现代数据架构-湖仓一体
当前的数据架构已经从数据库、数据仓库,发展到了数据湖、湖仓一体架构,本篇文章从头梳理了一下数据行业发展的脉络。
上世纪,最早出现了关系型数据库,也就是DBMS,有商业的Oracle、 IBM的DB2、Sybase、Informix、 微软的SQL Server等等,这些都是OLTP类型,transactional processing, 特点是保障ACID事务,低延时,CRUD操作,作用于少量数据(非大量/全量数据)。
随着关系型数据库里的数据增长,数据分析的需求越来越多,数据仓库 data warehouse随即诞生,DW是面向集成的数据,通过ETL、ELT加载不同数据源的数据入仓,面向分析OLAP, 针对大量或者全量数据做分析,存储历史数据,支持time travel,时间旅行,可回溯到数据的早前版本,代表的有teradata,snowflake, greenplum , clickhouse,数据仓库多为MPP架构,share nothing,云时代的数据仓库如 AWS Redshift、GCP Bigquery 、 Snowflake,几乎都支持存算分离。
数据仓库中的数据通常需要经过数仓建模形成 ODS DWD DWS ADS DM等不同数据层,每层都需要进行相应的清洗加工整合等数据开发,数据工程师大量工作就聚焦在数据仓库中的数据开发方向。
随着数据量的增长,商业的数据库,数据仓库也无法应对海量数据的存储和计算,Google发表了三篇论文,业内称之为三驾马车 GFS, BigTable, Map/Reduce , 基于理论慢慢形成了Hadoop ecosystem, hdfs,hbase,hive, spark,flink...越来越多的组件构成了Hadoop生态。
Apache Hadoop开源, 但安装运维成本高,各组件间版本兼容复杂,商业发行版,Cloudera/Hortonworks 有CDH, HDP 发行版,曾经有免费的社区版,目前两家公司合并,社区版停止更新和支持,如想使用整合好的Hadoop版本,则需要付费按年订购。
再后来,随着数据的增长,非结构化数据的比重越来越大,数据湖概念被提出。
AWS对数据湖的定义:数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
WIKIPEDIA:数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。
数据仓库和数据湖各有擅长的点,也互相有借鉴和融合,目前数仓产品大多对数据湖里的数据可以实现联邦查询,数据湖的分析引擎,通过连接器也可以查询数据仓库里的数据。
