网站有反爬机制就爬不了数据?那是你不会【反】反爬
目录
前言
一、什么是代理IP
二、使用代理IP反反爬
1.获取代理IP
2.设置代理IP
3.验证代理IP
4.设置代理池
5.定时更新代理IP
三、反反爬案例
1.分析目标网站
2.爬取目标网站
四、总结
前言
爬虫技术的不断发展,使得许多网站都采取了反爬机制,以保护自己的数据和用户隐私。常见的反爬手段包括设置验证码、IP封锁、限制访问频率等等。
但是,这些反爬机制并不能完全阻止爬虫的进攻,因为只要有技术,就一定有方法来破解。本文将介绍如何使用代理IP来反反爬,以及相关的Python代码和案例。

一、什么是代理IP
代理IP(Proxy IP)是指在访问网络时,使用的是代理服务器的IP地址,而不是自己的IP地址。代理服务器相当于一座桥梁,将我们请求的数据先代理一下,再转发到目标网站,从而达到隐藏我们真实IP地址的效果。
代理IP具有隐藏身份、突破访问限制、提高访问速度、保护个人隐私等作用。在反爬方面,使用代理IP可以很好地避免被封锁IP,从而爬取目标网站的数据。
二、使用代理IP反反爬
1.获取代理IP
获取代理IP最常见的方式是通过爬取免费代理网站或者购买收费代理服务。免费代理网站的免费IP质量参差不齐,且容易被封锁,而收费代理服务的IP质量相对较高,可靠性更高。
在获取代理IP时,需要注意以下几点:
- 获取的代理IP必须是可用的,否则无法正常访问目标网站;
- 获取的代理IP需要定时更新,避免被封锁或失效;
- 不要过于频繁地使用同一个代理IP,否则容易被目标网站识别出来。
2.设置代理IP
在使用代理IP时,需要将其设置到请求头中。以requests库为例,可以通过以下代码设置代理IP:
import requestsproxies = {'http': 'http://ip:port','https': 'https://ip:port'
}response = requests.get(url, proxies=proxies)其中,`ip`和`port`是代理IP的地址和端口号,根据实际情况进行设置。
3.验证代理IP
在进行爬取之前,需要先验证代理IP是否可用。一般来说,验证代理IP的可用性可以通过访问http://httpbin.org/ip网站来进行验证。以requests库为例,可以通过以下代码验证代理IP是否可用:
import requestsproxies = {'http': 'http://ip:port','https': 'https://ip:port'
}try:response = requests.get('http://httpbin.org/ip', proxies=proxies, timeout=10)if response.status_code == 200:print('代理IP可用')else:print('代理IP不可用')
except:print('代理IP请求失败')4.设置代理池
单个代理IP的可用时间有限,而且代理IP的质量也参差不齐,因此需要设置一个代理池,从中随机选择一个可用的代理IP进行访问。
代理池的实现可以通过列表、队列或数据库等方式进行。以列表为例,可以通过以下代码实现代理池的设置:
proxy_pool = ['http://ip1:port1','http://ip2:port2','http://ip3:port3',...
]proxy = random.choice(proxy_pool)proxies = {'http': proxy,'https': proxy
}其中,`random.choice(proxy_pool)`表示从代理池中随机选择一个代理IP进行访问。
5.定时更新代理IP
为了避免代理IP被封锁或失效,需要定时更新代理IP。更新代理IP的方法有很多种,可以通过爬取免费代理网站、购买收费代理服务或者自己搭建代理服务器等方式进行。在更新代理IP时,需要注意以下几点:
- 更新的代理IP必须是可用的;
- 更新的代理IP需要添加到代理池中,并在下一次请求中随机选择使用。
三、反反爬案例
下面以爬取豆瓣电影TOP250为例,介绍如何使用代理IP来反反爬。
1.分析目标网站
豆瓣电影TOP250的网址为:https://movie.douban.com/top250。我们需要获取其中的电影名称、电影链接、电影评分等信息。
打开浏览器的开发者工具,可以发现目标网站的数据请求链接为:https://movie.douban.com/top250?start=0&filter=,其中的`start`表示起始位置,每页有25条数据,共10页数据。我们需要遍历这10页数据,获取其中的电影信息。
