2023 第十二届中国智能产业高峰论坛 - 文档大模型的未来展望
目录
- 前言
- 文档图像分析识别与理解中的技术挑战
- 文档图像分析识别与理解的研究主题
- 文档图像分析与预处理
- 文档解析与识别
- 版面分析与还原
- 文档信息抽取与理解
- AI安全
- 知识化&存储检索和管理
- 多模态大模型在文档图像处理中的应用
- 多模态的GPT-4在文档图像上的表现
- 多模态的Google Bard在文档图像上的表现
- 文档图像大模型的进展
- 文档图像专有大模型
- LayoutLM系列
- LiLT
- UDOP
- Donut
- 多模态大模型
- BLIP2
- Flamingo
- LLaVA
- MiniGPT-4
- 多模态大模型用于OCR领域的局限性
- 文档图像是更偏向于文字还是更偏向于图像?
- Pixel2seq大模型系列
- Pix2Seq
- UniTAB
- NOUGAT
- 文档图像大模型探索
- 文档图像大模型设计思路
- SPTS文档图像大模型
- SPTS
- 基于SPTS的OCR大一统模型(SPTS v3)
- SPTSv3的任务定义
- 场景文本端到端检测识别
- 表格结构识别
- 手写数学公式识别
- 总结
前言
在2023年的第十二届中国智能产业高峰论坛上,合合信息副总经理和高级工程师丁凯博士为我们带来了一场精彩的演讲,分享了关于文档大模型的最新研究成果以及对未来的展望。
合合信息是一家领先的人工智能和大数据科技企业,以其创新的智能文字识别和商业大数据解决方案而闻名。本文将介绍丁凯博士在大会上的演讲内容,涵盖了文档图像分析、识别、以及大模型在这一领域的应用和挑战。
让我们一起深入了解,探索文档大模型的未来前景,以及合合信息在推动智能产业发展方面的独特贡献。
文档图像分析识别与理解中的技术挑战
- 场景及样式多样性:文档的多样化形状和光照条件增加了图像分析的复杂性,因为每个文档可能都有不同的特点。
- 采集设备不确定性:文档可以从多种设备上采集,包括摄像头、扫描仪、工业机器人和智能机器人。这需要适应不同输入源的算法和处理。
- 用户需求多样性:不同用户对文档图像识别的需求不同。例如,在金融领域,需要高精度的票据识别,而在教育、档案管理和办公领域,需要更注重可理解性和结构化的文档处理。
- 文档图像质量退化:文档图像可能会因多种原因而质量下降,包括噪音、模糊和失真。处理这些问题需要强大的图像预处理技术。
- 文字检测及版面分析:检测文档中的文字和分析版面结构是复杂的任务,涉及到视觉对象检测和解析。
- 非限定条件文字识别:在非受限条件下,例如手写文本或不规则排版的文档,文字识别的准确率较低。这需要更加灵活的模型和算法。
- 结构化智能理解:理解文档中的结构和内容需要高度智能化的处理,包括语义理解和信息抽取。

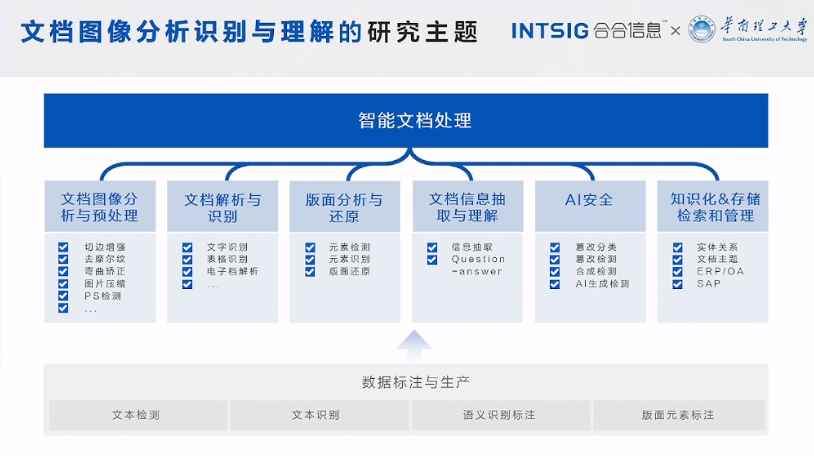
文档图像分析识别与理解的研究主题
为了解决上述技术难题,研究人员在文档图像分析识别与理解领域开展了广泛的研究,主要包括以下主题:
文档图像分析与预处理
- 切边增强
- 去摩尔纹
- 弯曲矫正
- 图片压缩
- PS检测
- …
文档解析与识别
- 文字识别
- 表格识别
- 电子档解析
- …
版面分析与还原
- 元素检测
- 元素识别
- 版面还原
文档信息抽取与理解
- 信息抽取
- Question-answer
AI安全
- 篡改分类
- 篡改检测
- 合成检测
- AI生成检测
知识化&存储检索和管理
- 实体关系
- 文档主题
- ERP/OA
- SAP
多模态大模型在文档图像处理中的应用
- GPT-4:多模态大模型如GPT-4已经取得了显著的进展,可以同时处理文本和图像数据,从而提高了文档图像识别与理解的性能。这使得处理多种类型的信息更加容易,包括文字、图像和其它媒体。
- Google Bard:Google Bard是另一个多模态大模型,同样在文档图像领域表现出色。这种竞争推动了领域内的技术进步,有望带来更多创新。
- 文档图像大模型:文档图像处理领域出现了一系列专有大模型,如LayoutLM系列、LiLT INTSIG、UDOP和Donut。这些模型使用了多模态Transformer编码器,可以应用于不同的文档图像处理任务,包括文本、表格、版面结构和多语言支持。
- 多模态大模型的局限性:尽管多模态大模型在处理文本和图像方面表现出色,但它们仍然存在一些局限性,特别是对于细粒度文本的处理表现较差。这为未来的研究提供了挑战和机会,以进一步提高这些模型的性能。
多模态的GPT-4在文档图像上的表现
多模态大型语言模型如GPT-4在文档图像分析方面取得了显著的进展,它们可以同时处理文本和图像数据,提高了文档图像识别与理解的性能。

