Canal实现Mysql数据同步至Redis、Elasticsearch
文章目录
- 1.Canal简介
- 1.1 MySQL主备复制原理
- 1.2 canal工作原理
- 2.开启MySQL Binlog
- 3.安装Canal
- 3.1 下载Canal
- 3.2 修改配置文件
- 3.3 启动和关闭
- 4.SpringCloud集成Canal
- 4.1 Canal数据结构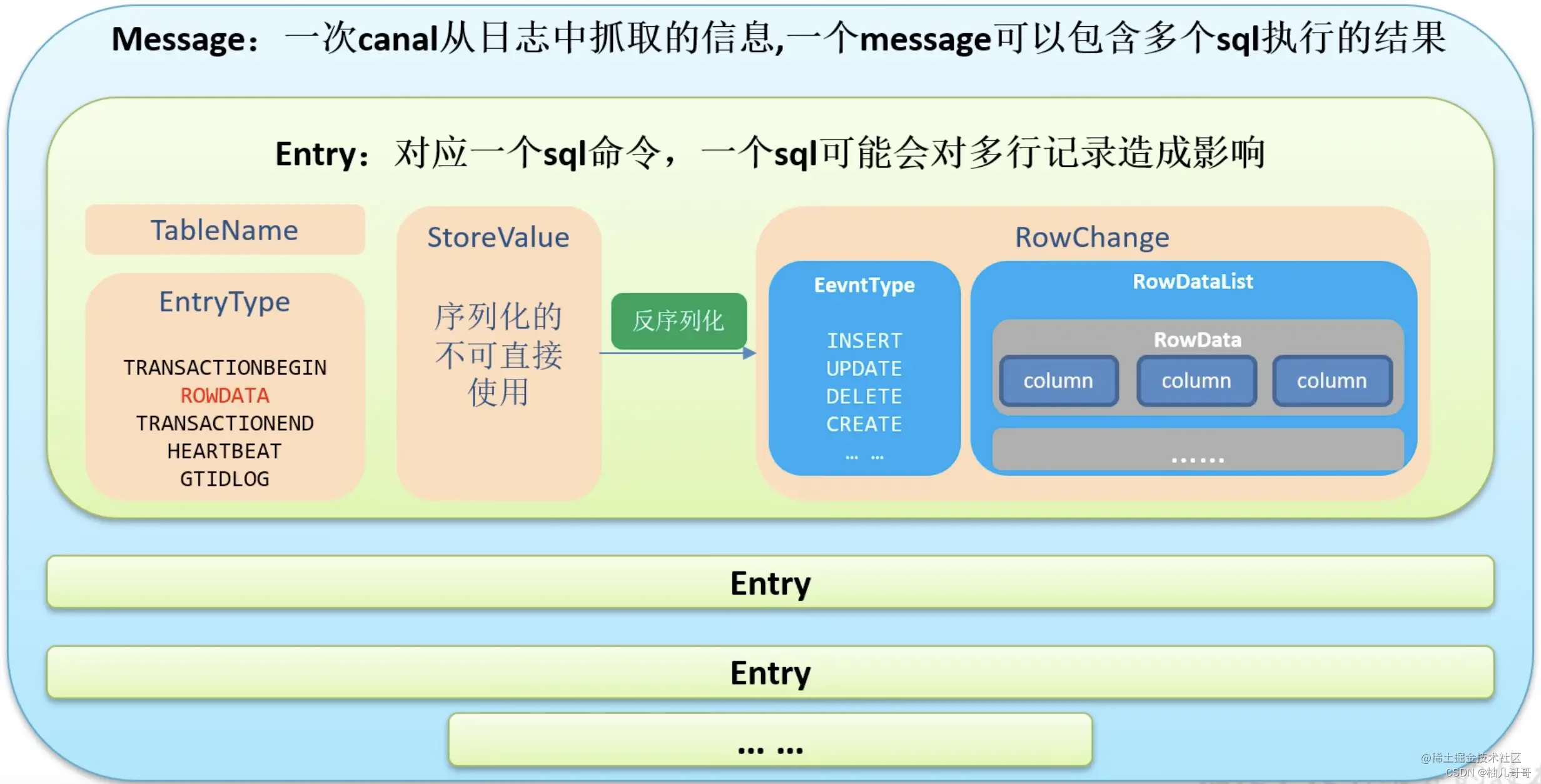
- 4.2 引入依赖
- 4.3 配置多个数据同步的目的地
- 4.4 application.yml
- 4.5 监听配置
- 4.5 监听配置
- 4.5.1 监听测试类
- 4.5.2 redis数据同步
- 4.5.3 Elasticsearch数据同步
- 4.5.4 Es Api 封装业务类 EsApiService
- 4.6 canal日志
- 4.7 第二种方案(解决数据库存在下划线,用上述方法,某些字段会为空)
- 4.7.1 引入依赖
- 4.7.2 创建监听
- 4.7.3 实体类
- 4.8 第三种方案(解决数据库存在下划线,某些字段会为空)
- 4.9 canal整合异常问题排查思路
- 4..1 无法正常启动
- 4.9.2 使用canal监听数据 启动成功了 没有报错 不过一直监听不到消息
1.Canal简介
官网
https://github.com/alibaba/canal
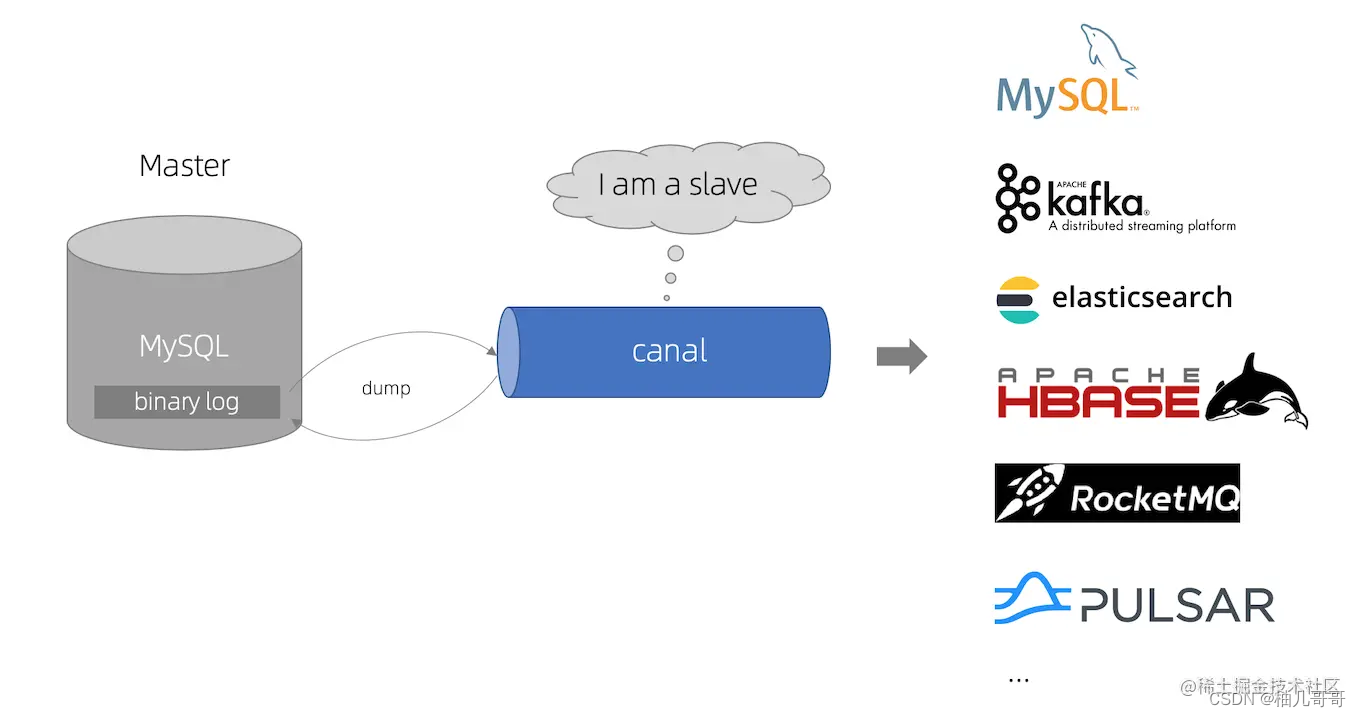

