Kakfa高效读写数据
1.概述
无论 kafka 作为 MQ 也好,作为存储层也罢,无非就是两个功能:一是 Producer 生产的数据存到 broker,二是 Consumer 从 broker 读取数据。那 Kafka 的快也就体现在读写两个方面了,本文也是从这两个方面去剖析Kafka为什么能那么快。
2.利用 Partition 实现并行处理
Kakfa是一个发布-订阅的消息队列,无论是发布还是订阅,必须要指定Topic。Topic是一个逻辑上的概念,而每个Partition是物理上的概念。每个Topic包含一个或者多个Partitiion,不同的Partition可位于不同的节点上。
- 由于不同的Partition可以位于不同的机器上,可以发挥集群的优势,实现机器间的并行处理。
- 由于Partition在物理上对应一个文件夹,即使多个Partition位于同一个节点,可以通过配置可以让同一个节点上的不同 Partition 置于不同的磁盘上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
3.顺序写磁盘
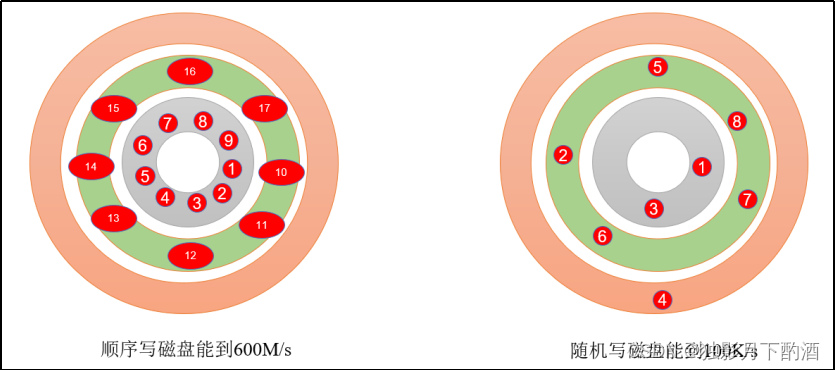
影响磁盘的关键因素是磁盘服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。 机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。衡量磁盘的重要主要指标是IOPS(Input/Output Operations Per Second )和吞吐量。
在Kafka中,都是通过追加写的方式来尽可能的将随机 I/O 转换为顺序 I/O,以此来降低寻址时间和旋转延时,从而最大限度的提高 IOPS。
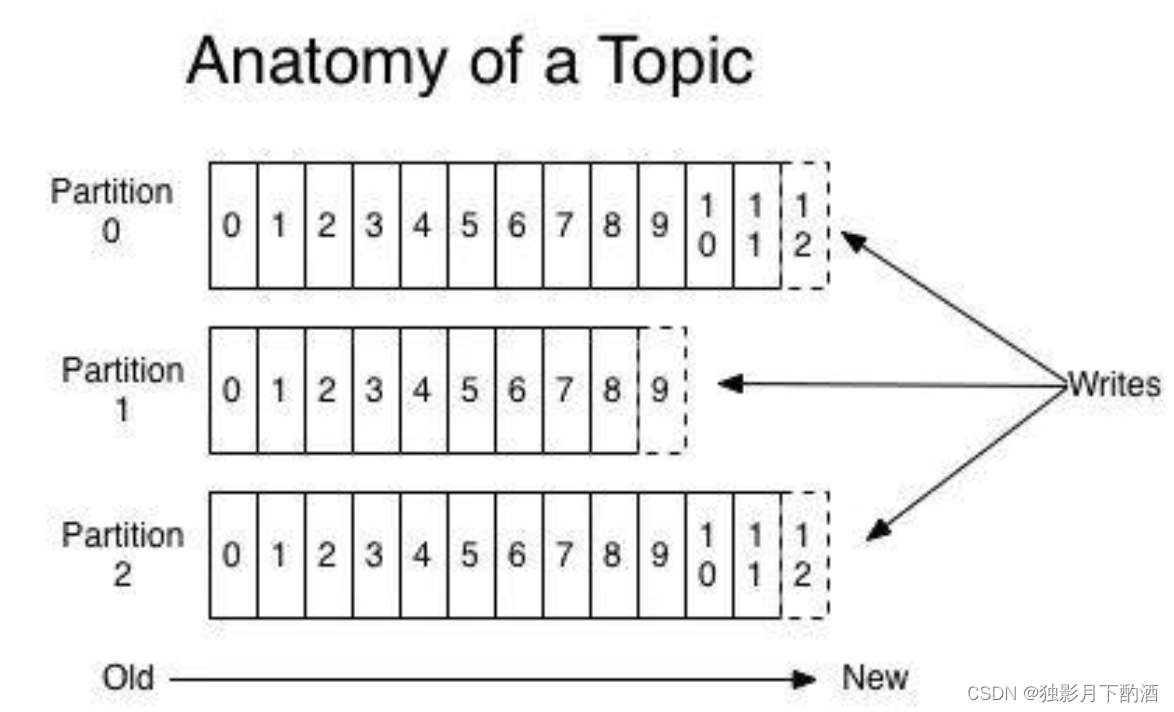
官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
由于磁盘有限,不可能保存所有数据,实际上 Kafka 也没必要保存所有数据,需要删除旧的数据。由于顺序写入的原因,所以 Kafka 采用各种删除策略删除数据时,并非通过使用“读 - 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
4.充分利用 Page Cache
引入 Cache 层的目的是为了提高 Linux 操作系统对磁盘访问的性能。Cache 层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在 Cache 中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。Cache 层也正是磁盘 IOPS 为什么能突破 200 的主要原因之一。
