【动手学深度学习-Pytorch版】序列到序列的学习(包含NLP常用的Mask技巧)
序言
这一节是对于“编码器-解码器”模型的实际应用,编码器和解码器架构可以使用长度可变的序列作为输入,并将其转换为固定形状的隐状态(编码器实现)。本小节将使用“fra-eng”数据集(这也是《动手学习深度学习-Pytorch版》提供的数据集)进行序列到序列的学习。在d2l官方文档中有很多的内容是根据英文版直译过来的,其中有很多空乏的句子,特别是对于每个模块的描述中,下面我提供一种全新的思路来理解整个代码(不得不说沐神团队的代码绝对值得推敲~)。
这里也是按照官方给的目录架构对于整个项目复现,在复现的过程中详细理解每一行代码的作用(去除无关内容~)同时关注数据的变化,特别是在源和目标的shape变化方面。当然需要注明的是源指的是数据集中所有的英语短语,其按照batch_size的大小装入模型,同时增加了num_steps维度,也就是“时间步”【那对于区分时间步和batch_size的概念有个类似的方式便于理解:将它们映射到图像中,batch_size是每一次取出多少个样本图像,而num_steps可以理解为图像本身的维度问题】。下面将会按着官方给出的步骤进行代码复现:导包、设计编码器、设计解码器、修改交叉熵损失函数、模型训练、模型预测、使用BLEU进行模型的评估。
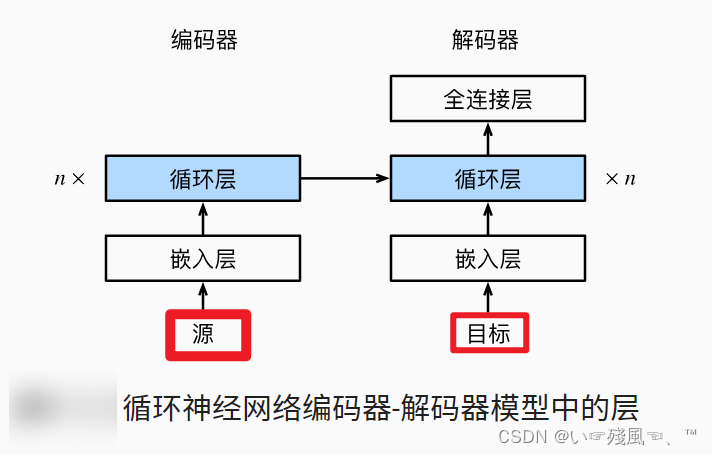
模型复现
导包【无脑导包】
# 无脑导包
import torch
import collections # 这个包还是需要注意一下
import math
from torch import nn
from d2l import torch as d2l
设计编码器
根据“编码器-解码器”的模型架构,梳理出编码器的主要任务,它的主要任务包括:
- 将某一个时刻t的输入特征向量 x t x_t xt和上一个时刻的隐状态 h t − 1 h_{t-1} ht−1转变为 h t h_t ht即 h t = f ( x t , h t − 1 ) h_t = f(x_t , h_{t-1}) ht=f(xt,ht−1)
- 编码器需要通过函数q实现把所有的隐状态转变为上下文变量:
c = q ( h 1 , . . . . , h T ) c = q( h_1,....,h_T ) c=q(h1,....,hT) - 使用嵌入层获取输入序列的每个词元的特征向量[嵌入层权重矩阵行数为vocab_size,列数是特征向量的维度]
明确了编码器的主要任务后下面来看具体的代码复现:
#@save
class Seq2SeqEncoder(d2l.Encoder):"""用于序列到序列学习的循环神经网络编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(Seq2SeqEncoder,self).__init__(**kwargs)# 实现嵌入层Embedding 将每一个词元转变成一个词向量self.embedding = nn.Embedding(vocab_size,embed_size)# print('Encoder中 self.embedding的size为:',self.embedding.size())# print('Encoder中 embed_size: ',embed_size)with open('D://pythonProject//Encoder_embed_pervir_size.txt', 'w') as f:f.write(str(embed_size))"""----------embed_size为32----------""""""这里的embed_size为每一个词元对应的特征向量的长度"""self.rnn = nn.GRU(embed_size,num_hiddens,num_layers,dropout=dropout)def forward(self, X, *args):with open('D://pythonProject//Encoder_Not_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------未进行embedding的X: torch.Size([64, 10]) batch_size * num_steps----------"""# print('Encoder中 未进行embedding前的X的size',X.size())# embedding 的形状 (vocab_size,embed_size)# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# print('Encoder中 进行embedding后的X的size',X.size())with open('D://pythonProject//Encoder_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了embedding的X: torch.Size([64, 10, 32])----------"""#torch要求在循环神经网络模型中,第一个轴对应的必须是时间步X = X.permute(1,0,2)# print('Encoder中 permute后的X的size',X.size())with open('D://pythonProject//Encoder_permute_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了permute的X: torch.Size([10, 64, 32]) 10为时间步----------"""output,state = self.rnn(X)# output的输出形状: (num_steps,batch_size,num_hiddens)# state的输出形状: (num_layers,batch_size,num_hiddens)return output,state
在上述的编码器中,forward()完成了
1、将输入值【形状为:batch_size*num_steps】输入到嵌入层Embedding,将输入的每个词元转成一个代表该词元的一个特征向量。【之所以用Embedding而不用One-Hot的原因在于:虽然One-Hot可将tokens转成稀疏矩阵便于运算,但是不适用于大批量数据的情况,容易导致运算过慢或者占用内存的情况,详细参考:一文读懂Embedding的概念,以及它和深度学习的关系】;
1-1 注意:原来X的输入形状是
torch.Size[64,10]
—>torch.Size(bach_size,num_steps]
经过Embedding后的X的形状为
torch.Size([64, 10, 32]
—>torch.Size(batch_size,num_steps,embedding_size)
即在输入的X后增加一个维度,用来作为每一个takens的特征向量
with open('D://pythonProject//Encoder_Not_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------未进行embedding的X: torch.Size([64, 10]) batch_size * num_steps----------"""# print('Encoder中 未进行embedding前的X的size',X.size())# embedding 的形状 (vocab_size,embed_size)# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# print('Encoder中 进行embedding后的X的size',X.size())with open('D://pythonProject//Encoder_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了embedding的X: torch.Size([64, 10, 32])----------"""
2、为了适应torch要求的循环神经网络模型中第一个维度需要为时间步的需求,这里做了一下permute操作,把第0个维度和第1个维度互换了一下,关于permute的详细操作可以参考:【PyTorch 两大转置函数 transpose() 和 permute()
】
permute后的矩阵形状就变成了:
torch.Size([10, 64, 32])
—>torch.size([num_steps,batch_size,embedding_size])
#torch要求在循环神经网络模型中,第一个轴对应的必须是时间步X = X.permute(1,0,2)# print('Encoder中 permute后的X的size',X.size())with open('D://pythonProject//Encoder_permute_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了permute的X: torch.Size([10, 64, 32]) 10为时间步----------"""
3、最后,编码器需要返回最后一个时间步的state隐状态和最后一个时间步的outputs。
output,state = self.rnn(X)# output的输出形状: (num_steps,batch_size,num_hiddens)# state的输出形状: (num_layers,batch_size,num_hiddens)return output,state
实例化编码器
下面通过设计一个两层门控循环单元编码器,其隐藏单元是16,给定一个小批量的输入序列X(批量大小为4,时间步为7)。同时,在完成所有时间步后,最后一层的隐状态的输出是一个张量【output由编码器的循环层返回】,形状为(时间步数,批量大小,隐藏单元数)
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape
注:这里使用的是门控循环单元GRU,最后一个时间步的多层隐状态的形状是(num_layers,batch_size,num_hiddens),如果使用LSTM 则state中还应该包含记忆单元信息。
设计解码器
编码器输出的整个上下文信息变量C需要作用于整个输入序列 x 1 , . . . , x r x_1,...,x_r x1,...,xr,对输入序列进行编码。解码器的输出 y t ′ y_t' yt′与上下文变量C输出子序列 y 1 , . . . , ( y t ′ − 1 ) y_1,...,(yt'-1) y1,...,(yt′−1)的关系:
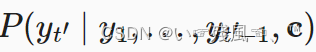
且隐状态与上一步的隐状态、上下文变量和上一个时间步的输出有关。在获得解码器的隐状态后,可以使用输出层+softmax操作来计算时间步 t ′ t' t′时输出 y t ′ y_t' yt′的概率分布:
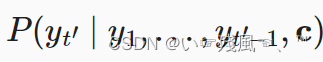
解码器的主要任务包括:
- 直接使用编码器的最后一个时间步的隐状态来初始化解码器的隐状态及两者具有相同的隐藏层和隐藏单元
- 为了让上下文信息更好包含更多的信息,可以用上下文变量C在所有的时间步与解码器的输入进行拼接
- 为了输出预测词元的概率分布,在最后一层采用全连接层来变换隐状态
class Seq2SeqDecoder(d2l.Decoder):"""用于序列到序列学习的循环神经网络解码器"""def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout=0,**kwargs):super(Seq2SeqDecoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size,embed_size)with open('D://pythonProject//Decoder_vocab_size.txt', 'w') as f:f.write(str(vocab_size))"""----------decoder的vocab_size为201----------"""with open('D://pythonProject//Decoder_embed_size.txt', 'w') as f:f.write(str(embed_size))"""----------decoder的embed_size为32----------"""self.rnn = nn.GRU(embed_size+num_hiddens,num_hiddens,num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens,vocab_size)def init_state(self,enc_outputs,*args):# enc_outputs[0]为编码器的输出# enc_outputs[1]为编码器最后一层输出的隐变量return enc_outputs[1]def forward(self, X, state):# print('Decoder中 未进行embedding的X的形状:',X.size())with open('D://pythonProject//Decoder_X_size.txt', 'w') as f:f.write(str(X.size()))"""Decoder的X的大小:torch.Size([25, 10])"""# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X).permute(1,0,2)with open('D://pythonProject//Decoder_X_embed_permute.txt', 'w') as f:f.write(str(X.size()))"""Decoder的X_embed_permute的大小:torch.Size([10, 25, 32])"""# 广播context,使其具有与X相同的num_steps 即X.shape[0]context = state[-1].repeat(X.shape[0], 1, 1)X_and_Context = torch.cat((X,context),2)output,state = self.rnn(X_and_Context,state)output = self.dense(output).permute(1,0,2)# output的形状:(batch_size,num_steps,vocab_size)# state的形状:(num_layers,batch_size,num_hiddens)return output, state
在初始化__init__()函数中完成了将输入维度(batch_size,num_steps)进行Embedding操作,其输出维度变为了(batch_size,num_steps,num_embedding)
同时,将embed+hiddens的大小同时送入GRU的输入层,同时不使用dropout操作。最后,初始化输出层要放入的Linear全连接层。
forward()函数——前向传播中,首先对X进行embedding操作,并进行了permulate()将第一个维度变为了num_steps。将编码器得到的state隐状态通过repeat成与X第一维度num_steps相同后利用广播机制形成最终含有上下文信息的Context并最终通过torch,cat连接到X中【维度选用2】。最后利用了rnn输出output和最后的隐状态state。
实例化解码器
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, state.shape
有关于model.train()和model.eval()的区别可以参考:torch 中的 model.eval() 是什么?
修改损失函数
# 修改损失函数:将填充词元的预测排除在损失函数的计算之外
"""下面的sequence_mask函数 通过零值化屏蔽不相关的项"""
#@save
def sequence_mask(X,valid_len,value=0):# print('mask X的形状:',X.size())with open('D://pythonProject//Mask_X_size.txt', 'w') as f:f.write(str(X.size()))"""损失函数中的Mask_X_size的大小:torch.Size([25, 10]) 显然是没有进行Embedding的""""""在序列中屏蔽不相干的项"""maxlen = X.size(1)mask = torch.arange((maxlen),dtype=torch.float32,device=X.device)[None,:]<valid_len[:,None]X[~mask] = valuereturn X
X = torch.tensor([[1,2,3],[4,5,6]])
res = sequence_mask(X,torch.tensor([1,2]))
print('valid_len 分别为 1 和 2: ',res)同时可以使用非0值替换要屏蔽的项
X = torch.ones(2,3,4)
res = sequence_mask(X,torch.tensor([1,2]),value=-1)
我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。
最初,所有预测词元的掩码都设置为1。 一旦给定了有效长度,与填充
词元对应的掩码将被设置为0。 最后,将所有词元的损失乘以掩码,以
过滤掉损失中填充词元产生的不相关预测。
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数"""# pred的形状:(batch_size,num_steps,vocab_size)# label的形状:(batch_size,num_steps)# valid_len的形状:(batch_size,)def forward(self, pred, label, valid_len):# 预测词元的掩码都设置为1weights = torch.ones_like(label)# 一旦给定了有效长度,与填充# 词元对应的掩码将被设置为0。weights = sequence_mask(weights, valid_len)self.reduction='none'unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)weighted_loss = (unweighted_loss * weights).mean(dim=1)return weighted_loss
训练
在训练部分,需要在原始的编码器输出序列前加入特定的序列开始词元 同时作为解码器的输入—>这种操作被称为强制教学。
"""在训练部分,需要在原始的编码器输出序列前加入特定的序列开始词元<bos> 同时作为解码器的输入--->这种操作被称为强制教学"""
#@save
def train_seq2seq(net,data_iter,lr,num_epochs,tgt_vocab,device):"""训练序列到序列模型"""def xavier_init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)if type(m) == nn.GRU:for param in m._flat_weights_names:if "weight" in param:nn.init.xavier_uniform_(m._parameters[param])net.apply(xavier_init_weights)net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)loss = MaskedSoftmaxCELoss()"""注意:这里使用的是net.train()"""net.train()animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[10, num_epochs])for epoch in range(num_epochs):timer = d2l.Timer()metric = d2l.Accumulator(2) # 训练损失总和,词元数量for batch in data_iter:optimizer.zero_grad()X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]# print('train-X:',X,'train-X_valid_len:',X_valid_len)# print('train-Y:',Y,'train-Y_valid_len:',Y_valid_len)with open('D://pythonProject//X_valid_len.txt', 'w') as f:f.write(str(X_valid_len))"""tensor([4, 4, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,5])---------->它的总长度为batch_size=25(最后一个batch_size) 之前的都是64"""with open('D://pythonProject//Y_valid_len.txt', 'w') as f:f.write(str(Y_valid_len))"""tensor([4, 4, 3, 5, 5, 4, 5, 3, 4, 4, 5, 4, 4, 4, 7, 5, 5, 4, 4, 3, 4, 4, 3, 3,5])---------->它的总长度为batch_size=25(最后一个batch_size) 之前的都是64"""bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学Y_hat, _ = net(X, dec_input, X_valid_len)l = loss(Y_hat, Y, Y_valid_len)l.sum().backward() # 损失函数的标量进行“反向传播”d2l.grad_clipping(net, 1)num_tokens = Y_valid_len.sum()optimizer.step()with torch.no_grad():metric.add(l.sum(), num_tokens)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, (metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')
在机器翻译数据集上创建和训练一个循环神经网络‘编码器-解码器‘模型用于序列到序列的学习
这里需要注意的是在decoder训练的时候丢进去的数据直接是真实的label值。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)预测
为了采用一个接着一个词元的方式预测输出序列, 每个解码器当前时间步的输入都将来自于前一时间步的预测词元。
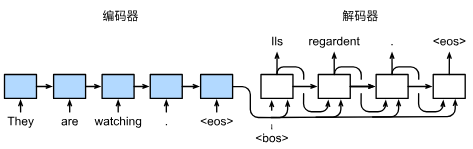
预测阶段的主要任务是:
- 将net设置为评估模式
- 在tokens后面加入< eos >;如果长度不够num_steps时在句子后填充< pad >拉长句子
- 将源tokens增加维度0,使得它变成一个二维向量
- 将编码器的输出(该输出包括outputs和state两个部分)传入解码器的初始化隐状态函数中初始化解码器的隐状态
- 将编码器的输入特征X转变成二维特征向量
- 预测过程:①利用预测最高可能性的词元作为解码器在下一个时间步的输入;②将解码器的输出转变成二维向量,如果预测的词元为< eos >则停止这个短句的预测;③最后利用join函数形成最终的预测短句
# 预测
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,device, save_attention_weights=False):"""序列到序列模型的预测"""# 在预测时将net设置为评估模式net.eval()src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]enc_valid_len = torch.tensor([len(src_tokens)], device=device)# 增加<pad>if len(src_tokens) > num_steps:with open('D://pythonProject//predict_seq2seq-truncate.txt', 'w') as f:f.write(str('截断'))else:with open('D://pythonProject//predict_seq2seq-pad.txt', 'w') as f:f.write(str('拉长'))src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])# 添加批量轴--->增肌维度,将"""input是一维,则dim=0时数据为行方向扩,dim=1时为列方向扩""""""这里的src_tokens是一个list对象"""print('len(src_tokens): ',len(src_tokens)) # len of src_tokens == 10enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)# enc_X的大小为 torch.Size([1, 10])"""这里将src_tokens从list对象转成了一个tensor,增加了维度0"""with open('D://pythonProject//predict_seq2seq-enc_X-enc_X.txt', 'w') as f:f.write(str(enc_X.size()))enc_outputs = net.encoder(enc_X, enc_valid_len)dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)# 添加批量轴"""这里将tgt_vocab从list对象转成了一个tensor,增加了维度0"""dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)output_seq, attention_weight_seq = [], []for _ in range(num_steps):Y, dec_state = net.decoder(dec_X, dec_state)# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入dec_X = Y.argmax(dim=2) #返回可能性最大词元的索引位置pred = dec_X.squeeze(dim=0).type(torch.int32).item()print('pred:--->', pred)# 保存注意力权重(稍后讨论)if save_attention_weights:attention_weight_seq.append(net.decoder.attention_weights)# 一旦序列结束词元被预测,输出序列的生成就完成了if pred == tgt_vocab['<eos>']:print('pred:--->eos',pred)breakoutput_seq.append(pred)return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