多模态的Google Bard在文档图像上的表现
Google Bard是另一个多模态大型语言模型,在文档图像领域表现出色。

文档图像大模型的进展
文档图像专有大模型
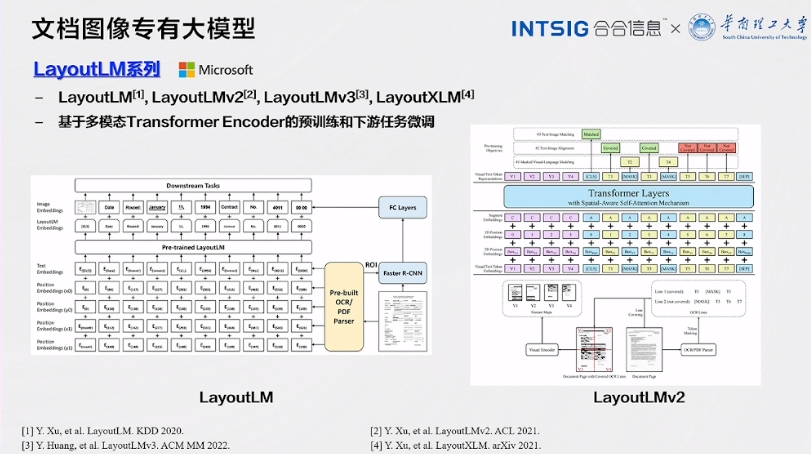
LayoutLM系列
LayoutLM系列是一组在文档图像处理领域取得了巨大成功的模型,它们的设计思路和技术应用值得深入探讨。以下是对LayoutLM系列的更详细介绍:
1.多模态Transformer Encoder的基础:LayoutLM系列的模型都基于多模态Transformer Encoder。这个核心组件结合了Transformer架构和多模态处理的能力,使得模型能够同时处理文本和图像数据。Transformer架构在自然语言处理领域取得了卓越的成功,而将其扩展到文档图像处理,为文本和图像之间的关系建模提供了有力工具。
2.预训练和下游任务微调:LayoutLM系列的模型采用了预训练和下游任务微调的训练策略。在预训练阶段,模型通过大规模文档图像数据进行训练,学习了文本和图像的表示以及它们之间的联系。这种预训练的方式使得模型具备了通用的文档图像理解能力。随后,在下游任务微调阶段,模型通过在特定任务上的训练进一步提高了性能,例如,文本识别、表格检测、版面分析等。
3.多模态任务的应用:LayoutLM系列模型在多模态任务上表现出色。它们不仅仅可以识别文本内容,还能够理解文档中的图像信息。这种多模态处理能力使得模型在处理包含文本、图表、图片等多种媒体元素的文档时更具优势,例如,处理年报、研究报告或金融文档。
4.不同版本的演进:LayoutLM系列包括多个版本,如LayoutLM、LayoutLMv2、LayoutLMv3和LayoutXLM。这些版本在核心架构上有所演进,以适应不同的应用场景和任务要求。例如,LayoutLMv3可能在某些方面具备更高的性能和效率,而LayoutXLM可能在多语言支持方面更具优势。这使得LayoutLM系列模型在各种需求下都能够发挥作用。
LiLT
1.视觉与语言模型的解耦联合建模:LiLT 采用了一种创新性的方法,将视觉和语言模型分开建模,并通过联合建模的方式将它们整合在一起。这种解耦的设计使模型能够更好地处理文档图像中的文本和视觉信息,从而提高了识别和理解的准确性。
2.双向互补注意力模块(BiCAM) :为了更好地融合视觉和语言模型,LiLT 引入了双向互补注意力模块(BiCAM)。这一模块的作用是使模型能够在视觉和语言之间进行双向的信息传递和交互,从而更好地捕捉文档图像中不同元素之间的关联性。
3.多语言小样本/零样本性能卓越:LiLT 在多语言小样本和零样本场景下表现出卓越的性能。这意味着即使在数据有限的情况下,该模型仍能够有效地执行文档图像信息抽取任务,展现了其在应对多语言和数据不足情况下的鲁棒性。
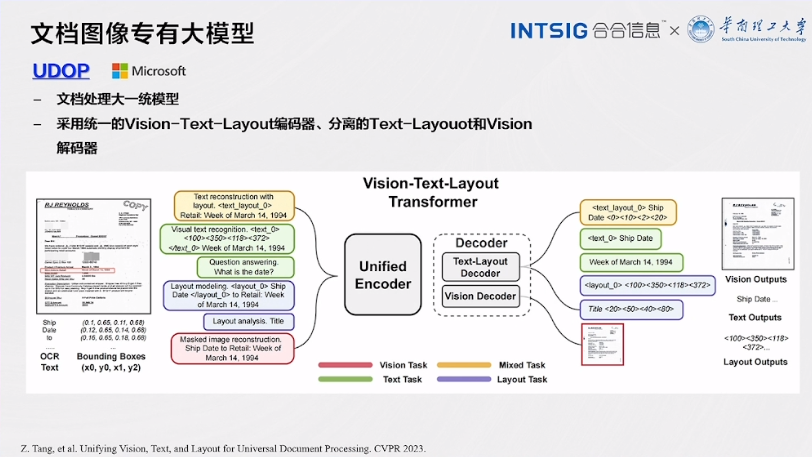
UDOP
UDOP,作为文档图像处理领域的一项重要创新,代表了文档处理大一统模型的新兴趋势。这一模型的设计目的是将文档处理过程变得更加高效、一体化,以应对不同领域和应用中的多样性需求。以下是UDOP的主要特点:
1.文档处理大一统模型:UDOP被称为文档处理的"大一统模型",这意味着它旨在成为一个通用工具,能够应对多种文档图像处理任务,包括文本识别、版面分析、图像处理等。这一统一的模型设计简化了文档处理工作流程,使其更加高效和灵活。
2.统一的Vision-Text-Layout编码器:UDOP采用了一个统一的编码器,将视觉信息、文本内容和版面结构信息融合在一起。这一编码器能够同时处理不同类型的输入,包括文本图像、表格、图片等,从而实现了对多模态信息的综合处理。
3.分离的Text-Layout和Vision解码器:为了更好地理解和处理文档图像,UDOP采用了分离的解码器,分别处理文本、版面和视觉信息。这种分离的架构使得模型能够更好地捕捉不同元素之间的关联性,提高了文档处理的精度和效率。
4.多任务支持:UDOP被设计成支持多种任务,包括文本识别、表格检测、版面还原等。这使得它可以适应不同领域和行业的需求,从金融领域的票据处理到医疗领域的病历管理,都能够发挥出其强大的潜力。
