使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索
在本教程中,我将引导您使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。
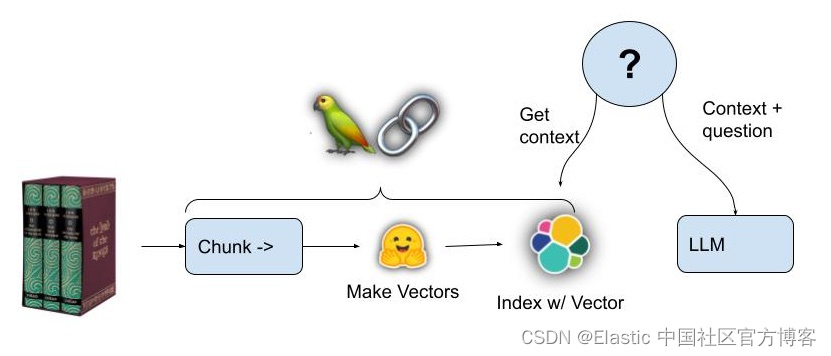
LangChain 是这个领域的新酷孩子。 它是一个旨在帮助你与大型语言模型 (LLM) 交互的库。 LangChain 简化了与 LLMs 相关的许多日常任务,例如从文档中提取文本或在向量数据库中对它们建立索引。 如果你现在正在与 LLMs 一起工作,LangChain 可以节省你的工作时间。
然而,它的一个缺点是,尽管它的文档很广泛,但可能比较分散,对于新手来说很难理解。 此外,大多数在线内容都集中在最新一代的向量数据库上。 由于许多组织仍在使用 Elasticsearch 这样经过实战考验的技术,我决定使用它编写一个教程。
我将 LangChain 和 Elasticsearch 结合到了最常见的 LLM 应用之一:语义搜索。 在本教程中,我将引导你使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。 你将创建一个应用程序,让用户可以提出有关马可·奥勒留《沉思录》的问题,并通过从书中提取最相关的内容为他们提供简洁的答案。
让我们深入了解吧!
前提条件
你应该熟悉这些主题才能充分利用本教程:
-
Elasticsearch:语义搜索、知识图和向量数据库概述
-
Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x
此外,你必须安装 Docker 并在 OpenAI 上创建一个帐户。
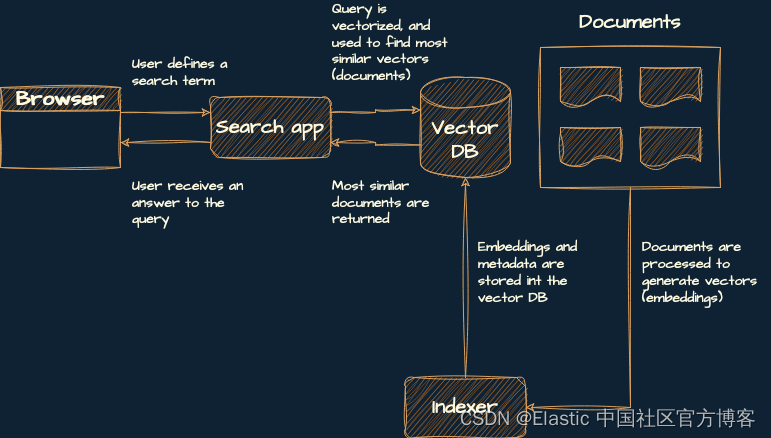
设计语义搜索服务
你将构建一个包含三个组件的服务:
- 索引器:这将创建索引,生成嵌入和元数据(在本例中为书籍的来源和标题),并将它们添加到向量数据库中。
- 矢量数据库:这是一个用于存储和检索生成的嵌入的数据库。
- 搜索应用程序:这是一个后端服务,它使用用户的搜索词,从中生成嵌入,然后在矢量数据库中查找最相似的嵌入。
这是该架构的示意图:
接下来,你将设置本地环境。
设置你的本地环境
请按照以下步骤设置您的本地环境:
1)安装 Python 3.10。
2)安装 Poetry。 它是可选的,但强烈推荐。
sudo pip install poetry
3) 克隆项目的存储库:
git clone https://github.com/liu-xiao-guo/semantic-search-elasticsearch-openai-langchain4)从项目的根文件夹中,安装依赖项:
- 使用 Poetry:在项目同目录下创建虚拟环境并安装依赖:
poetry config virtualenvs.in-project true
poetry install- 使用 venv 和 pip:创建虚拟环境并安装 requirements.txt 中列出的依赖项:
python3.10 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt5)打开 src/.env-example,添加你的 OpenAI 密钥,并将文件另存为 .env。
(.venv) $ pwd
/Users/liuxg/python/semantic-search-elasticsearch-openai-langchain/src
(.venv) $ ls -al
total 32
drwxr-xr-x 7 liuxg staff 224 Sep 17 17:27 .
drwxr-xr-x 13 liuxg staff 416 Sep 17 21:23 ..
-rw-r--r-- 1 liuxg staff 41 Sep 17 17:27 .env-example
-rw-r--r-- 1 liuxg staff 870 Sep 17 17:27 app.py
