【Java 基础篇】Java Stream 流详解

Java Stream(流)是Java 8引入的一个强大的新特性,用于处理集合数据。它提供了一种更简洁、更灵活的方式来操作数据,可以大大提高代码的可读性和可维护性。本文将详细介绍Java Stream流的概念、用法和一些常见操作。
什么是Stream流?
在开始介绍Java Stream流之前,让我们先了解一下什么是流。流是一系列元素的序列,它可以在一次遍历的过程中逐个处理这些元素。在Java中,流是对数据的抽象,可以操作各种不同类型的数据源,如集合、数组、文件等。
Stream流的主要特点包括:
- 链式调用:可以通过一系列的方法调用来定义对流的操作,使代码更具可读性。
- 惰性求值:流上的操作不会立即执行,只有在遇到终端操作时才会触发计算。
- 函数式编程:流操作使用了函数式编程的思想,可以通过Lambda表达式来定义操作。
- 并行处理:可以轻松地将流操作并行化,充分利用多核处理器的性能。
创建Stream流
在使用Java Stream流之前,首先需要创建一个流。流可以从各种数据源中创建,包括集合、数组、文件等。
从集合创建流
可以使用集合的stream()方法来创建一个流。例如:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
Stream<String> stream = names.stream();
从数组创建流
可以使用Arrays.stream()方法来从数组中创建一个流。例如:
int[] numbers = {1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(numbers);
从文件创建流
可以使用Files.lines()方法来从文件中创建一个流。例如:
try (Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset())) {// 处理文件中的每一行数据lines.forEach(System.out::println);
} catch (IOException e) {e.printStackTrace();
}
流的操作
一旦创建了流,就可以对其进行各种操作。流的操作可以分为两类:中间操作和终端操作。
中间操作
中间操作是对流的一系列处理步骤,这些步骤会返回一个新的流,允许链式调用。中间操作通常用于对数据进行过滤、映射、排序等操作。一些常见的中间操作包括:
filter(Predicate<T> predicate):根据条件过滤元素。map(Function<T, R> mapper):将元素映射为新的值。sorted():对元素进行排序。distinct():去重,去除重复的元素。limit(long maxSize):限制流中元素的数量。skip(long n):跳过流中的前n个元素。
例如,以下代码将对一个整数集合进行筛选、映射和排序操作:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> result = numbers.stream().filter(n -> n % 2 == 0) // 过滤偶数.map(n -> n * 2) // 映射为原来的2倍.sorted() // 排序.collect(Collectors.toList()); // 收集结果
终端操作
终端操作是流的最后一步操作,它会触发对流的计算并产生一个最终的结果。终端操作通常包括:
forEach(Consumer<T> action):对流中的每个元素执行操作。collect(Collector<T, A, R> collector):将流中的元素收集到一个容器中。toArray():将流中的元素收集到数组中。reduce(identity, accumulator):对流中的元素进行归约操作,返回一个值。count():返回流中元素的数量。min(comparator):返回流中的最小元素。max(comparator):返回流中的最大元素。allMatch(predicate):检查流中的所有元素是否都满足条件。anyMatch(predicate):检查流中是否存在满足条件的元素。noneMatch(predicate):检查流中是否没有元素满足条件。findFirst():返回流中的第一个元素。findAny():返回流中的任意一个元素。
终端操作是流的最后一步,一旦调用终端操作,流将被消耗,不能再被复用。
示例:从集合中筛选特定条件的元素
让我们通过一个示例来演示Java Stream流的使用。假设我们有一个包含学生对象的集合,每个学生对象都有姓名、年龄和成绩属性。我们想从集合中筛选出年龄大于18岁且成绩优秀的学生。
class Student {private String name;private int age;private double score;public Student(String name, int age, double score) {this.name = name;this.age = age;this.score = score;}public String getName() {return name;}public int getAge() {return age;}public double getScore() {return score;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", score=" + score +'}';}
}public class Main {public static void main(String[] args) {List<Student> students = Arrays.asList(new Student("Alice", 20, 90.0),new Student("Bob", 22, 85.5),new Student("Charlie", 19, 88.5),new Student("David", 21, 92.0),new Student("Eva", 18, 94.5));List<Student> result = students.stream().filter(student -> student.getAge() > 18 && student.getScore() >= 90.0).collect(Collectors.toList());result.forEach(System.out::println);}