canal [kə’næl] ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
1.1 MySQL主备复制原理
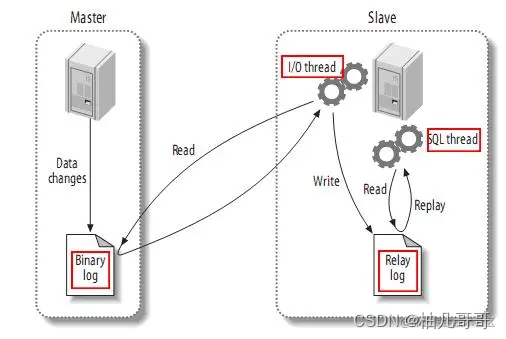
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
1.2 canal工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
2.开启MySQL Binlog
对于自建 MySQL , 需要先开启 Binlog 写入功能,
配置 binlog-format 为 ROW 模式,这里以mysql8.0.27为例,my.cnf 中配置如下
#开启bInlog
log-bin=mysql-bin
#以数据的方式写binlog日志 :statement 是记录SQL,row是记录数据
binlog-format=ROW
binlog-ignore-db=mysql
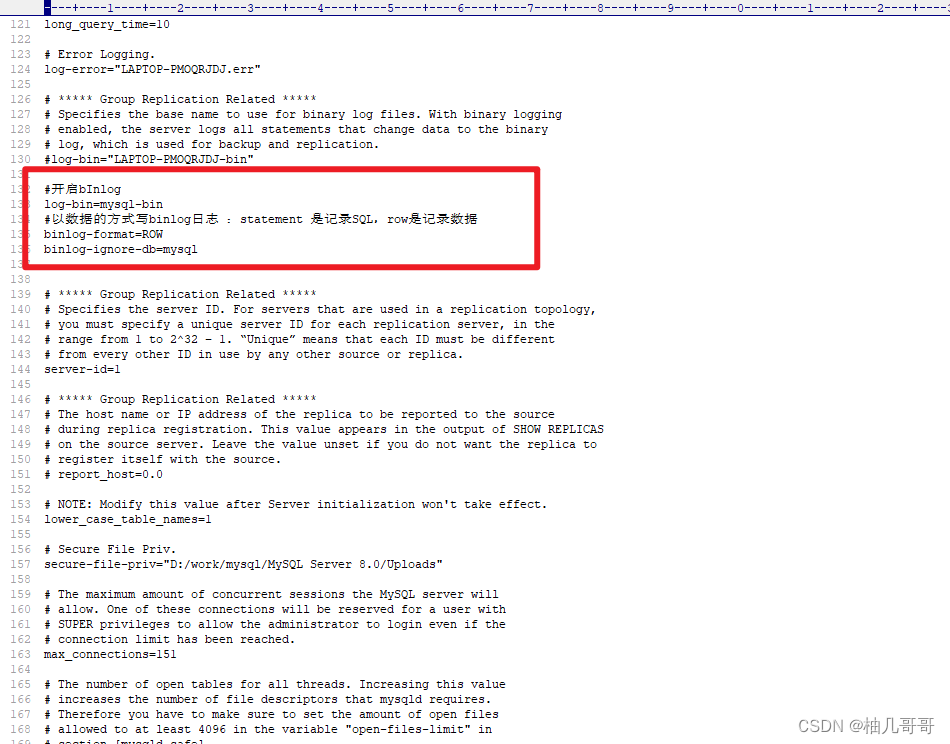
修改后,重启mysql服务。
- 创建cannal
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限,
flush privileges;
#创建用户cannal
CREATE USER canal IDENTIFIED BY 'canal';
#把所有权限赋予canal,密码也是canal
GRANT ALL PRIVILEGES ON canaldb.user TO 'canal'@'%' identified by "canal";
//GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' identified by "canal";
#刷新权限
flush privileges;如果已有账户可直接 grant
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; #更新一下用户密码
FLUSH PRIVILEGES; #刷新权限
通过以下命令,可以查看mysql用户信息
#查看所有数据库
show databases;
#使用mysql数据库
use mysql;
#查看当前库下所有表
show tables;
#查看user表
select Host, User from user;
3.安装Canal
3.1 下载Canal
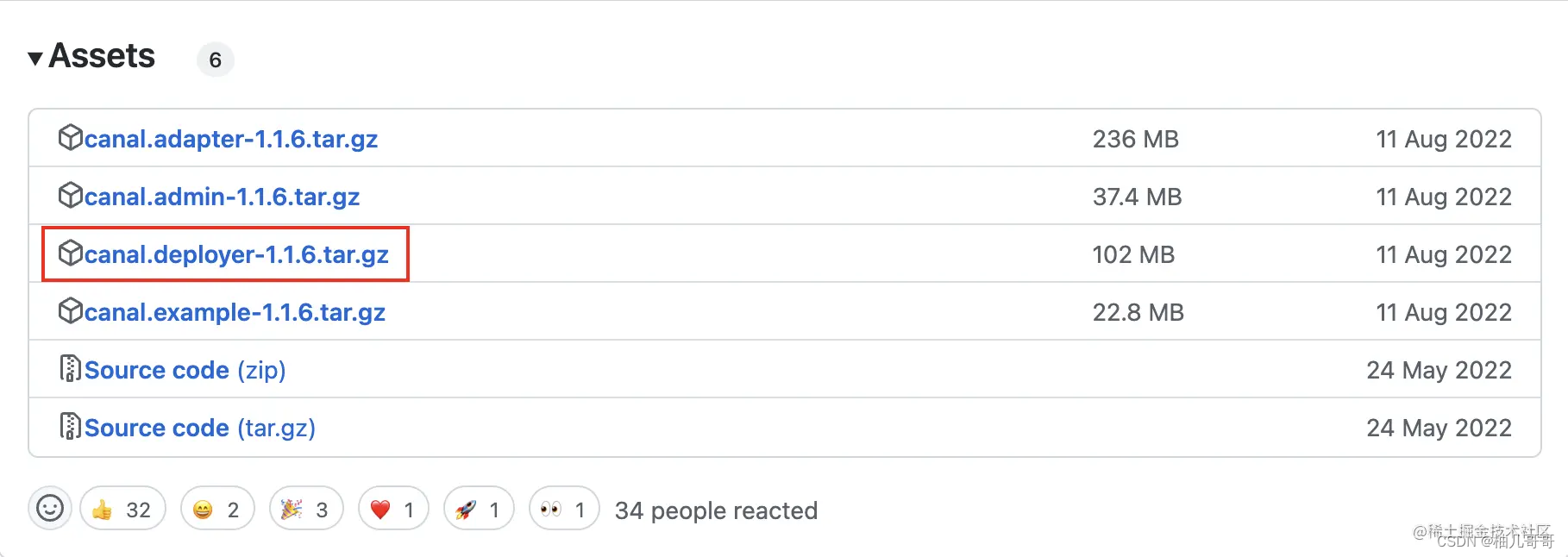
点击下载地址,选择版本后点击canal.deployer文件下载
https://github.com/alibaba/canal/releases
3.2 修改配置文件
打开目录下conf/example/instance.properties文件,主要修改以下内容
## mysql serverId,不要和 mysql 的 server_id 重复
canal.instance.mysql.slaveId = 10
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
#username/password,需要改成自己的数据库信息,与刚才添加的用户保持一致
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
复制代码
3.3 启动和关闭
#进入文件目录下的bin文件夹
#Linux启动
sh startup.sh
##Linux关闭
sh stop.sh
#Windows启动
双击 startup.bat
4.SpringCloud集成Canal
4.1 Canal数据结构
4.2 引入依赖
父工程规定版本,子工程引用
<!-- 统一管理jar包版本 --><properties><canal.version>1.2.1-RELEASE</canal.version></properties><!-- 子模块继承之后,提供作用:锁定版本+了modlue不用写groupId和version --><dependencyManagement><dependencies><!--Canal 依赖--><dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>${canal.version}</version></dependency></dependencies></dependencyManagement>
4.3 配置多个数据同步的目的地
由于我们这里是多个服务对应同一个canal端,则需要配置多个数据同步的目的地
在canal的安装目录下打开canal.deployer-1.1.6\conf\canal.properties文件
在canal.destinations = example后面添加多个数据目录,用逗号分割,一个服务对应一个目录,这里默认只有一个example
#################################################
######### destinations #############
#################################################
canal.destinations = example,ad,goods,course,order,secKill,auth
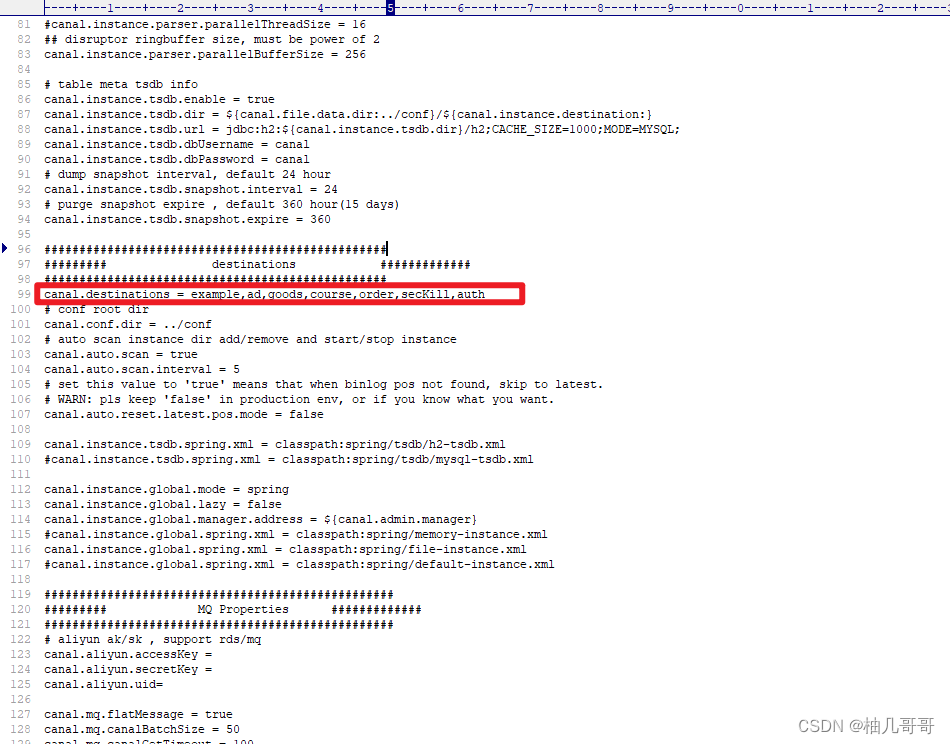
配置好后,重启canal服务
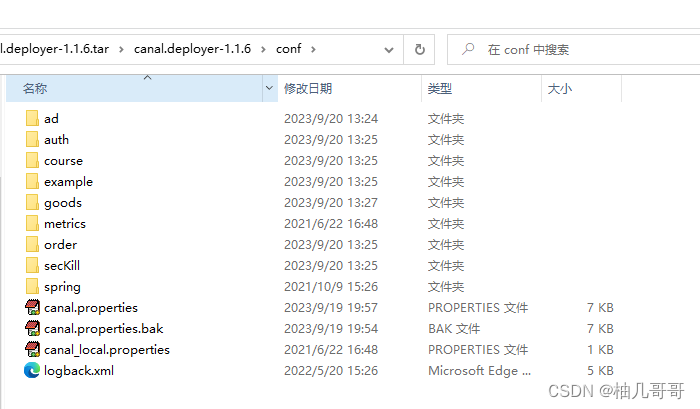
之后会看到会看到canal/conf目录下新增了这些数据目录的文件夹
我们需要将默认的example文件夹中的instance.properties配置文件复制到新创建的自定义数据目录中
4.4 application.yml
canal:#canal的地址server: 127.0.0.1:11111 #数据同步的目的地destination: goods
4.5 监听配置
去实现EntryHandler接口,添加自己的业务逻辑,比如缓存的删除更新插入,实现对增删改查的逻辑重写。
4.5 监听配置
去实现EntryHandler接口,添加自己的业务逻辑,比如缓存的删除更新插入,实现对增删改查的逻辑重写。
canal-client提供了EntryHandler,该handler中提供了insert,delete,update方法,当监听到某张表的相关操作后,会回调对应的方法把数据传递进来,我们就可以拿到数据往Redis同步了。
- @CanalTable(“employee”) :监听的表
EntryHandler<Employee>: 拿到employee表的改变后的数据之后,会封装为Employee实体 投递给我们
4.5.1 监听测试类
@CanalTable("test")
@Component
@Slf4j
public class TestHandler implements EntryHandler<Test> {@Resourceprivate RedisService redisService;@Overridepublic void insert(Test test) {log.info("新增Test:"+test);}@Overridepublic void delete(Test test) {log.debug("删除Test:"+test);}@Overridepublic void update(Test before, Test after) {log.info("修改前Test:"+before);log.info("修改后Test:"+after);}}
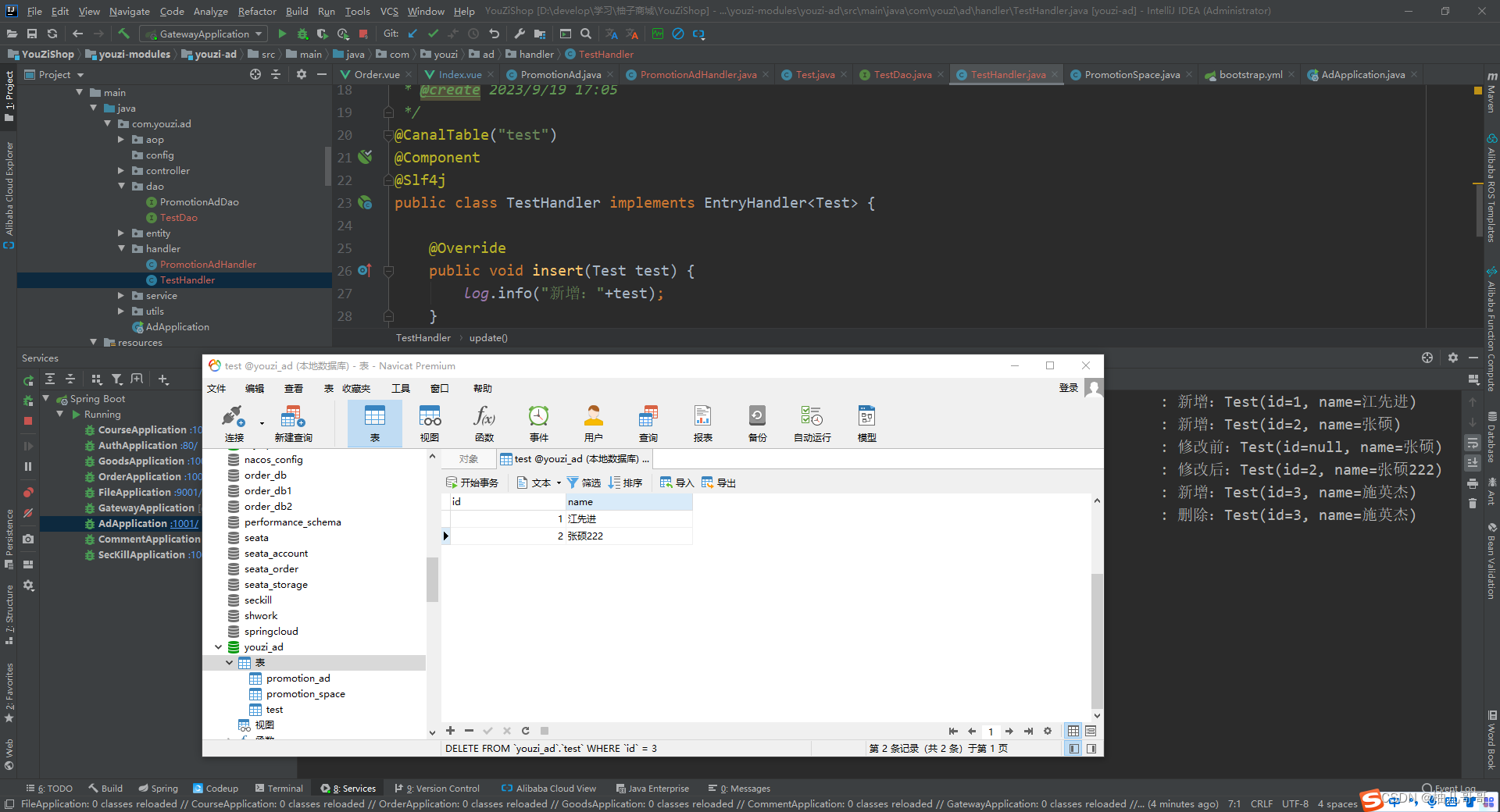
通过日志可以看到我们在navicat中对test这张表的增删改操作均被监听到了
4.5.2 redis数据同步
@CanalTable("employee")
@Component
@Slf4j
