Python爬虫基础(三):使用Selenium动态加载网页
文章目录
系列文章索引
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
Python爬虫基础(三):使用Selenium动态加载网页
Python爬虫基础(四):使用更方便的requests库
Python爬虫基础(五):使用scrapy框架
一、Selenium简介
1、什么是selenium?
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
2、为什么使用selenium
我们打开京东,看到有一个秒杀的模块,从网页源码中也可以定位到:
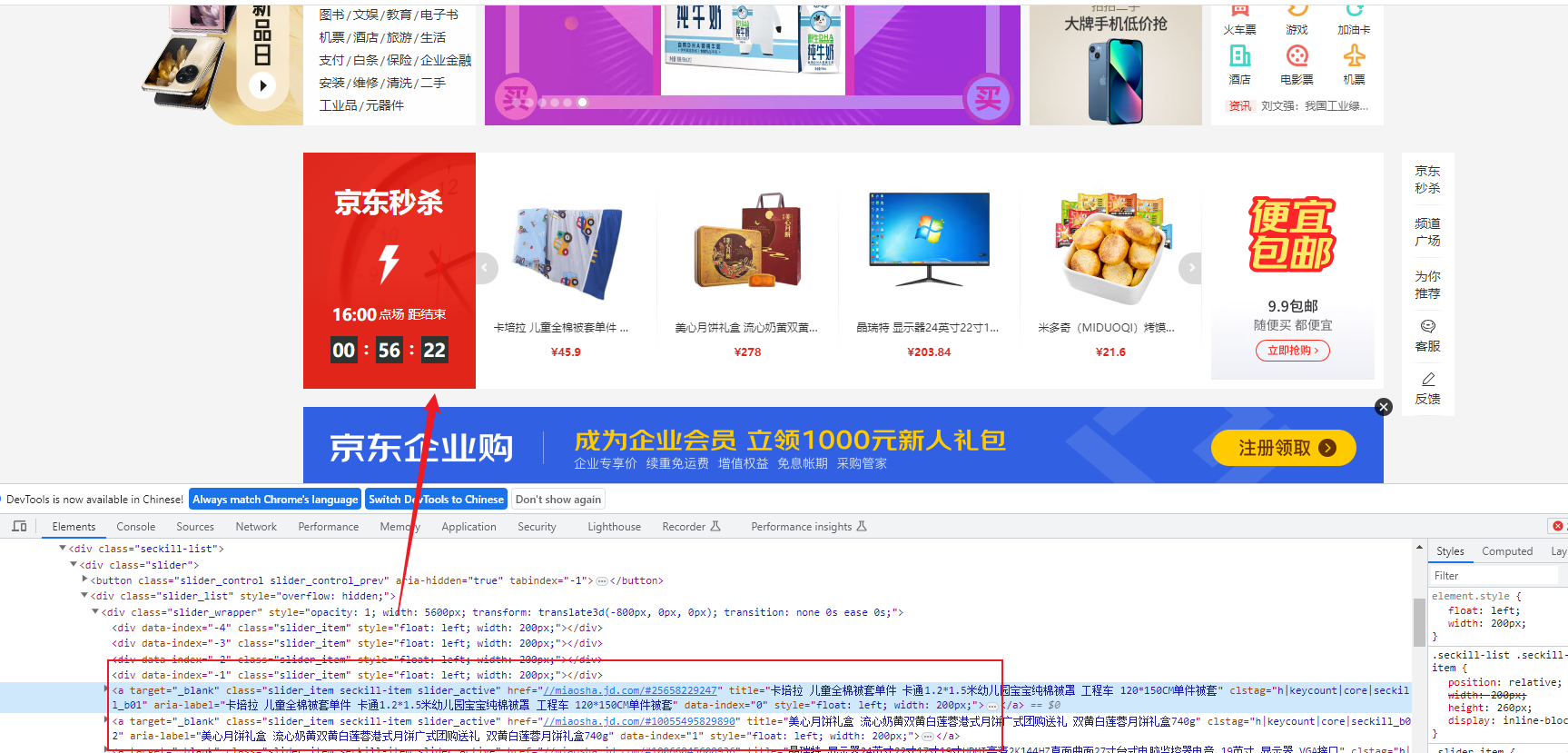
但是我们使用urllib爬取:
import urllib.requesturl = 'https://www.jd.com/'
urllib.request.urlretrieve(url,'jd.html')
爬取的网页,我们全局搜索发现,并没有秒杀这部分内容。
因为秒杀这部分内容,是在js中动态加载的,而selenium就可以模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
3、安装selenium
(1)谷歌浏览器驱动下载安装
查看谷歌浏览器的版本:帮助->关于google chrome,查看版本。
根据版本查找对应的chromedriver,大版本对应就可以,小版本不需要关心,下载地址(第一个网速比较慢),32位和64位都能用:
http://chromedriver.storage.googleapis.com/index.html
https://registry.npmmirror.com/binary.html?path=chromedriver/
如果是最新版的谷歌浏览器,以上可能没有同步更新,试试下面的网站:
https://googlechromelabs.github.io/chrome-for-testing/
下载之后是一个压缩文件。

