2023 “华为杯” 中国研究生数学建模竞赛(D题)深度剖析|数学建模完整代码+建模过程全解全析
问题一:区域碳排放量以及经济、人口、能源消费量的现状分析
思路:
定义碳排放量 Prediction 模型:
CO2 = P * (GDP/P) * (E/GDP) * (CO2/E)
其中: CO2:碳排放量 P:人口数量 GDP/P:人均GDP E/GDP:单位GDP能耗 CO2/E:单位能耗碳排放量
2.收集并统计相关历史数据:
人口数量P
GDP总量与人均GDP
各产业部门能耗E
各产业部门碳排放量CO2
3.分析历史数据变化趋势:
GDP增长率、人均GDP增长率
部门能耗强度降低率
部门碳排放强度降低率
4.预测未来发展态势:
人口预测
GDP增长目标
部门能效提升目标
非化石能源替代目标
5.将预测数据代入碳排放预测模型,计算各年碳排放量。
6.比较碳排放量预测结果与碳中和目标差距,分析碳中和的难点。
代码:
# 导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 读取历史数据
df = pd.read_excel('history_data.xlsx') # 数据预处理
df = df[['年份','人口','GDP','第一产业能耗','第二产业能耗','第三产业能耗','生活能耗','碳排放量']]
df['能耗总量'] = df[['第一产业能耗','第二产业能耗','第三产业能耗','生活能耗']].sum(axis=1)
df['人均GDP'] = df['GDP'] / df['人口']
df['能耗强度'] = df['能耗总量'] / df['GDP']
df['碳排放强度'] = df['碳排放量'] / df['能耗总量']# 分析历史趋势
df['GDP增长率'] = df['GDP'].pct_change()
df['人均GDP增长率'] = df['人均GDP'].pct_change() #见完整版问题二
区域碳排放量以及经济、人口、能源消费量的预测模型
人口预测模型
根据历史人口数据,可以建立简单的线性回归模型来预测未来人口数量。也可以研究人口增长的S形曲线规律,建立logistic回归模型。需要收集人口出生率、死亡率等数据,来综合判断未来人口变化趋势。
2.人均能耗模型
可以基于每个时期人均GDP水平,结合Engel系数法则等分析人均能耗需求变化规律。随着生活水平提高,人均能耗呈现先增加后下降的趋势。建立人均能耗预测模型时,需要考虑收入弹性、技术进步抑耗作用等因素。
3.能耗强度模型
这反映了经济活动的能效提升程度。可以收集国内外同类产业的能耗强度基准,判断本区域的节能潜力空间。还需要考虑电气化、新材料应用等因素对能耗强度的影响。不同产业需要建立独立的强度预测模型。
4.部门能耗预测
基于能耗总量预测,结合产业发展规划、产业结构优化目标,合理预测各部门的能源需求。重点对能源密集型产业的清洁生产提出指导意见。
5.情景比较
建议设计高能效提升情景、低能效提升情景,以及高非化石能源替代情景、低替代情景。比较各情景下的碳排放量、能耗指标,分析实现碳中和的关键措施。
结合公式:
人口预测模型
线性回归模型:
人口数P = a + b*年份
logistic模型:
P = P_m / [1 + exp(-k(年份-t))]
2.人均能耗模型
人均能耗E_p = c * GDP_p^d
3.能耗强度模型
能耗强度I = a * exp(-b*年份)
4.部门能耗预测模型
第i部门能耗E_i = E_total * r_i
