云计算与大数据——部署Hadoop集群并运行MapReduce集群(超级详细!)
云计算与大数据——部署Hadoop集群并运行MapReduce集群(超级详细!)
Linux搭建Hadoop集群(CentOS7+hadoop3.2.0+JDK1.8+Mapreduce完全分布式集群)
本文章所用到的版本号: CentOS7 Hadoop3.2.0 JDK1.8
基本概念及重要性
很多小伙伴部署集群用hadoop用mapreduce,却不知道到底部署了什么,有什么用。在部署集群之前先给大家讲一下Hadoop和MapReduce的基本概念,以及它们在大数据处理中的重要性:
-Hadoop 是一个由Apache基金会开发的开源软件框架,用于在大规模数据集上进行分布式处理和存储。Hadoop的核心组件包括Hadoop Distributed File System (HDFS)和MapReduce。
-
HDFS 是一个分布式文件系统,可以在普通的硬件上存储大量的数据。HDFS将数据分割成多个块,然后在集群中的多个节点上进行分布式存储,从而提供了高容错性和高吞吐量。
-
MapReduce 是一种编程模型,用于处理和生成大数据集。MapReduce任务包括两个阶段:Map阶段和Reduce阶段。在Map阶段,输入数据被分割成多个独立的块,然后并行处理。在Reduce阶段,处理结果被合并成一个最终的输出。
Hadoop和MapReduce在大数据处理中的重要性主要体现在以下几点:
-
可扩展性:Hadoop可以在数百或数千台机器上运行,处理PB级别的数据。
-
容错性:Hadoop可以自动处理节点故障,保证数据的可靠性和完整性。
-
成本效益:Hadoop可以在普通的硬件上运行,降低了大数据处理的成本。
-
灵活性:MapReduce编程模型可以处理结构化和非结构化的数据,适应各种类型的数据处理任务。
下面正式进入正题话!
一、直接选择root用户登录并关闭防火墙
直接选择root用户登录,避免了普通用户授权和切换用户导致的一些环境问题,简单来说就是高效、方便。
然后关闭防火墙:
systemctl stop firewalld //关闭防火墙
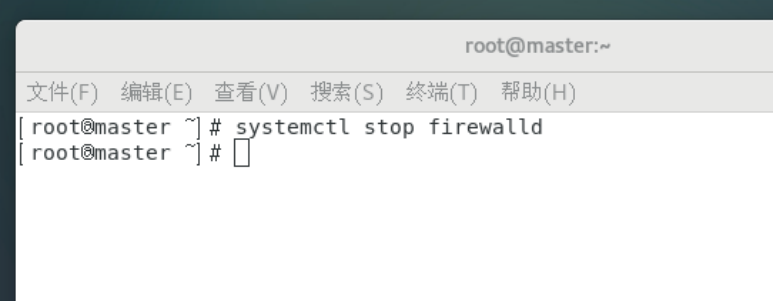
systemctl disable firewalld //关闭开机自启
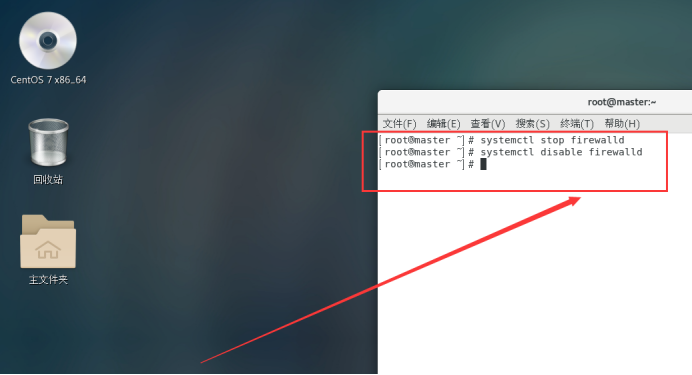
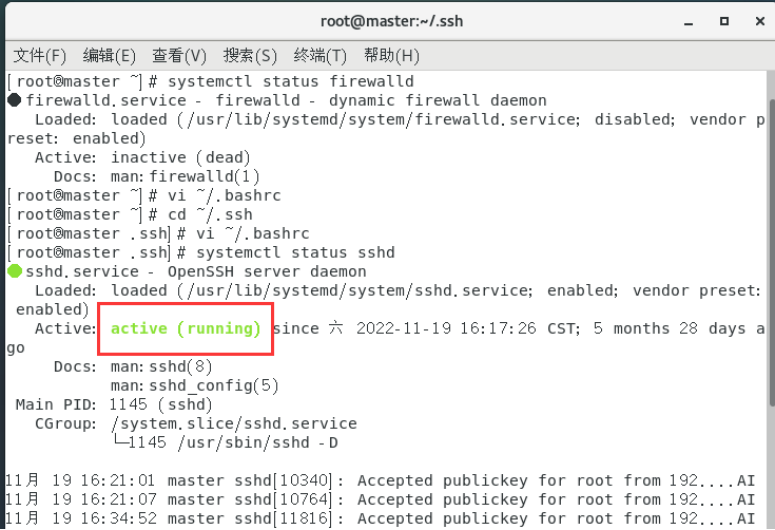
systemctl status firewalld //查看防火墙状态
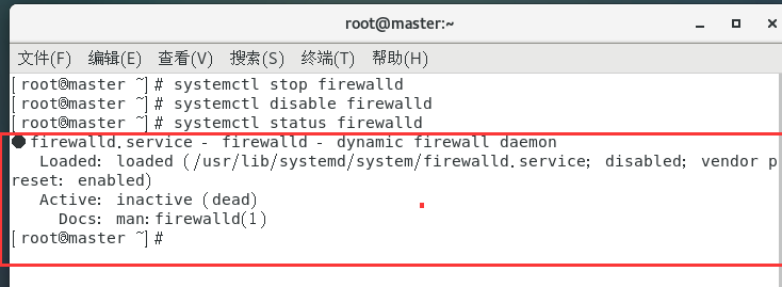
让防火墙处于关闭状态。
二、实现ssh免密码登录
配置ssh的无密码访问
ssh-keygen -t rsa
连续按回车
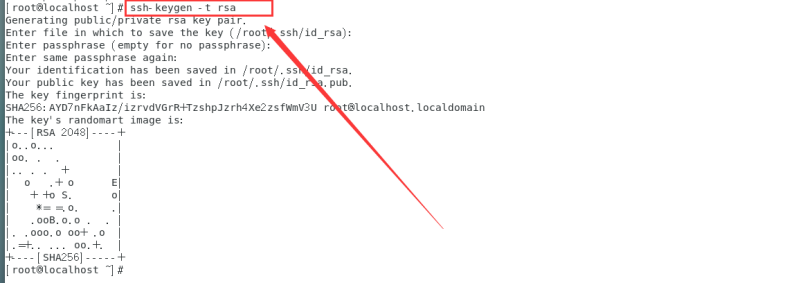
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
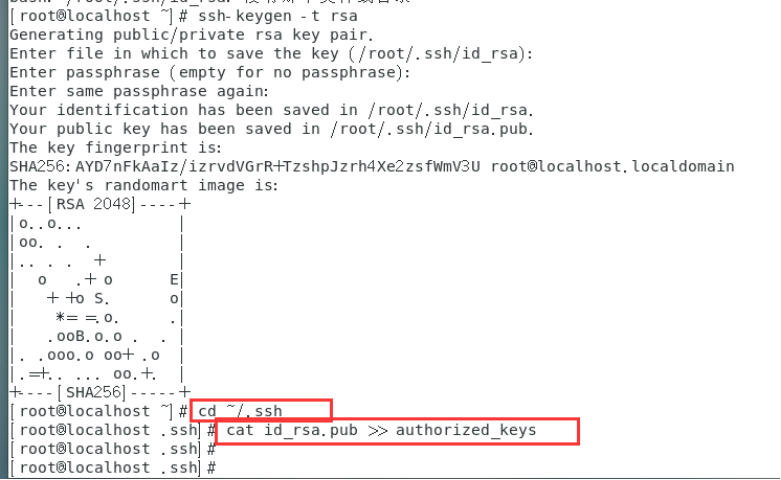
设置ssh服务器自动启动
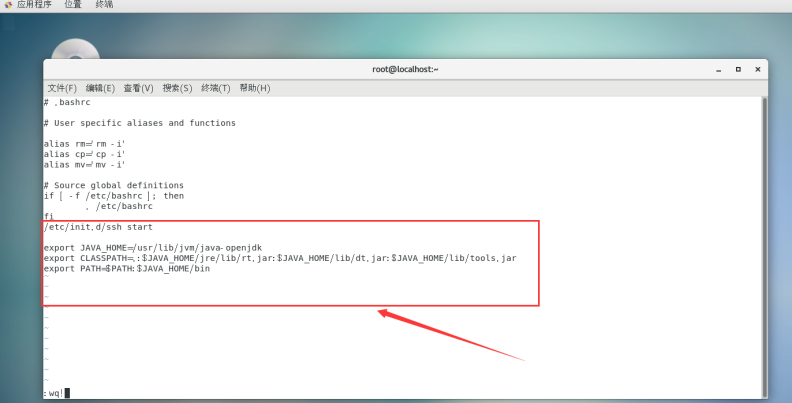
vi ~/.bashrc
在文件的最末尾按O进入编辑模式,加上:
/etc/init.d/ssh start
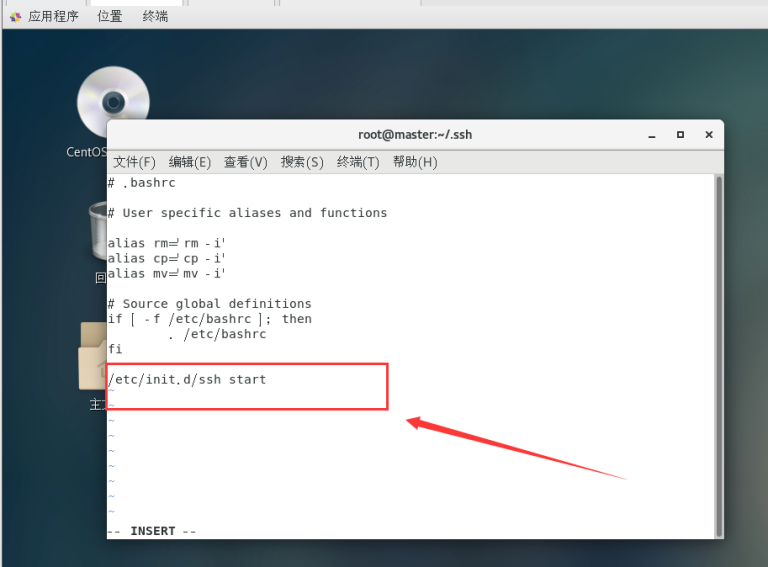
按ESC返回命令模式,输入:wq保存并退出。
让修改即刻生效
source ~/.bashrc