-rw-r--r-- 1 liuxg staff 384 Sep 17 17:27 config.py
drwxr-xr-x 3 liuxg staff 96 Sep 17 17:27 data
-rw-r--r-- 1 liuxg staff 840 Sep 17 17:27 indexer.py
(.venv) $ mv .env-example .env
(.venv) $ vi .env到目前为止,你将设置一个包含所需库和存储库的本地副本的虚拟环境。 你的项目结构应该如下所示:
.
├── LICENSE
├── README.md
├── docker-compose.yml
├── .env
├── poetry.lock
├── pyproject.toml
├── requirements.txt
└── src├── app.py├── config.py├── .env├── .env-example ├── data│ └── Marcus_Aurelius_Antoninus_-_His_Meditations_concerning_himselfe└── indexer.py
请注意:在上面的文件结构中,有两个 .env 文件。根目录下的 .env 文件是为 docker-compose.yml 文件所使用,而 src 目录里的文件是为应用所示使用。我们可以在根目录里的 .env 文件中定义想要的 Elastic Stack 版本号。
这些是项目中最相关的文件和目录:
- poetry.lock 和 pyproject.toml:这些文件包含项目的规范和依赖项,被 Poetry 用来创建虚拟环境。
- requirements.txt:该文件包含项目所需的 Python 包列表。
- docker-compose.yml:此文件包含用于在本地运行 Elasticsearch 集群及 Kibana。
- src/app.py:该文件包含搜索应用程序的代码。
- src/config.py:此文件包含项目配置规范,例如 OpenAI 的 API 密钥(从 .env 文件读取)、数据路径和索引名称。
- src/data/:该目录包含最初从维基文库下载的 Meditations 。 你将使用它作为本教程的文本语料库。
- src/indexer.py:此文件包含用于创建索引并将文档插入 Elasticsearch 的代码。
- .env-example:此文件通常用于环境变量。 在本例中,你可以使用它将 OpenAI 的 API 密钥传递给您的应用程序。
- .venv/:该目录包含项目的虚拟环境。
全做完了! 我们继续向下进行吧。
启动本地 Elasticsearch 集群
在我们进入代码之前,你应该启动一个本地 Elasticsearch 集群。 打开一个新终端,导航到项目的根文件夹,然后运行:
docker-compose up
在上面的部署中,出于方便,我们使用了没有带安全的 Elastic Stack 的安装以方便进行开发。具体的安装步骤,请参阅另外一篇文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。如果一切顺利,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2866c0356a2 kibana:8.9.2 "/bin/tini -- /usr/l…" 4 minutes ago Up 4 minutes 0.0.0.0:5601->5601/tcp kibana
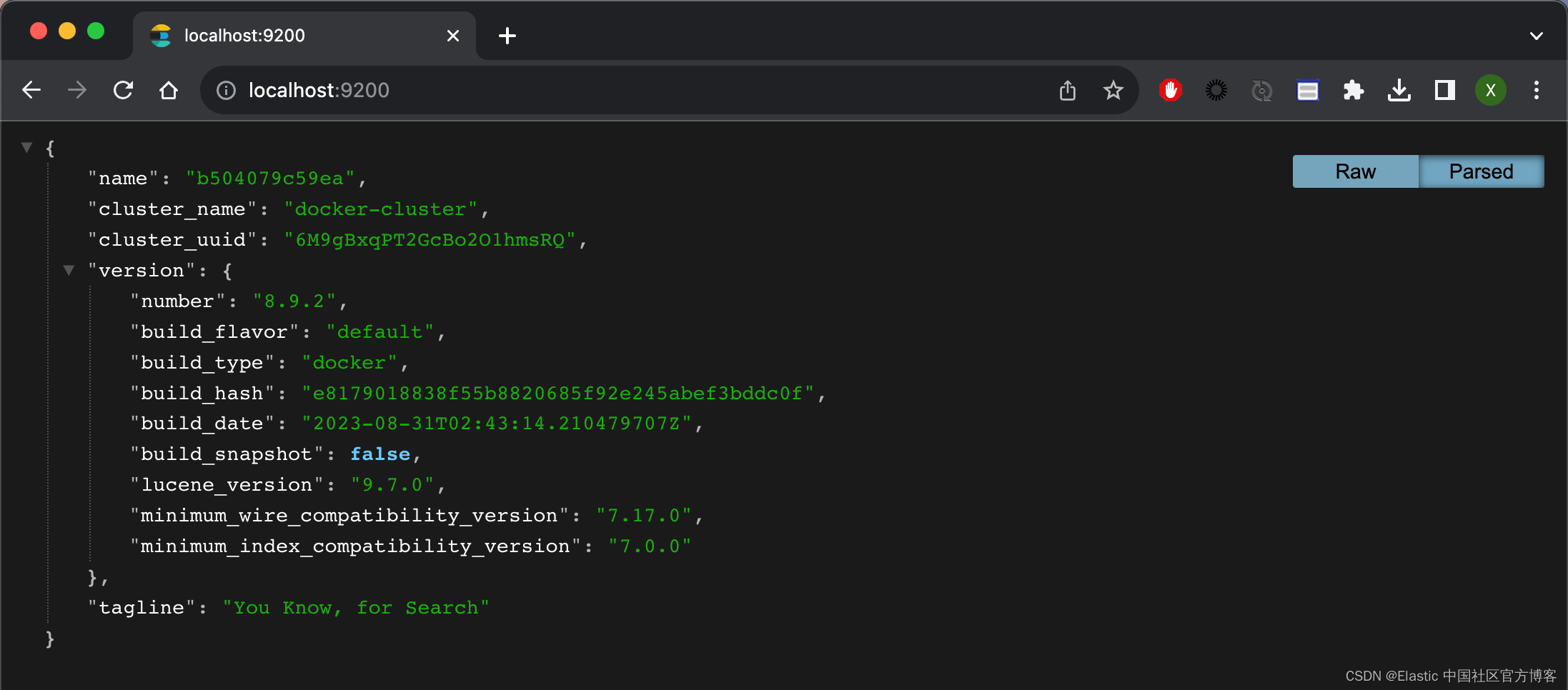
b504079c59ea elasticsearch:8.9.2 "/bin/tini -- /usr/l…" 4 minutes ago Up 4 minutes 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch我们可以在浏览器中针对 Elasticsearch 进行访问:
我们还可以在 localhost:5601 上访问 Kibana:
拆分书籍并为其建立索引