public class EmployeeHandler implements EntryHandler<Employee> {//把数据往Redis同步@Autowiredprivate RedisTemplate<Object,Object> redisTemplate;@Overridepublic void insert(Employee employee) {redisTemplate.opsForValue().set("EMP:"+employee.getId(),employee);}@Overridepublic void delete(Employee employee) {redisTemplate.delete("EMP:"+employee.getId());}@Overridepublic void update(Employee before, Employee after) {redisTemplate.opsForValue().set("EMP:"+after.getId(),after);}
}4.5.3 Elasticsearch数据同步
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;/*** GoodsHanlder : 数据同步处理器* 编写数据同步处理器,* canal-client提供了EntryHandler,* 该handler中提供了insert,delete,update方法,* 当监听到某张表的相关操作后,* 会回调对应的方法把数据传递进来,* 我们就可以拿到数据往Redis同步了。** @author zyw* @create 2023/9/19 17:19*/
@CanalTable("t_goods")
@Component
@Slf4j
public class GoodsHanlder implements EntryHandler<Goods> {@Resourceprivate EsApiService esApiService;@Resourceprivate RedisTemplate redisTemplate;@Resourceprivate RedisService redisService;/*** 新增商品后同步es** @param goods*/@SneakyThrows@Overridepublic void insert(Goods goods) {log.info("新增:" + goods);//同步至estry {boolean flag = esApiService.bulkRequest(EsConst.GOODS, String.valueOf(goods.getId()), goods);log.info("新增结果:" + flag);} catch (Exception e) {log.error("同步es新增:" + e.getMessage());}//同步redisMap<Long, Goods> goodsMap = (Map<Long, Goods>) redisTemplate.opsForValue().get(RedisEnum.GOODSLIST.getCode());goodsMap.put(goods.getId(),goods);redisService.setCacheObject(RedisEnum.GOODSLIST.getCode(), goodsMap);}/*** 更新商品后同步es** @param before* @param after*/@SneakyThrows@Overridepublic void update(Goods before, Goods after) {log.info("修改前:" + before);log.info("修改后:" + after);//同步至estry {boolean flag = esApiService.updateDocument(EsConst.GOODS, String.valueOf(after.getId()), after);log.info("修改结果:" + flag);} catch (Exception e) {log.error("同步es更新:" + e.getMessage());}//同步redisMap<Long, Goods> goodsMap = (Map<Long, Goods>) redisTemplate.opsForValue().get(RedisEnum.GOODSLIST.getCode());goodsMap.put(after.getId(),after);redisService.setCacheObject(RedisEnum.GOODSLIST.getCode(), goodsMap);}/*** 删除商品后同步es** @param goods*/@SneakyThrows@Overridepublic void delete(Goods goods) {log.info("删除:" + goods);//同步至estry {boolean flag = esApiService.deleteDocument(EsConst.GOODS, String.valueOf(goods.getId()));log.info("删除结果:" + flag);} catch (Exception e) {log.error("同步es更新:" + e.getMessage());}//同步redis//同步redisMap<Long, Goods> goodsMap = (Map<Long, Goods>) redisTemplate.opsForValue().get(RedisEnum.GOODSLIST.getCode());goodsMap.remove(goods.getId());redisService.setCacheObject(RedisEnum.GOODSLIST.getCode(), goodsMap);}
}4.5.4 Es Api 封装业务类 EsApiService
package com.youzi.elasticsearch.service;import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;import java.io.IOException;
import java.util.List;/*** EsService : es API封装类** @author zyw* @create 2023/9/19 17:31*/
@Component
@Slf4j
public class EsApiService {@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;/*** 更新文档信息* @param index 索引名称* @param id 更新文档的id* @param data 更新的对象* @return* @throws IOException*/public boolean updateDocument(String index, String id, Object data) throws IOException {UpdateRequest request = new UpdateRequest(index, id);request.timeout(TimeValue.timeValueSeconds(1));request.doc(JSON.toJSONString(data), XContentType.JSON);UpdateResponse update = client.update(request, RequestOptions.DEFAULT);log.info("更新文档信息:" + update);return true;}/*** 插入单个** @param index 索引名称* @param id 新增的文档id* @param data 新增的对象* @return* @throws IOException*/public boolean bulkRequest(String index, String id,Object data) throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");//批处理请求bulkRequest.add(new IndexRequest(index).id(id).source(JSON.toJSONString(data), XContentType.JSON));BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);return bulk.hasFailures();}/*** 删除文档信息** @param index 索引名称* @param id 删除文档的id* @throws IOException*/public boolean deleteDocument(String index, String id) throws IOException {DeleteRequest request = new DeleteRequest(index, id);request.timeout(TimeValue.timeValueSeconds(1));DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);log.info("删除文档信息:" + delete);return true;}4.6 canal日志
如果不想让控制台一直打印某些信息,可以配置如下配置屏蔽AbstractCanalClient类process()一直打印this.log.info(“获取消息 {}”, message)。
logging:level:#禁止AbstractCanalClient 打印常規日志 获取消息 {}top.javatool.canal.client: warn
4.7 第二种方案(解决数据库存在下划线,用上述方法,某些字段会为空)
上面的方式只适合数据库字段和实体类字段,属性完全一致的情况;当数据库字段含有下划线的适合,因为我们直接去监听的binlog日志,里面的字段是数据库字段,因为跟实体类字段不匹配,所以会出现字段为空的情况,这个适合需要去获取列的字段,对字段进行属性转换,实现方法如下:
4.7.1 引入依赖
<dependency><groupId>com.xpand</groupId><artifactId>starter-canal</artifactId><version>0.0.1-SNAPSHOT</version></dependency>
4.7.2 创建监听
@CanalEventListener
@Slf4j
public class KafkaListener {@Autowiredprivate RedisTemplate redisTemplate;/*** @param eventType 当前操作数据库的类型* @param rowData 当前操作数据库的数据*/@ListenPoint(schema = "maruko", table = "kafka_test")public void listenKafkaTest(CanalEntry.EventType eventType, CanalEntry.RowData rowData) {KafkaTest kafkaTestBefore = new KafkaTest();KafkaTest kafkaTestAfter = new KafkaTest();//遍历数据获取k-vList<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();getEntity(beforeColumnsList, kafkaTestBefore);log.warn("获取到提交前的对象为:" + kafkaTestBefore);getEntity(afterColumnsList, kafkaTestAfter);log.warn("获取到提交后的对象为:" + kafkaTestAfter);//判断是新增还是更新还是删除switch (eventType.getNumber()) {case CanalEntry.EventType.INSERT_VALUE:case CanalEntry.EventType.UPDATE_VALUE:redisTemplate.opsForValue().set("kafka_test" + kafkaTestAfter.getId(), kafkaTestAfter);break;case CanalEntry.EventType.DELETE_VALUE:redisTemplate.delete("kafka_test" + kafkaTestBefore.getId());break;}}/*** 遍历获取属性转换为实体类** @param columnsList* @param kafkaTest*/private void getEntity(List<CanalEntry.Column> columnsList, KafkaTest kafkaTest) {SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");for (CanalEntry.Column column : columnsList) {String name = column.getName();String value = column.getValue();switch (name) {case KafkaTest.ID:if (StringUtils.hasLength(value)) {kafkaTest.setId(Integer.parseInt(value));}break;case KafkaTest.CONTENT:if (StringUtils.hasLength(value)) {kafkaTest.setContent(value);}break;case KafkaTest.PRODUCER_STATUS:if (StringUtils.hasLength(value)) {kafkaTest.setProducerStatus(Integer.parseInt(value));}break;case KafkaTest.CONSUMER_STATUS:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerStatus(Integer.parseInt(value));}break;case KafkaTest.UPDATE_TIME:if (StringUtils.hasLength(value)) {try {kafkaTest.setUpdateTime(format.parse(value));} catch (ParseException p) {log.error(p.getMessage());}}break;case KafkaTest.TOPIC:if (StringUtils.hasLength(value)) {kafkaTest.setTopic(value);}break;case KafkaTest.CONSUMER_ID:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerId(value);}break;case KafkaTest.GROUP_ID:if (StringUtils.hasLength(value)) {kafkaTest.setGroupId(value);}break;case KafkaTest.PARTITION_ID:if (StringUtils.hasLength(value)) {kafkaTest.setPartitionId(Integer.parseInt(value));}break;case KafkaTest.PRODUCER_OFFSET:if (StringUtils.hasLength(value)) {kafkaTest.setProducerOffset(Long.parseLong(value));}break;case KafkaTest.CONSUMER_OFFSET:if (StringUtils.hasLength(value)) {kafkaTest.setConsumerOffset(Long.parseLong(value));}break;case KafkaTest.TEST:if (StringUtils.hasLength(value)) {kafkaTest.setTest(value);}break;}}}
