机器学习-基于KNN及其改进的汉字图像识别系统
一、简介和环境准备
knn一般指邻近算法。 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。而lmknn是局部均值k最近邻分类算法。
本次实验环境需要用的是Google Colab和Google Drive(云盘),文件后缀是.ipynb可以直接用。首先登录谷歌云盘(网页),再打卡ipynb文件就可以跳转到谷歌colab了。再按以下点击顺序将colab和云盘链接。
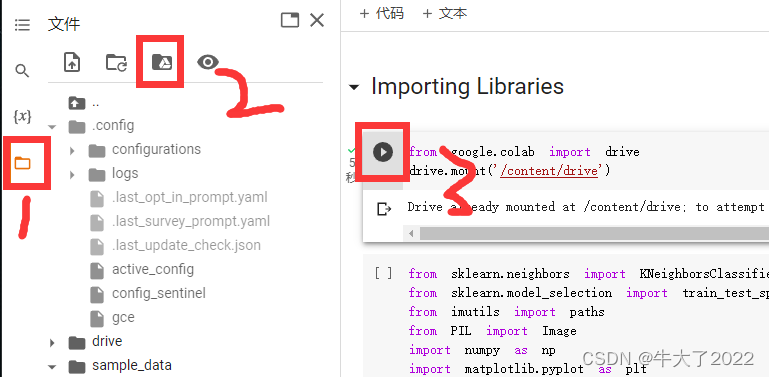
from google.colab import drive
drive.mount('/content/drive')准备的数据是一些分类好的手写汉字图(实验来源在结尾)
引入库
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from imutils import paths
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import glob
import argparse
import imutils
import cv2
import os
# import sys
# np.set_printoptions(threshold=sys.maxsize)二、数据预处理和算法简介
2.1预处理
注意路径的修改。这一步处理所有图片数据,存到xy的train和test。
x_train = []
y_train = []
x_test = []
y_test = []for i in os.listdir('./drive/MyDrive/Chinese-HCR-master/TA_dataset/train'):for filename in glob.glob('drive/MyDrive/Chinese-HCR-master/TA_dataset/train/'+str(i)+'/*.png'):im = cv2.imread(filename, 0) im = cv2.resize(im, (128, 128)) # resize to 128 * 128 pixel sizeblur = cv2.GaussianBlur(im, (5,5), 0) # using Gaussian blurret, th = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)x_train.append(th)y_train.append(i) # append classfor i in os.listdir('./drive/MyDrive/Chinese-HCR-master/TA_dataset/test'):for filename in glob.glob('drive/MyDrive/Chinese-HCR-master/TA_dataset/test/'+str(i)+'/*.png'):im = cv2.imread(filename, 0) im = cv2.resize(im, (128, 128)) # resize to 128 * 128 pixel sizeblur = cv2.GaussianBlur(im, (5,5), 0) # using Gaussian blurret, th = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)x_test.append(th)y_test.append(i) # append classx_train = np.array(x_train) / 255
x_test = np.array(x_test) / 255
y_train = np.array(y_train)
# x_train = np.array(x_train)
# x_test = np.array(x_test)可以打印看一下
plt.imshow(x_train[0])
plt.show()
plt.imshow(x_test[0], 'gray')
plt.show()
2.2算法代码
1.KNN
这里不像上一章分析源码,只调用
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_scoreneigh = KNeighborsClassifier(n_neighbors=3)
xtrain = np.reshape(x_train, (x_train.shape[0], x_train.shape[1] * x_train.shape[1]))
xtest = np.reshape(x_test, (x_test.shape[0], x_test.shape[1] * x_test.shape[1]))prediction = neigh.fit(xtrain, y_train).predict(xtrain)
prediction
print(accuracy_score(y_train,prediction))0.7969348659003831
2.基于HOG特征提取的KNN
from skimage.feature import hogfeatures = np.array(xtrain, 'int64')
labels = y_trainlist_hog_fd = []
for feature in features:fd = hog(feature.reshape((128, 128)), orientations=8, pixels_per_cell=(64, 64), cells_per_block=(1, 1), )list_hog_fd.append(fd)hog_features = np.array(list_hog_fd)
hog_featuresarray([[0.52801754, 0. , 0.52801754, ..., 0. , 0.5 , 0. ], [0.35309579, 0. , 0.54016151, ..., 0. , 0.5 , 0. ], [0.5 , 0. , 0.5 , ..., 0. , 0.5 , 0. ], ..., [0.5035908 , 0. , 0.59211517, ..., 0. , 0.5 , 0. ], [0.51920317, 0. , 0.51920317, ..., 0. , 0.5 , 0. ], [0.55221191, 0. , 0.55221191, ..., 0. , 0.5 , 0. ]])
