Java基础常考知识点(基础、集合、异常、JVM)
作者:
逍遥Sean
简介:一个主修Java的Web网站\游戏服务器后端开发者
主页:https://blog.csdn.net/Ureliable
觉得博主文章不错的话,可以三连支持一下~ 如有需要我的支持,请私信或评论留言!
Java基础常考知识点
- 基础
- JDK、JRE、JVM之间的区别
- hashCode()与equals()之间的关系
- String、StringBuffer、StringBuilder的区别
- 泛型中extends和super的区别
- ==和equals⽅法的区别
- 重载和重写的区别
- 深拷⻉和浅拷⻉
- 什么是字节码?采⽤字节码的好处是什么?
- Java中有哪些类加载器
- 说说类加载器双亲委派模型
- 集合
- List和Set的区别
- ArrayList和LinkedList区别
- 谈谈ConcurrentHashMap的扩容机制
- Jdk1.7到Jdk1.8 HashMap 发⽣了什么变化(底层)?
- 说⼀下HashMap的Put⽅法
- HashMap的扩容机制原理
- CopyOnWriteArrayList的底层原理是怎样的
- 异常
- Java中的异常体系是怎样的
- 在Java的异常处理机制中,什么时候应该抛出异常,什么时候捕获异常?
- JVM
- JVM中哪些是线程共享区
- 项⽬如何排查JVM问题
- ⼀个对象从加载到JVM,再到被GC清除,都经历了什么过程?
- 怎么确定⼀个对象到底是不是垃圾?
- JVM有哪些垃圾回收算法?
- 什么是STW?
本文收集Java核心的面试常考知识点,码起面试之前复习!!!
基础
JDK、JRE、JVM之间的区别
JDK(Java SE Development Kit),Java标准开发包,它提供了编译、运⾏Java程序所需的各种⼯具和资源,包括Java编译器、Java运⾏时环境,以及常⽤的Java类库等JRE( Java Runtime Environment),Java运⾏环境,⽤于运⾏Java的字节码⽂件。JRE中包括了JVM以及JVM⼯作所需要的类库,普通⽤户⽽只需要安装JRE来运⾏Java程序,⽽程序开发者必须安装JDK来编译、调试程序。JVM(Java Virtual Mechinal),Java虚拟机,是JRE的⼀部分,它是整个java实现跨平台的最核⼼的部分,负责运⾏字节码⽂件。
我们写Java代码,⽤txt就可以写,但是写出来的Java代码,想要运⾏,需要先编译成字节码,那就需要编译器,⽽JDK中就包含了编译器javac,编译之后的字节码,想要运⾏,就需要⼀个可以执⾏字节码的程序,这个程序就是JVM(Java虚拟机),专⻔⽤来执⾏Java字节码的。
如果我们要开发Java程序,那就需要JDK,因为要编译Java源⽂件。
如果我们只想运⾏已经编译好的Java字节码⽂件,也就是*.class⽂件,那么就只需要JRE。JDK中包含了JRE,JRE中包含了JVM。
另外,JVM在执⾏Java字节码时,需要把字节码解释为机器指令,⽽不同操作系统的机器指令是有可能不⼀样的,所以就导致不同操作系统上的JVM是不⼀样的,所以我们在安装JDK时需要选择操作系统。另外,JVM是⽤来执⾏Java字节码的,所以凡是某个代码编译之后是Java字节码,那就都能在JVM上运⾏,⽐如Apache Groovy, Scala and Kotlin 等等。
hashCode()与equals()之间的关系
在Java中,每个对象都可以调⽤⾃⼰的hashCode()⽅法得到⾃⼰的哈希值(hashCode),相当于对象的指纹信息,通常来说世界上没有完全相同的两个指纹,但是在Java中做不到这么绝对,但是我们仍然可以利⽤hashCode来做⼀些提前的判断,⽐如:
- 如果两个对象的hashCode不相同,那么这两个对象肯定不同的两个对象
- 如果两个对象的hashCode相同,不代表这两个对象⼀定是同⼀个对象,也可能是两个对象
- 如果两个对象相等,那么他们的hashCode就⼀定相同
在Java的⼀些集合类的实现中,在⽐较两个对象是否相等时,会根据上⾯的原则,会先调⽤对象的hashCode()⽅法得到hashCode进⾏⽐较,如果hashCode不相同,就可以直接认为这两个对象不相同,如果hashCode相同,那么就会进⼀步调⽤equals()⽅法进⾏⽐较。⽽equals()⽅法,就是⽤来最终确定两个对象是不是相等的,通常equals⽅法的实现会⽐较重,逻辑⽐较多,⽽hashCode()主要就是得到⼀个哈希值,实际上就⼀个数字,相对⽽⾔⽐较轻,所以在⽐较两个对象时,通常都会先根据hashCode想⽐较⼀下。
所以我们就需要注意,如果我们重写了equals()⽅法,那么就要注意hashCode()⽅法,⼀定要保证能遵守上述规则。
String、StringBuffer、StringBuilder的区别
- String是不可变的,如果尝试去修改,会新⽣成⼀个字符串对象,StringBuffer和StringBuilder是可变的
- StringBuffer是线程安全的,StringBuilder是线程不安全的,所以在单线程环境下StringBuilder效率会更⾼
泛型中extends和super的区别
- <? extends T>表示包括T在内的任何T的⼦类
- <? super T>表示包括T在内的任何T的⽗类
==和equals⽅法的区别
- ==:如果是基本数据类型,⽐较是值,如果是引⽤类型,⽐较的是引⽤地址