5.应对多语言需求:UDOP还具备处理多语言文档的能力,这对于国际化企业和跨国合作非常重要。它能够自如地处理不同语言的文档,为全球范围内的用户提供了便利。
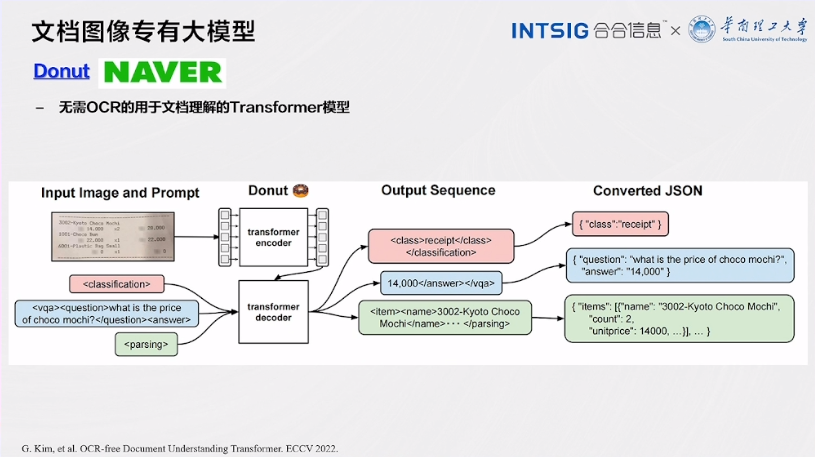
Donut
Donut,作为一种用于文档理解的Transformer模型,标志着文档图像处理领域的一次革命性突破。这一模型的设计和应用方式为文档理解带来了全新的可能性,以下是对Donut的更详细介绍:
1.无需OCR的文档理解:Donut的最显著特点之一是,它不需要传统的OCR(光学字符识别)步骤来处理文档图像。传统OCR方法可能受到图像质量、字体和版式的限制,而Donut则通过Transformer模型直接理解文档的内容和结构,无需将图像中的文字转化为文本。这使得文档理解变得更加高效和准确。
2.Transformer模型的应用:Donut采用了Transformer模型作为其核心架构。Transformer模型已在自然语言处理领域取得了巨大成功,但在文档理解中的应用是一个新领域。这一模型通过自注意力机制和多头注意力机制等先进技术,能够捕捉文档中不同元素之间的关联性,包括文本、图像和版面结构。
3.多模态处理:Donut不仅仅处理文本内容,还能够理解文档中的图像信息。这种多模态处理能力使得它在处理包含多种媒体元素的文档时表现出色,例如,处理包含文本、图表和图片的报告或文档。
4.文档结构理解:Donut不仅仅关注文本内容,还能够理解文档的结构。这包括识别标题、段落、列表、表格等不同类型的文档元素,并理解它们之间的层次关系。这种文档结构理解有助于更深入地挖掘文档的信息。
5.应用领域:Donut的应用领域广泛,可以用于自动化文档处理、信息提取、知识管理等各种任务。它能够从文档中提取关键信息、识别主题、分析趋势,为企业和研究机构提供有力的决策支持。
6.未来潜力:Donut代表了文档图像处理领域的未来趋势,它的无需OCR和多模态处理能力为文档理解带来了新的思路。未来,我们可以期待看到更多基于Donut模型的创新应用,将文档处理推向新的高度。
多模态大模型
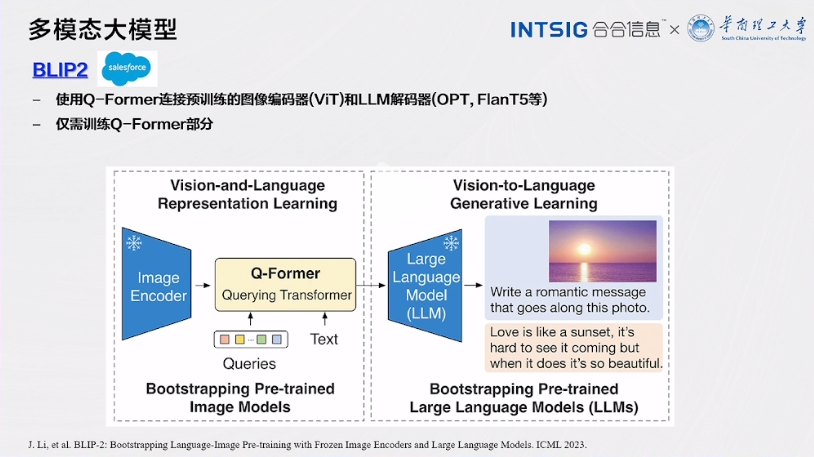
BLIP2
BLIP2(Bidirectional Language-Image Pretraining 2)采用了一种创新的方法,将图像编码和语言解码结合起来,实现了多模态数据的高效预训练和表示学习。以下是对BLIP2的更详细介绍:
1.Q-Former连接预训练:BLIP2采用了Q-Former来连接预训练的图像编码器(如ViT,Vision Transformer)和LLM(Language-Layout-Model)解码器(如OPT和FlanT5等)。这个Q-Former扮演着关键角色,它允许模型同时处理来自图像和文本的信息。这种连接的方式是创新性的,因为它充分利用了Transformer架构的优势,将视觉和语言信息进行有效整合。
2.仅需训练Q-Former部分:一个显著的特点是,BLIP2仅需要对Q-Former部分进行训练。这是因为Q-Former承担了整个模型的核心任务,它负责将来自图像和文本的信息融合在一起,生成丰富的多模态表示。这种策略不仅降低了训练的计算成本,还提高了模型的训练效率。
3. 多模态表示学习:BLIP2的核心目标是学习多模态表示,这意味着模型能够同时理解图像和文本,并在二者之间建立有意义的关联。这对于诸如图像标注、文本到图像生成、文档图像理解等多模态任务非常重要。通过预训练的方式,BLIP2可以在大规模多模态数据上学习通用的表示,为各种任务提供了强大的基础。
Flamingo
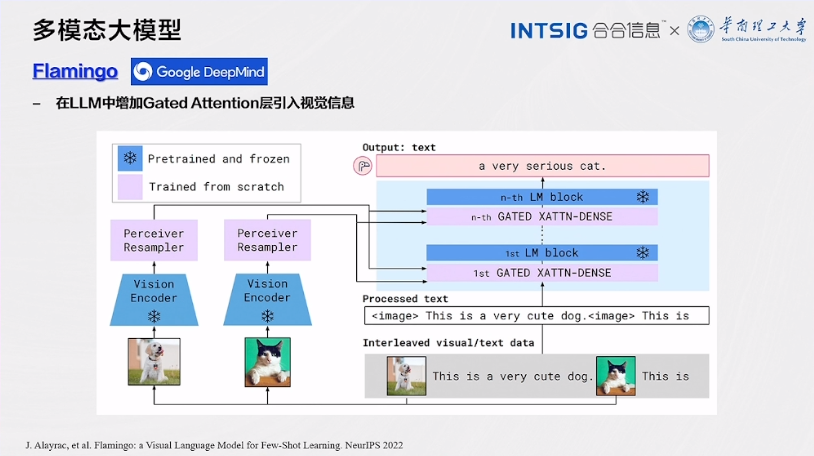
Flamingo是一种备受瞩目的模型,因其在多模态信息处理方面引入了创新性的设计而备受关注。下面是对Flamingo的更详细介绍:
1.引入Gated Attention层:Flamingo的一个显著特点是在LLM(Language-Layout-Model)中引入了Gated Attention层。这一层的作用是引入视觉信息,并将其融合到文本处理过程中。通过Gated Attention,模型可以有选择性地关注文本和图像信息,以便更好地理解多模态数据。
