只需4步使用Redis缓存优化Node.js应用
介绍
通过API获取数据时,会向服务器发出网络请求,收到响应数据。但是,此过程可能非常耗时,并且可能会导致程序响应时间变慢。
我们使用缓存来解决这个问题,客户端程序首先向API发送请求,将返回的数据存储在缓存中,之后的请求都从缓存中查找数据,而不是向API发送请求。
在本文中,使用 Redis做为缓存, 在 Node.js 的程序中通过4步实现数据缓存的机制。
第 1 步 — 设置项目
在此步骤中,我们将安装该项目所需的依赖项并启动 Express 服务器。
首先,为项目创建目录mkdir:
mkdir app
进入目录:
cd app
初始化项目:
npm init -y
它将创建package.json包含以下内容的文件:
{"name": "app","version": "1.0.0","description": "","main": "index.js","scripts": {"test": ""},"keywords": [],"author": "","license":"ISC"
}
接下来,使用以下命令安装express,redis,axios库:
npm install express redis axios
完成后,app目录结构如下:
app
--node_modules
--package-lock.json
--package.json
创建index.js文件,并输入以下代码:
const express = require("express");
const app = express();
const port = process.env.PORT || 3000; app.listen(port, () => { console.log(`App listening on port ${port}`);
});
保存并运行以下命令:
node index.js
输出如下:
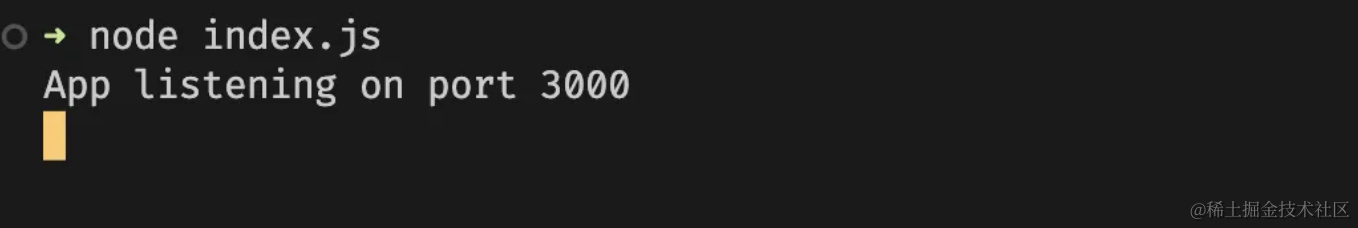
步骤 2 — 通过API获取数据
在刚才的index.js中增加从API获取数据的部分:
const express = require("express");
const app = express();
const port = process.env.PORT || 3000; async function fetchDataFromApi(userId) {let apiUrl = 'https://xxxx/api';if (characterId) {apiUrl = `${apiUrl}/user/${userId}`;} else {apiUrl = `${apiUrl}/user`;}const apiResponse = await axios.get(apiUrl);console.log("发送API请求");return apiResponse.data;
}app.get("/user/:id", async (req, res) => {try {const character = await fetchDataFromApi(req.params.id);if (!character.length) {throw new Error("请求异常");}return res.status(200).send({fromCache: false,data: character,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.get("/user", async (req, res) => {try {const characters = await fetchDataFromApi();if (!characters.length) {throw new Error("请求异常");}return res.status(200).send({fromCache: false,data: characters,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.listen(port, () => { console.log(`App listening on port ${port}`);
});
运行 node index.js启动服务器,之后打开 Postman 发送请求/user, 请求耗时 885 毫秒。为了加快请求速度,我们增加 Redis 缓存。
第 3 步 — 增加 Redis 缓存
增加缓存,只有初始访问才会从API请求数据,所有后续请求都从缓存中获取数据。
在项目中导入redis模块:
const redis = require ( "redis" );
添加以下代码连接到Redis:
let redisClient;(async () => {redisClient = redis.createClient();redisClient.on("error", (error) => console.error(`Error : ${error}`));await redisClient.connect();
})();
使用redisClient.get()从缓存中获取数据。如果数据存在,我们将isCached设置为 true 并分配cachedResult给result,如果cachedResult为空,则我们调用API获取数据,然后使用redisClient.set()设置到缓存中。
const redisKey = "user";
let results;
let isCached = false; const cachedResult = await redisClient.get(redisKey);
if (cachedResult) { isCached = true; results = JSON.parse(cachedResult);
} else { results = await fetchDataFromApi(); if (!results.length) { throw new Error("请求异常"); } await redisClient.set(redisKey, JSON.stringify(results));
}
完整的文件如下:
const express = require("express");
const app = express();
const port = process.env.PORT || 3000; let redisClient;(async () => {redisClient = redis.createClient();redisClient.on("error", (error) => console.error(`Error : ${error}`));await redisClient.connect();
})();async function fetchDataFromApi(userId) {let apiUrl = 'https://xxxx/api';if (characterId) {apiUrl = `${apiUrl}/user/${userId}`;} else {apiUrl = `${apiUrl}/user`;}const apiResponse = await axios.get(apiUrl);console.log("发送API请求");return apiResponse.data;