5.碳排放量预测
CO2 = ∑(E_i * f_i)
其中: P_m:人口饱和值上限 k,t:logistic模型参数 E_p:人均能耗 GDP_p:人均GDP I:能耗强度 E_i:第i部门能耗 E_total:总能耗 r_i:第i部门耗能占比 f_i:第i部门碳排放因子
代码:
# 导入库
import pandas as pd
from scipy.optimize import curve_fit# 人口预测
p_data = df[['年份','人口']]# 线性回归
def linear(x, a, b):return a + b*xpars, cov = curve_fit(linear, p_data['年份'], p_data['人口'])
a, b = pars
predict_p = [linear(x, a, b) for x in range(2025,2061)]# Logistic回归
def logistic(x, p_m, k, t):#见完整版问题三
区域双碳(碳达峰与碳中和)目标与路径规划方法
构建多情景框架
设置无干预情景、碳中和情景等多种发展情景。确定各情景的经济增长、能效提升、非化石能源比例等参数。
2.碳排放预测模型
CO2 = Σ(Ei * fi)
Ei = Etotal * ri
其中Ei表示部门i能耗,fi表示对应碳排放因子,ri表示耗能占比。
3.部门能耗确定
工业:Ei = VAi * (1-η1) * η2
建筑:Ei = VAi * (1-η1) * η2
VAi表示部门增加值,η1表示管理节能率,η2表示技术节能率。
4.非化石能源置换
调整碳排放因子fi,设置不同替代情景。
5.GDP约束
∑VAi = GDP
增加值之和约束为GDP总量。
6.情景对比
比较不同情景下的碳排放量、非化石能源比例等结果
详细来说,
构建多情景框架
可以设置3-5种情景,如基准情景、进取情景、保守情景等
确定每个情景的核心参数:经济增速、能效提升目标、非化石能源替代目标
收集相关国内外研究报告,综合判断参数的合理取值范围
2.碳排放预测模型
排放量由各部门的能耗及排放因子决定
部门能耗取决于总量分配和结构优化
排放因子通过提升非化石替代来降低
3.部门能耗确定
考虑管理节能、技术进步来推动能效提升
收集行业案例研究,判断节能潜力空间
4.非化石能源置换
不同情景可以设置不同的替代目标
替代路径可以通过电力置换、氢能应用、生物质利用等途径实现
5.GDP约束
部门增加值之和等于GDP总量
需要平衡部门发展速度,实现经济平稳增长
6.情景对比
比较碳排放量、非化石能源比例差异
分析不同情景的可行性和政策含义
提出相关决策建议
# 导入库
import pandas as pd
from scipy.optimize import curve_fit# 人口预测
p_data = df[['年份','人口']]# 线性回归
def linear(x, a, b):return a + b*xpars, cov = curve_fit(linear, p_data['年份'], p_data['人口'])
a, b = pars
predict_p = [linear(x, a, b) for x in range(2025,2061)]# Logistic回归
def logistic(x, p_m, k, t):#见完整版更多完整版见我的回答~
(5 封私信 / 2 条消息) 如何评价2023数学建模研赛? - 知乎 (zhihu.com)
相关文章:

2023 “华为杯” 中国研究生数学建模竞赛(D题)深度剖析|数学建模完整代码+建模过程全解全析
问题一:区域碳排放量以及经济、人口、能源消费量的现状分析 思路: 定义碳排放量 Prediction 模型: CO2 P * (GDP/P) * (E/GDP) * (CO2/E) 其中: CO2:碳排放量 P:人口数量 GDP/P:人均GDP E/GDP:单位GDP能耗 CO2/E:单位能耗碳排放量 2.收集并统计相关…...
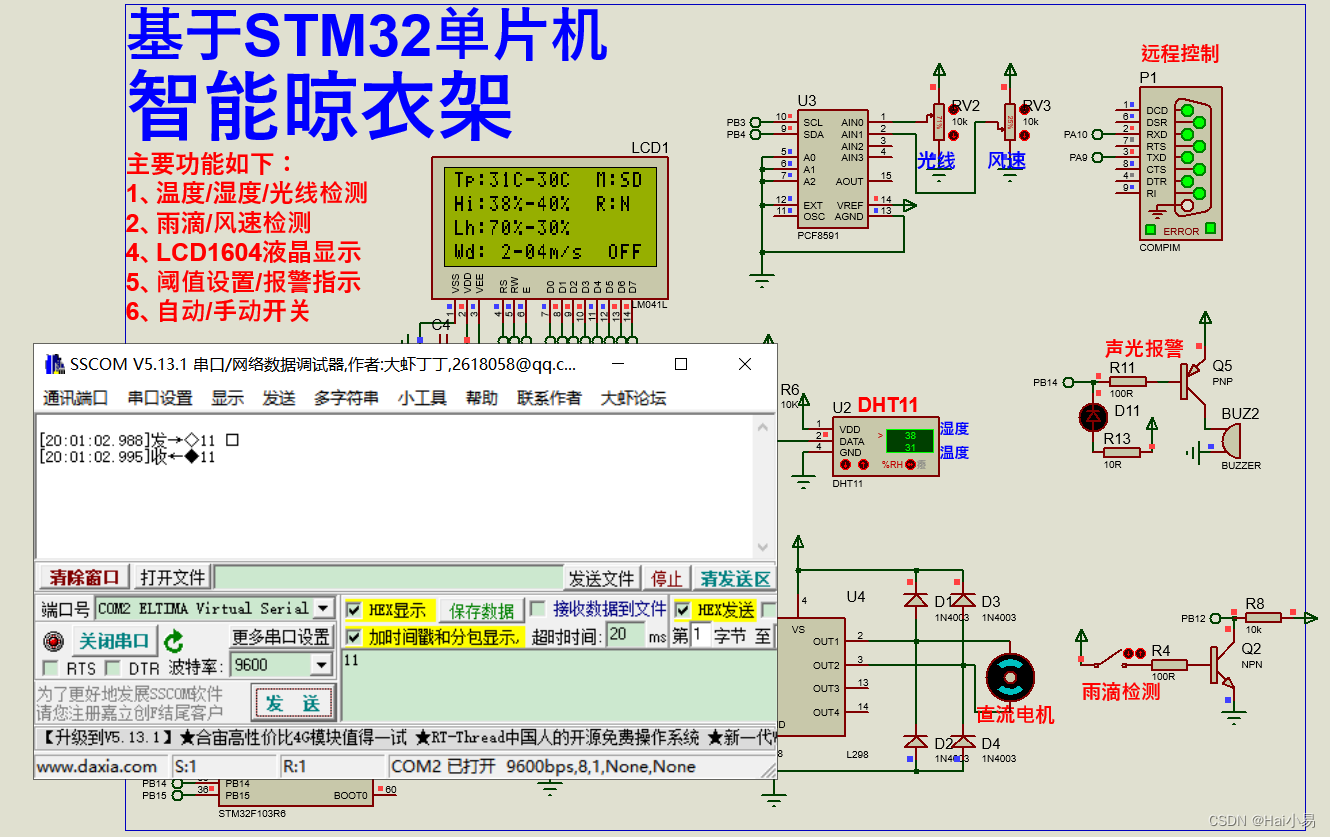
【Proteus仿真】【STM32单片机】基于单片机的智能晾衣架控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 系统运行后,LCD1604显示传感器检测的温湿度、光线强度和风速,工作模式,以及相应阈值,系统工作状态等;系统默认为自动模式, 可通过K4…...