2.多模态数据理解:Flamingo的设计目标之一是使模型能够有效地理解文本和图像之间的关系。通过Gated Attention,模型可以根据任务的需要调整关注的重点。例如,在图像标注任务中,模型可以根据图像内容来调整生成文本描述的注意力,从而生成更准确的标注。
3.增强了任务性能:引入Gated Attention层后,Flamingo在多模态任务上表现出色。它不仅能够更好地处理图像和文本的关联,还可以在各种任务中提高性能,包括图像标注、视觉问答、文档图像理解等。这使得Flamingo成为处理多模态数据的有力工具。
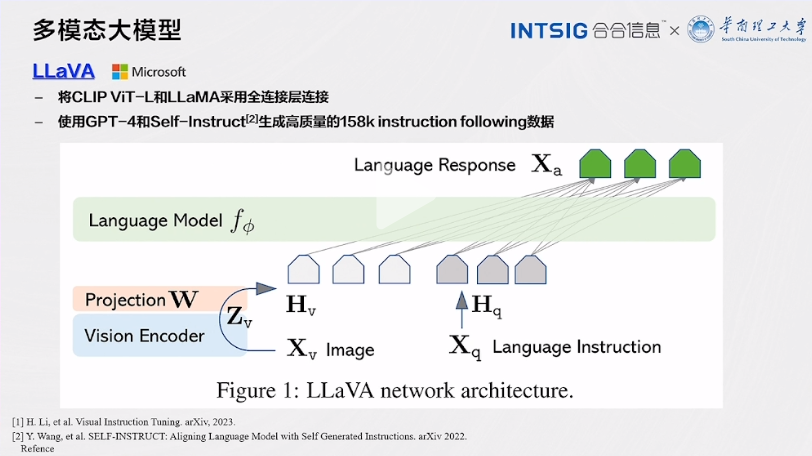
LLaVA
- 将CLIP ViT-L 和 LLaMA 采用全连接层连接
- 使用 GPT-4 和 Self-Instruct 生成高质量的158k instruction following 数据
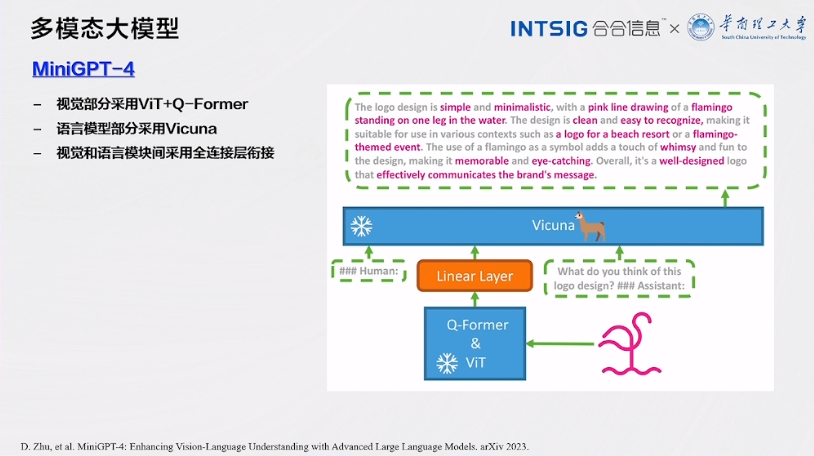
MiniGPT-4
- 视觉部分采用 ViT+Q-Former
- 语言模型部分采用 Vicuna
- 视觉和语言模块间采用全连接层衔接
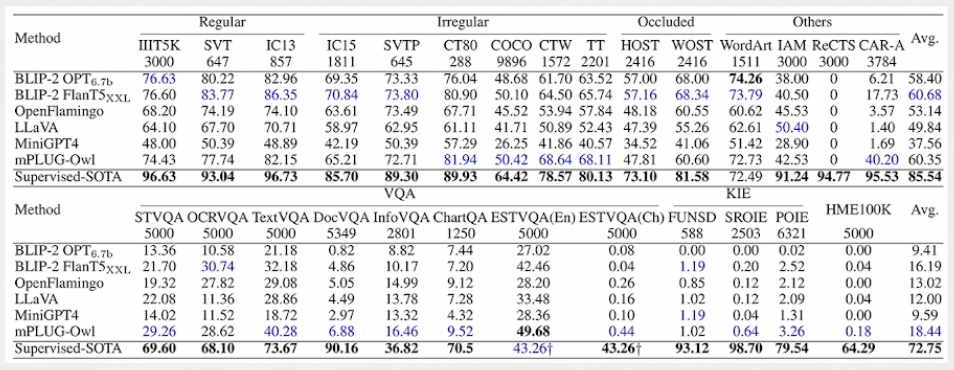
多模态大模型用于OCR领域的局限性
尽管多模态大模型在处理显著文本方面表现出色,但它们仍然存在一些局限性。这些模型受到视觉编码器的分辨率和训练数据的限制,对于细粒度文本的处理表现较差。
文档图像是更偏向于文字还是更偏向于图像?
在文档图像分析中,存在一个关键问题:文档图像是更偏向于文字还是更偏向于图像?这涉及到对文档图像中各种元素的识别和理解。
Pixel2seq大模型系列
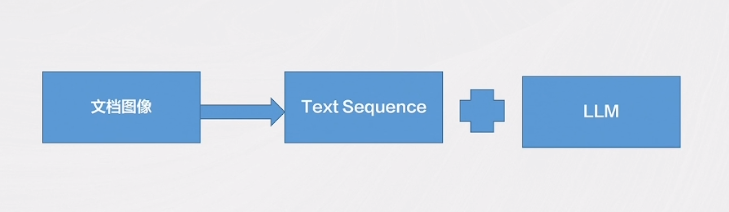
Pix2Seq
将目标检测任务当做一个图像到序列的语言建模任务来解决。
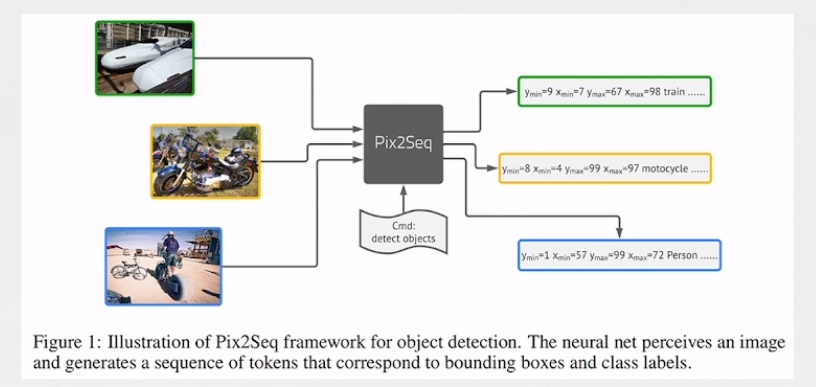
UniTAB
多模态编码器(图像&文本)+自回归解码器完成多种 Vision-Language(VL)任务。
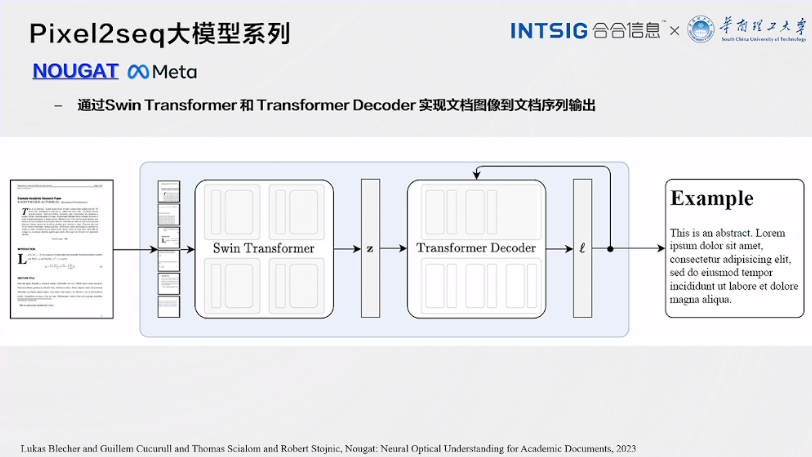
NOUGAT
通过Swin Transformer 和Transformer Decoder 实现文档图像到文档序列输出。
文档图像大模型探索
文档图像大模型设计思路
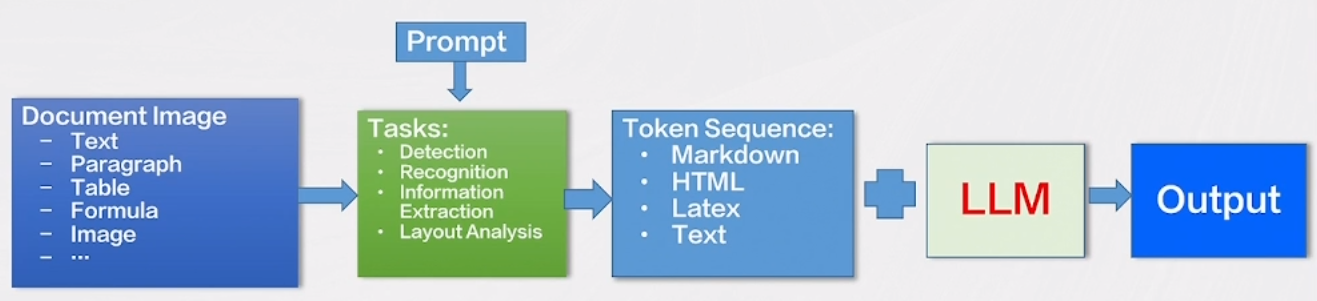
文档图像大模型的设计思路包括了几个关键要点,这些要点在推动文档图像识别和理解方面发挥了重要作用:
- 将文档图像识别和分析的任务定义为序列预测的形式,这包括了对文本、段落、版面分析、表格、公式等元素的预测。
- 通过不同的提示(prompt)引导模型执行不同的OCR(Optical Character Recognition)任务,从而提高了模型的多功能性和适用性。
- 支持篇章级的文档图像识别与分析,能够输出标准格式的Markdown、HTML或纯文本等文档类型,使模型在处理复杂文档时表现出色。
- 将文档理解相关的任务委托给了LLM(Language-Layout-Model),这一策略有助于提高模型在处理结构化文档时的效率和准确性。
SPTS文档图像大模型
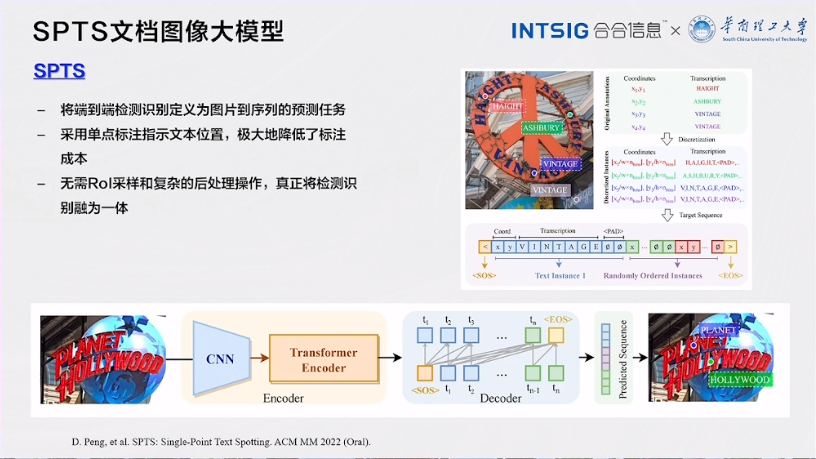
SPTS (Sequence-to-Sequence Prediction for Text Spotting) :SPTS 是一种重要的文档图像处理模型,将端到端的文本检测和识别任务定义为图片到序列的预测任务。这个模型通过单点标注来指示文本的位置,从而降低了标注成本,并且无需复杂的后处理步骤。这一方法为文档图像处理提供了更高效的解决方案,可以应用于场景文本端到端检测识别、表格结构识别和手写数学公式识别等任务。
SPTS
- 将端到端检测识别定义为图片到序列的预测任务
- 采用单点标注指示文本位置,极大地降低了标注成本
- 无需Rol采样和复杂的后处理操作,真正将检测识别融为一体
基于SPTS的OCR大一统模型(SPTS v3)
- 将多种OCR任务定义为序列预测的形式
- 通过不同的prompt引导模型完成不同的OCR任务
- 模型沿用SPTS的CNN+Transformer Encoder+Transformer Decoder的图片到序列的结构