将解压出来的exe文件,放到python项目的根目录下(为了方便使用,不这样做的话,使用时指定路径也可)。
(2)安装selenium
# 进入到python安装目录的Scripts目录
d:
cd D:\python\Scripts
# 安装
pip install selenium -i https://pypi.douban.com/simple
二、Selenium使用
1、简单使用
简单三步,轻松使用,获取网页的全部内容(网页完全加载完毕之后的)。
# (1)导入selenium
from selenium import webdriver# (2) 创建浏览器操作对象,就是指定我们驱动的路径
path = 'chromedriver.exe'browser = webdriver.Chrome(path)# (3)访问网站url = 'https://www.jd.com/'browser.get(url)# page_source获取网页源码
content = browser.page_source
with open('jd.html','w',encoding='utf-8') as fp:fp.write(content)
2、元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法。
from selenium import webdriver
from selenium.webdriver.common.by import Bypath = 'chromedriver.exe'
browser = webdriver.Chrome(path)url = 'https://www.baidu.com'
browser.get(url)# 元素定位# 根据id来找到对象 id = su
button = browser.find_element(by = By.ID, value = 'su')
print(button)# 根据标签属性的属性值来获取对象的 name = wd
button = browser.find_element(by = By.NAME, value = 'wd')
print(button)# 根据xpath语句来获取对象 xpath语法
button = browser.find_element(by = By.XPATH, value = '//input[@id="su"]')
print(button)# 根据标签的名字来获取对象
button = browser.find_element(by = By.TAG_NAME, value = 'input')
print(button)# 使用的bs4的语法来获取对象
button = browser.find_element(by = By.CSS_SELECTOR, value = '#su')
print(button)# 获取链接文本
button = browser.find_element(by = By.LINK_TEXT, value = '百度一下')
print(button)
By参数 包含许多可选的选项:

3、获取元素信息
from selenium import webdriver
from selenium.webdriver.common.by import Bypath = 'chromedriver.exe'
browser = webdriver.Chrome(path)url = 'http://www.baidu.com'
browser.get(url)input = browser.find_element(by = By.ID, value = 'su')# 获取标签的属性 获取class属性
print(input.get_attribute('class'))
# 获取标签的名字
print(input.tag_name)# 获取元素文本
a = browser.find_element(by = By.LINK_TEXT, value = '新闻')
print(a.text)4、交互
from selenium import webdriver
from selenium.webdriver.common.by import By# 创建浏览器对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)# url
url = 'https://www.baidu.com'
browser.get(url)# 休眠2秒
import time
time.sleep(2)# 获取文本框的对象
input = browser.find_element(by = By.ID, value = 'kw')# 在文本框中输入周杰伦
input.send_keys('周杰伦')time.sleep(2)# 获取百度一下的按钮
button = browser.find_element(by = By.ID, value = 'su')# 点击按钮
button.click()time.sleep(2)# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)time.sleep(2)# 获取下一页的按钮
next = browser.find_element(by = By.XPATH, value = '//a[@class="n"]')# 点击下一页
next.click()time.sleep(2)# 回到上一页
browser.back()time.sleep(2)# 回去
browser.forward()time.sleep(3)# 退出
browser.quit()
三、Phantomjs使用(停更)
1、什么是Phantomjs
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
Phantomjs已经过时了,推荐使用Chrome handless,高版本的Selenium已经不支持Phantomjs了
2、下载
官网:http://wenku.kuryun.com/docs/phantomjs/download.html

