高阶数据结构——图
图
图的基本概念
图的基本概念
图是由顶点集合和边的集合组成的一种数据结构,记作 G = ( V , E ) G=(V, E)G=(V,E) 。
有向图和无向图:
- 在有向图中,顶点对 < x , y >是有序的,顶点对 < x , y > 称为顶点 x 到顶点 y 的一条边,< x , y > 和 <y,x>是两条不同的边。
- 在无向图中,顶点对 ( x , y ) 是无序的,顶点对 ( x , y ) 称为顶点 x 和顶点 y 相关联的一条边,这条边没有特定方向,( x , y ) 和 ( y , x ) 是同一条边。
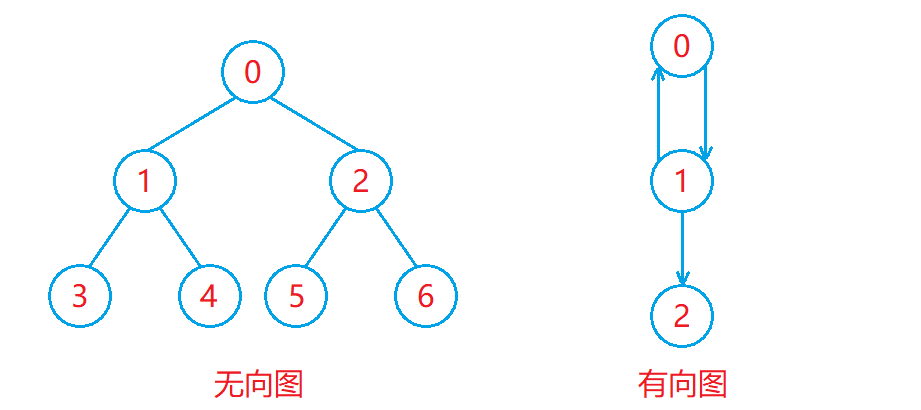
完全图:
- 在有 n 个顶点的无向图中,若有 n × ( n − 1 ) ÷ 2 条边,即任意两个顶点之间都有直接相连的边,则称此图为无向完全图。
- 在有 n 个顶点的有向图中,若有 n × ( n − 1 )条边,即任意两个顶点之间都有双向的边,则称此图为有向完全图。
如下图: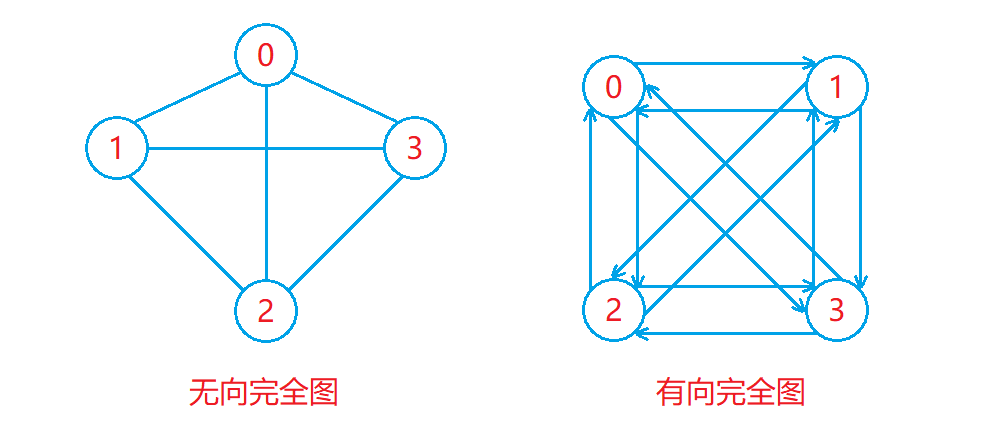
邻接顶点:
- 在无向图中,若 ( u , v ) 是图中的一条边,则称 u 和 v 互为邻接顶点,并称边 ( u , v ) 依附于顶点 u 和顶点v 。
- 在有向图中,若 < u , v > 是图中的一条边,则称顶点 u 邻接到顶点 v ,顶点 v 邻接自顶点 u ,并称边 <u , v > 与顶点 u 和顶点 v 相关联。
顶点的度:
- 在有向图中,顶点的度等于该顶点的入度与出度之和,顶点的入度是以该顶点为终点的边的条数,顶点的出度是以该顶点为起点的边的条数。
- 在无向图中,顶点的度等于与该顶点相关联的边的条数,同时也等于该顶点的入度和出度。
路径与路径长度:
- 若从顶点 vi 出发有一组边使其可到达顶点 vj ,则称顶点 vi 到顶点 vj 的顶点序列为从顶点 vi 到顶点 vj 的路径。
- 对于不带权的图,一条路径的长度是指该路径上的边的条数;对于带权的图,一条路径的长度是指该路径上各个边权值的总和。
带权图示例: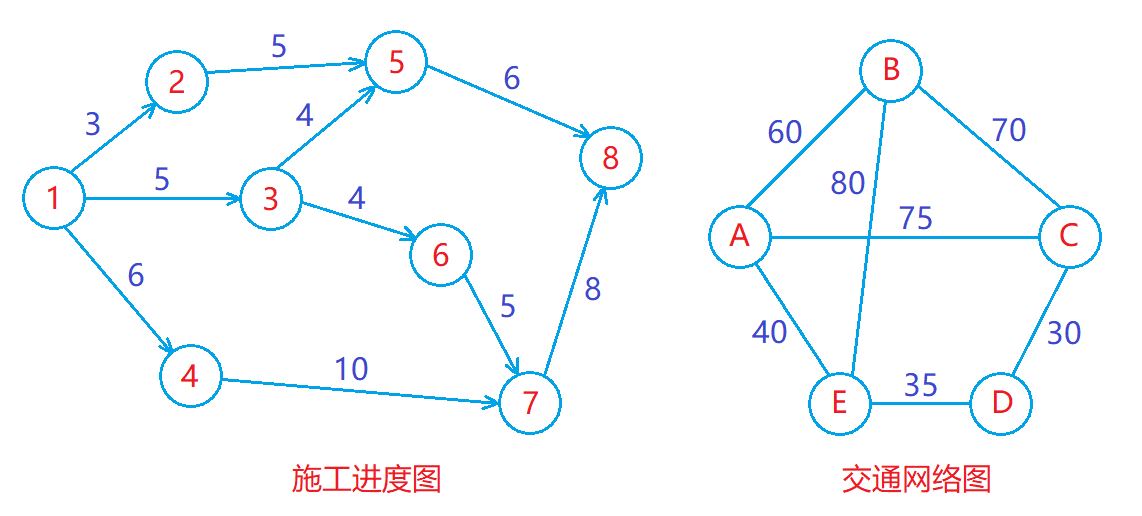
简单路径与回路:
- 若路径上的各个顶点均不相同,则称这样的路径为简单路径。
- 若路径上第一个顶点与最后一个顶点相同,则称这样的路径为回路或环。
如下图: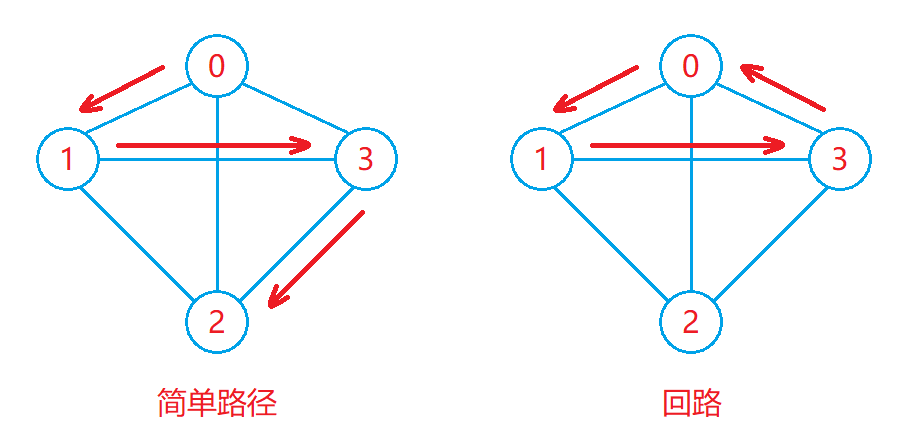
子图:
- 设图G=(V,E) 和图G1=(V1,E1),若 V 1 ⊆ V 且 E1⊆E ,则称 G1 是 G 的子图。
如下图: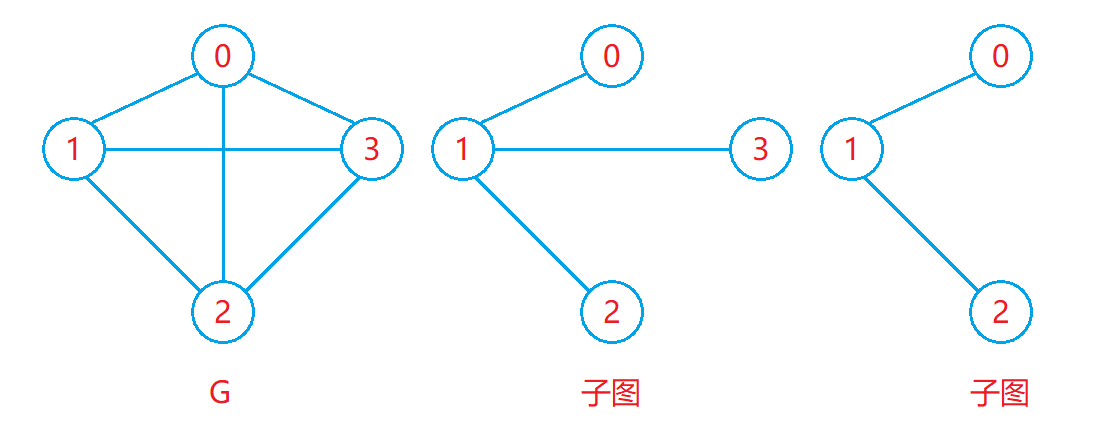
连通图和强连通图:
- 在无向图中,若从顶点 v1 到顶点 v2 有路径,则称顶点 v1 与顶点 v2 是连通的,如果图中任意一对顶点都是连通的,则称此图为连通图。
- 在有向图中,若每一对顶点vi 和 vj 之间都存在一条从vi到vj 的路,也存在一条从 vj 到 vi 的路,则称此图是强连通图。
生成树与最小生成树:
- 一个连通图的最小连通子图称为该图的生成树,有 n 个顶点的连通图的生成树有 n 个顶点和 n − 1 条边。
- 最小生成树指的是一个图的生成树中,总权值最小的生成树。
图的相关应用场景
图常见的表示场景如下:
- 交通网络:图中的每个顶点表示一个地点,图中的边表示这两个地点之间是否有直接相连的公路,边的权值可以是这两个地点之间的距离、高铁时间等。
- 网络设备拓扑:图中的每个顶点表示网络中的一个设备,图中的边表示这两个设备之间是否可以互传数据,边的权值可以是这两个设备之间传输数据所需的时间、丢包的概率等。
- 社交网络:图中的每个顶点表示一个人,图中的边表示这两个人是否互相认识,边的权值可以是这两个人之间的亲密度、共同好友个数等。
关于有向图和无向图:
- 交通网络对应的图可以是有向图,也可以是无向图,无向图对应就是双向车道,有向图对应就是单向车道。
- 网络设备拓扑对应的图通常是无向图,两个设备之间有边表示这两个设备之间可以互相收发数据。
- 社交网络对应的图可以是有向图,也可以是无向图,无向图通常表示一些强社交关系,比如QQ、微信等(一定互为好友),有向图通常表示一些弱社交关系,比如微博、抖音(不一定互相关注)。
图的其他相关作用:
- 在交通网络中,根据最短路径算法计算两个地点之间的最短路径,根据最小生成树算法得到将各个地点连通起来所需的最小成本。
- 在社交网络中,根据广度优先搜索得到两个人之间的共同好友进行好友推荐,根据入边表和出边表得知有哪些粉丝以及关注了哪些博主。
图与树的联系与区别
图与树的主要联系与区别如下:
- 树是一种有向无环且连通的图(空树除外),但图并不一定是树。
- 有 n 个结点的树必须有 n − 1 条边,而图中边的数量不取决于顶点的数量。
- 树通常用于存储数据,并快速查找目标数据,而图通常用于表示某种场景。
图的存储结构
图由顶点和边组成,存储图本质就是将图中的顶点和边存储起来。
邻接矩阵
邻接矩阵
邻接矩阵存储图的方式如下:
- 用一个数组存储顶点集合,顶点所在位置的下标作为该顶点的编号(所给顶点可能不是整型)。
- 用一个二维数组matrix存储边的集合,其中matrix[i][j] 表示编号为 i 和 j 的两个顶点之间的关系。
如下图: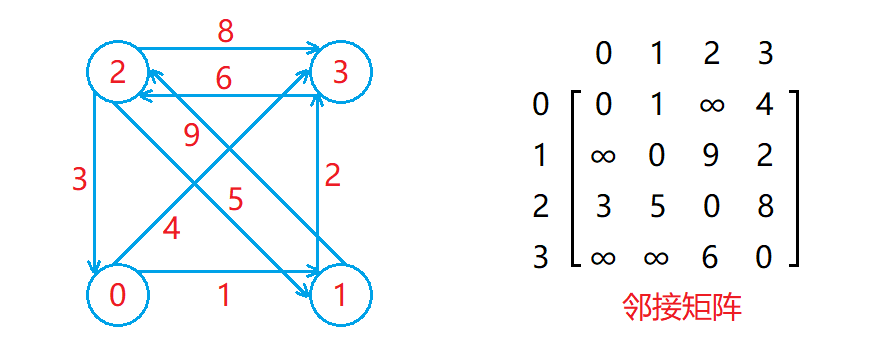
说明一下:
- 对于不带权的图,两个顶点之间要么相连,要么不相连,可以用0和1表示,m a t r i x [ i ] [ jmatrix[i][j] 为1表示编号为 i 和 j 的两个顶点相连,为0表示不相连。
- 对于带权的图,连接两个顶点的边会带有一个权值,可以用这个权值来设置对应matrix[i][j] 的值,如果两个顶点不相连,则使用不会出现的权值进行设置即可(图中为无穷大)。
- 对于无向图来说,顶点 i 和顶点 j 相连,那么顶点 j 就和顶点 i 相连,因此无向图对应的邻接矩阵是一个对称矩阵,即matrix[i][j] 的值等于 matrix[j][i] 的值。
- 在邻接矩阵中,第 i 行元素中有效权值的个数就是编号为 i 的顶点的出度,第 i ii 列元素中有效元素的个数就是编号为 i 的顶点的入度。
邻接矩阵的优缺点
邻接矩阵的优点:
- 邻接矩阵适合存储稠密图,因为存储稠密图和稀疏图时所开辟的二维数组大小是相同的,因此图中的边越多,邻接矩阵的优势就越明显。
- 邻接矩阵能够 O(1) 的判断两个顶点是否相连,并获得相连边的权值。
邻接矩阵的缺点:
- 邻接矩阵不适合查找一个顶点连接出去的所有边,需要遍历矩阵中对应的一行,该过程的时间复杂度是O(N),其中 N 表示的是顶点的个数。
邻接矩阵的实现
邻接矩阵所需成员变量:
- 数组 vertexs :用于存储顶点集合,顶点所在位置的下标作为该顶点的编号。
- 映射关系vIndexMap :用于建立顶点与其下标的映射关系,便于根据顶点找到其对应的下标编号。
- 邻接矩阵matrix :用于存储边的集合,matrix[i][j] 表示编号为 i 和 j 的两个顶点之间的关系。
邻接矩阵的实现:
- 为了支持任意类型的顶点类型以及权值,可以将图定义为模板类,其中V 和W 分别表示顶点和权值的类型,MAX_W 表示两个顶点没有连接时邻接矩阵中存储的值,将MAX_W 的缺省值设置为 INT_MAX (权值一般为整型),Direction 表示图是否为有向图,将Direction 的缺省值设置为false (无向图居多)。
- 在构造函数中完成顶点集合的设置,并建立各个顶点与其对应下标的映射关系,同时为邻接矩阵开辟空间,将矩阵中的值初始化为MAX_W ,表示刚开始时各个顶点之间均不相连。
- 提供一个接口用于添加边,在添加边时先分别获取源顶点和目标顶点对应的下标编号,然后再将邻接矩阵中对应位置设置为边的权值,如果图为无向图,则还需要在邻接矩阵中添加目标顶点到源顶点的边。
- 在获取顶点对应的下标时,先在vIndexMap 中进行查找,如果找到了对应的顶点,则返回该顶点对应的下标编号,如果没有找到对应的顶点,则说明所给顶点不存在,此时可以抛出异常。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://构造函数Graph(const V* vertexs, int n):_vertexs(vertexs, vertexs + n) //设置顶点集合,_matrix(n, vector<int>(n, MAX_W)) { //开辟二维数组空间//建立顶点与下标的映射关系for (int i = 0; i < n; i++) {_vIndexMap[vertexs[i]] = i;}}//获取顶点对应的下标int getVertexIndex(const V& v) {auto iter = _vIndexMap.find(v);if (iter != _vIndexMap.end()) { //顶点存在return iter->second;}else { //顶点不存在throw invalid_argument("不存在的顶点");return -1;}}//添加边void addEdge(const V& src, const V& dst, const W& weight) {int srci = getVertexIndex(src), dsti = getVertexIndex(dst); //获取源顶点和目标顶点的下标_matrix[srci][dsti] = weight; //设置邻接矩阵中对应的值if (Direction == false) { //无向图_matrix[dsti][srci] = weight; //添加从目标顶点到源顶点的边}}//打印顶点集合和邻接矩阵void print() {int n = _vertexs.size();//打印顶点集合for (int i = 0; i < n; i++) {cout << "[" << i << "]->" << _vertexs[i] << endl;}cout << endl;//打印邻接矩阵//横下标cout << " ";for (int i = 0; i < n; i++) {//cout << i << " ";printf("%4d", i);}cout << endl;for (int i = 0; i < n; i++) {cout << i << " "; //竖下标for (int j = 0; j < n; j++) {if (_matrix[i][j] == MAX_W) {printf("%4c", '*');}else {printf("%4d", _matrix[i][j]);}}cout << endl;}cout << endl;}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}
说明一下:
- 为了方便观察,可以在类中增加一个 p r i n t printprint 接口,用于打印顶点集合和邻接矩阵。
- 后续图的相关算法都会以邻接矩阵为例进行讲解,因为一般只有比较稠密的图才会存在最小生成树和最短路径的问题。
邻接表
邻接表
邻接表存储图的方式如下:
- 用一个数组存储顶点集合,顶点所在的位置的下标作为该顶点的编号(所给顶点可能不是整型)。
- 用一个出边表存储从各个顶点连接出去的边,出边表中下标为 i ii 的位置存储的是从编号为 i ii 的顶点连接出去的边。
- 用一个入边表存储连接到各个顶点的边,入边表中下标为 i ii 的位置存储的是连接到编号为 i ii 的顶点的边。
如下图: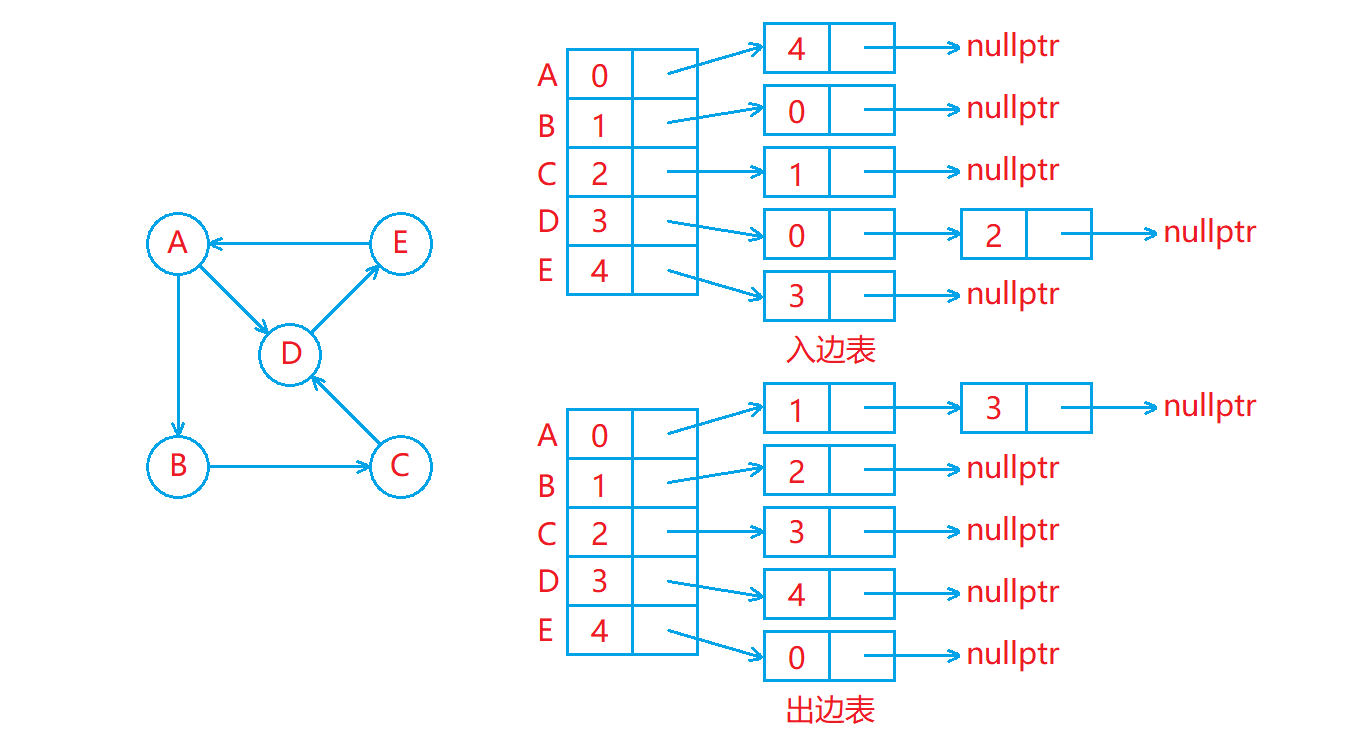
说明一下:
- 出边表和入边表类似于哈希桶,其中每个位置存储的都是一个链表,出边表中下标为 i 的位置的链表中存储的都是从编号为 i 的顶点连接出去的边,入边表中下标为 i 的位置的链表中存储的都是连接到编号为 i 的顶点的边。
- 在邻接表中,出边表中下标为 i ii 的位置的链表中元素的个数就是编号为 i 的顶点的出度,入边表中下标为 i 的的位置的链表中元素的个数就是编号为 i 的顶点的入度。
- 在实现邻接表时,一般只需要用一个出边表来存储从各个顶点连接出去的边即可,因为大多数情况下都是需要从一个顶点出发找与其相连的其他顶点,所以一般不需要存储入边表。
邻接表的优缺点
邻接表的优点:
- 邻接表适合存储稀疏图,因为邻接表存储图时开辟的空间大小取决于边的数量,图中边的数量越少,邻接表存储边时所需的内存空间就越少。
- 邻接表适合查找一个顶点连接出去的所有边,出边表中下标为 i ii 的位置的链表中存储的就是从顶点 i ii 连接出去的所有边。
邻接表的缺点:
- 邻接表不适合确定两个顶点是否相连,需要遍历出边表中源顶点对应位置的链表,该过程的时间复杂度是 O(E) ,其中 E 表示从源顶点连接出去的边的数量。
邻接表的实现
链表结点所需成员变量:
- 源顶点下标 srci :表示边的源顶点。
- 目标顶点下标 dsti :表示边的目标顶点。
- 权值 weight :表示边的权值。
- 指针 next :连接下一个结点。
代码如下:
//邻接表
namespace LinkTable {//链表结点定义template<class W>struct Edge {//int _srci; //源顶点的下标(可选)int _dsti; //目标顶点的下标W _weight; //边的权值Edge<W>* _next; //连接指针Edge(int dsti, const W& weight):_dsti(dsti),_weight(weight),_next(nullptr){}};
}
说明一下:
- 对于出边表来说,下标为 i 的位置的链表中存储的边的源顶点都是顶点 i ,所以链表结点中的源顶点成员可以不用存储。
- 对于入边表来说,下标为 i 的位置的链表中存储的边的目标顶点都是顶点 i ,所以链表结点中的目标顶点成员可以不用存储。
邻接表所需成员变量:
- 数组vertexs :用于存储顶点集合,顶点所在位置的下标作为该顶点的编号。
- 映射关系vIndexMap :用于建立顶点与其下标的映射关系,便于根据顶点找到其对应的下标编号。
- 邻接表(出边表)linkTable :用于存储边的集合,linkTable[i] 链表中存储的边的源顶点都是顶点 i 。
邻接表的实现:
- 为了支持任意类型的顶点类型以及权值,可以将图定义为模板,其中 V 和 W 分别表示顶点和权值的类型, Direction表示图是否为有向图,将Direction 的缺省值设置为false (无向图居多)。
- 在构造函数中完成顶点集合的设置,并建立各个顶点与其对应下标的映射关系,同时为邻接表开辟空间,将邻接表中的值初始化为空指针,表示刚开始时各个顶点之间均不相连。