}
4.7.3 实体类
@Data
@TableName("kafka_test")
public class KafkaTest {public static final String ID = "id";public static final String CONTENT = "content";public static final String PRODUCER_STATUS = "producer_status";public static final String CONSUMER_STATUS = "consumer_status";public static final String UPDATE_TIME = "update_time";public static final String TOPIC = "topic";public static final String CONSUMER_ID = "consumer_id";public static final String GROUP_ID = "group_id";public static final String PARTITION_ID = "partition_id";public static final String PRODUCER_OFFSET = "consumer_offset";public static final String CONSUMER_OFFSET = "producer_offset";public static final String TEST = "test";@TableId(type = IdType.AUTO)private Integer id;@TableField("content")private String content;@TableField("producer_status")private Integer producerStatus;@TableField("consumer_status")private Integer consumerStatus;@TableField("update_time")private Date updateTime;@TableField("topic")private String topic;@TableField("consumer_id")private String consumerId;@TableField("group_id")private String groupId;@TableField("partition_id")private int partitionId;@TableField("consumer_offset")private Long consumerOffset;@TableField("producer_offset")private Long producerOffset;@TableField("test")private String test;
}4.8 第三种方案(解决数据库存在下划线,某些字段会为空)
实体类加上@Column注解
/*** 商品表(TGoods)实体类** @author zyw* @since 2023-07-15 17:09:12*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@TableName("t_goods")
public class Goods implements Serializable {private static final long serialVersionUID = -53376609655570945L;/*** 商品ID*/@TableId(type = IdType.AUTO)@Column(name = "id")private Long id;/*** 商品名称*/@TableField("goods_name")@Column(name = "goods_name")private String goodsName;/*** 商品标题*/@TableField("goods_title")@Column(name = "goods_title")private String goodsTitle;/*** 商品图片*/@TableField("goods_img")@Column(name = "goods_img")private String goodsImg;/*** 商品详情*/@TableField("goods_detail")@Column(name = "goods_detail")private String goodsDetail;/*** 商品价格*/@TableField("goods_price")@Column(name = "goods_price")private Double goodsPrice;/*** 商品库存*/@TableField("goods_stock")@Column(name = "goods_stock")private Integer goodsStock;/*** 商家*/@TableField("shop")@Column(name = "shop")private String shop;/*** 创建时间*/@TableField("start_date")@Column(name = "start_date")@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")private Date startDate;/*** 删除时间*/@TableField("end_date")@Column(name = "end_date")@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")private Date endDate;}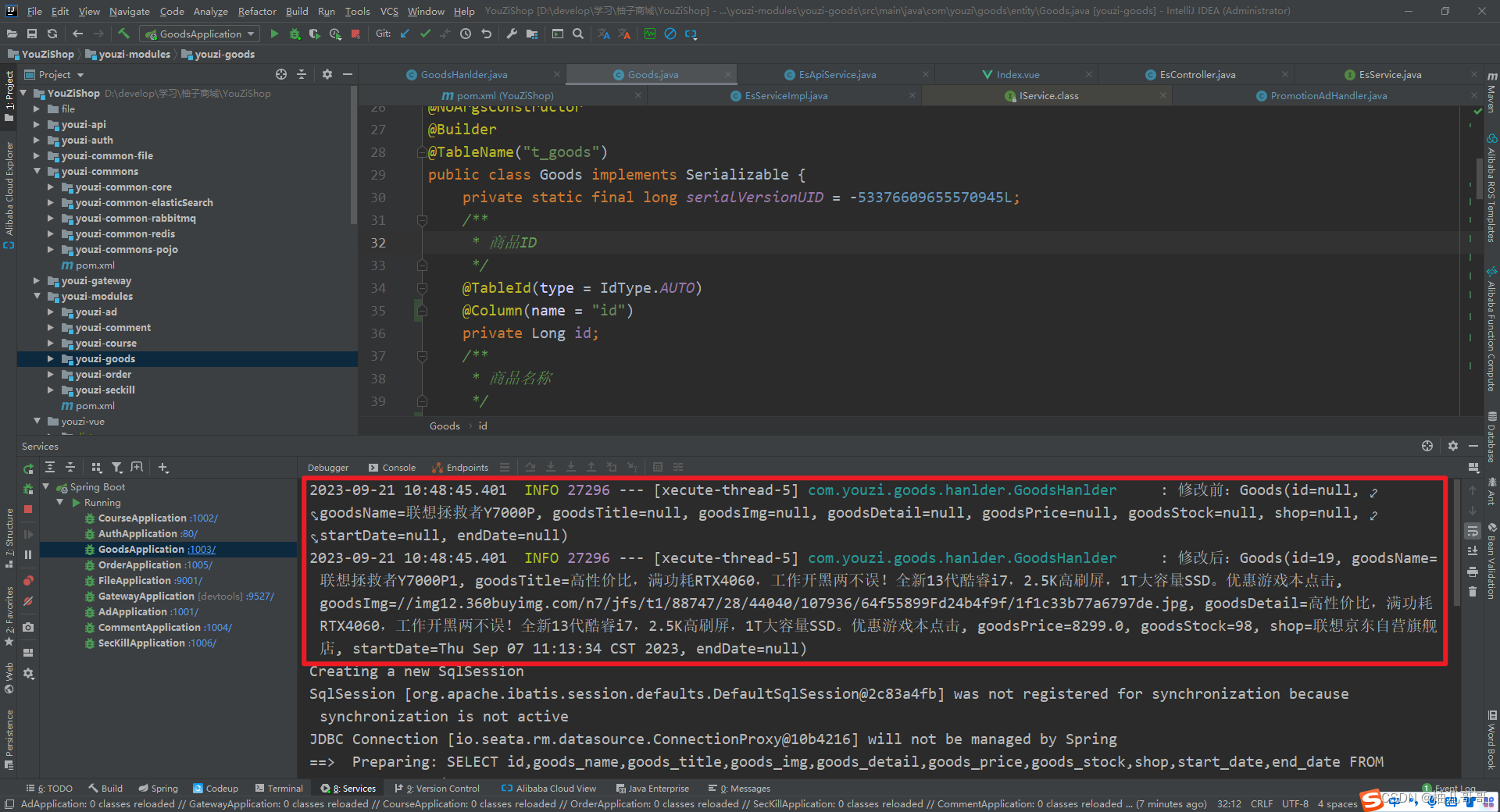
4.9 canal整合异常问题排查思路
4…1 无法正常启动
canal配置文件中mysql连接方式是否有效,
是否已为canal单独配置mysql账号,并赋予权限
服务对应的自定义数据存储目的地中配置文件是否完整,初始配置文件需要与默认的exmple中配置文件一致
更改配置文件之后如果自定义的数据目录还是无法连接,则将对应目录下的meta.dat文件删除之后再重启
4.9.2 使用canal监听数据 启动成功了 没有报错 不过一直监听不到消息
- 检查canal的配置,确保配置正确,特别是数据库的连接信息;
- 检查canal的日志,确保没有报错;
- 检查数据库的binlog是否开启,确保binlog格式为row;
- 检查数据库的binlog是否有变更,确保有变更;
- 检查canal的过滤规则,确保过滤规则正确;
- 检查canal的版本,确保版本与数据库版本兼容;
- 检查canal的运行环境,确保环境正确;
- 检查canal的配置文件,确保配置文件正确;
- 检查canal的运行状态,确保运行正常;
- 检查canal的监听端口,确保端口没有被占用。
相关文章:
Canal实现Mysql数据同步至Redis、Elasticsearch
文章目录 1.Canal简介1.1 MySQL主备复制原理1.2 canal工作原理 2.开启MySQL Binlog3.安装Canal3.1 下载Canal3.2 修改配置文件3.3 启动和关闭 4.SpringCloud集成Canal4.1 Canal数据结构
Kafka的消息传递保证和一致性
前言 通过前面的文章,相信大家对Kafka有了一定的了解了,那接下来问题就来了,Kafka既然作为一个分布式的消息队列系统,那它会不会出现消息丢失或者重复消费的情况呢?今天咱们就来一探。 实现机制 Kafka采用了一系列机…...

