【数据结构】Map 和 Set
目录
- 二叉搜索树
- 二叉搜索树---查找
- 二叉搜索树---插入
- 二叉搜索树---删除
- Map和Set
- Map的使用
- Set的使用
- 哈希表
- 哈希冲突
- 冲突避免
- 冲突解决
- 冲突解决---闭散列
- 冲突解决---开散列
- 题目练习
- 只出现一次的数
- 复制带随机指针的链表
- 宝石与石头
- 旧键盘
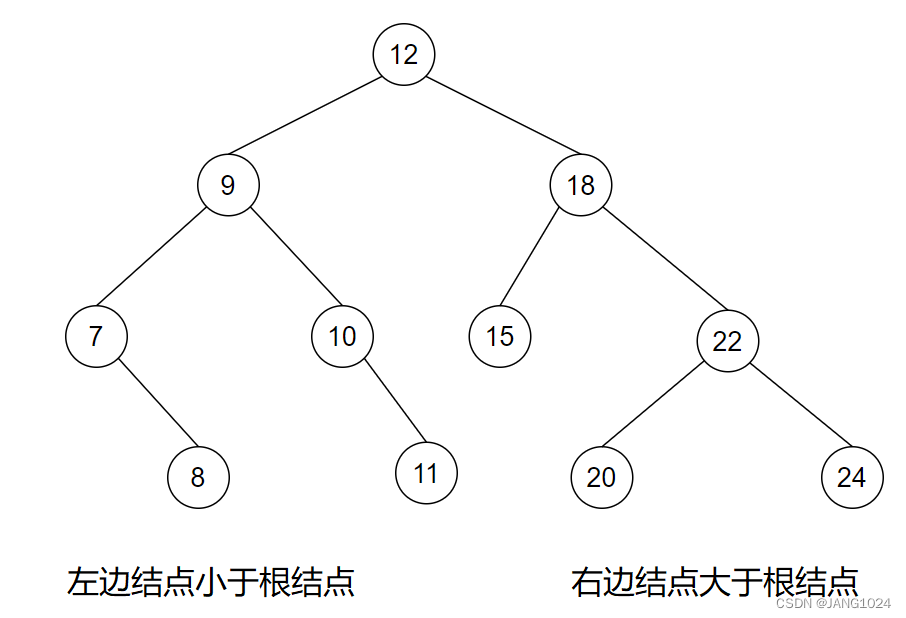
二叉搜索树
二叉搜索树也叫二叉排序树,具有以下性质:
- 若它的左子树不为空,则左子树的所有结点的值都小于根结点的值。
- 若它的右子树不为空,则右子树的所有结点的值都大于根结点的值。
- 左右子树都是二叉搜索树。
例如:
二叉搜索树—查找
二叉搜索树和普通二叉树的结构都一样,只是结点的值不太一样。
//二叉搜索树结构
static class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int val) {this.val = val;}
}public TreeNode root = null;
如何在二叉搜索树中查找某一结点值?我们可以根据二叉搜索树的性质,如果要查找的值大于根结点的值就继续往右边查找,如果要查找的值小于根结点的值就继续往左边查找。
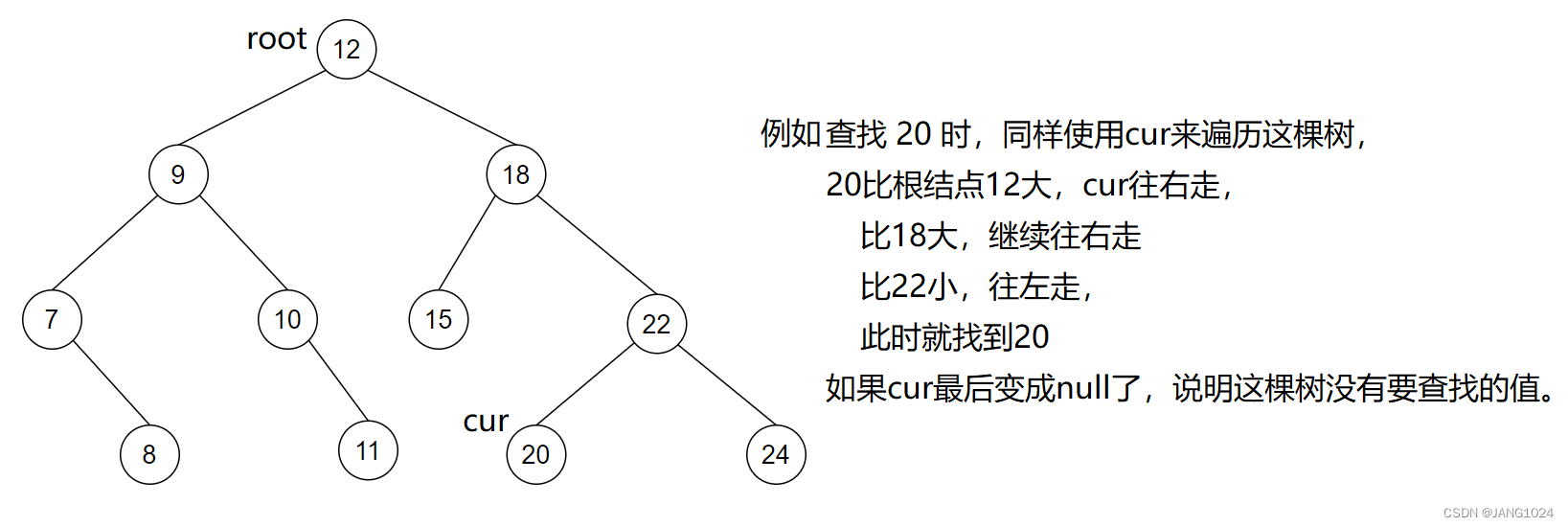
查找代码:
public TreeNode find(int val) {TreeNode cur = root;while (cur != null) {//大于往右边if (val > cur.val) {cur = cur.right;} else if (val < cur.val) {//小于往左边cur = cur.left;} elsereturn cur;}return null;
}
二叉搜索树—插入
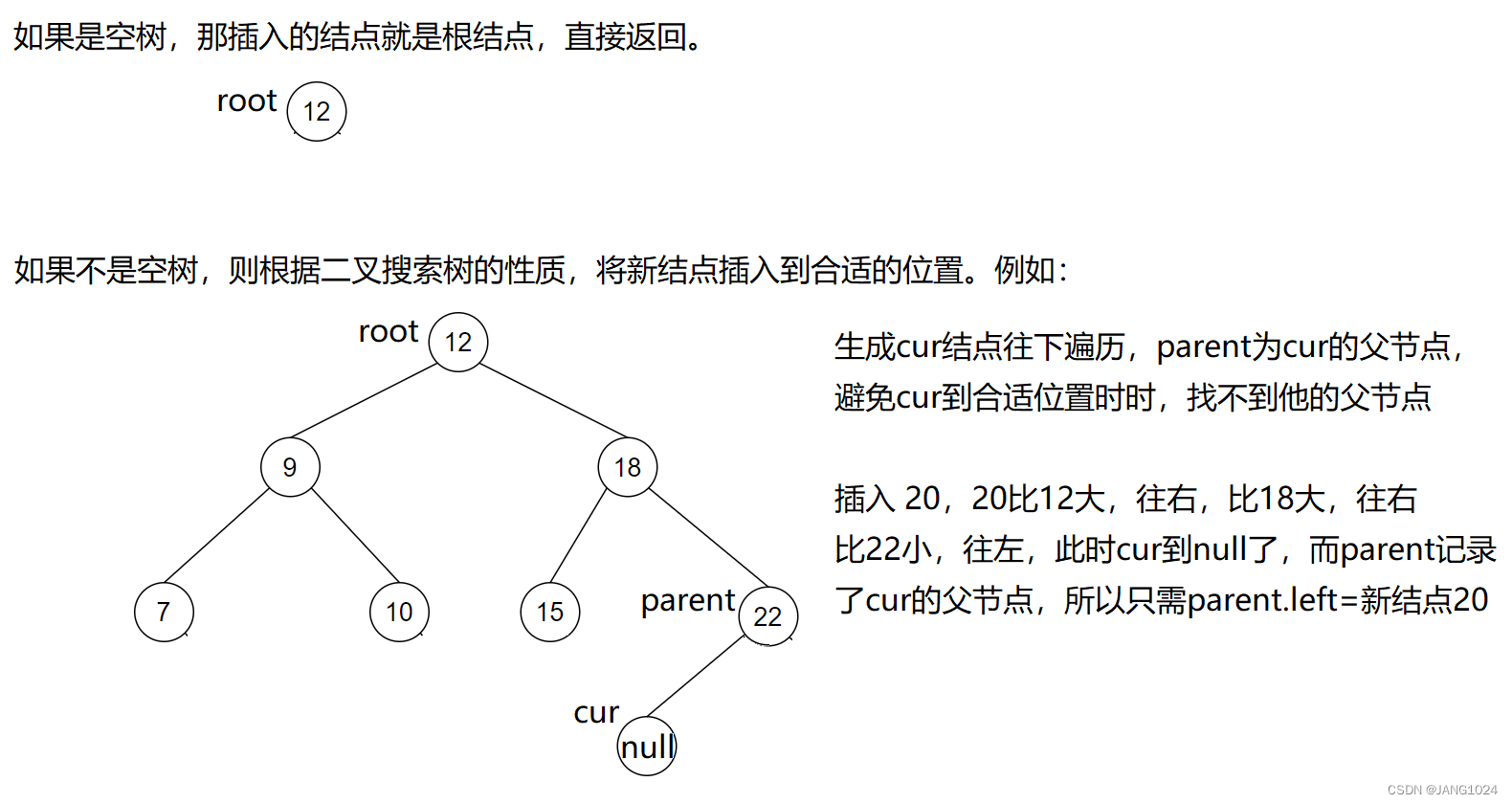
插入代码:
public boolean insert(int val) {TreeNode node = new TreeNode(val);//空树if (root == null) {root = node;return true;}TreeNode cur = root;TreeNode parent = null;while (cur != null) {if (val == cur.val) {return false;} else if (val < cur.val) {parent = cur;cur = cur.left;} else {parent = cur;cur = cur.right;}}//cur为空了,小于放左边,大于放右边if (val < parent.val) {parent.left = node;} else {parent.right = node;}return true;
}
二叉搜索树—删除
假设待删除结点为 cur,待删除结点的双亲结点为 parent,那么有下面几种情况:
-
cur.left 为空
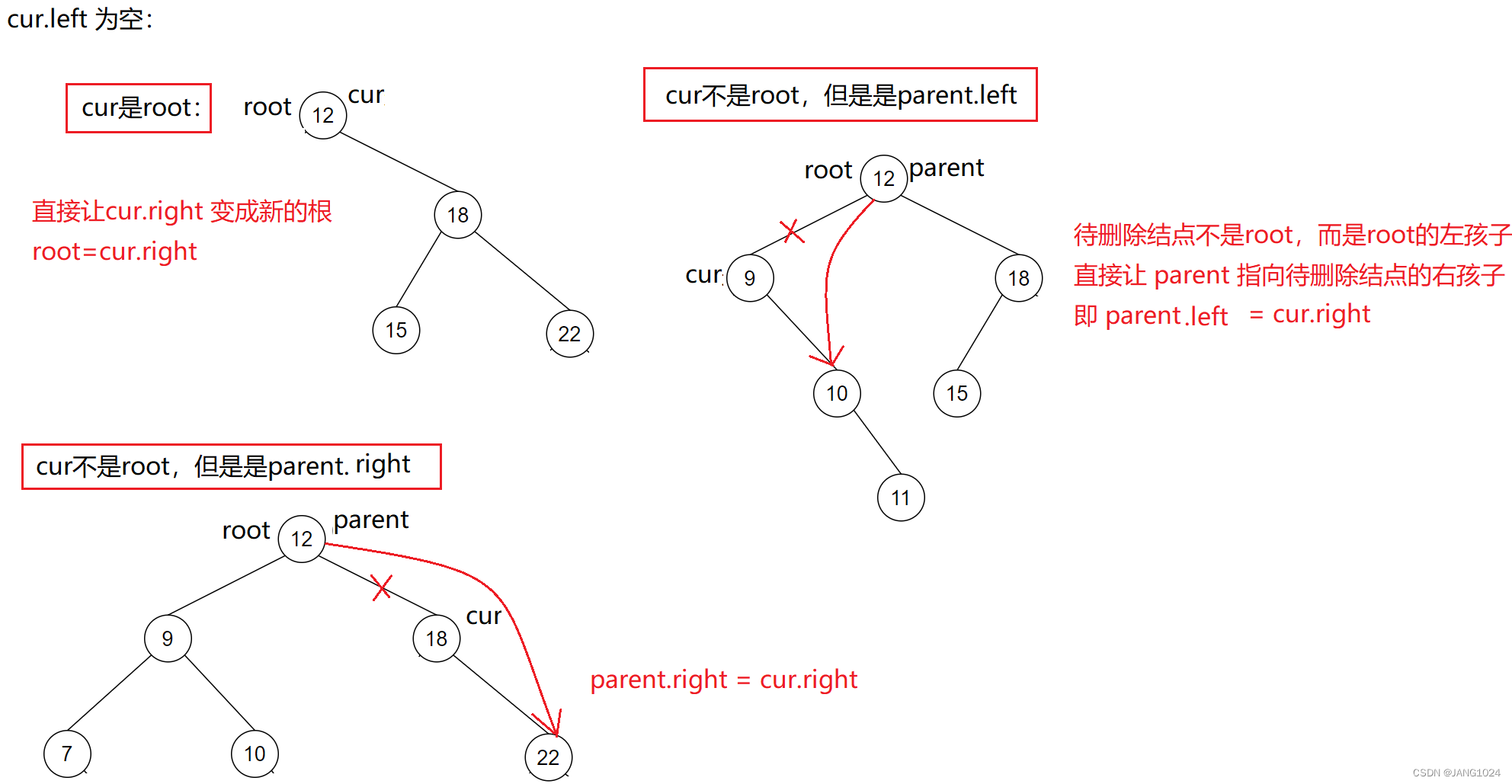
-
cur.right 为空
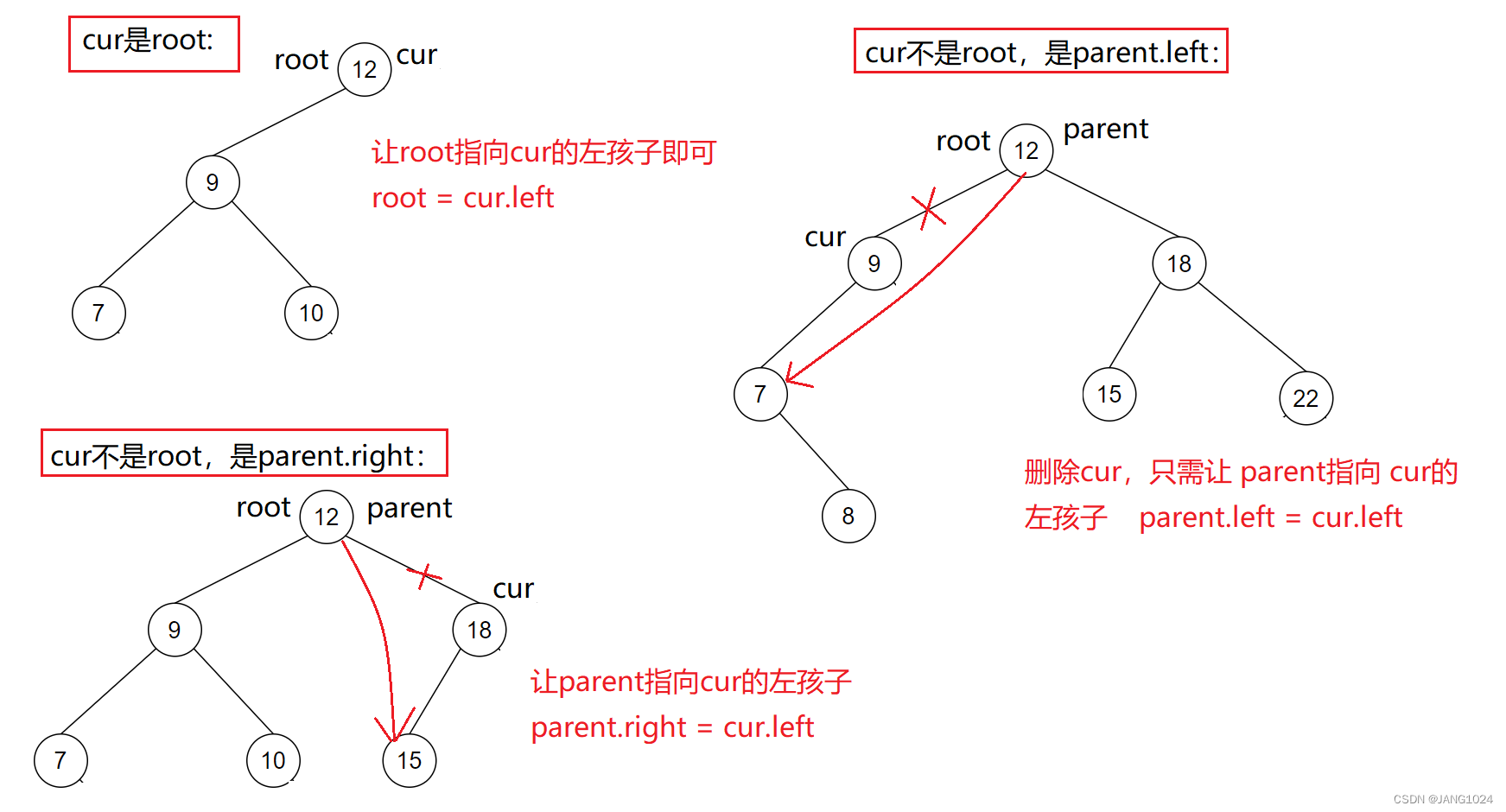
-
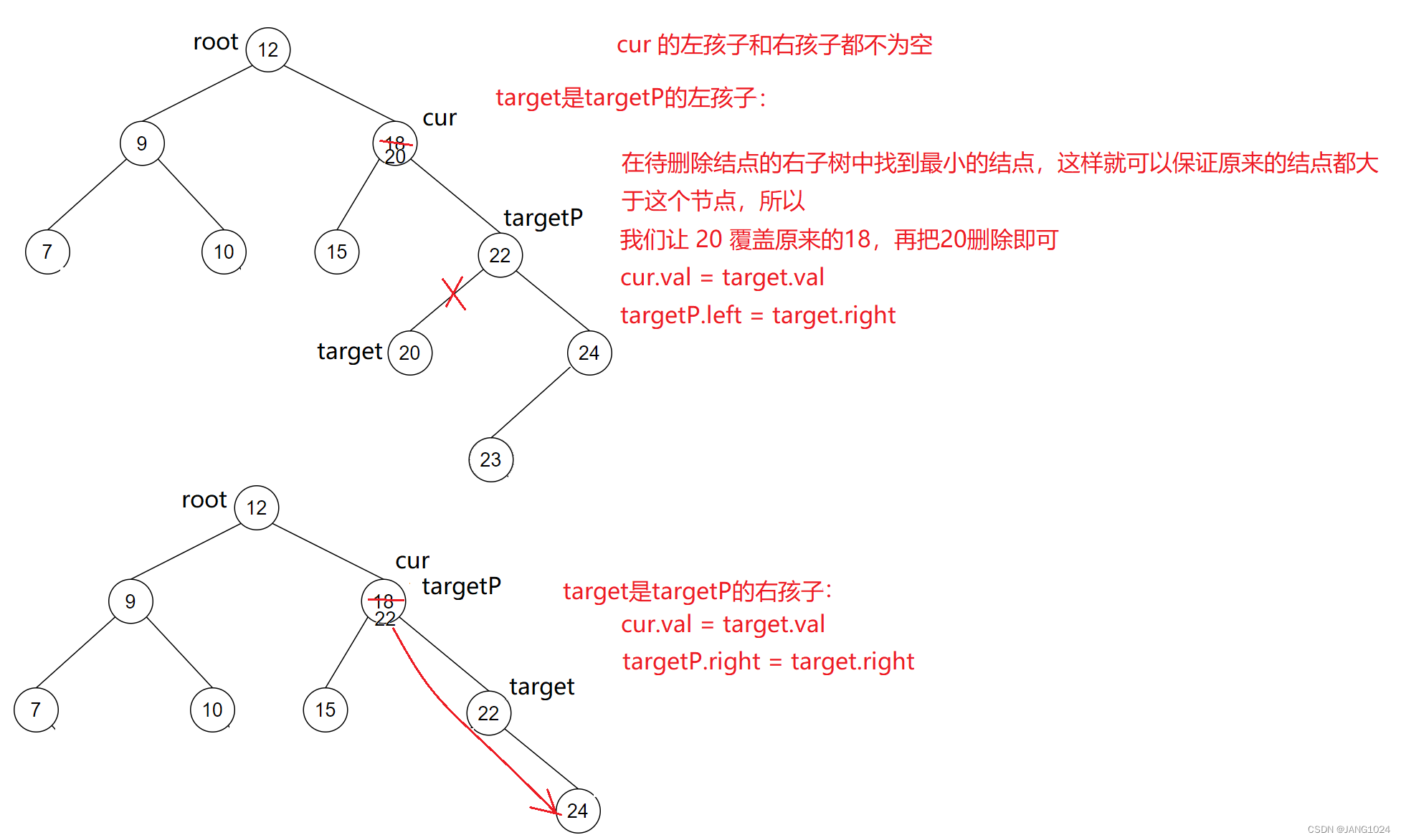
cur.left 不为空 并且 cur.right 不为空
删除代码:
public void remove(int val) {TreeNode cur = root;TreeNode parent = null;//循环遍历找到要删除的结点while (cur != null) {if (cur.val == val) {//找到后,判断当前节点的情况removeNode(parent, cur);return;} else if (cur.val < val) {parent = cur;cur = cur.right;} else {parent = cur;cur = cur.left;}}