- 提供一个接口用于添加边,在添加边时先分别获取源顶点和目标顶点对应的下标编号,然后在源顶点对应的链表中头插一个边结点,如果图为无向图,则还需要在目标顶点对应的链表中头插一个边结点。
代码如下:
//邻接表
namespace LinkTable {template<class V, class W, bool Direction = false>class Graph {typedef Edge<W> Edge;public://构造函数Graph(const V* vertexs, int n):_vertexs(vertexs, vertexs + n) //设置顶点集合, _linkTable(n, nullptr) { //开辟邻接表的空间//建立顶点与下标的映射关系for (int i = 0; i < n; i++) {_vIndexMap[vertexs[i]] = i;}}//获取顶点对应的下标int getVertexIndex(const V& v) {auto iter = _vIndexMap.find(v);if (iter != _vIndexMap.end()) { //顶点存在return iter->second;}else { //顶点不存在throw invalid_argument("不存在的顶点");return -1;}}//添加边void addEdge(const V& src, const V& dst, const W& weight) {int srci = getVertexIndex(src), dsti = getVertexIndex(dst); //获取源顶点和目标顶点的下标//添加从源顶点到目标顶点的边Edge* sdEdge = new Edge(dsti, weight);sdEdge->_next = _linkTable[srci];_linkTable[srci] = sdEdge;if (Direction == false) { //无向图//添加从目标顶点到源顶点的边Edge* dsEdge = new Edge(srci, weight);dsEdge->_next = _linkTable[dsti];_linkTable[dsti] = dsEdge;}}//打印顶点集合和邻接表void print() {int n = _vertexs.size();//打印顶点集合for (int i = 0; i < n; i++) {cout << "[" << i << "]->" << _vertexs[i] << " ";}cout << endl << endl;//打印邻接表for (int i = 0; i < n; i++) {Edge* cur = _linkTable[i];cout << "[" << i << ":" << _vertexs[i] << "]->";while (cur) {cout << "[" << cur->_dsti << ":" << _vertexs[cur->_dsti] << ":" << cur->_weight << "]->";cur = cur->_next;}cout << "nullptr" << endl;}}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<Edge*> _linkTable; //邻接表(出边表)};
}
说明一下:
为了方便观察,可以在类中增加一个print 接口,用于打印顶点集合和邻接表。
图的遍历
图的遍历指的是遍历图中的顶点,主要有广度优先遍历和深度优先遍历两种方式。
广度优先遍历
广度优先遍历
广度优先遍历又称BFS,其遍历过程类似于二叉树的层序遍历,从起始顶点开始一层一层向外进行遍历。
如下图: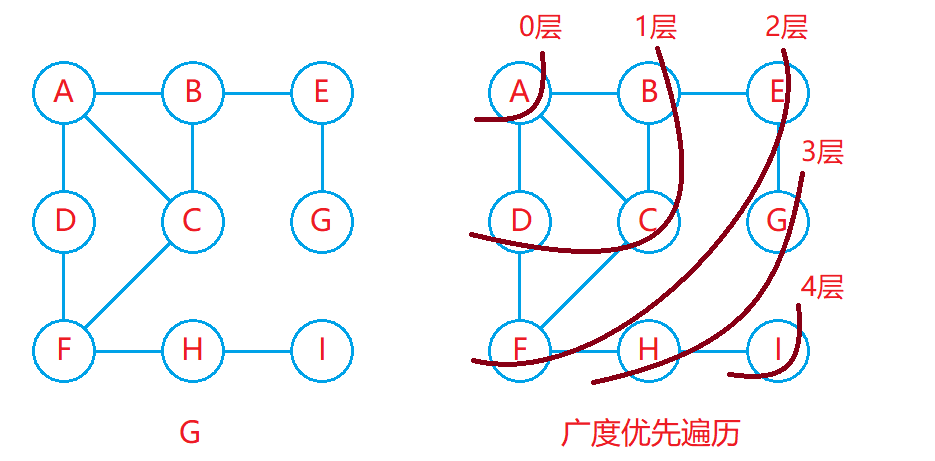
广度优先遍历的实现:
- 广度优先遍历需要借助一个队列和一个标记数组,利用队列先进先出的特点实现一层一层向外遍历,利用标记数组来记录各个顶点是否被访问过。
- 刚开始时将起始顶点入队列,并将起始顶点标记为访问过,然后不断从队列中取出顶点进行访问,并判断该顶点是否有邻接顶点,如果有邻接顶点并且该邻接顶点没有被访问过,则将该邻接顶点入队列,并在入队列后立即将该邻接顶点标记为访问过。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://广度优先遍历void bfs(const V& src) {int srci = getVertexIndex(src); //起始顶点的下标queue<int> q; //队列vector<bool> visited(_vertexs.size(), false); //标记数组q.push(srci); //起始顶点入队列visited[srci] = true; //起始顶点标记为访问过while (!q.empty()) {int front = q.front();q.pop();cout << _vertexs[front] << " ";for (int i = 0; i < _vertexs.size(); i++) { //找出从front连接出去的顶点if (_matrix[front][i] != MAX_W && visited[i] == false) { //是邻接顶点,并且没有被访问过q.push(i); //入队列visited[i] = true; //标记为访问过}}}cout << endl;}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}
说明一下:
- 为了防止顶点被重复加入队列导致死循环,因此需要一个标记数组,当一个顶点被访问过后就不应该再将其加入队列了。
- 如果当一个顶点从队列中取出访问时才再将其标记为访问过,也可能会存在顶点被重复加入队列的情况,比如当图中的顶点B出队列时,顶点C作为顶点B的邻接顶点并且还没有被访问过(顶点C还在队列中),此时顶点C就会再次被加入队列,因此最好在一个顶点被入队列时就将其标记为访问过。
- 如果所给图不是一个连通图,那么从一个顶点开始进行广度优先遍历,无法遍历完图中的所有顶点,这时可以遍历标记数组,查看哪些顶点还没有被访问过,对于没有被访问过的顶点,则从该顶点处继续进行广度优先遍历,直到图中所有的顶点都被访问过。
深度优先遍历
深度优先遍历
深度优先遍历又称DFS,其遍历过程类似于二叉树的先序遍历,从起始顶点开始不断对顶点进行深入遍历。
如下图:
深度优先遍历的实现:
- 深度优先遍历可以通过递归实现,同时也需要借助一个标记数组来记录各个顶点是否被访问过。
- 从起始顶点处开始进行递归遍历,在遍历过程中先对当前顶点进行访问,并将其标记为访问过,然后判断该顶点是否有邻接顶点,如果有邻接顶点并且该邻接顶点没有被访问过,则递归遍历该邻接顶点。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://深度优先遍历(子函数)void _dfs(int srci, vector<bool>& visited) {cout << _vertexs[srci] << " "; //访问visited[srci] = true; //标记为访问过for (int i = 0; i < _vertexs.size(); i++) { //找从srci连接出去的顶点if (_matrix[srci][i] != MAX_W && visited[i] == false) { //是邻接顶点,并且没有被访问过_dfs(i, visited); //递归遍历}}}//深度优先遍历void dfs(const V& src) {int srci = getVertexIndex(src); //起始顶点的下标vector<bool> visited(_vertexs.size(), false); //标记数组_dfs(srci, visited); //递归遍历cout << endl;}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}
说明一下:
- 如果所给图不是一个连通图,那么从一个顶点开始进行深度优先遍历,无法遍历完图中的所有顶点,这时可以遍历标记数组,查看哪些顶点还没有被访问过,对于没有被访问过的顶点,则从该顶点处继续进行深度优先遍历,直到图中所有的顶点都被访问过。
最小生成树
最小生成树
关于最小生成树:
- 一个连通图的最小连通子图称为该图的生成树,若连通图由 n 个顶点组成,则其生成树必含 n 个顶点和 n−1 条边,最小生成树指的是一个图的生成树中,总权值最小的生成树。
- 连通图中的每一棵生成树都是原图的一个极大无环子图,从其中删去任何一条边,生成树就不再连通,在其中引入任何一条新边,都会形成一条回路。
说明一下:
- 对于各个顶点来说,除了第一个顶点之外,其他每个顶点想要连接到图中,至少需要一条边使其连接进来,所以由 n 个顶点的连通图的生成树有 n个顶点和 n − 1 条边。
- 对于生成树来说,图中的每个顶点已经连通了,如果再引入一条新边,那么必然会使得被新边相连的两个顶点之间存在一条直接路径和一条间接路径,即形成回路。
- 最小生成树是图的生成树中总权值最小的生成树,生成树是图的最小连通子图,而连通图是无向图的概念,有向图对应的是强连通图,所以最小生成树算法的处理对象都是无向图。
构成最小生成树的准则
构造最小生成树的准则如下:
- 只能使用图中的边来构造最小生成树。
- 只能使用恰好n−1 条边来连接图中的n 个顶点。
- 选用的n−1 条边不能构成回路。
- 构造最小生成树的算法有Kruskal算法和Prim算法,这两个算法都采用了逐步求解的贪心策略。
Kruskal算法
Kruskal算法(克鲁斯卡尔算法)
Kruskal算法的基本思想如下:
- 构造一个含 n 个顶点、不含任何边的图作为最小生成树,对原图中的各个边按权值进行排序。
- 每次从原图中选出一条最小权值的边,将其加入到最小生成树中,如果加入这条边会使得最小生成树中构成回路,则重新选择一条边。
- 按照上述规则不断选边,当选出n−1 条合法的边时,则说明最小生成树构造完毕,如果无法选出n−1 条合法的边,则说明原图不存在最小生成树。
动图演示: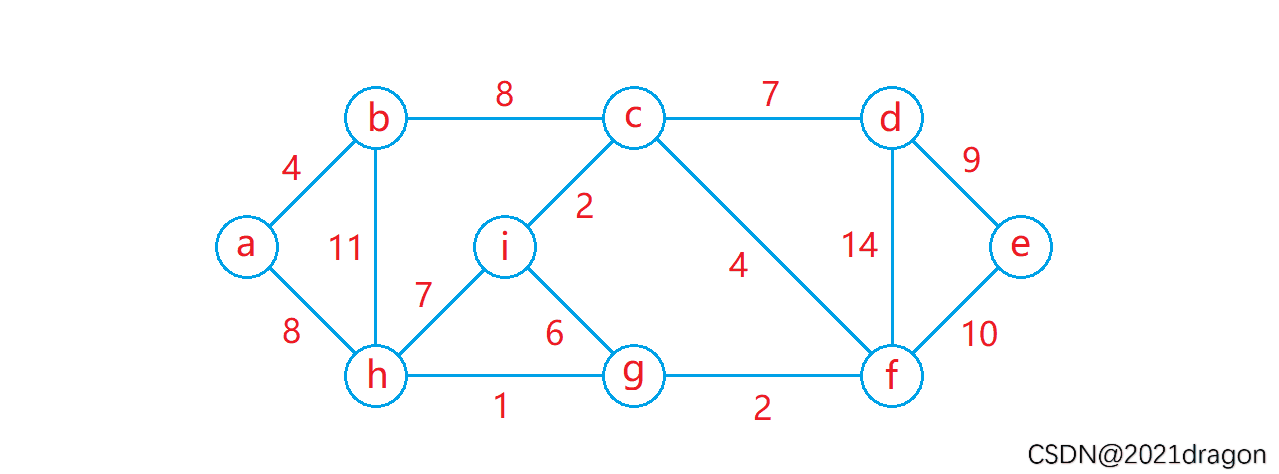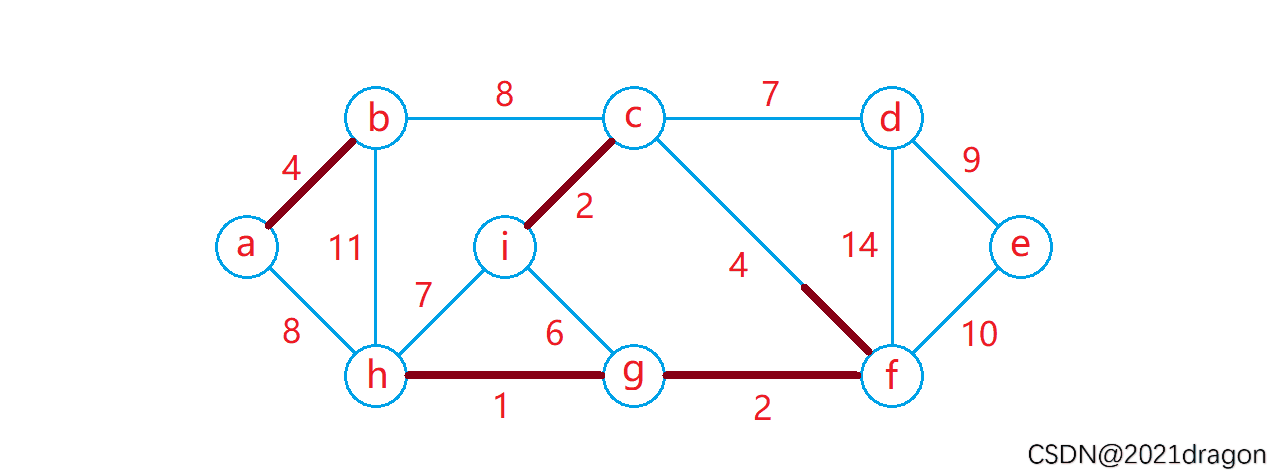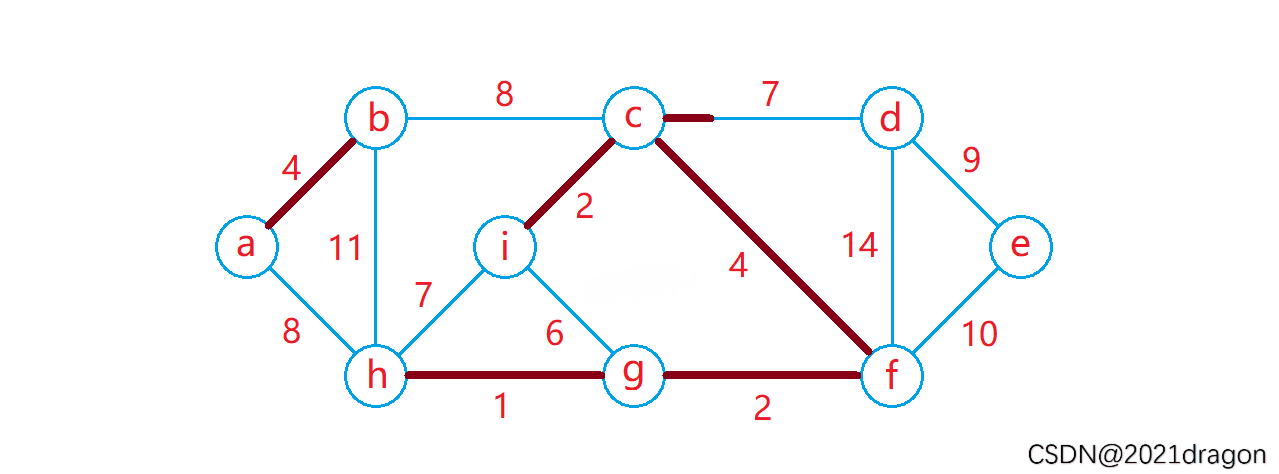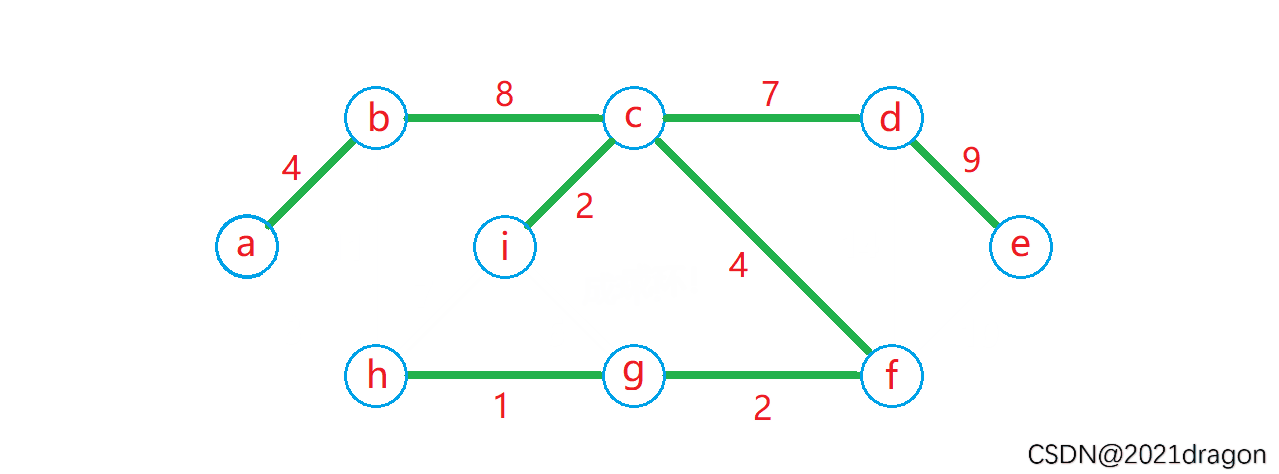
Kruskal算法的实现:
- 根据原图设置最小生成树的顶点集合,以及顶点与下标的映射关系,开辟最小生成树的邻接矩阵空间,并将矩阵中的值初始化为 MAX_W ,表示刚开始时最小生成树中不含任何边。
- 遍历原图的邻接矩阵,按权值将原图中的所有边添加到优先级队列(小堆)中,为了避免重复添加相同的边,在遍历原图的邻接矩阵时只应该遍历矩阵的一半。
- 使用一个并查集来辅助判环操作,刚开始时图中的顶点各自为一个集合,当两个顶点相连时将这两个顶点对应的集合进行合并,使得连通的顶点在同一个集合,这样通过并查集就能判断所选的边是否会使得最小生成树中构成回路,如果所选边连接的两个顶点本就在同一个集合,那么加入这条边就会构成回路。
- 使用count 和totalWeight 分别记录所选边的数量和最小生成树的总权值,当 count 的值等于n−1 时则停止选边,此时可以将最小生成树的总权值作为返回值进行返回。
- 每次选边时从优先级队列中获取一个权值最小的边,并通过并查集判断这条边连接的两个顶点是否在同一个集合,如果在则重新选边,如果不在则将这条边添加到最小生成树中,并将这条边连接的两个顶点对应的集合进行合并,同时更新count 和 totalWeight 的值。
- 当选边结束时,如果 count 的值等于 n−1 ,则说明最小生成树构造成功,否则说明原图无法构造出最小生成树。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://强制生成默认构造Graph() = default;void _addEdge(int srci, int dsti, const W& weight) {_matrix[srci][dsti] = weight; //设置邻接矩阵中对应的值if (Direction == false) { //无向图_matrix[dsti][srci] = weight; //添加从目标顶点到源顶点的边}}//添加边void addEdge(const V& src, const V& dst, const W& weight) {int srci = getVertexIndex(src), dsti = getVertexIndex(dst); //获取源顶点和目标顶点的下标_addEdge(srci, dsti, weight);}//边struct Edge {int _srci; //源顶点的下标int _dsti; //目标顶点的下标W _weight; //边的权值Edge(int srci, int dsti, const W& weight):_srci(srci), _dsti(dsti), _weight(weight){}bool operator>(const Edge& edge) const{return _weight > edge._weight;}};//获取当前图的最小生成树(Kruskal算法)W Kruskal(Graph<V, W, MAX_W, Direction>& minTree) {int n = _vertexs.size();//设置最小生成树的各个成员变量minTree._vertexs = _vertexs; //设置最小生成树的顶点集合minTree._vIndexMap = _vIndexMap; //设置最小生成树顶点与下标的映射minTree._matrix.resize(n, vector<W>(n, MAX_W)); //开辟最小生成树的二维数组空间priority_queue<Edge, vector<Edge>, greater<Edge>> minHeap; //优先级队列(小堆)//将所有边添加到优先级队列for (int i = 0; i < n; i++) {for (int j = 0; j < i; j++) { //只遍历矩阵的一半,避免重复添加相同的边if (_matrix[i][j] != MAX_W)minHeap.push(Edge(i, j, _matrix[i][j]));}}UnionFindSet ufs(n); //n个顶点的并查集int count = 0; //已选边的数量W totalWeight = W(); //最小生成树的总权值while (!minHeap.empty() && count < n - 1) {//从优先级队列中获取一个权值最小的边Edge minEdge = minHeap.top();minHeap.pop();int srci = minEdge._srci, dsti = minEdge._dsti;W weight = minEdge._weight;if (!ufs.inSameSet(srci, dsti)) { //边的源顶点和目标顶点不在同一个集合minTree._addEdge(srci, dsti, weight); //在最小生成树中添加边ufs.unionSet(srci, dsti); //合并源顶点和目标顶点对应的集合count++;totalWeight += weight;cout << "选边: " << _vertexs[srci] << "->" << _vertexs[dsti] << ":" << weight << endl;}else { //边的源顶点和目标顶点在同一个集合,加入这条边会构成环cout << "成环: " << _vertexs[srci] << "->" << _vertexs[dsti] << ":" << weight << endl;}}if (count == n - 1) {cout << "构建最小生成树成功" << endl;return totalWeight;}else {cout << "无法构成最小生成树" << endl;return W();}}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}说明一下:
- 在获取图的最小生成树时,会以无参的方式定义一个最小生成树对象,然后用原图对象调用上述Kruskal函数,通过输出型参数的方式获取原图的最小生成树,由于我们定义了一个带参的构造函数,使得编译器不再生成默认构造函数,因此需要通过default关键字强制生成Graph类的默认构造函数。
- 一条边包含两个顶点和边的权值,可以定义一个Edge结构体来描述一条边,结构体内包含边的源顶点和目标顶点的下标以及边的权值,在使用优先级队列构造小堆结构时,需要存储的对象之间能够支持 > 运算符操作,因此需要对Edge结构体的 > 运算符进行重载,将其重载为边的权值的比较。
- 当选出的边不会构成回路时,需要将这条边插入到最小生成树对应的图中,此时已经知道了这条边的源顶点和目标顶点对应的下标,可以在Graph类中新增一个_addEdge子函数,该函数支持通过源顶点和目标顶点的下标向图中插入边,而Graph类中原有的addEdge函数可以复用这个_addEdge子函数。
- 最小生成树不一定是唯一的,特别是当原图中存在很多权值相等的边的时候,比如对于动图中的图来说,将最小生成树中的bc 边换成 ah 边也是一棵最小生成树。
- 上述代码中通过优先级队列构造小堆来依次获取权值最小的边,你也可以通过其他排序算法按权值对边进行排序,然后按权值从小到大依次遍历各个边进行选边操作。
Prim算法
Prim算法(普里姆算法)
Prim算法的基本思想如下:
- 构造一个含 n 个顶点、不含任何边的图作为最小生成树,将图中的顶点分为两个集合,forest 集合中的顶点是已经连接到最小生成树中的顶点,remain 集合中的顶点是还没有连接到最小生成树中的顶点,刚开始时 forest 集合中只包含给定的起始顶点。
- 每次从连接forest 集合与 remain 集合的所有边中选出一条权值最小的边,将其加入到最小生成树中,由于选出来的边对应的两个顶点一个属于forest 集合,另一个属于 remain 集合,因此是不会构成回路的。
- 按照上述规则不断选边,当选出 n−1 条边时,所有的顶点都已经加入到了 forest 集合,此时最小生成树构造完毕,如果无法选出 n−1 条边,则说明原图不存在最小生成树。
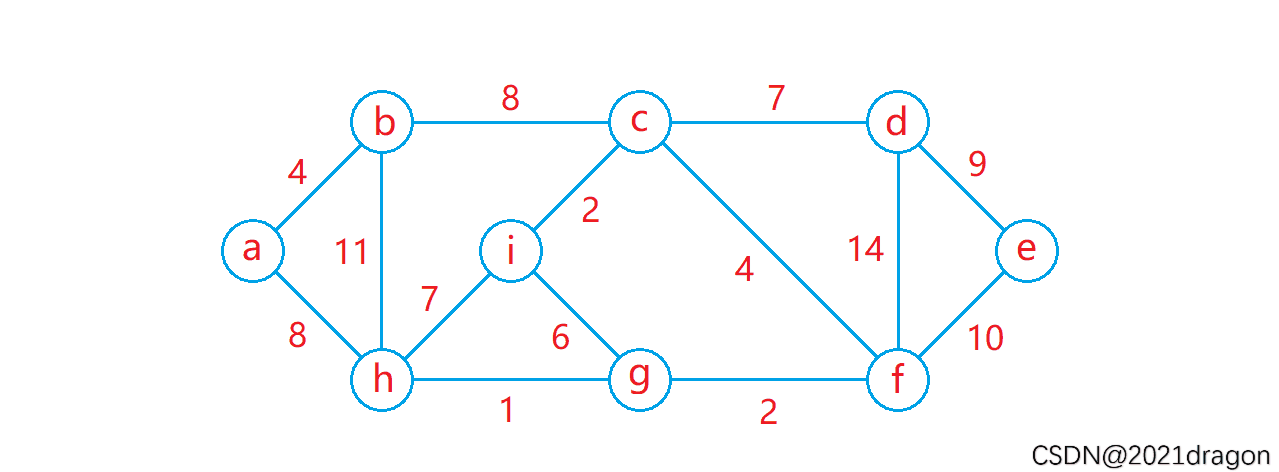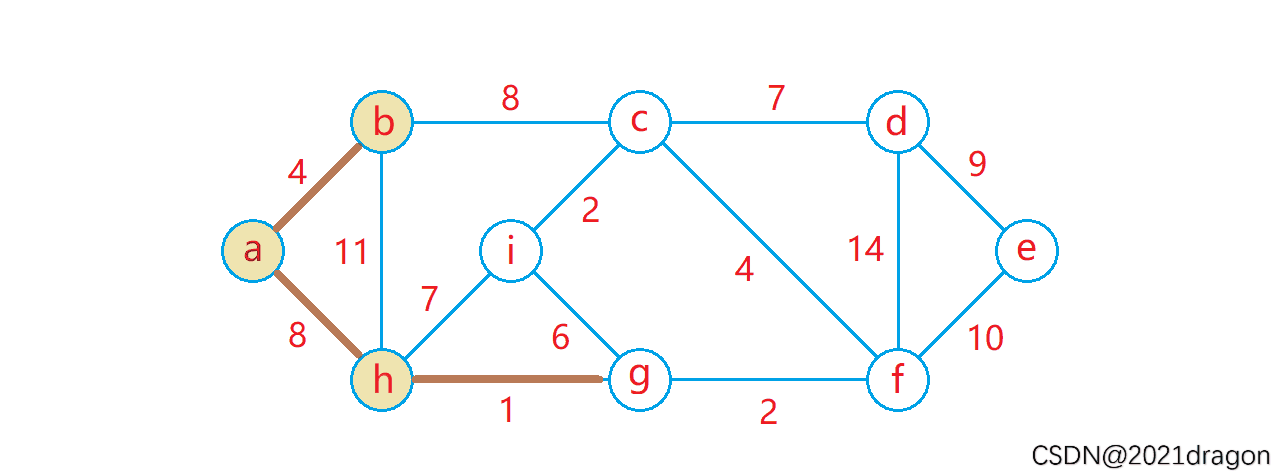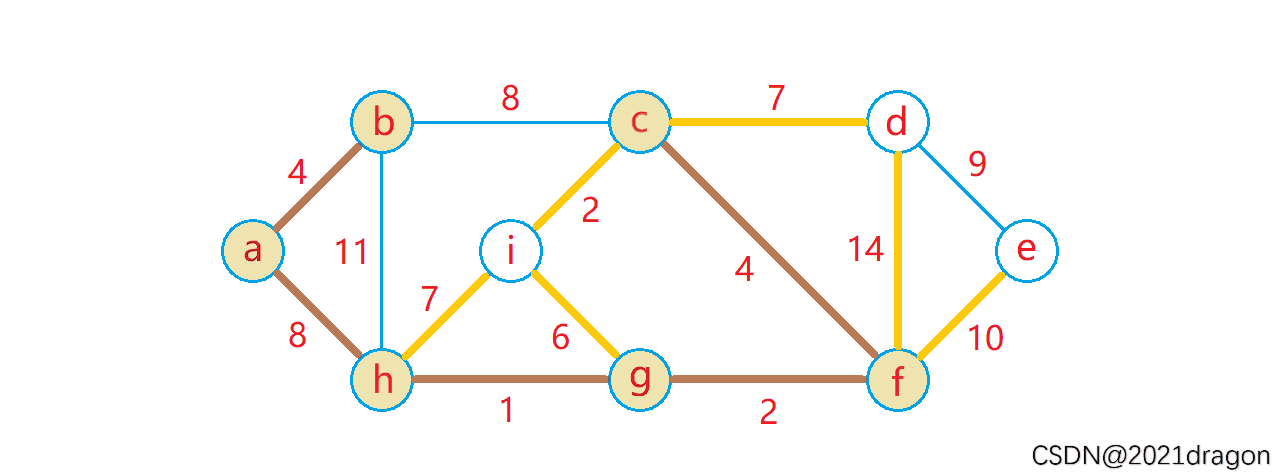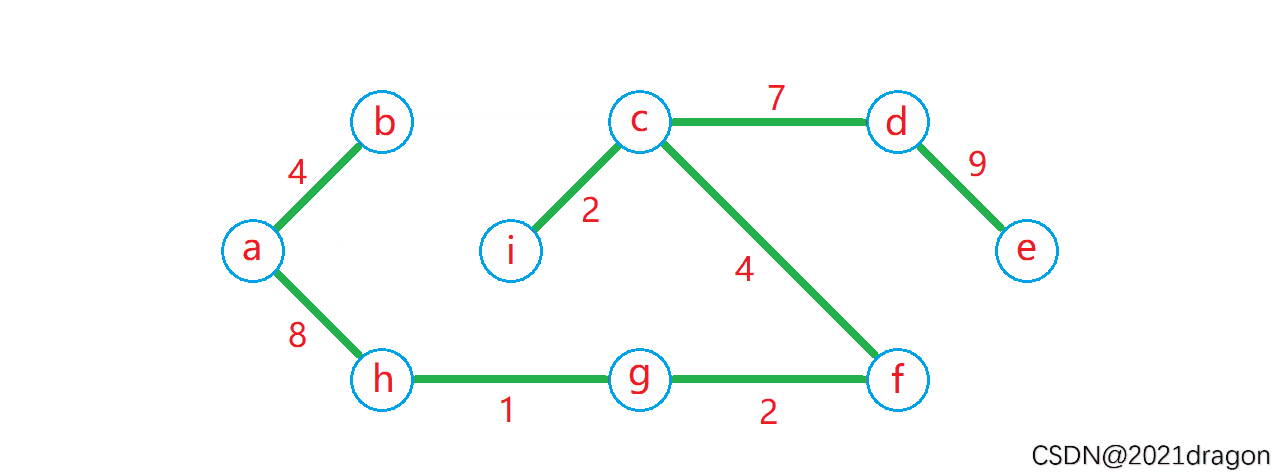
最短路径
关于最短路径:
- 最短路径问题:从带权有向图中的某一顶点出发,找出一条通往另一顶点的最短路径,最短指的是路径各边的权值总和达到最小,最短路径可分为单源最短路径和多源最短路径。
- 单源最短路径指的是从图中某一顶点出发,找出通往其他所有顶点的最短路径,而多源最短路径指的是,找出图中任意两个顶点之间的最短路径。
Prim算法的实现:
- 根据原图设置最小生成树的顶点集合,以及顶点与下标的映射关系,开辟最小生成树的邻接矩阵空间,并将矩阵中的值初始化为 MAX_W ,表示刚开始时最小生成树中不含任何边。
- 使用一个forest 数组来表示各个顶点是否在 forest 集合中,刚开始时只有起始顶点在 forest 集合中,并将所有从起始顶点连接出去的边加入优先级队列(小堆),这些边就是刚开始时连接 forest 集合与remain 集合的边。
- 使用 count 和 totalWeight 分别记录所选边的数量和最小生成树的总权值,当count 的值等于 n−1 时则停止选边,此时将最小生成树的总权值作为返回值进行返回。
- 每次选边时从优先级队列中获取一个权值最小的边,将这条边添加到最小生成树中,并将这条边的目标顶点加入 forest 集合中,同时更新 count 和 totalWeight 的值。此外,还需要将从这条边的目标顶点连接出去的边加入优先级队列,但是需要保证加入的边的目标顶点不能在 forest 集合,否则后续选出源顶点和目标顶点都在forest 集合的边就会构成回路。
- 需要注意的是,每次从优先级队列中选出一个权值最小的边时,还需要保证选出的这条边的目标顶点不在forest 集合中,避免构成回路。虽然向优先级队列中加入边时保证了加入的边的目标顶点不在forest 集合中,但经过后续不断的选边,可能会导致之前加入优先级队列中的某些边的目标顶点也被加入到了forest 集合中。
- 当选边结束时,如果 count 的值等于 n−1 ,则说明最小生成树构造成功,否则说明原图无法构造出最小生成树。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://边struct Edge {int _srci; //源顶点的下标int _dsti; //目标顶点的下标W _weight; //边的权值Edge(int srci, int dsti, const W& weight):_srci(srci), _dsti(dsti), _weight(weight){}bool operator>(const Edge& edge) const{return _weight > edge._weight;}};//获取当前图的最小生成树(Prim算法)W Prim(Graph<V, W, MAX_W, Direction>& minTree, const V& start) {int n = _vertexs.size();//设置最小生成树的各个成员变量minTree._vertexs = _vertexs; //设置最小生成树的顶点集合minTree._vIndexMap = _vIndexMap; //设置最小生成树顶点与下标的映射minTree._matrix.resize(n, vector<W>(n, MAX_W)); //开辟最小生成树的二维数组空间int starti = getVertexIndex(start); //获取起始顶点的下标vector<bool> forest(n, false);forest[starti] = true;priority_queue<Edge, vector<Edge>, greater<Edge>> minHeap; //优先级队列(小堆)//将从起始顶点连接出去的边加入优先级队列for (int i = 0; i < n; i++) {if (_matrix[starti][i] != MAX_W)minHeap.push(Edge(starti, i, _matrix[starti][i]));}int count = 0; //已选边的数量W totalWeight = W(); //最小生成树的总权值while (!minHeap.empty() && count < n - 1) {//从优先级队列中获取一个权值最小的边Edge minEdge = minHeap.top();minHeap.pop();int srci = minEdge._srci, dsti = minEdge._dsti;W weight = minEdge._weight;if (forest[dsti] == false) { //边的目标顶点还没有被加入到forest集合中//将从目标顶点连接出去的边加入优先级队列for (int i = 0; i < n; i++) {if (_matrix[dsti][i] != MAX_W && forest[i] == false) //加入的边的目标顶点不能在forest集合中minHeap.push(Edge(dsti, i, _matrix[dsti][i]));}minTree._addEdge(srci, dsti, weight); //在最小生成树中添加边forest[dsti] = true; //将边的目标顶点加入forest集合count++;totalWeight += weight;cout << "选边: " << _vertexs[srci] << "->" << _vertexs[dsti] << ":" << weight << endl;}else { //边的目标顶点已经在forest集合中,加入这条边会构成环cout << "成环: " << _vertexs[srci] << "->" << _vertexs[dsti] << ":" << weight << endl;}}if (count == n - 1) {cout << "构建最小生成树成功" << endl;return totalWeight;}else {cout << "无法构成最小生成树" << endl;return W();}}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}说明一下:
- Prim算法构造最小生成树的思想在选边时是不需要判环,但上述利用优先级队列实现的过程中仍需判环,如果在每次选边的时候能够通过某种方式,从连接forest 集合和remain 集合的所有边中选出权值最小的边,那么就无需判环,但这两个集合中的顶点是不断在变化的,每次选边时都遍历连接两个集合的所有边,该过程的时间复杂度较高。
- Kruskal算法本质是一种全局的贪心,每次选边时都是在所有边中选出权值最小的边,而Prim算法本质是一种局部的贪心,每次选边时是从连接 forest 集合和 remain 集合的所有边中选出权值最小的边。
最短路径
最短路径
关于最短路径:
- 最短路径问题:从带权有向图中的某一顶点出发,找出一条通往另一顶点的最短路径,最短指的是路径各边的权值总和达到最小,最短路径可分为单源最短路径和多源最短路径。
- 单源最短路径指的是从图中某一顶点出发,找出通往其他所有顶点的最短路径,而多源最短路径指的是,找出图中任意两个顶点之间的最短路径。
单源最短路径-Dijkstra算法
Dijkstra算法(迪杰斯特拉算法)
使用前提:图中所有边的权值非负。
Dijkstra算法的基本思想如下:
- 将图中的顶点分为两个集合,集合 S 中的顶点是已经确定从源顶点到该顶点的最短路径的顶点,集合 Q 中的顶点是尚未确定从源顶点到该顶点的最短路径的顶点。
- 每个顶点都有一个估计值,表示从源顶点到该顶点的可能最短路径长度,每次从集合Q 中选出一个估计值最小的顶点,将其加入到集合 S 中,并对该顶点连接出去的顶点的估计值和前驱顶点进行松弛更新。
- 按照上述步骤不断从集合 Q 中选取估计值最小的顶点到集合 S 中,直到所有的顶点都被加入到集合 S 中,此时通过各个顶点的估计值就可以得知源顶点到该顶点的最短路径长度,通过各个顶点的前驱顶点就可以得知最短路径的走向。
动图演示:
Dijkstra算法的实现:
- 使用一个dist 数组来记录从源顶点到各个顶点的最短路径长度估计值,初始时将源顶点的估计值设置为权值的缺省值(比如int就是0),表示从源顶点到源顶点的路径长度为0,将其余顶点的估计值设置为MAX_W,表示从源顶点暂时无法到达其他顶点。
- 使用一个PathparentPath 数组来记录到达各个顶点路径的前驱顶点,初始时将各个顶点的前驱顶点初始化为-1,表示各个顶点暂时只能自己到达自己,没有前驱顶点。
- 使用一个bool 数组来记录各个顶点是否在 S 集合中,初始时所有顶点均不在S 集合,表示各个顶点都还没有确定最短路径。
- 每次从 Q 集合中选出一个估计值最小的顶点 u,将其加入到 S 集合,并对顶点u 连接出去的各个顶点v 进行松弛更新,如果能够将顶点 v 更新出更小的估计值,则更新其估计值,并将被更新的顶点 v 的前驱顶点改为顶点 u ,因为从顶点 u 到顶点 v 能够得到更小的估计值,所以在当前看来(后续可能还会更新)到达顶点 v 的最短路径的前驱顶点就应该是顶点 u ,如果不能将顶点 v 更新出更小的估计值,则维持原样。