2.爬取目标网站
首先,需要获取代理IP,这里使用的是免费代理网站,代码如下:
import requests
from bs4 import BeautifulSoup
import randomdef get_proxy():url = 'https://www.zdaye.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')trs = soup.find_all('tr')proxy_list = []for tr in trs[1:]:tds = tr.find_all('td')ip = tds[1].textport = tds[2].textproxy = 'http://{}:{}'.format(ip, port)proxy_list.append(proxy)return proxy_list其中,`get_proxy()`函数用于获取代理IP,返回的是代理IP列表。
接下来,需要设置代理池,代码如下:
proxy_pool = get_proxy()随机选择一个代理IP进行访问,代码如下:
proxy = random.choice(proxy_pool)proxies = {'http': proxy,'https': proxy
}然后,开始爬取目标网站,代码如下:
import requests
from bs4 import BeautifulSoup
import randomdef get_proxy():url = 'https://www.zdaye.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')trs = soup.find_all('tr')proxy_list = []for tr in trs[1:]:tds = tr.find_all('td')ip = tds[1].textport = tds[2].textproxy = 'http://{}:{}'.format(ip, port)proxy_list.append(proxy)return proxy_listdef get_movie_info(url, proxies):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}response = requests.get(url, headers=headers, proxies=proxies)soup = BeautifulSoup(response.text, 'html.parser')items = soup.find_all('div', class_='info')movie_list = []for item in items:name = item.find('span', class_='title').texthref = item.find('a')['href']rating = item.find('span', class_='rating_num').textmovie_info = {'name': name,'href': href,'rating': rating}movie_list.append(movie_info)return movie_listif __name__ == '__main__':proxy_pool = get_proxy()movie_list = []for i in range(10):url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)proxy = random.choice(proxy_pool)proxies = {'http': proxy,'https': proxy}movie_list += get_movie_info(url, proxies)print(movie_list)在运行代码时,可能会出现代理IP不可用的情况,可以通过多次尝试或者定时更新代理IP来解决。
四、总结
本文介绍了如何使用代理IP来反反爬,并给出了相关的Python代码和案例。在实际爬取数据时,还需要注意以下几点:
- 避免频繁请求目标网站,尽量减少对目标网站的负担;
- 模拟真实请求,设置合理的User-Agent、Referer等请求头参数;
- 处理反爬机制,如验证码、JS渲染、动态IP等。

