YOLOv5、YOLOv8改进:Decoupled Head解耦头
目录
1.Decoupled Head介绍
2.Yolov5加入Decoupled_Detect
2.1 DecoupledHead加入common.py中:
2.2 Decoupled_Detect加入yolo.py中:
2.3修改yolov5s_decoupled.yaml
1.Decoupled Head介绍
Decoupled Head是一种图像分割任务中常用的网络结构,用于提取图像特征并预测每个像素的类别。传统的图像分割网络通常将特征提取和像素预测过程集成在同一个网络中,而Decoupled Head则将这两个过程进行解耦,分别处理。
Decoupled Head的核心思想是通过引入额外的分支网络来进行像素级的预测。这个分支网络通常被称为“头”(head),因此得名Decoupled Head。具体而言,Decoupled Head网络在主干网络的特征图上添加一个或多个额外的分支,用于预测像素的类别。
Decoupled Head的优势在于可以更好地处理不同尺度和精细度的语义信息。通过将像素级的预测与特征提取分开,可以更好地利用底层和高层特征之间的语义信息,从而提高分割的准确性和细节保留能力。
Decoupled Head的优点:
-
分离特征提取和像素预测:Decoupled Head将特征提取和像素级预测分离开来,使得网络可以更加灵活地处理不同尺度和语义信息。
-
多尺度特征融合:通过在主干网络的不同层级添加分支,Decoupled Head可以融合来自不同尺度的特征信息,从而提高对多尺度目标的分割能力。
-
更好的像素级预测:由于Decoupled Head将像素级的预测作为独立的任务进行处理,可以更好地保留细节和边缘信息,提高分割的精确性。
-
可扩展性:Decoupled Head结构可以根据需要进行扩展和修改,例如添加更多的分支或调整分支的结构,以适应不同的任务和数据集需求。
YOLOv6 采用了解耦检测头(Decoupled Head)结构,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。
原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,因此加入 Decoupled Head。
为什么要用到解耦头?
因为分类和定位的关注点不同;
分类更关注目标的纹理内容;
定位更关注目标的边缘信息
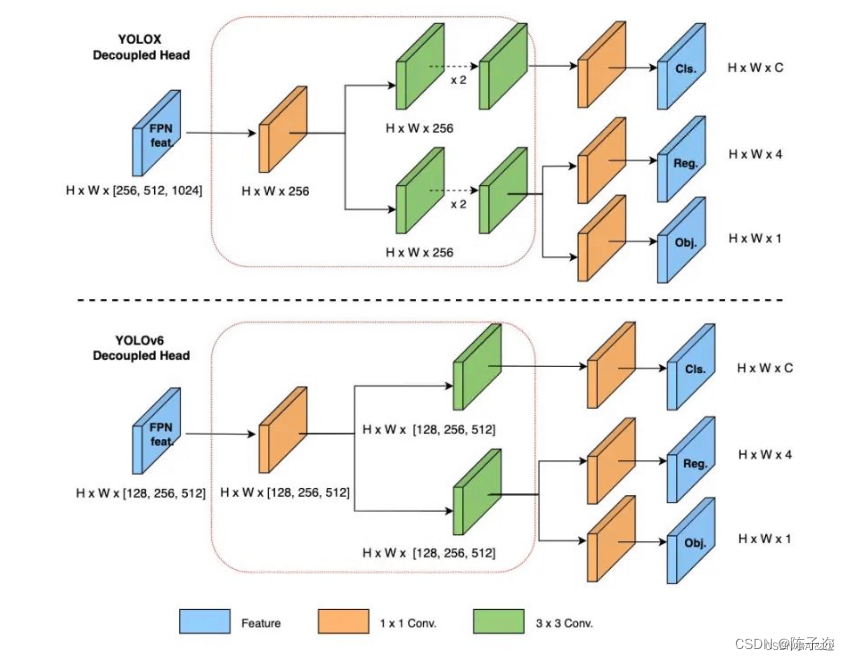
2.Yolov5加入Decoupled_Detect
2.1 DecoupledHead加入common.py中:
#======================= 解耦头=============================#
class DecoupledHead(nn.Module):def __init__(self, ch=256, nc=80, anchors=()):super().__init__()self.nc = nc # number of classesself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.merge = Conv(ch, 256 , 1, 1)self.cls_convs1 = Conv(256 , 256 , 3, 1, 1)self.cls_convs2 = Conv(256 , 256 , 3, 1, 1)self.reg_convs1 = Conv(256 , 256 , 3, 1, 1)self.reg_convs2 = Conv(256 , 256 , 3, 1, 1)self.cls_preds = nn.Conv2d(256 , self.nc * self.na, 1) # 一个1x1的卷积,把通道数变成类别数,比如coco 