在 Linux 的实现中,文件 Cache 分为两个层面,一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache。Page Cache 主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有 read/write 操作的时候。Buffer Cache 则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。
使用 Page Cache 的好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能。
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间。
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担。
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据。
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用。
Broker 收到数据后,写磁盘时只是将数据写入 Page Cache,并不保证数据一定完全写入磁盘。从这一点看,可能会造成机器宕机时,Page Cache 内的数据未写入磁盘从而造成数据丢失。但是这种丢失只发生在机器断电等造成操作系统不工作的场景,而这种场景完全可以由 Kafka 层面的 Replication 机制去解决。
如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。也正因如此,Kafka 虽然提供了 flush.messages 和 flush.ms 两个参数将 Page Cache 中的数据强制 Flush 到磁盘,但是 Kafka 并不建议使用。
5.零拷贝技术
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程。这一过程的性能直接影响 Kafka 的整体吞吐量。
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。 为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。
传统的 Linux 系统中,标准的 I/O 接口(例如read,write)都是基于数据拷贝操作的,即 I/O 操作会导致数据在内核地址空间的缓冲区和用户地址空间的缓冲区之间进行拷贝,所以标准 I/O 也被称作缓存 I/O。这样做的好处是,如果所请求的数据已存放在内核的高速缓冲存储器中,那么就可以减少实际的 I/O 操作,但坏处就是数据拷贝的过程,会导致 CPU 开销。
把 Kafka 的生产和消费简化成如下两个过程来看:
- 网络数据持久化到磁盘 (Producer 到 Broker)
- 磁盘文件通过网络发送(Broker 到 Consumer)
5.1 网络数据持久化到磁盘 (Producer 到 Broker)
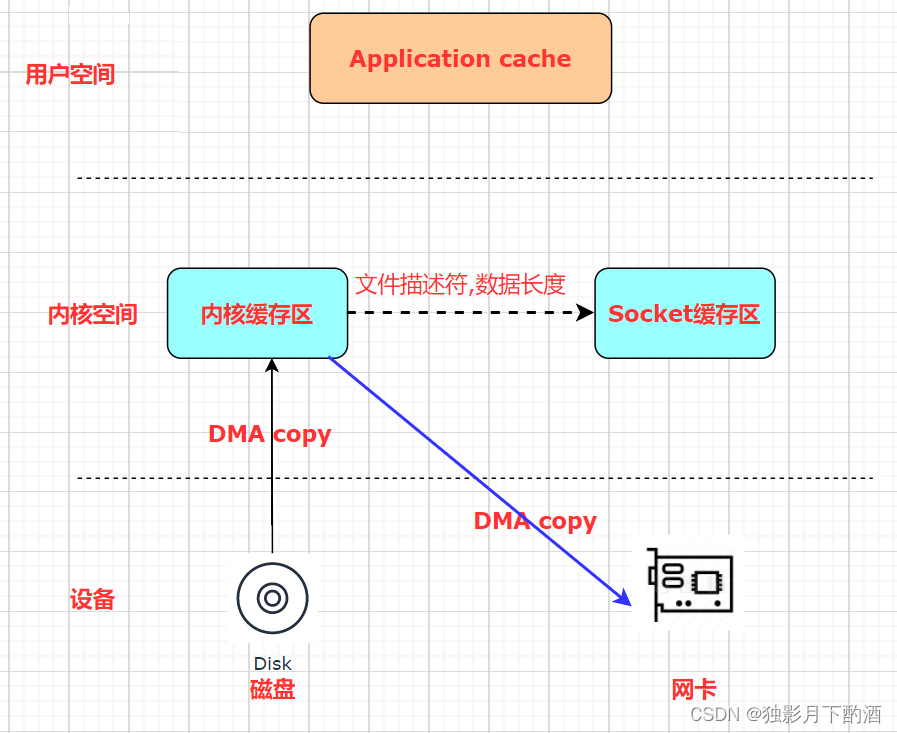
传统模式下,数据从网络传输到文件需要 4 次数据拷贝、4 次上下文切换和两次系统调用。
data = socket.read()// 读取网络数据
File file = new File()
file.write(data)// 持久化到磁盘
file.flush()
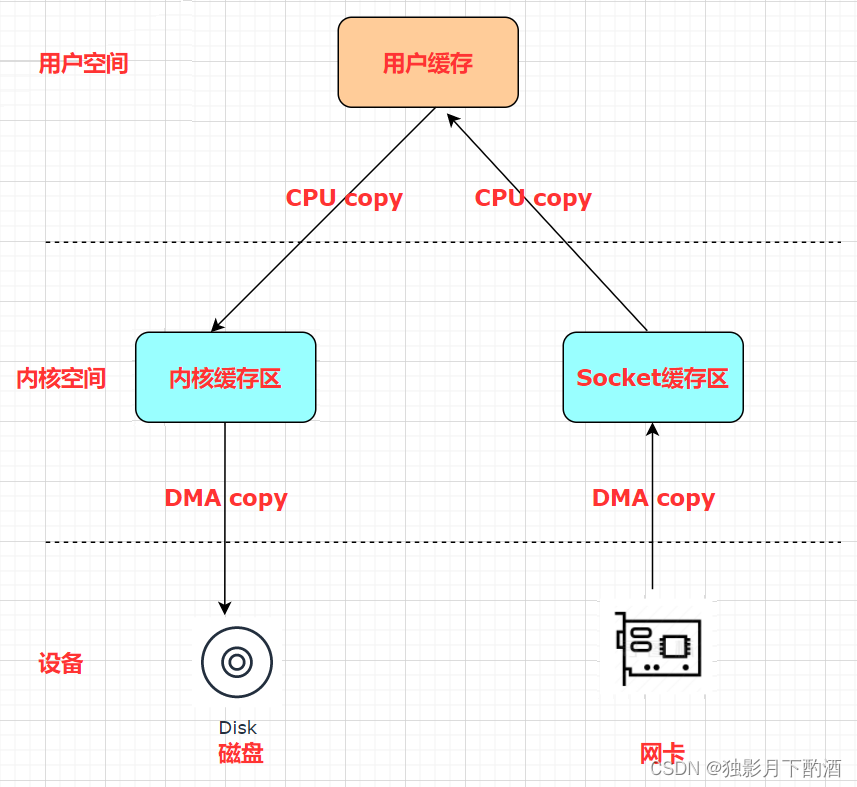
这一过程实际上发生了四次数据拷贝:
- 首先通过 DMA copy 将网络数据拷贝到内核态 Socket Buffer
- 然后应用程序将内核态 Buffer 数据读入用户态(CPU copy)
- 接着用户程序将用户态 Buffer 再拷贝到内核态(CPU copy)
- 最后通过 DMA copy 将数据拷贝到磁盘文件
DMA(Direct Memory Access):直接存储器访问。DMA 是一种无需 CPU 的参与,让外设和系统内存之间进行双向数据传输的硬件机制。使用 DMA 可以使系统 CPU 从实际的 I/O 数据传输过程中摆脱出来,从而大大提高系统的吞吐率。
同时,还伴随着四次上下文切换,如下图所示:
数据落盘通常都是非实时,kafka 生产者数据持久化也是如此。Kafka 的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高 I/O 效率。
对于 kafka 来说,Producer 生产的数据存到 broker,这个过程读取到 socket buffer 的网络数据,其实可以直接在内核空间完成落盘。并没有必要将 socket buffer 的网络数据,读取到应用进程缓冲区;在这里应用进程缓冲区其实就是 broker,broker 收到生产者的数据,就是为了持久化。
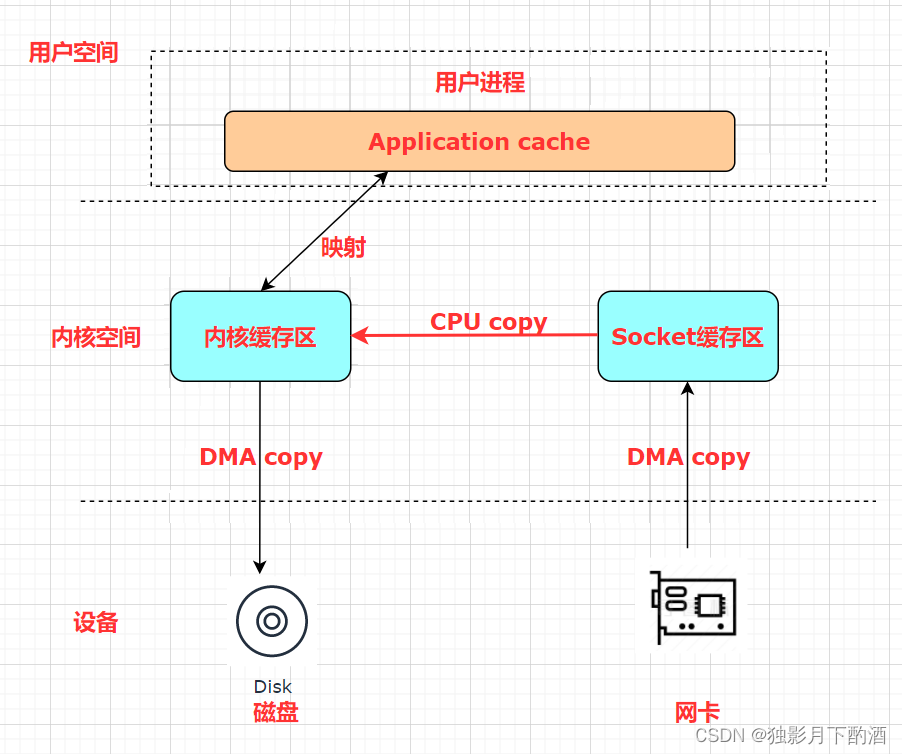
在此特殊场景下:接收来自 socket buffer 的网络数据,应用进程不需要中间处理、直接进行持久化时。可以使用 mmap 内存文件映射。
Memory Mapped Files:简称 mmap,也称 MMFile,使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射。从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程。工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射。完成映射之后对物理内存的操作会被同步到硬盘上。 使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