利用BLEU函数进行预测序列的评估
BLEU函数:
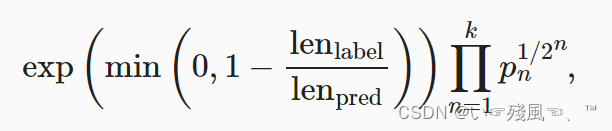
正如上述式子所列,当预测的长度 l e n p r e d len_{pred} lenpred小于真实的label长度 l e n l a b e l len_{label} lenlabel时说明预测成功的可能性很低,此时整个分式就变得很大,最后出来的值就会很小,这就在一定程度上加强了短句子的权重惩罚。同时,如果后面的连乘加重了长句子的权重惩罚。
# 预测序列的评估
def bleu(pred_seq, label_seq, k): #@save"""计算BLEU"""pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')len_pred, len_label = len(pred_tokens), len(label_tokens)score = math.exp(min(0, 1 - len_label / len_pred))for n in range(1, k + 1):num_matches, label_subs = 0, collections.defaultdict(int)for i in range(len_label - n + 1):label_subs[' '.join(label_tokens[i: i + n])] += 1for i in range(len_pred - n + 1):if label_subs[' '.join(pred_tokens[i: i + n])] > 0:num_matches += 1label_subs[' '.join(pred_tokens[i: i + n])] -= 1score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))return score
在“fra-eng”数据集上做预测
"""最后,利用训练好的循环神经网络“编码器-解码器”模型, 将几个英语句子翻译成法语,并计算BLEU的最终结果。"""
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, attention_weight_seq = predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device)print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')省流—全部代码
注意:这里为了debug,我增加了很多写文件的操作,主要是观察每一个向量的形状变化,具体的结果已经通过注释的方式写到了下面代码中,仅做参考~
"""模块torch已被修改
def read_data_nmt():# Load the English-French dataset.data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='UTF-8') as f:return f.read()
"""
""" 代码中出现的torch.Size([25, 10, 32])是因为将原始的数据按照batch_size进行划分最后一个batch的大小就是25
"""
# 无脑导包
import torch
import collections # 这个包还是需要注意一下
import math
from torch import nn
from d2l import torch as d2l# 实现Encoder编码器部分
"""
内容部分:
编码器的任务主要包括:将某一个时刻t的输入特征向量x_t和上一个时刻的隐状态h_(t-1)转变为h_t即h_t = f(x_t , h_(t-1))编码器需要通过函数q实现把所有的隐状态转变为上下文变量:c = q( h_1,....,h_T )使用嵌入层获取输入序列的每个词元的特征向量[嵌入层权重矩阵行数为vocab_size,列数是特征向量的维度]采用GRU实现编码器
"""#@save
class Seq2SeqEncoder(d2l.Encoder):"""用于序列到序列学习的循环神经网络编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(Seq2SeqEncoder,self).__init__(**kwargs)# 实现嵌入层Embedding 将每一个词元转变成一个词向量self.embedding = nn.Embedding(vocab_size,embed_size)# print('Encoder中 self.embedding的size为:',self.embedding.size())# print('Encoder中 embed_size: ',embed_size)with open('D://pythonProject//Encoder_embed_pervir_size.txt', 'w') as f:f.write(str(embed_size))"""----------embed_size为32----------""""""这里的embed_size为每一个词元对应的特征向量的长度"""self.rnn = nn.GRU(embed_size,num_hiddens,num_layers,dropout=dropout)def forward(self, X, *args):with open('D://pythonProject//Encoder_Not_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------未进行embedding的X: torch.Size([64, 10]) batch_size * num_steps----------"""# print('Encoder中 未进行embedding前的X的size',X.size())# embedding 的形状 (vocab_size,embed_size)# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# print('Encoder中 进行embedding后的X的size',X.size())with open('D://pythonProject//Encoder_embed_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了embedding的X: torch.Size([64, 10, 32])----------"""#torch要求在循环神经网络模型中,第一个轴对应的必须是时间步X = X.permute(1,0,2)# print('Encoder中 permute后的X的size',X.size())with open('D://pythonProject//Encoder_permute_size.txt', 'w') as f:f.write(str(X.size()))"""----------进行了permute的X: torch.Size([10, 64, 32]) 10为时间步----------"""output,state = self.rnn(X)# output的输出形状: (num_steps,batch_size,num_hiddens)# state的输出形状: (num_layers,batch_size,num_hiddens)return output,state# 编码器实例化
"""
输入:
layer: 2层
hiddens: 16个
batch: 4
steps: 7
输出:
tensor[时间步数,批量大小,隐藏单元数]
"""
encoder = Seq2SeqEncoder(vocab_size=10,embed_size=8,num_hiddens=16,num_layers=2,dropout=0)
X = torch.zeros((4,7),dtype=torch.long)
output,state = encoder(X) # X的维度对应于forwoard中的X的维度
# print('output.shape: ',output.shape)
with open('D://pythonProject//Encoder_output_size.txt', 'w') as f:f.write(str(output.shape))
"""----------output的形状: torch.Size([7, 4, 16]) 10为时间步----------""""""这里使用的是门控循环单元GRU,最后一个时间步的多层隐状态的形状是(num_layers,batch_size,num_hiddens)"""
"""如果使用LSTM 则state中还应该包含记忆单元信息"""
# 实现Decoder部分
"""编码器输出的整个上下文信息变量C需要作用于整个输入序列x_1,...,x_r,对输入序列进行编码"""
"""解码器输出(star)y取决于输出子序列y1,...,(star)y_(t-1),C"""
"""P((star)y|y1,...,(star)y_(t-1),C)"""
"""
·使用解码器时,我们直接使用编码器的最后一个时间步的隐状态来初始化解码器的隐状态--->两者应该具有相同的隐藏层和隐藏单元
·为了让上下文信息更好包含更多的信息,可以用上下文变量C在所有的时间步与解码器的输入进行拼接
·为了输出预测词元的概率分布,在最后一层采用全连接层来变换隐状态
"""
class Seq2SeqDecoder(d2l.Decoder):"""用于序列到序列学习的循环神经网络解码器"""def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,dropout=0,**kwargs):super(Seq2SeqDecoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size,embed_size)with open('D://pythonProject//Decoder_vocab_size.txt', 'w') as f:f.write(str(vocab_size))"""----------decoder的vocab_size为201----------"""with open('D://pythonProject//Decoder_embed_size.txt', 'w') as f:f.write(str(embed_size))"""----------decoder的embed_size为32----------"""self.rnn = nn.GRU(embed_size+num_hiddens,num_hiddens,num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens,vocab_size)def init_state(self,enc_outputs,*args):# enc_outputs[0]为编码器的输出# enc_outputs[1]为编码器最后一层输出的隐变量return enc_outputs[1]def forward(self, X, state):# print('Decoder中 未进行embedding的X的形状:',X.size())with open('D://pythonProject//Decoder_X_size.txt', 'w') as f:f.write(str(X.size()))"""Decoder的X的大小:torch.Size([25, 10])"""# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X).permute(1,0,2)with open('D://pythonProject//Decoder_X_embed_permute.txt', 'w') as f:f.write(str(X.size()))"""Decoder的X_embed_permute的大小:torch.Size([10, 25, 32])"""# 广播context,使其具有与X相同的num_steps 即X.shape[0]context = state[-1].repeat(X.shape[0], 1, 1)X_and_Context = torch.cat((X,context),2)output,state = self.rnn(X_and_Context,state)output = self.dense(output).permute(1,0,2)# output的形状:(batch_size,num_steps,vocab_size)# state的形状:(num_layers,batch_size,num_hiddens)return output, state# 实例化解码器
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, state.shape# 修改损失函数:将填充词元的预测排除在损失函数的计算之外
"""下面的sequence_mask函数 通过零值化屏蔽不相关的项"""
#@save
def sequence_mask(X,valid_len,value=0):# print('mask X的形状:',X.size())with open('D://pythonProject//Mask_X_size.txt', 'w') as f:f.write(str(X.size()))"""损失函数中的Mask_X_size的大小:torch.Size([25, 10]) 显然是没有进行Embedding的""""""在序列中屏蔽不相干的项"""maxlen = X.size(1)mask = torch.arange((maxlen),dtype=torch.float32,device=X.device)[None,:]<valid_len[:,None]X[~mask] = valuereturn X
X = torch.tensor([[1,2,3],[4,5,6]])
res = sequence_mask(X,torch.tensor([1,2]))
print('valid_len 分别为 1 和 2: ',res)# 同时可以使用非0值替换要屏蔽的项
X = torch.ones(2,3,4)
res = sequence_mask(X,torch.tensor([1,2]),value=-1)
"""
我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。
最初,所有预测词元的掩码都设置为1。 一旦给定了有效长度,与填充
词元对应的掩码将被设置为0。 最后,将所有词元的损失乘以掩码,以
过滤掉损失中填充词元产生的不相关预测。
"""
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数"""# pred的形状:(batch_size,num_steps,vocab_size)# label的形状:(batch_size,num_steps)# valid_len的形状:(batch_size,)def forward(self, pred, label, valid_len):# 预测词元的掩码都设置为1weights = torch.ones_like(label)# 一旦给定了有效长度,与填充# 词元对应的掩码将被设置为0。weights = sequence_mask(weights, valid_len)self.reduction='none'unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)weighted_loss = (unweighted_loss * weights).mean(dim=1)return weighted_loss
# 使用三个相同的序列 来进行代码健全性检查 分别指定这些序列的有效长度是4,2,0
# 得出的损失结果为 第一个序列是第二个序列的两倍,第三个序列的损失直接为0# 训练
"""在训练部分,需要在原始的编码器输出序列前加入特定的序列开始词元<bos> 同时作为解码器的输入--->这种操作被称为强制教学"""
#@save
def train_seq2seq(net,data_iter,lr,num_epochs,tgt_vocab,device):"""训练序列到序列模型"""def xavier_init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)if type(m) == nn.GRU:for param in m._flat_weights_names:if "weight" in param:nn.init.xavier_uniform_(m._parameters[param])net.apply(xavier_init_weights)net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)loss = MaskedSoftmaxCELoss()"""注意:这里使用的是net.train()"""net.train()animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[10, num_epochs])for epoch in range(num_epochs):timer = d2l.Timer()metric = d2l.Accumulator(2) # 训练损失总和,词元数量for batch in data_iter:optimizer.zero_grad()X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]# print('train-X:',X,'train-X_valid_len:',X_valid_len)# print('train-Y:',Y,'train-Y_valid_len:',Y_valid_len)with open('D://pythonProject//X_valid_len.txt', 'w') as f:f.write(str(X_valid_len))"""tensor([4, 4, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,5])---------->它的总长度为batch_size=25(最后一个batch_size) 之前的都是64"""with open('D://pythonProject//Y_valid_len.txt', 'w') as f:f.write(str(Y_valid_len))"""tensor([4, 4, 3, 5, 5, 4, 5, 3, 4, 4, 5, 4, 4, 4, 7, 5, 5, 4, 4, 3, 4, 4, 3, 3,5])---------->它的总长度为batch_size=25(最后一个batch_size) 之前的都是64"""bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学Y_hat, _ = net(X, dec_input, X_valid_len)l = loss(Y_hat, Y, Y_valid_len)l.sum().backward() # 损失函数的标量进行“反向传播”d2l.grad_clipping(net, 1)num_tokens = Y_valid_len.sum()optimizer.step()with torch.no_grad():metric.add(l.sum(), num_tokens)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, (metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')
"""在机器翻译数据集上创建和训练一个循环神经网络‘编码器-解码器‘模型用于序列到序列的学习"""
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)# 预测
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,device, save_attention_weights=False):"""序列到序列模型的预测"""# 在预测时将net设置为评估模式net.eval()src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]enc_valid_len = torch.tensor([len(src_tokens)], device=device)# 增加<pad>if len(src_tokens) > num_steps:with open('D://pythonProject//predict_seq2seq-truncate.txt', 'w') as f:f.write(str('截断'))else:with open('D://pythonProject//predict_seq2seq-pad.txt', 'w') as f:f.write(str('拉长'))src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])# 添加批量轴--->增肌维度,将"""input是一维,则dim=0时数据为行方向扩,dim=1时为列方向扩""""""这里的src_tokens是一个list对象"""print('len(src_tokens): ',len(src_tokens)) # len of src_tokens == 10enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)# enc_X的大小为 torch.Size([1, 10])"""这里将src_tokens从list对象转成了一个tensor,增加了维度0"""with open('D://pythonProject//predict_seq2seq-enc_X-enc_X.txt', 'w') as f:f.write(str(enc_X.size()))enc_outputs = net.encoder(enc_X, enc_valid_len)dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)# 添加批量轴"""这里将tgt_vocab从list对象转成了一个tensor,增加了维度0"""dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)output_seq, attention_weight_seq = [], []for _ in range(num_steps):Y, dec_state = net.decoder(dec_X, dec_state)# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入dec_X = Y.argmax(dim=2) #返回可能性最大词元的索引位置pred = dec_X.squeeze(dim=0).type(torch.int32).item()print('pred:--->', pred)# 保存注意力权重(稍后讨论)if save_attention_weights:attention_weight_seq.append(net.decoder.attention_weights)# 一旦序列结束词元被预测,输出序列的生成就完成了if pred == tgt_vocab['<eos>']:print('pred:--->eos',pred)breakoutput_seq.append(pred)return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
# 预测序列的评估
def bleu(pred_seq, label_seq, k): #@save"""计算BLEU"""pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')len_pred, len_label = len(pred_tokens), len(label_tokens)score = math.exp(min(0, 1 - len_label / len_pred))for n in range(1, k + 1):num_matches, label_subs = 0, collections.defaultdict(int)for i in range(len_label - n + 1):label_subs[' '.join(label_tokens[i: i + n])] += 1for i in range(len_pred - n + 1):if label_subs[' '.join(pred_tokens[i: i + n])] > 0:num_matches += 1label_subs[' '.join(pred_tokens[i: i + n])] -= 1score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))return score
"""最后,利用训练好的循环神经网络“编码器-解码器”模型, 将几个英语句子翻译成法语,并计算BLEU的最终结果。"""
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, attention_weight_seq = predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device)print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')相关文章:
【动手学深度学习-Pytorch版】序列到序列的学习(包含NLP常用的Mask技巧)
序言 这一节是对于“编码器-解码器”模型的实际应用,编码器和解码器架构可以使用长度可变的序列作为输入,并将其转换为固定形状的隐状态(编码器实现)。本小节将使用“fra-eng”数据集(这也是《动手学习深度学习-Pytor…...