- 当所有的顶点都加入集合 S 后,dist 数组中存储的就是从源顶点到各个顶点的最短路径长度,parentPath 数组中存储的就是从源顶点到各个顶点的最短路径的前驱顶点,通过不断查找各个顶点的前驱顶点,最终就能得到从源顶点到各个顶点的最短路径。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://获取单源最短路径(Dijkstra算法)void Dijkstra(const V& src, vector<W>& dist, vector<int>& parentPath) {int n = _vertexs.size();int srci = getVertexIndex(src); //获取源顶点的下标dist.resize(n, MAX_W); //各个顶点的估计值初始化为MAX_WparentPath.resize(n, -1); //各个顶点的前驱顶点初始化为-1dist[srci] = W(); //源顶点的估计值设置为权值的缺省值vector<bool> S(n, false); //已经确定最短路径的顶点集合for (int i = 0; i < n; i++) { //将Q集合中的n个顶点全部加入到S集合//从集合Q中选出一个估计值最小的顶点W minW = MAX_W; //最小估计值int u = -1; //估计值最小的顶点for (int j = 0; j < n; j++) {if (S[j] == false && dist[j] < minW) {minW = dist[j];u = j;}}S[u] = true; //将选出的顶点加入到S集合//对u连接出去的顶点进行松弛更新for (int v = 0; v < n; v++) {if (S[v] == false && _matrix[u][v] != MAX_W && dist[u] + _matrix[u][v] < dist[v]) { //松弛的顶点不能在S集合dist[v] = dist[u] + _matrix[u][v]; //松弛更新出更小的估计值parentPath[v] = u; //更新路径的前驱顶点}}}}//打印最短路径及路径权值void printShortPath(const V& src, const vector<W>& dist, const vector<int>& parentPath) {int n = _vertexs.size();int srci = getVertexIndex(src); //获取源顶点的下标for (int i = 0; i < n; i++) {vector<int> path;int cur = i;while (cur != -1) { //源顶点的前驱顶点为-1path.push_back(cur);cur = parentPath[cur];}reverse(path.begin(), path.end()); //逆置for (int j = 0; j < path.size(); j++) {cout << _vertexs[path[j]] << "->";}cout << "路径权值: " << dist[i] << "" << endl;}}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}
说明一下:
- 为了方便观察,可以在类中增加一个 printShortPath 接口,用于根据 dist 和 parentPath 数组来打印最短路径及路径权值。
- 对于从源顶点 s 到目标顶点 j 的最短路径来说,如果最短路径经过了顶点 i ,那么最短路径中从源顶点 s 到顶点 i 的这条子路径一定是源顶点 s 到顶点 i 的最短路径,因此可以通过存储前驱顶点的方式来表示从源顶点到各个顶点的最短路径。
- Dijkstra算法每次需要选出一个顶点,并对其连接出去的顶点进行松弛更新,因此其时间复杂度是 O (N2) 空间复杂度是O(N) 。
Dijkstra算法的原理
- Dijkstra算法每次从集合 Q 中选出一个估计值最小的顶点 u ,将该顶点加入到集合 S 中,表示确定了从源顶点到顶点 u 的最短路径。
- 因为图中所有边的权值非负(使用Dijkstra算法的前提),所以对于估计值最小的顶点 u 来说,其估计值不可能再被其他比它估计值更大的顶点松弛更新得更小,因此顶点 u 的最短路径就是当前的估计值。
- 而对于集合 Q 中的其他顶点来说,这些顶点的估计值比顶点 u 的估计值大,因此顶点 u 可能将它们的估计值松弛更新得更小,所以顶点 u 在加入集合 S 后还需要尝试对其连接出去的顶点进行松弛更新。
单源最短路径-Bellman-Ford算法
Bellman-Ford算法(贝尔曼福特算法)
Bellman-Ford算法的基本思想如下:
- Bellman-Ford算法本质是暴力求解,对于从源顶点 s 到目标顶点 j 的路径来说,如果存在从源顶点s 到顶点 i 的路径,还存在一条从顶点 i 到顶点 j 的边,并且其权值之和小于当前从源顶点 s 到目标顶点 j 的路径长度,则可以对顶点 j 的估计值和前驱顶点进行松弛更新。
- Bellman-Ford算法根据路径的终边来进行松弛更新,但是仅对图中的边进行一次遍历可能并不能正确更新出最短路径,最坏的情况下需要对图中的边进行 n−1 轮遍历(n 表示图中的顶点个数)。
Bellman-Ford算法的实现:
- 使用一个dist 数组来记录从源顶点到各个顶点的最短路径长度估计值,初始时将源顶点的估计值设置为权值的缺省值(比如int就是0),表示从源顶点到源顶点的路径长度为0,将其余顶点的估计值设置为MAX_W,表示从源顶点暂时无法到达其他顶点。
- 使用一个 parentPath 数组来记录到达各个顶点路径的前驱顶点,初始时将各个顶点的前驱顶点初始化为-1,表示各个顶点暂时只能自己到达自己,没有前驱顶点。
- 对图中的边进行 n−1 轮遍历,对于i−>j 的边来说,如果存在s−>i 的路径,并且s−>i 的路径权值与边 i−>j 的权值之和小于当前 s−>j 的路径长度,则将顶点 j 的估计值进行更新,并将顶点j 的前驱顶点改为顶点 i ,因为 i−>j 是图中的一条直接相连的边,在这条路径中顶点 j 的上一个顶点就是顶点 i 。
- 再对图中的边进行一次遍历,尝试进行松弛更新,如果还能更新则说明图中带有负权回路,无法找到最短路径
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://获取单源最短路径(BellmanFord算法)bool BellmanFord(const V& src, vector<W>& dist, vector<int>& parentPath) {int n = _vertexs.size();int srci = getVertexIndex(src); //获取源顶点的下标dist.resize(n, MAX_W); //各个顶点的估计值初始化为MAX_WparentPath.resize(n, -1); //各个顶点的前驱顶点初始化为-1dist[srci] = W(); //源顶点的估计值设置为权值的缺省值for (int k = 0; k < n - 1; k++) { //最多更新n-1轮bool update = false; //记录本轮是否更新过for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (_matrix[i][j] != MAX_W && dist[i] != MAX_W && dist[i] + _matrix[i][j] < dist[j]) {dist[j] = dist[i] + _matrix[i][j]; //松弛更新出更小的路径权值parentPath[j] = i; //更新路径的前驱顶点update = true;}}}if (update == false) { //本轮没有更新过,不必进行后续轮次的更新break;}}//更新n-1轮后如果还能更新,则说明带有负权回路for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j]) {return false; //带有负权回路的图无法求出最短路径}}}return true;}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}
说明一下:
- Bellman-Ford算法是暴力求解,可以解决带有负权边的单源最短路径问题。
- 负权回路指的是在图中形成回路的各个边的权值之和为负数,路径每绕一圈回路其权值都会减少,导致无法找到最短路径,由于最多需要进行n−1 轮松弛更新,因此可以在 n−1 轮松弛更新后再进行一轮松弛更新,如果还能进行更新则说明带有负权回路。
- Bellman-Ford算法需要对图中的边进行 n 轮遍历,因此其时间复杂度是 O(N×E),由于这里是用邻接矩阵实现的,遍历图中的所有边的时间复杂度是O(N2)所以上述代码的时间复杂度是O(N3)空间复杂度是O(N)。
为什么最多进行n−1 轮松弛更新?
从一个顶点到另一个顶点的最短路径中不能包含回路:
- 如果形成回路的各个边的权值之和为负数,则该回路为负权回路,找不到最短路径。
- 如果形成回路的各个边的权值之和为非负数,则多走这个回路是“徒劳”的,可能会使得路径长度变长。
在每一轮松弛过程中,后面路径的更新可能会影响到前面已经更新过的路径,比如使得前面已经更新过的路径的长度可以变得更短,或者使得某些源顶点之前不可达的顶点变得可达,但每一轮松弛至少能确定最短路径中的一条边,如果图中有n 个顶点,那么两个顶点之间的最短路径最多有n−1 条边,因此最多需要进行n−1 次松弛更新。
例如下图中,顶点A、B、C、D、E 的下标分别是0、1、2、3、4,现在要计算以顶点 E 为源顶点的单源最短路径。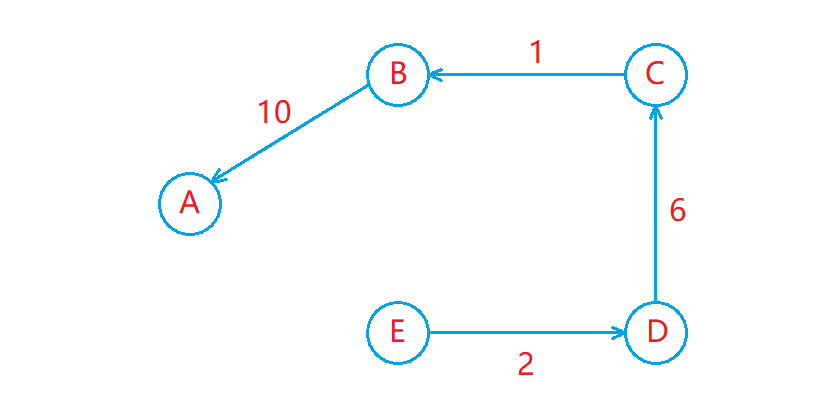
对于上述图来说,Bellman-Ford算法在第一轮松弛的时候只能更新出E−>D 这条边,在第二轮的时候只能更新出 D−>C ,以此类推,最终就会进行4轮松弛更新(建议通过代码调试观察)。
说明一下:
- 由于只有当前轮次进行过更新,才有可能会影响其他路径,因此在代码中使用update 标记每轮松弛算法是否进行过更新,如果没有进行过更新,则无需进行后面轮次的更新。
- Bellman-Ford算法还有一个优化方案叫做SPFA(Shortest Path Faster Algorithm),其用一个队列来维护可能需要松弛更新的顶点,避免了不必要的冗余计算,大家可以自行了解。
多源最短路径-Floyd-Warshall算法
Floyd-Warshall算法(弗洛伊德算法)
Floyd-Warshall算法的基本思想如下:
- Floyd-Warshall算法解决的是任意两点间的最短路径的算法,其考虑的是路径的中间顶点,对于从顶点 i ii 到顶点 j jj 的路径来说,如果存在从顶点 i 到顶点 k 的路径,还存在从顶点 k 到顶点 j 的路径,并且这两条路径的权值之和小于当前从顶点 i 到顶点 j 的路径长度,则可以对顶点 j 的估计值和前驱顶点进行松弛更新。
- Floyd-Warshall算法本质是一个简单的动态规划,就是判断从顶点 i 到顶点 j 的这条路径是否经过顶点 k ,如果经过顶点 k 可以让这条路径的权值变得更小,则经过,否则则不经过。
Floyd-Warshall算法的实现:
- 使用一个 vvDist 二维数组来记录从各个源顶点到各个顶点的最短路径长度的估计值,vvDist[i][j] 表示从顶点 i ii 到顶点 j 的最短路径长度的估计值,初始时将二维数组中的值全部初始化为MAX_W,表示各个顶点之间暂时无法互通。
- 使用一个vvParentPath 二维数组来记录从各个源顶点到达各个顶点路径的前驱顶点,初始时将二维数组中的值全部初始化为-1,表示各个顶点暂时只能自己到自己,没有前驱顶点。
- 根据邻接矩阵对vvDist 和vvParentPath 进行初始化,如果从顶点 i 到顶点 j 有直接相连的边,则将 vvDist[i][j] 初始化为这条边的权值,并将 vvParentPath[i][j] 初始化为 i ,表示在i−>j 这条路径中顶点 j 前驱顶点是 i ,将 vvDist[i][i] 的值设置为权值的缺省值(比如int就是0),表示自己到自己的路径长度为0。
- 依次取各个顶点 k 作为 i−>j 路径的中间顶点,如果同时存在i−>k 的路径和k−>j 的路径,并且这两条路径的权值之和小于当前i−>j 路径的权值,则更新vvDist[i][j] 的值,并将vvParentPath[i][j] 的值更新为vvParentPath[k][j] 的值。
代码如下:
//邻接矩阵
namespace Matrix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public://获取多源最短路径(FloydWarshall算法)void FloydWarshall(vector<vector<W>>& vvDist, vector<vector<int>>& vvParentPath) {int n = _vertexs.size();vvDist.resize(n, vector<W>(n, MAX_W)); //任意两个顶点直接的路径权值初始化为MAX_WvvParentPath.resize(n, vector<int>(n, -1)); //各个顶点的前驱顶点初始化为-1//根据邻接矩阵初始化直接相连的顶点for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (_matrix[i][j] != MAX_W) { //i->j有边vvDist[i][j] = _matrix[i][j]; //i->j的路径权值vvParentPath[i][j] = i; //i->j路径的前驱顶点为i}if (i == j) { //i->ivvDist[i][j] = W(); //i->i的路径权值设置为权值的缺省值}}}for (int k = 0; k < n; k++) { //依次取各个顶点作为i->j路径的中间顶点for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W &&vvDist[i][k] + vvDist[k][j] < vvDist[i][j]) { //存在i->k和k->j的路径,并且这两条路径的权值之和小于当前i->j路径的权值vvDist[i][j] = vvDist[i][k] + vvDist[k][j]; //松弛更新出更小的路径权值vvParentPath[i][j] = vvParentPath[k][j]; //更小路径的前驱顶点}}}}}private:vector<V> _vertexs; //顶点集合unordered_map<V, int> _vIndexMap; //顶点映射下标vector<vector<W>> _matrix; //邻接矩阵};
}说明一下:
- Bellman-Ford算法是根据路径的终边来进行松弛更新的,而Floyd-Warshall算法是根据路径经过的中间顶点来进行松弛更新的,因为根据Bellman-Ford算法中的dist 只能得知从指定源顶点到某一顶点的路径权值,而根据Floyd-Warshall算法中的vvDist 可以得知任意两个顶点之间的路径权值。
- Floyd-Warshall算法的时间复杂度是O(N3)空间复杂度是O(N2)虽然求解多源最短路径也可以以图中不同的顶点作为源顶点,去调用Dijkstra算法或Bellman-Ford算法,但Dijkstra算法不能解决带负权的图,Bellman-Ford算法调用 N 次的时间复杂度又太高。
相关文章:
高阶数据结构——图
图 图的基本概念 图的基本概念 图是由顶点集合和边的集合组成的一种数据结构,记作 G ( V , E ) G(V, E)G(V,E) 。 有向图和无向图: 在有向图中,顶点对 < x , y >是有序的,顶点对 < x , y > 称为顶点 x 到顶点 y 的…...