数据湖治理起来比较难,需要有完善的管理工具、管理流程和制度保障,一旦缺乏治理,容易形成数据沼泽,数据沼泽是一种退化的、缺乏管理的数据湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
主流的开源数据湖平台有Delta Lake、Iceberg和Hudi,主要提供对数据湖中数据的Table定义,实现upsert/delete 、ACID 、管理 Schema Evolution等等。
数据湖有两种处理并发的两种机制。
COW(copy on write) 写时复制,读性能好,写性能差,针对多读少写场景
MOR(merge on read) 读时合并 ,写性能好,读性能略差,针对高频更新场景
Databricks的白皮书:「Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics」中最早提出了湖仓一体这个概念。Lakehouse 是一种全新的开放式架构,结合了数据湖和数据仓库的最佳元素。Lakehouses 由一个新的系统设计实现:在开放格式的低成本云存储之上直接实现与数据仓库中类似的数据结构和数据管理功能。从下图可以看到,实际目前的发展阶段如中间的架构图所示,湖仓并存,各自负责一部分自己优势的工作负载。但是从第三个架构图可以看出Databricks的雄心,它希望用低廉的存储和上面的治理层,统一实现数据湖和数据仓库的所有功能需求,简而言之,不再需要Teradata、Redshift、Snowflake这些云上云下数仓产品,任重道远。
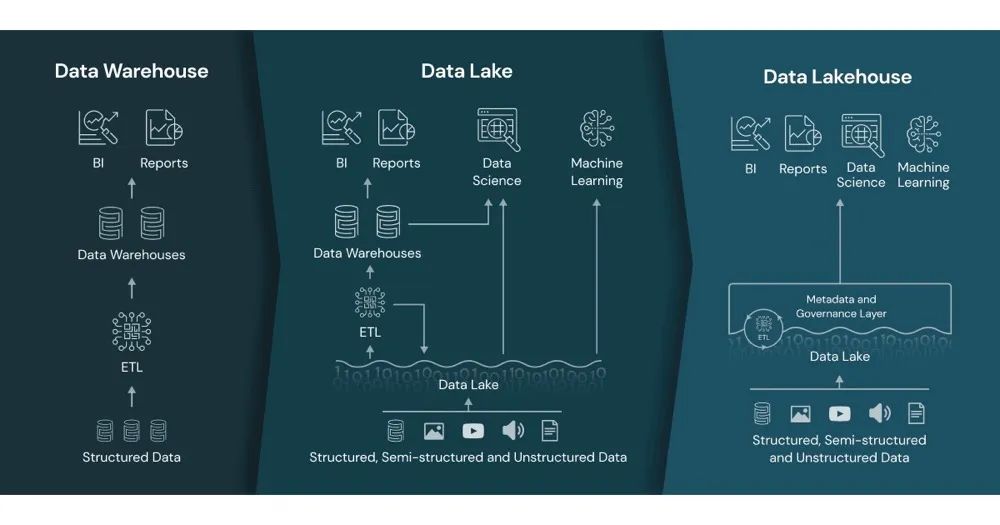
下面我们看看经常提到的术语,数据平台和数据中台。
数据平台:提供的是数据加工处理的能力,从计算和存储等技术角度看
数据中台:是一套可持续“让企业的数据用起来”的机制,一种战略选择和组织形式,是依据企业特有的业务模式和组织架构,通过有形的产品和实施方法论支撑,构建一套持续不断把数据变成资产并服务于业务的机制。
数据中台从技术角度当然包括数据平台的构建,但数据中台的外延还包括企业内部组织和流程上的支撑,目的是数据资产化,资产服务化,数据的生产和应用形成闭环,数据价值得到变现。
接下来我们来看看AWS对现代数据架构的定义:智能湖仓架构,不是简单地将数据湖和数据仓库糅合在一起,而是将数据湖、数据仓库和专用数据存储集成,从而支持统一的监管和轻松的数据移动。借助 AWS 上的现代数据架构,客户可以快速构建可扩展的数据湖,使用丰富且专业的专用数据服务,通过统一的数据访问、安全性和治理确保合规,在不降低性能的前提下以低成本扩展系统,并轻松跨越组织边界共享数据,从而快速、敏捷、大规模地作出决策。