}//根据结点情况删除结点
private void removeNode(TreeNode parent, TreeNode cur) {//待删除结点的左为空if (cur.left == null){if (cur == root){root = cur.right;}else if (parent.left == cur){parent.left = cur.right;}else {parent.right = cur.right;}//待删除结点的右为空}else if (cur.right == null){if (cur == root){root = cur.left;}else if (parent.left == cur){parent.left = cur.left;}else {parent.right = cur.left;}//待删除结点的左右都不空}else {TreeNode target = cur.right;TreeNode targetParent = cur;//找到最小的结点while (target.left != null){targetParent = target;target = target.left;}//将最小结点值替换待删除结点cur.val = target.val;//判断最小结点是左孩子还是有孩子if (target == targetParent.left){targetParent.left = target.right;}else {targetParent.right = target.right;}}
}
Map和Set
map 和 set 是一种专门用来进行搜索的容器或者数据结构,属于动态查找,也就是在查找时可以进行插入和删除操作。
一般把搜索的数据称为关键字(Key),和 Key 对应的称为值(Value),将其称为 Key-value 的键值对。分为以下两种:
- 纯 key 模型(Set): 例如:某单词是否在一句话中。
- Key-Value 模型(Map): 例如:某单词出现的次数 <单词,出现次数>。
Map的使用
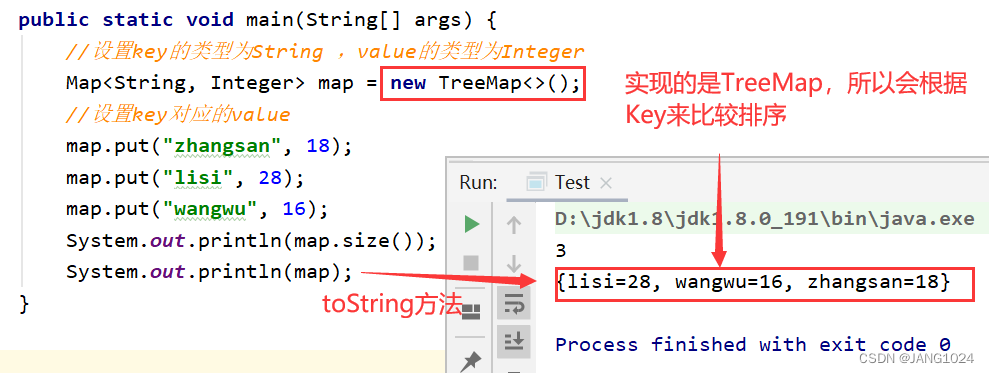
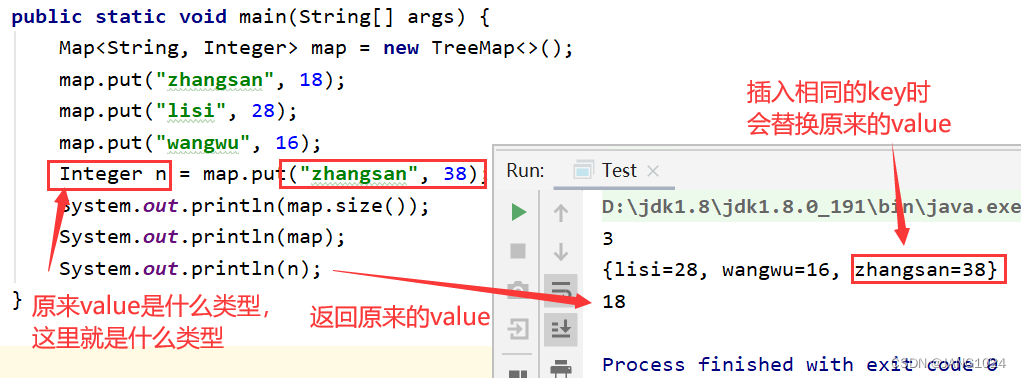
put(K key, V value),设置 key 对应的 value
使用 put 方法时,插入的 key 一定不能是 null,否则会空指针异常,但是 value 可以。
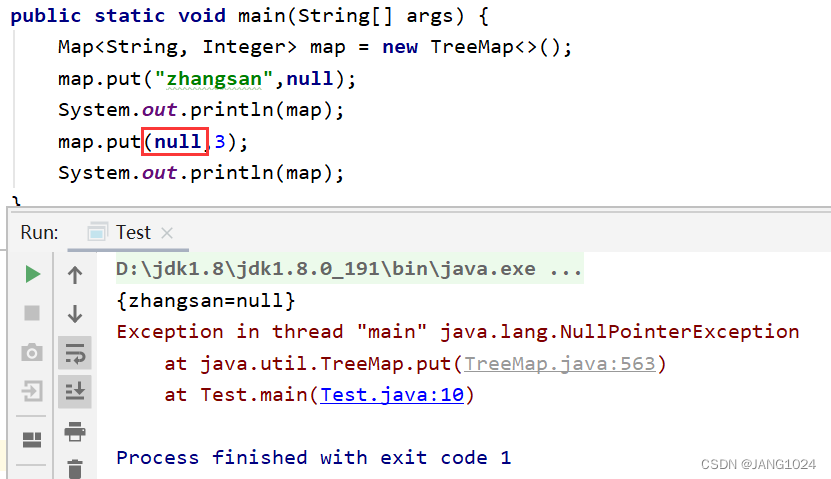
插入的 key 一定是可以比较的,否则会报错。
如果 key 相同,则会替换原来的 value。
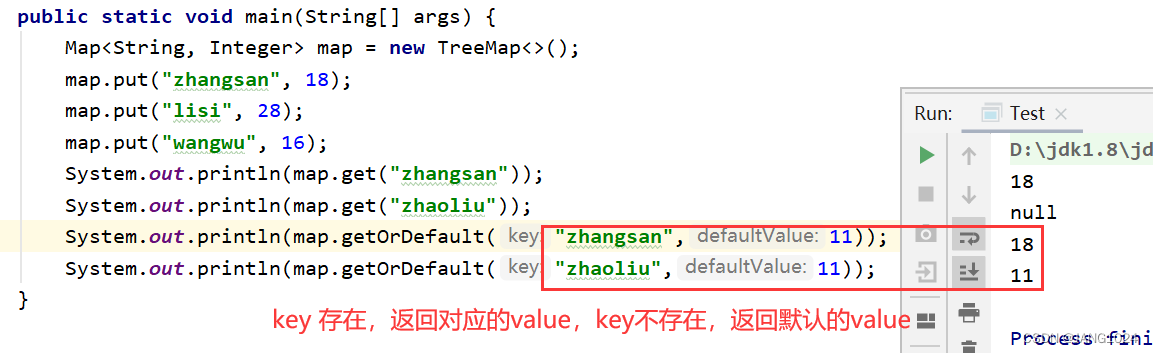
get(Object key) 返回 key 对应的 value
getOrDefault(Object key, V defaultValue) 返回 key 对应的 value,key 不存在,返回默认值
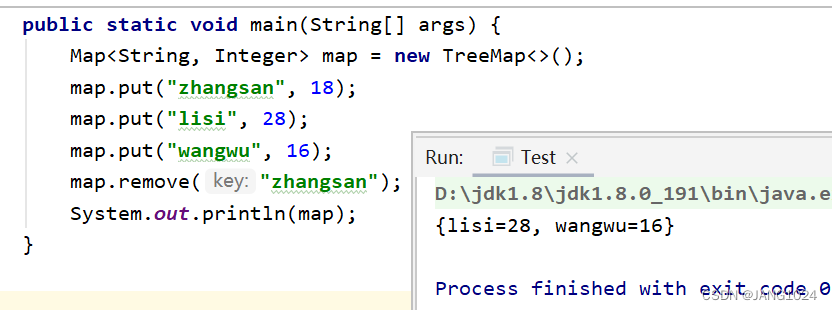
remove(Object key) 删除 key 对应的映射关系
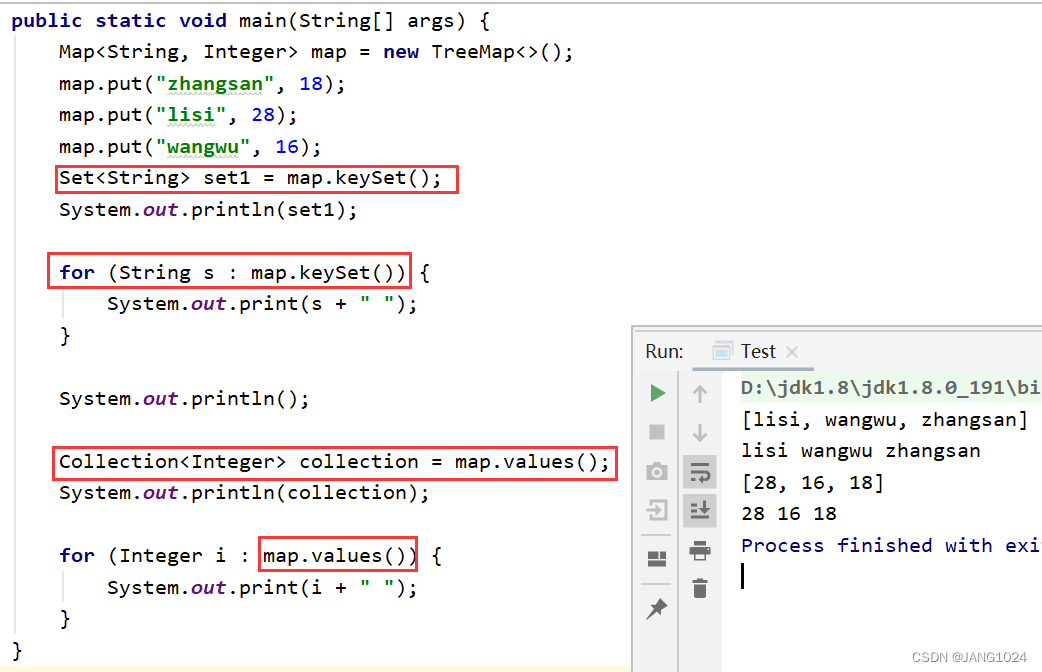
Set<K> keySet() 返回所有 key 的不重复集合
Collection<V> values() 返回所有 value 的可重复集合
Set<Map.Entry<K, V>> entrySet() 返回所有的 key-value 映射关系
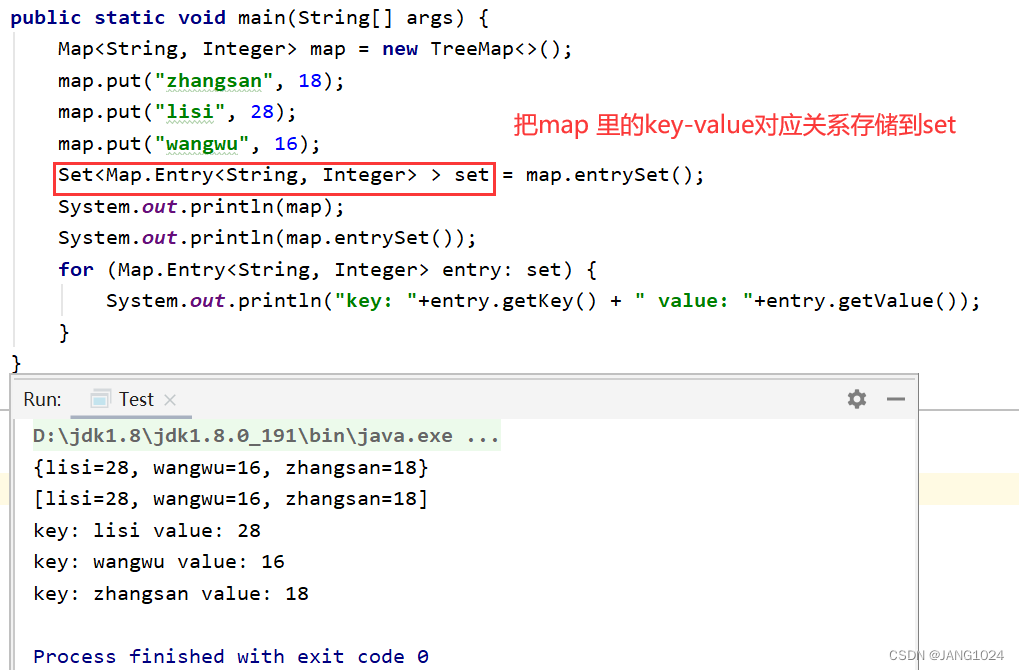
containsKey(Object key) 判断是否包含 key
containsValue(Object value) 判断是否包含 value

