Python实战之小说下载神器(三)排行榜所有小说:最全热门小说合集,总有一款适合你,好多好多好多超赞的小说...(源码分享学习)
前言
这次的是一个系列内容
给大家讲解一下何一步一步实现一个完整的实战项目案例系列之
小说下载神器(三)(GUI界面化程序)多线程采集小说下载、采集排行榜所有小说
哈喽!大家上午好啦,我是爱看小说的栗子同学。
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。
今天这一期就如开头写的内容一样,接着来学习小说下载,下一期就写搜索界面跟GUI界面
啦~下一期就是小说下载器的最后一篇文章。
好啦,话不多说直接开始今天的正题吧!
主要内容:用Python代码实现多线程方式采集小说以及采集排行榜所有小说内容。

正文
一、运行环境
本文用到的环境如下—— Python3、Pycharm社区版,第三方模块:requests等
部分自带的库只 要安装完 Python就可 以直接使用了需要安装 的库的话看教程下🎐
一般安装:pip install +模块名 镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名 二、多线程采集小说
代码注释的很清楚的,对家可以看着学习。
1)主程序
"""
# 导入数据请求模块 --> 第三方模块, 需要安装
import requests
# 导入正则表达式模块 --> 内置模块, 不需要安装
import re
# 导入数据解析模块 --> 第三方模块, 需要安装
import parsel
# 导入文件操作模块 --> 内置模块, 不需要安装
import os
# 导入线程池
import concurrent.futuresdef get_response(html_url):"""发送请求函数:param html_url: 请求链接:return: response响应对象"""# 模拟浏览器 headers 请求头headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=html_url, headers=headers)return responsedef get_list_url(html_url):"""获取章节url/小说名:param html_url: 小说目录页:return:"""# 调用发送请求函数html_data = get_response(html_url).text# 提取小说名字name = re.findall('<h1>(.*?)</h1>', html_data)[0]# 提取章节urlurl_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)return name, url_listdef get_content(html_url):"""获取小说内容/小说标题:param html_url: 小说章节url:return:"""# 调用发送请求函数html_data = get_response(html_url).text# 提取标题title = re.findall('<h1>(.*?)</h1>', html_data)[0]# 提取内容content = re.findall('<div id="content">(.*?)<p>', html_data, re.S)[0].replace('<br/><br/>', '\n')return title, contentdef save(name, title, content):"""保存数据函数:param name: 小说名:param title: 章节名:param content: 内容:return:"""# 自动创建一个文件夹file = f'{name}\\'if not os.path.exists(file):os.mkdir(file)with open(file + title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n')print(title, '已经保存')def main(home_url):# index_url = 'https://www.biqudu.net' + urltitle, content = get_content(html_url=home_url)save(name, title, content)if __name__ == '__main__':url = 'https://www.biqudu.net/1_1631/'name, url_list = get_list_url(html_url=url)exe = concurrent.futures.ThreadPoolExecutor(max_workers=7)for url in url_list:index_url = 'https://www.biqudu.net' + urlexe.submit(main, index_url)exe.shutdown()# # 请求链接: 小说目录页