}app.get("/user/:id", async (req, res) => {try {const redisKey = `user-${req.params.id}`; let results;let isCached = false;const cachedResult = await redisClient.get(redisKey);if (cachedResult) {isCached = true;results = JSON.parse(cachedResult);} else {results = await fetchDataFromApi(req.params.id);if (!results.length) {throw new Error("请求异常");}await redisClient.set(redisKey, JSON.stringify(results));}return res.status(200).send({fromCache: isCached,data: results,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.get("/user", async (req, res) => {try {const redisKey = "user";let results;let isCached = false;const cachedResult = await redisClient.get(redisKey);if (cachedResult) {isCached = true;results = JSON.parse(cachedResult);} else {results = await fetchDataFromApi();if (!results.length) {throw new Error(请求异常");}await redisClient.set(redisKey, JSON.stringify(results));}return res.status(200).send({fromCache: isCached,data: results,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.listen(port, () => { console.log(`App listening on port ${port}`);
});
保存并运行以下命令:
node index.js
服务启动后,我们通过Postman发送请求,发现第一次请求比较慢,后边的请求速度都变快了,从868毫秒缩短到14毫秒。
到目前为止,我们可以从 API 获取数据,并把数据设置到到缓存中,后续请求从缓存中取数据。
为了防止API端数据变化,但是缓存数据没变的情况,还需要设置缓存有效性。
第 4 步 — 设置缓存有效性
当缓存数据时,要设置合适的过期时间,具体时间可以根据业务情况决定。
在本文中,将缓存持续时间设置为120秒。
在index.js中增加以下内容:
await redisClient.set(redisKey, JSON.stringify(results), { EX: 120, NX: true,
});
EX:缓存有效时间(单位:秒)。NX:当设置为时true,set()方法只设置 Redis 中不存在的键。
把以上代码添加到API接口中:
app.get("/user/:id", async (req, res) => {try {const redisKey = `user-${req.params.id}`; results = await fetchDataFromApi(req.params.id);if (!results.length) {throw new Error("请求异常");}await redisClient.set(redisKey, JSON.stringify(results), { EX: 120, NX: true, });return res.status(200).send({fromCache: isCached,data: results,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.get("/user", async (req, res) => {try {const redisKey = "user";results = await fetchDataFromApi(); if (!results.length) {throw new Error("请求异常");}await redisClient.set(redisKey, JSON.stringify(results), { EX: 120, NX: true, });return res.status(200).send({fromCache: isCached,data: results,});} catch (error) {console.log(error);res.status(404).send("请求异常");}
});app.listen(port, () => { console.log(`App listening on port ${port}`);
});
现在创建一个中间件,从缓存中获取数据:
async function cacheData(req, res, next) {try {const characterId = req.params.id;let redisKey = "user";if (characterId) {redisKey = `user-${req.params.id}`;}const cacheResults = await redisClient.get(redisKey);if (cacheResults) {res.send({fromCache: true,data: JSON.parse(cacheResults),});} else {next();}} catch (error) {console.error(error);res.status(404);}
}
把cacheData加入到API调用中
app.get("/user/:id", cacheData, async (req, res) => { try { const redisKey = `user-${req.params.id}`; results = await fetchDataFromApi(req.params.id); if (!results.length) { throw new Error("请求异常"); } await redisClient.set(redisKey, JSON.stringify(results), { EX: 120, NX: true, }); return res.status(200).send({ fromCache: false, data: results, }); } catch (error) { console.log(error); res.status(404).send("请求异常"); }
}); app.get("/user", cacheData, async (req, res) => { try { const redisKey = "user"; results = await fetchDataFromApi(); if (!results.length) { throw new Error("请求异常"); } await redisClient.set(redisKey, JSON.stringify(results), { EX: 120, NX: true, }); return res.status(200).send({ fromCache: false, data: results, }); } catch (error) { console.log(error); res.status(404).send("请求异常"); }
});
当访问API时/user,cacheData()首先执行。如果数据被缓存,它将返回响应。如果在缓存中没有找到数据,则会从API请求数据,将其存储在缓存中,并返回响应。
再次利用Postman来验证接口,发现响应时间只有15毫秒左右。
总结
在本文中,我们构建了一个 Node.js 程序,该程序 API 获取数据并使用Redis进行缓存,只有初次请求和缓存过期后才从API获取数据,之后的请求都从缓存中获取数据,大大缩短请求所用的时间。
相关文章:
只需4步使用Redis缓存优化Node.js应用
介绍 通过API获取数据时,会向服务器发出网络请求,收到响应数据。但是,此过程可能非常耗时,并且可能会导致程序响应时间变慢。 我们使用缓存来解决这个问题,客户端程序首先向API发送请求,将返回的数据存储…...