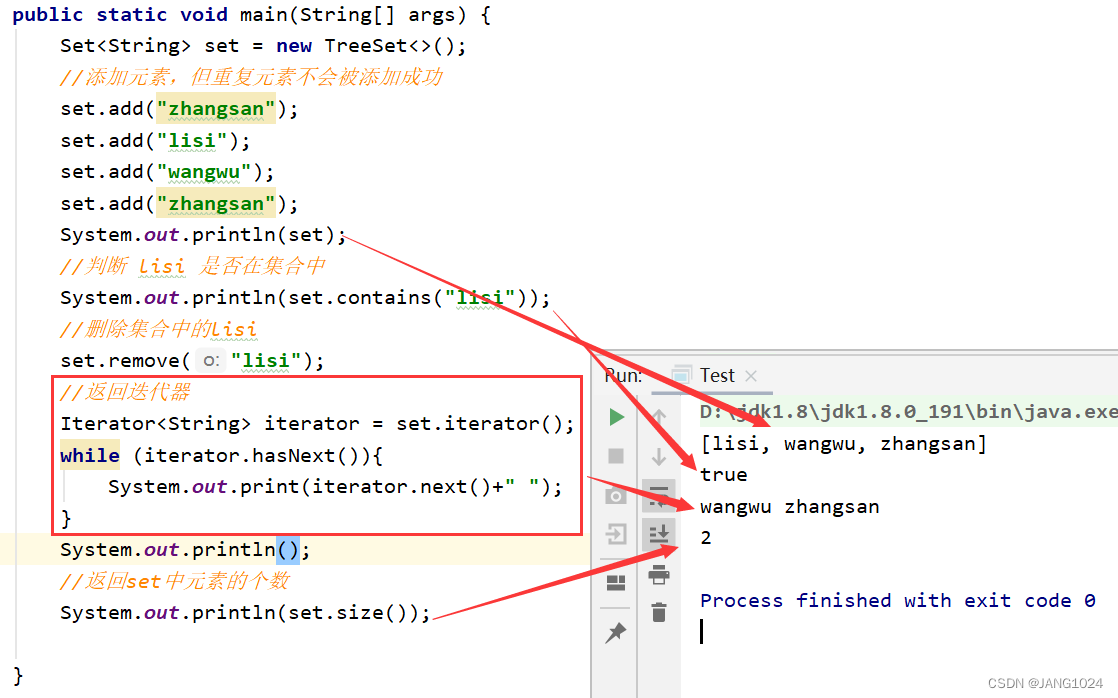
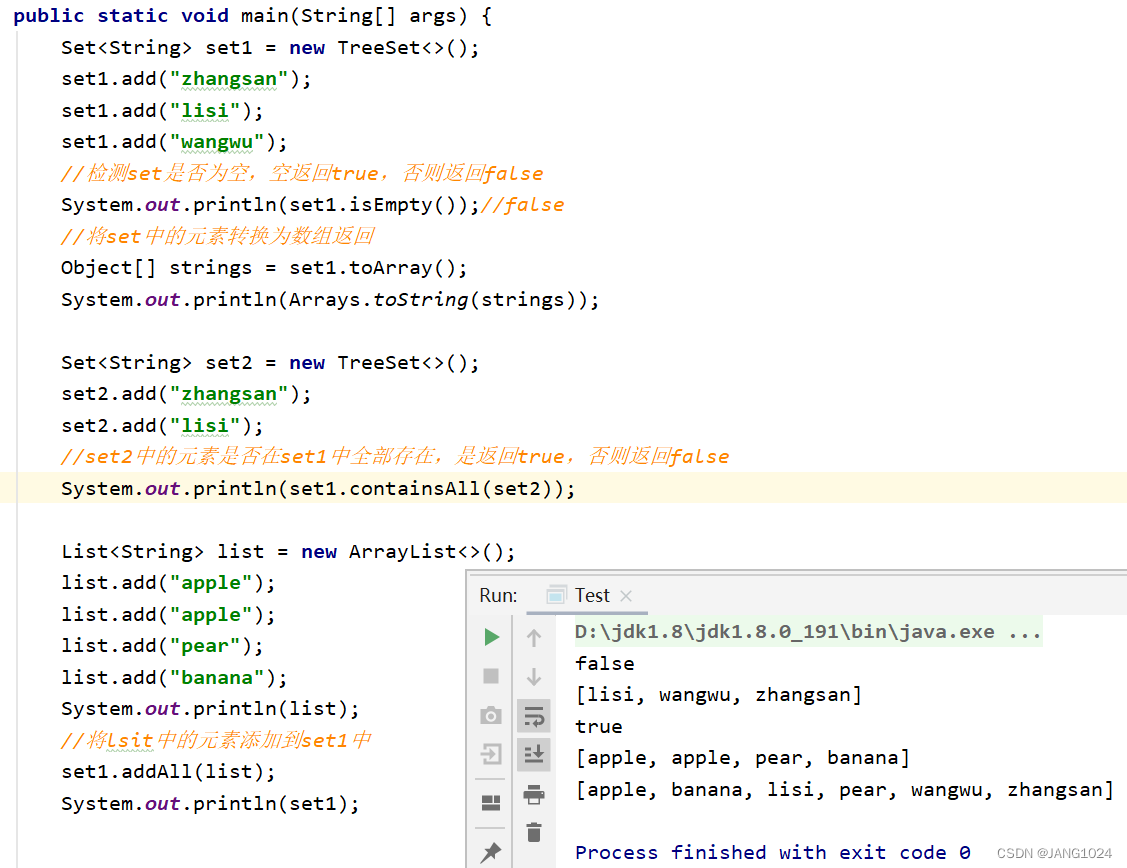
Set的使用
哈希表
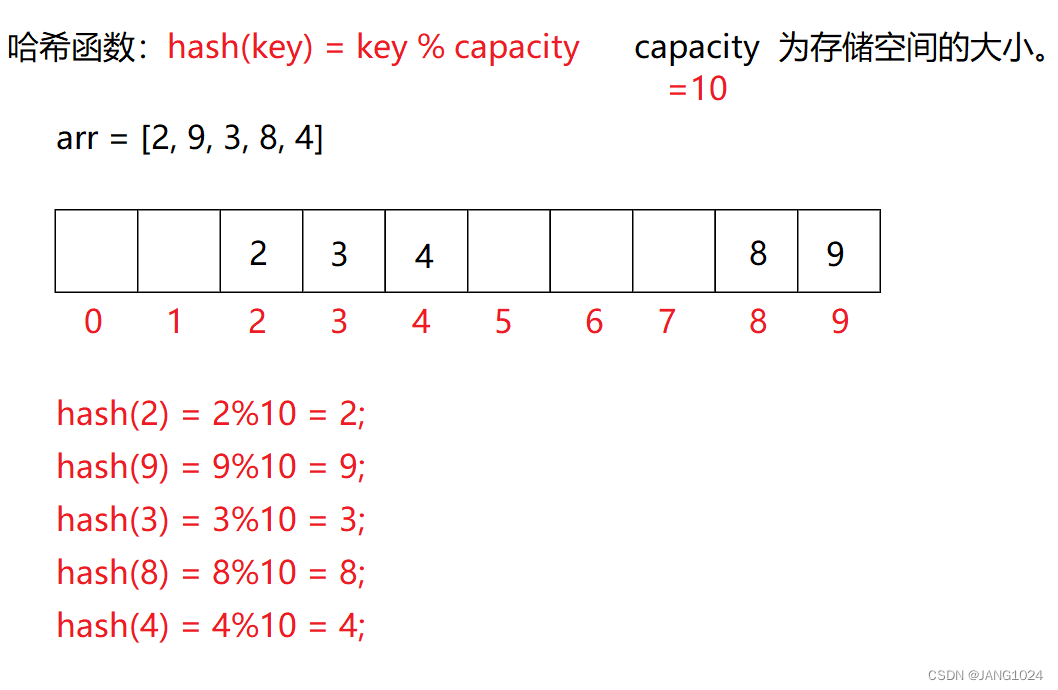
通过某种函数使元素的存储位置与它的关键码之间建立映射关系的一种存储结构叫做哈希表(散列表)。
插入元素: 根据待插入元素的关键码,使用函数计算出该元素的存储位置并按此位置进行存放。
搜索元素: 对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
例如:
哈希冲突
假设现在要插入 23,就会出现冲突:
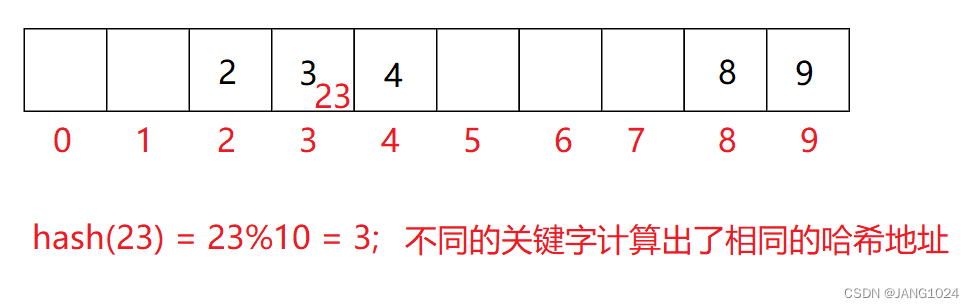
不同关键字通过相同的哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
注意: 哈希表底层数组的容量往往小于实际要存储的数量,这就导致一个问题,冲突的发生是必然的,我们只能尽量的低冲突。
冲突避免
设计合理的哈希函数可以减小冲突的概率。哈希函数设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有 m 个地址时,其值域必须在 0 到 m-1 之间。
- 哈希函数计算出来的地址能均匀分布在整个空间中。
- 哈希函数应该比较简单。
常见哈希函数:
-
直接定制法
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况 -
除留余数法
设散列表中允许的地址数为 m,取一个不大于 m,但最接近或者等于 m 的质数 p 作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址。
还有几个不常用的:平方取中法、折叠法、随机数法、数学分析法。
负载因子调节: α(负载因子) = 元素个数 / 表的长度
负载因子越大,产生冲突的可能性就越大,所以要想减小负载因子,就要增大表的长度(扩容)。
冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列。
冲突解决—闭散列
闭散列: 也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把 key 存放到冲突位置中的 “下一个” 空位置中去。
寻找下一个空位置:
-
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
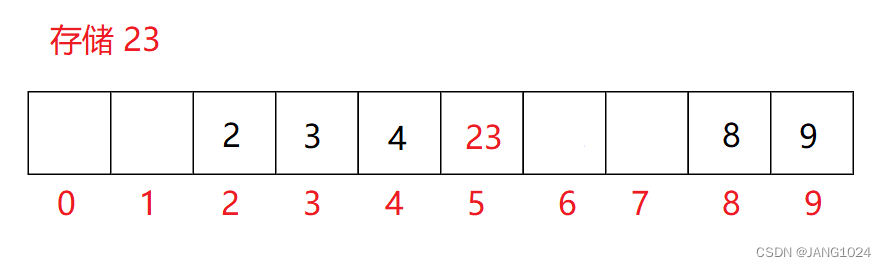
如果再插入 33,那几个数据就会在一块,那就需要其他方法解决这个问题。 -
二次探测:
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:Hiii= ( H000+iii2)% m,i 等于1,2,3……。