80类(主要对目标框的类别,预测分数)self.reg_preds = nn.Conv2d(256 , 4 * self.na, 1) # 一个1x1的卷积,把通道数变成4通道,因为位置是xywhself.obj_preds = nn.Conv2d(256 , 1 * self.na, 1) # 一个1x1的卷积,把通道数变成1通道,通过一个值即可判断有无目标(置信度)def forward(self, x):x = self.merge(x)x1 = self.cls_convs1(x)x1 = self.cls_convs2(x1)x1 = self.cls_preds(x1)x2 = self.reg_convs1(x)x2 = self.reg_convs2(x2)x21 = self.reg_preds(x2)x22 = self.obj_preds(x2)out = torch.cat([x21, x22, x1], 1) # 把分类和回归结果按channel维度,即dim=1拼接return outclass Decoupled_Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(DecoupledHead(x, nc, anchors) for x in ch)self.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid(y, x, indexing='ij')else:yv, xv = torch.meshgrid(y, x)grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_grid2.2 Decoupled_Detect加入yolo.py中:
class BaseModel(nn.Module):
def _apply(self, fn):# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffersself = super()._apply(fn)m = self.model[-1] # Detect()if isinstance(m, (Detect, Segment,Decoupled_Detect)):m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return selfclass DetectionModel(BaseModel):
def _initialize_dh_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency# https://arxiv.org/abs/1708.02002 section 3.3# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # from# reg_bias = mi.reg_preds.bias.view(m.na, -1).detach()# reg_bias += math.log(8 / (640 / s) ** 2)# mi.reg_preds.bias = torch.nn.Parameter(reg_bias.view(-1), requires_grad=True)# cls_bias = mi.cls_preds.bias.view(m.na, -1).detach()# cls_bias += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls# mi.cls_preds.bias = torch.nn.Parameter(cls_bias.view(-1), requires_grad=True)b = mi.b3.bias.view(m.na, -1)b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)mi.b3.