}
运行以上代码,将输出符合条件的学生信息:
Student{name='Alice', age=20, score=90.0}
Student{name='David', age=21, score=92.0}
并行流
Java Stream还提供了并行流的支持,可以充分利用多核处理器的性能。只需将普通流转换为并行流,即可实现并行化处理。
List<Student> result = students.parallelStream().filter(student -> student.getAge() > 18 && student.getScore() >= 90.0).collect(Collectors.toList());
需要注意的是,并行流在某些情况下可能会引发线程安全问题,因此在处理共享状态时要格外小心。
更多操作
当使用Java Stream流进行数据处理时,除了基本的过滤、映射、排序和归约等操作外,还有许多其他有用的中间操作和终端操作。在本节中,我将介绍一些常见的Stream流操作,帮助你更好地理解如何使用它们。
中间操作
1. distinct()
distinct()方法用于去除流中的重复元素,返回一个去重后的新流。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 4, 4, 5);
List<Integer> distinctNumbers = numbers.stream().distinct().collect(Collectors.toList());System.out.println(distinctNumbers); // 输出: [1, 2, 3, 4, 5]
2. limit(n)
limit(n)方法用于截取流中的前n个元素,返回一个包含前n个元素的新流。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> limitedNumbers = numbers.stream().limit(5).collect(Collectors.toList());System.out.println(limitedNumbers); // 输出: [1, 2, 3, 4, 5]
3. skip(n)
skip(n)方法用于跳过流中的前n个元素,返回一个跳过前n个元素后的新流。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> skippedNumbers = numbers.stream().skip(5).collect(Collectors.toList());System.out.println(skippedNumbers); // 输出: [6, 7, 8, 9, 10]
4. flatMap()
flatMap()方法用于将流中的每个元素映射成一个新的流,然后将这些新流合并成一个流。通常用于将嵌套的集合扁平化。
示例:
List<List<Integer>> nestedLists = Arrays.asList(Arrays.asList(1, 2),Arrays.asList(3, 4),Arrays.asList(5, 6)
);List<Integer> flattenedList = nestedLists.stream().flatMap(Collection::stream).collect(Collectors.toList());System.out.println(flattenedList); // 输出: [1, 2, 3, 4, 5, 6]
终端操作
1. forEach()
forEach()方法用于对流中的每个元素执行指定的操作。
示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.stream().forEach(name -> System.out.println("Hello, " + name));
2. toArray()
toArray()方法用于将流中的元素收集到数组中。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Integer[] numberArray = numbers.stream().toArray(Integer[]::new);
3. reduce(identity, accumulator)
reduce()方法用于对流中的元素进行归约操作,返回一个值。identity是初始值,accumulator是归约函数。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream().reduce(0, (a, b) -> a + b);System.out.println(sum); // 输出: 15
4. collect()
collect()方法用于将流中的元素收集到一个集合或其他数据结构中。可以使用Collectors类提供的各种工厂方法创建不同类型的集合。
示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> collectedNames = names.stream().collect(Collectors.toList());Set<String> collectedSet = names.stream().collect(Collectors.toSet());Map<String, Integer> collectedMap = names.stream().collect(Collectors.toMap(name -> name, String::length));
5. min(comparator) 和 max(comparator)