AUTOSAR 面试知识回顾
如果答不上来,就讲当时做了什么 1. Ethernet基础: 硬件接口: ECU到PHY: data 是MII总线, 寄存器控制是SMI总线【MDCMDIO两根线, half duplex】PHY输出(100BASE-T1): MDI总线,2 wire 【T1: twisted 1 pair …...
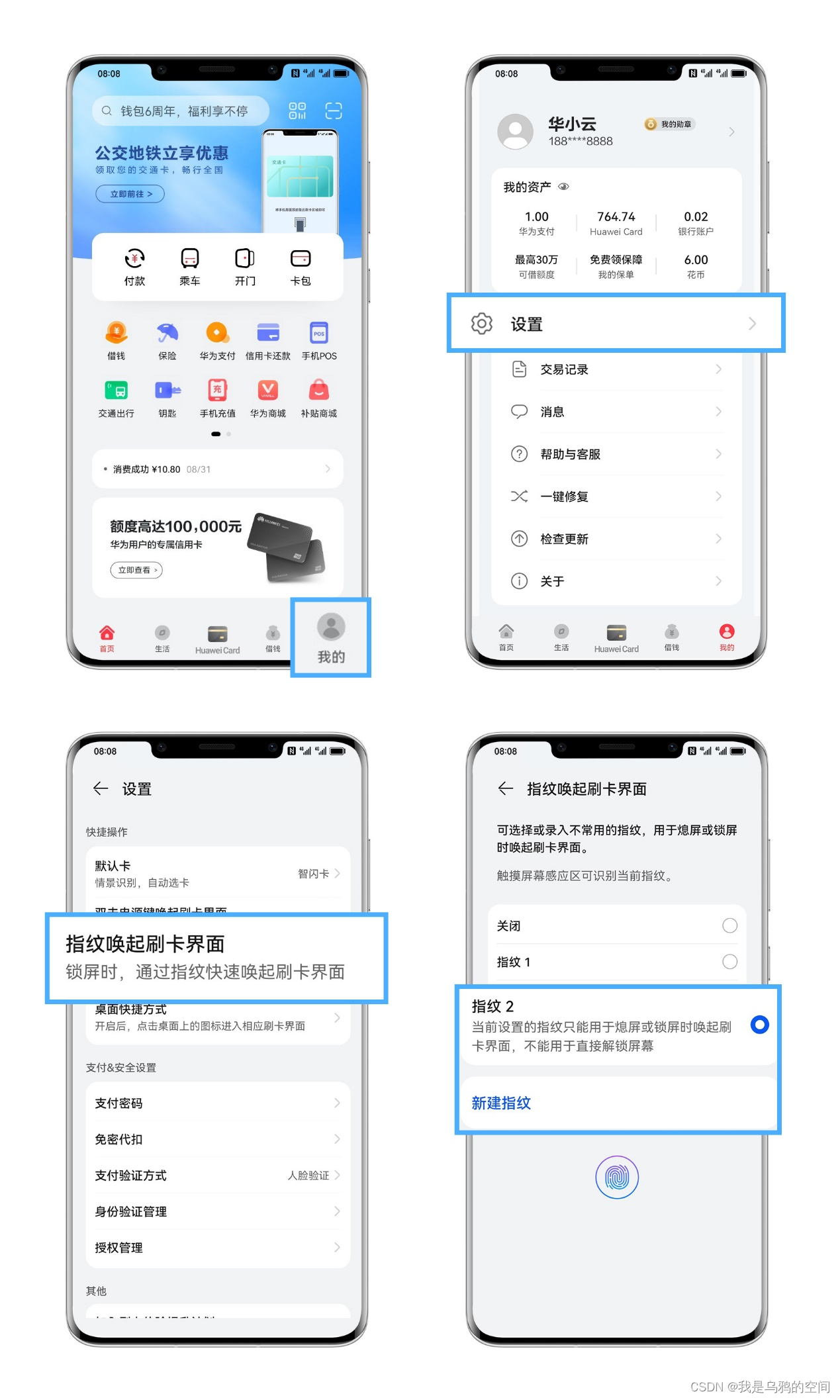
华为NFC设置教程(门禁卡/公交卡/校园卡等)
今天把华为NFC设置教程分享给大家 出门带门禁卡、校园卡、银行卡、身份证……东西又多,携带又麻烦,还容易搞丢,有没有一种方法可以把它们都装下?有!只要一部手机,出门不带卡包,各种证件&#x…...
基于微信小程序的音乐播放器设计与实现(源码+lw+部署文档+讲解等)
前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 👇🏻…...
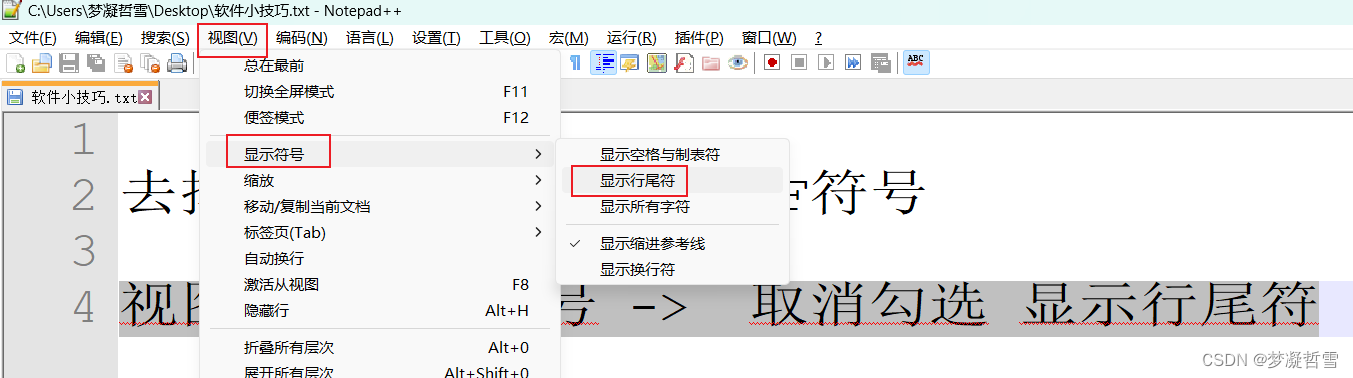
如何取消显示Notepad++每行显示的CRLF符号
新电脑中重新安装了Nodepad,打开记事本后发现出现了许多黑底的CR|LF标记,特别碍眼。 如何取消呢? 视图 -> 显示符号 -> 取消勾选 显示行尾符操作步骤 预期效果...
数据结构与算法之时间复杂度和空间复杂度(C语言版)
1. 时间复杂度 1.1 概念 简而言之,算法中的基本操作的执行次数,叫做算法的时间复杂度。也就是说,我这个程序执行了多少次,时间复杂度就是多少。 比如下面这段代码的执行次数: void Func1(int N) {int count 0;for…...