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)b = mi.c3.bias.datab += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # clsmi.c3.bias = torch.nn.Parameter(b, requires_grad=True) if isinstance(m, (Detect, Segment,ASFF_Detect)):s = 256 # 2x min stridem.inplace = self.inplaceforward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forwardcheck_anchor_order(m)m.anchors /= m.stride.view(-1, 1, 1)self.stride = m.strideself._initialize_biases() # only run onceelif isinstance(m, Decoupled_Detect):s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forwardcheck_anchor_order(m) # must be in pixel-space (not grid-space)m.anchors /= m.stride.view(-1, 1, 1)self.stride = m.strideself._initialize_dh_biases() # only run oncedef parse_model(d, ch): # model_dict, input_channels(3)
elif m in {Detect, Segment,Decoupled_Detect}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)2.3修改yolov5s_decoupled.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5),解耦]相关文章:
YOLOv5、YOLOv8改进:Decoupled Head解耦头
目录 1.Decoupled Head介绍 2.Yolov5加入Decoupled_Detect 2.1 DecoupledHead加入common.py中: 2.2 Decoupled_Detect加入yolo.py中: 2.3修改yolov5s_decoupled.yaml 1.Decoupled Head介绍 Decoupled Head是一种图像分割任务中常用的网络结构&#…...
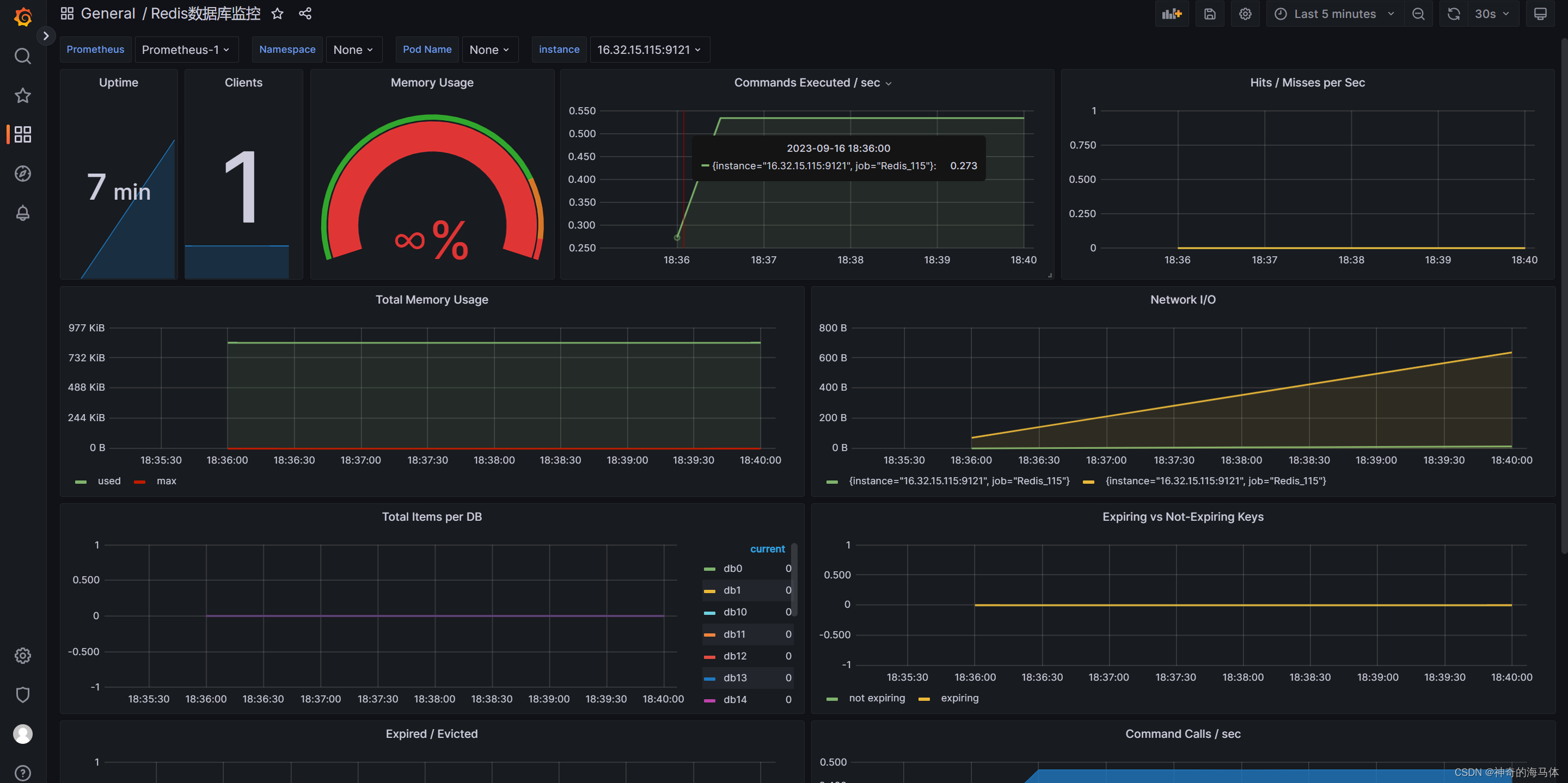
Prometheus+Grafana可视化监控【Redis状态】
文章目录 一、安装Docker二、安装Redis数据库(Docker容器方式)三、安装Prometheus四、安装Grafana五、Pronetheus和Grafana相关联六、安装redis_exporter七、Grafana添加Redis监控模板 一、安装Docker 注意:我这里使用之前写好脚本进行安装Docker,如果已…...
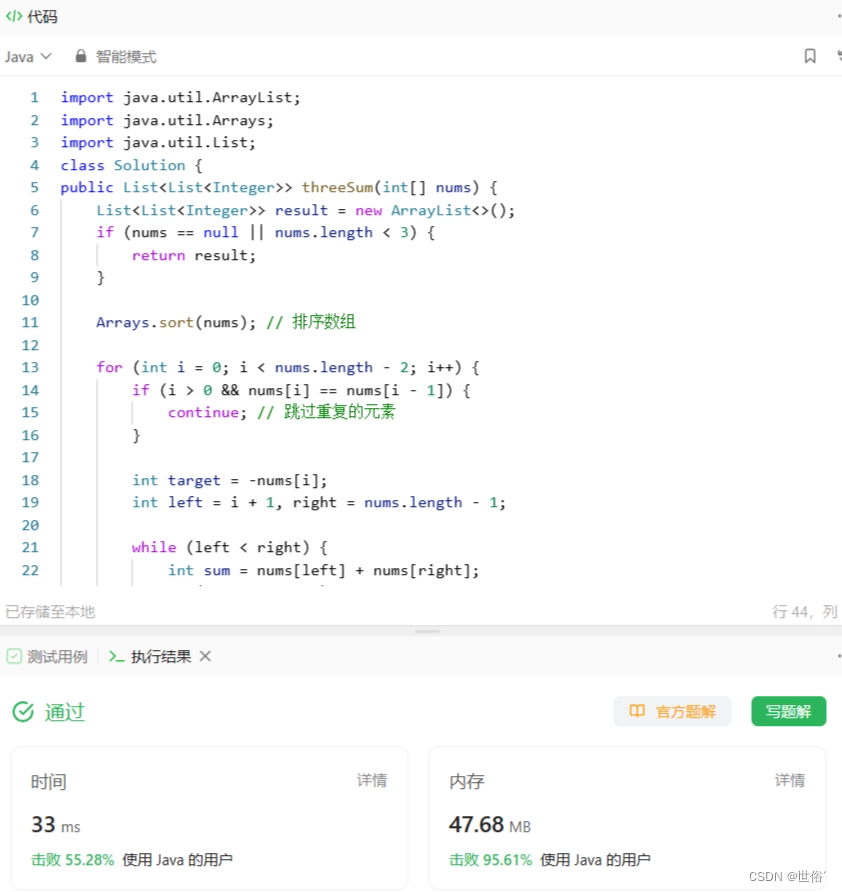
怒刷LeetCode的第6天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:哈希表 方法二:逐个判断字符 方法三:模拟减法 第二题 题目来源 题目内容 解决方法 方法一:水平扫描法 方法二:垂直扫描法 方法三:分治法 方…...