查看ssh服务状态。
systemctl status sshd
三、CentOS7 安装jdk1.8
1、yum安装
- 安装之前先查看一下有无系统自带jdk,有的话先卸载。
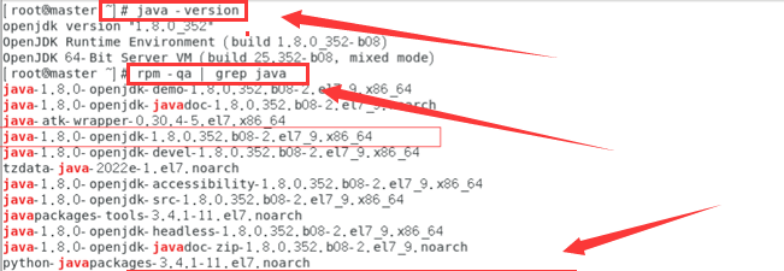
卸载自带的jdk:
rpm -e --nodeps上步查询出的所有jdk
例如:
[root@master ~]# rpm -e --nodeps copy-jdk-configs-3.3-10.el7_5.noarch
验证是否已经卸载干净:
java -version

卸载完之后开始安装jdk1.8:
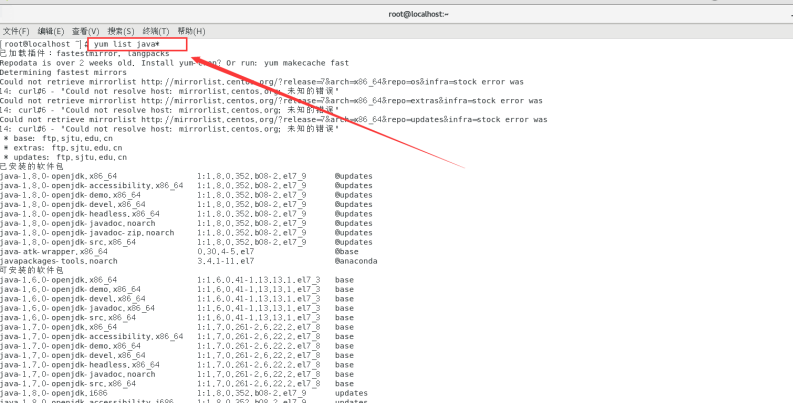
查看可安装的版本
yum list java*
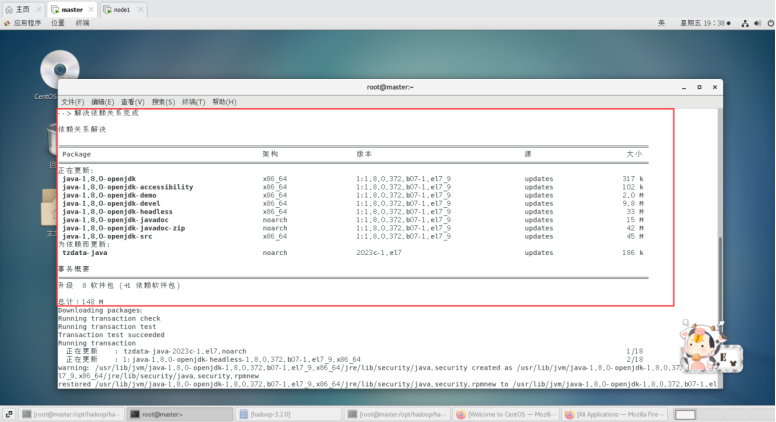
安装1.8.0版本openjdk
yum -y install java-1.8.0-openjdk*

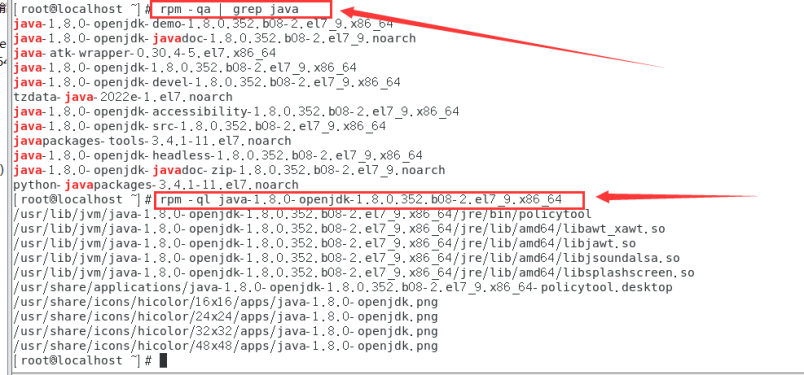
安装位置查看:
rpm -qa | grep java
rpm -ql java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64
添加用户环境变量
添加:
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后执行
source ~/.bashrc
验证安装:
which java
查看java版本信息
java -version
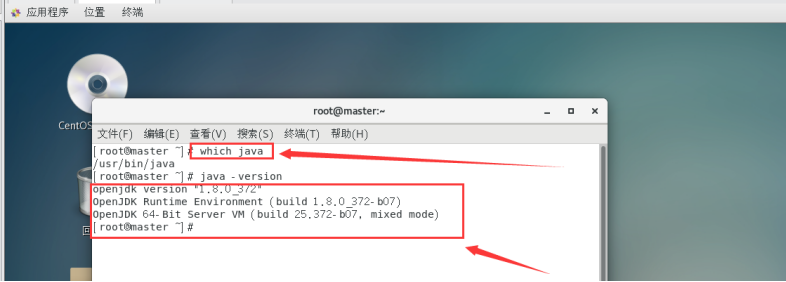
说明JDK配置完成。
四、下载hadoop
这个链接也有更多3.2.0版本其它的hadoop文件:
https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/
这里有下载好的hadoop-3.2.0.tar.gz网盘文件链接:
链接:https://pan.baidu.com/s/1a3GJH_fNhUkfaDbckrD8Gg?pwd=2023
下载hadoop文件:
然后上传文件并解压缩
1.在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop-3.2.0.tar上传到该目录下
mkdir /opt/hadoop
解压安装:
tar -zxvf hadoop-3.2.0.tar.gz
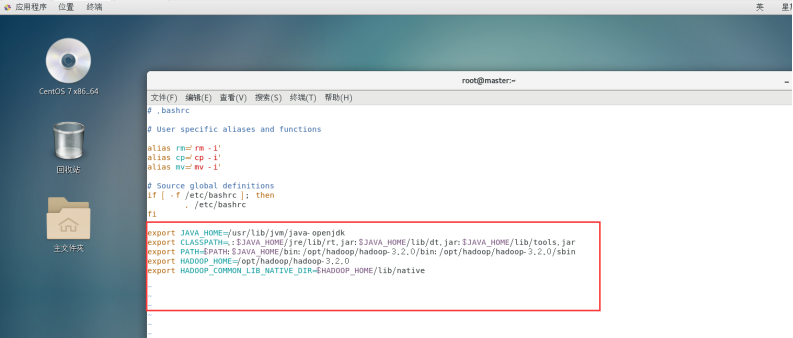
配置Hadoop环境变量:
vim ~/.bashrc