总之,反爬机制是爬虫开发中不可避免的挑战,需要不断学习技术、探索方法、思考策略,才能够更好地应对挑战并获取所需数据。
相关文章:
网站有反爬机制就爬不了数据?那是你不会【反】反爬
目录 前言 一、什么是代理IP 二、使用代理IP反反爬 1.获取代理IP 2.设置代理IP 3.验证代理IP 4.设置代理池 5.定时更新代理IP 三、反反爬案例 1.分析目标网站 2.爬取目标网站 四、总结 前言 爬虫技术的不断发展,使得许多网站都采取了反爬机制ÿ…...
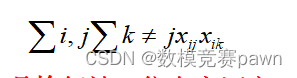
2023华为杯研究生数学建模C题分析
完整的分析查看文末名片获取! 问题一 在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作品集合之间应有一些交集。但有的交集大了,则…...
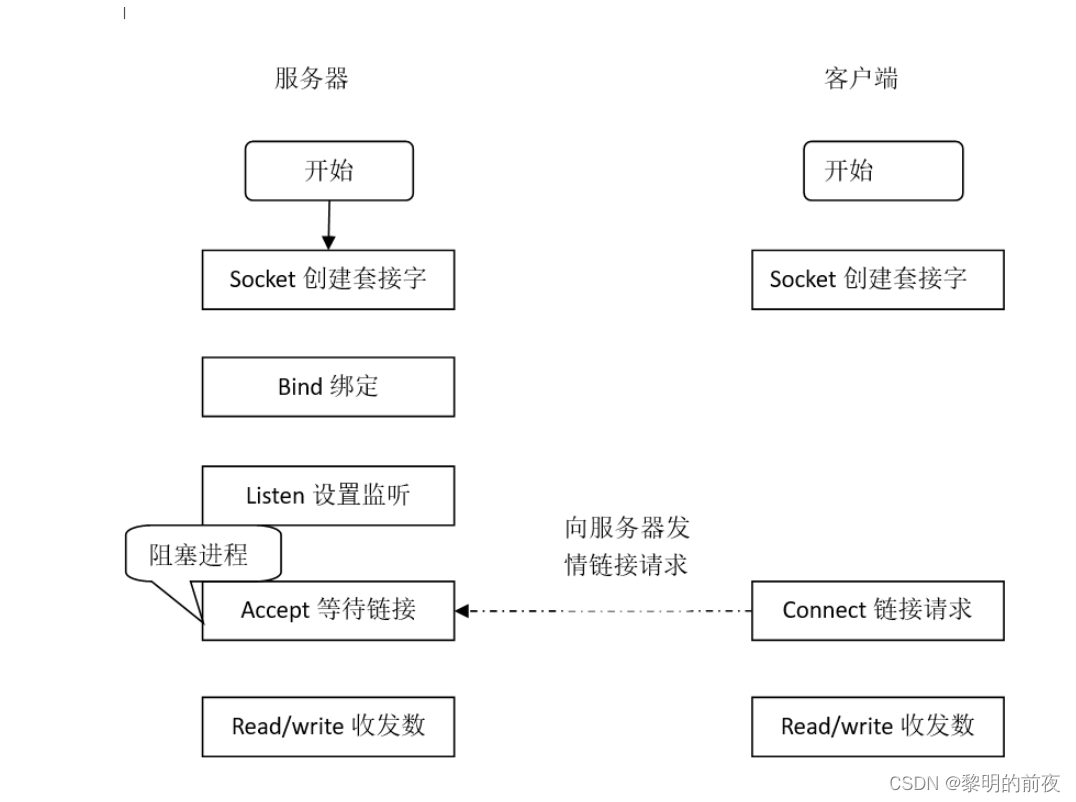
第三天:实现网络编程基于tcp/udp协议在Ubuntu与gec6818开发板之间双向通信
互联网地址 每一台设备接入互联网后,都会举报一个唯一的地址编号 IP地址 INTERNET地址 internet地址 :它是协议上的一个逻辑地址 目前来说,我们主要的IP地址有两类 IPV4 IPV6 IPV4 其实就是使用一个32bit整数作为IP IPV6 其实就是使用一…...
【MediaSoup---源码篇】(三)Transport
概述 RTC::Transport是mediasoup中的一个重要概念,它用于在mediasoup与客户端之间传输实时音视频数据。 Transport继承着众多的类,主要用于Transport的整体感知 class Transport : public RTC::Producer::Listener,public RTC::Consumer::Listener,publ…...