在此步骤中,你将执行两件事:
- 通过将书中的文本拆分为 1,000 个 token 的块来处理该文本。
- 对你在 Elasticsearch 集群中生成的文本块(从现在开始称为文档)建立索引。
看一下 src/indexer.py:
from langchain.document_loaders import BSHTMLLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import ElasticVectorSearchfrom config import Paths, openai_api_keydef main():loader = BSHTMLLoader(str(Paths.book))data = loader.load()text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)documents = text_splitter.split_documents(data)embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)db = ElasticVectorSearch.from_documents(documents,embeddings,elasticsearch_url="http://localhost:9200",index_name="elastic-index",)print(db.client.info())if __name__ == "__main__":main()此代码采用 Meditations(书),将其拆分为 1,000 个 token 的文本块,然后在 Elasticsearch 集群中为这些块建立索引。 以下是详细的细分:
- 第 1 行到第 4 行从 langchain 导入所需的组件:
- BSHTMLLoader:此 Loader 使用 BeautifulSoup4 来解析文档。
- OpenAIembeddings:该组件是 OpenAI 嵌入的包装器。 它可以帮助你生成文档和查询的嵌入。
- RecursiveCharacterTextSplitter:此实用程序函数通过尝试按旨在保持语义相似内容邻近的顺序尝试各种字符来分割输入文本。 用于分割的字符按以下顺序排列为:“\n\n”、“\n”、“ ”、“”。
- ElasticSearchVector:这是 Elasticsearch 客户端的包装器,可简化与集群的交互。
- 第 6 行从 config.py 导入相关配置
- 第 11 行和第 12 行使用 BSHTMLLoader 提取书籍的文本。
- 第 13 至 16 行初始化文本拆分器,并将文本拆分为不超过 1,000 个标记的块。 在这种情况下,你可以使用 tiktoken 来计算 token,但你也可以使用不同长度的函数,例如计算字符数而不是 token 或不同的 token 化函数。
- 第 18 至 25 行初始化嵌入函数,创建新索引,并对文本拆分器生成的文档建立索引。 在 elasticsearch_url 中,你指定应用程序在本地运行的端口,在index_name 中指定你将使用的索引的名称。 最后,打印 Elasticsearch 客户端信息。
要运行此脚本,请打开终端,激活虚拟环境,然后从项目的 src 文件夹中运行以下命令:
# ../src/
export export OPENAI_API_KEY=your_open_ai_token
python indexer.py
注意:你如果使用 OpenAI 来进行矢量化,那么你需要在你的账号中有充分的钱来支付这种费用,否则你可能得到如下的错误信息:
Retrying langchain.embeddings.openai.embed_with_retry.<locals>._embed_with_retry in 4.0 seconds as it raised RateLimitError: You exceeded your current quota, please check your plan and billing details..
如果一切顺利,你应该得到与此类似的输出:
{'name': '0e1113eb2915', 'cluster_name': 'docker-cluster', 'cluster_uuid': 'og6mFMqwQtaJiv_3E_q2YQ', 'version': {'number': '8.9.2', 'build_flavor': 'default', 'build_type': 'docker', 'build_hash': '09520b59b6bc1057340b55750186466ea715e30e', 'build_date': '2023-03-27T16:31:09.816451435Z', 'build_snapshot': False, 'lucene_version': '9.5.0', 'minimum_wire_compatibility_version': '7.17.0', 'minimum_index_compatibility_version': '7.0.0'}, 'tagline': 'You Know, for Search'}接下来,让我们创建一个简单的 FastAPI 应用程序,以与你的集群进行交互。
创建搜索应用程序
在此步骤中,你将创建一个简单的应用程序来与 Meditations 交互。 你将连接到 Elasticsearch 集群,始化检索提问/应答 Chain,并创建一个 /ask 端点以允许用户与应用程序交互。
看一下 src/app.py 的代码:
from fastapi import FastAPI
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import ElasticVectorSearchfrom config import openai_api_keyembedding = OpenAIEmbeddings(openai_api_key=openai_api_key)db = ElasticVectorSearch(elasticsearch_url="http://localhost:9200",index_name="elastic-index",embedding=embedding,
)
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0),chain_type="stuff",retriever=db.as_retriever(),
)app = FastAPI()@app.get("/")
def index():return {"message": "Make a post request to /ask to ask questions about Meditations by Marcus Aurelius"}@app.post("/ask")
def ask(query: str):response = qa.run(query)return {"response": response,}
此代码允许用户提出有关马库斯·奥勒留《沉思录》的问题,并向用户提供答案。 让我向你展示它是如何工作的:
- 第 1 至 5 行导入所需的库:
- FastAPI:此类初始化应用程序。
- RetrievalQA:这是一个允许你询问有关向量数据库中文档的问题的 Chain。 它根据你的问题找到最相关的文档并从中生成答案。
- ChatOpenAI:这是 OpenAI 聊天模型的包装。
- OpenAIembeddings 和 ElasticVectorSearch:这些是上一节中讨论的相同包装器。
- 第 7 行导入 OpenAI 密钥。
- 第 9 至 15 行使用 OpenAI 嵌入初始化 Elasticsearch 集群。
- 第 16 至 20 行使用以下参数初始化 RetrievalQA Chain:
- llm:指定用于运行链中定义的提示的 LLM。
- chain_type:定义如何从向量数据库检索和处理文档。 通过指定内容,将检索文档并将其传递到链以按原样回答问题。 或者,你可以在回答问题之前使用 map_reduce 或 map_rerank 进行额外处理,但这些方法使用更多的 API 调用。 有关更多信息,请参阅 langchain 文档。
- retrieve:指定链用于检索文档的向量数据库。
- 第 22 至 36 行初始化 FastAPI 应用程序并定义两个端点。 / 端点为用户提供有关如何使用应用程序的信息。 /ask 端点接受用户的问题(查询参数)并使用先前初始化的链返回答案。
最后,你可以从终端运行该应用程序(使用你的虚拟环境):
uvicorn app:app --reload然后,访问 http://127.0.0.1:8000/docs,并通过询问有关这本书的问题来测试 /ask:

如果一切顺利,你应该得到这样的结果:
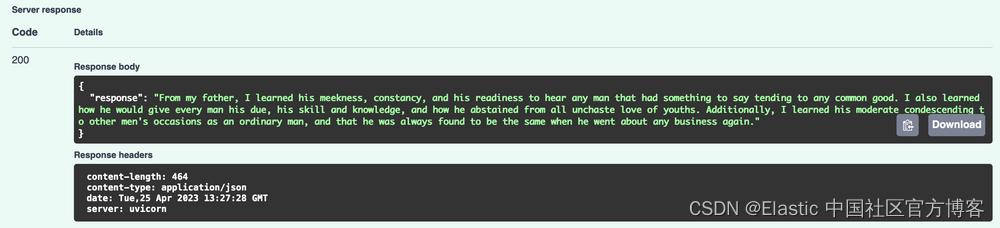
就是这样! 您现在已经启动并运行了自己的基于 Elasticsearch、OpenAI、Langchain 和 FastAPI 的语义搜索服务。
结论
干得好! 在本教程中,你学习了如何使用 Elasticsearch、OpenAI 和 Langchain 构建语义搜索引擎。
特别是,你已经了解到:
- 如何构建语义搜索服务。
- 如何使用 LangChain 对文档进行拆分和索引。
- 如何使用 Elasticsearch 作为向量数据库与 LangChain 一起使用。
- 如何使用检索问答链通过向量数据库回答问题。
- 产品化此类应用程序时应考虑什么。
希望您觉得本教程有用。 如果你有任何疑问,请参入讨论!
相关文章:
使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索
在本教程中,我将引导您使用 Elasticsearch、OpenAI、LangChain 和 FastAPI 构建语义搜索服务。 LangChain 是这个领域的新酷孩子。 它是一个旨在帮助你与大型语言模型 (LLM) 交互的库。 LangChain 简化了与 LLMs 相关的许多日常任务,例如从文档中提取文本…...
NIFI集群_队列Queue中数据无法清空_清除队列数据报错_无法删除queue_解决_集群中机器交替重启删除---大数据之Nifi工作笔记0061
今天发现,有两个处理器,启动以后,数据流不过去,后来,锁定问题在,queue队列上面,因为别的队列都可以通过,右键,empty queue清空,就是 这个队列不行,这个队列无法被删除,至于为什么导致这样的, 猜测是因为之前,流程设计好以后,队列没有设置背压,也没有设置队列中的内容大小和fl…...