TLS/SSL(十) session缓存、ticket 票据、TLS 1.3的0-RTT
一 TLS优化手段 TLS 为了提升握手速度而提出优化手段,主要是减少TLS握手中RTT消耗的时间关于session cache和session ticket,nginx关于ssl握手的地方都有影子 [指令] https面经 ① session 缓存 resume: 重用,复用 案例: 第二次访问www.baidu.com 说明&#x…...
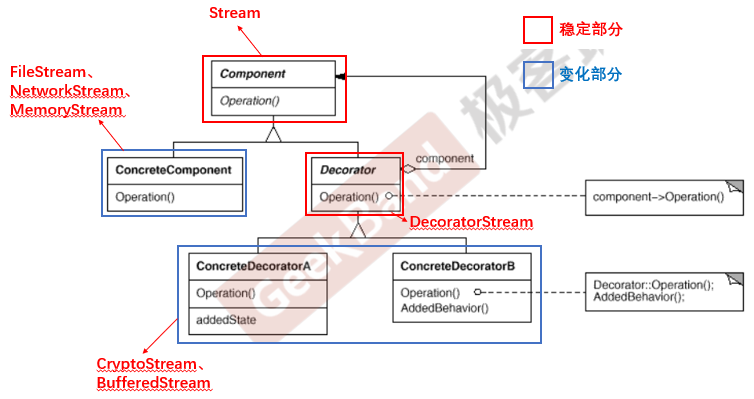
C++设计模式_06_Decorator 装饰模式
本篇将会介绍Decorator 装饰模式,它是属于一个新的类别,按照C设计模式_03_模板方法Template Method中介绍的划分为“单一职责”模式。 “单一职责”模式讲的是在软件组件的设计中,如果责任划分的不清晰,使用继承得到的结果往往是随…...
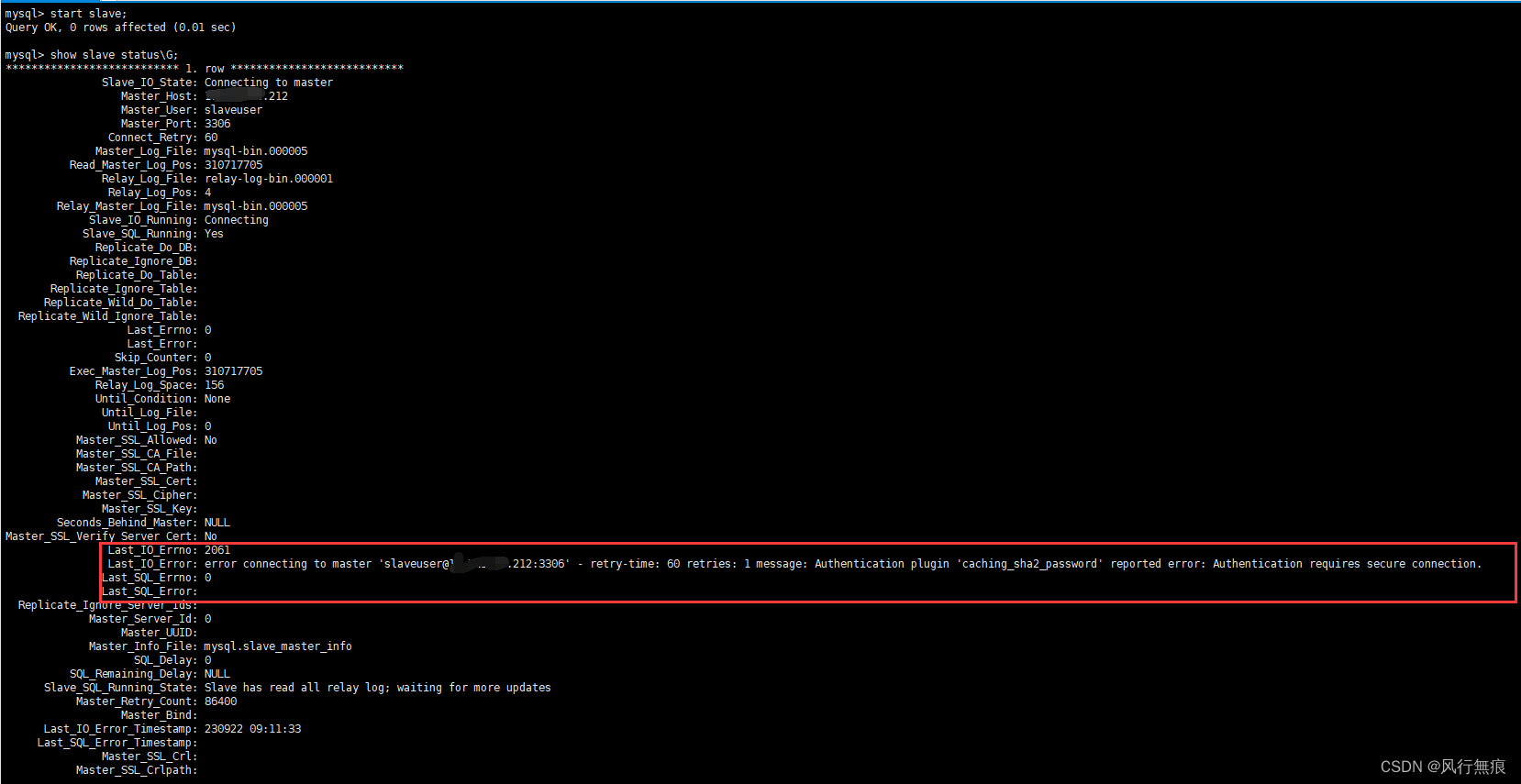
MySQL 8.0数据库主从搭建和问题处理
错误处理: 在从库通过start slave启动主从复制时出现报错 Last_IO_Error: error connecting to master slaveuser10.115.30.212:3306 - retry-time: 60 retries: 1 message: Authentication plugin caching_sha2_password reported error: Authentication require…...