# list_url = 'https://www.biqudu.net/1_1631/'
# # 模拟浏览器 headers 请求头
# headers = {
# # user-agent 用户代理 表示浏览器基本身份信息
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
# }
# # 发送请求
# html_data = requests.get(url=list_url, headers=headers).text
# # 提取小说名字
# name = re.findall('<h1>(.*?)</h1>', html_data)[0]
# # 自动创建一个文件夹
# file = f'{name}\\'
# if not os.path.exists(file):
# os.mkdir(file)
#
# # 提取章节url
# url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)
# # for循环遍历
# for url in url_list:
# index_url = 'https://www.biqudu.net' + url
# print(index_url)
# """
# 1. 发送请求, 模拟浏览器对于url地址发送请求
# 请求链接: https://www.biqudu.net/1_1631/3047505.html
# 安装模块方法:
# - win + R 输入cmd, 输入安装命令 pip install requests
# - 在pycharm终端, 输入安装命令
# 模拟浏览器 headers 请求头:
# 字典数据结构
# AttributeError: 'set' object has no attribute 'items'
# 因为headers不是字典数据类型, 而是set集合
# """
# # # 请求链接
# # url = 'https://www.biqudu.net/1_1631/3047506.html'
# # 模拟浏览器 headers 请求头
# headers = {
# # user-agent 用户代理 表示浏览器基本身份信息
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
# }
# # 发送请求
# response = requests.get(url=index_url, headers=headers)
# # <Response [200]> 响应对象, 表示请求成功
# print(response)
# """
# 2. 获取数据, 获取服务器返回响应数据内容
# 开发者工具: response
# response.text --> 获取响应文本数据 <网页源代码/html字符串数据>
# 3. 解析数据, 提取我们想要的数据内容
# 标题/内容
#
# re正则表达式: 是直接对于字符串数据进行解析
# re.findall('什么数据', '什么地方') --> 从什么地方, 去找什么数据
# .*? --> 可以匹配任意数据, 除了\n换行符
# # 提取标题
# title = re.findall('<h1>(.*?)</h1>', response.text)[0]
# # 提取内容
# content = re.findall('<div id="content">(.*?)<p>', response.text, re.S)[0].replace('<br/><br/>', '\n')
#
# css选择器: 根据标签属性提取数据
# .bookname h1::text
# 类名为bookname下面h1标签里面文本
# get() --> 提取第一个标签数据内容 返回字符串
# getall() --> 提取多个数据, 返回列表
# # 提取标题
# title = selector.css('.bookname h1::text').get()
# # 提取内容
# content = '\n'.join(selector.css('#content::text').getall())