冲突解决—开散列
开散列法又叫链地址法(开链法),同样先计算出散列地址,把相同地址的关键码放于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。类似下面这种:
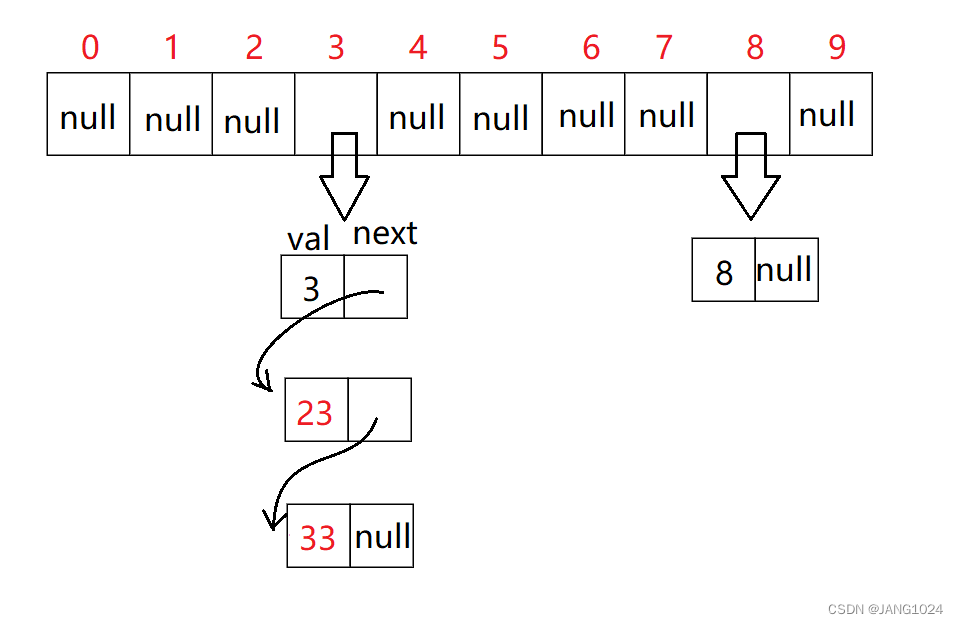
开散列中每个桶中放的都是发生哈希冲突的元素,开散列就是把一个在大集合中的搜索问题转化为在小集合中做搜索了。我们还可以继续优化在小集合中搜索,例如:每个桶的背后是另一个哈希表或者每个桶的背后是一棵搜索树。
题目练习
只出现一次的数
题目链接:【leetcode】136. 只出现一次的数字
题目描述:
这题我们利用 set 的性质来做,使用异或(将数组里的元素全部异或,最后结果就是只出现一次的数字)或者 map(统计每个元素出现的次数,value 为1的就是只出现一次的数字)也可以。