min(comparator)和max(comparator)方法用于查找流中的最小和最大元素,需要传入一个比较器(Comparator)来定义比较规则。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> minNumber = numbers.stream().min(Integer::compareTo);Optional<Integer> maxNumber = numbers.stream().max(Integer::compareTo);System.out.println(minNumber.orElse(0)); // 输出: 1
System.out.println(maxNumber.orElse(0)); // 输出: 5
6. anyMatch(predicate)、allMatch(predicate) 和 noneMatch(predicate)
这些方法用于检查流中的元素是否满足给定的条件。
anyMatch(predicate):检查流中是否有任意一个元素满足条件。allMatch(predicate):检查流中的所有元素是否都满足条件。noneMatch(predicate):检查流中是否没有元素满足条件。
示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean anyGreaterThanThree = numbers.stream().anyMatch(n -> n > 3);boolean allGreaterThanThree = numbers.stream().allMatch(n -> n > 3);boolean noneGreaterThanTen = numbers.stream().noneMatch(n -> n > 10);System.out.println(anyGreaterThanThree); // 输出: true
System.out.println(allGreaterThanThree); // 输出: false
System.out.println(noneGreaterThanTen); // 输出: true
7. findFirst() 和 findAny()
findFirst()方法返回流中的第一个元素(在串行流中通常是第一个元素,但在并行流中不确定),findAny()方法返回流中的任意一个元素。
示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Optional<String> first = names.stream().findFirst();Optional<String> any = names.parallelStream().findAny();
这些只是Java Stream流的一些常见操作,Stream API提供了更多的方法来处理数据。根据具体的需求,你可以组合这些操作来构建复杂的数据处理流程。希望这些示例能帮助你更好地理解和使用Java Stream流。
注意事项
在使用Java Stream流时,有一些注意事项需要考虑,以确保代码的正确性和性能。以下是一些常见的注意事项:
-
不可重用性: 一旦创建了一个Stream对象并执行了终端操作,该Stream就不能再被重用。如果需要对同一数据集进行多次处理,应该每次都创建新的Stream对象。
-
惰性求值: Stream是惰性求值的,中间操作只会在终端操作触发后才会执行。这意味着中间操作不会立即产生结果,而是在需要结果时才进行计算。这可以帮助节省计算资源,但也需要谨慎处理,以免产生意外的行为。
-
并行流的线程安全性: 如果使用并行流(parallelStream()),要确保Stream操作是线程安全的。一些操作可能会引发并发问题,需要适当的同步或避免使用并行流。
-
流的关闭: 如果你使用的是基于IO的流(如Files.lines()),需要确保在使用完后关闭流,以释放资源。
-
性能注意事项: Stream操作的性能可能会受到数据量的影响。在大数据集上使用Stream时,要注意性能问题,可以考虑使用并行流或其他优化方法。
-
空值处理: 在使用Stream时,要注意空值(null)的处理,避免空指针异常。可以使用
filter、map等操作来过滤或转换空值。 -
有状态操作: 一些Stream操作是有状态的,例如
sorted和distinct,它们可能需要缓存所有元素,因此在处理大数据集时要谨慎使用,以免导致内存溢出。 -
自定义收集器: 如果需要自定义收集器(Collector),要确保它的线程安全性和正确性,以便在Stream中使用。
-
不可变性: 推荐使用不可变对象和不可变集合来处理Stream,以避免并发问题。
-
了解Stream操作的复杂度: 不同的Stream操作具有不同的时间复杂度。了解操作的复杂度有助于选择最适合的操作来满足性能需求。
总之,使用Java Stream流可以编写更简洁和可读性强的代码,但在使用过程中需要考虑到流的惰性求值、线程安全性、性能等方面的注意事项,以确保代码的正确性和性能。
总结
Java Stream流是一项强大的特性,可以极大地简化集合数据的处理。通过中间操作和终端操作的组合,我们可以轻松地实现各种复杂的数据处理任务。同时,流还提供了并行处理的支持,可以充分利用多核处理器的性能。
要注意的是,流是一次性的,一旦调用了终端操作,流将被消耗,不能再被复用。此外,在使用并行流时要注意线程安全的问题。
希望本文能帮助你更好地理解和使用Java Stream流,提高代码的可读性和可维护性。如果你对Java Stream流还有更多的疑问或想要深入了解,可以查阅官方文档或进一步学习相关的教程和示例。 Happy coding!
相关文章:
【Java 基础篇】Java Stream 流详解
Java Stream(流)是Java 8引入的一个强大的新特性,用于处理集合数据。它提供了一种更简洁、更灵活的方式来操作数据,可以大大提高代码的可读性和可维护性。本文将详细介绍Java Stream流的概念、用法和一些常见操作。 什么是Stream…...