SPTSv3的任务定义
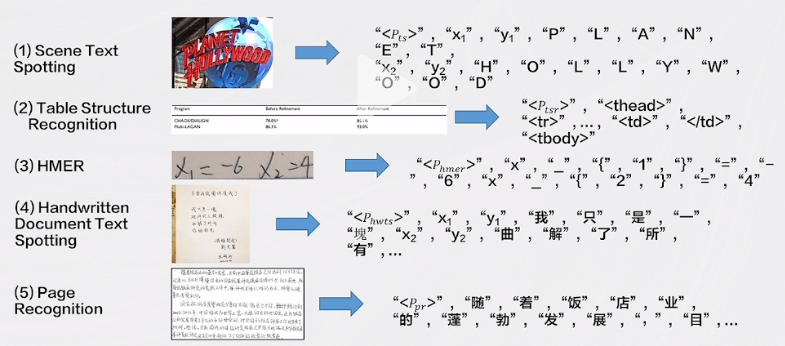
- SPTSv3 将多种OCR任务定义为序列预测的形式,包括端到端检测识别、表格结构识别和手写数学公式识别。这一模型通过不同的提示(prompt)来引导模型完成不同的OCR任务,使其更加灵活和多用途。
实验结果表明,SPTSv3 在各个OCR任务上都取得了出色的性能,显示了其在文档图像处理中的潜力。这为文档图像的多任务处理提供了一种高效的解决方案,有望应用于广泛的应用领域,包括自动化文档处理、文档搜索和内容提取等。
训练平台:A100GPUx10
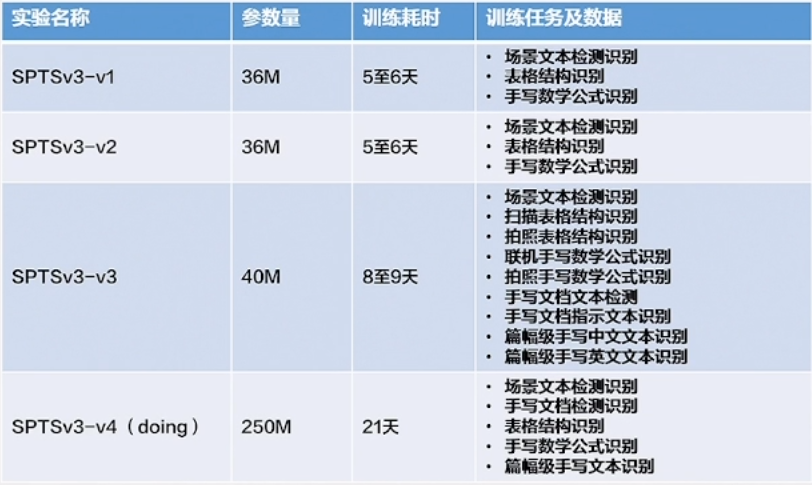
场景文本端到端检测识别
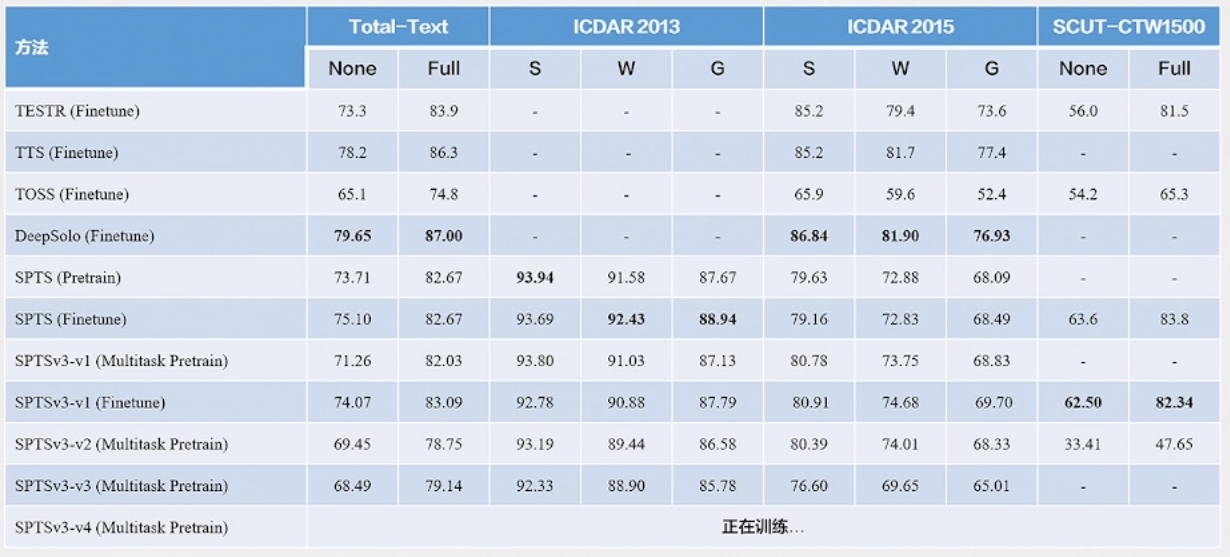
表格结构识别
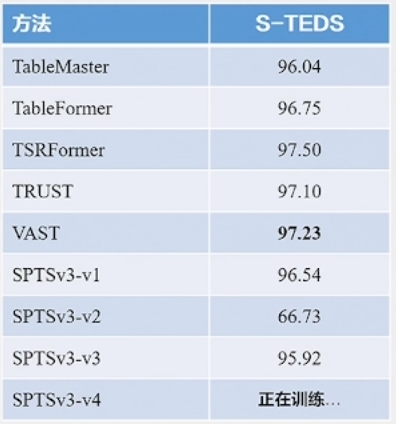
手写数学公式识别
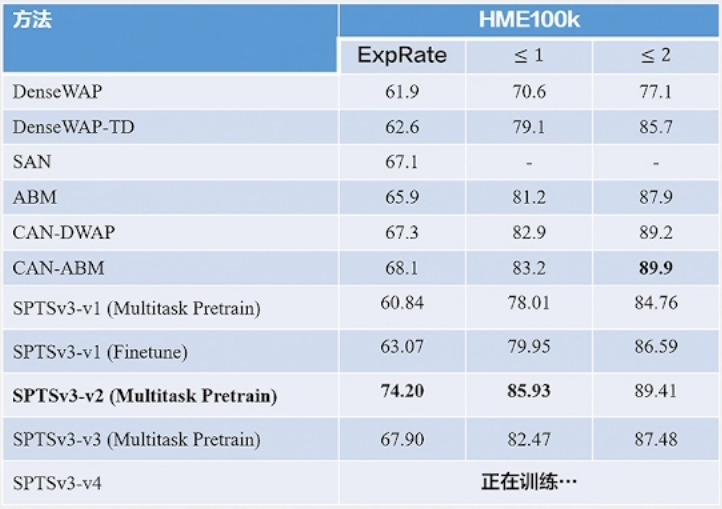
实验结果