公众号迁移多久可以完成?
公众号账号迁移的作用是什么?只能变更主体吗?长期以来,由于部分公众号在注册时,主体不准确的历史原因,或者公众号主体发生合并、分立或业务调整等现实状况,在公众号登记主体不能对应实际运营人的情况下&…...
使用)
Spring Cloud Stream Kafka(3.2.2版本)使用
问题 正在尝试只用Spring Cloud Stream Kafka。 步骤 配置 spring:cloud:function:definition: project2Building stream:kafka:binder:brokers: xxxx:9002configuration:enable.auto.commit: falsesession.timeout.ms: 30000max.poll.records: 30allow.auto.create.top…...

8位微控制器上的轻量级SM2加密算法实现:C语言详细指南与完整代码解析
引言 在当今的数字化世界中,安全性是每个系统的核心。无论是智能家居、医疗设备还是工业自动化,每个设备都需要确保数据的安全性和完整性。对于许多应用来说,使用高级的微控制器或处理器可能是不切实际的,因为它们可能会增加成本…...
neo4j下载安装配置步骤
目录 一、介绍 简介 Neo4j和JDK版本对应 二、下载 官网下载 直接获取 三、解压缩安装 四、配置环境变量 五、启动测试 一、介绍 简介 Neo4j是一款高性能的图数据库,专门用于存储和处理图形数据。它采用节点、关系和属性的图形结构,非常适用于…...

