ChatGPT追祖寻宗:GPT-3技术报告要点解读

论文地址:Language Models are Few-Shot Learners
往期相关文章:
- ChatGPT追祖寻宗:GPT-1论文要点解读_五点钟科技的博客-CSDN博客
- ChatGPT追祖寻宗:GPT-2论文要点解读_五点钟科技的博客-CSDN博客
本文的标题之所以取名技术报告而不是论文,是因为长达63页的GPT-3的这篇文章它不是一个发表的论文,而是一份报告,文中也没有针对模型的结构和整个训练过程的细节介绍,基本上都是在讨论,因此本博客也只挑一些个人觉得值得关注的点介绍一下。
Abstract

回顾一下GPT-1和GPT-2,GPT-1中主要用到了改变输入样式的方式让模型学会执行不同任务,GPT-2作者通篇在强调零样本学习,放弃用在输入中加入特殊符号区分不同任务的做法,改用纯自然语言输入的方式执行不同的任务,而在GPT-3中,作者又不再强调零样本的事了,也认为依靠大量的标注数据进行任务相关的微调不是个好主意,因为作者提到,人类对于新的任务的学习,往往只需要少量的样本就能学到新知识,估计作者认为也不能一个样本都不给,因此,作者想到了一个few-shot的方法,牛掰!当然也提到了one-shot的方法,这个后面会说。摘要中作者主要说明了他们开发出一个包含1750亿个参数的GPT-3,比之前非稀疏的模型大10倍,为啥是非稀疏的,因为稀疏模型的权重存在很多0,会导致模型虚大,所以 没有对比意义。其次,作者发现GPT-3生成的新闻文本连人类都难以分辨真假是不是人写的。
1. Instruct

接下来,作者提到了目前对于语言模型训练的范式,就是在一个任务无关的数据集上预训练,再在特定任务数据集上做微调,但是这种范式存在很大的问题,就是这样训练模型仍然需要大量的标注数据去做微调,具体地,作者列出了3个问题:


总结来说,主要是3个方面的问题:
- 标注数据集的依赖,即模型的训练需要大量的标注数据,这是十分困难的;
- 在微调模型表现的好不见得是因为预训练模型泛化能力强,有可能是因为预训练使用的大批量数据涵盖了微调数据的信息,如果微调的数据在预训练中没有相应的分布,那么模型的表现可能就变差了。
- 人类在学习某个新的任务时,往往不需要有大量的例子进行辅助,比如让你认识猫,那么其实给你几只猫的样子,后期不管什么颜色什么品种的猫,你都大概率能区分出它是只猫。而GPT-3就想类比人类学习的过程,认为模型也不需要大量的任务相关的例子来学习,这就是few-shot。

为了解决上述的问题,作者也提出了他们的思路,这一段中作者提到了一个比较新的名词,叫元学习(meta-learning),还提到了“in-context learning”,这是上下文学习的意思。对于元学习,其实也没那么高深,说白了就是将大量的不同任务的样本同时送给模型做预训练,和GPT2中的多任务学习形似,而在做in-context learning的时候,根据示例样本的多少,区分zero-shot、one-shot和few-shot,所以这个in-context learning过程有没有在做梯度更新?是没有的。作者对于元学习和in-context learning在本页的尾部做了解释:

作者说了,之前提到的零样本学习不是真的从零样本的情况下学习,为了避免这种歧义,所以用了元学习来代替预训练过程,用in-context leaning代表前向传播过程(注意,可以认为是推理,因为不涉及到梯度的更新)。而且根据在推理过程所依赖示例样本的多少划分零样本、单样本和少样本。说实话,有点绕,如果不深入分析作者的意思的话,困扰更大。作者还附上了一幅图来说明这个过程:
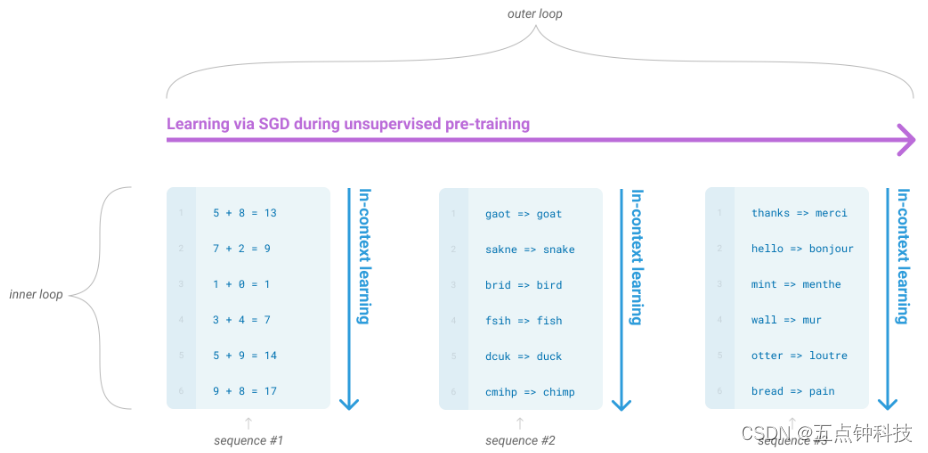
outer loop部分是无监督预训练过程,底下蓝色部分就是in-context learning。单从图上来看,整个outer loop部分是无监督预训练,在这个过程中,分别包含了不同的in-context learning阶段,可是按照文中的意思,预训练过程是不可能不做梯度更新的,而in-context learning又是不做梯度更新的,所以上图可能表示的有些问题,所以我认为,这个图并不是在讲GPT-3是怎么训练的,而是告诉我们有这么个组成阶段,具体的就是,有个无监督预训练阶段,而in-context learning只发生在前向传播阶段,作者想告诉我们,在预训练阶段,只要数据量足够大,那么就很有可能包括了in-context learning过程中的任务相关的示例样本。大家看看就好,挺奇怪的反正是。当然,由于GPT-3未开源,所以这些只是猜测。

这段话作者想说明随着模型参数量的不断增大,模型的性能也的确在不断改善,总结就是模型的参数量对模型的性能确实有直接的影响。


作者对不同shot做的实验对比图,从图上来看,few-shot貌似是最好的,注意图上三条实线取的是n次实验的平均值。也就是说,随着给的示例样本的增多,模型的性能大体也越来越好。但值得注意的是,给的示例样本并非用来给模型进行微调训练的,而是在不更新梯度的条件下让模型能够根据示例样本执行相关的任务,这的确有点像人类执行新任务的过程。
 作者也提到了说GPT-3在自然语言推断方面的任务仍然有很大的改进空间,他们也会继续在少样本学习方面加大改进研究的力度。
作者也提到了说GPT-3在自然语言推断方面的任务仍然有很大的改进空间,他们也会继续在少样本学习方面加大改进研究的力度。

这几段话主要概括了接下来作者要在文中讨论的内容。包括数据集、模型尺寸、不同训练方式、模型的局限、社会影响等方面,没啥可说的。
2. Approach


接下来作者又介绍了一遍什么是微调、少样本学习、单样本学习、零样本学习,以及他们是怎么做的。这里值得一提的是,作者在少样本学习中介绍了他们实验的示例样本范围是10到100个,也提到了少样本学习的一个主要缺点是它仍然比目前最好的有微调过程的模型表现的差。而零样本学习是最接近人类学习新任务的情形。下面是一张示例图,分别对微调、零样本、单样本、少样本学习剧了不同的例子:

从上图可以清楚的明白4个不同过程究竟是怎么一回事:微调就是在预训练模型的基础上用一定量的带标签的样本进行增量训练(有梯度更新);零样本就是只有提示词,没有示例样本;单样本就是有提示词,也有一个示例;少样本就是提示词加上少量的示例。示例就是为了让模型推理的时候也给个例子让模型看,使模型能够知道你要让它干嘛。比如上图的提示词“translate English to French:”,提示词下面就是示例样本和待预测样本,“=>”左端序列指的是原始文本(English),右边是目标文本(French),最后一条不存在目标文本的序列就是需要模型做预测的待预测的样本。
接下来,作者列举了他们在文章中所设计的不同大小的模型的参数情况:

这个大家看图就一目了然了,其中,GPT-3 Small的参数和Bert-base类似,GPT-3 Medium和Bert-Large差不多。GPT-3 XL的参数量和GPT-2的相当,但是其向量维度会比GPT-2宽一些,层数比GPT-2深一些,GPT-2是48层的。至于这些参数为什么这么设定,我想应该是作者们的玄学思维发挥了作用。。。比较好奇的是,随着GPT层数的增加,其向量维度增加的程度并不高,而且随着batchsize的增加,学习率也往小了调,我感觉这有点和我们的认识反着来。通常层数增加的倍数要和向量维度增加的倍数相当,因为层数增加了,就要有更多的向量维度去记住更多的信息,当batchsize增大,学习率应该也有所增大才是,因为在那么一大批量的样本上,应该先要有个大的学习率快速的接近最优空间,总之这块挺玄学的。
2.1 Model and Architectures