添加hadoop环境变量:
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:/opt/hadoop/hadoop-3.2.0/bin:/opt/hadoop/hadoop-3.2.0/sbin
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.0
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
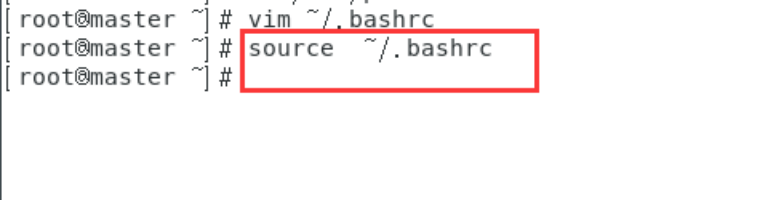
然后我们执行
source ~/.bashrc
使修改的配置文件生效。
五、Hadoop配置文件修改
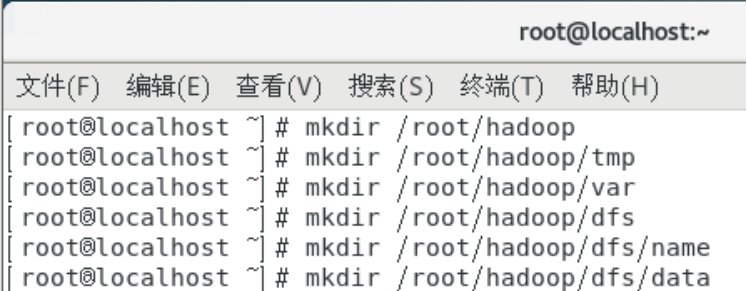
新建几个目录:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
修改etc/hadoop中的一系列配置文件
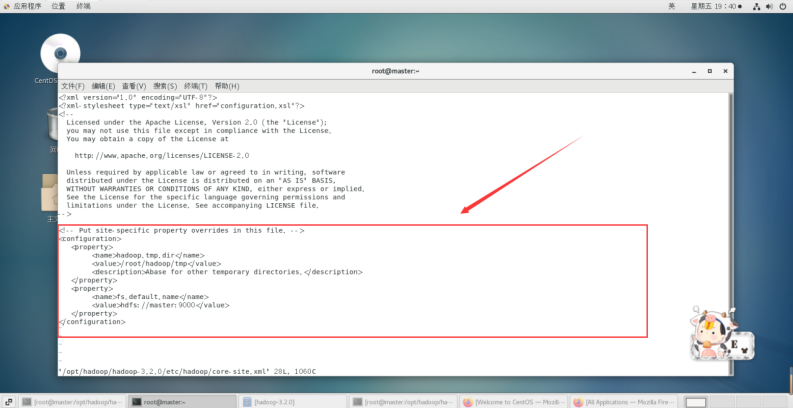
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/core-site.xml
在节点内加入配置:
<configuration><property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.default.name</name><value>hdfs://master:9000</value></property></configuration>
修改hadoop-env.sh
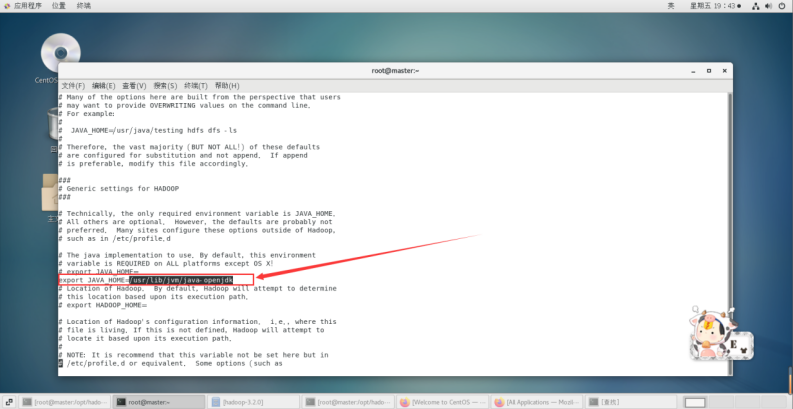
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
将 export JAVA_HOME=${JAVA_HOME}
修改为: export JAVA_HOME=/usr/lib/jvm/java-openjdk
说明:修改为自己的JDK路径
修改hdfs-site.xml
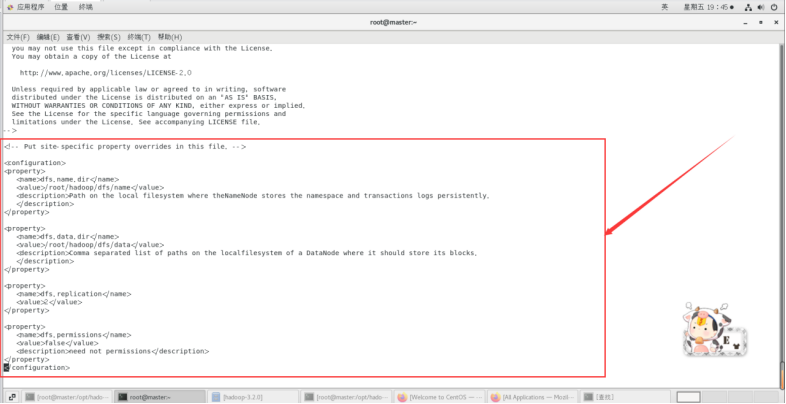
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
在节点内加入配置:
<configuration>
<property><name>dfs.name.dir</name><value>/root/hadoop/dfs/name</value><description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property><property><name>dfs.data.dir</name><value>/root/hadoop/dfs/data</value><description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property><property><name>dfs.replication</name><value>2</value>
</property><property><name>dfs.permissions</name><value>false</value><description>need not permissions</description>
</property>
</configuration>
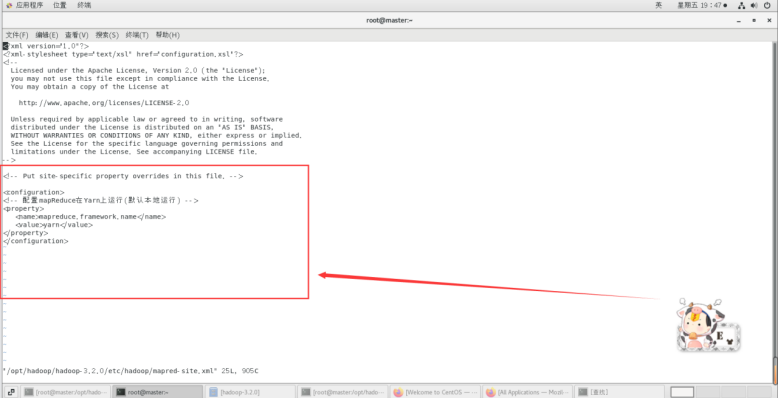
新建并且修改mapred-site.xml:
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/mapred-site.xml
在节点内加入配置:
<configuration>
<!-- 配置mapReduce在Yarn上运行(默认本地运行) -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>
修改workers文件:
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/workers
将里面的localhost删除,添加以下内容(master和node1节点都要修改):
master
node1

修改yarn-site.xml文件:
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/yarn-site.xml
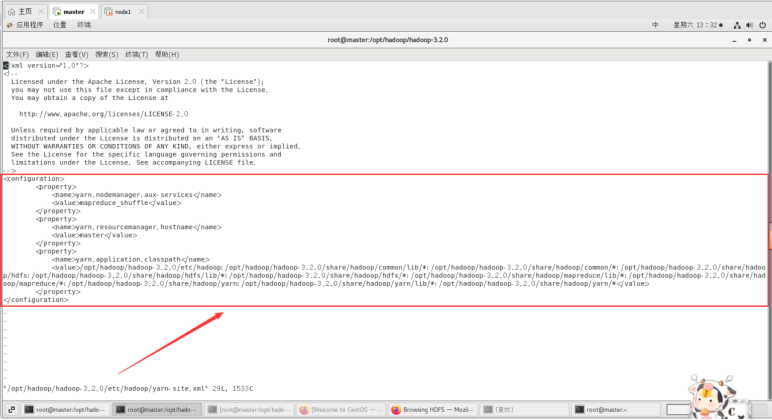
配置hadoop-3.2.0/sbin/目录下start-dfs.sh、start-yarn.sh、stop-dfs.sh、stop-yarn.sh文件
服务启动权限配置
cd /opt/hadoop/hadoop-3.2.0
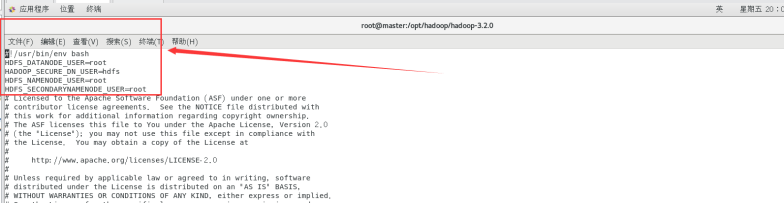
配置start-dfs.sh与stop-dfs.sh文件
vi sbin/start-dfs.sh
vi sbin/stop-dfs.sh
加入下面内容
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
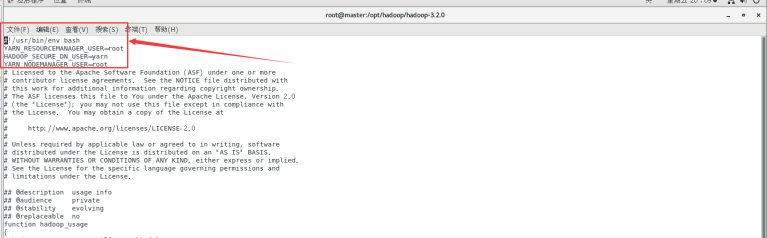
配置start-yarn.sh与stop-yarn.sh文件
vi sbin/start-yarn.sh
vi sbin/stop-yarn.sh
加入下面内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

配置好基础设置(SSH、JDK、Hadooop、环境变量、Hadoop和MapReduce配置信息)后,克隆虚拟机,获得从机node1节点。

克隆master主机后,获得从机node1节点。
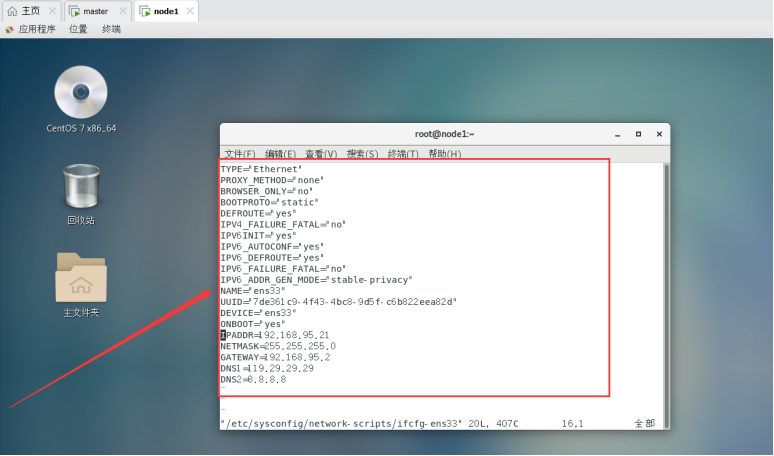
然后开始修改网卡信息:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改node1节点ip信息:
修改node1节点主机名:
vi /etc/hostname
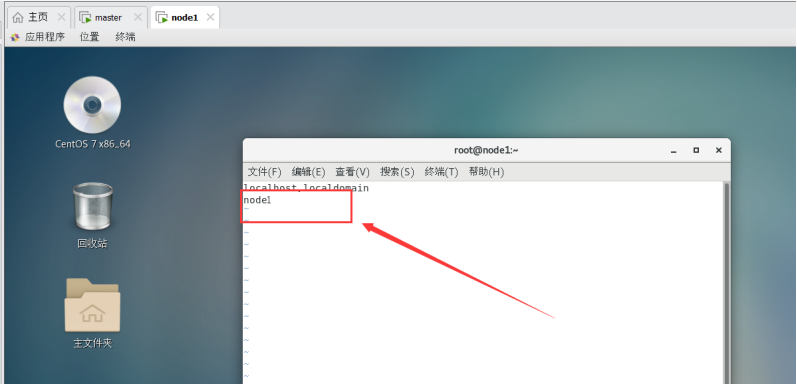
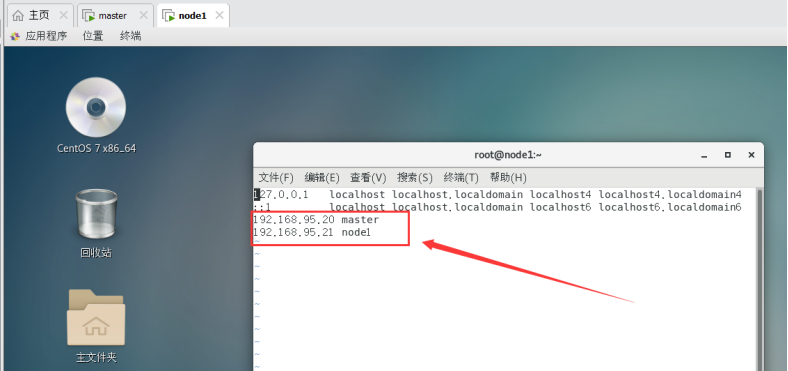
修改node1节点对应的ip 和主机名(主从节点保持一致)
vim /etc/hosts
主从节点互连ssh试试:
先试试在master节点连接node1节点
ssh node1