(注:如果没运行1的knn 要先跑下面的)
neigh = KNeighborsClassifier(n_neighbors=3)
xtrain = np.reshape(x_train, (x_train.shape[0], x_train.shape[1] * x_train.shape[1]))
xtest = np.reshape(x_test, (x_test.shape[0], x_test.shape[1] * x_test.shape[1]))prediction = neigh.fit(hog_features, labels).predict(hog_features)
prediction
print(accuracy_score(labels,prediction))0.6360153256704981
3.带骨架的KNN
from skimage.morphology import skeletonize
from skimage import data
import matplotlib.pyplot as plt
from skimage.util import invert# Invert the horse image
image = invert(x_train[0])# perform skeletonization
skeleton = skeletonize(image)# display results
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 4),sharex=True, sharey=True)ax = axes.ravel()ax[0].imshow(image, cmap=plt.cm.gray)
ax[0].axis('off')
ax[0].set_title('original', fontsize=20)ax[1].imshow(skeleton, cmap=plt.cm.gray)
ax[1].axis('off')
ax[1].set_title('skeleton', fontsize=20)fig.tight_layout()
plt.show()
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
xtrain = np.reshape(x_train, (x_train.shape[0], x_train.shape[1] * x_train.shape[1]))
xtest = np.reshape(x_test, (x_test.shape[0], x_test.shape[1] * x_test.shape[1]))from sklearn.metrics import accuracy_score
prediction = neigh.fit(xtrain, y_train).predict(xtrain)
prediction
print(accuracy_score(y_train,prediction))0.7969348659003831
4.拓展--Otsu方法概述
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('drive/MyDrive/Chinese-HCR-master/TA_dataset/train/亮/37162.png',0)
img = cv.medianBlur(img,5)
ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\cv.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')plt.title(titles[i])plt.xticks([]),plt.yticks([])
plt.show()
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('drive/MyDrive/Chinese-HCR-master/TA_dataset/train/亮/37162.png',0)
# global thresholding
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu's thresholding
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# Otsu's thresholding after Gaussian filtering
blur = cv.GaussianBlur(img,(5,5),0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# plot all the images and their histograms
images = [img, 0, th1,img, 0, th2,blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)','Original Noisy Image','Histogram',"Otsu's Thresholding",'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in range(3):plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()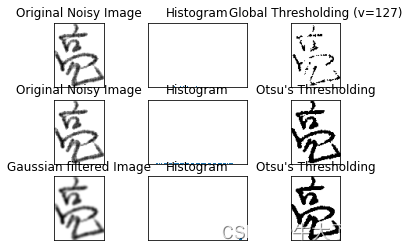
来源:GitHub - NovitaGuok/Chinese-HCR: A Chinese Character Recognition system using KNN, LMPNN, and MVMCNN
相关文章:
机器学习-基于KNN及其改进的汉字图像识别系统
一、简介和环境准备 knn一般指邻近算法。 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。而lmknn是局部均值k最近邻分类算法。 本次实验环境需要用的是Google Colab和Google Dr…...