【react基础01】项目文件结构描述
react 项目文件结构描述 📂 REACTWORKSPACE📂 node_modules📂 public📄 favicon.ico📄 index.html📄 logo192.png📄 logo512.png📄 manifest.json📄 robots.txt …...
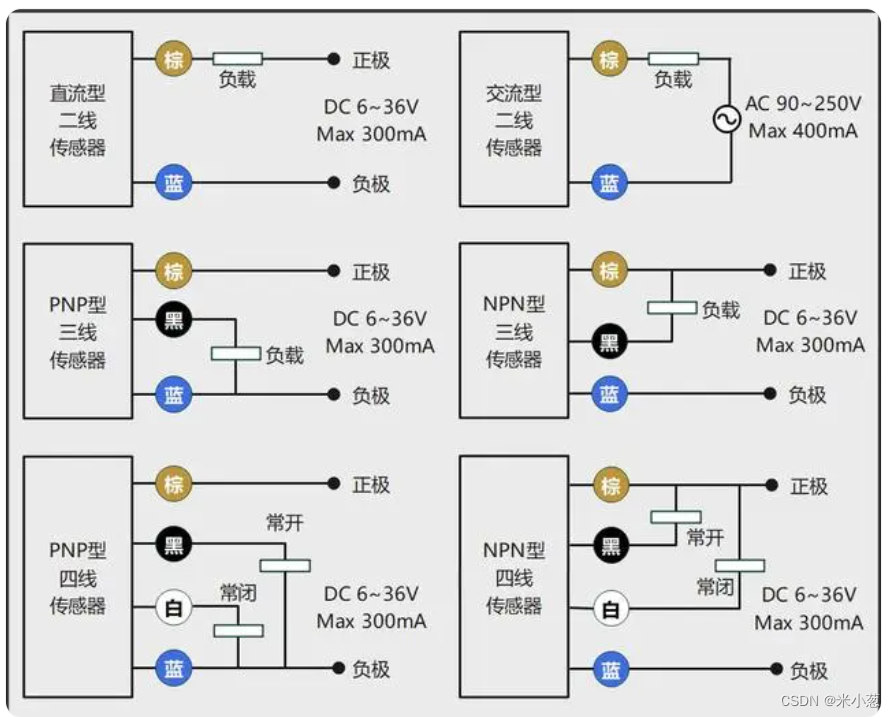
光电开关-NPN-PNP
基础概念 有信号 “检测到物体/有物体遮挡” 工作原理 NPN:表示共正电压,输出负电压【只能输出低电压或者悬空 常开常闭是指 输出有没有跟“地”接通】; NPN NO:表示常态下是常开的,检测到物体时黑色线输出一个负电压…...
学会使用Git 和 GitHub
Git 和 GitHub 都是程序员每天都要用到的东西 —— 前者是目前最先进的 版本控制工具,拥有最多的用户,且管理着地球上最庞大的代码仓库;而后者是全球最大 同性交友 代码托管平台、开源社区。 在没有这两个工具时,编程可能是这样的…...