再试试node1节点连接master节点:
ssh master
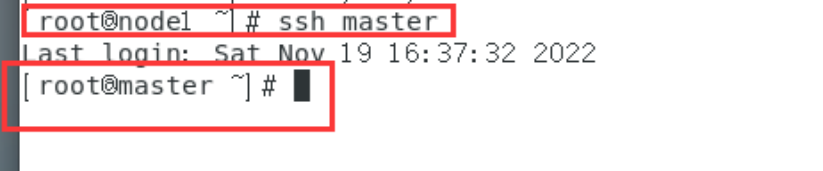
OK,互连成功。(按exit可以退出
六、启动Hadoop
因为master是namenode,node1是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化。
进入到master这台机器/opt/hadoop/hadoop-3.2.0/bin目录:
cd /opt/hadoop/hadoop-3.2.0/bin
执行初始化脚本
./hadoop namenode -format
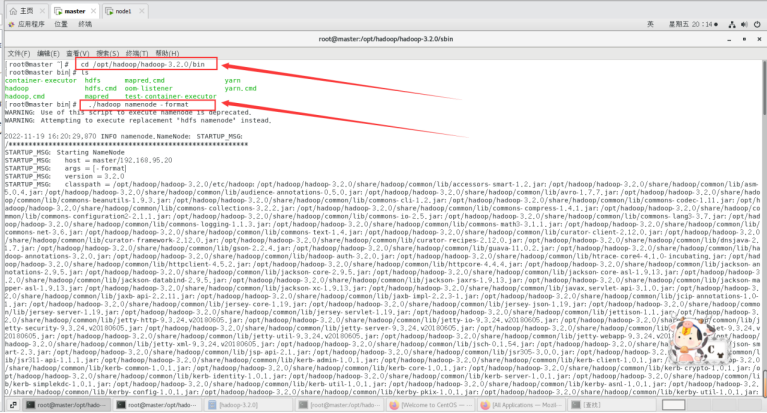
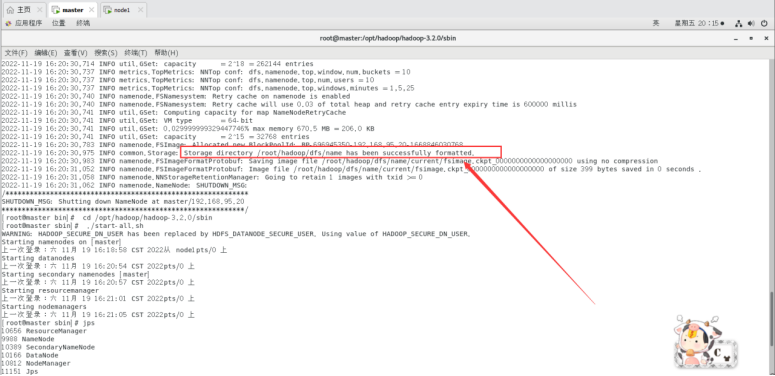
然后执行启动进程:
./sbin/start-all.sh
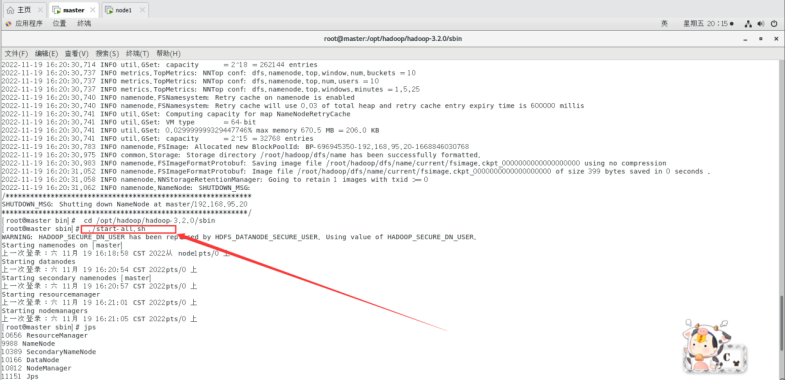
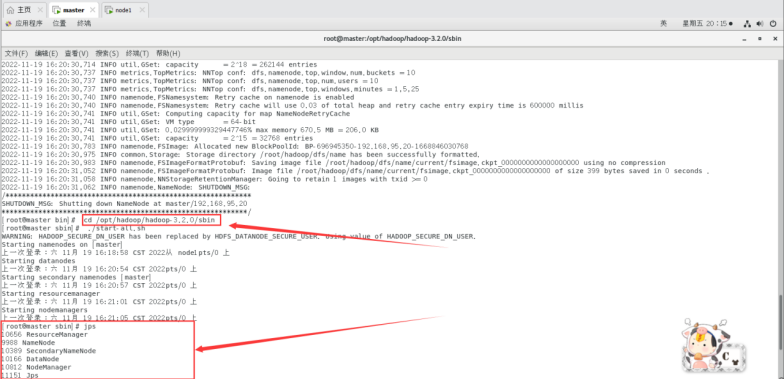
查看启动进程情况。
jps
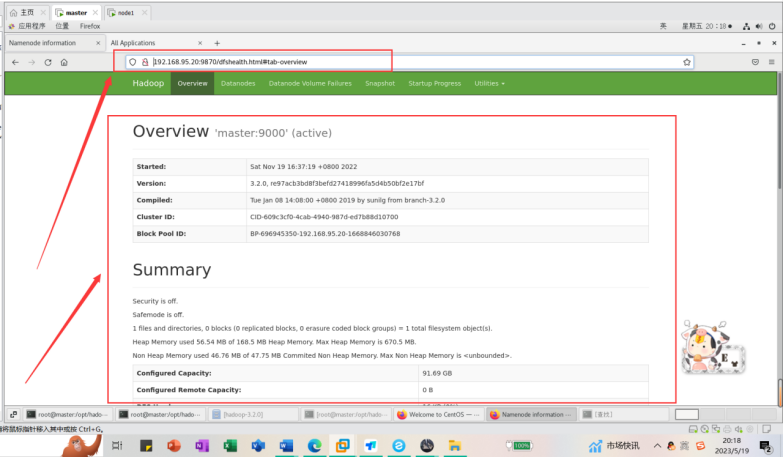
master是我们的namenode,该机器的IP是192.168.95.20,在本地电脑访问如下地址:
http://192.168.95.20:9870/
在本地浏览器里访问如下地址:
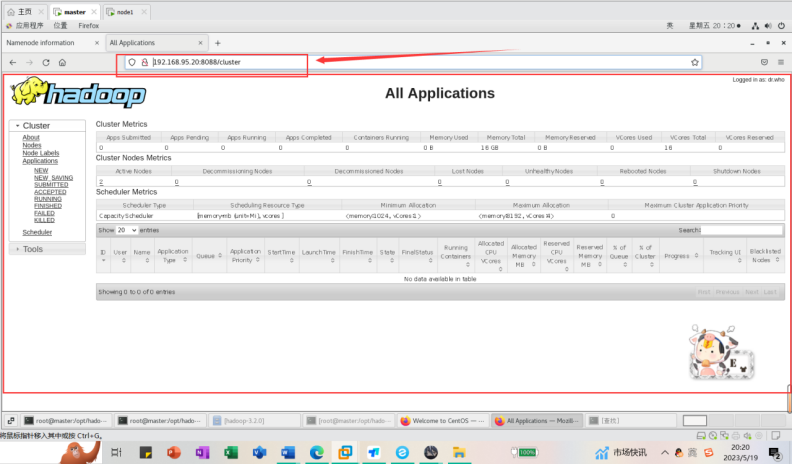
http://192.168.95.20:8088/cluster
自动跳转到cluster页面
在hdfs上建立一个目录存放文件
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input
查看分发复制是否正常
./bin/hdfs dfs -ls /home/hadoop/myx/wordcount/input

七、运行MapReduce集群
Mapreduce运行案例:
在hdfs上建立一个目录存放文件
例如
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input
可以先简单地写两个小文件分别为text1和text2,如下所示。
file:text1.txt
hadoop is very good
mapreduce is very good
vim text1

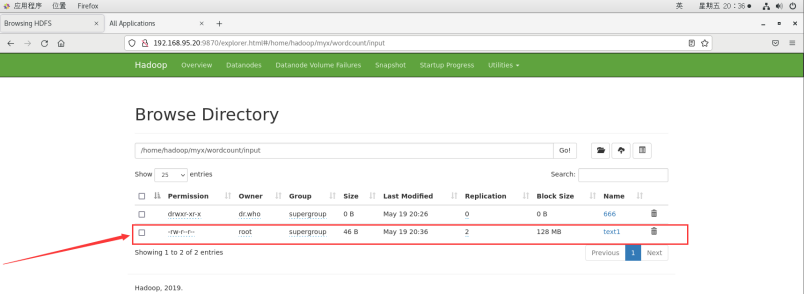
然后可以把这两个文件存入HDFS并用WordCount进行处理.
./bin/hdfs dfs -put text1 /home/hadoop/myx/wordcount/input