爱分析《商业智能最佳实践案例》
近日,国内知名数字化市场研究咨询机构爱分析发布《2023爱分析商业智能最佳实践案例》,此评选活动面向落地商业智能的各行企业和商业智能厂商,以第三方专业视角深入调研,评选出具有参考价值的创新案例。永达汽车集团与数聚股份合作…...

golang:context
context作用 goroutine的退出机制 多个goroutine都是平行的被调度的,多个goroutine如何协调工作涉及通信、同步、通知和退出 通信:goroutine之间的通信同步chan通道 同步:不带缓冲的chan提供了一个天然的同步等待机制。通过WaitGroup也可以…...

探讨代理IP与Socks5代理在跨界电商中的网络安全应用
在数字化时代,跨界电商已经成为了商业世界中的一大趋势。然而,跨越国界的电商活动也伴随着网络安全挑战。本文将讨论如何利用代理IP和Socks5代理技术来提高跨界电商中的网络安全,同时也探讨了与游戏相关的爬虫应用。 1. 代理IP和Socks5代理的…...
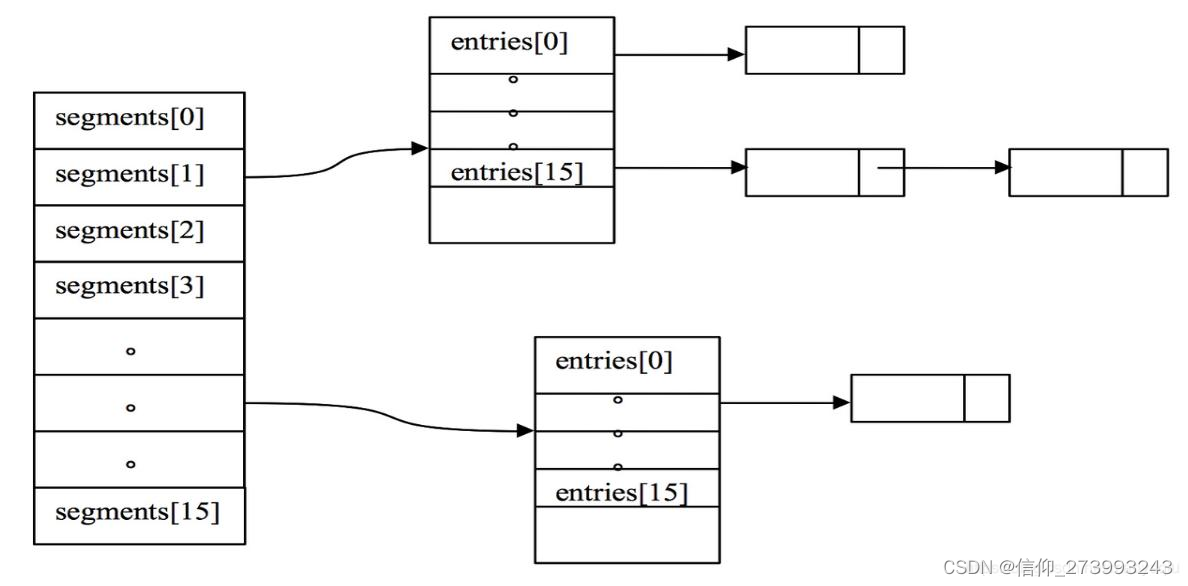
Guava Cache介绍-面试用
一、Guava Cache简介 1、简介 Guava Cache是本地缓存,数据读写都在一个进程内,相对于分布式缓存redis,不需要网络传输的过程,访问速度很快,同时也受到 JVM 内存的制约,无法在数据量较多的场景下使用。 基…...

ARM 汇编指令作业(求公约数、for循环实现1-100之间和、从SVC模式切换到user模式简单写法)
1、求两个数最大公约数 .text .globl _start_start:mov r0, #9mov r1, #15 Loop: 循环cmp r0,r1 比较r0和r1的大小beq stop 当r0和r1相等时,跳到stop标签subhi r0,r0,r1 r0-r1>0 时,证明r0>r1,将r0-r1的值赋给r0&…...

Go - 【字符串,数组,哈希表】常用操作
一. 字符串 字符串长度: s : "hello" l : len(s) fmt.Println(l) // 输出 5遍历字符串: s : "hello" for i, c : range s {fmt.Printf("%d:%c ", i, c) } // 输出:0:h 1:e 2:l 3:l 4:ofor i : 0; i < le…...