#
# xpath节点提取: 提取标签节点提取数据
#
# """
# # 获取下来response.text <html字符串数据>, 转成可解析对象
# selector = parsel.Selector(response.text)
# # 提取标题
# title = selector.xpath('//*[@class="bookname"]/h1/text()').get()
# # 提取内容
# content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())
# print(title)
# # print(content)
# # title <文件名> '.txt' 文件格式 a 追加保存 encoding 编码格式 as 重命名
# with open(file + title + '.txt', mode='a', encoding='utf-8') as f:
# """
# 第一章 标题
# 小说内容
# 第二章 标题
# 小说内容
# """
# # 写入内容
# f.write(title)
# f.write('\n')
# f.write(content)
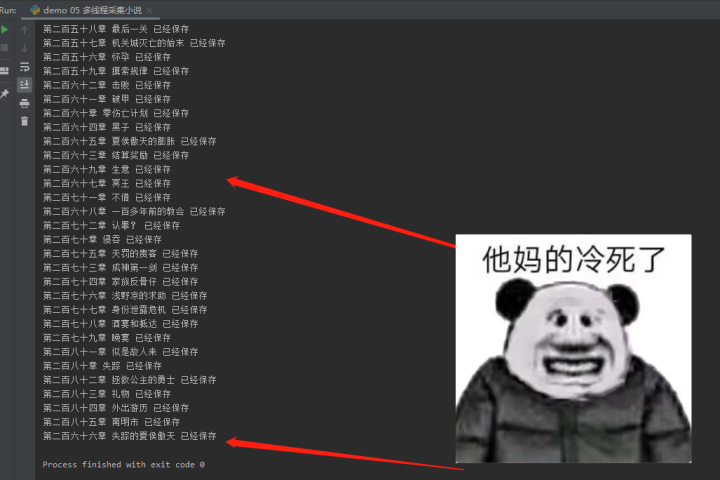
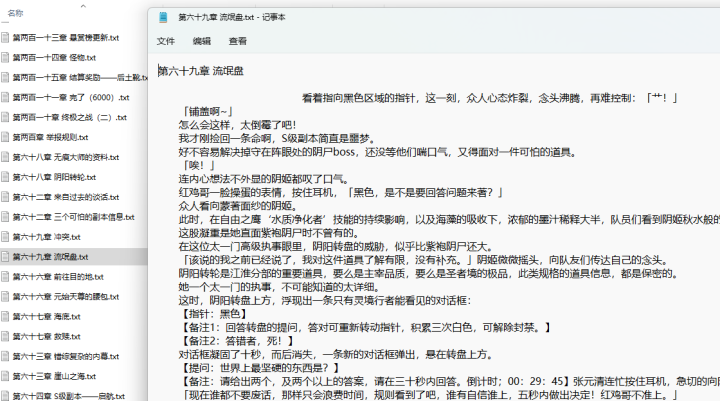
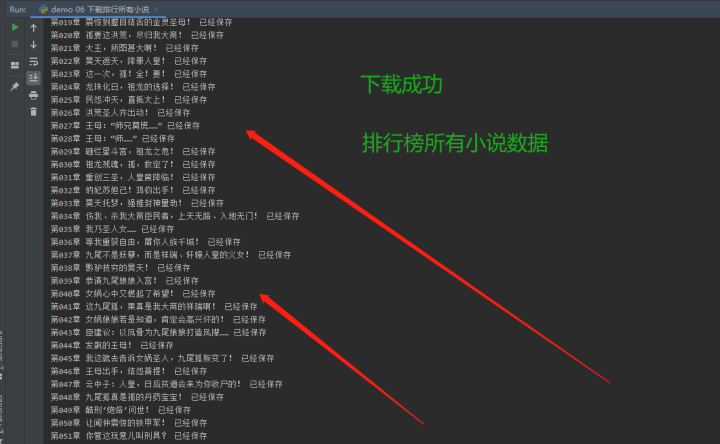
# f.write('\n') 2)效果展示
2)效果展示
三、采集排行榜所有小说
下面我们采集玄幻榜单所有小说具体看是怎么操作的呢?🤔
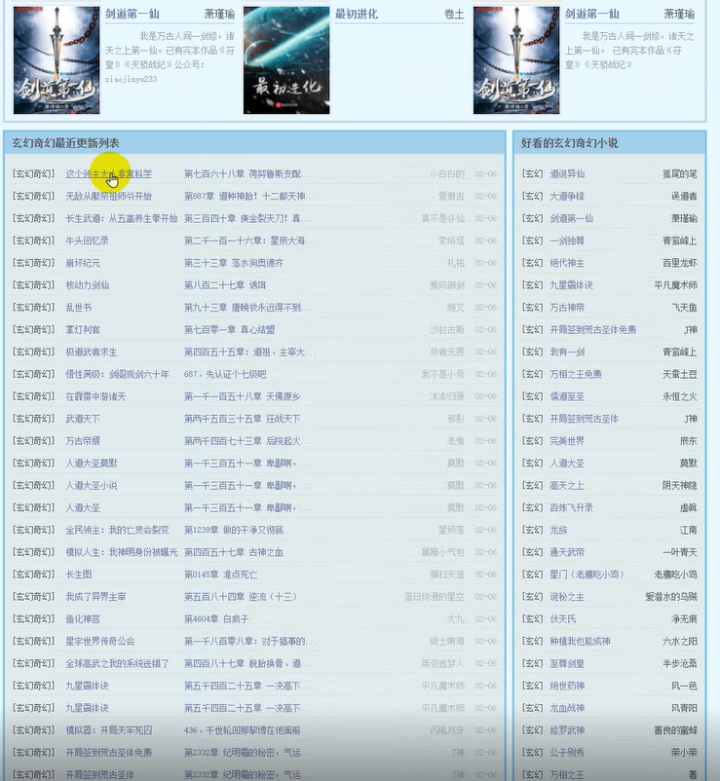
主要是要获取所有小说id——
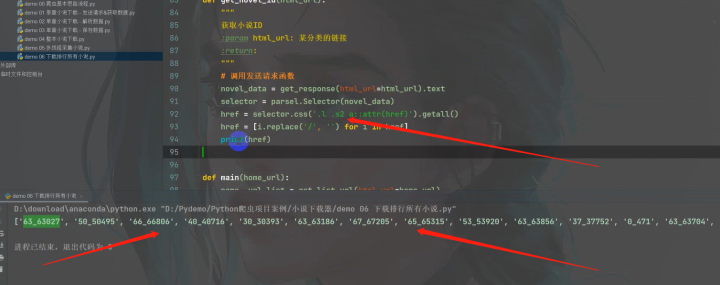
1)主程序
环境安装都是一样的方式,看最上面安装就可以,第三方库这里只是多了parsel库。
import requests
import re
import parsel
import osdef get_response(html_url):"""发送请求函数:param html_url: 请求链接:return: response响应对象"""# 模拟浏览器 headers 请求头headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0 WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}response = requests.get(url=html_url, headers=headers)return responsedef get_list_url(html_url):"""获取章节url/小说名:param html_url: 小说目录页:return:"""# 调用发送请求函数html_data = get_response(html_url).text# 提取小说名字name = re.findall('<h1>(.*?)</h1>', html_data)[0]# 提取章节urlurl_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)return name, url_listdef get_content(html_url):"""获取小说内容/小说标题:param html_url: 小说章节url:return:"""# 调用发送请求函数html_data = get_response(html_url).text# 提取标题title = re.findall('<h1>(.*?)</h1>', html_data)[0]# 提取内容content = re.findall('<div id="content">(.*?)<p>', html_data, re.S)[0].replace('<br/><br/>', '\n')return title, contentdef save(name, title, content):"""保存数据函数:param name: 小说名:param title: 章节名:param content: 内容:return:"""# 自动创建一个文件夹file = f'{name}\\'if not os.path.exists(file):os.mkdir(file)with open(file + title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n')print(title, '已经保存')def get_novel_id(html_url):"""获取小说ID:param html_url: 某分类的链接:return:"""# 调用发送请求函数novel_data = get_response(html_url=html_url).textselector = parsel.Selector(novel_data)href = selector.css('.l .s2 a::attr(href)').getall()href = [i.replace('/', '') for i in href]return hrefdef main(home_url):href = get_novel_id(html_url=home_url)for novel_id in href:novel_url = f'https://www.biqudu.net/{novel_id}/'name, url_list = get_list_url(html_url=novel_url)print(name, url_list)for url in url_list:index_url = 'https://www.biqudu.net' + urltitle, content = get_content(html_url=index_url)save(name, title, content)breakif __name__ == '__main__':html_url = 'https://www.biqudu.net/biquge_1/'main(html_url) 2)效果展示
2)效果展示
总结
好啦!今天的内容到这里就结束了哈,想看的60多本小说全部爬下来了,大家可以自己慢慢看
很久了~下一期这个系列内容就完结了,希望大家好好学一下哦!
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
🔨推荐往期文章——
项目1.0 小说下载神器(GUI界面)系列内容
Python实战之小说下载神器(一)看小说怎么能少了这款宝藏神器呢?全网小说书籍随便下,随便看,爆赞(你准备好了吗?)
项目1.1 小说下载神器(GUI界面)系列内容 Python实战之小说下载神器(二)整本小说下载:看小说不用这个程序,我实在替你感到可惜*(小说爱好者必备)
项目1.6 【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~
项目1.8 【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)

相关文章:
Python实战之小说下载神器(三)排行榜所有小说:最全热门小说合集,总有一款适合你,好多好多好多超赞的小说...(源码分享学习)
前言 这次的是一个系列内容 给大家讲解一下何一步一步实现一个完整的实战项目案例系列之 小说下载神器(三)(GUI界面化程序) 多线程采集小说下载、采集排行榜所有小说 哈喽!大家上午好啦,我是爱看小说的栗子…...
)
前端监控之用户行为监控实践1(数据收集)
前文对前端监控进行了简单介绍,起因是因为当前做的一个需求,老板要看当前项目的uv、pv信息。其实这是非常简单的统计。 但在最开始接到这个需求,却难倒我了。 现在进行简单的复盘,记录一下实现方法。 一、数据记录 用户行为从大…...
【网络原理7】认识HTTP
目录 一、HTTP协议的位置 二、HTTP协议的特点&应用场景 三、HTTP协议的格式的查看 Fiddler下载与使用 编辑 如何查看HTTP请求消息 编辑 如何查看HTTP响应数据包 如何默认开启HTTPS的解析功能 四、HTTP的请求数据包的格式含义 第一部分:请求行&…...

SPI实验
目录 一、SPI 简介 二、硬件原理 ECSPI3_SCLK ECSPI3_MISO和ECSPI3_MOSI ECSPI3_SS0 三、I.MX6U ECSPI 简介 ECSPIx_RXDATA ECSPIx_TXDATA ECSPIx_CONREG ECSPIx_CONFIGREG ECSPIx_PERIODREG编辑 ECSPIx_STATREG 四、ICM-20608 简介 五、代码编写 1、创建文件及文…...
去基线处理
目录detrend函数去除基线多项式拟合原函数BEADS 基线处理小波算法经验模态分解(EMD)参考detrend函数去除基线 detrend函数只能用于去除线性趋势,对于非线性的无能为力。 函数表达式:y scipy.signal.detrend(x): 从信号中删除线…...