查看分发情况
运行MapReduce用WordCount进行处理
./bin/hadoop jar 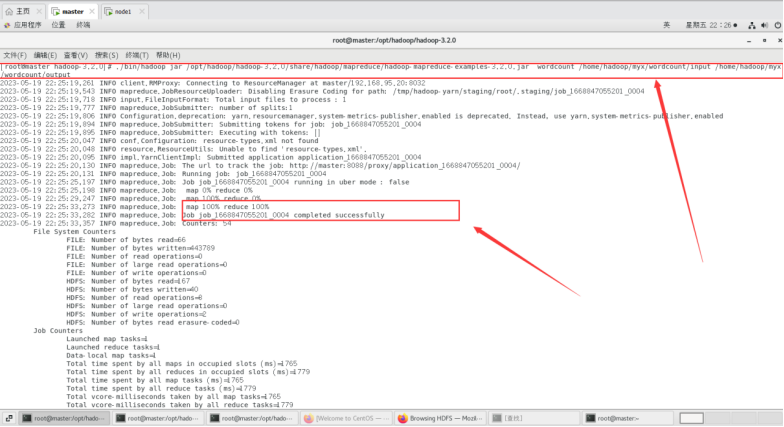
/opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /home/hadoop/myx/wordcount/input /home/hadoop/myx/wordcount/output
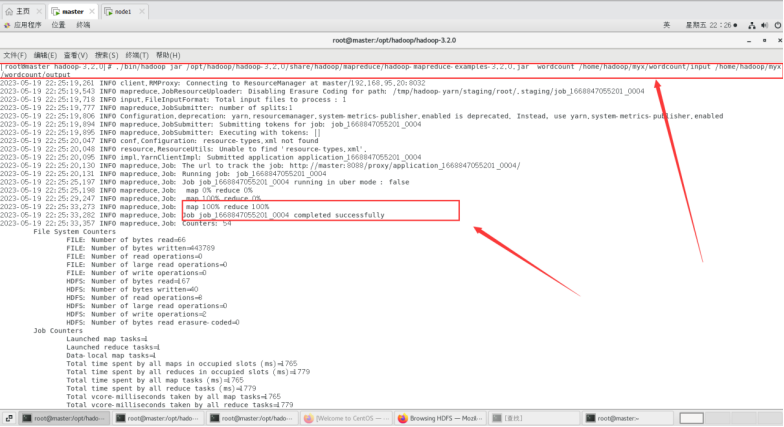
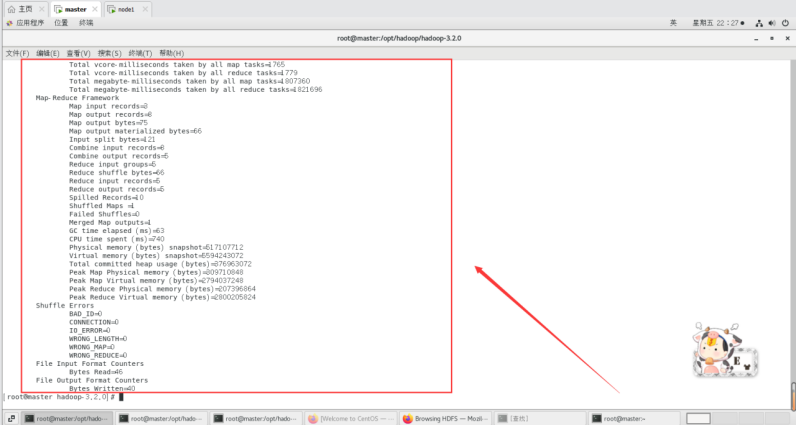
最终结果会存储在指定的输出目录中,查看输出目录里面可以看到以下内容。
./bin/hdfs dfs -cat /home/hadoop/myx/wordcount/output/part-r-00000*
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/home/hadoop/myx/wordcount/output
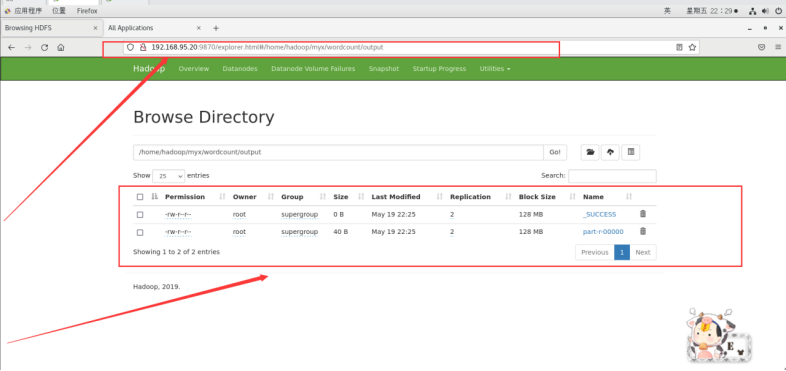
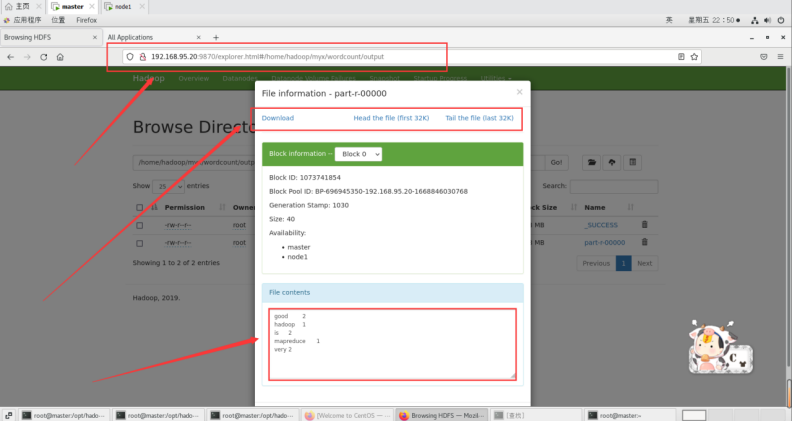
以上输出结果为每个单词出现的次数。
再来试试第二个案例:
file:text2.txt
vim text2
hadoop is easy to learn
mapreduce is easy to learn

在浏览器端查看新建的input2目录:
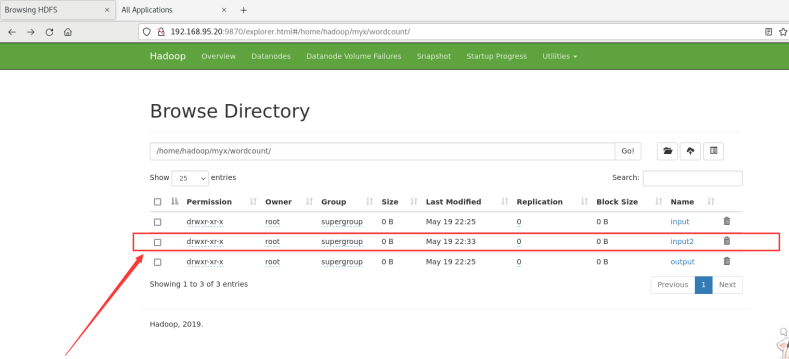
运行MapReduce进行处理,设置输出的目录为output2(输出结果目录不用提前创建,Mapreduce运行过程中会自动生成output2输出目录)。
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /home/hadoop/myx/wordcount/input2 /home/hadoop/myx/wordcount/output2
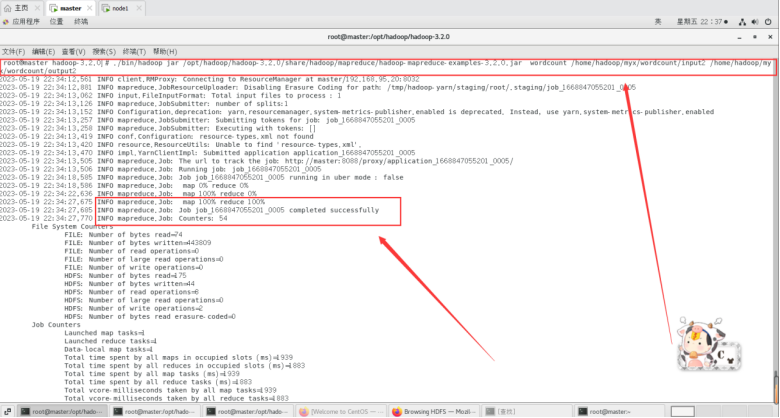
运行结束后,查看text2的输出结果
./bin/hdfs dfs -cat /home/hadoop/myx/wordcount/output2/part-r-00000*

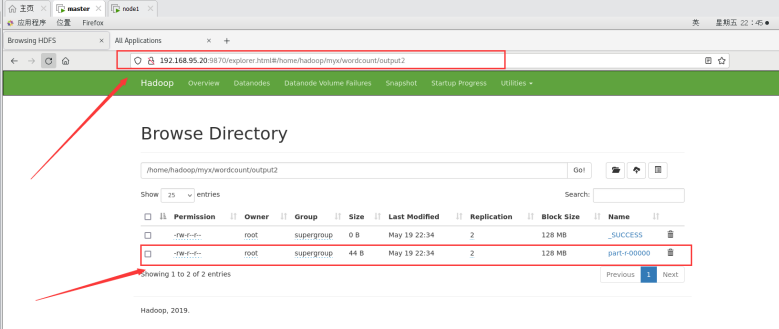
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/home/hadoop/myx/wordcount/output2
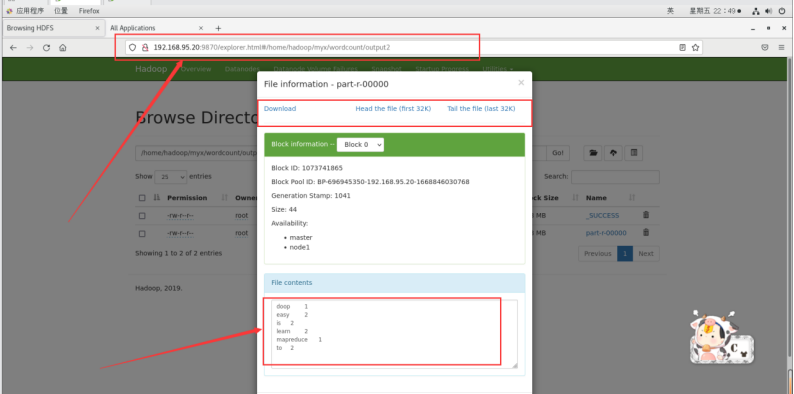
以上输出结果为每个单词出现的次数。
我们再自己试试运行测试程序WordCount
先在hadoop当前用户目录下新建文件夹WordCount,在其中建立两个测试文件分别为file1.txt,file2.txt。自行在两个文件中填写内容。
新建文件夹WordCount。
mkdir WordCount
ls

cd WordCount
vim file1.txt

file1.txt文件内容为:
This is the first hadoop test program!

vim file2.txt
file2.txt文件内容为:
This program is not very difficult,but this program is a common hadoop program!

然后在Hadoop文件系统HDFS中/home目录下新建文件夹input,并查看其中的内容。具体命令如下。
cd /opt/hadoop/hadoop-3.2.0
./bin/hadoop fs -mkdir /input
./bin/hadoop fs -ls /

在浏览器端查看:
http://192.168.95.20:9870/explorer.html#/input
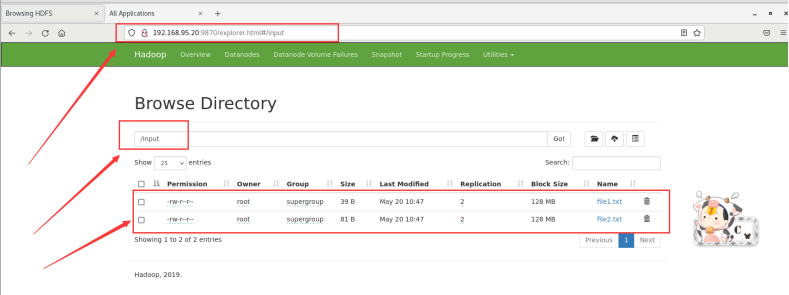
将WordCount文件夹中file1.txt\file2.txt文件上传到刚刚创建的“input”文件夹。具体命令如下。
./bin/hadoop fs -put /opt/hadoop/hadoop-3.2.0/WordCount/*.txt /input