【机组】计算机系统组成课程笔记 第二章 计算机中的信息表示
2.1 无符号数和有符号数 2.1.1 无符号数 没有符号的数,其实就是非负数。在计算机中用字节码表示,目前最常用的是八位和十六位的。 2.1.2 有符号数 将正负符号数字化,0代表 ,1代表 - ,并把代表符号的数字放在有效数…...
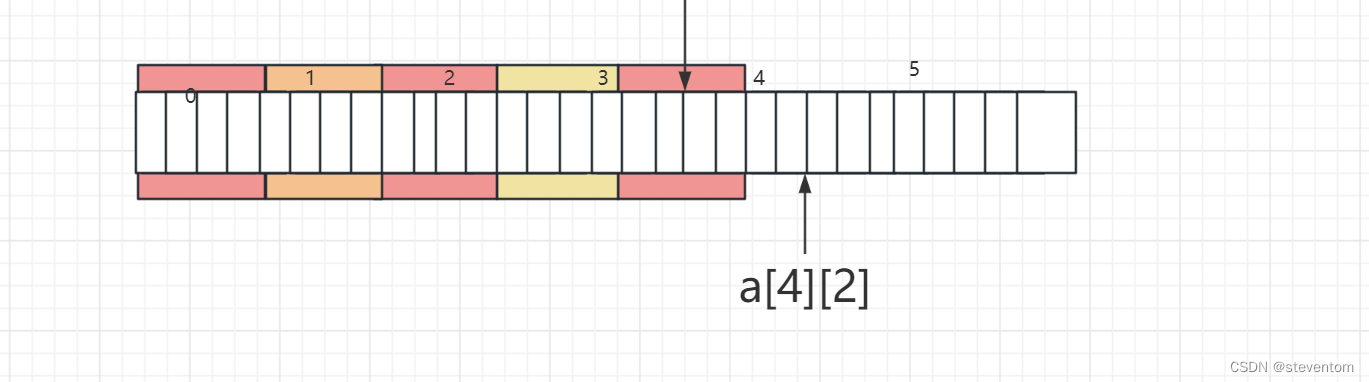
指针笔试题详解
个人主页:点我进入主页 专栏分类:C语言初阶 C语言程序设计————KTV C语言小游戏 C语言进阶 C语言刷题 欢迎大家点赞,评论,收藏。 一起努力,一起奔赴大厂。 目录 1.前言 2.指针题写出下列程序的结…...