leetcode20. 有效的括号 [简单题]
题目 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。每个右括号都有一个对应的相同类型…...

ubuntu20.04下源码编译colmap
由于稠密重建需要CUDA,因此先安装CUDA,我使用的是3050GPU,nvidia-smi显示最高支持CUDA11.4。 不要用sudo apt安装,版本较低,30系显卡建议安装CUDA11.0以上,这里安装了11.1版本。 下载: cuda_1…...
Jumpserver堡垒机
一、堡垒机概述 1、堡垒机的基本概念 堡垒机也是一台服务器,在一个特定的网络环境下,为了保障网络和数据不受来自外部和内部用户的入侵和破坏,而运用各种技术手段实时收集、监控网络环境中每一个组成部分(服务器)的系…...

第一百五十三回 如何实现滑动窗口
文章目录 概念介绍实现方法示例代码 我们在上一章回中介绍了自定义组件实现游戏摇杆相关的内容,本章回中将介绍 如何实现滑动窗口.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在本章回中介绍的滑动窗口表示在屏幕底部向上滑动时弹出一个窗口&a…...

Oracle 12c自动化管理特性的新进展:自动备份、自动恢复和自动维护功能的优势|oracle 12c相对oralce 11g的新特性(3)
一、前言: 前面几期讲解了oracle 12c多租户的使用、In-Memory列存储来提高查询性能以及数据库的克隆、全局数据字典和共享数据库资源的使用 今天我们讲讲oracle 12c的另外的一个自动化管理功能新特性:自动备份、自动恢复、自动维护的功能 二、自动备份、自动恢复、自动维护…...

Redis——Jedis中hash类型使用