总结
在本次2023年第十二届中国智能产业高峰论坛上,丁凯博士的演讲引领我们深入文档大模型的前沿研究。他分享了关于文档大模型的最新研究成果,介绍了合合信息科技公司以及文档图像分析识别与理解领域的挑战。演讲还提到了当前的技术难题和未来的研究方向,旨在实现更灵活的文档图像处理。为文档图像处理的未来带来了更多的可能性。这次精彩的演讲让我们对智能产业的发展充满了信心,期待着更多创新和突破。
相关文章:
2023 第十二届中国智能产业高峰论坛 - 文档大模型的未来展望
目录 前言文档图像分析识别与理解中的技术挑战 文档图像分析识别与理解的研究主题文档图像分析与预处理文档解析与识别版面分析与还原文档信息抽取与理解AI安全知识化&存储检索和管理 多模态大模型在文档图像处理中的应用多模态的GPT-4在文档图像上的表现多模态的Google Ba…...

【小沐学NLP】关联规则分析Apriori算法(Mlxtend库,Python)
文章目录 1、简介2、Mlxtend库2.1 安装2.2 功能2.2.1 User Guide2.2.2 User Guide - data2.2.3 User Guide - frequent_patterns 2.3 入门示例 3、Apriori算法3.1 基本概念3.2 apriori3.2.1 示例 1 -- 生成频繁项集3.2.2 示例 2 -- 选择和筛选结果3.2.3 示例 3 -- 使用稀疏表示…...