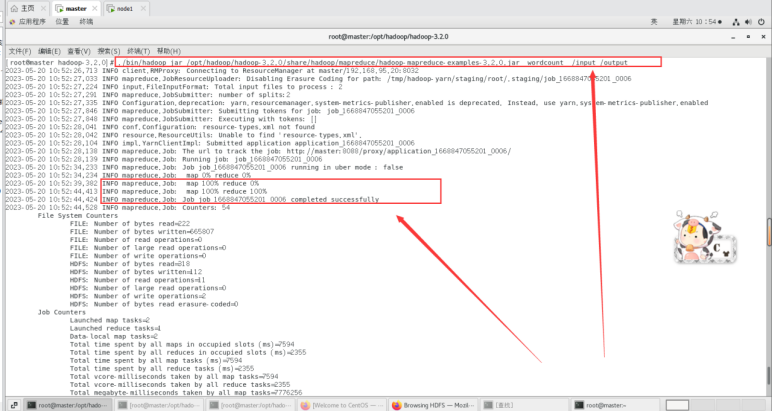
运行Hadoop的示例程序,设置输出的目录为/output(输出结果目录不用提前创建,Mapreduce运行过程中会自动生成/output输出目录)。
./bin/hadoop jar /opt/had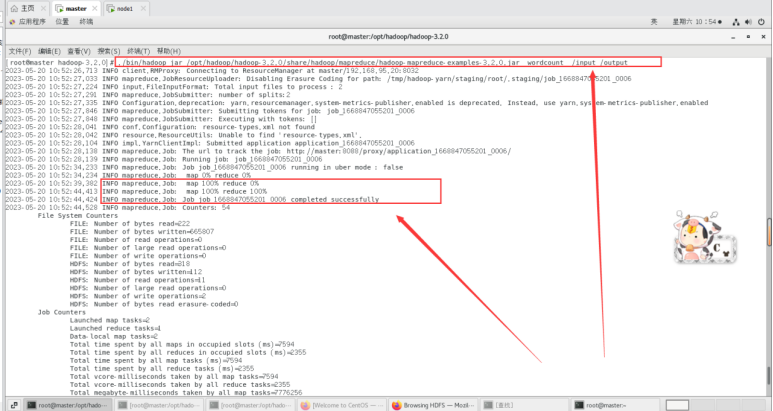
oop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output
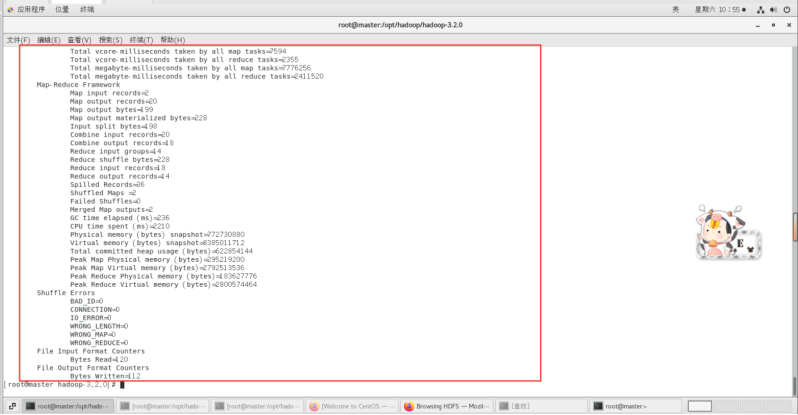
查看输出结果的文件目录信息和WordCount结果。
使用如下命令查看输出结果的文件目录信息。
./bin/hadoop fs -ls /output

使用如下命令查看WordCount的结果。
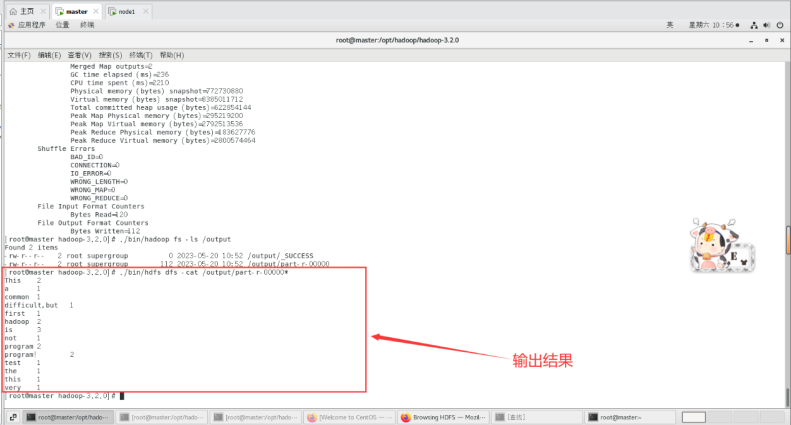
./bin/hdfs dfs -cat /output/part-r-00000*
输出结果如下所示
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/output
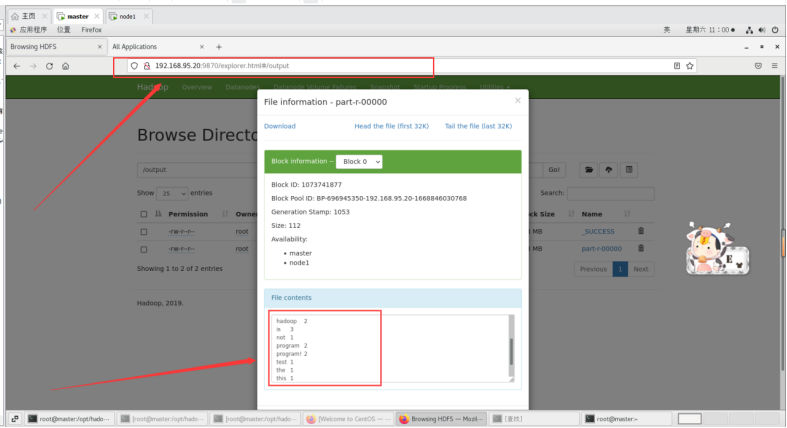
以上输出结果为每个单词出现的次数。
至此Centos搭建hadoop集群和运行3个MapReduce集群案例完成!
在这里给大家扩展一下优化Hadoop集群性能和MapReduce任务效率的一些技巧和建议:
-
硬件优化:选择适合的硬件配置是提高Hadoop集群性能的关键。例如,使用更快的CPU,更大的内存,更快的硬盘(如SSD),以及高速的网络连接。
-
配置优化:Hadoop和MapReduce的配置参数可以根据具体的工作负载进行调整。例如,可以增加HDFS的块大小以提高大文件的处理速度,或者调整MapReduce的内存设置以适应更大的任务。
-
数据本地化:尽可能在数据所在的节点上运行MapReduce任务,以减少网络传输的开销。
-
并行处理:通过增加MapReduce任务的并行度,可以更充分地利用集群的资源。
-
编程优化:在编写MapReduce程序时,应尽可能减少数据的传输和排序。例如,可以使用Combiner函数来减少Map和Reduce阶段之间的数据传输。
-
使用高级工具:一些高级的数据处理工具,如Apache Hive和Apache Pig,可以自动优化MapReduce任务,使其更高效。
-
监控和调试:使用Hadoop自带的监控工具,如Hadoop Web UI和Hadoop Metrics,可以帮助你发现和解决性能问题。
以上只是一些基本的优化技巧和建议,具体的优化策略需要根据具体需求和环境进行调整。小马同学在这里祝各位部署一切顺利!
相关文章:
云计算与大数据——部署Hadoop集群并运行MapReduce集群(超级详细!)
云计算与大数据——部署Hadoop集群并运行MapReduce集群(超级详细!) Linux搭建Hadoop集群(CentOS7hadoop3.2.0JDK1.8Mapreduce完全分布式集群) 本文章所用到的版本号: CentOS7 Hadoop3.2.0 JDK1.8 基本概念及重要性 很多小伙伴部署集群用hadoop用mapr…...
基于jenkins+k8s实现devops
1、背景 由于jenkins运行在k8s上能够更好的利用动态agent进行构建。所以写了个部署教程,亲测无坑 2、部署 1、创建ns kubectl create namespace devops 2、kubectl apply -f jenkins.yml apiVersion: v1 kind: ServiceAccount metadata:name: jenkinsnamespace…...
一文了解企业如何实现文件自动化实时同步
在当今的数字化时代,数据是企业的核心资产,也是企业竞争力的重要体现。数据的传输、共享、协作、备份等都需要依赖文件同步技术,实现数据在不同平台和设备之间的一致性和可用性。文件同步是指将一个或多个文件夹中的内容复制或更新到另一个或…...

低代码系统哪里好
低代码作为近些年来被热议的话题,一直备受争议。低代码的出现更多的是用来辅助那些没有太多技能的人士而使用,在某些方面依然需要强大的代码来解决生产革新。所以低代码也不是浑水猛兽,也需要根据实际情况加以利用。那么为什么低代码会收到如…...
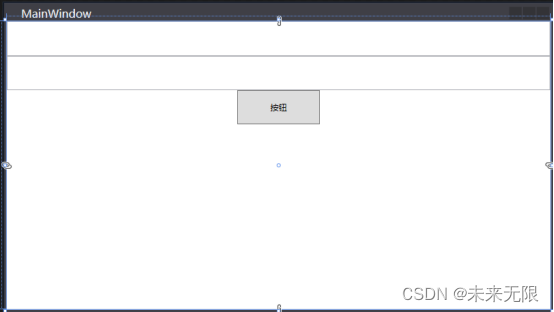
C#WPF通知更改公共类使用实例
本文实例演示C#WPF通知更改公共类使用实例,通过使用公共类简化了代码。其中的代码中也实现了命令的用法。 定义: INotifyPropertyChanged 接口:用于向客户端(通常是执行绑定的客户端)发出某一属性值已更改的通知。 首先创建WPF项目,添加按钮和文本控件 <Window x:C…...