hset 和 hget hset可以逐一添加key和value,也可以通过map类型来直接添加多组fields 而hget则返回string类型,如果元素不存在则返回null private static void hsetAndHget(Jedis jedis) {jedis.flushAll();jedis.hset("key", "f1"…...
肖sir__项目实战讲解__004
项目实战讲解 一、项目的类型 金融类: 保险(健康险理财险)、证券、基金(股票型基金、混合型基金、指数型基金、债券型基金、 天天基金网(ETF基金、货币型基金、量化基金)、银行、贷款、信用卡、外汇、二元期权、期货原油、blockchain、 数字货币、黄金白…...

数据库数据恢复-ORACLE常见故障有哪些?恢复数据的可能性高吗?
ORACLE数据库常见故障: 1、ORACLE数据库无法启动或无法正常工作。 2、ORACLE数据库ASM存储破坏。 3、ORACLE数据库数据文件丢失。 4、ORACLE数据库数据文件部分损坏。 5、ORACLE数据库DUMP文件损坏。 ORACLE数据库数据恢复可能性分析: 1、ORACLE数据库无…...

合规性管理如何帮助产品团队按时交付?
成功的产品和产品发布背后通常需要经过一个涉及多个监督机构、多功能团队和利益相关者的复杂流程。在组织的治理、风险管理和合规性(GRC)框架下,产品团队不仅需要追求市场创新,还需要确保符合所有适用的法规、标准和合同要求。由于…...
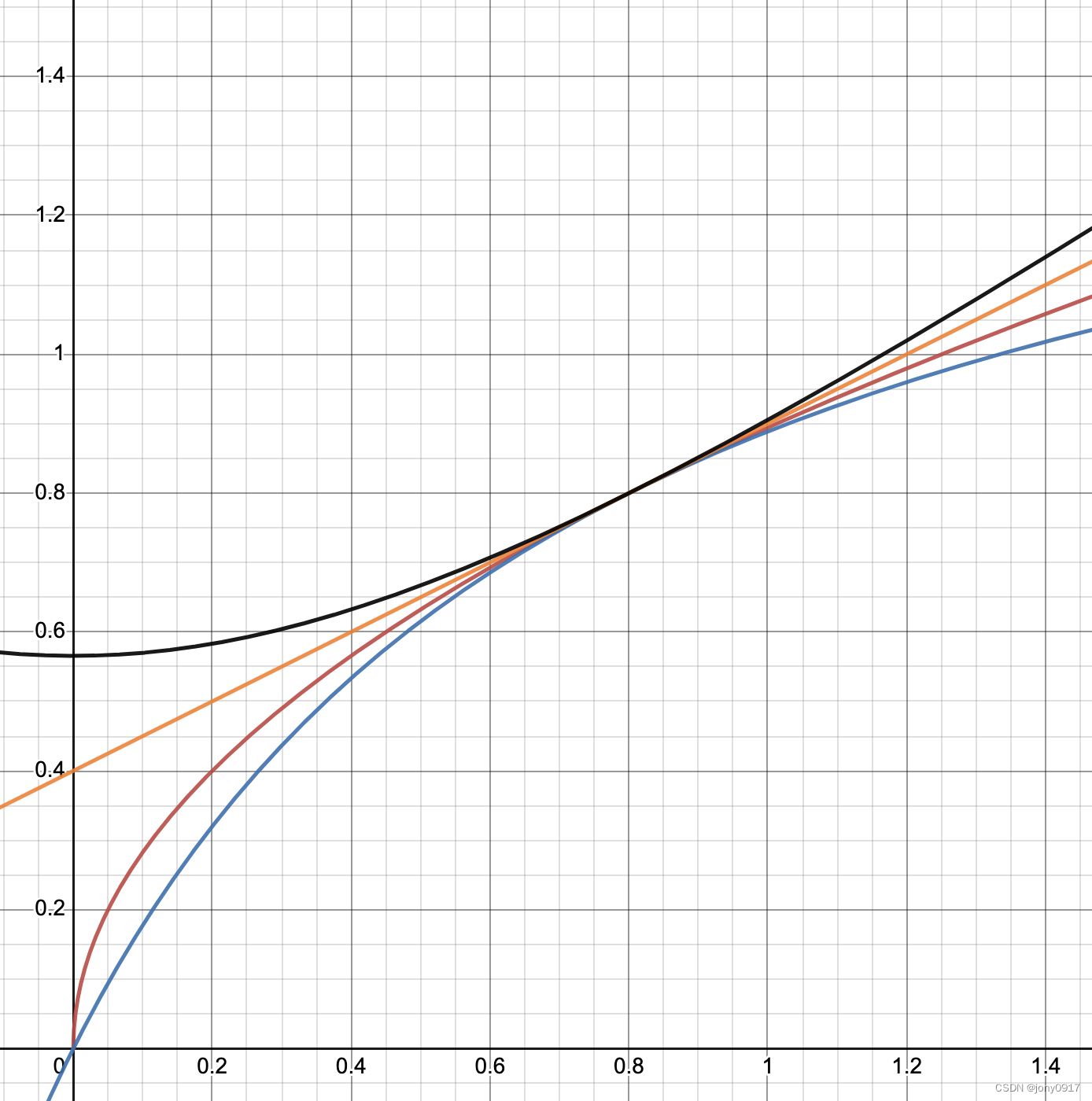
从平均数到排名算法
平均数用更少的数字,概括一组数字。属于概述统计量、集中趋势测度、位置测度。中位数是第二常见的概述统计量。许多情况下比均值更合适。算术平均数是3中毕达哥拉斯平均数之一,另外两种毕达哥拉斯平均数是几何平均数和调和平均数。 算术平均 A M 1 n ∑…...