对话ChatGPT:AIGC时代下,分布式存储的应用与前景
随着科技的飞速发展,我们正步入一个被称为AIGC时代的全新阶段,人工智能、物联网、大数据、云计算成为这个信息爆炸时代的主要特征。自2022年11月以来,ChatGPT的知名度迅速攀升,引发了全球科技爱好者的极大关注,其高超的…...

java多线程学习笔记一
一、线程的概述 1.1 线程的相关概念 1.1.1 进程(Process) 进程(Process)是计算机的程序关于某数据集合上的一次运行活动,是操作系统进行资源分配与调度的基本单位。 可以把进程简单的理解为操作系统中正在有运行的一…...

BOM与DOM--记录
BOM基础(BOM简介、常见事件、定时器、this指向) BOM和DOM的区别和联系 JavaScript的DOM与BOM的区别与用法详解 DOM和BOM是什么?有什么作用? 图解BOM与DOM的区别与联系 BOM和DOM详解 JavaScript 中的 BOM(浏览器对…...
Docker安装MongoDB
一、docker安装mongodb MongoDB 是一个免费的开源跨平台面向文档的 NoSQL 数据库程序。 二、安装步骤 1.docker 拉取mysql镜像 docker pull mongo:latest 2.运行容器 docker run -itd --name mongo -p 27017:27017 mongo --auth参数说明: -p 27017:27017 &#…...

不要对正则表达式进行频繁重复预编译
背景 在频繁调用场景,如方法体内或者循环语句中,新定义Pattern会导致重复预编译正则表达式,降低程序执行效率。另外,在 JDK 中部分 入参为正则表达式格式的 API,如 String.replaceAll, String.split 等,也…...

vue入门及小项目小便签条
vue 框架:是一个半成品软件,是一套可重用的,通用的,软件基础代码模型。基于框架进行开发,更加快捷 ,更加高效 v-bind为HTML标签绑定属性值,如设置href,css样式等 v-model在表单元素上创建双向数…...

详解TCP/IP协议第四篇:数据在网络中传输方式的分类概述
文章目录 前言 一:面向有连接型与面向无连接型 1:大致概念 2:面向有连接型 3:面向无连接型 二:电路交换与分组交换 1:分组交换概念 2:分组交交换过程 三:根据接收端数量分…...

SpringMvc决战-【SpringMVC之自定义注解】
目录 一、前言 1.1.什么是注解 1.2.注解的用处 1.3.注解的原理 二.注解父类 1.注解包括那些 2.JDK基本注解 3. JDK元注解 4.自定义注解 5.如何使用自定义注解(包括:注解标记【没有任何东西】,元数据注解)? 三…...
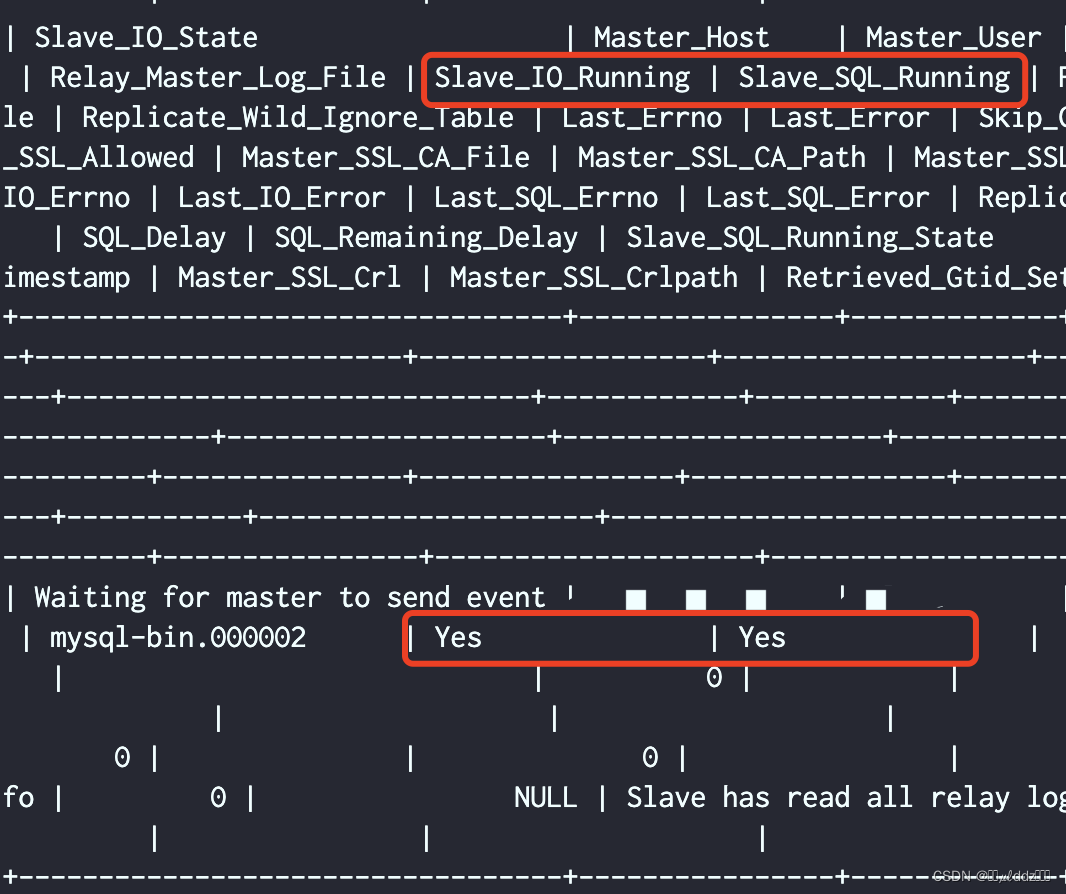
【MySQL集群一】CentOS 7上搭建MySQL集群:一主一从、多主多从
CentOS 7上搭建MySQL集群 介绍一主一从步骤1:准备工作步骤2:安装MySQL步骤3:配置主服务器步骤4:创建复制用户步骤5:备份主服务器数据,如果没有数据则省略这一步步骤6:配置从服务器步骤7…...
RGB格式
Qt视频播放器实现(目录) RGB的使用场景 目前,数字信号源(直播现场的数字相机采集的原始画面)和显示设备(手机屏幕、笔记本屏幕、个人电脑显示器屏幕)使用的基本上都是RGB格式。 三原色 RGB是…...
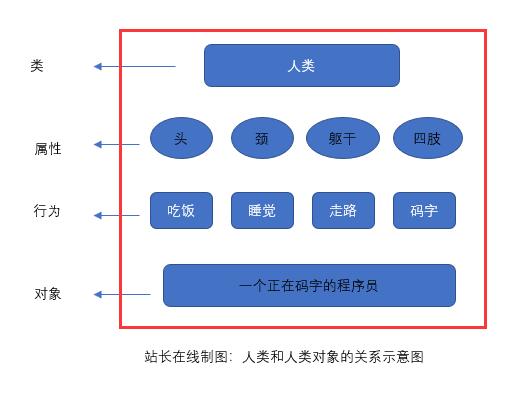
认识面向对象-PHP8知识详解
面向对象编程,也叫面向对象程序设计,是在面向过程程序设计的基础上发展而来的,它比面向过程编程具有更强的灵活性和扩展性。 它用类、对象、关系、属性等一系列东西来提高编程的效率,其主要的特性是可封装性、可继承性和多态性。…...
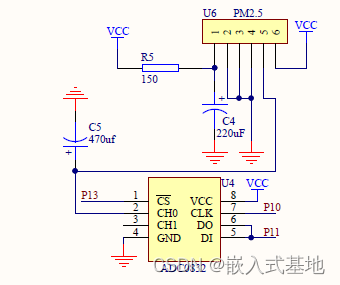
毕业设计|基于51单片机的空气质量检测PM2.5粉尘检测温度设计
基于51单片机的空气质量检测PM2.5粉尘检测温度设计 1、项目简介1.1 系统构成1.2 系统功能 2、部分电路设计2.1 LED信号指示灯电路设计2.2 LCD1602显示电路2.3 PM2.5粉尘检测电路设计 3、部分代码展示3.1 串口初始化3.1 定时器初始化3.2 LCD1602显示函数 4 演示视频及代码资料获…...