- equals:具体看各个类重写equals⽅法之后的⽐较逻辑,⽐如String类,虽然是引⽤类型,但是String类中重写了equals⽅法,⽅法内部⽐较的是字符串中的各个字符是否全部相等。
重载和重写的区别
重载(Overload): 在⼀个类中,同名的⽅法如果有不同的参数列表(⽐如参数类型不同、参数个数不同)则视为重载。重写(Override): 从字⾯上看,重写就是 重新写⼀遍的意思。其实就是在⼦类中把⽗类本身有的⽅法重新写⼀遍。⼦类继承了⽗类的⽅法,但有时⼦类并不想原封不动的继承⽗类中的某个⽅法,所以在⽅法名,参数列表,返回类型都相同(⼦类中⽅法的返回值可以是⽗类中⽅法返回值的⼦类)的情况下, 对⽅法体进⾏修改,这就是重写。但要注意⼦类⽅法的访问修饰权限不能⼩于⽗类的。
深拷⻉和浅拷⻉
深拷⻉和浅拷⻉就是指对象的拷⻉,⼀个对象中存在两种类型的属性,⼀种是基本数据类型,⼀种是实例对象的引⽤。
- 浅拷⻉是指,只会拷⻉基本数据类型的值,以及实例对象的引⽤地址,并不会复制⼀份引⽤地址所指向的对象,也就是浅拷⻉出来的对象,内部的类属性指向的是同⼀个对象
- 深拷⻉是指,既会拷⻉基本数据类型的值,也会针对实例对象的引⽤地址所指向的对象进⾏复制,深拷⻉出来的对象,内部的属性指向的不是同⼀个对象
什么是字节码?采⽤字节码的好处是什么?
编译器(javac)将Java源⽂件(.java)⽂件编译成为字节码⽂件(.class),可以做到⼀次编译到处运⾏,windows上编译好的class⽂件,可以直接在linux上运⾏,通过这种⽅式做到跨平台,不过Java的跨平台有⼀个前提条件,就是不同的操作系统上安装的JDK或JRE是不⼀样的,虽然字节码是通⽤的,但是需要把字节码解释成各个操作系统的机器码是需要不同的解释器的,所以针对各个操作系统需要有各⾃的JDK或JRE。
采⽤字节码的好处,⼀⽅⾯实现了跨平台,另外⼀⽅⾯也提⾼了代码执⾏的性能,编译器在编译源代码时可以做⼀些编译期的优化,⽐如锁消除、标量替换、⽅法内联等。
Java中有哪些类加载器
JDK⾃带有三个类加载器:bootstrap ClassLoader、ExtClassLoader、AppClassLoader。
- BootStrapClassLoader是ExtClassLoader的⽗类加载器,默认负责加载%JAVA_HOME%lib下的jar包和class⽂件。
- ExtClassLoader是AppClassLoader的⽗类加载器,负责加载%JAVA_HOME%/lib/ext⽂件夹下的jar包和class类。
- AppClassLoader是⾃定义类加载器的⽗类,负责加载classpath下的类⽂件。
说说类加载器双亲委派模型
JVM中存在三个默认的类加载器:
- BootstrapClassLoader
- ExtClassLoader
- AppClassLoader
AppClassLoader的⽗加载器是ExtClassLoader,ExtClassLoader的⽗加载器是BootstrapClassLoader。
JVM在加载⼀个类时,会调⽤AppClassLoader的loadClass⽅法来加载这个类,不过在这个⽅法中,会先使⽤ExtClassLoader的loadClass⽅法来加载类,同样ExtClassLoader的loadClass⽅法中会先使⽤
BootstrapClassLoader来加载类,如果BootstrapClassLoader加载到了就直接成功,如果BootstrapClassLoader没有加载到,那么ExtClassLoader就会⾃⼰尝试加载该类,如果没有加载到,那么则会由AppClassLoader来加载这个类。
所以,双亲委派指得是,JVM在加载类时,会委派给Ext和Bootstrap进⾏加载,如果没加载到才由⾃⼰进⾏加载。
集合
List和Set的区别
- List:有序,按对象插⼊的顺序保存对象,可重复,允许多个Null元素对象,可以使⽤Iterator取出所有元素,在逐⼀遍历,还可以使⽤get(int index)获取指定下标的元素
- Set:⽆序,不可重复,最多允许有⼀个Null元素对象,取元素时只能⽤Iterator接⼝取得所有元素,在逐⼀遍历各个元素
ArrayList和LinkedList区别
- ⾸先,他们的底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现的
- 由于底层数据结构不同,他们所适⽤的场景也不同,ArrayList更适合随机查找,LinkedList更适合删除和添加,查询、添加、删除的时间复杂度不同
- 另外ArrayList和LinkedList都实现了List接⼝,但是LinkedList还额外实现了Deque接⼝,所以LinkedList还可以当做队列来使⽤
谈谈ConcurrentHashMap的扩容机制
1.7版本
- 1.7版本的ConcurrentHashMap是基于Segment分段实现的
- 每个Segment相对于⼀个⼩型的HashMap
- 每个Segment内部会进⾏扩容,和HashMap的扩容逻辑类似
- 先⽣成新的数组,然后转移元素到新数组中
- 扩容的判断也是每个Segment内部单独判断的,判断是否超过阈值
1.8版本
- 1.8版本的ConcurrentHashMap不再基于Segment实现
- 当某个线程进⾏put时,如果发现ConcurrentHashMap正在进⾏扩容那么该线程⼀起进⾏扩容