SSL双向认证-Nginx配置
SSL双向认证需要CA证书,开发过程可以利用自签CA证书进行调试验证。 自签CA证书生成过程:SSL双向认证-自签CA证书生成 Nginx配置适用于前端项目或前后端都通过Nginx转发的时候(此时可不配置后端启用双向认证) 1.Nginx配置&#…...
)
GO学习之 远程过程调用(RPC)
GO系列 1、GO学习之Hello World 2、GO学习之入门语法 3、GO学习之切片操作 4、GO学习之 Map 操作 5、GO学习之 结构体 操作 6、GO学习之 通道(Channel) 7、GO学习之 多线程(goroutine) 8、GO学习之 函数(Function) 9、GO学习之 接口(Interface) 10、GO学习之 网络通信(Net/Htt…...

八大排序(四)--------直接插入排序
本专栏内容为:八大排序汇总 通过本专栏的深入学习,你可以了解并掌握八大排序以及相关的排序算法。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:八大排序汇总 🚚代码仓库:小小unicorn的代码仓库…...

MYSQL--存储引擎和日志管理
存储引擎: 一、存储引擎概念: MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。存储引擎是My…...

VUE之更换背景颜色
1. 确定需求 在实现之前,首先需要明确需求,即用户可以通过某种方式更改页面背景颜色,所以我们需要提供一个可操作的控件来实现此功能。 2. 创建Vue组件 为了实现页面背景颜色更换功能,我们可以创建一个Vue组件。下面是一个简单…...