到了大家最关心的模型结构问题,很可惜,最重要的地方篇幅却很少。开头作者就说,GPT-3和GPT-2在模型结构上没有本质区别,唯一不同的就是GPT-3在注意力机制这块GPT-3采用了一种叫做Sparse Transformer的网络结构,抱歉,这个模型我还没仔细研究过,暂且不做讨论。所有的8个模型作者均采用了2048个token的输入限制,也就是说GPT-3支持最多2048个token。文中作者还简要提了一下工程上的问题,把模型的深度和宽度分布在多台机器上并行,这样可以减少计算复杂度。
2.2 Training Dataset
当要的到GPT-3这么大的模型时,就不得不考虑大数据了。作者在这一节里介绍了他们的主要数据来源是基于Common Crawl来采样的。

在GPT-2那篇文章中,作者有提到说这个数据集质量低,所以他们没有采用,而是采取了其它方式构建了新的数据集,但在GPT-3中,为了训练如此大的模型,作者不得不采用该数据集了。为了提高数据集的质量,作者采取了3个步骤来提高数据集的平均质量:(1)下载并筛选了与一系列高质量参考语料库相似的Common Crawl版本,简单来讲,就是拿一个质量高的参考语料,经过对比来筛选出common crawl中的高质量语料,对比的方法我看网上有人说用的二分类,就是把common crawl数据集中质量低的当成负样本,其它质量高的数据集当成正样本,训练一个二分类模型,然后再用二分类模型去筛选common crawl,这是一种方法,反正无所谓了,只要能够较好的完成这项工作,用什么方式去筛选都行,属于数据特征工程的任务;(2)在文档层面进行了模糊去重,防止冗余并保持验证集的完整性,以此作为准确衡量过拟合的依据,我想这么大批量的去重,十有八九就是用到哈希的方法,类似于LSH;(3)向训练混合中添加了已知的高质量参考语料库,以增加Common Crawl的多样性和丰富性,比如GPT-2、Bert之类的所用到的语料。

从上表中可以看到,虽然common crawl基数很大,但是它的采样率不及下面几个数据集的采样率,这可能是因为作者仍然认为common crawl数据集的质量较低,所以应当降低其采样比例。

作者提到对在大量互联网数据上预训练的语言模型,特别是具有记住大量内容能力的大模型,存在一个主要的方法论问题,即预训练过程中可能会无意中看到测试集或开发集,从而对下游任务产生潜在的污染。其实就是模型的“作弊”问题,这容易导致模型性能虚高。虽然作者做了一些去重,但是由于过滤器设计上的一些缺陷,导致了去重不彻底,也就是GPT-3的数据集中,仍然存在着许多训练样本和测试样本重叠的情况,对于这一问题,重新训练是不可能的,因为成本太高了,所以作者想把它放在后续研究中来解决。
2.3 Training Process
这一小节稍微介绍了一下训练过程(细节无),没有太多值得关注的。
 这段话主要了解一下作者他们用的是v100分布式训练的,其它的没啥,可以看下附录B里的内容:
这段话主要了解一下作者他们用的是v100分布式训练的,其它的没啥,可以看下附录B里的内容:

从附录B可以提炼出以下几点:
- Adam优化器的参数是β1=0.9,β2=0.95,
=10^-8;
- 学习率在前260亿个tokens之前,以余弦衰减策略将学习率从初始值衰减到其10%,之后就保持不变,并在3.75亿个tokens之前采用线性学习率预热策略;
- 根据模型大小,在训练的前4-12亿个tokens期间,逐步将batchsize线性地从一个小值(32k个tokens)增加到全值;
- 训练阶段的数据采样是不放回抽取;
- 所有模型以0.1比例进行权重衰减;
- 输入长度限制在2048个tokens,当一篇文档的总token数小于2048时,用其它文档补齐,总之每条输入序列保证是2048个tokens。如果一条序列是由多个文档组成的,那么文档与文档之间用一个特殊的结束符来区分;
2.4 Evaluation
本节就是关于实验评估的一些介绍,不同的是,作者采用的是上下文学习的方式,由于这里不涉及微调,所以对GPT-3的评估就是直接用预训练好的模型拿不同数量的示例样本进行评估了。
写到这里,其实关于GPT-3比较重要的部分都介绍完了,后面的一堆内容就是关于各种实验任务的介绍,以及一堆附录,感兴趣的小伙伴根据自己的需求挑着看就行。
总结
总结一下,GPT-1中,作者提出了无监督预训练结合任务相关的微调训练范式,将输入结构改成和任务相关的样子进行微调,这也是后续Bert、T5等模型的训练方式;GPT-2中,作者将任务相关的输入全用自然语言来描述,而不再使用特殊符号区分不同任务,这也是后来指示学习的范式,并提出了零样本在语言模型训练上的应用;GPT-3一改前面模型的训练范式,直接用大规模语料进行模型的训练,而不需要使用特定任务的微调,并在少样本示例上验证了大规模数据训练以及大参数量模型性能的提升,这也是现如今各大语言模型所采用的的基本方式。总结一句话:牛逼!
相关文章:
ChatGPT追祖寻宗:GPT-3技术报告要点解读
论文地址:Language Models are Few-Shot Learners 往期相关文章: ChatGPT追祖寻宗:GPT-1论文要点解读_五点钟科技的博客-CSDN博客ChatGPT追祖寻宗:GPT-2论文要点解读_五点钟科技的博客-CSDN博客 本文的标题之所以取名技术报告而不…...