题解:ABC321A - 321-like Checker
题解:ABC321A - 321-like Checker 题目 链接:Atcoder。 链接:洛谷。 难度 算法难度:C。 思维难度:C。 调码难度:C。 综合评价:见洛谷链接。 算法 模拟。 思路 输入n后从后往前依次抽…...
Zig实现Hello World
1. 什么是zig 先列出一段官方的介绍: Zig is a general-purpose programming language and toolchain for maintaining robust, optimal, and reusable software. 大概意思就是说: Zig是一种通用编程语言和工具链,用于维护健壮、最佳和可重用的软件。 官…...
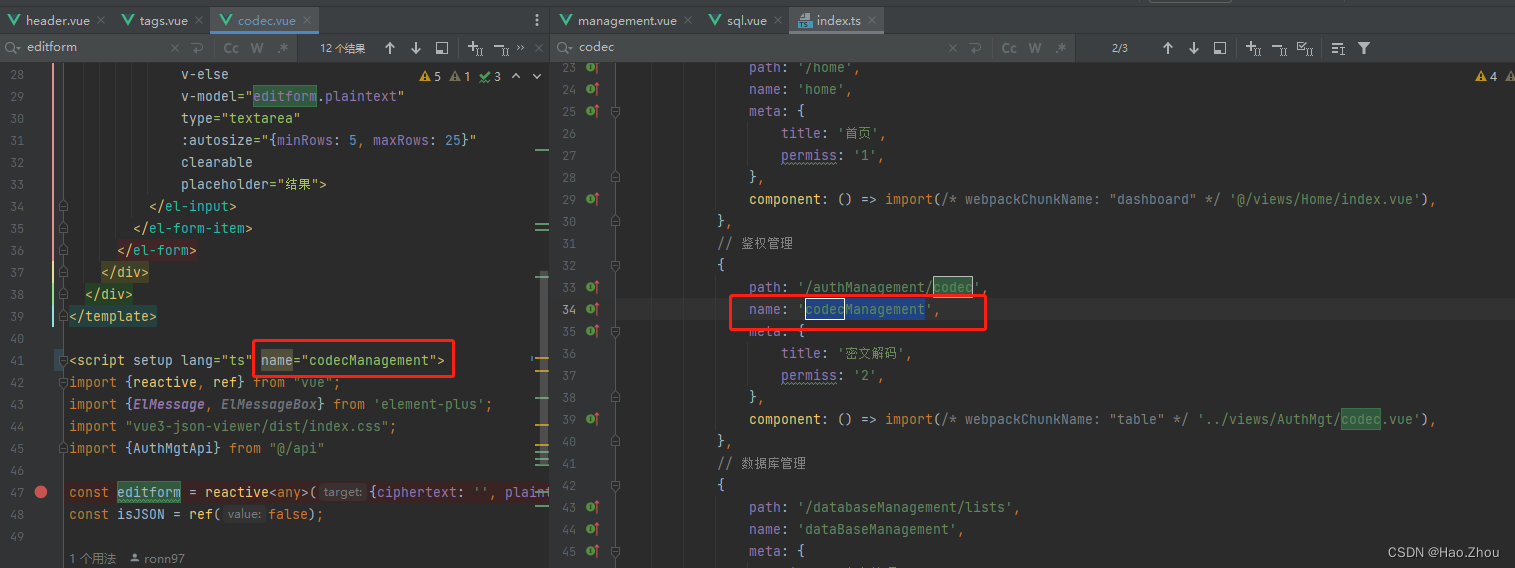
Vue3+element-plus切换标签页时数据保留问题
记录一次切换标签页缓存失效问题,注册路由时name不一致可能会导致缓存失效...