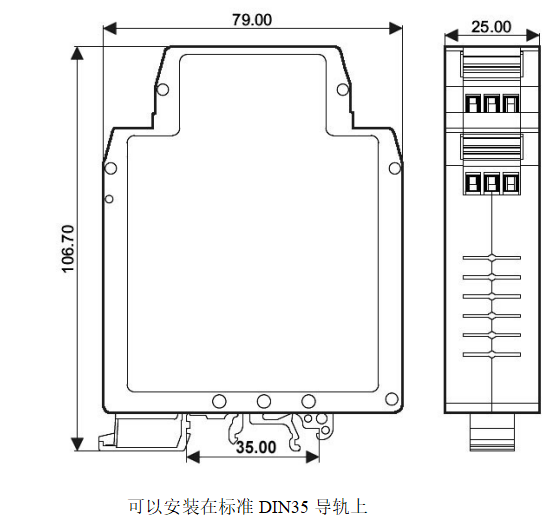
模拟信号4-20mA /0-5V/0-75mV/0-100mV转RS-485/232,数据采集A/D转换模块 YL21
特点:● 模拟信号采集,隔离转换 RS-485/232输出● 采用12位AD转换器,测量精度优于0.1%● 通过RS-485/232接口可以程控校准模块精度● 信号输入 / 输出之间隔离耐压3000VDC ● 宽电源供电范围:8 ~ 32VDC● 可靠性高,编程…...

[USB]键盘数据格式以及按键键值
USB键盘数据包含8个字节 BYTE1 – 特殊按键 |–bit0: Left Control是否按下,按下为1 |–bit1: Left Shift 是否按下,按下为1 |–bit2: Left Alt 是否按下,按下为1 |–bit3: Left GUI(Windows键) 是否按下,…...
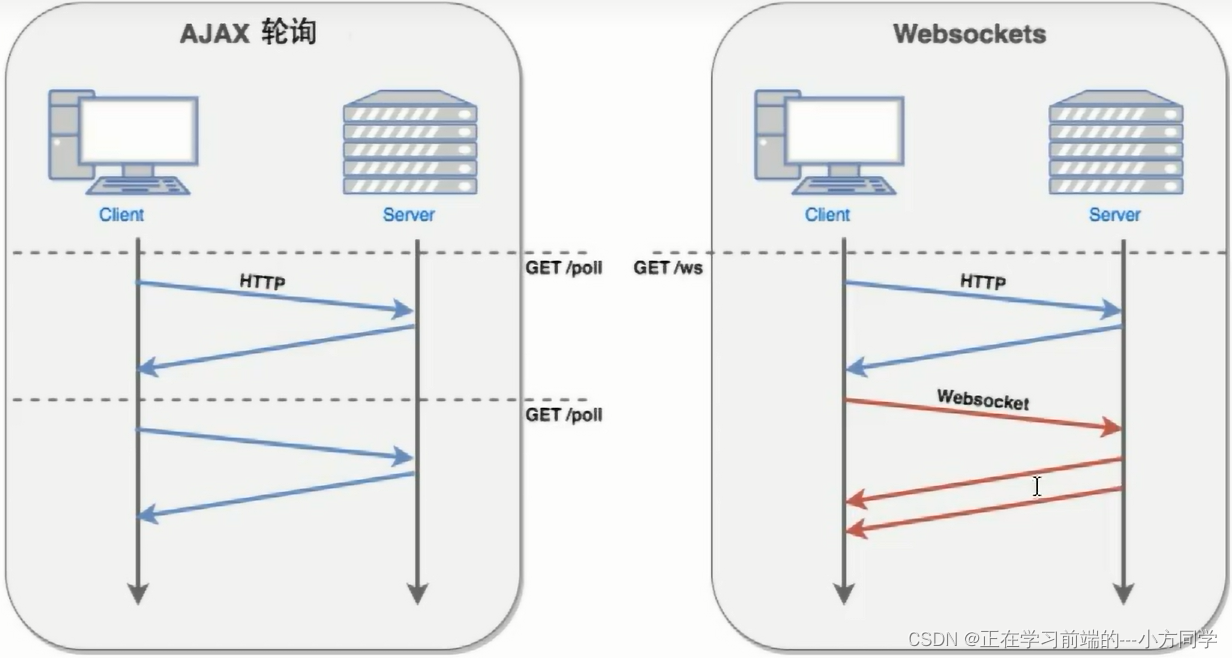
web客户端-websocket
1、websocket简介 WebSocket是HTML5开始提供的一种在单个TCP连接上进行全双工通讯的协议。 WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,…...