解决高并发问题
在处理项目中的高并发问题时,可以采取以下几种方法: 后端处理:大部分的高并发处理是在后端进行的。可以通过优化数据库查询、增加缓存机制(如集成Redis)、使用分布式技术(如分布式缓存、分布式锁ÿ…...
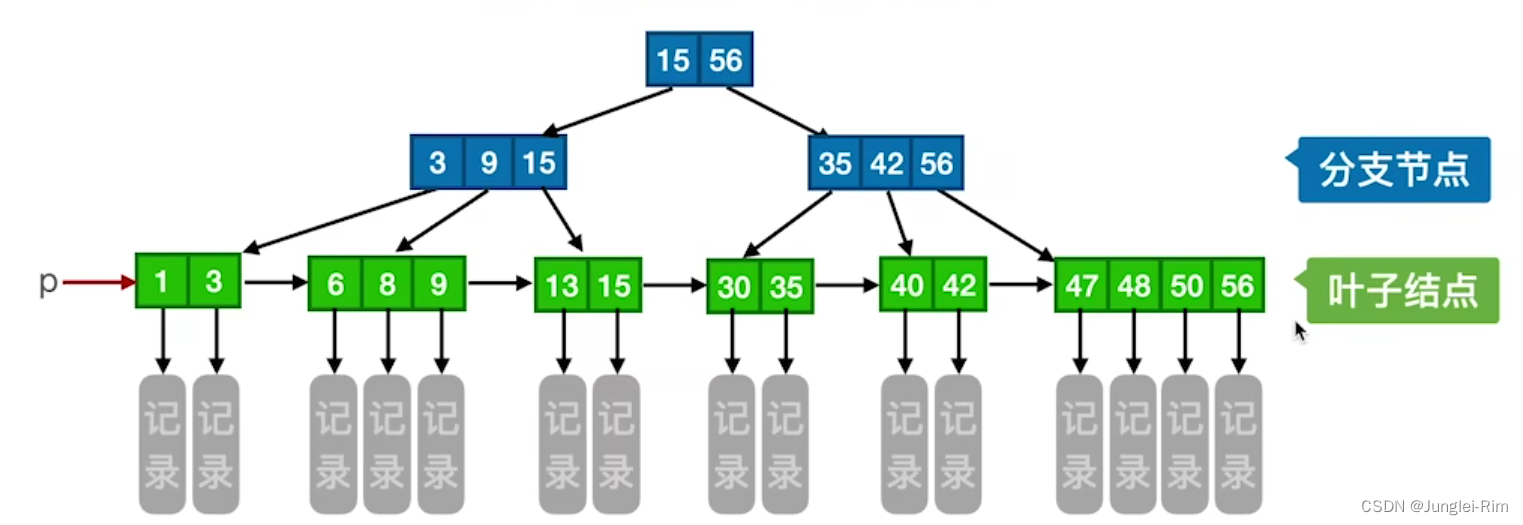
B+树的定义以及查找
1.B树的定义 一棵m阶的B树需满足下列条件: 每个分支结点最多有m棵子树(孩子结点)。非叶根结点至少有两棵子树,其他每个分支结点至少有「m/2]棵子树。结点的子树个数与关键字个数相等。所有叶结点包含全部关键字及指向相应记录的指针,叶结点中将关键字按…...
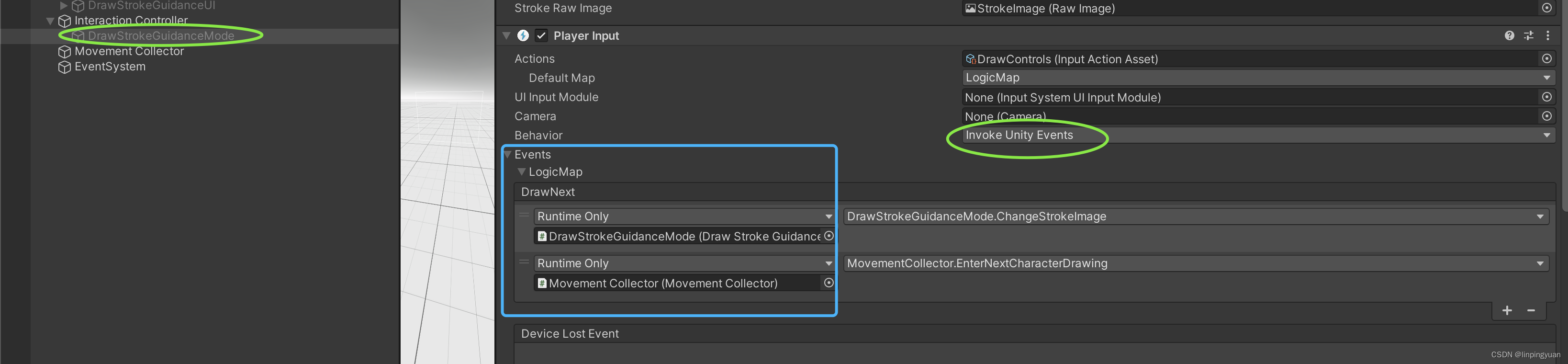
InputAction的使用
感觉Unity中InputAction的使用,步步都是坑。 需求点介绍 当用户长按0.5s 键盘X或者VR left controller primaryButton (即X键)时,显示下一个图片。 步骤总览 创建InputAction资产将该InputAction资产绑定到某个GameObject上在对应的script中…...

Bug排查思路
遇到一个Bug,怎么排查?以下几个思路,希望能对大家有所启发 一、环境问题 1、开发的代码是否已更新 2、是否是缓存原因导致的(强刷,手动清除缓存,web甚至可以直接用无恒模式查看页面) 3、是否…...
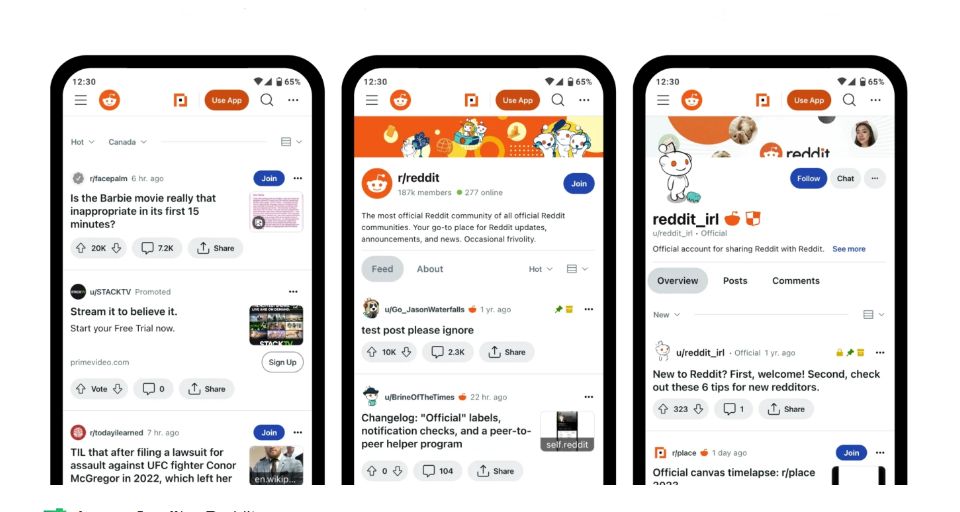
独立站引流,如何在Reddit进行营销推广?
Reddit是目前最被忽视却最具潜力的社交媒体营销平台之一,它相当于国内的百度贴吧,是美国最大的论坛,也是美国第五大网站,流量仅次于Google、Youtube、Facebook以及亚马逊。 如果会玩,Reddit也可以跟其他的社交媒体营销…...

文件拖拽上传功能已经烂大街了,你还不会吗?
说在前面 🖼文件拖拽上传功能现在已经随处可见,大家应该都用过了吧,那么它具体是怎么实现的大家有去了解过吗?今天我们一起来实现一下这个功能,并封装一个拖拽上传组件吧。 效果展示 体验地址:http://jyeon…...
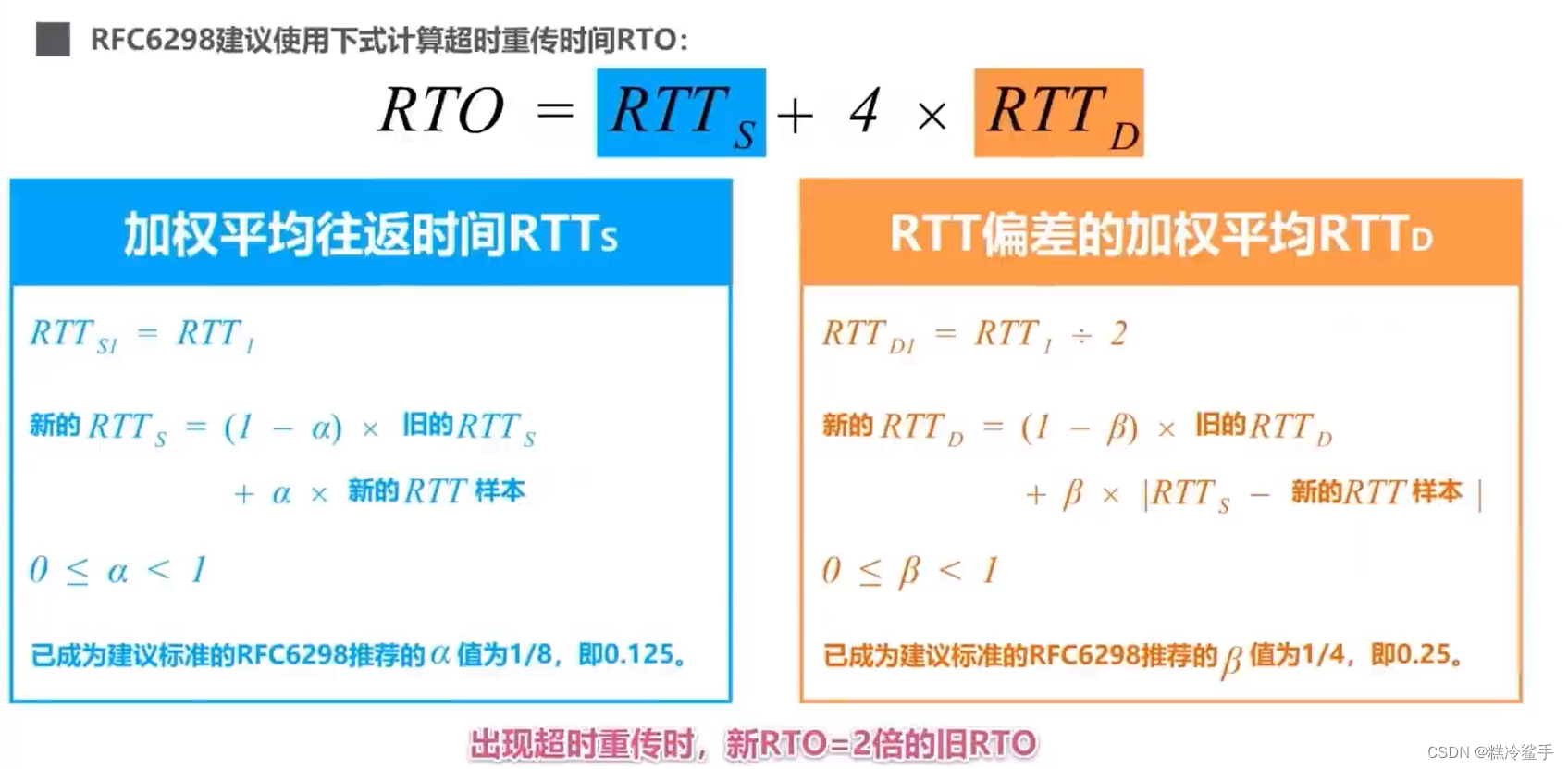
TCP与UDP协议详解!!!
TCP/IP运输层中的两个重要协议 TCP的报文结构 TCP的流量控制 流量控制:让发送方发送速率不要太快,TCP协议使用滑动窗口实现流量控制。 利用滑动窗口机制可以很方便地在TCP连接上实现对发送方的流量控制。 TCP接收方利用自己的接收窗口的大小来限制发送…...