前端教程-TypeScript
官网 TypeScript官网 TypeScript中文官网 视频教程 尚硅谷TypeScript教程(李立超老师TS新课)...
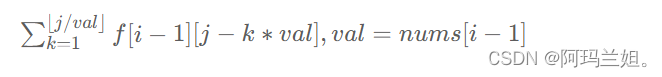
代码随想录算法训练营 动态规划part06
一、完全背包 卡哥的总结,还挺全代码随想录 (programmercarl.com) 二、零钱兑换 II 518. 零钱兑换 II - 力扣(LeetCode) 被选物品之间不需要满足特定关系,只需要选择物品,以达到「全局最优」或者「特定状态」即可。 …...

能跑通的mmdet3d版本
能跑通的mmdet3d版本 1.0版本 2.0版本 注意:mmdet和mmdet3d简单地运行 pip install -v -e . 将会安装最低运行要求的版本。不要pip install -r requirements.txt安装依赖项,否则依赖库版本不对。 运行mmdet3d时,注释掉以上代码。...
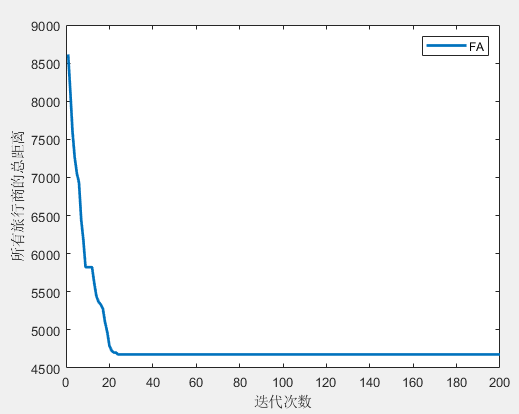
SD-MTSP:萤火虫算法(FA)求解单仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点)
一、萤火虫算法(FA)简介 萤火虫算法(Firefly Algorithm,FA)是Yang等人于2009年提出的一种仿生优化算法。 参考文献:田梦楚, 薄煜明, 陈志敏, et al. 萤火虫算法智能优化粒子滤波[J]. 自动化学报, 2016, 42(001):89-97. 二、单仓…...
bootstrapv4轮播图去除两侧阴影及线框的方法
文章目录 前言一、前提条件:二、bootstrap文档组件展示与实际应用1.官方文档展示如下:没有阴影2.实际应用情况如下: 三、解决方案 前言 这篇文章主要介绍了bootstrapv4轮播图去除两侧阴影及线框的方法,本文通过示例代码给大家介绍的非常详细…...

python 自建kafka消息生成和消费小工具
要将 Kafka 的消息生产和消费转换为 API 接口,我们可以使用 Python 的 Web 框架。其中 Flask 是一个轻量级且易于使用的选择。下面是一个简单的例子,使用 Flask 创建 API 来生成和消费 Kafka 消息。 1. 安装所需的库: pip install kafka-py…...