C/C++代码静态检测工具PC-Lint常见错误总结
目录 1、PC-Lint 概述 2、PC-lint 常见错误列举 3、PC-Lint报告的语法错误 4、总结 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)https://blog.csdn.net/chenlycly/article/details/124272585C软件异常排查从入门到…...
概率深度学习建模数据不确定性
https://zhuanlan.zhihu.com/p/568912284理解论文 What uncertainties do we need in Bayesian deep learning for computer vision? (NeurIPS 2017) [1]中的数据不确定性建模,并给出公式推导。论文[1]指出不确定性uncertainty分为随机不确定性(aleator…...

Jenkins自动化部署前后端分离项目 (svn + Springboot + Vue + maven)有图详解
1. 准备工作 本文的前后端分离项目,技术框架是: Springboot Vue Maven SVN Redis Mysql Nginx JDK 所以首先需要安装以下: 在腾讯云服务器OpenCLoudOS系统中安装jdk(有图详解) 在腾讯云服务器OpenCLoudOS系统…...
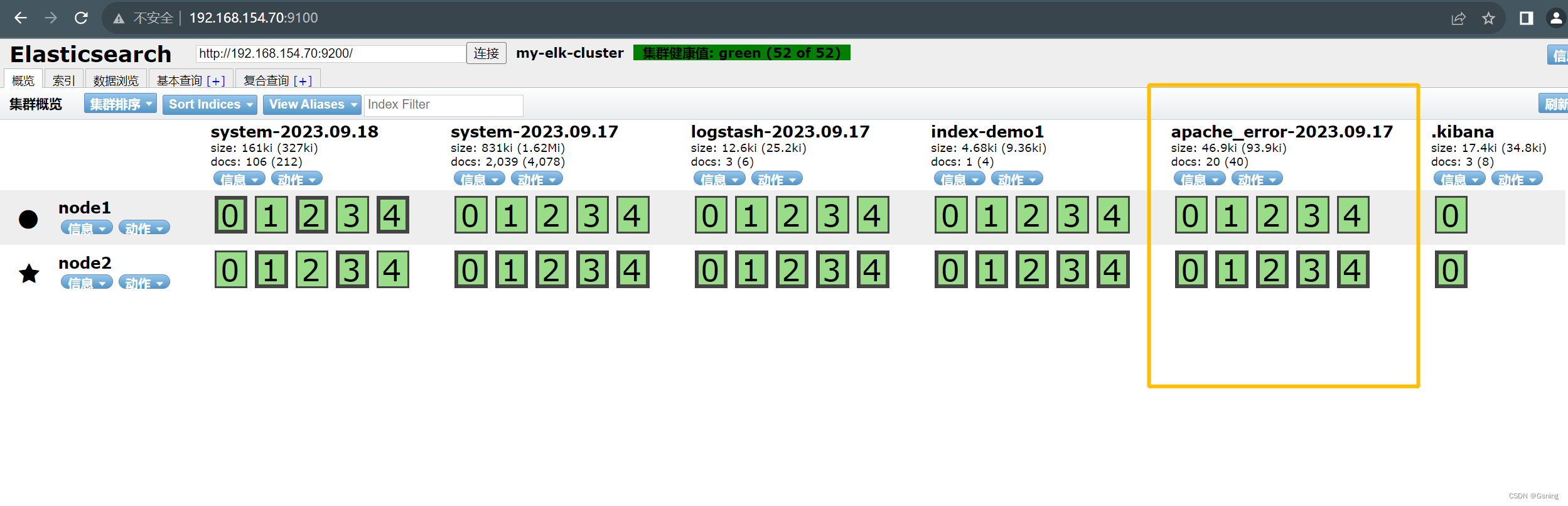
【ELK】日志系统部署
一、ELK日志分析系统 1、ELK的组成 ElasticSearchLogStashKibana ELK基于这三个开源日志的收集、存储、检索和可视化的解决方案;可帮助用户快速定位和分析应用程序的故障,监控应用程序性能和安全,以及提供丰富的数据分析和展示功能。 2、完…...