Docker 部署 Firefly III 服务
拉取最新版本的 Firefly III 镜像: $ sudo docker pull fireflyiii/core:latest在本地预先创建好 upload 和 export 目录, 用于映射 Firefly III 容器内的 /var/www/html/storage/upload 和 /var/www/html/storage/export 目录。 使用以下命令来运行 Firefly III …...
配置OSPFv3基本功能 华为笔记
1.1 实验介绍 1.1.1 关于本实验 OSPF协议是为IP协议提供路由功能的路由协议。OSPFv2(OSPF版本2)是支持IPv4的路由协议,为了让OSPF协议支持IPv6,技术人员开发了OSPFv3(OSPF版本3)。 无论是OSPFv2还是OSPFv…...
【AI视野·今日Sound 声学论文速览 第九期】Thu, 21 Sep 2023
AI视野今日CS.Sound 声学论文速览 Thu, 21 Sep 2023 Totally 1 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚Auto-ACD,大规模文本-音频数据集自动生成方法。 基于现有的大模型和api构建了一套大规模高质量的音频文本数据收集方法,…...

数据结构-----堆(完全二叉树)
目录 前言 一.堆 1.堆的概念 2.堆的存储方式 二.堆的操作方法 1.堆的结构体表示 2.数字交换接口函数 3.向上调整(难点) 4.向下调整(难点) 5.创建堆 6.堆的插入 7.判断空 8.堆的删除 9.获取堆的根(顶)元素 10.堆的遍历…...