- 如果某个线程put时,发现没有正在进⾏扩容,则将key-value添加到ConcurrentHashMap中,然 后判断是否超过阈值,超过了则进⾏扩容
- ConcurrentHashMap是⽀持多个线程同时扩容的
- 扩容之前也先⽣成⼀个新的数组
- 在转移元素时,先将原数组分组,将每组分给不同的线程来进⾏元素的转移,每个线程负责⼀组或 多组的元素转移⼯作
Jdk1.7到Jdk1.8 HashMap 发⽣了什么变化(底层)?
- 1.7中底层是数组+链表,1.8中底层是数组+链表+红⿊树,加红⿊树的⽬的是提⾼HashMap插⼊和查询整体效率
- 1.7中链表插⼊使⽤的是头插法,1.8中链表插⼊使⽤的是尾插法,因为1.8中插⼊key和value时需要判断链表元素个数,所以需要遍历链表统计链表元素个数,所以正好就直接使⽤尾插法
- 1.7中哈希算法⽐较复杂,存在各种右移与异或运算,1.8中进⾏了简化,因为复杂的哈希算法的⽬的就是提⾼散列性,来提供HashMap的整体效率,⽽1.8中新增了红⿊树,所以可以适当的简化哈希算法,节省CPU资源
说⼀下HashMap的Put⽅法
先说HashMap的Put⽅法的⼤体流程:
- 根据Key通过哈希算法与与运算得出数组下标
- 如果数组下标位置元素为空,则将key和value封装为Entry对象(JDK1.7中是Entry对象,JDK1.8中
是Node对象)并放⼊该位置 - 如果数组下标位置元素不为空,则要分情况讨论
a. 如果是JDK1.7,则先判断是否需要扩容,如果要扩容就进⾏扩容,如果不⽤扩容就⽣成Entry对 象,并使⽤头插法添加到当前位置的链表中
b. 如果是JDK1.8,则会先判断当前位置上的Node的类型,看是红⿊树Node,还是链表Node
ⅰ.如果是红⿊树Node,则将key和value封装为⼀个红⿊树节点并添加到红⿊树中去,在这个过程中会判断红⿊树中是否存在当前key,如果存在则更新value
ⅱ. 如果此位置上的Node对象是链表节点,则将key和value封装为⼀个链表Node并通过尾插法插⼊到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历链表的过程中会判断是否存在当前key,如果存在则更新value,当遍历完链表后,将新链表Node插⼊到链表中,插⼊到链表后,会看当前链表的节点个数,如果⼤于等于8,那么则会将该链表转成 红⿊树
ⅲ. 将key和value封装为Node插⼊到链表或红⿊树中后,再判断是否需要进⾏扩容,如果需要 就扩容,如果不需要就结束PUT⽅法
HashMap的扩容机制原理
1.7版本
1. 先⽣成新数组
2. 遍历⽼数组中的每个位置上的链表上的每个元素
3. 取每个元素的key,并基于新数组⻓度,计算出每个元素在新数组中的下标
4. 将元素添加到新数组中去
5. 所有元素转移完了之后,将新数组赋值给HashMap对象的table属性
1.8版本
1. 先⽣成新数组
2. 遍历⽼数组中的每个位置上的链表或红⿊树
3. 如果是链表,则直接将链表中的每个元素重新计算下标,并添加到新数组中去
4. 如果是红⿊树,则先遍历红⿊树,先计算出红⿊树中每个元素对应在新数组中的下标位置a. 统计每个下标位置的元素个数b. 如果该位置下的元素个数超过了8,则⽣成⼀个新的红⿊树,并将根节点的添加到新数组的对应位置c. 如果该位置下的元素个数没有超过8,那么则⽣成⼀个链表,并将链表的头节点添加到新数组的对应位置
5. 所有元素转移完了之后,将新数组赋值给HashMap对象的table属性
CopyOnWriteArrayList的底层原理是怎样的
- ⾸先CopyOnWriteArrayList内部也是⽤过数组来实现的,在向CopyOnWriteArrayList添加元素时,会复制⼀个新的数组,写操作在新数组上进⾏,读操作在原数组上进⾏
- 并且,写操作会加锁,防⽌出现并发写⼊丢失数据的问题
- 写操作结束之后会把原数组指向新数组
- CopyOnWriteArrayList允许在写操作时来读取数据,⼤⼤提⾼了读的性能,因此适合读多写少的应⽤场景,但是CopyOnWriteArrayList会⽐较占内存,同时可能读到的数据不是实时最新的数据,所以不适合实时性要求很⾼的场景
异常
Java中的异常体系是怎样的
- Java中的所有异常都来⾃顶级⽗类Throwable。
- Throwable下有两个⼦类Exception和Error。
- Error表示⾮常严重的错误,⽐如java.lang.StackOverFlowError和Java.lang.OutOfMemoryError,通常这些错误出现时,仅仅想靠程序⾃⼰是解决不了的,可能是虚拟机、磁盘、操作系统层⾯出现的问题了,所以通常也不建议在代码中去捕获这些Error,因为捕获的意义不⼤,因为程序可能已经根本运⾏不了了。
- Exception表示异常,表示程序出现Exception时,是可以靠程序⾃⼰来解决的,⽐如NullPointerException、IllegalAccessException等,我们可以捕获这些异常来做特殊处理。
- Exception的⼦类通常⼜可以分为RuntimeException和⾮RuntimeException两类
- RunTimeException表示运⾏期异常,表示这个异常是在代码运⾏过程中抛出的,这些异常是⾮检查异常,程序中可以选择捕获处理,也可以不处理。这些异常⼀般是由程序逻辑错误引起的,程序应该从逻辑⻆度尽可能避免这类异常的发⽣,⽐如NullPointerException、IndexOutOfBoundsException等。