《C++ primer》练习6.36-6.38:书写返回数组引用的函数声明
最近看C primer,看到《C primer》6.3.3练习,要求书写返回数组引用的函数声明,觉得有必要实践记录一下。 这里先总结返回数组的引用的的函数声明写法(下面的Type是数组元素的类型,可以是int、float等,如果要…...
——过滤器)
Spring Cloud Gateway快速入门(三)——过滤器
文章目录 前言Gateway内置网关过滤器什么是网关过滤器Gateway内置网关过滤器GlobalFilterPreFilterPostFilter 使用示例 Gateway全局网关过滤器什么是全局网关过滤器使用全局网关过滤器注册全局网关过滤器使用全局网关过滤器 全局网关过滤器和Gateway内置网关过滤器的区别1. 注…...

vue3相比vue2的优点
一、响应式: (1)vue2:内置的Object.defineProperty将data中的数据转化成响应式数据的,它会将data中的每个属性都转换为具有getter和setter的响应式属性 Object.defineProperty是一个内置的方法,它用于定义…...
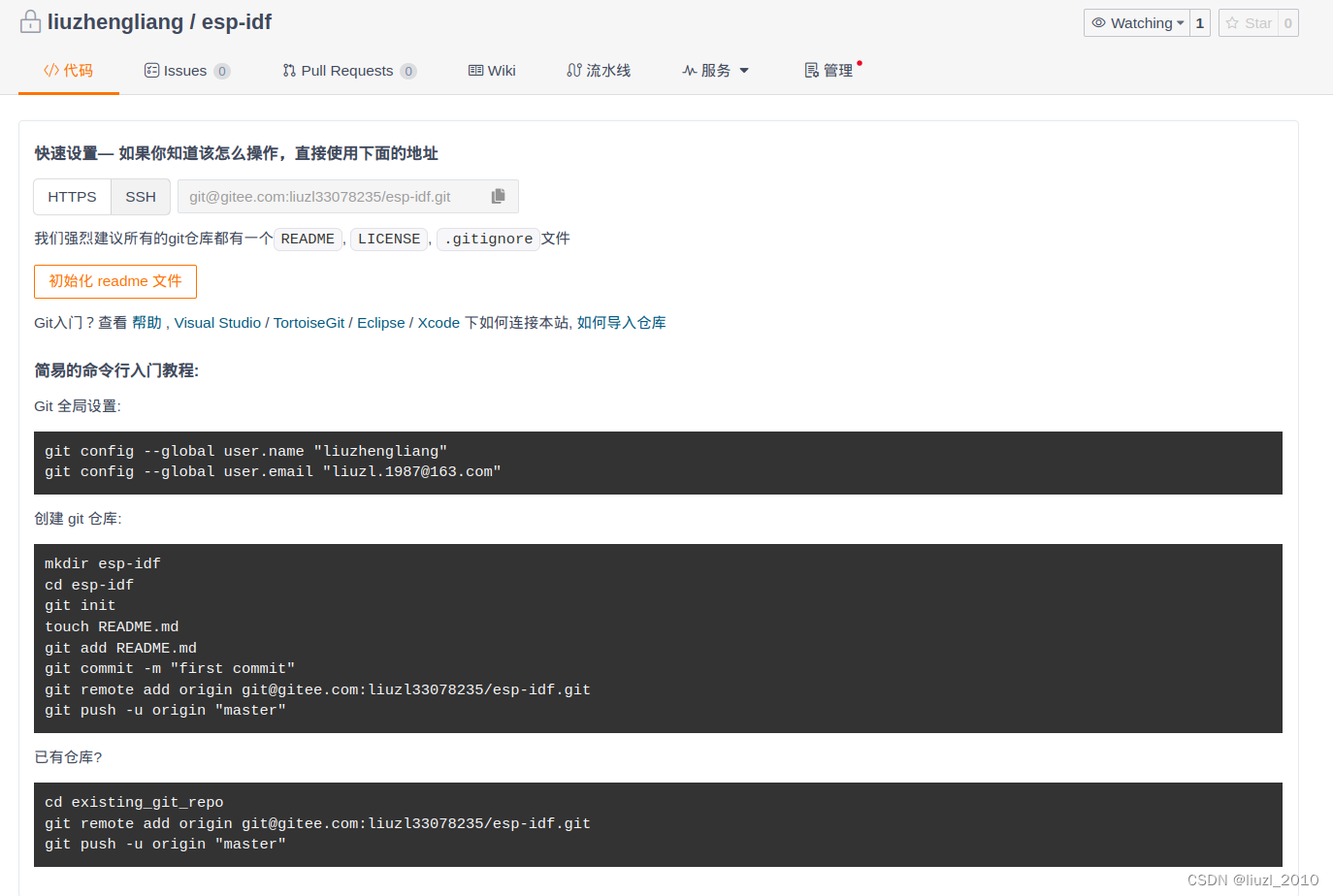
gitee-快速设置
快速设置— 如果你知道该怎么操作,直接使用下面的地址 HTTPS SSH: gitgitee.com:liuzl33078235/esp-idf.git 我们强烈建议所有的git仓库都有一个README, LICENSE, .gitignore文件 初始化 readme 文件 Git入门?查看 帮助 , Visual Studio / TortoiseG…...
将切分的图片筛选出有缺陷的
将切分的图片筛选出有缺陷的 需求代码 需求 由于之前切分的图像有一些存在没有缺陷,需要再次筛选 将可视化的图像更改后缀 更改为xml的 可视化代码 可视化后只有7000多个图像 原本的图像有1W多张 代码 # 按照xml文件删除对应的图片 # coding: utf-8 from P…...

el-tooltip内容换行显示
效果图: html: <div class"rules-tooltip flex-center"><el-tooltip class"item" effect"dark" placement"bottom-start"><div slot"content" v-html"tipsContent"></div>&l…...

linux 下用posix semaphore 解决资源竞争问题实例
/* author: hjjdebug date: 2023年 09月 20日 星期三 09:33:58 CST description: 10辆汽车通过承重5辆汽车的桥,处理一个资源争用问题 * 10个线程代表10辆汽车 * 桥上只能承载5辆汽车, 代表最大只能同时有5辆汽车通过 概要: 让10个线程竞争5个资源,用posix 接口, sem…...

RocketMQ —消费者负载均衡
消费者从 Apache RocketMQ 获取消息消费时,通过消费者负载均衡策略,可将主题内的消息分配给指定消费者分组中的多个消费者共同分担,提高消费并发能力和消费者的水平扩展能力。本文介绍 Apache RocketMQ 消费者的负载均衡策略。 背景信息 …...

实时行情系统设计:从协议选择到高可用架构,再到数据源选型
一、核心问题及解决方案(按踩坑频率排序) 问题 1:误删他人持有锁——最基础也最易犯的漏洞 成因:释放锁时未做身份校验,直接执行 DEL 命令删除键。典型场景:服务 A 持有锁后,业务逻辑耗时超过锁…...

Kandinsky-5.0-I2V-Lite-5s多场景应用:社交头像动效、PPT动态配图、电子相册生成
Kandinsky-5.0-I2V-Lite-5s多场景应用:社交头像动效、PPT动态配图、电子相册生成 1. 认识Kandinsky-5.0-I2V-Lite-5s Kandinsky-5.0-I2V-Lite-5s是一款轻量级图生视频模型,它能将静态图片转化为动态视频。你只需要上传一张首帧图片,再补充一…...

3大优化方案让经典游戏重获新生:WarcraftHelper解决老游戏新设备适配难题
3大优化方案让经典游戏重获新生:WarcraftHelper解决老游戏新设备适配难题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 当你在4K显示器上…...

提升社区运营效率:用快马ai为openclaw网站快速生成搜索与数据看板模块
提升社区运营效率:用快马AI为OpenClaw网站快速生成搜索与数据看板模块 维护一个活跃的开源技术社区网站,比如OpenClaw中文社区,经常需要根据用户反馈快速迭代功能。最近我们社区就遇到了两个需求:一是现有的搜索功能太简单&#…...

忍者像素绘卷GPU优化部署教程:双显卡加速与显存平衡详解
忍者像素绘卷GPU优化部署教程:双显卡加速与显存平衡详解 1. 认识忍者像素绘卷 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,专为像素艺术创作而设计。它将16-Bit复古游戏美学与现代AI技术完美结合,为创作者提供了一个独特…...

DFT工程师的隐藏技巧:深入解读TestMAX中Shared与Dedicated Wrapper Cell的选择策略
DFT工程师的隐藏技巧:深入解读TestMAX中Shared与Dedicated Wrapper Cell的选择策略 在芯片设计的可测试性设计(DFT)领域,Wrapper Cell的选择往往被视为一项"黑盒"操作——工程师们习惯依赖EDA工具自动完成,却…...

OpenFOAM字典文件关键配置实战指南
1. OpenFOAM字典文件基础认知 第一次接触OpenFOAM的朋友,看到满屏幕的字典文件可能会有点懵。这玩意儿就像乐高积木的说明书,告诉你每个零件该怎么拼。我刚开始用的时候,经常把blockMeshDict和snappyHexMeshDict搞混,结果生成的网…...

从原型到实战:基于快马生成代码快速开发可用的worldmonitor疫情监控系统
从原型到实战:基于快马生成代码快速开发可用的worldmonitor疫情监控系统 最近在做一个全球疫情数据监控系统的项目,正好用到了InsCode(快马)平台来快速生成基础代码,然后在这个基础上进行二次开发。整个过程非常顺畅,特别是平台的…...
)
告别编译报错!手把手教你用Keil MDK5搭建GD32F103开发环境(含AC5编译器配置)
告别编译报错!手把手教你用Keil MDK5搭建GD32F103开发环境(含AC5编译器配置) 嵌入式开发新手在初次接触GD32F103时,往往会被各种编译报错搞得焦头烂额。特别是从STM32转过来的开发者,本以为操作流程相似,结…...

EC2Instances.info未来发展规划:AI驱动的智能实例推荐系统
EC2Instances.info未来发展规划:AI驱动的智能实例推荐系统 【免费下载链接】ec2instances.info Amazon EC2 instance comparison site 项目地址: https://gitcode.com/gh_mirrors/ec/ec2instances.info EC2Instances.info作为专业的Amazon EC2实例比较平台&a…...