java easyexcel 导出多级表头
maven <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>${easyexcel.version}</version> </dependency> 导出行的对象 import com.alibaba.excel.annotation.ExcelIgnore; import …...

rar格式转换zip格式,如何做?
平时大家压缩文件时对压缩包格式可能没有什么要求,但是,可能因为工作需要,我们要将压缩包格式进行转换,那么我们如何将rar格式转换为其他格式呢?方法如下: 工具:WinRAR 打开WinRAR,…...

Java中的构造方法
在Java中,构造方法是类的特殊方法,用于初始化对象的实例变量和执行其他必要的操作,以便使对象能够正确地工作。构造方法与类同名,没有返回类型,并且在创建对象时自动调用。 以下是构造方法的一些基本特性:…...

【Java】fastjson
Fastjson简介 Fastjson是阿里巴巴的团队开发的一款Java语言实现的JSON解析器和生成器,它具有简单易用、高性能、高可用性等优点,适用于Java开发中的数据解析和生成。Fastjson的主要特点包括: 简单易用:Fastjson提供了简单易用的…...
JMeter之脚本录制
【软件测试面试突击班】如何逼自己一周刷完软件测试八股文教程,刷完面试就稳了,你也可以当高薪软件测试工程师(自动化测试) 前言: 对于一些JMeter初学者来说,录制脚本可能是最容易掌握的技能之一。…...

计算机网络的相关知识点总结
1.谈一谈对OSI七层模型和TCP/IP四层模型的理解? 不管是OSI七层模型亦或是TCP/IP四层模型,它们的提出都有一个共同的目的:通过分层来将复杂问题细化,通过各个层级之间的相互配合来更好的解决计算机中出现的问题。 说到分层…...