代码:
class Solution {public int singleNumber(int[] nums) {Set<Integer> set = new HashSet<>();for(int x : nums){//利用add函数的返回值,返回false,//说明set中已经存在这个元素,那我们就移除if(!set.add(x)){set.remove(x);}}//最后 set 中就剩下只出现一次的数字for (Integer x : set) {return x;}return -1;}
}
复制带随机指针的链表
题目链接:【leetcode】138. 复制带随机指针的链表
题目描述: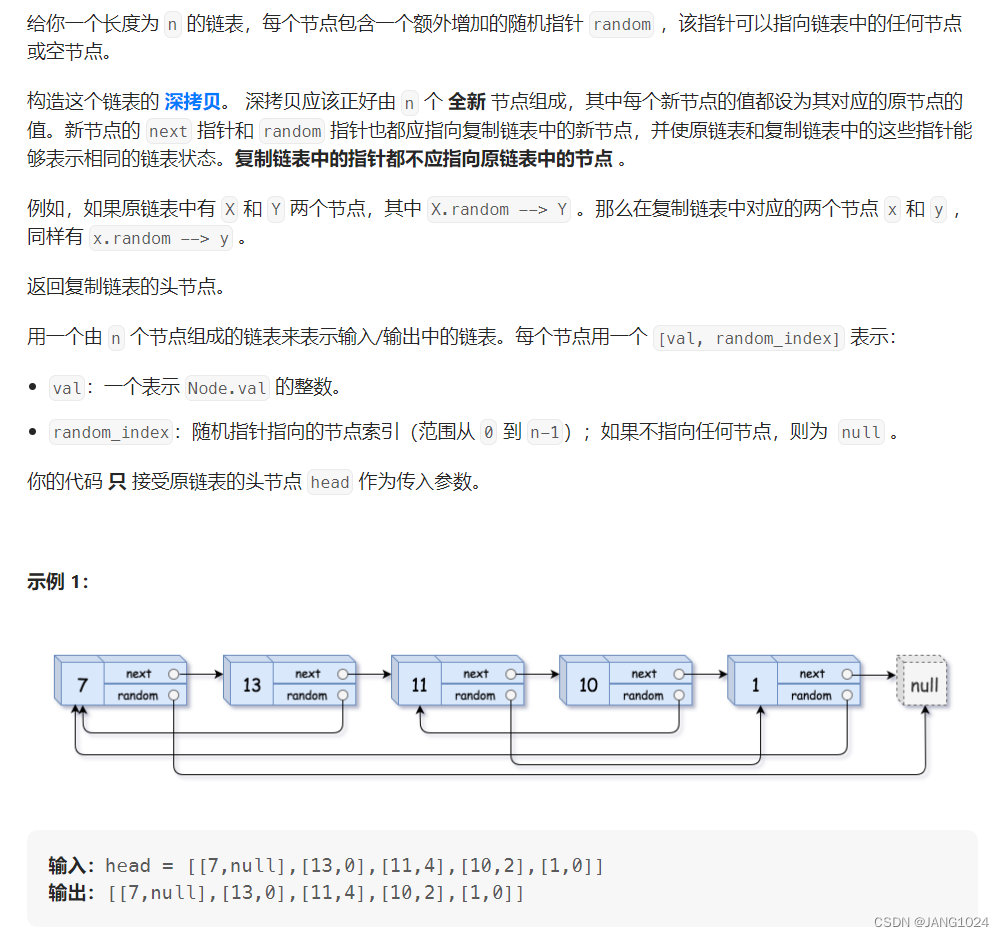
题目的意思就是,我们需要根据题目给的链表,生成同等个数并且结点的 val 相等,所给链表的 next 和 random 域指向链表中的哪个结点,我们就需要在自己生成的链表中指向位置相对应的结点。
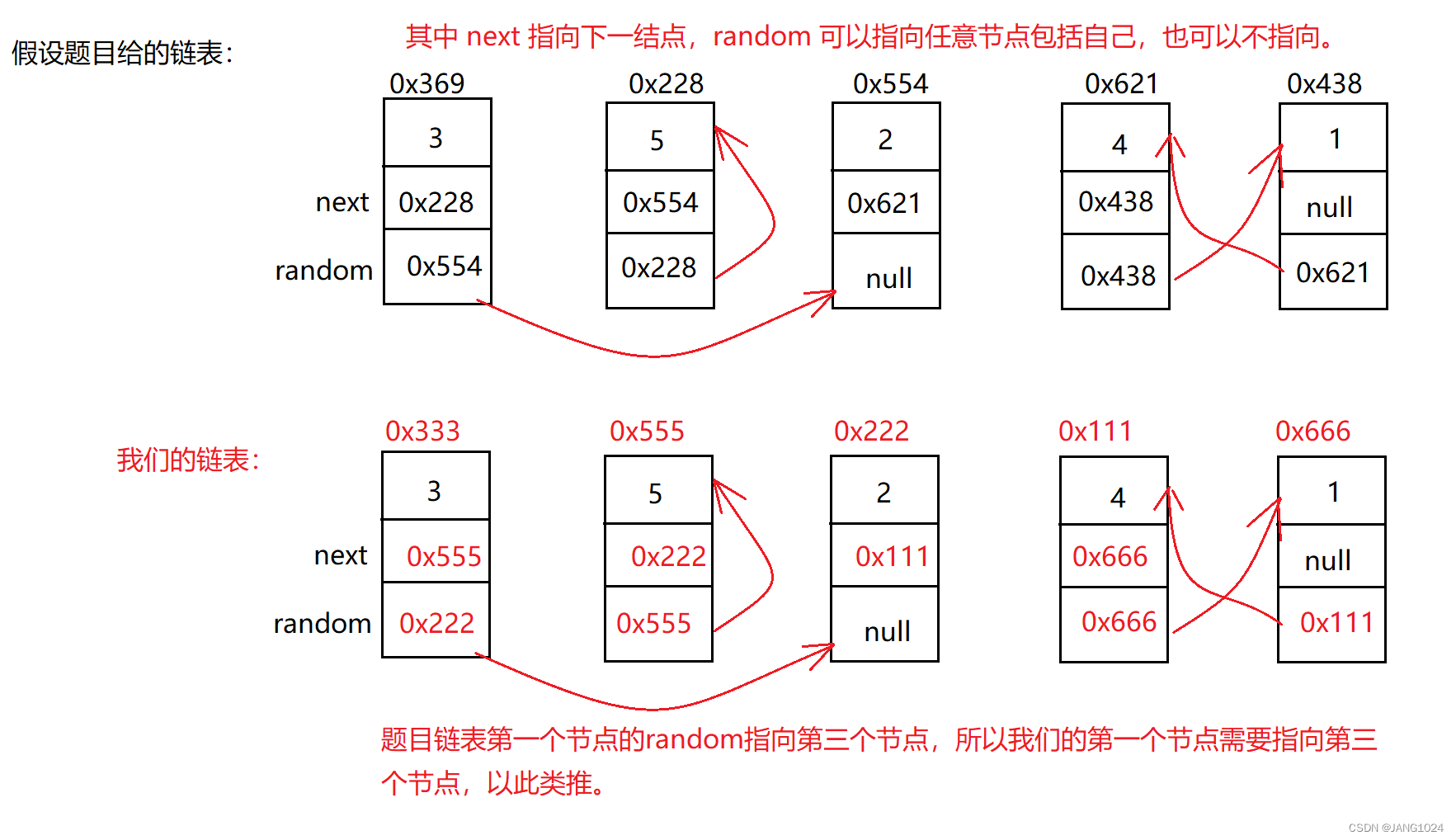
为了达到题目要求,我们可以使用 map 来存储他们对应位置的结点。