- ⾮RuntimeException表示⾮运⾏期异常,也就是我们常说的检查异常,是必须进⾏处理的异常,如果不处理,程序就不能检查异常通过。如IOException、SQLException等以及⽤户⾃定义的Exception异常。
在Java的异常处理机制中,什么时候应该抛出异常,什么时候捕获异常?
异常相当于⼀种提示,如果我们抛出异常,就相当于告诉上层⽅法,我抛了⼀个异常,我处理不了这个异常,交给你来处理,⽽对于上层⽅法来说,它也需要决定⾃⼰能不能处理这个异常,是否也需要交给它的上层。
所以我们在写⼀个⽅法时,我们需要考虑的就是,本⽅法能否合理的处理该异常,如果处理不了就继续向上抛出异常,包括本⽅法中在调⽤另外⼀个⽅法时,发现出现了异常,如果这个异常应该由⾃⼰来处理,那就捕获该异常并进⾏处理。
JVM
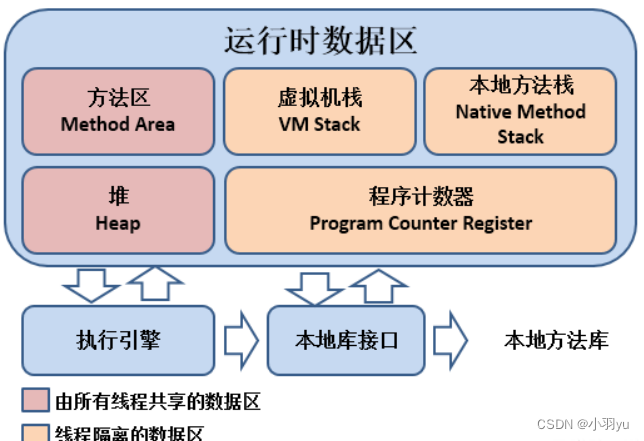
JVM中哪些是线程共享区
堆区和⽅法区是所有线程共享的,栈、本地⽅法栈、程序计数器是每个线程独有的
项⽬如何排查JVM问题
对于还在正常运⾏的系统:
- 可以使⽤
jmap来查看JVM中各个区域的使⽤情况 - 可以通过
jstack来查看线程的运⾏情况,⽐如哪些线程阻塞、是否出现了死锁 - 可以通过
jstat命令来查看垃圾回收的情况,特别是fullgc,如果发现fullgc⽐较频繁,那么就得进⾏调优了 - 通过各个命令的结果,或者
jvisualvm等⼯具来进⾏分析 - ⾸先,初步猜测频繁发送fullgc的原因,如果频繁发⽣fullgc但是⼜⼀直没有出现内存溢出,那么表示fullgc实际上是回收了很多对象了,所以这些对象最好能在younggc过程中就直接回收掉,避免这些对象进⼊到⽼年代,对于这种情况,就要考虑这些存活时间不⻓的对象是不是⽐较⼤,导致年轻代放不下,直接进⼊到了⽼年代,尝试加⼤年轻代的⼤⼩,如果改完之后,fullgc减少,则证明修改有效
- 同时,还可以找到占⽤CPU最多的线程,定位到具体的⽅法,优化这个⽅法的执⾏,看是否能避免某些对象的创建,从⽽节省内存
对于已经发⽣了OOM的系统:
- ⼀般⽣产系统中都会设置当系统发⽣了OOM时,⽣成当时的dump⽂件
(-XX:+HeapDumpOnOutOfMemoryError -XX : HeapDumpPath = /usr/local/base) - 我们可以利⽤
jsisualvm等⼯具来分析dump⽂件 - 根据
dump⽂件找到异常的实例对象,和异常的线程(占⽤CPU⾼),定位到具体的代码 - 然后再进⾏详细的分析和调试
总之,调优不是⼀蹴⽽就的,需要分析、推理、实践、总结、再分析,最终定位到具体的问题
⼀个对象从加载到JVM,再到被GC清除,都经历了什么过程?
- ⾸先把字节码⽂件内容加载到⽅法区
- 然后再根据类信息在堆区创建对象
- 对象⾸先会分配在堆区中年轻代的Eden区,经过⼀次Minor GC后,对象如果存活,就会进⼊Suvivor区。在后续的每次Minor GC中,如果对象⼀直存活,就会在Suvivor区来回拷⻉,每移动⼀次,年龄加1
- 当年龄超过15后,对象依然存活,对象就会进⼊⽼年代
- 如果经过Full GC,被标记为垃圾对象,那么就会被GC线程清理掉
怎么确定⼀个对象到底是不是垃圾?
- 引⽤计数算法: 这种⽅式是给堆内存当中的每个对象记录⼀个引⽤个数。引⽤个数为0的就认为是
垃圾。这是早期JDK中使⽤的⽅式。引⽤计数⽆法解决循环引⽤的问题。 - 可达性算法: 这种⽅式是在内存中,从根对象向下⼀直找引⽤,找到的对象就不是垃圾,没找到的对象就是垃圾。
JVM有哪些垃圾回收算法?
标记清除算法:
a. 标记阶段:把垃圾内存标记出来
b. 清除阶段:直接将垃圾内存回收。
c. 这种算法是⽐较简单的,但是有个很严重的问题,就是会产⽣⼤量的内存碎⽚。复制算法:为了解决标记清除算法的内存碎⽚问题,就产⽣了复制算法。复制算法将内存分为⼤⼩相等的两半,每次只使⽤其中⼀半。垃圾回收时,将当前这⼀块的存活对象全部拷⻉到另⼀半,然后当前这⼀半内存就可以直接清除。这种算法没有内存碎⽚,但是他的问题就在于浪费空间。⽽且,他的效率跟存活对象的个数有关。标记压缩算法:为了解决复制算法的缺陷,就提出了标记压缩算法。这种算法在标记阶段跟标记清除算法是⼀样的,但是在完成标记之后,不是直接清理垃圾内存,⽽是将存活对象往⼀端移动,然后将边界以外的所有内存直接清除。
什么是STW?
STW: Stop-The-World,是在垃圾回收算法执⾏过程当中,需要将JVM内存冻结的⼀种状态。在STW状态下,JAVA的所有线程都是停⽌执⾏的-GC线程除外,native⽅法可以执⾏,但是,不能与JVM交互。GC各种算法优化的重点,就是减少STW,同时这也是JVM调优的重点。
相关文章:
Java基础常考知识点(基础、集合、异常、JVM)
作者:逍遥Sean 简介:一个主修Java的Web网站\游戏服务器后端开发者 主页:https://blog.csdn.net/Ureliable 觉得博主文章不错的话,可以三连支持一下~ 如有需要我的支持,请私信或评论留言! Java基础常考知识点…...
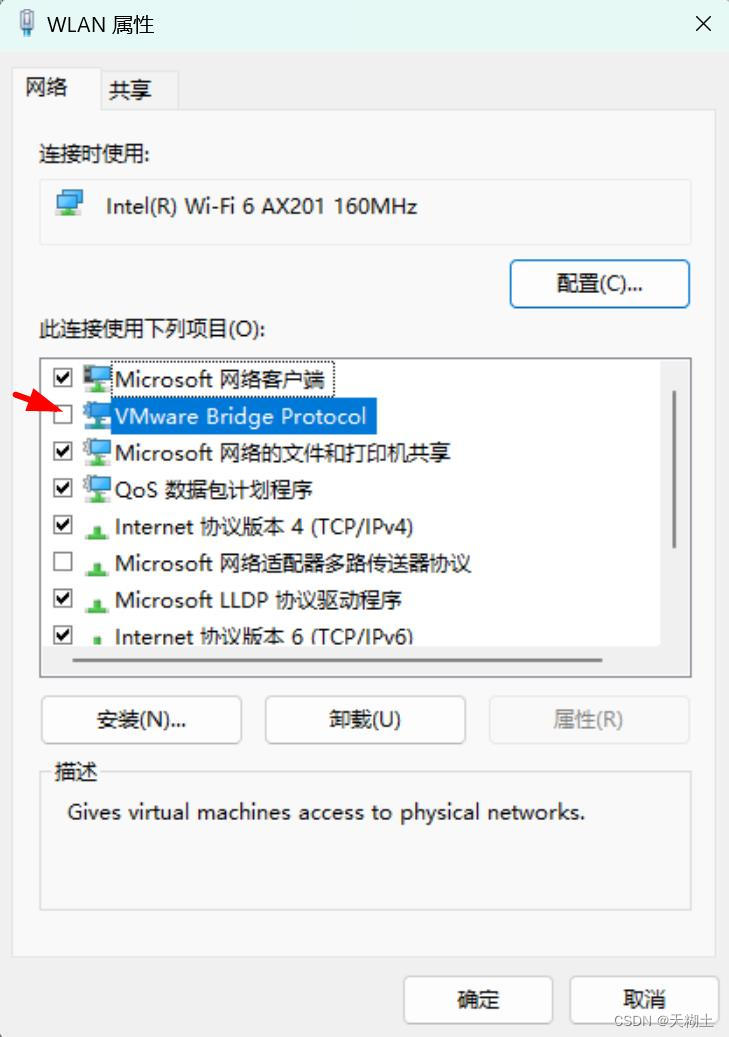
虚拟机桥接模式下没有无线网卡选项
我以为是雷电模拟器占用了网卡的缘故,但想起之前可能修改了无线网卡的某些内容,于是到网络属性里面查看。 如下所示,原来是之前我不小心把这个红箭头指向的项目取消勾选了。...