【算法挨揍日记】day08——30. 串联所有单词的子串、76. 最小覆盖子串
30. 串联所有单词的子串 30. 串联所有单词的子串 题目描述: 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["…...
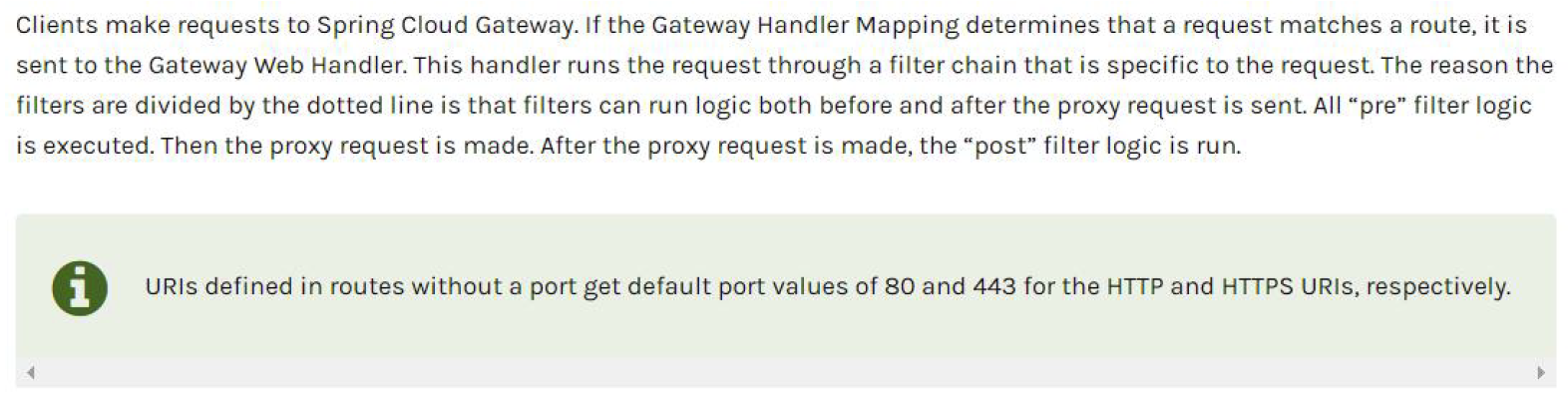
SpringCloud Gateway--网关服务基本介绍和基本原理
😀前言 本篇博文是关于SpringCloud Gateway的基本介绍,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的满意是我的动力…...

使用Vue-cli构建spa项目及结构解析
一,Vue-cli是什么? 是一个官方发布的Vue脚手架工具,用于快速搭建Vue项目结构,提供了现代前端开发所需要的一些基础功能,例如:Webpack打包、ESLint语法检查、单元测试、自动化部署等等。同时,Vu…...
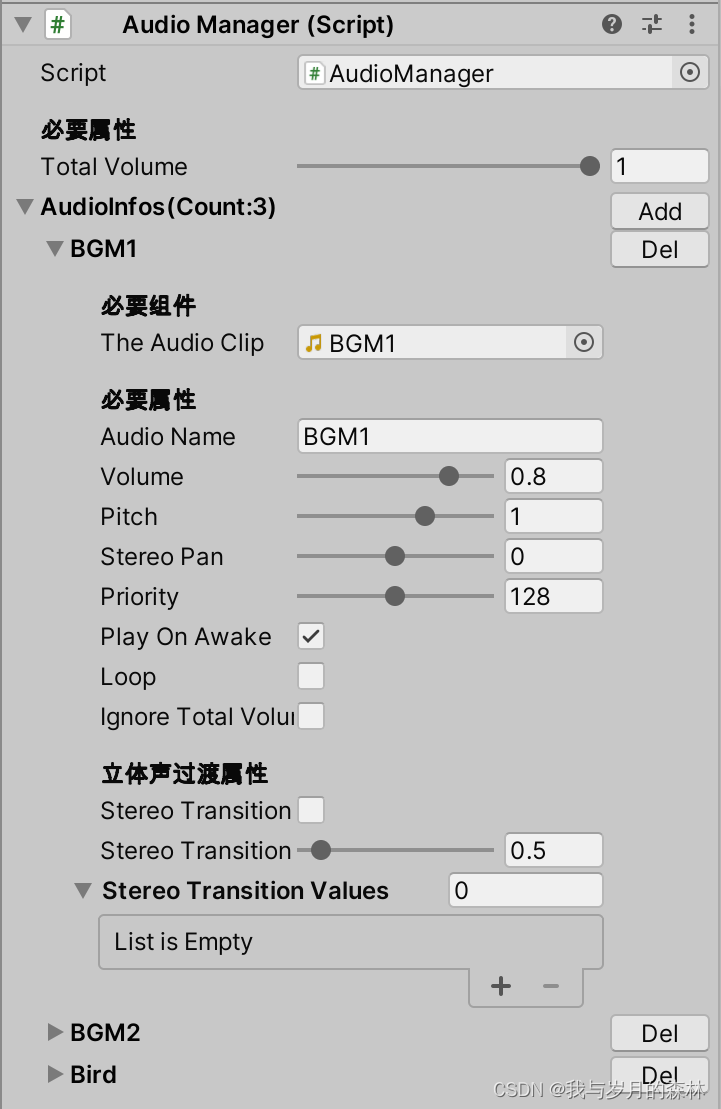
自定义Unity组件——AudioManager(音频管理器)
需求描述 在游戏开发中,音频资源是不可或缺的,通常情况下音频资源随机分布,各个音频的操作和管理都是各自负责,同时对于音频的很多操作逻辑都是大同小异的,这就造成了许多冗余代码的堆叠,除此之外在获取各类…...