代码:
public Node copyRandomList(Node head) {Map<Node, Node> map = new HashMap<>();Node cur = head;//遍历链表while (cur != null) {//生成和题目的链表节点 相同值 的结点Node node = new Node(cur.val);//再把题目中链表的结点 和 生成的新结点存储到 map中map.put(cur, node);cur = cur.next;}//再次指向题目链表的头结点cur = head;while (cur != null) {//获取对应位置关系的结点map.get(cur).next = map.get(cur.next);map.get(cur).random = map.get(cur.random);cur = cur.next;}//新链表的头结点对应老链表头结点的valuereturn map.get(head);
}
宝石与石头
题目链接:【leetcode】771. 宝石与石头
题目描述: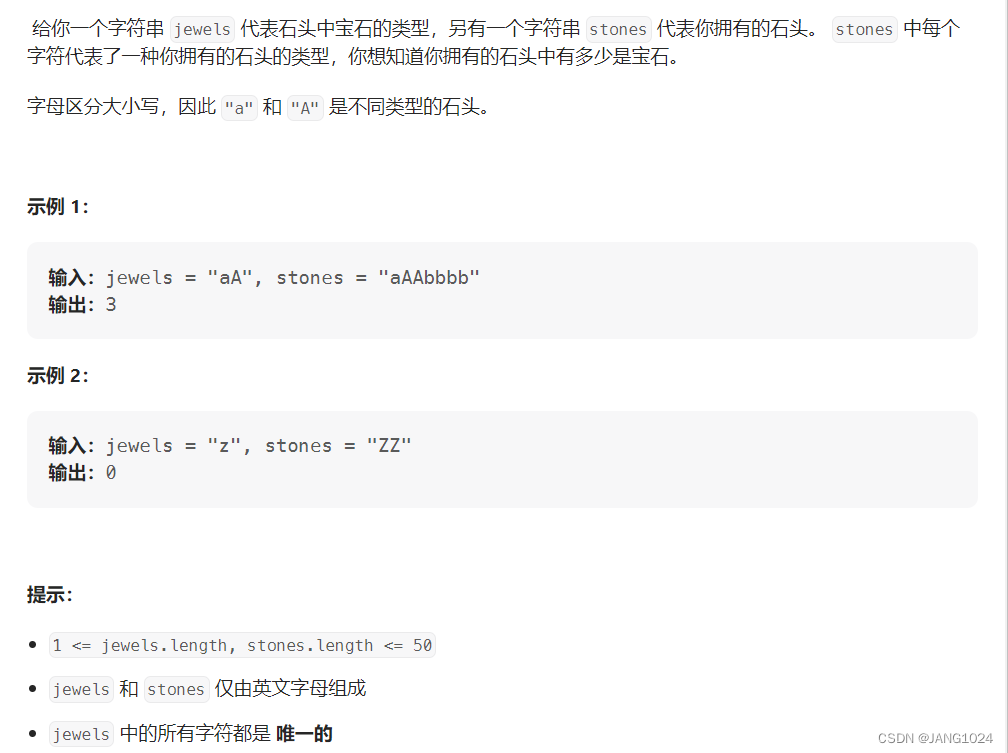
我们可以把宝石都放到 set 中,然后遍历石头,如果 set 中有这个元素,那就是宝石,否则就不是。
代码:
class Solution {public int numJewelsInStones(String jewels, String stones) {Set<Character> set = new HashSet<>();//先把宝石加到 set中for (int i = 0; i < jewels.length(); i++) {set.add(jewels.charAt(i)); }int count = 0;//遍历石头,如果 set中包含,就是宝石for (int i = 0; i < stones.length(); i++) {if (set.contains(stones.charAt(i))) {count++;}}return count;}
}
旧键盘
题目链接:【牛客网】旧键盘
题目描述: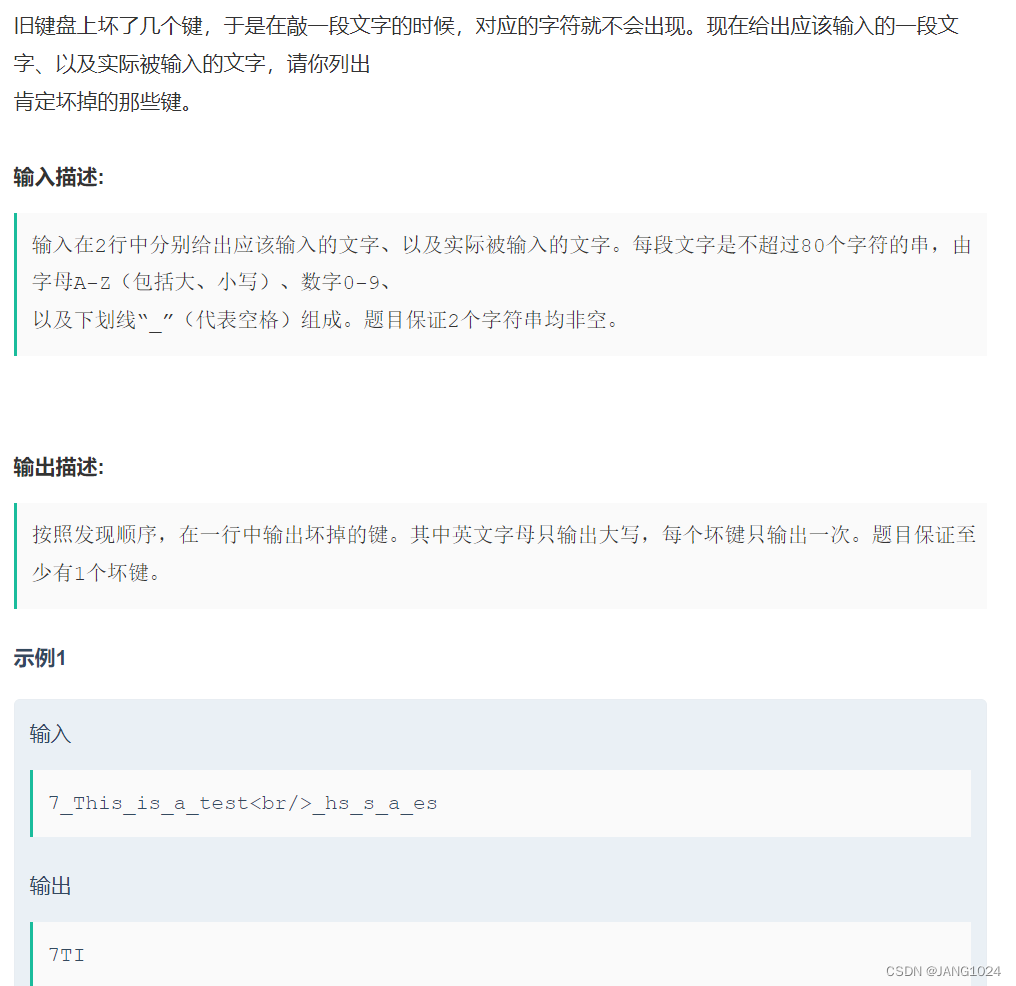
和上题类似,我们把坏键(_hs_s_a_es) 输出的字符串添加到 set 中,在遍历好键(7_This_is_a_test) 输出的字符串,如果没有哪个字符,那个键就是坏的,也就是我们要输出的。
代码:
public static void func(String str1,String str2) {Set<Character> set = new HashSet<>();//把坏键先转成大写,然后存储到 set中for (char c : str2.toUpperCase().toCharArray()) {set.add(c);}Set<Character> res = new HashSet<>();//遍历好键,把不存在的添加到 res中for (char c : str1.toUpperCase().toCharArray()) {//!res.contains(c) 避免重复输出 if (!set.contains(c) && !res.contains(c)) {res.add(c);System.out.print(c);}}
}
相关文章:
【数据结构】Map 和 Set
目录二叉搜索树二叉搜索树---查找二叉搜索树---插入二叉搜索树---删除Map和SetMap的使用Set的使用哈希表哈希冲突冲突避免冲突解决冲突解决---闭散列冲突解决---开散列题目练习只出现一次的数复制带随机指针的链表宝石与石头旧键盘二叉搜索树 二叉搜索树也叫二叉排序树&#x…...
IPVlan 详解
文章目录简介Ipvlan2同节点 Ns 互通Ns 内与宿主机 通信第三种方法Ns 到节点外部结论Ipvlan31. 同节点 Ns 互通Ns 内与宿主机 通信Ns 内到外部网络总结源码分析ipvlan 收包流程收包流程主要探讨使用 ipvlan 为 cni 通过虚拟网卡的实现。简介 ipvlan 和 macvlan 类似,…...