SoftwareTest3 - 要了人命的Bug
软件测试基础篇 一 . 如何合理的创建一个 Bug二 . Bug 等级2.1 崩溃2.2 严重2.3 一般2.4 次要 三 . Bug 的生命周期四 . 跟开发产生争执应该怎么解决 Hello , 大家好 , 又给大家带来新的专栏喽 ~ 这个专栏是专门为零基础小白从 0 到 1 了解软件测试基础理论设计的 , 虽然还不足…...

Linux系统中MySQL库的操作,实操sql代码
Linux系统中MySQL库的操作 本文主要是对linux系统下MySQL库操作的总结,包含创建、删除、修改数据库,数据库的编码格式和校验格式以及数据库的恢复和备份。 1.创建数据库 1.1基本语法: CREATE DATABASE [IF NOT EXISTS] db_name [create_s…...

Python基础分享之面向对象的进一步拓展
我们熟悉了对象和类的基本概念。我们将进一步拓展,以便能实际运用对象和类。 调用类的其它信息 上一讲中提到,在定义方法时,必须有self这一参数。这个参数表示某个对象。对象拥有类的所有性质,那么我们可以通过self,调…...
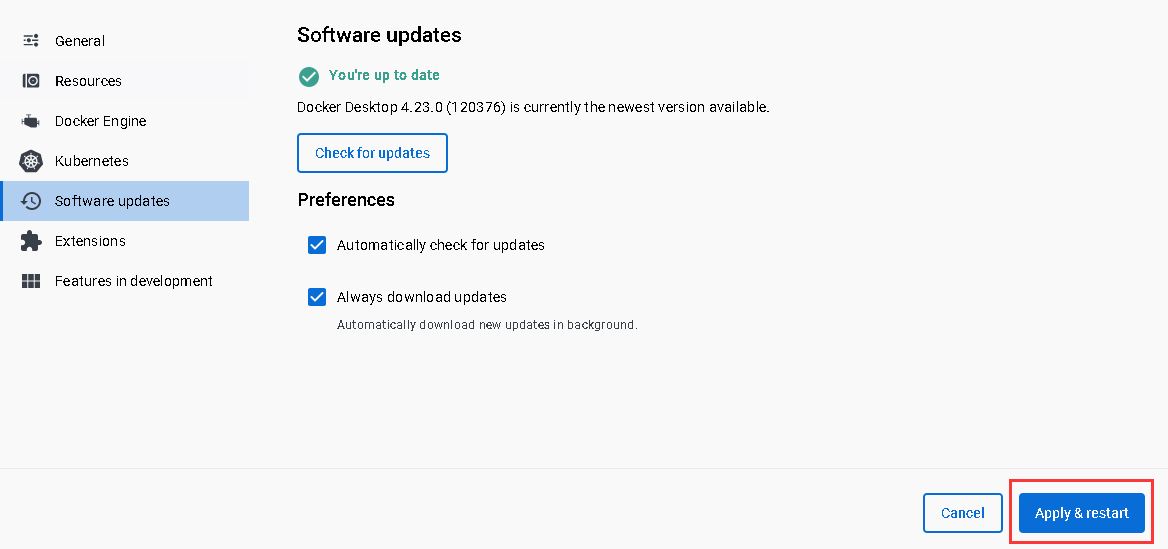
Windows安装Docker Desktop并配置镜像、修改内存占用大小
启用Hyper-V Win S 搜索控制面板 安装WSL2 第一种方法(推荐) 以管理员运行命令提示符,然后重启Docker Desktop wsl --updatewsl --set-default-version 2第2种方法去微软官网下载WSL2并安装 《微软官网下载WSL2》 配置WSL2最大内…...