Prim算法:经过图中所有节点的最短路径
题目链接:53. 寻宝(第七期模拟笔试) #include<bits/stdc.h> using namespace std;// v为节点数量,e为边数量 int v, e;// 最小生成树 void prim(vector<vector<int>>& adj) {vector<int> dist(v1, I…...
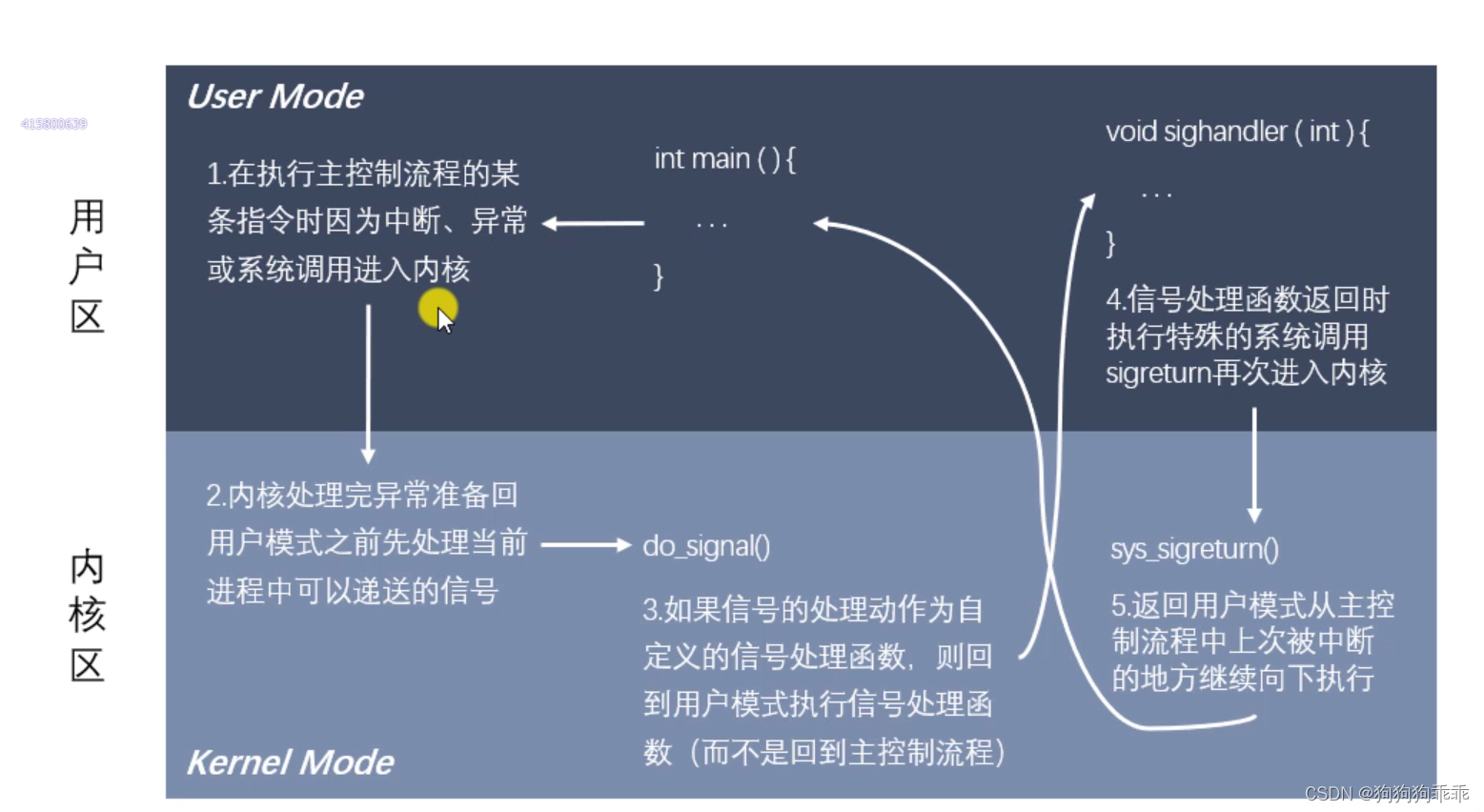
Linux 信号捕捉函数 signal sigaction
signal函数 #include <signal.h> typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); 功能:设置某个信号的捕捉行为 参数: -signum:要捕捉的信号 handler:对捕捉到的信号怎么处理…...

StarRocks操作笔记
最近在使用starRocks,记录一些临时的操作技巧,防止遗忘。 1. 创建表 CREATE TABLE IF NOT EXISTS ODS.T_TEST( pk_day date, pool_address string, code string comment 唯一主键, test1 string, test2 string, test3 string, pk_year varchar(4), pk_m…...

Linux的ls -ld命令产生的信息怎么看
2023年9月24日,周日上午 目录 ls -ld列出的目录或文件的信息含义文件硬链接什么是文件硬链接为什么新建目录的文件硬链接为2举例说明例一例二例三 ls -ld列出的目录或文件的信息含义 第一个字符表示文件类型: d: 目录 -: 普通文件 l: 软链接 b: 块设备文件 c:…...
)
Linux- 内存映射文件(Memory-Mapped File)
内存映射文件(Memory-Mapped File)是⼀种将文件内容映射到内存中的机制,允许程序直接访问文件数据,就好像这些数据已经被加载到了内存⼀样。这个机制允许文件的内容被映射到⼀个进程的地址空间,从而允许程序以⼀种更高…...
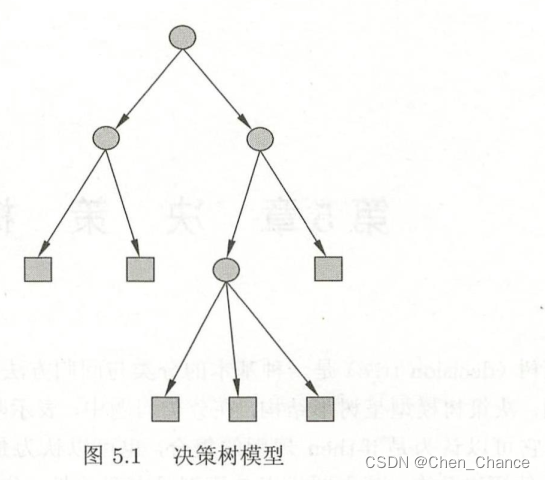
李航老师《统计学习方法》第五章阅读笔记
决策树(decision tree)是一种基本的分类与回归方法。本章主要讨论用于分类的决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。 以下是关于分类决策树的一些基本概念和特点: 树形结构&am…...