设计模式笔记
关于设计模式 1. 如何阅读本文 略 2. 面向对象程序设计简介 2.1 面向对象程序设计基础 面向对象程序设计 (Object-Oriented Programming,缩写为 OOP)是一种范式,其基本理念是将 数据块 及 与数据相关的行为 封装成为特殊的、…...
c==ubuntu+vscode debug redis7源码
新建.vscode文件夹,创建launch.json和tasks.json {"version": "0.2.0","configurations": [{"name": "C/C Launch","type": "cppdbg","request": "launch","prog…...

java字符串储存底层原理
字符串原理:原理1: 内存原理 (1)直接赋值给字符串,会把这个字符串放到常量池里,如果之后出现重复使用这个字符串的,就会直接从这个常量池中去引用,不会再去new一个字符串 (2)new出来的字符串不会重复使用,而是开辟一个新的空间存储原理2: 字符串中的""比较的是什么?…...
c++获取当前时间的字符串
代码 void getNowTimePrefix(std::string& prefix) {std::time_t nowTime;struct tm* p new tm;std::time(&nowTime);localtime_s(p, &nowTime);int year p->tm_year 1900;int month p->tm_mon 1;int day p->tm_mday;int hour p->tm_hour;int …...

【精品】通用Mapper 批量更新bug解决方案
问题描述 环境:mysql8.xmybatis3.5.13tk.mybatis4.2.3 在使用tk.mybatis做批量更新时,程序会报错,说是执行的SQL语法错误,经研究源代码发现tk.mybatis在实现批量更新时是通过多次执行update语句实现的。这本身就不符合MySQL批量…...