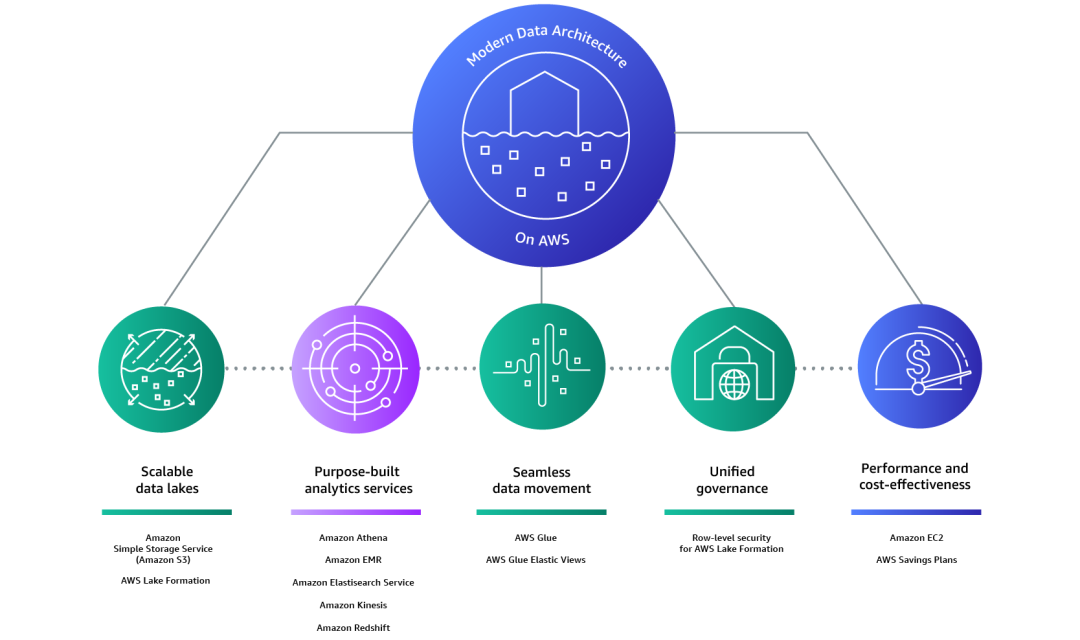
随着这些数据湖和专用存储中的数据量持续增长,由于数据具有重力,移动所有这些数据将变得越来越困难。而确保可以方便地将数据移动到需要的任何位置,具备恰当的控制,以支持分析和获取洞察也同样重要。这种数据的移动方向可能是“由内向外”、“由外向内”、“沿周界”或者“跨界共享”。
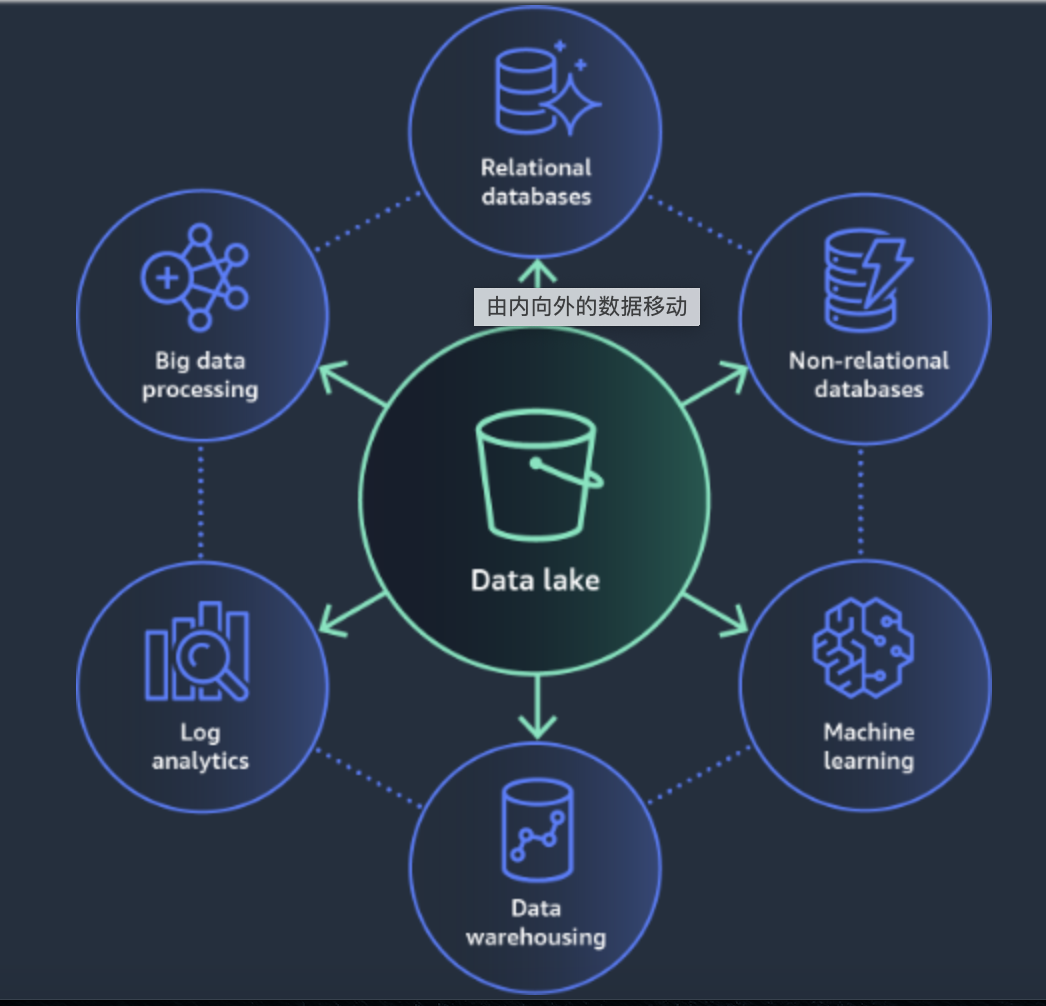
除了AWS对现代数据架构的定义,通用的现代数据架构是这样定义的。
现代数据架构是一种基于云计算、大数据和人工智能技术的数据管理和分析架构,旨在帮助企业更好地处理和分析大数据,并从中获得更多商业价值。现代数据架构通常由以下组件组成:
数据采集层:数据采集层用于从各种数据源中收集数据,并将其传输到数据存储层。数据采集层可以使用多种数据采集工具和技术,包括ETL、ELT、流数据处理等。
数据存储层:数据存储层用于存储和管理各种类型和格式的数据,包括结构化、半结构化和非结构化数据。数据存储层可以使用多种存储服务和技术,包括数据湖、数据仓库、NoSQL数据库等。
数据处理层:数据处理层用于处理和分析存储在数据存储层中的数据,以提取有价值的信息和洞察力。数据处理层可以使用多种处理和分析工具和技术,包括ApacheSpark、Hadoop、SQL Server等。
数据可视化和报表层:数据可视化和报告层用于呈现处理和分析后的数据,以便用户可以更好地理解和使用数据。数据可视化和报告层可以使用多种可视化工具和技术,包括Tableau、Power BI、Excel等。
机器学习和人工智能层:机器学习和人工智能层用于应用机器学习和人工智能技术,以提高数据处理和分析的效率和准确性。机器学习和人工智能层可以使用多种机器学习框架和技术,包括TensorFlow、PyTorch、Scikit-learn等。
现代数据架构可以帮助企业更好地管理和分析大数据,并从中获得更多商业价值。企业可以根据自身业务需求和数据特点,选择适当的组件和技术,构建适合自己的现代数据架构。
相关文章:
现代数据架构-湖仓一体
当前的数据架构已经从数据库、数据仓库,发展到了数据湖、湖仓一体架构,本篇文章从头梳理了一下数据行业发展的脉络。 上世纪,最早出现了关系型数据库,也就是DBMS,有商业的Oracle、 IBM的DB2、Sybase、Informix、 微软…...
最新AI写作系统ChatGPT源码/支持GPT4.0+GPT联网提问/支持ai绘画Midjourney+Prompt应用+MJ以图生图+思维导图生成
一、智能创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧&…...