iOS16新特性:实时活动-在锁屏界面实时更新APP消息 | 京东云技术团队
简介 之前在 《iOS16新特性:灵动岛适配开发与到家业务场景结合的探索实践》 里介绍了iOS16新的特性:实时更新(Live Activity)中灵动岛的适配流程,但其实除了灵动岛的展示样式,Live Activity还有一种非常实用的应用场景…...
使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索
在本教程中,我将引导您使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。 LangChain 是这个领域的新酷孩子。 它是一个旨在帮助你与大型语言模型 (LLM) 交互的库。 LangChain 简化了与 LLMs 相关的许多日常任务,例如从文档中提取文本…...
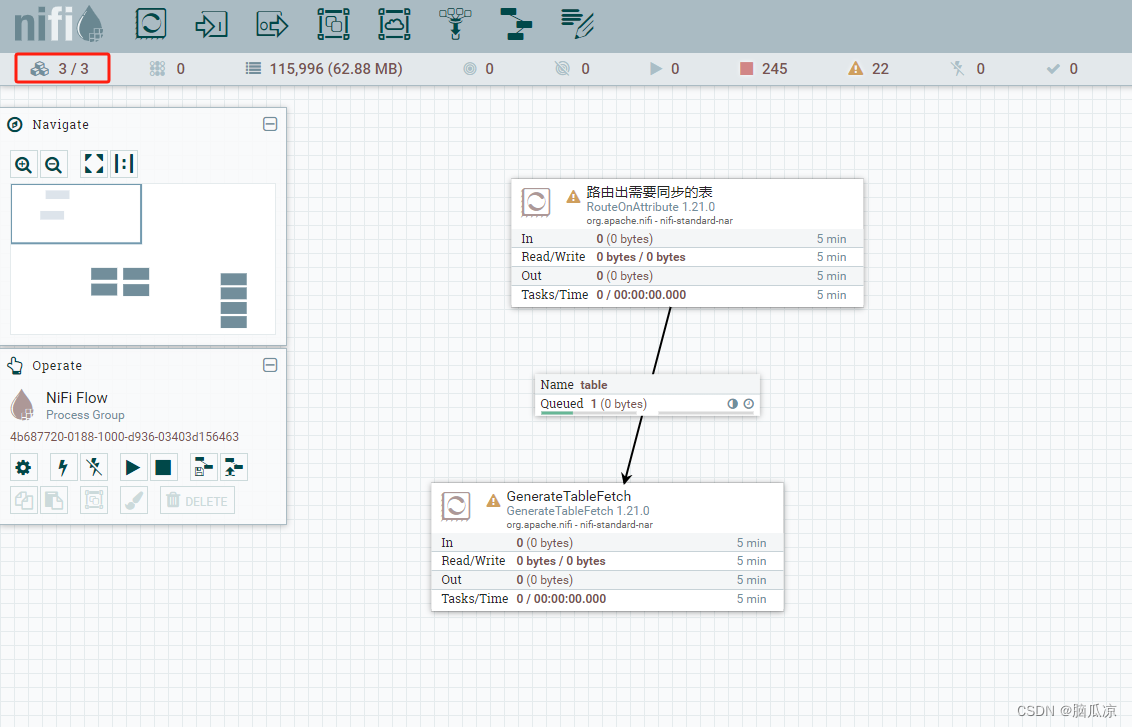
NIFI集群_队列Queue中数据无法清空_清除队列数据报错_无法删除queue_解决_集群中机器交替重启删除---大数据之Nifi工作笔记0061
今天发现,有两个处理器,启动以后,数据流不过去,后来,锁定问题在,queue队列上面,因为别的队列都可以通过,右键,empty queue清空,就是 这个队列不行,这个队列无法被删除,至于为什么导致这样的, 猜测是因为之前,流程设计好以后,队列没有设置背压,也没有设置队列中的内容大小和fl…...

leetcode20. 有效的括号 [简单题]
题目 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。每个右括号都有一个对应的相同类型…...