大型集团借力泛微搭建语言汇率时区统一、业务协同的国际化OA系统
国际化、全球化集团,业务遍布全世界,下属公司众多,集团对管理方式和企业文化塑造有着很高的要求。不少大型集团以数字化方式助力全球统一办公,深化企业统一管理。 面对大型集团全球化的管理诉求,数字化办公系统作为集…...
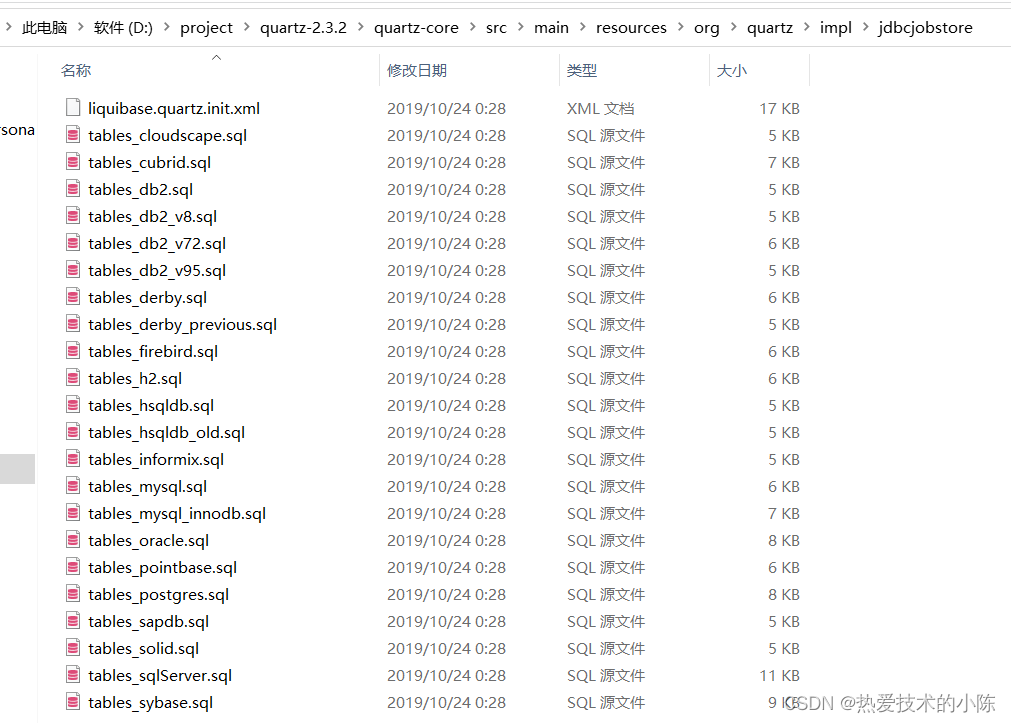
Quartz 建表语句SQL文件
SQL文件在jar里面,github下载 https://github.com/quartz-scheduler/quartz/releases/tag/v2.3.2 解压,sql文件路径:quartz-core\src\main\resources\org\quartz\impl\jdbcjobstore tables_mysql_innodb.sql # # In your Quartz propertie…...