高性能AC算法多关键词匹配文本功能Java实现
直接上测试结果: 1000000数据集。 1000000关键词(匹配词) 装载消耗时间:20869 毫秒 匹配消耗时间:6599 毫秒 代码和测试案例: package com.baian.tggroupmessagematchkeyword.ac;import lombok.Data;im…...
如何在没有第三方.NET库源码的情况,调试第三库代码?
大家好,我是沙漠尽头的狼。 本方首发于Dotnet9,介绍使用dnSpy调试第三方.NET库源码,行文目录: 安装dnSpy编写示例程序调试示例程序调试.NET库原生方法总结 1. 安装dnSpy dnSpy是一款功能强大的.NET程序反编译工具,…...
仿互站资源商城平台系统源码多款应用模版
首先安装好环境,推荐用Linux宝塔 请示:安装前请先别开防火墙,和跨站篡改 第1步上传程序到服务器, 第2步修改数据库文件,config/config.php 第3步,导入数据,根目录的数据库文件夹里面 数据.s…...
华为云云耀云服务器L实例评测 | L实例性能测试实践
🦖我是Sam9029,一个前端 Sam9029的CSDN博客主页:Sam9029的博客_CSDN博客-JS学习,CSS学习,Vue-2领域博主 **🐱🐉🐱🐉恭喜你,若此文你认为写的不错,不要吝啬你的赞扬,求…...
VR赋能红色教育,让爱国主义精神永放光彩
昨天的918防空警报长鸣,人们默哀,可见爱国主义精神长存。为了贯彻落实“把红色资源利用好、红色传统发扬好、红色基因传承好”的指示精神,许多红色景点开始引入VR全景展示技术,为游客提供全方位720度无死角的景区展示体验。 VR全…...