将下载的phantomjs.exe文件拷贝到项目目录(为了方便使用,不这样做的话,使用时指定路径也可)。
3、使用Phantomjs
(1)获取PhantomJS.exe文件路径path
(2)browser = webdriver.PhantomJS(path)
(3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot(‘baidu.png’)
from selenium import webdriverpath = 'phantomjs.exe'browser = webdriver.PhantomJS(path)url = 'https://www.baidu.com'
browser.get(url)
# 保存快照
browser.save_screenshot('baidu.png')import time
time.sleep(2)
# 最新版selenium不支持该语法
input = browser.find_element_by_id('kw')
input.send_keys('昆凌')time.sleep(3)browser.save_screenshot('kunling.png')四、Chrome handless无界面模式
1、简介
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致,性能更高。
系统要求:
Chrome:Unix\Linux 系统需要 chrome >= 59、Windows 系统需要 chrome >= 60
Python3.6 +
Selenium3.4.* +
ChromeDriver2.31 +
2、基本使用
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsdef share_browser():'''该方法的内容,都不需要动,只需要修改自己的chrome浏览器路径'''chrome_options = Options()chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')# path是你自己的chrome浏览器的文件路径path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe'chrome_options.binary_location = pathbrowser = webdriver.Chrome(chrome_options=chrome_options)return browserbrowser = share_browser()url = 'https://www.baidu.com'browser.get(url)browser.save_screenshot('baidu.png')
相关文章:
Python爬虫基础(三):使用Selenium动态加载网页
文章目录 系列文章索引一、Selenium简介1、什么是selenium?2、为什么使用selenium3、安装selenium(1)谷歌浏览器驱动下载安装(2)安装selenium 二、Selenium使用1、简单使用2、元素定位3、获取元素信息4、交互 三、Phan…...
Linux系统下安装Mysql
1、执行命令:rpm -qa | grep -i mysql,先查看系统之前是否有安装相关的rpm包,如果有,会显示类似下面的信息; 2、通过命令yum -y remove mysql-* 一次性删除系统上所有相关的rpm包,或者通过命令yum -y …...
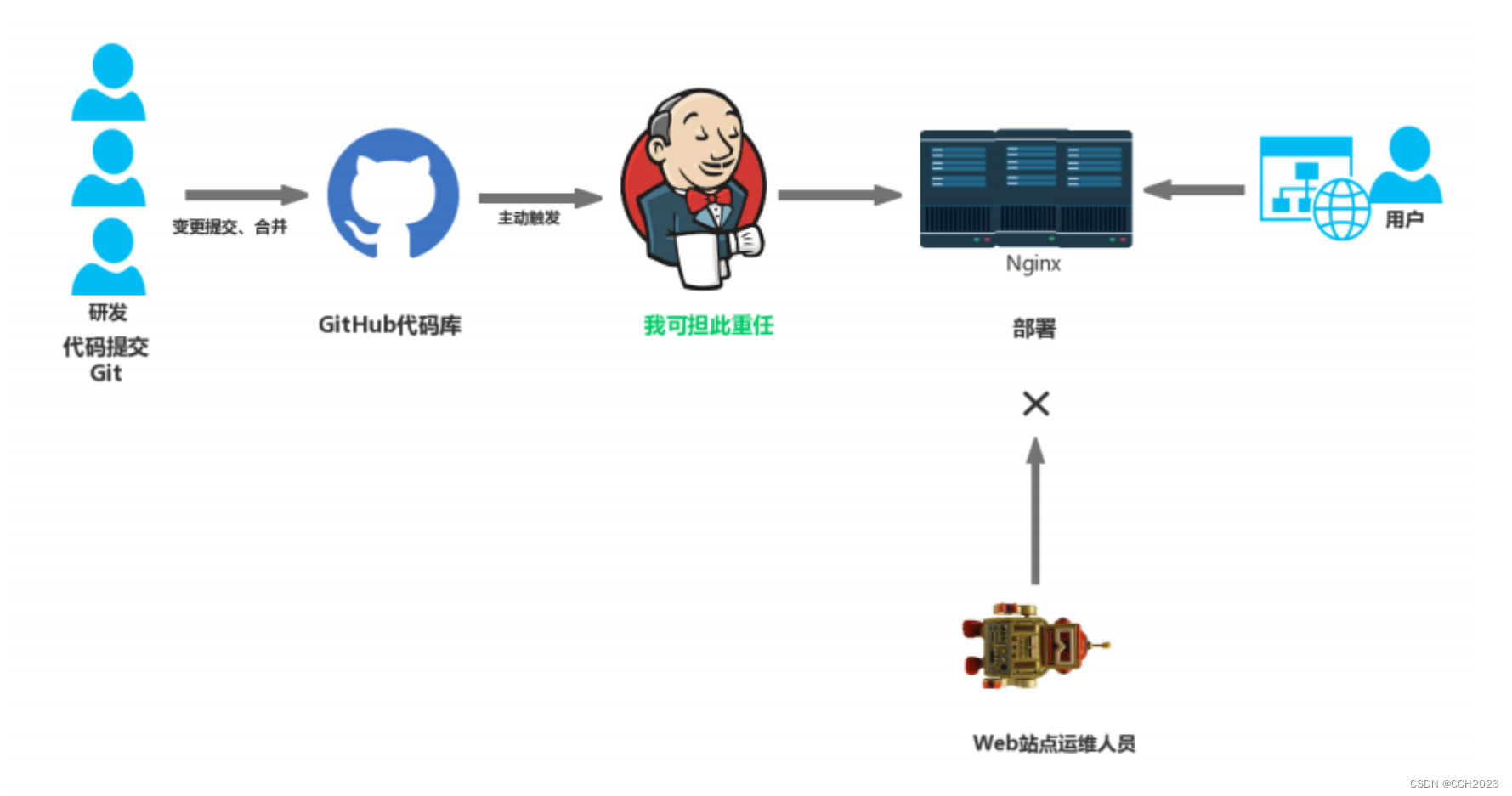
Jenkins学习笔记1
CI 服务器: 认识Jenkins: Jenkins是一个可扩展的持续集成(CI)引擎,是一个开源项目,旨在提供一个开放易用的软件平台,使得软件持续集成变成可能。Jenkins非常易于安装和配置,简单易…...