腾讯mini项目-【指标监控服务重构-会议记录】2023-07-06
7/6 会议记录 Profile4个步骤 解压kafka消息初始化性能事件,分析事件将数据写入kafkaRun 开始执行各stage handler 上报耗时到otel-collector。。。 // ConsumerDispatchHandler consumer // // param msg *sarama.ConsumerMessage // param consumer *databus.K…...

【React】函数式组件和类式组件的用法和逻辑
组件的使用 当应用是以多组件的方式实现,这个应用就是一个组件化的应用 注意: 组件名必须是首字母大写虚拟DOM元素只能有一个根元素虚拟DOM元素必须有结束标签 < /> 渲染类组件标签的基本流程React 内部会创建组件实例对象调用render()得到虚拟 …...

题目 1061: 二级C语言-计负均正
从键盘输入任意20个整型数,统计其中的负数个数并求所有正数的平均值。 保留两位小数 样例输入 1 2 3 4 5 6 7 8 9 10 -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 样例输出 10 5.50 解题思路: 如题所示,输入20个正负数,---》求付数的个…...
)
数位和(C++)
系列文章目录 进阶的卡莎C++_睡觉觉觉得的博客-CSDN博客数1的个数_睡觉觉觉得的博客-CSDN博客双精度浮点数的输入输出_睡觉觉觉得的博客-CSDN博客足球联赛积分_睡觉觉觉得的博客-CSDN博客大减价(一级)_睡觉觉觉得的博客-CSDN博客小写字母的判断_睡觉觉觉得的博客-CSDN博客纸币(…...
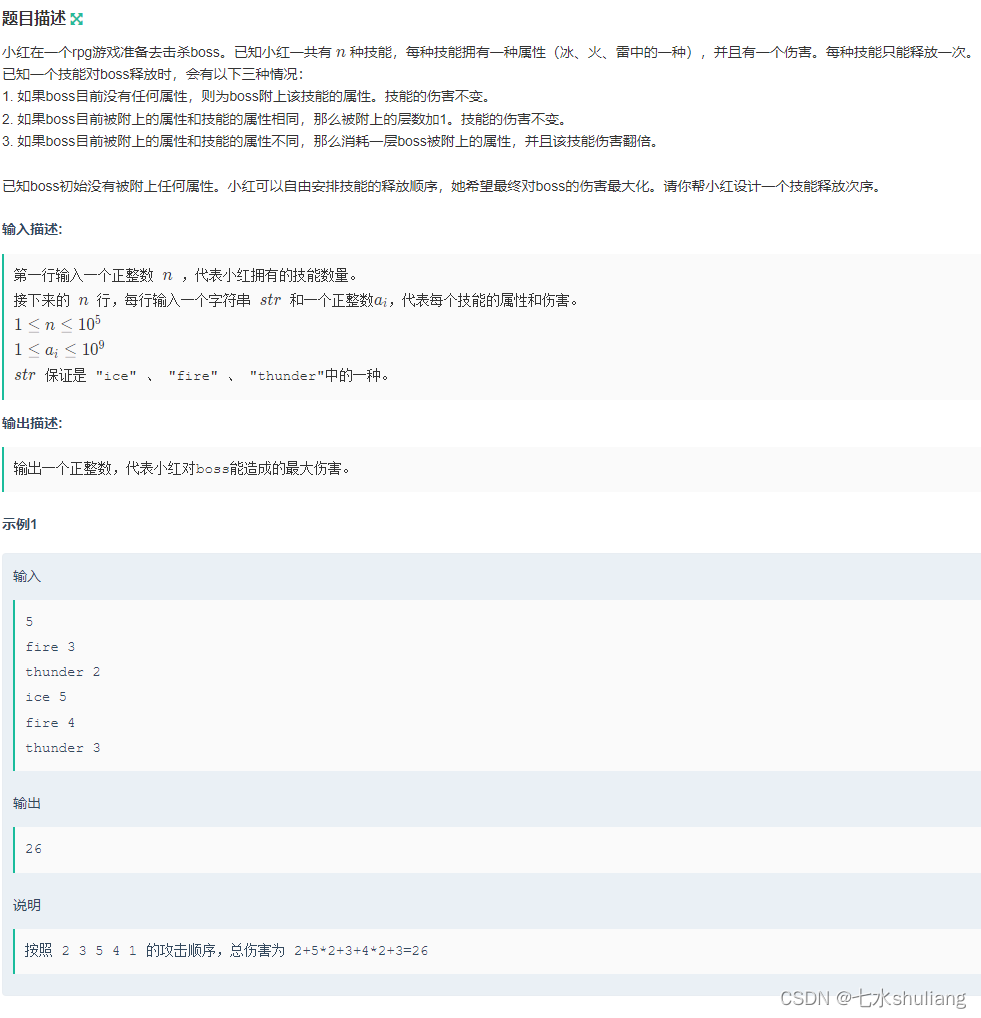
[牛客复盘] 牛客周赛round13 20230924
[牛客复盘] 牛客周赛round13 20230924 总结矩阵转置置2. 思路分析3. 代码实现 小红买基金1. 题目描述2. 思路分析3. 代码实现 小红的密码修改1. 题目描述2. 思路分析3. 代码实现 小红的转账设置方式1. 题目描述2. 思路分析3. 代码实现 小红打boss1. 题目描述2. 思路分析3. 代码…...
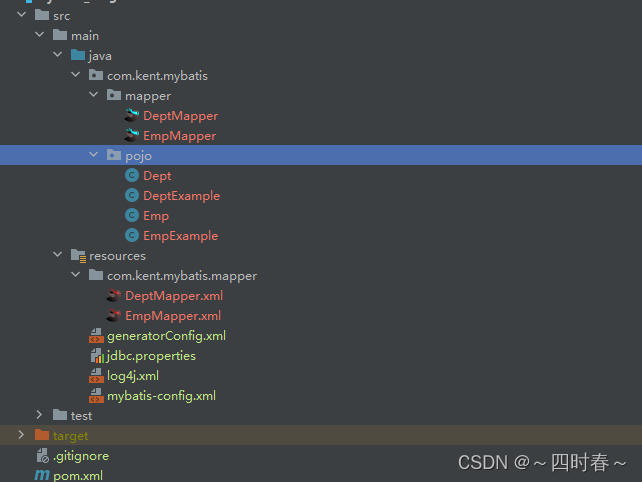
mybatsi-MyBatis的逆向工程
mybatsi-MyBatis的逆向工程 一、前言二、创建逆向工程的步骤1.添加依赖和插件2.创建MyBatis的核心配置文件3.创建逆向工程的配置文件4.执行MBG插件的generate目标 一、前言 正向工程:先创建Java实体类,由框架负责根据实体类生成数据库表。 Hibernate是支…...