计算机视觉与深度学习-卷积神经网络-卷积图像去噪边缘提取-图像去噪 [北邮鲁鹏]
目录标题 参考学习链接图像噪声噪声分类椒盐噪声脉冲噪声对椒盐噪声&脉冲噪声去噪使用高斯卷积核中值滤波器 高斯噪声减少高斯噪声 参考学习链接 计算机视觉与深度学习-04-图像去噪&卷积-北邮鲁鹏老师课程笔记 图像噪声 噪声点,其实在视觉上看上去让人感…...

三行代码实现图像画质修复,图片清晰度修复,清晰度提升python
核心代码 # 原始文件 enhancer ImageEnhance.Sharpness(Image.open(文件路径.png)) # 增强图片 img_enhanced enhancer.enhance(增强系数float) # 输出目标文件 img_enhanced.save(文件名.png)注意,输入输出文件格式必须一致 所需依赖 # 文件选择框,…...
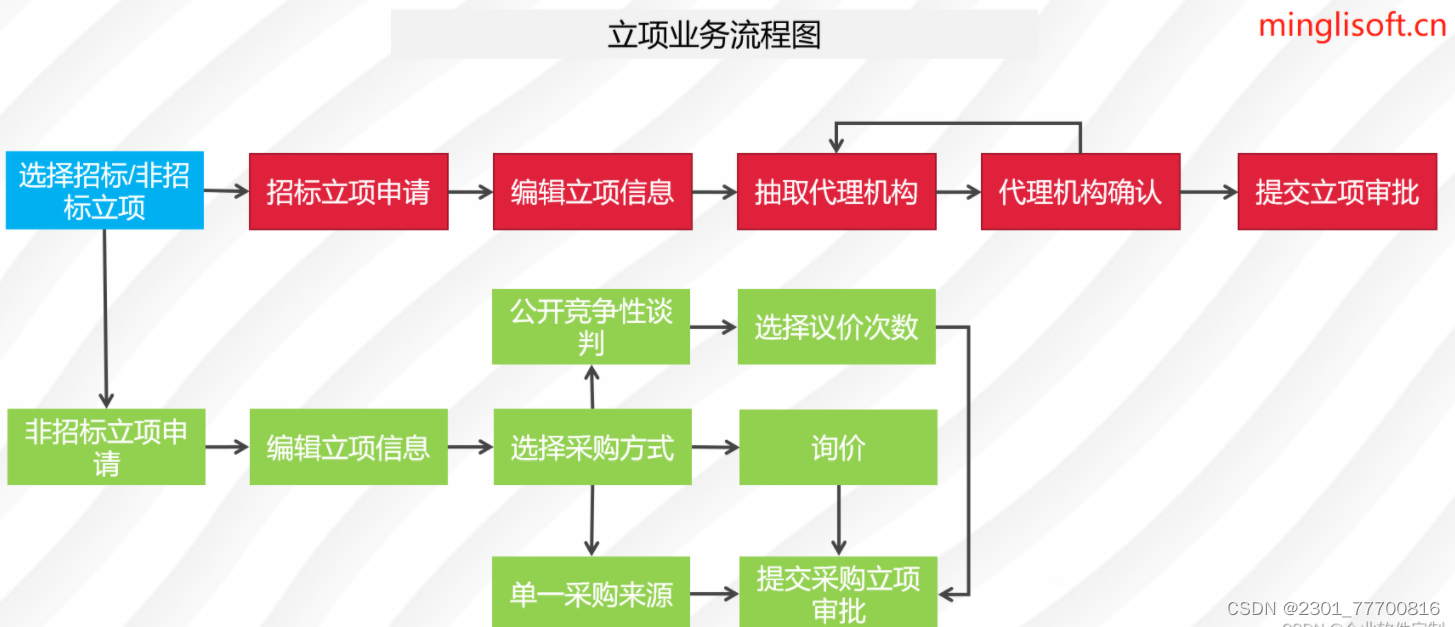
企业电子招投标采购系统源码之电子招投标的组成
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外部供…...
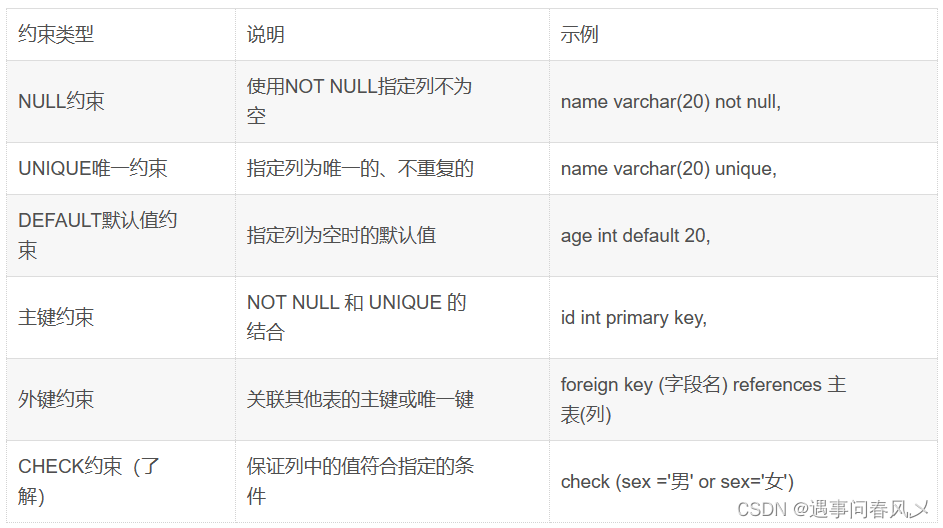
【MySQL】 MySQL的增删改查(进阶)--贰
文章目录 🛫新增🛬查询🌴聚合查询🚩聚合函数🎈GROUP BY子句📌HAVING 🎋联合查询⚾内连接⚽外连接🧭自连接🏀子查询🎡合并查询 🎨MySQL的增删改查(…...