vue 普通组件的 局部注册
vue 普通组件的 注册 11 Vue2_3入门到实战-配套资料\01-随堂代码素材\day03\素材\00-准备代码\小兔鲜首页静态页\src...
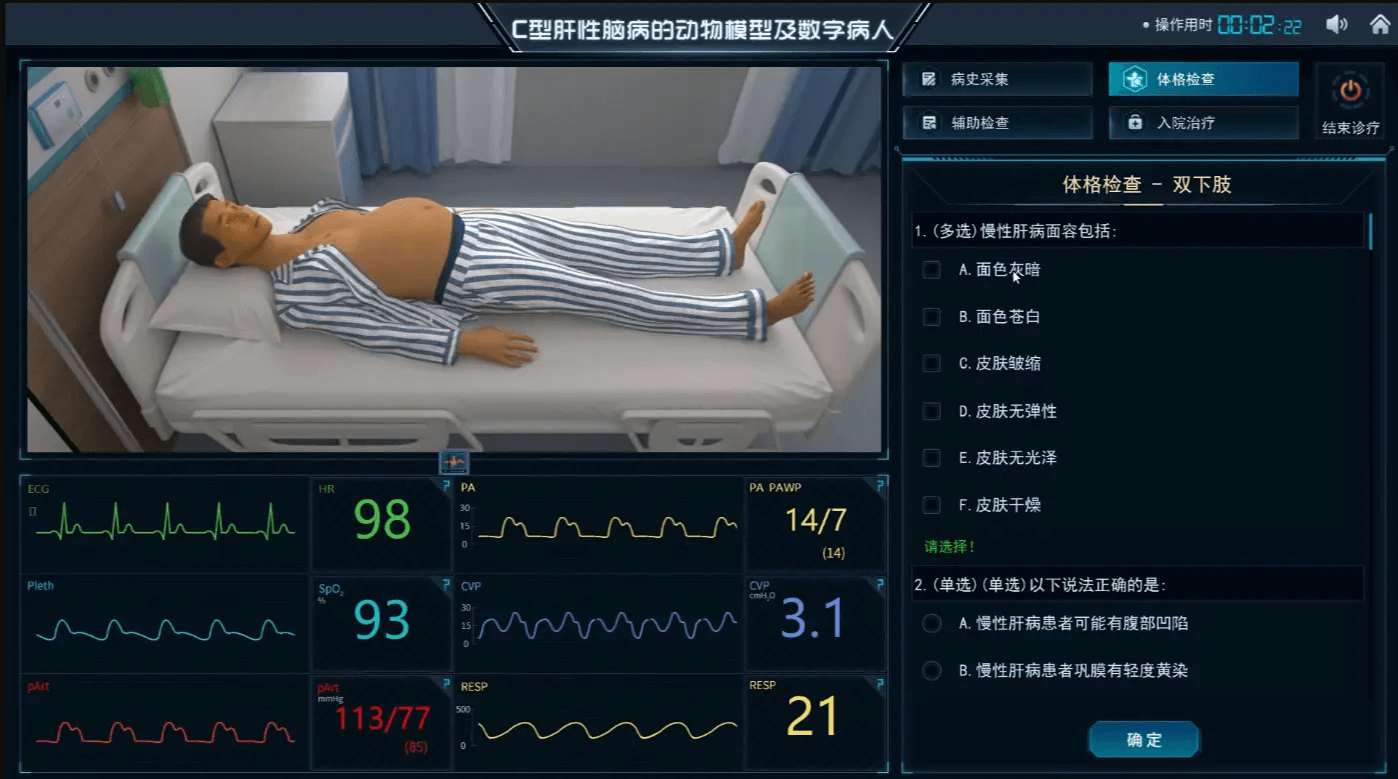
医疗虚拟仿真和虚拟现实有什么区别?哪个更好?
随着我们在仿真教育中越来越多地使用新技术,区分虚拟模式的类型很重要。虚拟仿真是一个统称,用来概括术语来描述各种基于仿真的体验,从基于屏幕的平台到沉浸式虚拟现实。然而,各虚拟平台在保真度、沉浸感和临场感的水平上有很大差…...

【.net core】yisha框架使用nginx代理swagger接口无法访问问题
后端代码配置 #在StartUp.cs文件中Configure方法中增加以下代码 app.UseSwagger(c >{//代理路径访问c.PreSerializeFilters.Add((doc, item) >{//根据代理服务器提供的协议、地址和路由,生成api文档服务地址doc.Servers new List<OpenApiServer>{ new…...

uniapp录音功能和音频播放功能制作
录音功能 在 UniApp 中,你可以使用 uni.getRecorderManager() 方法来创建一个录音管理器实例,从而实现录音功能。 以下是一个示例,演示了如何在 UniApp 中使用 uni.getRecorderManager() 实现录音功能: // 在需要录音的页面或组…...

服务器数据恢复-LINUX操作系统下各文件系统误删除/格式化数据的恢复方案
服务器数据恢复环境: 基于EXT2/EXT3/EXT4/Reiserfs/Xfs文件系统的Linux操作系统。 服务器故障: LINUX操作系统下误删除/格式化数据。 服务器数据恢复过程: 1、首先会检测服务器是否存在硬件故障,如果检测出硬件故障,交…...
 、upper_bound,bisect_left,bisect_right))
python/C++二分查找库函数(lower_bound() 、upper_bound,bisect_left,bisect_right)
二分查找是一种经典的搜索算法,广泛应用于有序数据集中。它允许在大型数据集中高效地查找目标元素,减少了搜索的时间复杂度。本文将介绍在 C 和 Python 中内置的二分查找函数,让二分查找变得更加容易。 c lower_bound() 、upper_bound 定义…...