leetcode 558 设计内存文件系统
题目 Design an in-memory file system to simulate the following functions: ls: Given a path in string format. If it is a file path, return a list that only contains this files name. If it is a directory path, return the list of file and directory namesin th…...
Haproxy负载均衡群集
HAproxy搭建Web群集一、Web集群调度器1、常见的Web集群调度器2、常用集群调度器的优缺点(LVS ,Nginx,Haproxy)2.1 Nginx2.2 LVS2.3 Haproxy 3、LVS、Nginx、HAproxy的区别 二、Haproxy1、简介2、Haproxy应用分析3、HAProxy的主要特性4、Haproxy调度算法(…...

什么是面包屑导航?
面包屑导航(Breadcrumb Navigation)这个概念来自童话故事“汉赛尔和格莱特”,当汉赛尔和格莱特穿过森林时,不小心迷路了,但是他们发现沿途走过的地方都撒下了面包屑,让这些面包屑来帮助他们找到回家的路。 在网站应用中࿰…...
VS2019创建GIt仓库时剔除文件或目录
假设本地有解决方案“SomeSolution” 1、首先”团队资源管理器“-“创建Git存储库”,选择“仅限本地”、“创建” VS会在解决方案目录下自动生成.gitattributes、.gitignore 2、编辑gitignore,直接拖到VS里或者用记事本打开。添加要剔除的文件或文件夹…...

计算机等级考试—信息安全三级真题六
目录 一、单选题 二、填空题 三、综合题 一、单选题...

vue循环滚动字幕
在Vue.js中创建一个循环滚动字幕的效果通常需要使用一些CSS和JavaScript来实现。以下是一个简单的示例,展示如何使用Vue.js创建一个循环滚动字幕的效果: 首先,在HTML中创建一个Vue实例,并添加一个包含滚动字幕的容器元素ÿ…...
扩展pytest接口自动化框架-MS数据解析功能
【软件测试行业现状】2023年了你还敢学软件测试?未来已寄..测试人该何去何从?【自动化测试、测试开发、性能测试】 开篇 MeterSphere的数据源通过html页面上传后,需要将请求方式进行拆分。 get接口的参数,常以params的方式进行传…...

docker容器安装MongoDB数据库
一:MongoDB数据库 1.1 简介 MongoDB是一个开源、高性能、无模式的文档型数据库,当初的设计就是用于简化开发和方便扩展,是NoSQL数据库产品中的一种。是最 像关系型数据库(MySQL)的非关系型数据库。 它支持的数据结构…...