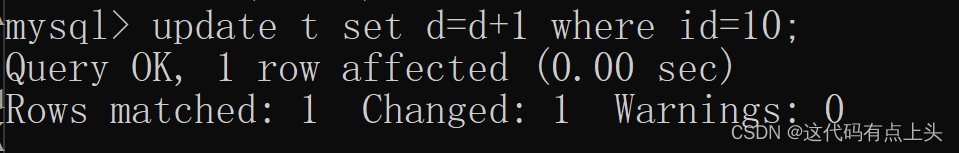
mysql间隙锁
首先我们这里有一个表t,其中的数据如下图所示 注意哈 update由于操作的最新的值,所以是当前读! 另外一个事务插入 8的时候发生锁 而我对id为10的数据进行更新,却不会被锁住 分析:在执行当前读时,由于id7不存…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 计算面积(Java) | 机试题+算法思路+考点+代码解析 【2023】
计算面积 绘图机器的绘图笔初始位i在原点(0.0)。 机器启动后其绘图笔按下面规则绘制直线: 1 )尝试沿着横向坐标轴正向绘制直线,直到给定的终点值E, 2 )期间可通过指令在纵坐标轴方向进行偏移。井同时绘制直线,偏移后按规则1绘制直线;指令的格式为X offsetY。表示在横坐标X…...
 时间频率进行移位))
Python 之 Pandas 时间戳、通过时间间隔实现 datetime 加减、时间转化、时期频率转换和 shift() 时间频率进行移位)
文章目录一、时间戳1. unit 参数是 s2. year、month、day、hour、minute、second、microsecond 单独设置时间二、通过时间间隔实现 datetime 加减三、时间转化1. 处理各种输入格式2. 将字符串转 datetime3. 除了可以将文本数据转为时间戳外,还可以将 unix 时间转为时…...
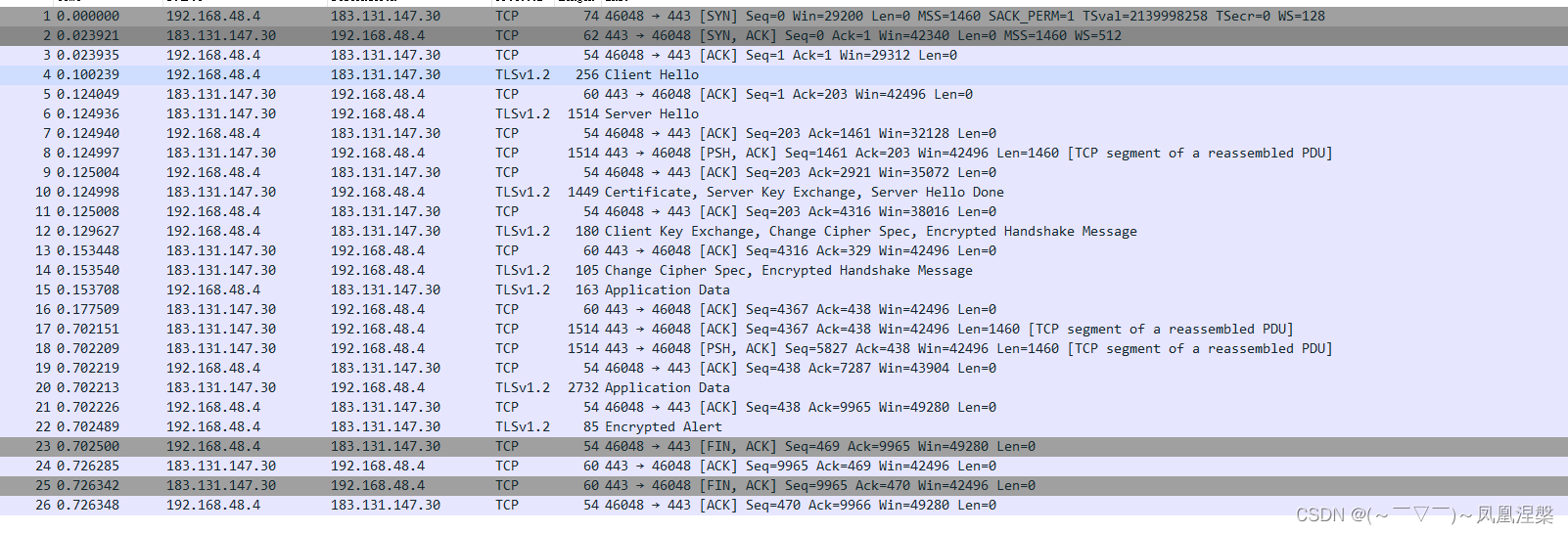
一篇文章搞定linux网络模型
网络协议感觉晦涩难懂?什么七层网络模型?又五层网络模型?又四层网络模型?TCP/IP协议是个啥?UDP是啥?什么是三次握手?什么是四次挥手?tcpdump听说是抓包的,怎么用…...