set/multiset容器、map容器
目录 set/multiset容器 set基本概念 set大小和交换 set插入和删除 查找和统计 set和multiset的区别 改变set排序规则 set存放内置数据类型 set存放自定义数据类型 pair队组 map容器 map容器的基本概念 map构造和赋值 map大小和交换 map插入和删除 map查找和统计…...
)
Linux系统编程——总结初识Linux(常用命令、特点、常见操作系统)
文章目录 UNIX操作系统(了解)Linux操作系统主要特征Linux和unix的区别和联系什么是操作系统常见的操作系统Ubuntu操作系统Ubuntu安装linux下的目录的类型(掌握)shell指令shell指令的格式文件操作相关指令系统相关命令网络相关命令其他命令软件安装相关的…...

Js使用ffmpeg进行视频剪辑和画面截取
ffmpeg 使用场景是需要在web端进行视频的裁剪,包括使用 在线视频url 或 本地视频文件 的裁剪,以及对视频内容的截取等功能。 前端进行视频操作可能会导致性能下降,最好通过后端使用java,c进行处理,本文的案例是备选方…...

Linux基本命令,基础知识
进到当前用户目录:cd ~ 回到上级目录:cd .. 查看当前目录层级:pwd 创建目录:mkdir mkdir ruanjian4/linux/zqm41 -p级联创建文件夹(同时创建多个文件夹需要加-p) 查看详细信息:ls -l (即 ll) 查看所有详细信息:ls -al 隐藏文件是以.开头的 查看:l…...
【Android知识笔记】进程通信(三)
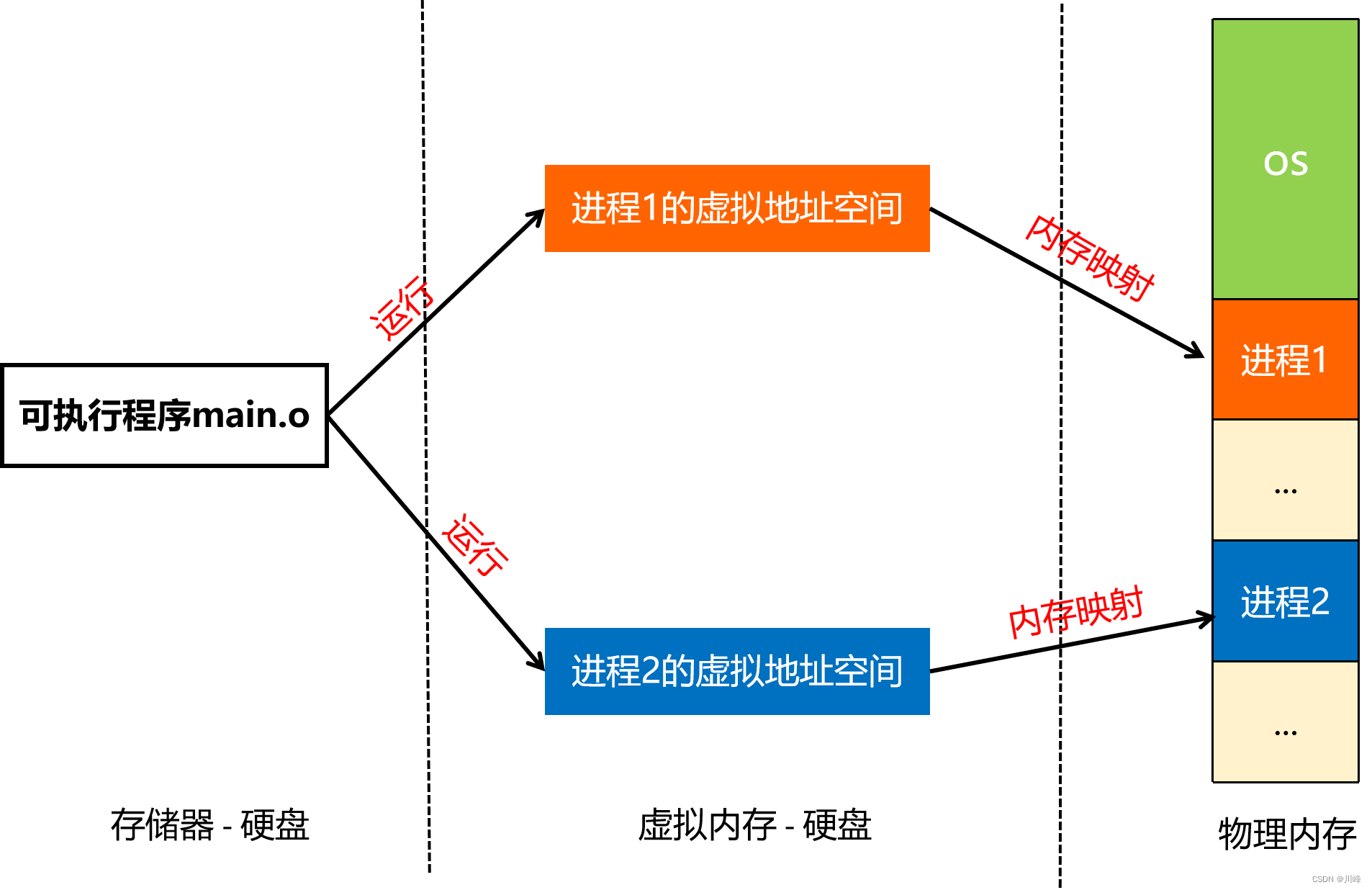
在上一篇探索Binder通信原理时,提到了内存映射的概念,其核心是通过mmap函数,将一块 Linux 内核缓存区映射到一块物理内存(匿名文件),这块物理内存其实是作为Binder开辟的数据接收缓存区。这里有两个概念,需要理解清楚,那就是操作系统中的虚拟内存和物理内存,理解了这两…...