注意力机制
概念没什么好说的,反正大家都会说,具体实战怎么写才是最为重要的 1.自注意力 假设有一组数据,都是一维的向量,这个向量可能是一个样本,可能是其他什么,都无所谓。 假设有一组一维向量x1,x2,x3,x4,x5; 第…...

JVM-Java字节码技术笔记
Java字节码技术 Java字节码是java代码编译后的中间代码格式,JVM需要读取并解析字节码才能执行相应的任务 获取字节码简介:由单字节(byte)的指令组成 操作码( 指令), 主要由类型前缀和操作名称两部分组成。根据指令的性质…...

C++ 友元、重载、继承、多态
友元 关键字:friend 友元的三种实现 全局函数做友元类做友元成员函数做友元 全局函数做友元 //建筑物类 class Building {//goodGay全局函数是Building好朋友,可以访问Building中私有成员friend void goodGay(Building& building); public:Build…...
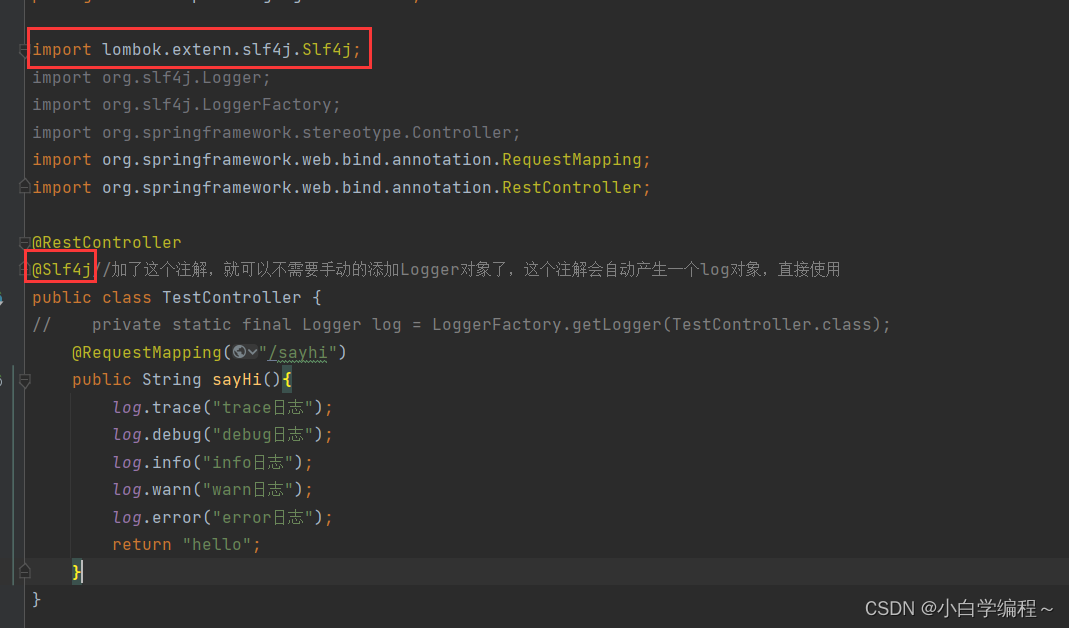
Spring Boot 日志文件
前言 本篇博客主要介绍自定义的日志打印、日志的级别高低、如何保存日志等等..... 一、日志是什么?日志有什么用? 日志就是我们控制台上输出的内容,控制台上的输出的信息就是日志信息,如下所示: 日志有什么用&#x…...
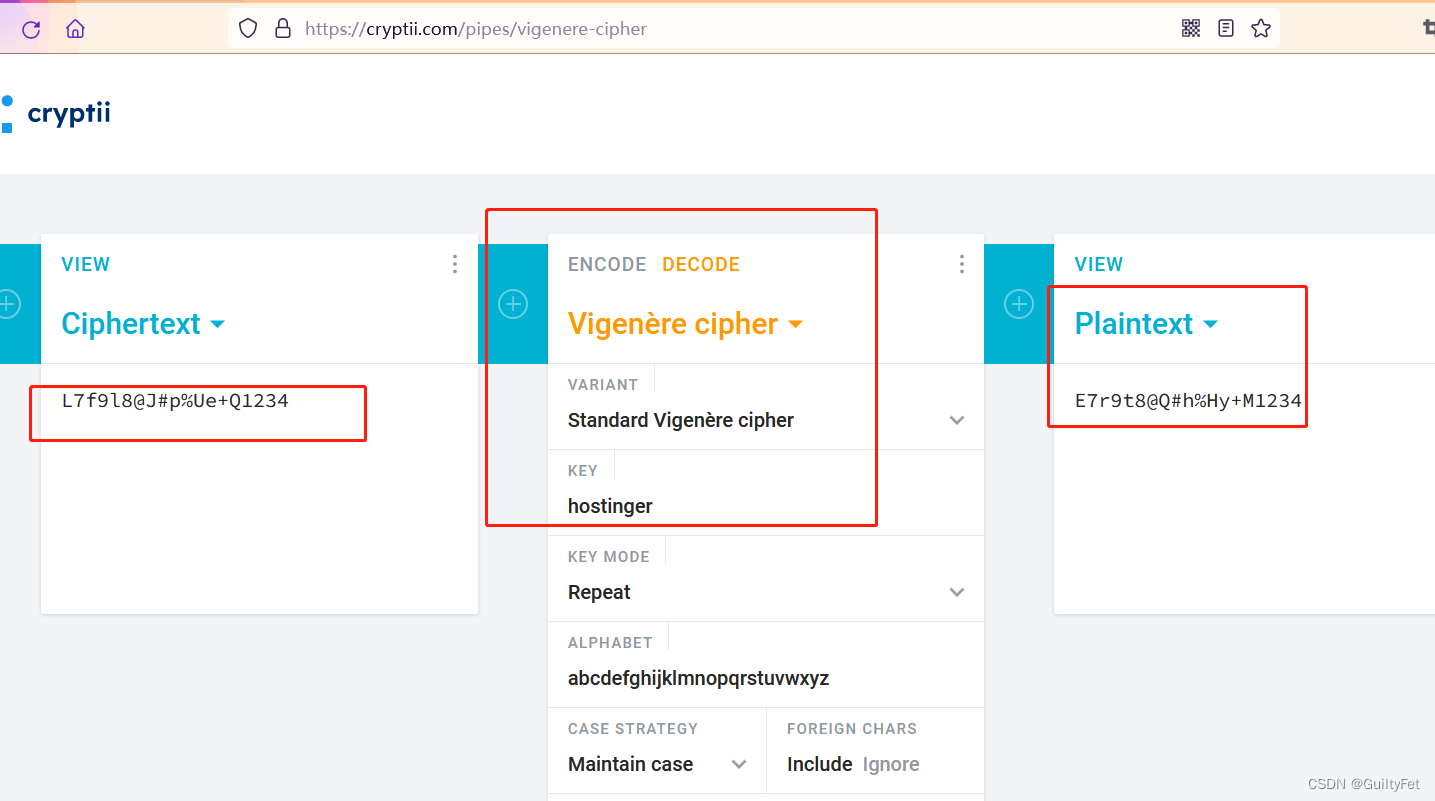
vulhub venom
文章目录 靶场环境信息收集ftp服务二、信息利用三、任意文件上传三 sudo提权靶场环境 `vmware 靶场信息:https://www.vulnhub.com/entry/venom-1,701/ 下载地址:https://download.vulnhub.com/venom/venom.zip 新建虚拟机打开下载后的ovf文件 遇见导入失败合规性检查时,重试…...