惠普庆祝在中国40年,强化中国发展战略
中国北京,2023年2月23日 ——今日,“品质信赖向未来” 惠普在中国40年系列活动启动仪式及惠普打印春季新品发布会在北京盛大举行。现场,惠普回顾了40年来与中国经济及产业共同发展的历程,并再次强调了惠普一以贯之的“在中国&…...

C++小作业
前言:long long time ago,老大留了点小作业,一直忘了写…偷偷补上 小作业目录unique_ptr vs shared_ptrunique_ptrshared_ptrpublisher/subscriber 1?boost::bindstd::bindthis? _1?TopicContextPtr?std::moveunique_ptr vs sh…...

Python基础 — lambda匿名函数
1、什么是匿名函数? 匿名函数,顾名思义,就是没有名字的函数,它主要用在那些只使用一次的场景中。如果我们的程序中只需要调用一次某个简单逻辑,把它写成函数还需要先定义、取函数名字等一些列操作,这种场景…...

MongoDB安装和使用过程常见问题
文章目录一、安装过程显示没有相应的权限二、pymongo无法使用,报错一、安装过程显示没有相应的权限 oh我的天,找了网上很多种方法都不行哈哈 不同的电脑对应不同的问题吧~ 我的这个问题是这样解决滴 先直接简述操作路径,不明白的可以看如下图…...
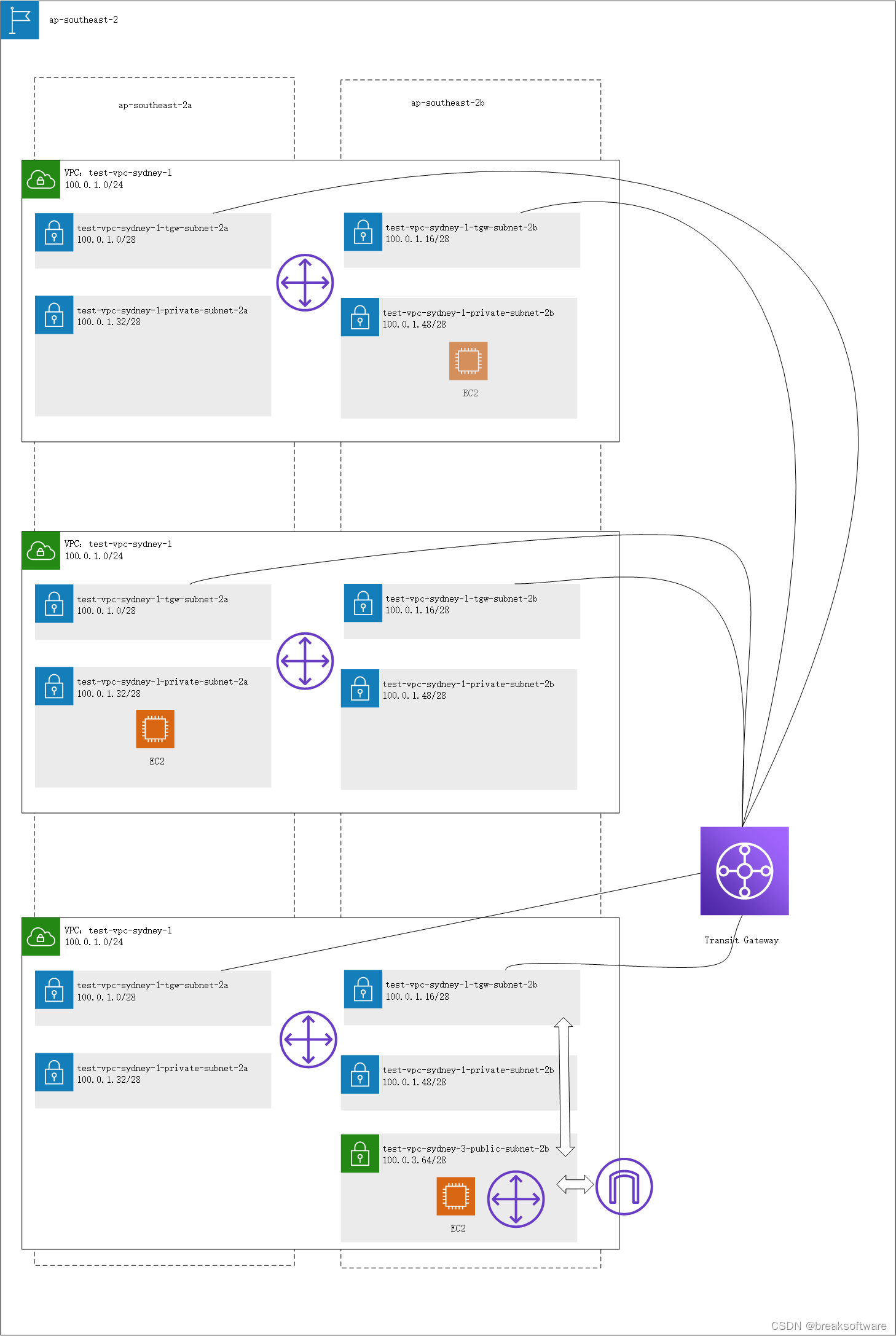
AWS攻略——使用中转网关(Transit Gateway)连接同区域(Region)VPC
文章目录环境准备创建VPC配置中转网关给每个VPC创建Transit Gateway专属挂载子网创建中转网关创建中转网关挂载修改VPC的路由验证创建业务Private子网创建可被外网访问的环境测试子网连通性Public子网到Private子网Private子网到Private子网知识点参考资料在《AWS攻略——Peeri…...