WPF实现轮播图(图片、视屏)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
【Vue.js】使用Element搭建首页导航左侧菜单
目录 Mock.js 是什么 有什么好处 安装mockjs 编辑 引入mockjs mockjs使用 login-mock Bus事物总线 首页导航栏与左侧菜单搭建 结合总线完成组件通讯 Mock.js 是什么 Mock.js是一个用于生成随机数据的模拟数据生成器。它可以帮助开发人员模拟接口请求,生…...
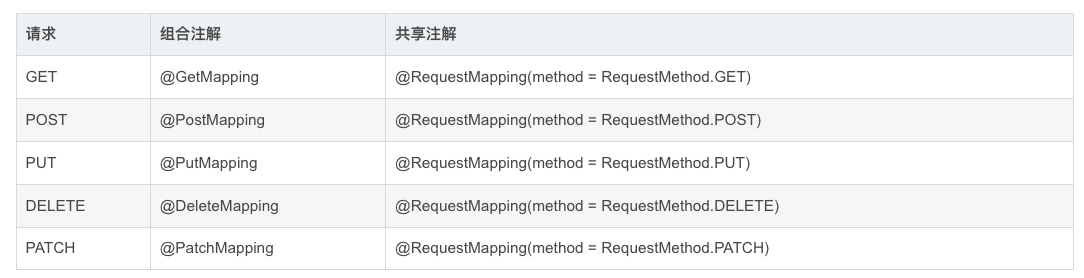
Spring MVC常见面试题
Spring MVC简介 Spring MVC框架是以请求为驱动,围绕Servlet设计,将请求发给控制器,然后通过模型对象,分派器来展示请求结果视图。简单来说,Spring MVC整合了前端请求的处理及响应。 Servlet 是运行在 Web 服务器或应用…...
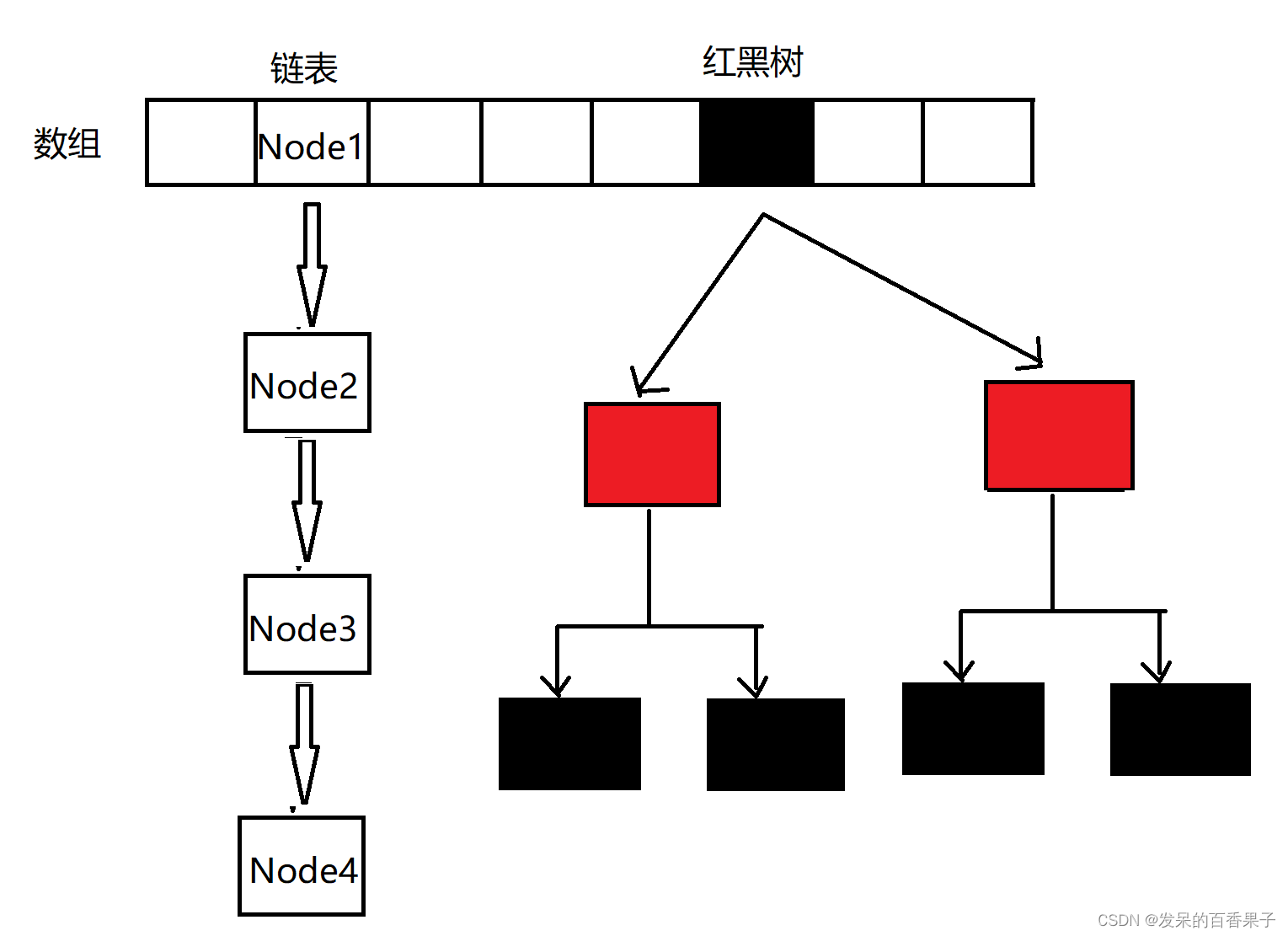
Java基础面试题精选:深入探讨哈希表、链表和接口等
目录 1.ArrayList和LinkedList有什么区别?🔒 2.ArrayList和Vector有什么区别?🔒 3.抽象类和普通类有什么区别?🔒 4.抽象类和接口有什么区别?🔒 5.HashMap和Hashtable有什么区别&…...
Spark计算框架
Spark计算框架 一、Spark概述二、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)1、Spark的安装模式1.1、Spark(单节点)本地安装1.2 Spark的Standalone部署模式的伪分布式安装1.3Spark的YARN部署模式1.4Spark…...

mybatis缓存源码分析
mybatis缓存源码分析 背景 在java程序与数据库交互的过程中永远存在着性能瓶颈,所以需要一直进行优化.而我们大部分会直接将目标放到数据库优化,其实我们应该先从宏观上去解决问题进而再去解决微观上的问题.性能瓶颈体现在什么地方呢?第一网络通信开销,网络数据传输通信.…...