)
量化交易之One Piece篇 - linux - 定时任务(重启服务器、执行程序、验证)
linux 执行命令: crontab -e 0 5 * * 1-5 sudo /sbin/shutdown -r now 0 17 * * 1-5 sudo /sbin/shutdown -r now 45 8 * * 1-5 cd /home/ubuntu/onepiece/bin/datacore && ./datacore 45 20 * * 1-5 cd /home/ubuntu/onepiece/bin/datacore && ./datacore 以…...
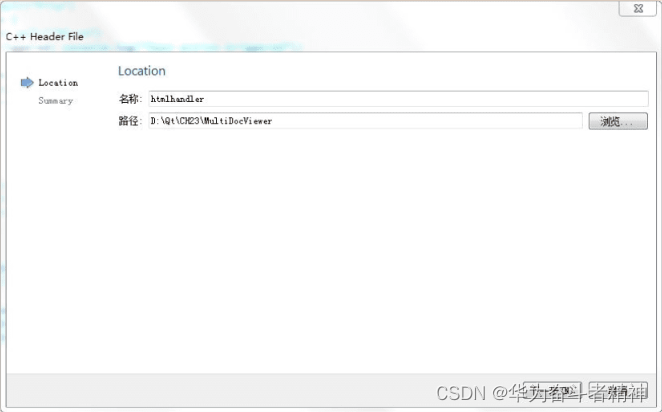
Qt5开发及实例V2.0-第二十三章-Qt-多功能文档查看器实例
Qt5开发及实例V2.0-第二十三章-Qt-多功能文档查看器实例 第23章 多功能文档查看器实例23.1. 简介23.2. 界面与程序框架设计23.2.1. 图片资源23.2.2. 网页资源23.2.3. 测试用文件 23.3 主程序代码框架23.4 浏览网页功能实现23.4.1 实现HtmIHandler处理器 23.5. 部分代码实现23.5…...
爬虫笔记_
爬虫简介 爬虫初始深入 爬虫在使用场景中的分类 通用爬虫: 抓取系统重要组成部分。抓取的是一整张页面数据 聚焦爬虫: 是建立在通用爬虫的基础上。抓取的是页面中特定的局部内容。 增量式爬虫 监测网站中数据更新的情况。只会抓取网站中最新更新出来的…...