Rouge | 自动文摘及机器翻译评价指标
tag:评价指标,摘要,nlp Rouge(Recall-Oriented Understudy for Gisting Evaluation),是评估自动文摘以及机器翻译的一组指标。它通过将自动生成的摘要或翻译与一组参考摘要(通常是人工生成的)进行比较计算,得出相应的分值&#x…...
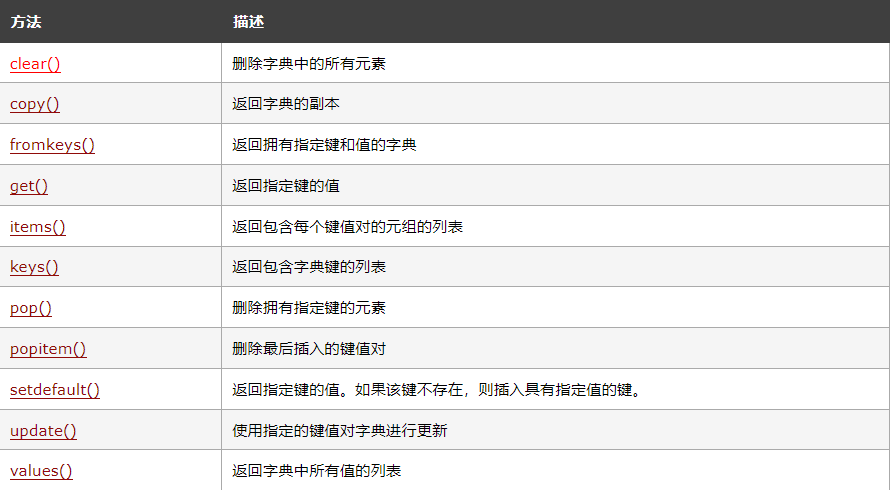
【Python入门第十五天】Python字典
字典(Dictionary) 字典是一个无序、可变和有索引的集合。在 Python 中,字典用花括号编写,拥有键和值。 实例 创建并打印字典: thisdict {"brand": "Porsche","model": "911&q…...

java学习思路
基础概念:了解Java的基本概念,如Java虚拟机(JVM)、Java标准版(Java SE)、Java企业版(Java EE)等。了解Java的版本、发展历程以及Java应用场景。可以通过阅读Java官方文档、相关书籍、…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...

理想二极管控制器:用MOSFET实现毫伏级压降的电源管理方案
1. 理想二极管控制器:告别传统二极管的压降损耗 在电源设计、电池保护、太阳能板并联这些领域里,二极管是个再常见不过的元件。我们用它来防反接、做整流、实现“或”逻辑供电,几乎不假思索。但如果你设计过一个需要处理大电流、低电压的系统…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...