云上亚运:所使用的高新技术,你知道吗?
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 前言 一.什么是云上亚运会 二.为什么要使用云…...

数据结构简述,时间、空间复杂度,学习网站推荐
目录 IT 学习路线 相关坚韧大厚书 相关有趣/耐看书或视频 数据结构与算法学习网站推荐 刷题 时间、空间复杂度 数据结构简述 基本概念 数据结构与算法简述和CS综述整理。本文非基础的教程,本文会列出大量学习和参考网站。老惯例,一个文章是一个集…...
在线安装qt5.15之后任意版本
下载qt现在安装包: window安装包链接 进入cmd,用命令行打开安装包,并指定组件下载地址(这个是关键,之前用的是腾讯镜像,出现了版本灰色无法选中问题) .\qt-unified-windows-x64-4.6.1-online…...
【kafka实战】01 3分钟在Linux上安装kafka
本节采用docker安装Kafka。采用的是bitnami的镜像。Bitnami是一个提供各种流行应用的Docker镜像和软件包的公司。采用docker的方式3分钟就可以把我们想安装的程序运行起来,不得不说真的很方便啊,好了,开搞。使用前提:Linux虚拟机&…...

yum安装mysql8
记录一下安装过程用于后面项目参考 目录 说明安装步骤yum安装默认目录修改默认的数据目录必要的my.cnf属性修改卸载Mysql 说明 一般情况下都是docker安装,部分特殊情况下,例如老外的项目部分禁用docker,那一般二进制安装或者yum直接安装。 …...
Stable Diffusion使用教程:另一个线稿出3D例子)
十五)Stable Diffusion使用教程:另一个线稿出3D例子
案例:黄金首饰出图 1)线稿,可以进行色阶加深,不易丢失细节; 2)文生图,精确材质、光泽、工艺(抛光、拉丝等)、形状(包括深度等,比如镂空)和渲染方式(3D、素描、线稿等)提示词,负面提示词; 3)seed调-1,让ai随机出图; 4)开启controlnet,上传线稿图,选择cann…...
)
2023icpc网络预选赛I. Pa?sWorD(dp)
题目给定字符串长度n以及字符串s 其中出现小写字母可以代表小写字母和大写字母 比如a可以代表a和A 出现?可以代表26个小写字母和26个大写字母和10个数字 出现大写字母和数字就是原本的数 同时要求大写字母,小写字母,数字一定都存在替换完的字符串中…...

maven本地安装jar包
在实际开发中,有些jar包不能通过公共库下载,只能本地安装。可以按照以下步骤操作: 1、安装命令 mvn install:install-file -DgroupIdcom.chinacreator.sm -DartifactIdfbm-sm-common -Dversion0.0.1 -Dpackagingjar -Dfile../newJar/fbm-sm…...

QT中的inherits
目录 简介: 实例: 简介: 在Qt中,可以使用inherits函数来判断一个对象是否属于某个类或其派生类。inherits函数是QObject类的成员函数,因此只能用于继承自QObject的类的对象。 以下是inherits函数的一般用法…...

深度探索.NET Aspire在云原生应用性能与安全加固的创新实践
深度探索.NET Aspire在云原生应用性能与安全加固的创新实践 前言 云原生应用在当今数字化转型浪潮中扮演着关键角色,其性能与安全成为决定应用成败的核心要素。.NET Aspire作为微软推出的面向云原生开发的框架,为开发者提供了一套完整的工具与方法&#…...

RAG系统里最容易被低估的环节:深度解析检索优化策略,提升大模型应用效果!
本文深入剖析了RAG系统中检索环节的重要性,指出检索错误是导致大模型应用效果不佳的关键因素。文章从表达鸿沟、粒度鸿沟和意图鸿沟三重鸿沟出发,详细介绍了Query侧优化(如Query Rewriting、Multi-Query、HyDE)、索引侧优化&#…...

数据库死锁的排查:从现象到根因
在软件测试工作中,数据库的稳定性和数据一致性是评估系统质量的关键维度。死锁问题,作为数据库并发控制中的“顽疾”,其随机性、隐蔽性和破坏性常常让测试人员感到棘手。它不仅是性能测试中的“拦路虎”,更可能在线上引发严重故障…...

Unity | HDRP高清渲染管线实战:优化Lightmapping性能的10个关键技巧
1. 理解HDRP中的Lightmapping核心机制 在HDRP高清渲染管线中,光照烘焙(Lightmapping)是将复杂光照计算转化为纹理贴图的关键技术。与实时渲染不同,烘焙过程会预先计算场景中静态物体的间接光照、阴影和环境光遮蔽效果,…...

基于SpringBoot + Vue的人工智能时代个人计算机的安全防护科普系统
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

保姆级教程!小程序开发只需3步,Gemini设计 + Trae开发 + 微信开发者工具预览上架
大家好,我是李奔腾。今天我想分享一下,如何通过AI工具快速设计和开发一个万年历小程序。借助 Gemini、Trae 和 微信开发者工具,几分钟时间就能让小程序顺利运行起来,极大地提升开发效率。第一步:使用Gemini设计小程序首…...

未发表!25年顶级SCI算法SOO优化CNN-LSTM-Attention一键实现多步预测!多步预测全家桶更新啦!
目录 多步预测案例 多步预测教程 创新点与原理 ①创新点一:基于CNN-LSTM的多尺度特征联合提取架构 ②创新点二:融合SE通道注意力机制的自适应特征重标定策略 ③创新点三:基于SOO智能算法的超参数自适应寻优 结果展示 全家桶目录 获取…...

避坑指南:Qt Modbus TCP开发中自动刷新与写入冲突的排查与修复
Qt Modbus TCP开发实战:自动刷新与写入冲突的深度解决方案 在工业控制系统的HMI界面开发中,实时数据刷新与用户交互操作的平衡是个经典难题。上周调试一个智能仓储监控系统时,就遇到了这样的场景:当PLC寄存器数据以500ms间隔自动刷…...

科技金融数智底座技术架构及优秀厂商
好的,科技金融数智底座的技术架构通常包含以下核心层级,并推荐相关厂商(含火石创造):一、科技金融数智底座技术架构1. 数据层功能:集成多源异构数据(如交易数据、用户行为、产业经济数据等&…...

嵌入式工程师的核心竞争力与职业发展路径
1. 嵌入式工程师的现状与挑战嵌入式系统作为连接物理世界与数字世界的桥梁,已经渗透到现代社会的各个角落。从我们口袋里的智能手机到工厂的自动化设备,从智能家居到航空航天系统,嵌入式技术无处不在。然而,这个看似广阔的领域&am…...