Spring设计模式,事务管理和代理模式的应用
扩充:贝叶斯定理答案见底。 设计模式对关于面向对象问题的具体解决方案. 1,单例多例 在设计单例模式时,要注意两个点 1.构造方法要私有 2.成员变量要私有 3.创建对象所用的方法要被synchronized修饰.(因为方法体中会涉及到判断当…...
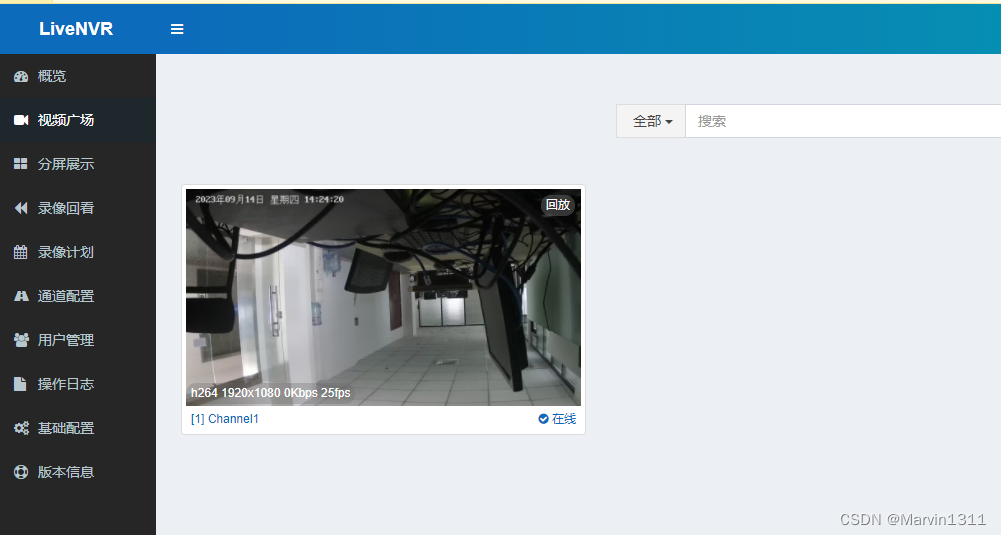
基于海康Ehome/ISUP接入到LiveNVR实现海康摄像头、录像机视频统一汇聚,做到物联网无插件直播回放和控制
LiveNVR支持海康NVR摄像头通EHOME接入ISUP接入LiveNVR分发视频流或是转GB28181 1、海康 ISUP 接入配置2、海康设备接入2.1、海康EHOME接入配置示例2.2、海康ISUP接入配置示例 3、通道配置3.1、直播流接入类型 海康ISUP3.2、海康 ISUP 设备ID3.3、启用保存3.4、接入成功 4、相关…...