第七章 查找
一、树形查找-二叉排序树和红黑树 二叉排序树 // 二叉排序树节点 typedef struct BSTNode{ElemType key;struct BSTNode *lchild, *rchild; } BSTNode, *BSTree;五叉查找树 // 5叉排序树的节点定义 struct Node{ElemType keys[4]; // 5叉查找树一个节点最多4个关键字struct…...

openfeign返回消息报错.UnknownContentTypeException
1. springcloud项目使用openfeign报错 org.springframework.web.client.UnknownContentTypeException: Could not extract response: no suitable HttpMessageConverter found for response type [com.yl.base.Result<java.util.List<com.yl.entity.LabelConfig>>…...
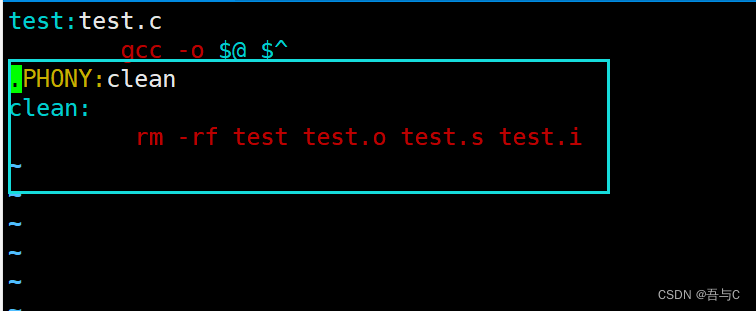
[Linux入门]---Linux项目自动化构建工具-make/Makefile
目录 1.背景2.make指令输入make默认为Makefile文件第一条指令执行Makefile文件对gcc指令特殊处理及原理特殊符号 3.总结 1.背景 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力一个工程中的源文件不计数,其按类型、功能、模块分别放…...