机房小探索
现在连不了NJU-WLAN,怀疑是没有插网线,可以考虑买个USB转网卡的接口,但是我的电脑只有两个USB插口,还不知道版本是什么,之后还想连鼠标跟键盘外设呢。只能连NJU_SWI_WLAN,合理怀疑是Software Internet的缩写…...

PHP8的类与对象的基本操作之成员变量-PHP8知识详解
成员变量是指在类中定义的变量。在类中可以声明多个变量,所以对象中可以存在多个成员变量,每个变量将存储不同的对象属性信息。 例如以下定义: public class Goods { 关键字 $name; //类的成员变量 }成员属性必须使用关键词进行修饰…...
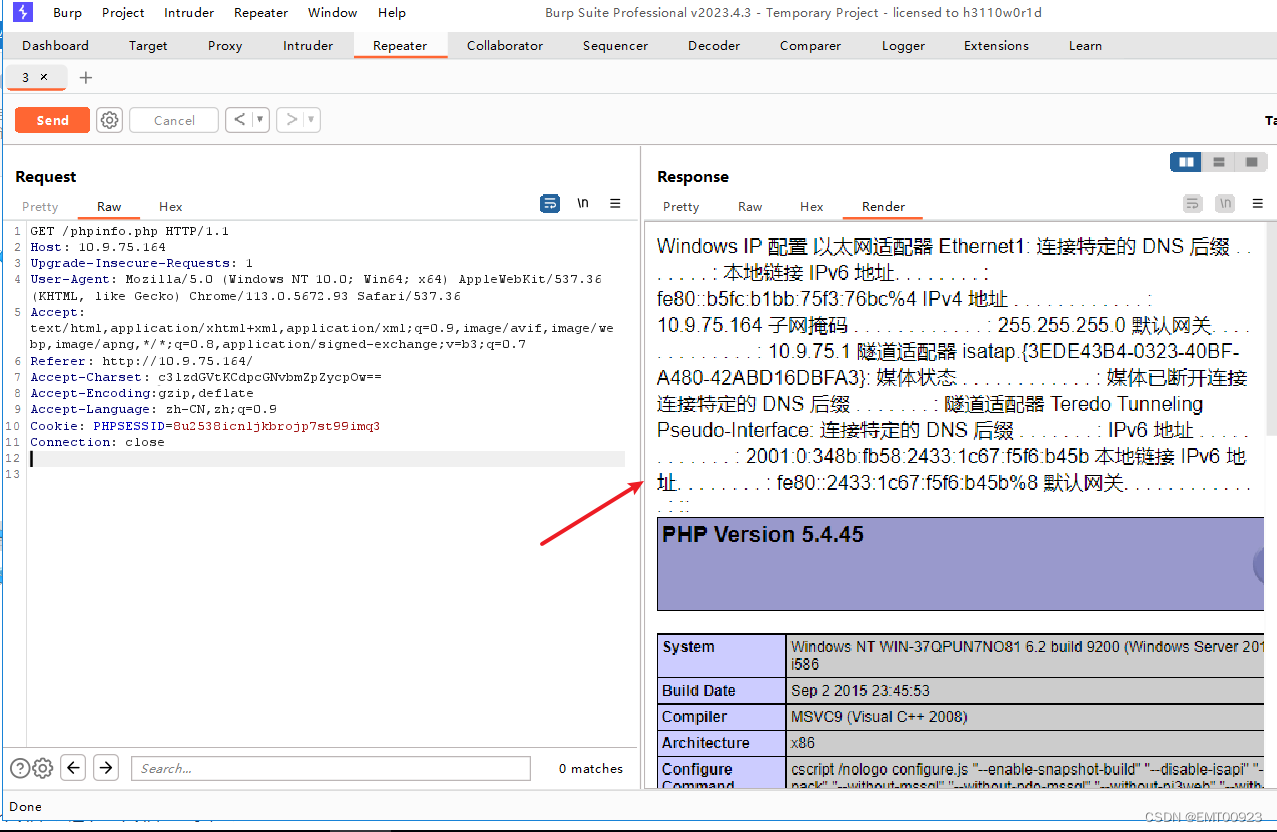
phpstudy2016 RCE漏洞验证
文章目录 漏洞描述漏洞验证 漏洞描述 PHPStudyRCE(Remote Code Execution),也称为phpstudy_backdoor漏洞,是指PHPStudy软件中存在的一个远程代码执行漏洞。 漏洞验证 打开phpstudy2016,用bp自带的浏览器访问www目录下…...