Zebec生态持续深度布局,ZBC通证月内翻倍或只是开始
“Zebec生态近日利好不断,除了推出了回购计划外, Nautilus Chain 、Zebec Labs等也即将面向市场,都将为ZBC通证深度赋能。而ZBC通证涨幅月内突破100%,或许只是开始。”近日,流支付生态Zebec生态通证ZBC迎来了大涨&…...

Leetcode.1238 循环码排列
题目链接 Leetcode.1238 循环码排列 Rating : 1775 题目描述 给你两个整数 n和 start。你的任务是返回任意 (0,1,2,,...,2^n-1)的排列 p,并且满足: p[0] startp[i]和 p[i1]的二进制表示形式只有一位不同p[0]和 p[2^n -1]的二进制表示形式也…...
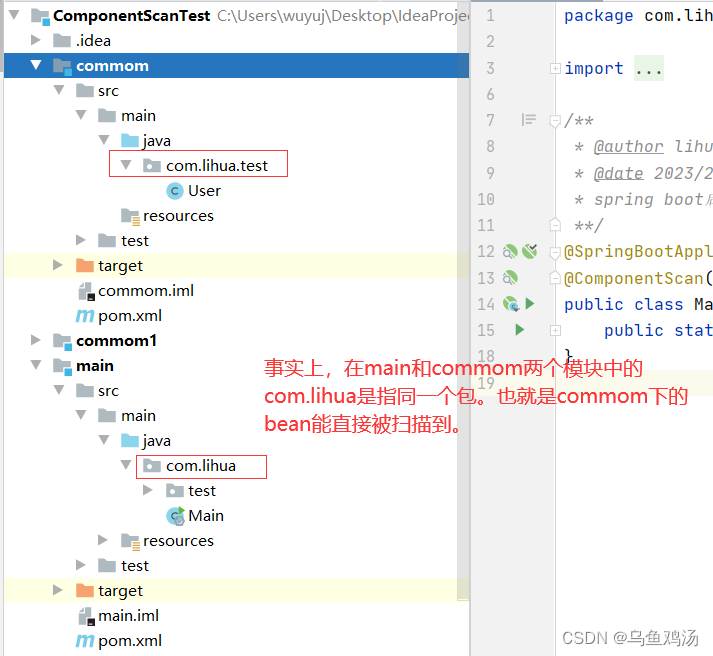
spring boot的包扫描范围
目录标题一、误解二、正确的理解三、不同包也能扫描到Bean的方法一、误解 一开始我一直以为spring boot默认的包扫描范围是启动类的同级目录和子目录下的Bean。其实正真是与启动类在同个包以及子包下的Bean。 我一直误解了包的概念,包并不是只文件夹(文…...

常青科技冲刺A股上市:研发费用率较低,关联方曾拆出资金达1亿元
近日,江苏常青树新材料科技股份有限公司(下称“常青科技”或“常青树科技”)递交招股书,准备在上海证券交易所主板上市。本次冲刺上市,常青科技计划募资8.50亿元,光大证券为其保荐机构。 据招股书介绍&…...
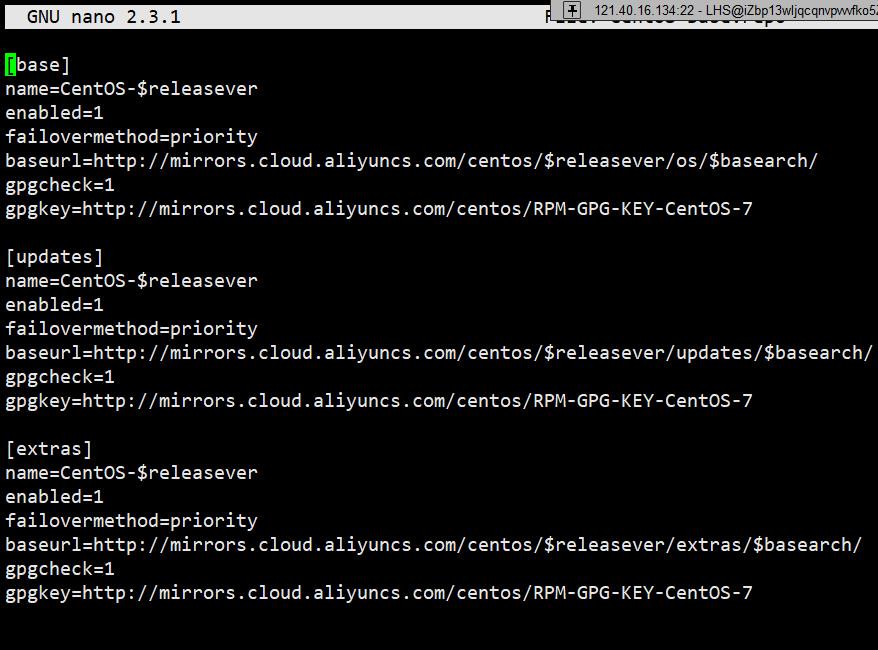
【Linux】工具(1)——yum
好久不见,让大家久等啦~最近开学被一系列琐事所耽误了,接下来会进入稳定更新状态~话不多说,在我们了解Linux基本内容之后,我们的目的是要在Linux环境下进行软硬件开发,在这个过程中我们会用到一系列工具,例…...

MySQL - 排序与分页
目录1. 排序1.2 排序规则1.2 单列排序1.3 多列排序2. 分页2.1 实现规则1. 排序 1.2 排序规则 使用 ORDER BY 子句排序 ASC(ascend):升序DESC(descend):降序 ORDER BY 子句在SELECT语句的结尾。 1.2 单列…...