Zipping
Zipping 信息收集端口扫描目录扫描webbanner信息收集 漏洞利用空字节绕过---->失败sqlI-preg_match bypass反弹shell 稳定维持 提权-共享库漏洞 参考:https://rouvin.gitbook.io/ibreakstuff/writeups/htb-season-2/zipping#sudo-privileges-greater-than-stock-…...
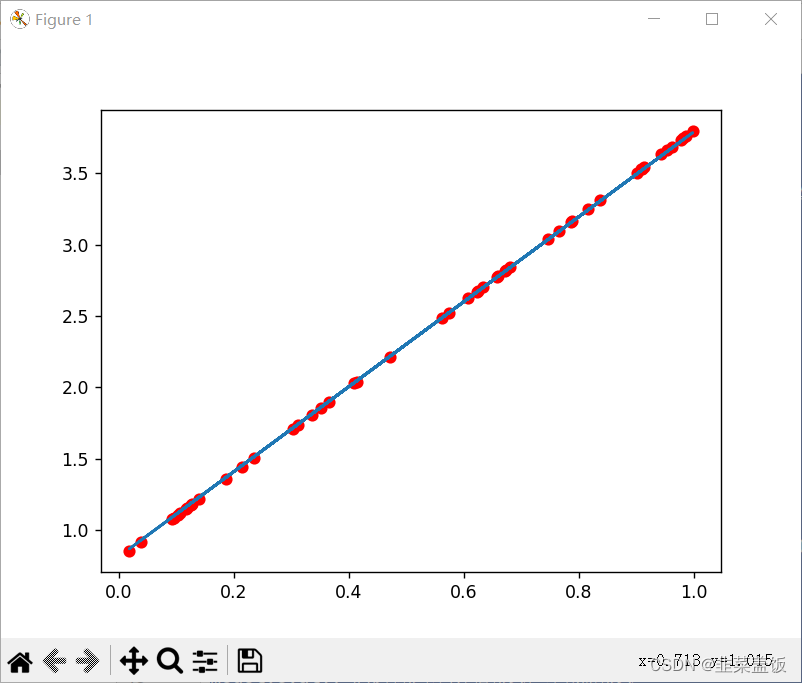
pytorch学习---实现线性回归初体验
假设我们的基础模型就是y wx b,其中w和b均为参数,我们使用y 3x0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8。 步骤如下: 准备数据计算预测值计算损失,把参数的梯度置为0,进行反向传播…...

别再乱写git commit了
B站|公众号:啥都会一点的研究生 写在前面 在很长的一段时间中,使用git commit都是随心所欲,log肥肠简洁,随着代码的迭代,当时有多偷懒,返过头查看git日志就有多懊悔,就和写代码不写doc string…...

八大排序(一)冒泡排序,选择排序,插入排序,希尔排序
一、冒泡排序 冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。 以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮…...

泊松分布简要介绍
泊松分布是一种常见的离散概率分布,它用于描述某个时间段或区域内随机事件发生的次数。它得名于法国数学家西蒙丹尼泊松。 泊松分布的概率质量函数表示某个时间段或区域内事件发生次数的概率。如果随机变量 X 服从泊松分布,记作 X ~ Poisson(λ)&#x…...

C语言每日一题(10):无人生还
文章主题:无人生还🔥所属专栏:C语言每日一题📗作者简介:每天不定时更新C语言的小白一枚,记录分享自己每天的所思所想😄🎶个人主页:[₽]的个人主页🏄…...

VSCode开发go手记
断点调试: 安装delve(windows): go get -u github.com/go-delve/delve/cmd/dlv 设置 launch.json 配置文件: ctrlshiftp 输入 Debug: Open launch.json 打开 launch.json 文件,如果第一次打开,会新建一…...

怎么选择AI伪原创工具-AI伪原创工具有哪些
在数字时代,创作和发布内容已经成为了一种不可或缺的活动。不论您是个人博主、企业家还是网站管理员,都会面临一个共同的挑战:如何在互联网上脱颖而出,吸引更多的读者和访客。而正是在这个背景下,AI伪原创工具逐渐崭露…...

【块状链表C++】文本编辑器(指针中 引用 的使用)
》》》算法竞赛 /*** file * author jUicE_g2R(qq:3406291309)————彬(bin-必应)* 一个某双流一大学通信与信息专业大二在读 * * brief 一直在竞赛算法学习的路上* * copyright 2023.9* COPYRIGHT 原创技术笔记:转载…...
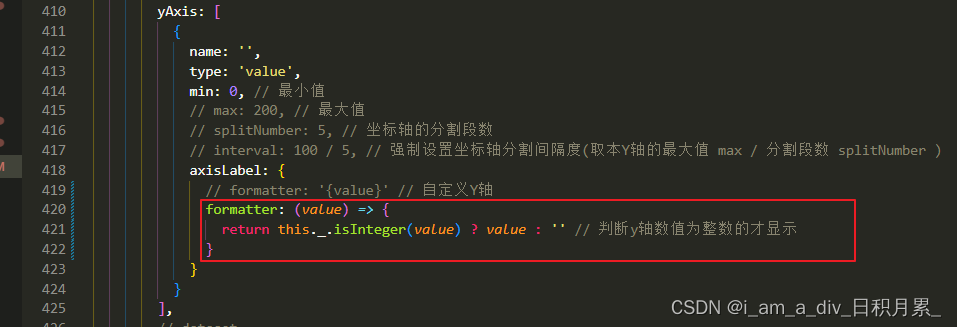
echarts的Y轴设置为整数
场景:使用echarts,设置Y轴为整数。通过判断Y轴的数值为整数才显示即可 yAxis: [{name: ,type: value,min: 0, // 最小值// max: 200, // 最大值// splitNumber: 5, // 坐标轴的分割段数// interval: 100 / 5, // 强制设置坐标轴分割间隔度(取本Y轴的最大…...
恢复删除文件?不得不掌握的4个方法!
“删除了的文件还可以恢复吗?有个文件我本来以为不重要了,就把它删除了,没想到现在还需要用到!这可怎么办?有没有办法找回来呢?” 重要的文件一旦丢失或误删可能都会对我们的工作和学习造成比较大的影响。怎…...