爬虫 — App 爬虫(二)
目录 一、Appium介绍二、node.js 安装三、Java 的 SDK 安装以及配置1、安装步骤2、配置环境变量 四、安卓环境的配置1、配置环境变量 五、Appium 安装1、安装2、打开 APP3、使用 六、Appium 使用1、定位数据(方法一,不常用)2、定位数据&#…...
汽车电子相关术语
SOA SOA(Service-Oriented Architecture,面向服务的架构)是一种在计算机环境中设计、开发、部署和管理离散模型的方法。是由Garnter1996年提出的概念,将应用程序的不同功能单元(称为服务)进行拆分…...
Python 找出最大数
"""在输入的三个数中找出最大知识点:1、条件嵌套语句if/else2.字符串分割函数split()3、列表元素索引4、数据类型转换举一反三:1、如何控制只能输入三个数,否则重新输入2、如何避免输入无效字母"""# 定义一个变…...

Spring Security 用了那么久,你对它有整体把控吗?
文章目录 1.Servlet Filter:守门人的角色2.DelegatingFilterProxy:桥接 Servlet 和 Spring 的神器3.FilterChainProxy:Spring Security 过滤器链的管家3.SecurityFilterChain:Security 过滤器的串绳4.Spring Security 中的过滤器机…...

Vexip UI暗黑主题实现:CSS变量与主题切换完全指南 [特殊字符]
Vexip UI暗黑主题实现:CSS变量与主题切换完全指南 🎨 【免费下载链接】vexip-ui A Vue 3 UI library, highly customizability, full TypeScript, performance pretty good. 项目地址: https://gitcode.com/gh_mirrors/ve/vexip-ui 想要为你的Vue…...

《深入浅出通信原理》连载101-105
连载101:正弦信号的傅立叶变换连载102:直流信号的傅立叶变换连载103:复指数信号傅立叶变换的另外一种求法连载104:非周期信号的傅立叶变换连载105:傅立叶变换的对称性(一)...

Kubernetes多租户架构设计与实践
Kubernetes多租户架构设计与实践 一、引言 多租户是指在同一个Kubernetes集群中为多个用户或团队提供隔离的资源和环境。本文将深入探讨Kubernetes多租户架构的核心概念、实现方法和最佳实践。 二、多租户架构设计 2.1 多租户参考架构 ┌────────────────…...

Mac上如何用DistroAV插件实现无线多机位直播:NDI技术完整指南
Mac上如何用DistroAV插件实现无线多机位直播:NDI技术完整指南 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 还在为Mac上的OBS直播设置烦恼吗?想…...

全方位降本增效,Captain AI重构OZON运营成本结构
当前OZON市场竞争日趋激烈,人力、物流、广告、库存等各项运营成本持续攀升,利润空间不断压缩,“降本”与“增效”成为商家生存发展的核心命题。不同于单一工具仅能优化某一项成本,Captain AI立足OZON商家全运营场景,以…...

Go语言极简Web框架Meridian:依赖注入与清晰架构实践
1. 项目概述:一个“极简”的现代Web应用框架最近在GitHub上闲逛,又看到了一个名为rynfar/meridian的项目。点进去一看,简介写着“A modern web framework for building APIs and web applications in Go”。说实话,现在Go语言的We…...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...

FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼
FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...
)
Mac小白必看:手把手教你找回丢失的Recovery HD分区(附diskutil命令详解)
Mac用户必备技能:深度解析Recovery HD分区修复与diskutil实战指南 当你按下CommandR却只看到闪烁的问号图标时,那种手足无措的感觉我深有体会。Recovery HD分区就像是Mac的急救箱,藏着系统恢复、磁盘修复和时间机器备份等关键工具。但很多用户…...

Topit:突破macOS窗口层级限制,打造极致高效的多任务工作流
Topit:突破macOS窗口层级限制,打造极致高效的多任务工作流 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 想象一下这样的场景ÿ…...