转转闲鱼交易猫链接源码 支持二维码收款
最新仿二手闲置链接源码 后台一键生成链接,后台管理教程:解压源码,修改数据库config/Congig 不会可以看源码里有教程 下载程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3...

Python爬虫基础(三):使用Selenium动态加载网页
文章目录 系列文章索引一、Selenium简介1、什么是selenium?2、为什么使用selenium3、安装selenium(1)谷歌浏览器驱动下载安装(2)安装selenium 二、Selenium使用1、简单使用2、元素定位3、获取元素信息4、交互 三、Phan…...
Linux系统下安装Mysql
1、执行命令:rpm -qa | grep -i mysql,先查看系统之前是否有安装相关的rpm包,如果有,会显示类似下面的信息; 2、通过命令yum -y remove mysql-* 一次性删除系统上所有相关的rpm包,或者通过命令yum -y …...
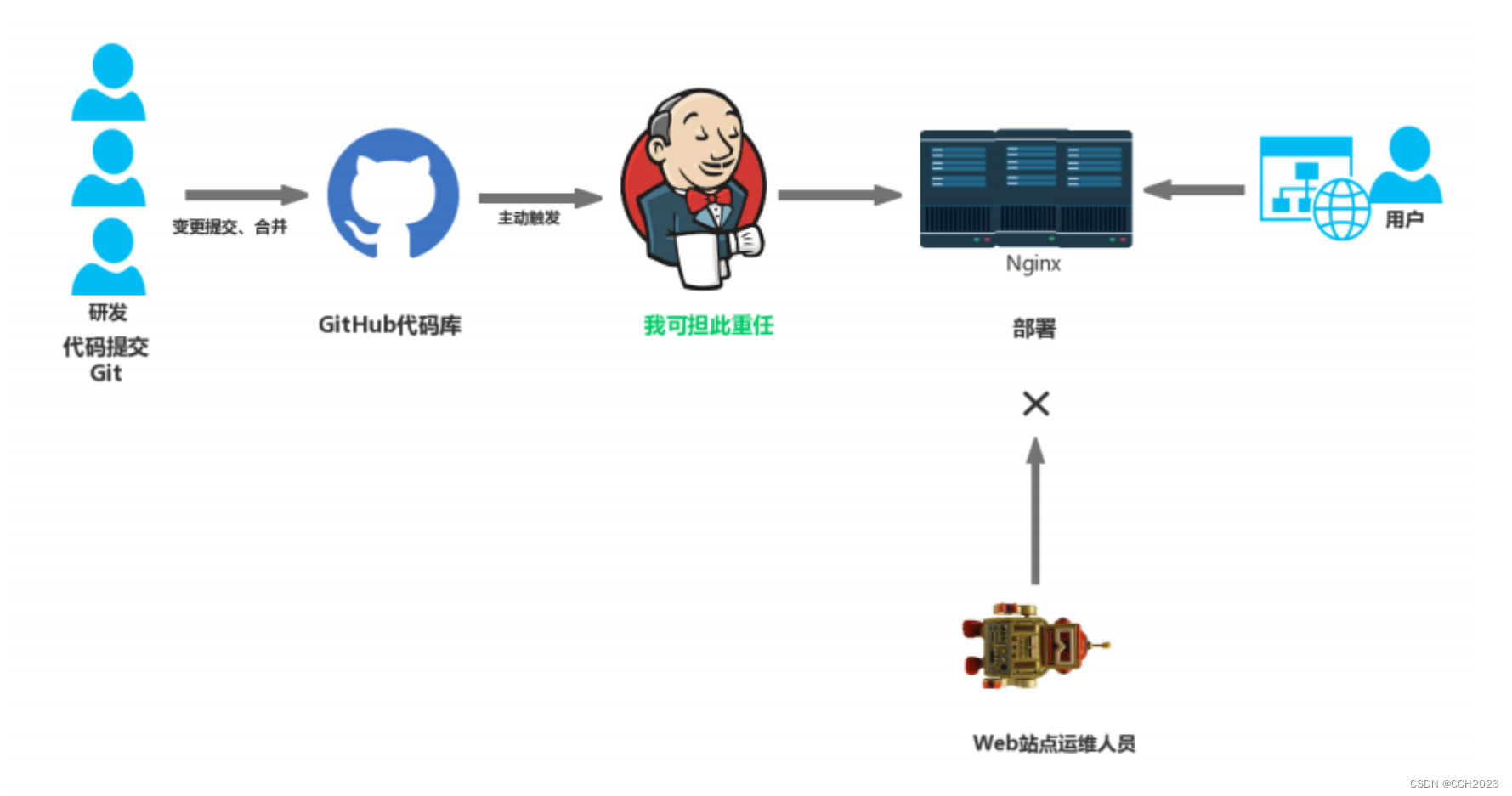
Jenkins学习笔记1
CI 服务器: 认识Jenkins: Jenkins是一个可扩展的持续集成(CI)引擎,是一个开源项目,旨在提供一个开放易用的软件平台,使得软件持续集成变成可能。Jenkins非常易于安装和配置,简单易…...