GitLab CI/CD:.gitlab-ci.yml 文件常用参数小结
文章目录 一、.gitlab-ci.yml 文件作用二、一个简单的.gitlab-ci.yml 文件示例参考 一、.gitlab-ci.yml 文件作用 可以定义跑CI时想要运行的命令或脚本 可以定义job之间的依赖和缓存 可以执行程序部署并定义部署位置 可以定义想要包含的其他配置文件和模版 二、一个简单的.gi…...

全能图像工具ImageGlass:免费开源的图像浏览颠覆体验
全能图像工具ImageGlass:免费开源的图像浏览颠覆体验 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass ImageGlass是一款专为Windows用户设计的轻量级开源图像浏览…...

3种方法如何解决Balena Etcher在Arch Linux上的安装难题
3种方法如何解决Balena Etcher在Arch Linux上的安装难题 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 问题诊断:为什么Arch Linux安装Etcher总是失…...

光伏逆变器测试避坑:派能协议下电流值5倍偏差的修复实录
光伏逆变器测试实战:派能协议电流值异常分析与精准修复指南 光伏系统集成测试中,协议解析环节往往成为数据异常的"重灾区"。去年某分布式光伏项目中,我们遭遇了逆变器显示电流值异常放大5倍的典型案例——BMS实际发送95A电流数据&a…...

【电商PHP高并发订单处理黄金法则】:20年架构师亲授5大防超卖、零重复、秒级响应的实战方案
第一章:电商PHP高并发订单处理的底层挑战与认知重构在亿级日活的电商场景中,PHP 传统同步阻塞式订单流程在秒杀、大促等峰值时刻频繁遭遇超卖、库存错乱、数据库连接耗尽与事务死锁等问题。这些表象背后,是开发者对 PHP 运行模型、MySQL 事务…...

大模型实战:利用tiktoken精准控制GPT模型输入成本与长度
1. 为什么需要精准控制GPT模型的输入成本与长度 第一次调用GPT-4 API时,我盯着账单愣了半天——短短几百字的对话居然消耗了这么多token。后来才发现,同样的内容用不同编码方式计算,token数量能差出30%。这就像去超市买东西不看价签ÿ…...

音乐自由终极解决方案:Unlock Music本地解密完全指南
音乐自由终极解决方案:Unlock Music本地解密完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:…...

Sketch MeaXure终极指南:如何快速生成专业设计规范
Sketch MeaXure终极指南:如何快速生成专业设计规范 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 你是否经历过这样的场景?精心设计完界面后,开发团队却反复询问"这个间距是多少…...

从14k+star的goview到完整解决方案:手把手教你集成dcluster实现数据可视化全流程
从14kstar的goview到完整解决方案:手把手教你集成dcluster实现数据可视化全流程 在数据驱动的时代,企业对于可视化分析的需求日益增长。开源项目goview凭借其14k的star数,已成为前端数据可视化领域的明星产品。但真正要在企业环境中落地&…...

三步解锁Cursor Pro功能:免费体验AI编程助手完整能力
三步解锁Cursor Pro功能:免费体验AI编程助手完整能力 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

OBS-Multi-RTMP终极指南:5分钟实现多平台同步直播的完整解决方案
OBS-Multi-RTMP终极指南:5分钟实现多平台同步直播的完整解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp OBS-Multi-RTMP是一款专为直播创作者设计的开源插件&#x…...