星闪空口技术初探
星闪技术设计目标 在星闪技术的应用场景中,最低的时延要求达到了20us量级,比如智能座舱的主动降噪。最高的可靠性要求达到了99.9999%,比如智能制造的传感器与执行器的消息收发。除了低时延和高可靠之外,高精度同步、多并发和信息…...

如何在不失去理智的情况下调试 TensorFlow 训练程序
一、说明 关于tensorflow的调试,是一个难啃的骨头,除了要有耐力,还需要方法;本文假设您是一个很有耐力的开发者,为您提供一些方法;这些方法也许不容易驾驭,但是依然强调您只要有耐力,…...
24. 图论 - 图的表示种类
Hi,你好。我是茶桁。 之前的一节课中,我们了解了图的来由和构成,简单的理解了一下图的一些相关概念。那么这节课,我们要了解一下图的表示,种类。相应的,我们中间需要穿插一些新的知识点用于更好的去理解图…...

C++ 读bin文件,部分代码。赚经验。
编号:1 Head: magicWord[0] 0x0102 magicWord[1] 0x0304 magicWord[2] 0x0506 magicWord[3] 0x0708 version 0x02010004 totalPacketLen 288 platform 0x000a1443 frameNumber 12 timeCpuCycles 172969774 numDetectedObj 99 numTLVs 2 subFrameNumber 0 TLV…...

vue3 父子组件传值
一,子传父 父组件 <script setup> import HelloWorld from ./components/HelloWorld.vue import { ref } from vue//直接赋值页面不会自动渲染,使用ref存储响应式数据 import { defineExpose } from "vue";父传子 let val ref(); con…...
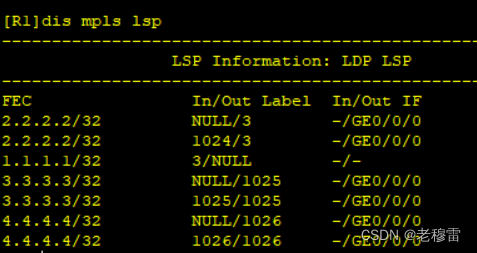
【看懂MPLS LSP表项】
IP网络 R1根据路由表项去查FIB表 目的网络、出口、下一跳 MPLS网络 R1根据LFIB表现去查表, 路由,出口、(标签) 要实现MPLS网络全局可达性,R1应具有到每一个LSR、LSE的路由。 1、R1去FEC(转发等价类) /去往2.2.2.2的路由《路由方…...

ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案
ScanTailor Advanced终极指南:免费开源扫描文档处理完整解决方案 【免费下载链接】scantailor-advanced ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes. …...

drprov.dll文件丢失找不到 免费下载修复方法分享
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

别再让C盘爆红了!Windows 11上Ollama安装与模型存储路径修改保姆级教程
Windows 11上Ollama安装避坑指南:彻底解决C盘空间焦虑 每次看到C盘飘红,就像看到手机电量只剩5%一样让人焦虑。特别是当你兴冲冲地安装Ollama准备体验本地大模型时,却发现默认安装路径无情地吞噬着宝贵的C盘空间。本文将带你从零开始…...

捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战?
捉妖雷达Web版:如何解决游戏数据实时同步的技术挑战? 【免费下载链接】zhuoyao_radar 捉妖雷达 web版 项目地址: https://gitcode.com/gh_mirrors/zh/zhuoyao_radar 捉妖雷达Web版是一个开源的游戏辅助工具项目,旨在为捉妖游戏玩家提供…...

DeOldify图像上色服务完整流程:基于Flask的Web服务部署与使用
DeOldify图像上色服务完整流程:基于Flask的Web服务部署与使用 1. 项目概述与核心功能 DeOldify图像上色服务是一个基于深度学习技术的Web应用,能够将黑白或褪色的老照片自动转换为彩色图像。这个项目通过简单的Web界面,让用户无需任何技术背…...

5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南
5个步骤掌握UE4SS:虚幻引擎游戏定制与脚本开发完全指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

SpringBoot+Mybatis多数据源实战:TDengine与MySQL混搭的物联网数据存储方案
SpringBootMybatis多数据源实战:TDengine与MySQL混搭的物联网数据存储方案 在物联网系统开发中,数据存储架构的设计往往面临一个核心矛盾:海量设备时序数据的高效存储与业务数据的复杂关系处理如何平衡?传统单一数据库方案要么在时…...
)
手把手教你用NEWLab搭建智能温控系统(附完整代码)
手把手教你用NEWLab搭建智能温控系统(附完整代码) 在智能家居和工业自动化领域,温度控制始终是核心需求之一。无论是保持室内舒适环境,还是确保精密设备的稳定运行,一套可靠的温控系统都不可或缺。对于物联网初学者和…...
的时序特征提取进阶)
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶
Granite TimeSeries FlowState R1实战:基于卷积神经网络(CNN)的时序特征提取进阶 你是不是也遇到过这样的问题?面对一长串传感器读数、股票价格波动或者服务器监控数据,感觉信息量巨大,却不知道从哪里入手…...

旧笔记本别扔!用飞牛OS+阿里云DDNS,5分钟搞定个人云盘外网访问
旧笔记本改造指南:用飞牛OS与阿里云DDNS打造高性价比个人云存储 你是否曾为家中堆积的旧电子设备感到困扰?那些性能落后但依然能正常运行的旧笔记本,其实蕴藏着巨大的实用价值。本文将带你探索如何将这些被时代淘汰的硬件变废为宝,…...