nginx SseEmitter 长连接
1、问题还原: 在做openai机器人时,后台使用 SseEmitterEventSource 实现流式获取数据,前端通过 EventSourcePolyfill 函数接收后端的数据,在页面流式输出到页面,做成逐字打稿的效果。本地测试后,可以正常获…...
若依cloud -【 100 ~ 】
100 分布式日志介绍 | RuoYi 分布式日志就相当于把日志存储在不同的设备上面。比如若依项目中有ruoyi-modules-file、ruoyi-modules-gen、ruoyi-modules-job、ruoyi-modules-system四个应用,每个应用都部署在单独的一台机器里边,应用对应的日志的也单独存…...
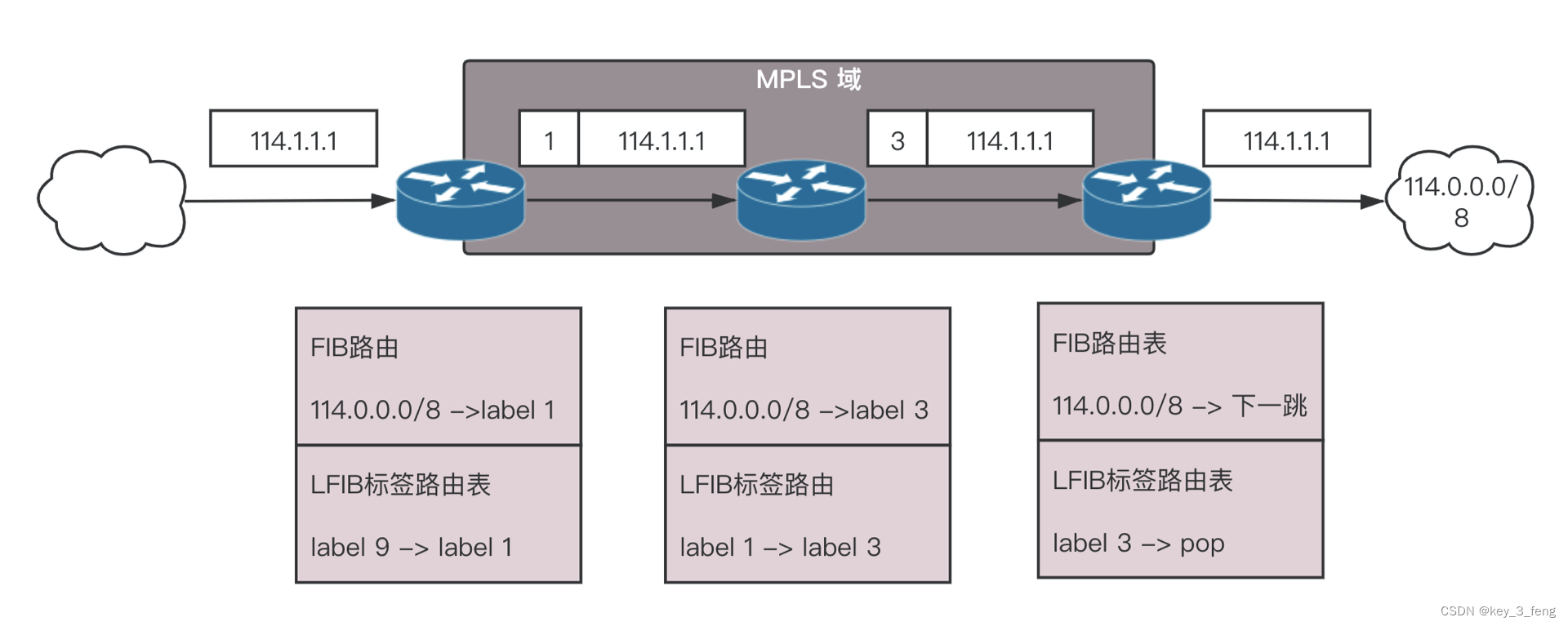
VPN协议是如何工作的
VPN,全名 Virtual Private Network,虚拟专用网,就是利用开放的公众网络,建立专用数据传输通道,将远程的分支机构、移动办公人员等连接起来。 VPN 通过隧道技术在公众网络上仿真一条点到点的专线,是通过利用…...

c++::作用域符解析
1)当存在具有相同名称的局部变量时,要访问全局变量 2)在类之外定义函数。 class A { } void A::func(){ }A a;a.func();3)访问一个类的静态变量 class A { static int b; } A::b; 4) 如果两个命名空间中都存在一个具有相同名称的类…...

【电源专题】什么是充电芯片的Shipping Mode(船运模式)
现在越来越多电子产品小型化,手持化,这样就需要电池来为产品供电。但电池供电造成的另一个难题就是产品的续航能力的强与弱。 如果想提升续航能力,有一种方法是提高电池容量。如果电池体积没有变化的情况下,可能使用了新型材料、高级技术来增加电池容量,但这势必会增加电池…...

WebGL笔记: 2D和WebGL坐标系对比和不同的画图方式, 程序对象通信,顶点着色器,片元着色器
WebGL 坐标系 canvas2d画布和webgl画布使用的坐标系都是二维直角坐标系,但它们坐标原点、y 轴的坐标方向,坐标基底都不一样canvas2d 坐标系的原点在左上角, x轴朝右,y轴朝下1个单位的宽就是一个像素的宽,1个单位的高就是一个像素…...

【php经典算法】冒泡排序,冒泡排序原理,冒泡排序执行逻辑,执行过程,执行结果 代码
冒泡排序原理 每次比较两个相邻的元素,将较大的元素交换至右端 冒泡排序执行过程输出效果 冒泡排序实现思路 每次冒泡排序操作都会将相邻的两个元素进行比较,看是否满足大小关系要求,如果不满足,就交换这两个相邻元素的次序&…...

多模块和分布式项目
一、什么是多模块项目 多模块项目是一种软件项目组织结构,其中一个大型项目被分成多个独立的子模块或子项目。每个子模块通常具有自己的功能、目录结构和开发周期,但它们可以协同工作以构建一个完整的应用程序。这种项目结构有助于提高代码的可维护性、…...
AI视频剪辑:批量智剪技巧大揭秘
对于许多内容创作者来说,视频剪辑是一项必不可少的技能。然而,传统的视频剪辑方法需要耗费大量的时间和精力。如今,有一种全新的剪辑方式正在改变这一现状,那就是批量AI智剪。这种智能化的剪辑方式能够让你在短时间内轻松剪辑大量…...

vue项目实现地址自动识别功能
1、安装第三方依赖 npm install address-parse 2、在需要使用的页面引入 import AddressParse from address-parse; 3、在页面上写入静态的html代码,可以输入地址,加上识别的输入框; <div class"auto_address"><van-…...