Linux下git安装及使用
Linux下Git使用 1. git的安装 sudo apt install git安装完,使用git --version查看git版本 2. 配置git git config --global user.name "Your Name“ ##配置用户 git config --global user.email emailexample.com ##配置邮箱git config --global --list …...

python读取图片
要在Python中读取图片,你可以使用第三方库Pillow(Python Imaging Library,PIL)或OpenCV。以下是使用这两个库的示例: 使用Pillow库读取图片: 首先,确保你已经安装了Pillow库。如果还没有安装&am…...
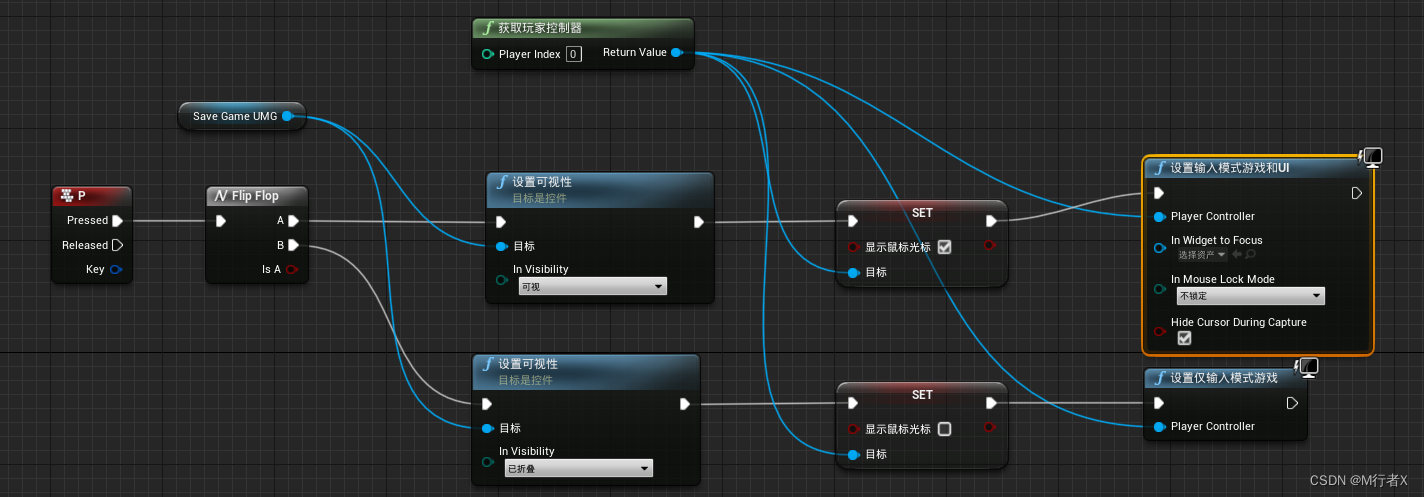
虚幻4学习笔记(15)读档 和存档 的实现
虚幻4学习笔记 读档存档 B站UP谌嘉诚课程:https://www.bilibili.com/video/BV164411Y732 读档 添加UI蓝图 SaveGame_UMG 添加Scroll Box 修改Scrollbar Thickness滚动条厚度 15 15 勾选 is variable 添加text 读档界面 添加背景模糊 添加UI蓝图 SaveGame_Slot …...

Spring面试题22:Spring支持哪些ORM框架?优缺点分别是什么?Spring可以通过哪些方式访问Hibernate?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:Spring支持哪些ORM框架?优缺点分别是什么? Spring 支持多种 ORM(对象关系映射)框架,其中包括: Hibernate:Hibernate 是一个强大的 ORM 框架…...

流行的Python库numpy及Pandas简要介绍
numpy.ndarray 是NumPy库中的主要数据结构,它是一个多维数组,用于存储和操作数值数据。NumPy是Python中用于数值计算的强大库,numpy.ndarray 是它的核心数据类型,提供了高效的数值运算和广泛的数学函数。 以下是 numpy.ndarray 的…...