Python机器学习实战-特征重要性分析方法(3):迭代删除法:Leave-one-out(附源码和实现效果)
实现功能 迭代地每次删除一个特征并评估准确性 实现代码 from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score impo…...
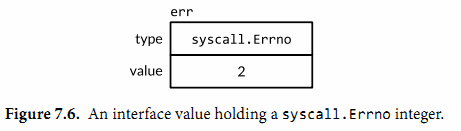
Go的error接口
从本书的开始,我们就已经创建和使用过神秘的预定义error类型,而且没有解释它究竟是什么。实际上它就是interface类型,这个类型有一个返回错误信息的单一方法: type error interface { Error() string } 创建一个error最简单的方…...

基于ARM9工业平板与Linux的水质在线监测系统开发实践
1. 项目概述:当工业平板电脑遇上水质监测在环保、水产养殖、市政水务这些领域里,数据就是眼睛。过去,我们看水质,得靠人拿着采样瓶,一趟趟跑现场,再送回实验室,等上半天甚至几天才能拿到一份报告…...

BIN文件操作指南:从字节视角到实战应用
1. 项目概述:为什么我们需要系统性地掌握BIN文件操作?在嵌入式开发、固件逆向、游戏修改乃至数据恢复这些领域里,我们经常会遇到一个后缀名为.bin的文件。很多新手朋友第一次接触时可能会有点懵,这既不是文本文件可以直接打开看&a…...

告别复杂配置,使用Taotoken CLI一键生成多工具环境配置文件
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别复杂配置,使用Taotoken CLI一键生成多工具环境配置文件 在接入多个大模型工具时,开发者常常需要为每个…...

iPhone 14上跑出0.8ms延迟!SwiftFormer加性注意力实战:从论文到移动端部署避坑指南
iPhone 14上实现0.8ms延迟:SwiftFormer移动端部署全流程实战 当我在iPhone 14 Pro上首次看到SwiftFormer-L1模型以0.8毫秒完成图像分类时,手中的咖啡杯差点滑落——这个速度已经快于人眼单次眨动的1/10时长。作为长期奋战在移动端AI部署一线的工程师&am…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...

有钱才懂爱:赚到钱你再去谈男女关系,你会发现,择偶逻辑都变了。 没钱的时候,你看到的是一堆条件:房子、车子、工作、家境。 有钱了之后,那些条件你都自己有了
先谋生,再谋爱:有钱之后,我才看懂了男女关系的真相 目录 先谋生,再谋爱:有钱之后,我才看懂了男女关系的真相 没钱的时候,你谈的从来都不是爱情,是“生存合伙” 钱是最好的过滤器,它能帮你滤掉所有的“功能性需求” 底层的“忠诚”,很多时候只是“没有选择”的同义词…...

3步解锁百度网盘全速下载,让你的macOS下载速度提升70倍
3步解锁百度网盘全速下载,让你的macOS下载速度提升70倍 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾经在macOS上使用百度网盘时…...
实战:从配置到调试,手把手教你防止程序‘饿死’)
ESP32任务看门狗(TWDT)实战:从配置到调试,手把手教你防止程序‘饿死’
ESP32任务看门狗深度实战:构建高可靠多任务系统的关键技巧 在物联网设备开发中,系统稳定性往往决定着产品的成败。想象一下这样的场景:你的智能家居网关在凌晨3点突然停止响应,或者工业传感器节点在关键时刻丢失数据——这些问题的…...

3分钟搞定OFD转PDF:免费开源工具Ofd2Pdf完整使用指南
3分钟搞定OFD转PDF:免费开源工具Ofd2Pdf完整使用指南 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 还在为打不开OFD文件而烦恼吗?今天我要向你推荐一个完全免费、简单高效的…...

手把手教你用UE5 C++为角色添加动态攀爬:支持移动平台与高度自适应
手把手实现UE5动态攀爬系统:移动平台与高度自适应全解析 在当代3A级动作游戏中,角色与环境的动态交互已成为沉浸感的核心要素。想象一个场景:玩家在摇晃的空中浮岛上追逐目标,需要连续攀爬移动中的平台;或是潜入敌方基…...