如何使用ESP8266微控制器和Nextion显示器为Home Assistant展示温度传感器和互联网天气预报
第一部分:引言与项目概述 在智能家居领域,实时监控和显示环境数据已经成为了一个热门的话题。无论是室内温度、室外温度,还是游泳池的温度,都可以通过各种传感器轻松获取。但如何将这些数据以直观、美观的方式展现出来呢…...
阻塞队列-生产者消费者模型
阻塞队列介绍标准库阻塞队列使用基于阻塞队列的简单生产者消费者模型。实现一个简单型阻塞队列 (基于数组实现) 阻塞队列介绍 不要和之前学多线程的就绪队列搞混; 阻塞队列:也是一个队列,先进先出。带有特殊的功能 &…...

Vector Art - 矢量艺术
什么是矢量艺术? 矢量图形允许创意人员构建高质量的艺术作品,具有干净的线条和形状,可以缩放到任何大小。探索这种文件格式如何为各种规模的项目提供创造性的机会。 什么是矢量艺术作品? 矢量艺术是由矢量图形组成的艺术。这些图形是基于…...
)
ruoyi-nbcio增加flowable流程待办消息的提醒,并提供右上角的红字数字提醒(一)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 1、数据库表方面 在原来sys_notice修改基础上增加一个表叫sys_notice_send 表结构如下: DROP …...
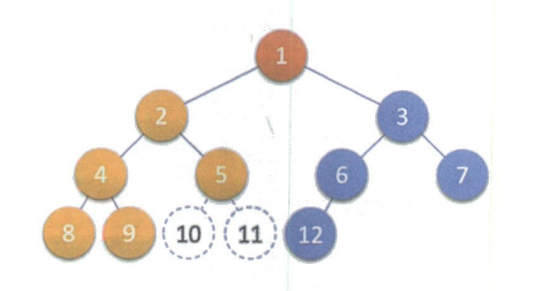
数据结构:二叉树的基本概念
文章目录 1. 二叉树的定义2. 二叉树的特点3. 特殊二叉树斜树满二叉树完全二叉树 4. 二叉树的性质 1. 二叉树的定义 如果我们猜一个100以内的数字,该怎么猜才能理论最快呢? 第一种方式:从1,2一直猜到100, 反正数字都是100以内,总能猜到的 第二种方式:先猜50,如果比结果小,猜75…...