【二、安装centOS】
下载 地址:https://mirrors.aliyun.com/centos/ 地址 1、https://mirrors.aliyun.com/centos/7.9.2009/ 2、https://mirrors.aliyun.com/centos/7.9.2009/isos/ 3、https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/ 选哪一个 可以选择第一个࿰…...
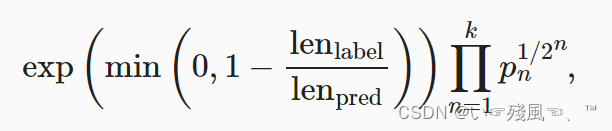
【动手学深度学习-Pytorch版】序列到序列的学习(包含NLP常用的Mask技巧)
序言 这一节是对于“编码器-解码器”模型的实际应用,编码器和解码器架构可以使用长度可变的序列作为输入,并将其转换为固定形状的隐状态(编码器实现)。本小节将使用“fra-eng”数据集(这也是《动手学习深度学习-Pytor…...

原神抽卡模拟器:无需安装也能精准规划资源?浏览器端祈愿体验全解析
原神抽卡模拟器:无需安装也能精准规划资源?浏览器端祈愿体验全解析 【免费下载链接】Genshin-Impact-Wish-Simulator Best Genshin Impact Wish Simulator Website, no need to download, 100% running on browser! 项目地址: https://gitcode.com/gh_…...

LDDC:开源歌词工具的高效解决方案
LDDC:开源歌词工具的高效解决方案 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: https://gitcode…...

终极指南:如何使用XGP-save-extractor解锁Xbox Game Pass存档迁移自由
终极指南:如何使用XGP-save-extractor解锁Xbox Game Pass存档迁移自由 【免费下载链接】XGP-save-extractor Python script to extract savefiles out of Xbox Game Pass for PC games 项目地址: https://gitcode.com/gh_mirrors/xg/XGP-save-extractor XGP-…...

下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式
下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET COMET(A Neural Framework for MT Evaluation)…...
)
RK3506 AMP 异构多核通信 RPMsg-Lite 握手卡死 (wait_for_link_up)
RK3506 AMP 异构多核通信 RPMsg-Lite 握手卡死 (wait_for_link_up) 1. 问题背景与现象 硬件平台:Rockchip RK3506 (Cortex-A7 集群 Cortex-M0 协处理器) 软件环境:Linux 6.1 (主核) 裸机/RTOS (从核 MCU),使用 RPMsg-Lite 框架进行核间通信…...

Swagger Client 完整教程:从零开始构建强大的 API 集成应用
Swagger Client 完整教程:从零开始构建强大的 API 集成应用 【免费下载链接】swagger-js Javascript library to connect to swagger-enabled APIs via browser or nodejs 项目地址: https://gitcode.com/gh_mirrors/sw/swagger-js Swagger Client 是一款功能…...

Nooploop TOFSense-M 点阵激光测距模块:从开箱到ROS集成的全栈开发指南
1. 开箱与硬件初体验 刚拿到Nooploop TOFSense-M时,这个火柴盒大小的模块确实让我有些意外——毕竟能实现0.1-12米测距能力的设备,想象中应该更笨重些。包装盒里除了主体模块,还贴心地配备了杜邦线和转接板,这对嵌入式开发者来说就…...

智能家居中枢:OpenClaw桥接Qwen3.5-9B实现语音控制图片检索
智能家居中枢:OpenClaw桥接Qwen3.5-9B实现语音控制图片检索 1. 为什么需要智能家居中的图片检索 每次家庭聚会后整理照片都让我头疼。手机相册里堆积着上千张照片,当亲友们围坐在客厅想回顾某次旅行时,"找那张在雪山前跳起来的合影&qu…...

本地AI模型开发终极指南:从零开始构建智能应用社区
本地AI模型开发终极指南:从零开始构建智能应用社区 【免费下载链接】gallery A gallery that showcases on-device ML/GenAI use cases and allows people to try and use models locally. 项目地址: https://gitcode.com/GitHub_Trending/gallery44/gallery …...

Geekble测谎模块Arduino库:GSR生理信号采集与多模态反馈
1. 项目概述Geekble_LieDetector 是一款面向嵌入式平台(典型为基于ATmega328P的Arduino兼容控制器)设计的生理信号检测与交互控制库,专用于驱动 Geekble LieDetector 模块。该模块并非传统意义上的“测谎仪”,而是一个以皮肤电导&…...