【QT】QT事件Event大全
很高兴在雪易的CSDN遇见你 ,给你糖糖 欢迎大家加入雪易社区-CSDN社区云 前言 本文分享QT中的事件Event技术,主要从QT事件流程和常用QT事件方法等方面展开,希望对各位小伙伴有所帮助! 感谢各位小伙伴的点赞关注,小易…...
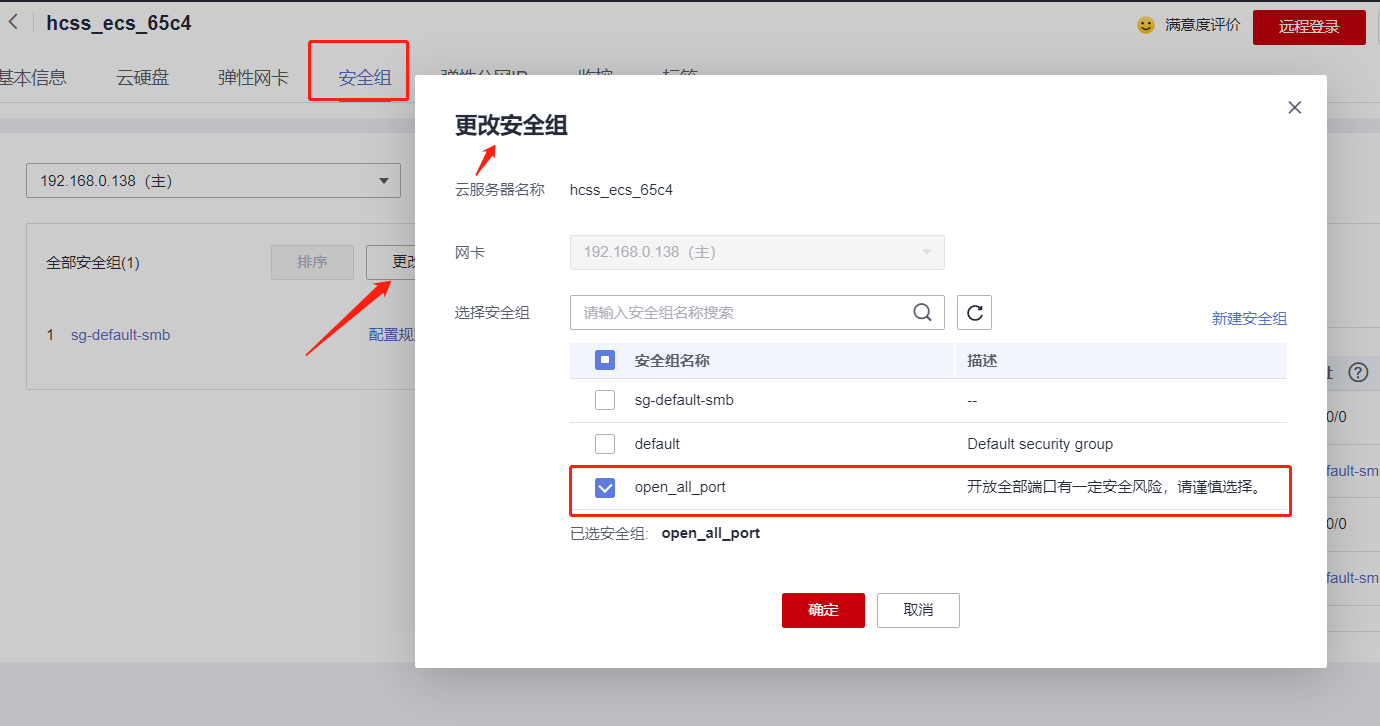
华为云云耀云服务器L实例评测|华为云上安装etcd
文章目录 华为云云耀云服务器L实例评测|华为云上安装etcd一、什么是etcd官方硬件建议 二、华为云主机准备三、etcd安装1. 安装预构建的二进制文件2. 从源代码构建 四、etcd服务注册与发现1. 配置etcd2. 使用systemctl 管理启动etcd服务3. 注册服务4. 发现服务 五、其…...