利用Socks5代理IP加强跨界电商爬虫的网络安全
随着跨界电商的兴起,爬虫技术在这个领域变得越来越重要。然而,网络安全一直是一个值得关注的问题。在本文中,我们将讨论如何利用代理IP和Socks5代理来增强跨界电商爬虫的网络安全,确保稳定和可靠的数据采集,同时避免封…...
Spring学习笔记6 Bean的实例化方式
Spring学习笔记5 GoF之工厂模式_biubiubiu0706的博客-CSDN博客 Spring为Bean提供了多种实例化方式,通常包括4中(目的:更加灵活) 1.通过构造方法实例化 2.通过简单工厂模式实例化 3.通过factory-bean实例化 4.通过FactoryBean接口实例化 新建模块 spring-005 依赖 <!--S…...

大二毕设.3-网盘系统-用户模块讲解
目录 模块功能介绍 具体实现讲解 constants层:存放用户模块常量类 entity层:存放实体类,与数据库中的属性值基本保持一致 mapper层:对数据库进行数据持久化操作 service层:业务逻辑层,主要是针对具体…...

Windows下OpenClaw安装详解:千问3.5-9B接口配置全流程
Windows下OpenClaw安装详解:千问3.5-9B接口配置全流程 1. 为什么选择OpenClaw千问3.5-9B组合 去年我在尝试自动化办公流程时,发现市面上的RPA工具要么太笨重,要么需要频繁上传数据到云端。直到遇到OpenClaw这个开源的本地化AI智能体框架&am…...

嵌入式Linux无线服务器搭建指南
1. 项目概述在嵌入式Linux开发中,传统的有线网络连接方式往往限制了设备的灵活性和部署便捷性。作为一名嵌入式开发者,我最近成功在S3C2410开发板上实现了基于WiFi模块的无线服务器搭建,彻底摆脱了网线的束缚。这套方案不仅适用于智能家居控制…...

SEO_如何通过内容SEO有效获取精准流量?
如何通过内容SEO有效获取精准流量? 在互联网时代,获取精准流量是每个网站和博客主人的首要目标之一。通过内容SEO,我们可以有效地提高网站在搜索引擎上的排名,吸引更多的访客。如何通过内容SEO有效获取精准流量呢?本文…...

告别重复劳动:用快马平台智能整合opencode,打造专属效率工具库
作为一名经常需要处理各种数据格式和工具函数的开发者,我最近发现了一个能显著提升开发效率的方法——利用InsCode(快马)平台快速生成可复用的工具库。今天就来分享下如何用这个平台智能整合opencode资源,打造自己的JavaScript效率工具库。 为什么需要工…...

数字孪生简介
数字孪生简介摘要数字孪生(Digital Twin)作为连接物理世界与数字世界的核心技术,正在重塑全球产业格局。本报告系统梳理了数字孪生技术的概念演进、技术架构、行业应用及发展趋势,深入分析了其在智能制造、航空航天、智慧城市、医…...

2026届学术党必备的十大降重复率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,各种各样的降AI工具纷纷出现,其关键功能是借助文本改写、句式重…...

指针精要:从入门到精通,嵌入式开发学习日志32——stm32之PWM。
指针的基本概念 指针是编程中用于存储内存地址的变量,它指向另一个变量的位置。通过指针可以直接访问或修改内存中的数据,提升程序的灵活性和效率。 在C/C中,指针的声明方式为: int *ptr; // 声明一个整型指针指针的类型决定了…...

随堂笔记0403
负载监控计算机核心资源:CPU: 计算(lscpu)内存: 缓存数据(掉电丢失)硬盘: 持久化存储数据网络: 传播数据[rootCentos01 wyj]# lscpuCPU(s): 2型号名称&am…...

OpenClaw学术写作助手:Kimi-VL-A3B-Thinking自动生成论文图表说明
OpenClaw学术写作助手:Kimi-VL-A3B-Thinking自动生成论文图表说明 1. 为什么需要自动化论文图表说明 写论文最痛苦的时刻之一,就是整理完数据图表后,还要绞尽脑汁写出专业又准确的说明文字。去年我完成硕士论文时,光是图表说明就…...

002、环境搭建:Python虚拟环境、LangChain安装与核心依赖解析
002、环境搭建:Python虚拟环境、LangChain安装与核心依赖解析从一次深夜调试说起 上周三凌晨两点,我被一个诡异的错误钉在屏幕前:明明本地测试通过的LangChain智能体,在同事的机器上死活跑不起来。报错信息指向一个版本冲突——py…...