自动化测试框架对比
Robot Framework(RF) 链接:http://robotframework.org/ Robot Framework(RF)是用于验收测试和验收测试驱动开发(ATDD)的自动化测试框架。 基于 Python 编写,但也可以在 Jython&…...

第7章 Memcached replace 命令教程
Memcached replace 命令教程用于替换已存在的 key(键) 的 value(数据值)。 如果 key 不存在,则替换失败,并且将获得响应 NOT_STORED。 语法: replace 命令的基本语法格式如下: replace key flags exptime bytes [noreply]value…...
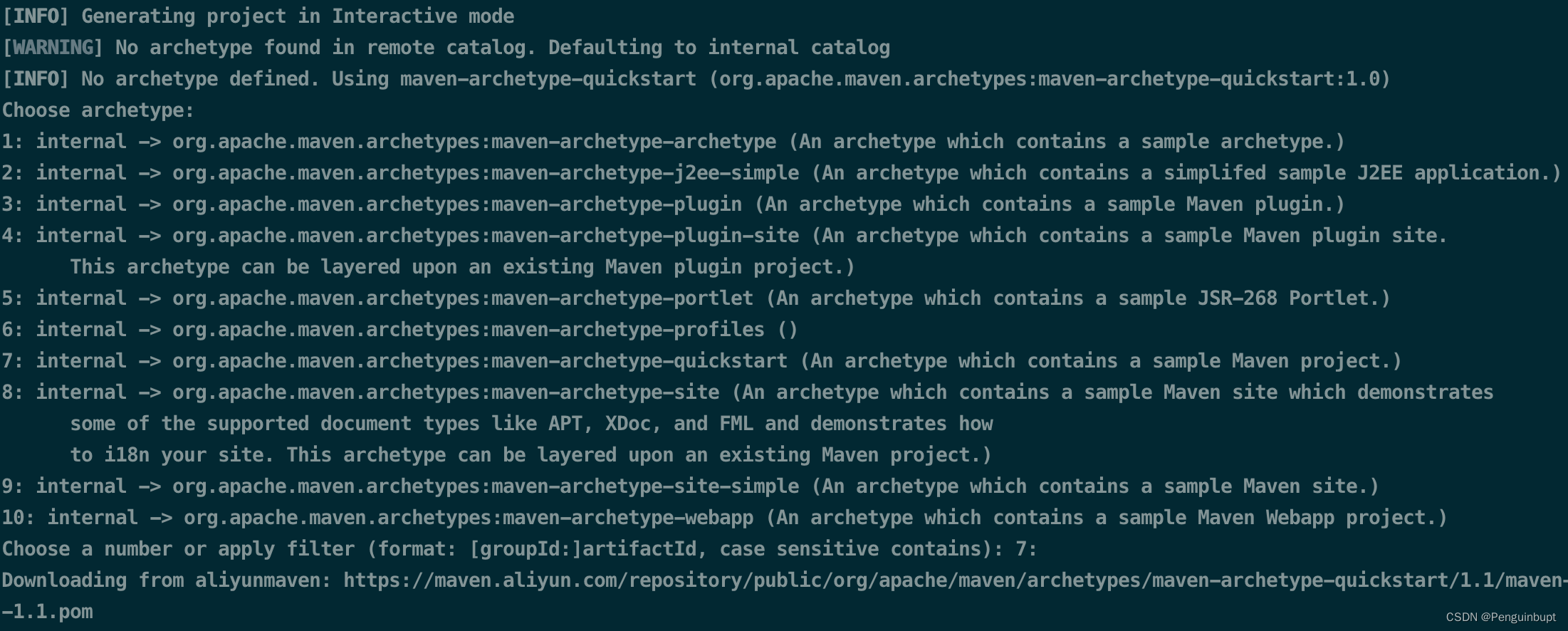