RDLC动态设置整个表格是否显示
最近有个新的需求:使用RDLC打印,当数据库中能查出数据时,显示表格。没有数据时,不显示整个表格。 1.首先在RDLC中选中表格的任意一列,右键Tablix属性 2.Tablix属性中选中可见性》选中基于表达式显示或隐藏(E)并点开右…...
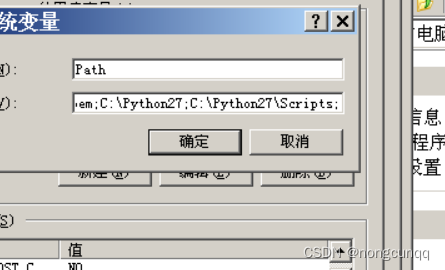
xp 系统 安装 python 2.7 ide pip
1 下载python http://www.python.org/ftp/python/ python-2.7.2.msi 安装完需要设置环境变量 2 下载 setuptools setuptools-0.6c11.win32-py2.7.exe https://pypi.tuna.tsinghua.edu.cn/simple/setuptools/ 3 下载 pip ,python 2.7 最高支持 pip 20.3.4 https:…...

快速上手3DGS数字孪生开发:一份必做的技术动作盘点清单
一、行业核心技术科普:3DGS数字孪生开发的关键技术节点从零开始构建一个基于3D高斯泼溅(3DGS)的数字孪生应用,涉及多个关键技术节点。每个节点的执行质量,都直接影响最终应用的性能与用户体验。其域创新推出的LCC格式&…...
)
Android 14开发避坑:用audit2allow搞定SELinux权限拒绝(Python 2.7环境配置详解)
Android 14开发实战:用audit2allow精准解决SELinux权限问题 在Android系统开发中,SELinux权限问题就像一道无形的墙,经常让开发者陷入"明明代码没问题,为什么功能就是不工作"的困境。特别是升级到Android 14后ÿ…...

基于雪崩晶体管设计2ns快速边沿脉冲发生器:原理、实现与调试
1. 项目概述与核心价值在射频、高速数字电路测试,甚至是核物理、激光雷达的前沿实验中,我们常常会遇到一个令人头疼的问题:市面上能买到的标准脉冲信号源,其输出脉冲的上升时间(Rise Time)往往在几十纳秒甚…...

Mos:三步解决Mac鼠标滚动卡顿,免费享受触控板般丝滑体验
Mos:三步解决Mac鼠标滚动卡顿,免费享受触控板般丝滑体验 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction in…...

Claude Code 2026 路线图深度拆解:5 大新增能力与企业级项目落地时间表
1. 5 大新增能力不是“功能列表”,而是上下文治理的5个切口 大多数人看到「Claude Code 2026 路线图」的第一反应,是去官网截图那张带箭头和时间轴的PPT——然后立刻开始评估“哪个功能我团队下周就能用上”。我试过。去年Q4我们团队在三个项目里并行接入了路线图中已发布的…...

终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧
终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox是一款专业的免费…...

前沿:小目标检测,YOLOv11n 再进化!
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 https://sensors.myu-group.co.jp/sm_pdf/SM4311.pdf 计算机视觉研究院专栏 Column of Computer Vision Institute 基于最新 YOLOv…...

Hyper-V虚拟机文件迁移避坑指南:从C盘挪走Ubuntu,释放系统盘空间
Hyper-V虚拟机文件迁移实战:安全释放C盘空间的完整方案 当你在Windows系统上使用Hyper-V运行Ubuntu虚拟机时,是否注意到C盘空间正在被悄悄吞噬?许多技术爱好者初次接触Hyper-V时,往往直接采用默认设置,将所有虚拟机文件…...

传递函数极零点分析:从RC滤波器到系统稳定性设计
1. 从电路到方程:理解传递函数的基石在电子工程,尤其是模拟电路和信号处理领域,我们常常需要精确描述一个系统如何“加工”输入信号。比如,一个简单的RC低通滤波器,它如何让低频信号顺利通过,同时抑制高频噪…...
)
别再怕模型不准了!用MATLAB的musyn命令搞定鲁棒控制器设计(附D-K迭代详解)
用MATLAB的musyn命令实现工业级鲁棒控制器设计实战指南 在控制系统的实际工程应用中,模型不确定性就像房间里的大象——人人都知道存在,却常常选择忽视。直到某天,精心设计的控制器在真实环境中表现失常,工程师们才意识到那些被忽…...