[Python进阶] 程序打包之Pyinstaller参数介绍
5.4 Pyinstaller参数介绍 5.4.1 选项参数 参数名 说明 -h、–help 查看Pyinstaller所有命令的用法和帮助 -v、–version 查看当前Pyinstaller版本 –distpath DIR 设置dist位置,默认当前目录 –workpath WORKPATH 设置build位置,默认当前目录 -y、–no…...

Python中如何判断列表中的元素,是否在一段文本中??
#我的Python教程 #官方微信公众号:wdPython1.要判断列表中的每个元素是否在一段文本中,可以使用Python中的字符串的 in 运算符来实现。以下是一个示例代码: text "Hello, how are you today?" word_list ["Hello", &…...
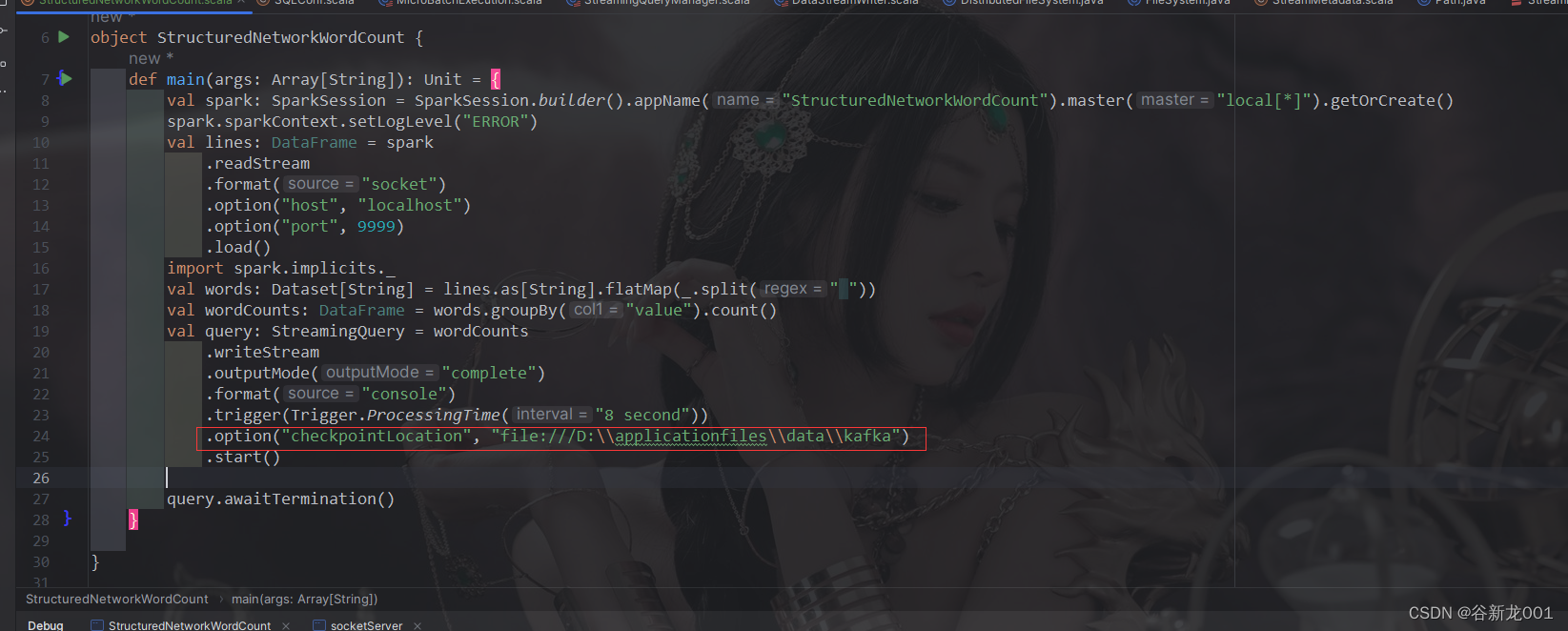
spark Structured报错解决
报错,不想看原因的直接去解决方案试试 Exception in thread "main" java.lang.IllegalArgumentException: Pathname /C:/Users/Administrator/AppData/Local/Temp/1/temporary-611514af-8dc5-4b20-9237-e5f2d21fdf88/metadata from hdfs://master:8020/C…...

Matter 协议系列:发现
Commissionable 发现 Commissionable 发现发生在投入使用(未绑定)之前,指的是发现和识别Commissionable 节点的过程。有三种方法可以通过这些方法中的任何一种来 广播Commissionable 的节点: 蓝牙低功耗(BLEÿ…...

Oracle 12c Docker镜像配置SSL
一、Docker运行Oracle 12c服务 a.拉取镜像 docker pull truevoly/oracle-12cb.运行 docker run -d -p 1521:1521 -p 2484:2484 -v /data/oracle/:/opt/oracle --name oracle_12c truevoly/oracle-12cc.查看日志 docker logs -f oracle_12cd.出现如下信息,则启动…...
版本控制系统git:一文了解git,以及它在生活中的应用,网站维护git代码,图导,自动化部署代码
目录 1.Git是什么 2.git在生活中的应用 2.1git自动化部署代码 3.网站维护git代码 3.1如何在Git代码托管平台等上创建一个仓库 3.2相关文章 4.ruby实现基础git 4.1.Git add 4.2 Git commit 4.3 Git log 1.Git是什么 Git是一个版本控制系统,它可以追踪文件的…...
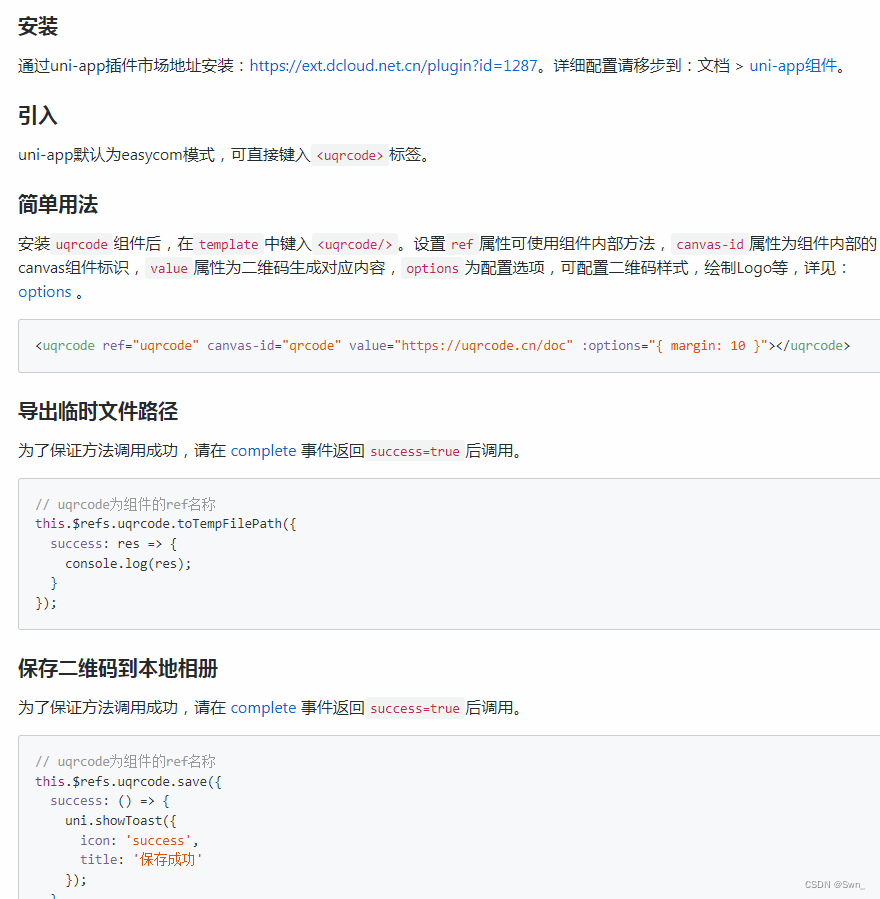
uqrcode+uni-app 微信小程序生成二维码
使用微信小程序需要弹出动态二维码的需求,从插件市场选了一个下载次数较多的组件引入到项目中uqrcode,使用步骤如下: 1、从插件市场下载 插件地址:https://ext.dcloud.net.cn/plugin?id1287,若你是跟我一样是用uni-…...

微服务核心框架设计:从Bumblecore看高可用架构与工程实践
1. 项目概述:从“Bumblecore”看现代微服务架构的演进与核心实践最近在梳理团队的技术资产时,我重新审视了一个内部代号为“Bumblecore”的微服务核心框架。这个项目并非一个开源明星,但在我们过去几年的业务高速迭代中,它扮演了至…...

【ROS进阶-1】从零构建自定义消息:实战配置与编译全解析
1. 为什么需要自定义ROS消息 在ROS开发中,消息是节点间通信的基础载体。虽然ROS已经提供了丰富的标准消息类型,比如std_msgs、geometry_msgs等,但在实际项目中,我们经常会遇到标准消息无法满足需求的情况。就像在C编程中ÿ…...

ANSYS Workbench网格划分进阶:扫掠、多区与2D网格的实战精解
1. 扫掠网格划分:从原理到实战技巧 第一次用ANSYS Workbench做薄壁结构分析时,我对着那个复杂的几何模型发呆了半小时——到底该选哪种网格划分方法?直到掌握了扫掠网格的精髓,才发现原来处理这类问题可以如此高效。扫掠网格特别适…...

给Windows桌面注入macOS灵魂:鼠标指针美化的艺术之旅
给Windows桌面注入macOS灵魂:鼠标指针美化的艺术之旅 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.com/gh_mirrors/ma/macOS…...

mitojs高级配置与Hook机制:如何实现高度定制化监控
mitojs高级配置与Hook机制:如何实现高度定制化监控 【免费下载链接】monitor 👀 一款轻量级的收集页面的用户点击行为、路由跳转、接口报错、代码报错、页面性能并上报服务端的SDK 项目地址: https://gitcode.com/gh_mirrors/mo/monitor 在当今We…...

CANN/asc-devkit向量减法ReLU函数
asc_sub_relu 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...

Linux超级计算机Roadrunner的设计与优化实践
1. Linux超级计算机Roadrunner的设计背景与核心理念在1990年代末期,高性能计算领域正处于一个关键的转折点。传统超级计算机如Cray系列虽然性能强大,但价格昂贵且维护成本极高,使得大多数研究机构难以负担。与此同时,个人计算机性…...

OpenHarmony.Avalonia 归档事件对中国自主软件生态的影响--信任的坍塌与生态的异化
026年5月8日,中国开源技术社区发生了一起具有里程碑意义的争议性事件:由开发者“布布”(Bubu)主导的 OpenHarmony-NET/OpenHarmony.Avalonia 项目正式宣告停止更新并进入归档状态。这一决定不仅标志着一个由民间力量驱动的底层基础…...

【大模型灰度发布黄金法则】:奇点智能大会首次披露7大避坑指标与实时熔断阈值
更多请点击: https://intelliparadigm.com 第一章:大模型灰度发布策略:奇点智能大会 在2024年奇点智能大会上,多家头部AI企业联合发布了面向生产环境的大模型灰度发布参考架构,强调“可控、可观、可退”三大核心原则。…...

Rust Trait系统深度解析:从基础到高级应用
Rust Trait系统深度解析:从基础到高级应用 引言 Trait是Rust中实现代码复用和多态的核心机制。通过Trait,我们可以定义共享行为,并为不同类型实现这些行为。 本文将深入探讨Rust Trait系统的核心概念、高级特性和最佳实践。 一、Trait基础 1.…...