直播间的2个小感悟
我是卢松松,点点上面的头像,欢迎关注我哦! 在线人数固定 最近直播间出现了很多新面孔,有的是偶然刷到的,有的是关注互联网找到的。而直播间的人数一直没什么变化,卢松松在抖音直播较少,主播间…...

STM32开发(15)----芯片内部温度传感器
芯片内部温度传感器前言一、什么是内部温度传感器?二、实验过程1.STM32CubeMX配置2.代码实现3.实验结果总结前言 本章介绍STM32芯片温度传感器的使用方法和获取方法。 一、什么是内部温度传感器? STM32 有一个内部的温度传感器,可以用来测…...
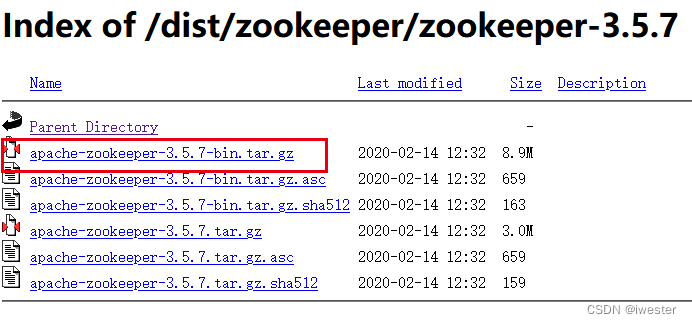
Apache Hadoop生态部署-zookeeper分布式安装
目录 查看服务架构图-服务分布、版本信息 一:安装前准备 1:zookeeper安装包选择--官网下载 2:zookeeper3.5.7安装包--百度网盘 二:安装与常用配置 2.1:下载解压zk安装包 2.2:配置环境变量 2.3&#x…...
)
MySQL(九)
mysql的锁机制 1、MySQL锁的基本介绍 **锁是计算机协调多个进程或线程并发访问某一资源的机制。**在数据库中,除传统的 计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一…...

Matlab 计算一条直线与一条线段的交点
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里假设一条直线的方向为 ( a , b , c ) (a,b,c) (a,b,...
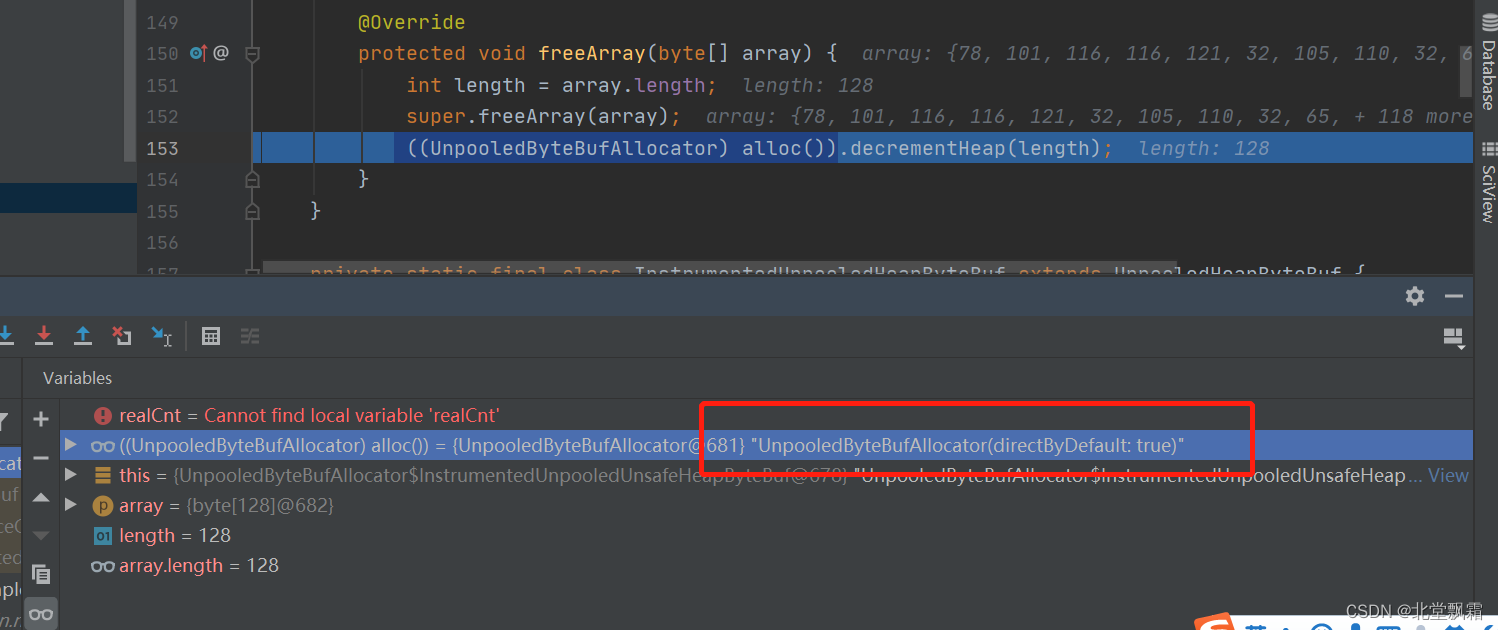
Read book Netty in action(Chapter VI)--ByteBuf
序言 之前学习了传输,通过前面的学习我们都知道,网络数据的基本单位是字节。JDK中提供了ByteBuffer作为字节的容器,但是过于繁琐复杂,Netty中提供了ByteBuf作为替代品。学习一下。 API Netty的数据处理API通过两个组件暴露 ---…...
VsCode开发工具的入门及基本使用
VsCode开发工具的入门及基本使用一、VsCode介绍1.VsCode简介2.VsCode特点二、安装VsCode1.下载VsCode2.安装VsCode3.打开VsCode三、设置VsCode中文1.搜索中文语言插件2.安装中文语言插件四、初识VsCode1.VsCode左侧栏模块2.系统设置功能五、VsCode初始配置1.禁用自动更新2.开启…...

python标准库——OS模块接口详解
OS系统操作模块 os模块提供各种Python 程序与操作系统进行交互的接口 os模块是整理文件和目录最常用的模块 函数作用补充os.sep()取代操作系统特定的路径分隔符os.name()指示你正在使用的工作平台。比如对于Windows,它是nt,而对于Linux/Unix用户&…...
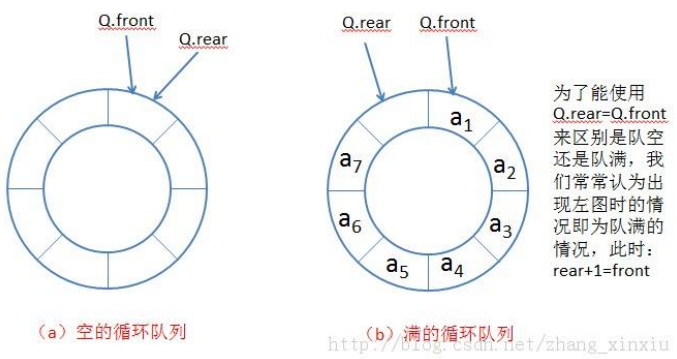
LeetCode 622.设计循环队列
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里&a…...
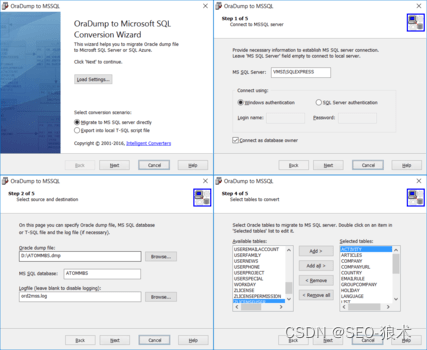
OraDump导出套件
OraDump导出套件 只需单击几下即可将数据从Oracle转储文件导出到流行的数据库和格式。 OraDump Export Kit是一个将数据从Oracle转储文件导出到流行数据库和格式的软件包。该产品具有高性能,因为它直接读取转储文件。命令行支持允许编写脚本、自动化和安排转换过程。…...