Python机器学习实战-特征重要性分析方法(5):递归特征消除(附源码和实现效果)
实现功能 递归地删除特征并查看它如何影响模型性能。删除时会导致更大下降的特征更重要。 实现代码 from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE import pandas as pd from sklearn.datasets import load_breast_cance…...

如何快速走出网站沙盒期(关于优化百度SEO提升排名)
网站沙盒期是指新建立的网站在百度搜索引擎中无法获得好的排名,甚至被完全忽略的现象。这个现象往往发生在新建立的网站上,因为百度需要时间来评估网站的质量和内容。蘑菇号www.mooogu.cn 为了快速走出网站沙盒期,需要优化百度SEO。以下是5个…...
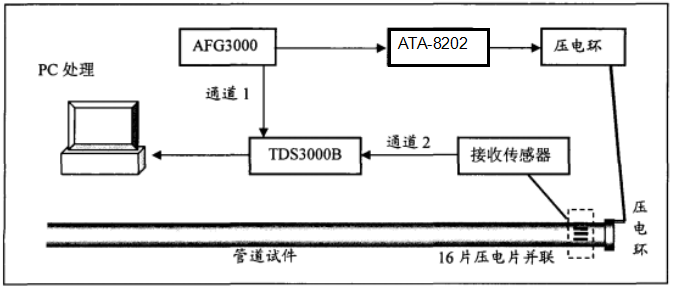
ATA-8000系列射频功率放大器——应用场景介绍
ATA-8000系列是一款射频功率放大器。其P1dB输出功率500W,饱和输出功率最大1000W。增益数控可调,一键保存设置,提供了方便简洁的操作选择,可与主流的信号发生器配套使用,实现射频信号的放大。 图:ATA-8000系…...
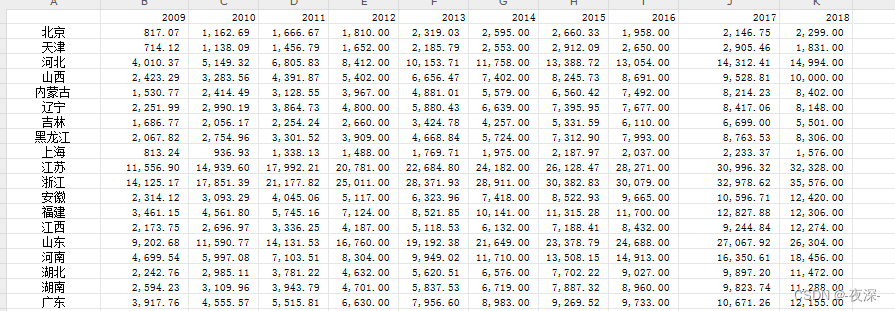
2009-2018年各省涉农贷款数据(wind)
2009-2018年各省涉农贷款数据(wind) 1、时间::209-2018年 2、范围:31省 3、来源:wind 4、指标:涉农贷款 指标解释 :在涉农贷款的分类上,按照城乡地域将涉农贷款分为农村贷款和城…...
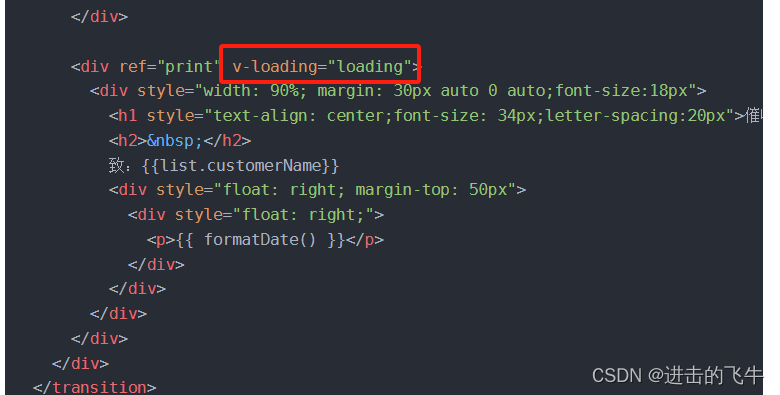
window.print()打印及出现的问题
<template><transition name"el-zoom-in-center"><div class"JNPF-preview-main"><div class"JNPF-common-page-header"><el-page-header back"goBack" :content"打印通知书" /><div clas…...