8.68万新车普及车位到车位,世界模型不吃高算力!零跑夯爆了
贾浩楠 发自 凹非寺量子位 | 公众号 QbitAI2026智能车最热黑科技——世界模型,第一个把门槛打下来的玩家,意料之外,情理之中:零跑汽车,创造了科技“普及平权”的新纪录,四五十万豪华车的世界模型智能辅助驾…...

马年开始杂谈补
总感觉时间越过越快,是不是年纪大了。马年春节9天假期,历史上最长春节,一眨眼就过去了。今年刚开始就发生了很多事,不知福祸。首先是人工智能发展迅速,各种智能体开始出现。美以伊战争,油价狂飙。到了3月&a…...

如何高效使用PDF-Guru:5种实用PDF处理技巧与完整操作指南
如何高效使用PDF-Guru:5种实用PDF处理技巧与完整操作指南 【免费下载链接】PDF-Guru A Multi-purpose PDF file processing tool with a nice UI that supports merge, split, rotate, reorder, delete, scale, crop, watermark, encrypt/decrypt, bookmark, extrac…...

零基础入门:PyTorch-2.x-Universal-Dev-v1.0环境使用避坑指南
零基础入门:PyTorch-2.x-Universal-Dev-v1.0环境使用避坑指南 1. 环境介绍与快速验证 PyTorch-2.x-Universal-Dev-v1.0是一个专为深度学习开发者设计的预配置环境,基于官方PyTorch底包构建,已经集成了常用的数据处理、可视化和开发工具。这…...

语音转文字工具推荐:FireRedASR Pro实测,识别准确率超高
语音转文字工具推荐:FireRedASR Pro实测,识别准确率超高 1. 为什么我们需要专业的语音转文字工具? 在日常工作和学习中,语音转文字的需求无处不在。从会议记录到采访整理,从课程笔记到灵感记录,手动转录不…...

化工模拟老司机的原油蒸馏骚操作
Aspen 化工过程模拟虚拟组分蒸馏原油 本可模型 在本模型中,将使用pseudocomponents进行原油蒸馏。 将创建一个由常压蒸馏塔和真空蒸馏塔组成的模型。 常压蒸馏塔将使用 Chao-Seader 热力学模型建模,而真空蒸馏塔将使用 Braun K10 模型建模。在Aspen里折腾…...

YOLOv8模型训练避坑指南:GTX16系列显卡兼容性问题解决方案
GTX16系列显卡用户必读:YOLOv8模型训练全流程避坑手册 当你在GTX16系列显卡上运行YOLOv8训练脚本时,是否遇到过这样的场景:训练过程看似正常,但最终输出的P(精确率)、R(召回率)、mAP…...

告别网络盲区:手把手教你用Wireshark抓包分析IEEE 1905.1拓扑发现协议
实战解析:用Wireshark透视IEEE 1905.1拓扑发现协议的运行机制 当你面对一个由Wi-Fi、电力线和以太网组成的复杂混合网络时,是否曾好奇这些设备是如何自动发现彼此并构建出完整拓扑图的?这正是IEEE 1905.1拓扑发现协议的魔力所在。不同于枯燥的…...
)
Python多解释器不是“未来技术”——它已在金融高频交易系统稳定运行417天(附完整监控看板截图)
第一章:Python多解释器的核心机制与历史演进Python长期以来以全局解释器锁(GIL)为标志性设计,单解释器模型主导了其执行范式。然而,随着多核硬件普及与异步编程兴起,对真正并行执行、内存隔离及轻量级运行时…...

PyTorch/TensorFlow张量加速实战:3个被90%工程师忽略的底层CUDA内核调优技巧
第一章:PyTorch/TensorFlow张量加速实战:3个被90%工程师忽略的底层CUDA内核调优技巧CUDA流与默认流解耦:避免隐式同步瓶颈 PyTorch 和 TensorFlow 默认将所有 CUDA 操作提交至默认流(null stream),导致跨 k…...