注意力机制
概念没什么好说的,反正大家都会说,具体实战怎么写才是最为重要的 1.自注意力 假设有一组数据,都是一维的向量,这个向量可能是一个样本,可能是其他什么,都无所谓。 假设有一组一维向量x1,x2,x3,x4,x5; 第…...

JVM-Java字节码技术笔记
Java字节码技术 Java字节码是java代码编译后的中间代码格式,JVM需要读取并解析字节码才能执行相应的任务 获取字节码简介:由单字节(byte)的指令组成 操作码( 指令), 主要由类型前缀和操作名称两部分组成。根据指令的性质…...

C++ 友元、重载、继承、多态
友元 关键字:friend 友元的三种实现 全局函数做友元类做友元成员函数做友元 全局函数做友元 //建筑物类 class Building {//goodGay全局函数是Building好朋友,可以访问Building中私有成员friend void goodGay(Building& building); public:Build…...
)
企业网络准入实战:用华三WX2540H和深信服AC搞定有线无线统一Portal认证(附OA集成)
企业级网络准入实战:华三WX2540H与深信服AC协同部署全攻略 当企业网络规模扩张到数百个终端时,传统MAC地址绑定和静态VLAN分配的管理方式就会暴露出明显短板。某制造企业IT主管张工最近就遇到了这样的困扰:研发部门的访客需要临时网络接入时&…...

如何轻松掌握Google Cloud Vision图像识别:5步快速上手指南
如何轻松掌握Google Cloud Vision图像识别:5步快速上手指南 【免费下载链接】cloud-vision Sample code for Google Cloud Vision 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-vision Google Cloud Vision是一款强大的图像识别服务,它能让…...

如何构建 Flink SQL 任务的血缘分析
版本一:干燥苦涩、缺乏深度(反面回答素材)面试者语气:(机械地背诵,没有眼神交流,缺乏实践细节)“关于 Flink SQL 的血缘分析,我认为主要分为以下几个步骤:首先…...

12年不上班,我靠什么支撑到现在
我已经12年没去上过班了,14年从学校辞职出来后,就没再给人打过工。虽然我不上班,但身边人都觉得我很会赚钱,觉得我很幸运,也觉得我很有勇气。 其实,并不是我多勇敢,是因为早在2014年,…...

抖音直播回放下载工具全解析:技术原理与跨领域应用指南
抖音直播回放下载工具全解析:技术原理与跨领域应用指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

完整指南:如何高效使用SecHex-Spoofy进行Windows系统伪装与安全测试
完整指南:如何高效使用SecHex-Spoofy进行Windows系统伪装与安全测试 【免费下载链接】SecHex-Spoofy C# HWID Changer 🔑︎ Disk, Guid, Mac, Gpu, Pc-Name, Win-ID, EFI, SMBIOS Spoofing [Usermode] 项目地址: https://gitcode.com/gh_mirrors/se/Se…...

Blender 3MF插件完整指南:轻松实现3D打印文件导入导出
Blender 3MF插件完整指南:轻松实现3D打印文件导入导出 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 如果你正在寻找一个能让你在Blender中轻松处理3D打印文…...

如何用Untrunc开源工具拯救损坏的视频文件:从理论到实践的完整指南
如何用Untrunc开源工具拯救损坏的视频文件:从理论到实践的完整指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc …...

DedeCMS文件包含漏洞深度剖析:为什么一个‘无害’的txt文件能让你getshell?
DedeCMS文件包含漏洞技术解析:从文本文件到系统沦陷的连锁反应 在内容管理系统(CMS)的安全领域,最危险的漏洞往往藏匿于最平凡的功能之中。DedeCMS作为国内广泛使用的开源CMS,其文件包含漏洞(CVE-2023-2928…...

ChatGLM-6B惊艳案例:高考作文命题分析、范文生成与评分建议
ChatGLM-6B惊艳案例:高考作文命题分析、范文生成与评分建议 ChatGLM-6B智能对话服务:本镜像为CSDN镜像构建作品,集成了清华大学KEG实验室与智谱AI共同训练的开源双语对话模型ChatGLM-6B,提供开箱即用的智能对话体验。 1. 高考作文…...