界电商中的网络安全应用
在数字化时代,跨界电商已经成为了商业世界中的一大趋势。然而,跨越国界的电商活动也伴随着网络安全挑战。本文将讨论如何利用代理IP和Socks5代理技术来提高跨界电商中的网络安全,同时也探讨了与游戏相关的爬虫应用。 1. 代理IP和Socks5代理的…...

孤舟笔记 IO 与网络编程篇五 网络编程你真的懂吗?从Socket到TCP连接全解析
文章目录一、先说结论:网络编程核心事实二、TCP 编程:三次握手的 Socket 视角三、UDP 编程:无连接的数据报四、服务端线程模型演进模型一:一连接一线程(最原始)模型二:线程池(改进&a…...

3步快速上手RobotHelper:安卓自动化脚本框架新手指南
3步快速上手RobotHelper:安卓自动化脚本框架新手指南 【免费下载链接】RobotHelper 安卓游戏自动化脚本框架|Automated script for Android games 项目地址: https://gitcode.com/gh_mirrors/ro/RobotHelper 你是否想要开发安卓游戏自动化脚本,却…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管三种状态
用Arduino点亮三极管:5分钟可视化实验理解电子开关的三种状态 你是否曾被三极管的"截止"、"放大"、"饱和"这些术语困扰?教科书上的电压公式和载流子运动图虽然精确,却难以形成直观认知。今天我们将用Arduino和…...

量子机器学习在网络安全中的应用与性能分析
1. 量子机器学习在网络安全中的应用现状量子机器学习(Quantum Machine Learning, QML)近年来在网络安全领域引起了广泛关注。作为一名长期从事网络安全与量子计算交叉研究的从业者,我见证了这项技术从理论探讨到实际验证的发展历程。量子计算…...
)
基于微信小程序的民宿短租系统(30292)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...

工程师如何运用专业技能参与人道主义项目:从思维转变到实践落地
1. 项目概述:工程师的人道主义行动倡议每年8月19日,世界人道主义日都会提醒我们关注那些在全球最艰苦、最危险地区默默奉献的人们。这个日子最初是为了纪念在履职中牺牲的人道主义工作者,如今已演变为一个更广泛的号召——庆祝那种激励全球人…...

算力入门:从FLOPS到PUE全解析
算力入门:FLOPS、TFLOPS、EFLOPS、算力规模、能效比、PUE 全解 算力(计算能力)是衡量计算机系统性能的关键指标,尤其在科学计算、人工智能和大数据处理等领域至关重要。本指南将逐步解释FLOPS、TFLOPS、EFLOPS、算力规模、能效比和PUE这些核心概念,帮助您快速入门。所有内…...

可视化监控大盘构建:Grafana搭配Prometheus的艺术
在软件测试领域,我们早已不满足于“功能正确”这一单一维度。性能表现、资源消耗、服务稳定性、异常预警……这些非功能质量属性正逐渐成为衡量系统成熟度的关键标尺。而要将这些隐性的、动态的指标转化为可感知、可决策的信息,一套高效、灵活的可视化监…...

从“鸡尾酒会”到手机通话:用生活场景图解CDMA码分多址到底是怎么“听清”你的
鸡尾酒会里的通信密码:用生活场景拆解CDMA如何从噪音中识别你的声音 1. 当鸡尾酒会遇见通信技术 想象你站在一个嘈杂的鸡尾酒会现场,四周充斥着数十人同时进行的对话。神奇的是,尽管声波在空气中混杂叠加,你的大脑却能自动过滤无关…...