CVE-2022-22947 SpringCloud GateWay SPEL RCE 漏洞分析
漏洞概要 Spring Cloud Gateway 是Spring Cloud 生态中的API网关,包含限流、过滤等API治理功能。 Spring官方在2022年3月1日发布新版本修复了Spring Cloud Gateway中的一处代码注入漏洞。当actuator端点开启或暴露时,可以通过http请求修改路由ÿ…...
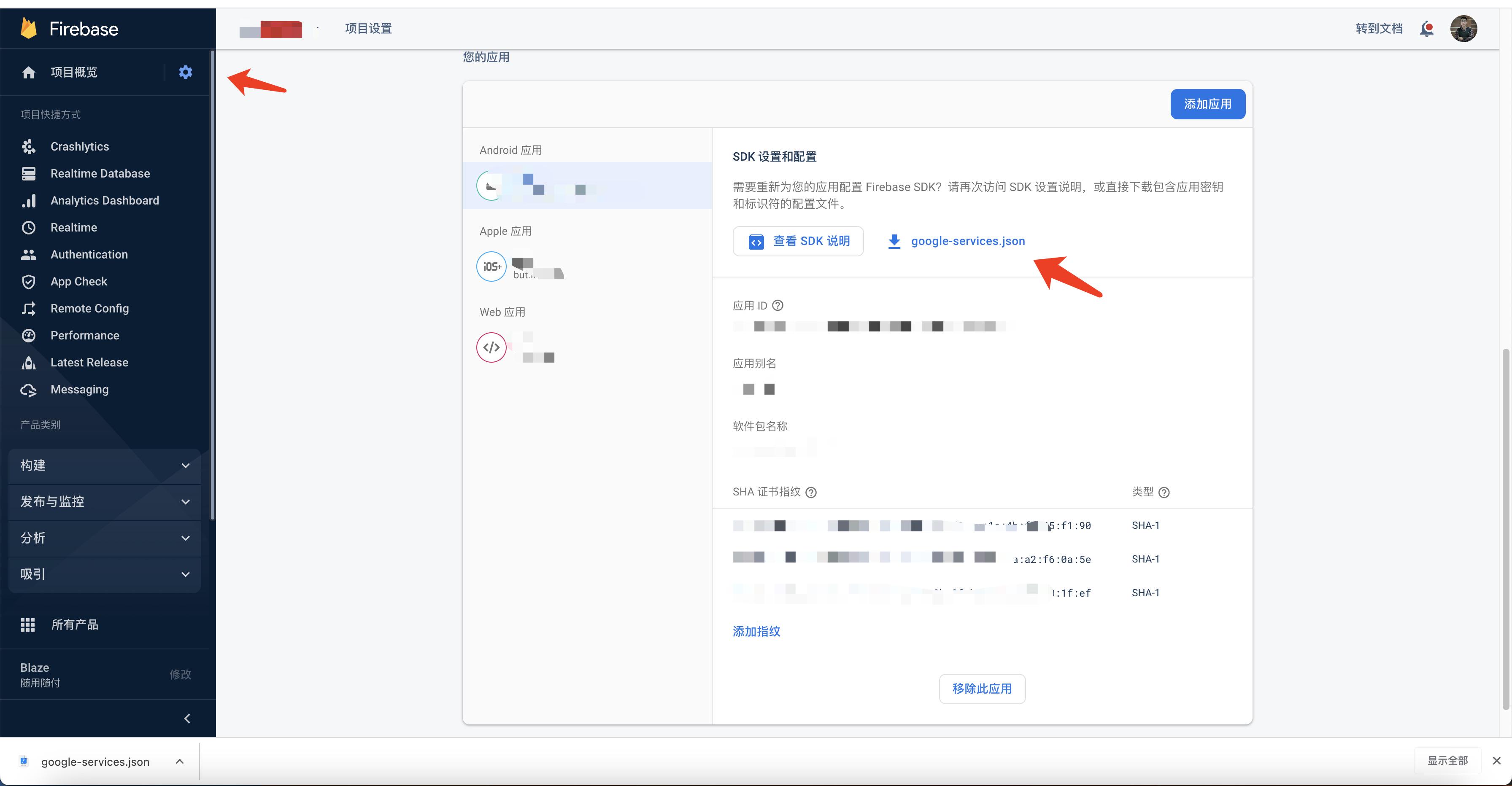
Firebase常用功能和官方Demo简介
一、Firebase简介Firebase刚开始是一家实时后端数据库创业公司,它能帮助开发者很快的写出Web端和移动端的应用。自2014年10月Google收购Firebase以来,用户可以在更方便地使用Firebase的同时,结合Google的云服务。现在的Firebase算是谷歌旗下的…...
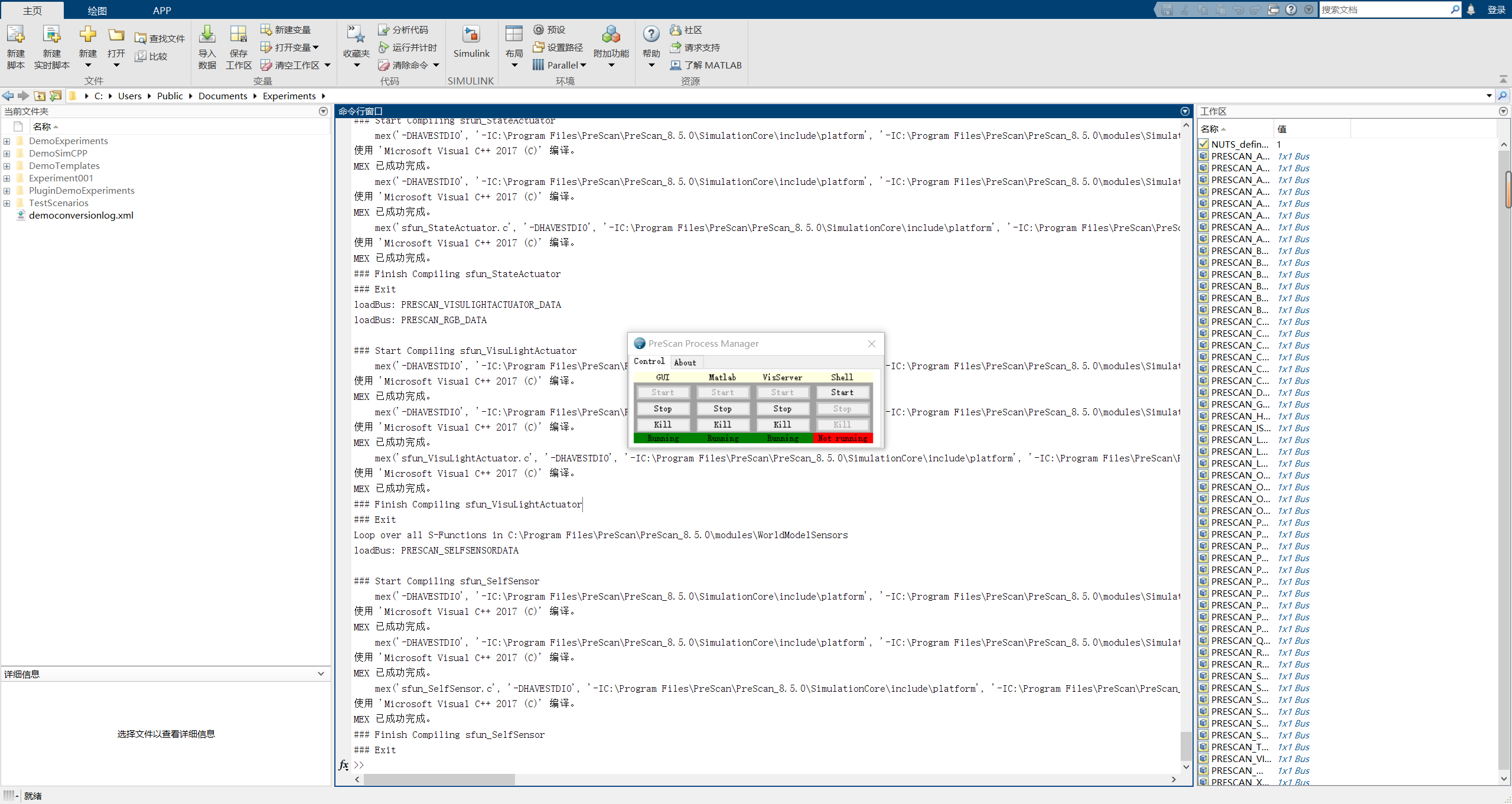
MATLAB R2020a 与PreScan8.5.0 详细安装教程(图文版)
目录MATLAB安装PreScan安装每文一语MATLAB安装 MATLAB是一款数学软件,用于科学计算、数据分析和可视化等任务。以下是MATLAB的几个优势: 丰富的工具箱:MATLAB拥有多种工具箱,包括信号处理、图像处理、优化、控制系统等࿰…...

CNI 网络流量 4.3 Calico felix
文章目录felix 太重要了,单独一文搞懂它Felix是一个守护程序,在每个 endpoints 的节点上运行。Felix 负责编制路由和 ACL 规则等,以便为该主机上的 endpoints 资源正常运行提供所需的网络连接 主要实现一下工作 管理网络接口,Feli…...

超声波风速风向传感器的通讯协议
接线定义 1 电源正 棕色线 4 风向信号 2 电源负 黑色线 5 485A 蓝色线 3 风速信号 6 485B 灰色线 ⊙寄存器参数表 地址 访问权限 参数名称 数据解析方法 0x0000 R 风速 瞬时 *100 上报 0x0001 R 风向 原数上报 0x0002 R 最大风速 *100 上报 0x0003 R 平均风速 *100 上报 0x000…...
—— 直接内存)
JVM笔记(8)—— 直接内存
一、什么是直接内存 直接内存不是虚拟机运行时数据区的一部分,是在运行时数据区外、直接向系统申请的内存空间。 通常,访问直接内存的速度会优于堆,读写性能更好。因此,出于性能考虑,读写频繁的场合可能会考虑使用直…...

Unity性能优化:如何优化Drawcall
前言 降低游戏的Drawcall,是渲染优化很重要的手段,接下来从以下4个方面来分析如何降低DrawCall: 对惹,这里有一个游戏开发交流小组,希望大家可以点击进来一起交流一下开发经验呀 降低Drawcall的意义是什么?如何查看游戏的Drawca…...

类与对象(this 关键字、构造器)
目录一、面向对象二、类与对象三、对象内存图四、成员变量和局部变量区别五、this关键字六、构造器/构造方法一、面向对象 一种编程思想:也就是说我们要以何种思路,解决问题,以何种形式组织代码 当解决一个问题的时候,面向对象会把事物抽象成…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南
如何深度定制索尼相机:Sony-PMCA-RE逆向工程工具完整指南 【免费下载链接】Sony-PMCA-RE Reverse Engineering Sony Digital Cameras 项目地址: https://gitcode.com/gh_mirrors/so/Sony-PMCA-RE 索尼相机逆向工程工具Sony-PMCA-RE是一款专业的开源工具&…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...

ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换
ncmdumpGUI终极指南:3分钟搞定网易云音乐NCM文件转换 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐的NCM加密格式而烦恼吗&…...

LeetCode 每日一题笔记 日期:2026.05.24 题目:1340. 跳跃游戏 V
LeetCode 每日一题笔记 0. 前言 日期:2026.05.24题目:1340. 跳跃游戏 V难度:困难标签:数组、动态规划、记忆化搜索、单调栈 1. 题目理解 问题描述: 给定一个整数数组 arr 和整数 d,从下标 i 出发࿰…...