MySQL 日志管理、备份与恢复
目录 1 数据备份的重要性 2 MySQL 日志管理 3 备份类型 3.1 数据备份的分类 3.2 备份方式比较 3.3 合理值区间 3.4 常见的备份方法 4 MySQL 完全备份与恢复 4.1 MySQL 完全备份 5 mysqldump 备份与恢复 5.1 MySQL 完全恢复 6 MySQL 增量备份与恢复 6.1 MySQL 增量…...
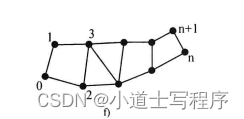
vtk- 数据类型(一) 三角链实例代码
三角链实例代码 #include <iostream> #include <string> #include <regex> #include "tuex.h" #include "vtkCylinderSource.h" #include "vtkPolyDataMapper.h" #include "vtkActor.h" #include "vtkRendere…...
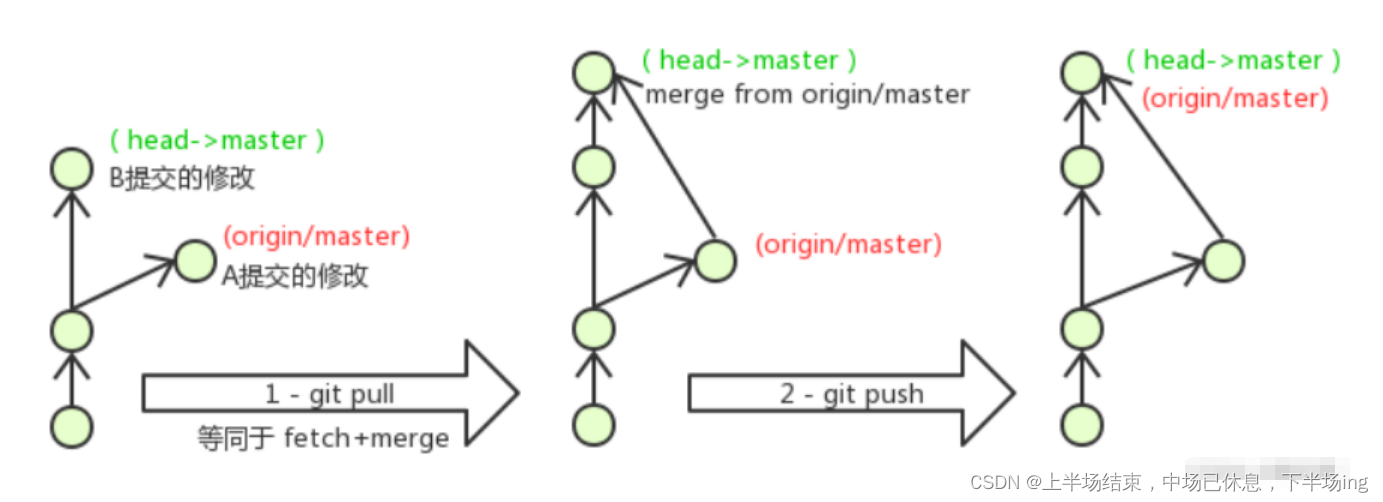
Git大全
目录 一、Git概述 1.1Git简介 1.2Git工作流程图 1.3查看Git的版本 1.4 Git 使用前配置 1.5为常用指令配置别名(可选) 1.5.1打开用户目录,创建 .bashrc 文件 1.5.2在 .bashrc 文件中输入如下内容: 1.5.3打开gitBash,执行…...