我记不住的那些maven内容
背景: 之前使用maven都是基于IDE并且对maven本身也很少究其过程和原理,当出现问题也不知道如何解决,后续想使用命令行来进行操作,并通过文档记录一下学习的内容加深理解以防止忘记。 一、简要介绍 maven是通过插件来增强功能&am…...
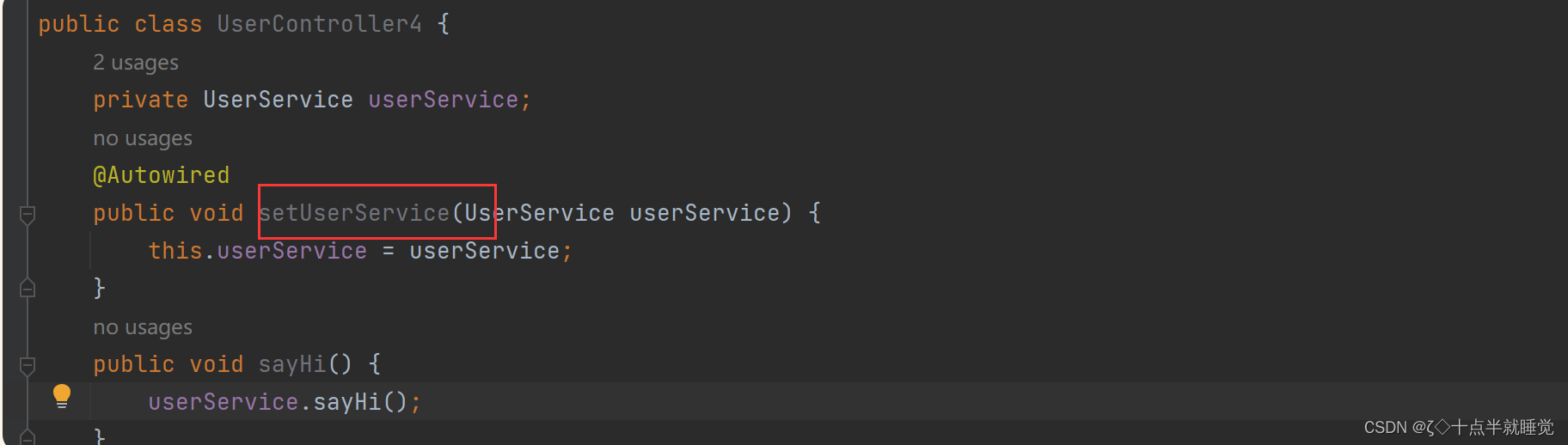
【Java】Spring更简单的读取和存储
文章目录Spring更简单的读取和存储对象1. 存储Bean对象1.1 前置工作:配置扫描路径1.2 添加注解存储Bean对象1.2.1 Controller(控制器存储)1.2.2 Service(服务存储)1.2.3 Repository(仓库存储)1.2.4 Component(组件存储)1.2.5 Configuration1.3 为什么要这么多类注解…...