Fedora Linux 39 Beta 预估 10 月底发布正式版
Fedora 39 Beta 镜像于今天发布,用户可以根据自己的使用偏好,下载 KDE Plasma,Xfce 和 Cinnamon 等不同桌面环境版本,正式版预估将于 10 月底发布 Fedora 39 Beta 版本主要更新了 DNF 软件包管理器,并优化了 Anaconda …...

【zookeeper】基于Linux环境安装zookeeper集群
前提,需要有几台linux机器,我们可以准备好诸如finalshell来连接linux并且上传文件; 其次Linux需要安装上ssh,并且在/etc/hosts文件中写好其他几台机器的名字和Ip 127.0.0.1 localhost localhost.localdomain localhost4 localh…...
什么是IoT数字孪生?
数字孪生是资产或系统的实时虚拟模型,它使用来自连接的物联网传感器的数据来创建数字表示。数字孪生允许您从任何地方实时监控设备、资产或流程。数字孪生用于多种目的,例如分析性能、监控问题或在实施之前运行测试。从物联网数字孪生中获得的见解使用户…...

俄罗斯四大平台速卖通、Joom、Ozon 和 UMKA中国卖家如何脱颖而出!
随着全球化的不断推进,越来越多的中国卖家将目光投向了俄罗斯这个广阔的市场。在众多的跨境电商平台中,速卖通、Joom、Ozon 和 UMKA 无疑是最受关注的四个平台。本文将从卖家的角度,详细分析这四大平台的特点和优势,帮助找到最…...

destoon 调用第三方api接口
调用企查查企业工商信息接口为例: 在 \api\extend.func.php 文件下 注意:有注释内容可能接口无法访问 function select_list($k){$query_data array(key>,keyword>$k);$url "https://api.qichacha.com/ECIV4/GetBasicDetailsByName?&q…...
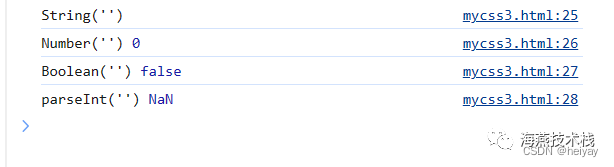
js中的类型转换
原文地址 JavaScript 中有两种类型转换:隐式类型转换(强制类型转换)和显式类型转换。类型转换是将一个数据类型的值转换为另一个数据类型的值的过程。 隐式类型转换(强制类型转换): 隐式类型转换是 Java…...

Oracle物化视图(Materialized View)
与Oracle普通视图仅存储查询定义不同,物化视图(Materialized View)会将查询结果"物化"并保存下来,这意味着物化视图会消耗存储空间,物化的数据需要一定的刷新策略才能和基表同步,在使用和管理上比…...