为什么工业 AI 必须引入本体论?
如果你只用大语言模型(LLM)写周报、画插图、做视频,你只需要关心它聪不聪明。但如果你要用它去设计一座造价上亿的芯片工厂、去控制百万集群算力中心的液冷系统。你就必须回答:AI 凭什么保证绝对不出错?大模型的数学本…...

基于Multisim的FM接收机中频点优化与正交鉴频器性能验证
1. FM接收机中频点优化设计实战 第一次用Multisim调FM接收机时,我被中频点漂移问题折磨得够呛。当时示波器上的波形就像喝醉了一样左右摇摆,根本抓不住稳定的10.7MHz信号。后来发现,中频点优化其实是个系统工程,需要从混频、滤波…...

拓朋N86车载台:畜牧运输的隐形守护者
在广袤无垠的畜牧运输途中,牲畜的安全监控与车队间的协同调度是每位运输人员最为关心的两大要素。在这片充满不确定性的长途路线上,拓朋N86公网集群车载台以其出色的性能,悄然成为了畜牧运输的隐形守护者。 全国覆盖,沟通无阻 畜牧…...

OZON平台选品指南:揭秘俄罗斯市场的潜力品牌与爆款趋势
对于跨境电商卖家而言,俄罗斯市场正成为一片充满机遇的蓝海。作为俄罗斯本土最大的综合电商平台,OZON的用户规模和消费潜力持续增长。然而,机遇往往伴随着挑战,如何在庞大的商品海洋中精准捕捉爆款,规避风险࿰…...

【花雕动手做】ESP32-S3 + MimiClaw 实战:通过飞书自然语言指令控制板载 WS2812 彩灯
【花雕动手做】嵌入式 AI Agent 实战:MimiClaw ESP32-S3 接入飞书,远程控制板载 RGB 全彩灯效 ——从源码修改到飞书指令,手把手打造一个能“听懂颜色话”的嵌入式 AI 智能体 一、引言:当“养龙虾”热潮遇到嵌入式 AI 2026 年开春…...

SVG-Morpheus实战教程:10个实用技巧打造惊艳UI动画
SVG-Morpheus实战教程:10个实用技巧打造惊艳UI动画 【免费下载链接】SVG-Morpheus JavaScript library enabling SVG icons to morph from one to the other. It implements Material Designs Delightful Details transitions. (THIS PROJECT IS NOT MAINTAINED ANY…...

避坑指南:ROS2+PCL+LOAM建图定位中,点云格式、体素滤波与G2O链接的那些坑
ROS2PCLLOAM实战避坑指南:从点云处理到精准定位的完整解决方案 在机器人自主导航领域,激光SLAM技术凭借其高精度和稳定性成为工业级应用的首选方案。本文将深入剖析ROS2环境下基于PCL和LOAM的建图定位全流程,针对开发者实际遇到的12类典型问…...

Java8时间魔法:Duration与Period实战,精准掌控时间与日期间隔
1. Duration与Period:Java8的时间魔法棒 第一次接触Java8的日期时间API时,我被LocalDate和LocalDateTime的简洁惊艳到了。但真正让我感受到时间魔法魅力的,是在处理两个时间点间隔时遇到的Duration和Period。记得有次做会员系统,…...

从零到一:手把手教你用TruckSim搭建你的第一辆虚拟牵引车模型
从零到一:手把手教你用TruckSim搭建你的第一辆虚拟牵引车模型 第一次打开TruckSim时,面对密密麻麻的参数和复杂的界面,很多新手会感到无从下手。作为一款专业的商用车动力学仿真软件,TruckSim确实有一定的学习门槛,但掌…...

【V2X】高通平台EMMC复位机制
错误类型 检测函数 返回值 恢复动作 是否会继续升级到 reset/power-cycle 命令 CRC / End Bit / Index 错误 sdhci_cmd_irq() -EILSEQ 结束当前 request;sdhci_needs_reset() 置位后执行 sdhci_do_reset(SDHCI_RESET_CMD/DATA);mmc_request_done() 标记 mmc_retune_needed();…...