Kafka 命令行操作
主题命令行操作 1)查看操作主题命令参数 [ubuntuhadoop kafka]$ bin/kafka-topics.sh 参数描述--bootstrap-server连接的KafkaBroker主机名称和端口号。--topic操作的topic名称。--create创建主题。--delete删除主题。--alter修改主题。--list查看所有主题。--desc…...

KUKA机器人_基础编程中的变量和协定
KUKA机器人_基础编程中的变量和协定 KUKA机器人KRL中的数据保存: 每个变量都在计算机的存储器中有一个专门指定的地址 一个变量用非KUKA关键词的名称来表示 每个变量都属于一个专门的数据类型 在应用前必须声明变量的数据类型 在KRL中有局部变量和全局变量之分…...
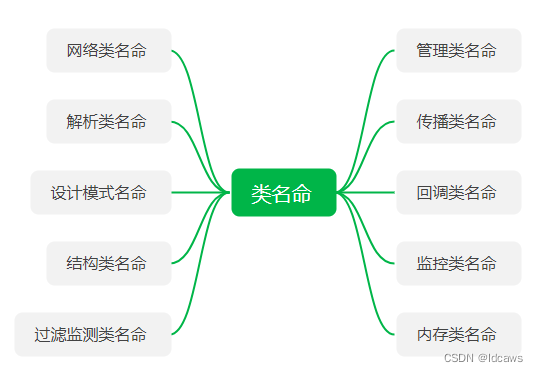
代码名命规范浅析
日常开发编码中,代码的名命是个大学问,能快速的看懂开源代码的结构和意图,也是一项必备的能力。在java项目的代码结构中,采用长名命的方式来规范类的名命,能够自己表达其主要意图,配合高级IDE,可…...
)
数据结构第15周 :( 求第k大的数 + 查找3个数组的最小共同元素 + 查找一个循环顺序数组的最小元素 + Crazy Search)
目录求第k大的数查找3个数组的最小共同元素查找一个循环顺序数组的最小元素Crazy Search求第k大的数 【问题描述】 求n个数中第k大的数 【输入形式】 第一行n k,第二行为n个数,都以空格分开 【输出形式】 第k大的数 【样例输入】 10 3 18 21 11 26 12 2…...
【数据结构】Map 和 Set
目录二叉搜索树二叉搜索树---查找二叉搜索树---插入二叉搜索树---删除Map和SetMap的使用Set的使用哈希表哈希冲突冲突避免冲突解决冲突解决---闭散列冲突解决---开散列题目练习只出现一次的数复制带随机指针的链表宝石与石头旧键盘二叉搜索树 二叉搜索树也叫二叉排序树&#x…...
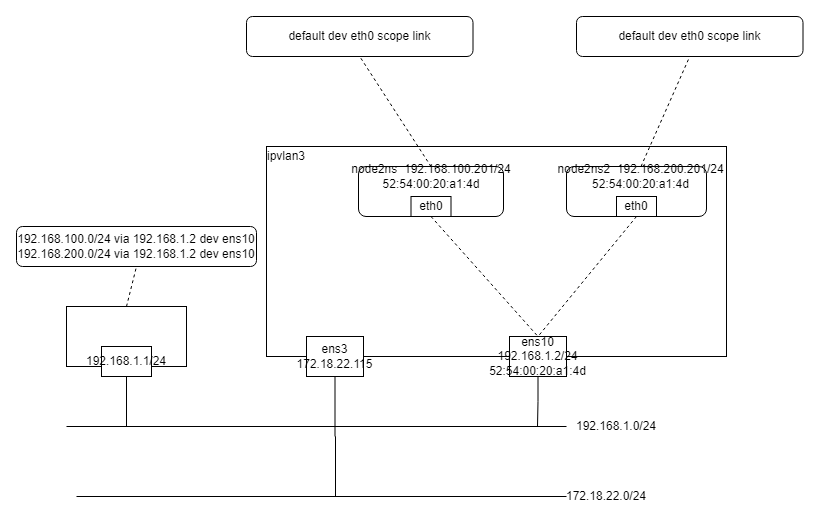
IPVlan 详解
文章目录简介Ipvlan2同节点 Ns 互通Ns 内与宿主机 通信第三种方法Ns 到节点外部结论Ipvlan31. 同节点 Ns 互通Ns 内与宿主机 通信Ns 内到外部网络总结源码分析ipvlan 收包流程收包流程主要探讨使用 ipvlan 为 cni 通过虚拟网卡的实现。简介 ipvlan 和 macvlan 类似,…...

直播间的2个小感悟
我是卢松松,点点上面的头像,欢迎关注我哦! 在线人数固定 最近直播间出现了很多新面孔,有的是偶然刷到的,有的是关注互联网找到的。而直播间的人数一直没什么变化,卢松松在抖音直播较少,主播间…...

STM32开发(15)----芯片内部温度传感器
芯片内部温度传感器前言一、什么是内部温度传感器?二、实验过程1.STM32CubeMX配置2.代码实现3.实验结果总结前言 本章介绍STM32芯片温度传感器的使用方法和获取方法。 一、什么是内部温度传感器? STM32 有一个内部的温度传感器,可以用来测…...
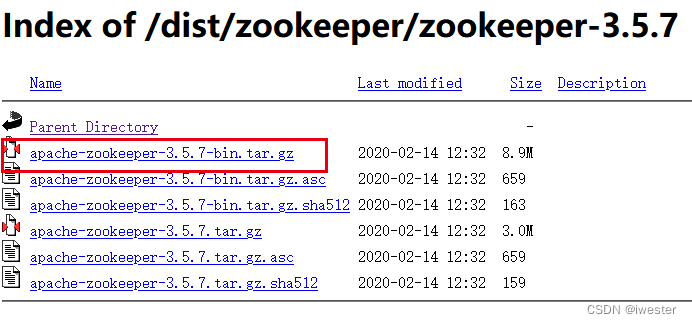
Apache Hadoop生态部署-zookeeper分布式安装
目录 查看服务架构图-服务分布、版本信息 一:安装前准备 1:zookeeper安装包选择--官网下载 2:zookeeper3.5.7安装包--百度网盘 二:安装与常用配置 2.1:下载解压zk安装包 2.2:配置环境变量 2.3&#x…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

Rydberg原子量子门实现原理与优化技术
1. Rydberg原子平台中的量子门实现基础1.1 Rydberg原子特性与量子计算优势Rydberg原子是指外层电子被激发到高主量子数能级的原子态,这类原子具有三个关键特性使其成为量子计算的理想平台:强偶极-偶极相互作用:当两个原子同时处于Rydberg态时…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...