Spring 学习(九)整合 Mybatis
1. 整合 Mybatis 步骤 导入相关 jar 包 <dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency>…...
)
Android AMS——概述(一)
一、AMS简介 Android AMS(Activity Manager Service)是 Android 操作系统中的一个核心组件,它是 Android 应用程序的管理器,负责管理应用的生命周期、任务栈、进程和活动之间的切换等。AMS在 Android 系统中起着至关重要的作用,确保应用程序能够正确运行并与用户进行交互。…...
DDoS攻击和CC攻击
DDoS是(Distributed Denial of Service,分布式拒绝服务)攻击和CC(Challenge Collapsar,挑战黑洞) 攻击是两种常见且具有破坏性的攻击类型,它们可以对网络基础设施和在线业务造成重大损害。为了抵御这些攻击…...

Lnmp架构之mysql数据库实战2
4、mysql组复制集群 一主多从的请求通常是读的请求高于写 ,但是如果写的请求很高,要求每个节点都可以进行读写,这时分布式必须通过(多组模式)集群的方式进行横向扩容。 组复制对节点的数据一致性要求非常高ÿ…...

【软件工程_设计模式Designer Method】三类?23种常用设计模式?-简介-作业一
设计模式?what? what is Design pattern??? 是一套反复被使用的、经过分类编目的、家喻户晓的、代码设计经验的总结。 它是 软件工程的一块基石。 “ 设计模式是软件工程中一种通用的,可复用的一种解决方案…...

信号相关的函数
#include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); -功能:给任何进程pid,发送任何信号sig 参数: pid: >0:将信号发送给指定的进程 0:将信号发送给当前的进程组 -1:将信号发送…...

【Python | matplotlib】从入门到精通:matplotlib.cm颜色映射的实战应用与自定义指南
1. 初识matplotlib.cm:颜色映射的基础概念 第一次接触数据可视化时,我常常被那些色彩斑斓的热力图和散点图吸引。后来才发现,这些漂亮的颜色背后都离不开一个关键组件——颜色映射(colormap)。matplotlib.cm模块就是专…...

90年代末至21世纪初黑客工具怀旧:从RAT到IRC,我们学到了什么?
远程管理工具(RAT)的黄金时代一切大约始于1998年,“死亡牛仔崇拜”组织在黑帽大会上发布“后门孔”工具。这名字是对微软BackOffice的有意双关,幼稚又精准,符合该组织风格。它能远程控制Windows 95/98机器,…...

如何在5分钟内用Blender创建专业级分子可视化效果
如何在5分钟内用Blender创建专业级分子可视化效果 【免费下载链接】blender-chemicals Draws chemicals in Blender using common input formats (smiles, molfiles, cif files, etc.) 项目地址: https://gitcode.com/gh_mirrors/bl/blender-chemicals 还在为制作分子结…...

BLE心率监测服务开发:从GATT协议到CCCD通知机制的完整实现
1. 项目概述如果你正在开发一款智能手环、心率带或者任何需要实时上报生理数据的可穿戴设备,那么蓝牙低功耗(BLE)的心率监测服务(Heart Rate Service, HRS)几乎是你绕不开的核心功能。这个看似标准的服务,其…...

别再被格式拖垮论文!Paperxie 一键搞定 4000 + 高校毕业论文排版,省下三天改稿时间
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能格式排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 当你终于写完毕业论文的最后一个字,以为能松口气,却发现格式排版才是真正的 “…...
)
8088单板机DIY--串口转换(一)
1.USB转232电路2.功能测试打开设备管理器,可以看到新增的串口。3.通讯测试短接发送和接收,进行自发自收测试。...

Blender 3MF插件:从设计到打印的无缝桥梁 [特殊字符]
Blender 3MF插件:从设计到打印的无缝桥梁 🚀 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 还在为3D模型在不同软件间转换而烦恼吗?B…...

掌控AMD Ryzen性能:5步精通SMUDebugTool硬件调试技巧
掌控AMD Ryzen性能:5步精通SMUDebugTool硬件调试技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

Syzygy-of-Thoughts:用代数几何思想提升大语言模型推理能力
1. 项目概述:当大语言模型遇上代数几何如果你最近在折腾大语言模型(LLM)的推理能力提升,大概率听说过“思维链”(Chain of Thought, CoT)和“自洽性”(Self-Consistency, CoT-SC)这些…...

多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台
多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台在数字孪生与视频孪生全域空间智能感知的建设进程中,各类管控场景普遍部署多品牌、多焦距、多布设姿态的异构摄像设备,衍生出大量编码格式各异、传输时延参差、时钟相位错位的多源异步…...