Touch命令使用指南:创建、更新和修改文件时间戳
文章目录 教程:touch命令的使用指南一、介绍1.1 什么是touch命令?1.2 touch命令的作用1.3 touch命令的语法 二、基本用法2.1 创建新文件2.2 更新文件时间戳2.3 创建多个文件2.4 修改文件访问时间2.5 修改文件修改时间2.6 修改文件创建时间 三、高级用法3…...

Windows开启 10 Telnet
在Windows 10中,Telnet客户端默认是不安装的。要在Windows 10上使用Telnet客户端,您需要手动启用它。以下是启用Telnet客户端的步骤: 打开控制面板。您可以通过在开始菜单中搜索"控制面板"来找到它。在控制面板中,选择…...

实战演练:基于快马生成利用claude code重构低质python代码的完整案例
今天想和大家分享一个实战案例:如何用Claude Code重构低质Python代码。这个项目完全在InsCode(快马)平台上完成,从生成到测试一气呵成,特别适合想学习代码重构技巧的开发者。 项目背景 最近接手了一个遗留项目,里面有个处理用户数…...
,OpenClaw Auto-Dream 实战从入门到精通,收藏这一篇就够了!)
让 AI Agent “睡觉”整理记忆(非常详细),OpenClaw Auto-Dream 实战从入门到精通,收藏这一篇就够了!
你有没有遇到过这样的情况:辛辛苦苦教会了 AI Agent 你的工作习惯和项目背景,关掉窗口、重启会话后,它又变回了一张白纸?这是当前所有基于 LLM(大语言模型)的 Agent 面临的核心痛点——“聊完就忘”。2026 …...

UniApp 集成 Cesium 实战:RenderJS 通信优化与性能调优
1. UniApp集成Cesium的挑战与解决方案 在移动端开发轻量级GIS应用时,很多开发者会选择UniApp作为跨平台框架,同时利用Cesium实现三维地图渲染。但实际集成过程中,最让人头疼的就是性能问题。我去年做过一个林业巡检项目,需要在手机…...

3步掌握Blender 3MF插件:轻松实现3D打印文件无缝导入导出
3步掌握Blender 3MF插件:轻松实现3D打印文件无缝导入导出 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 想要在Blender中直接处理3D打印文件吗?B…...

构建包容性界面:Vant Weapp无障碍设计全流程解析
构建包容性界面:Vant Weapp无障碍设计全流程解析 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp 一、设计理念:无障碍设计的核心价值 无障碍设计不是可选功能,而…...

OpenCore Legacy Patcher:让旧Mac重获新生的完整方案
OpenCore Legacy Patcher:让旧Mac重获新生的完整方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当您的Mac被官方系统更新拒之门外时…...

如何快速上手AICoverGen:免费制作专业级AI翻唱歌曲的完整指南
如何快速上手AICoverGen:免费制作专业级AI翻唱歌曲的完整指南 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen …...

TCC-G15散热控制实战指南:释放Dell游戏本性能潜力
TCC-G15散热控制实战指南:释放Dell游戏本性能潜力 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 一、问题发现:游戏本散热困境的技术根…...

数字记忆守护者:WeChatMsg让微信聊天记录成为永恒的时光胶囊
数字记忆守护者:WeChatMsg让微信聊天记录成为永恒的时光胶囊 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we…...

看了Claude Code泄露的源码,发现4个意想不到的秘密......
这两天,Claude Code的源码在网上传得飞起。谁都没想到,程序员的一次疏漏,就把核心商业资产暴露在了全世界的面前。在好奇心驱使下,我也忍不住去看了看,你别说,发现了几个小秘密,还真有点意思。0…...