mmap 也有一个很明显的缺陷——不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。Kafka 提供了一个参数——producer.type 来控制是不是主动flush;如果 Kafka 写入到 mmap 之后就立即 flush 然后再返回 Producer 叫同步(sync);写入 mmap 之后立即返回 Producer 不调用 flush 就叫异步(async),默认是 sync。
零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而减少上下文切换以及 CPU 的拷贝时间。 它的作用是在数据从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。
目前零拷贝技术主要有三种类型:
- 直接I/O:数据直接跨过内核,在用户地址空间与I/O设备之间传递,内核只是进行必要的虚拟存储配置等辅助工作;
- 避免内核和用户空间之间的数据拷贝:当应用程序不需要对数据进行访问时,则可以避免将数据从内核空间拷贝到用户空间 mmap, sendfile, splice && tee, sockmap。
- copy on write:写时拷贝技术,数据不需要提前拷贝,而是当需要修改时再进行部分拷贝。
5.2 磁盘文件通过网络发送(Broker 到 Consumer)
传统方式实现:先读取磁盘、再用 socket 发送,实际也进过四次 copy。
buffer = File.read
Socket.send(buffer)
这一过程可以类比上边的生产消息:
- 首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝)
- 然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝)
- 接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝)
- 最后通过 DMA 拷贝将数据拷贝到 NIC Buffer
Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer,无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 - 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
Kafka 在这里采用的方案是通过 NIO 的 transferTo/transferFrom 调用操作系统的 sendfile 实现零拷贝。总共发生 2 次内核数据拷贝、2 次上下文切换和一次系统调用,消除了 CPU 数据拷贝 。
6.总结
kafka高效读写的原因:
-
利用partition 并行处理
-
顺序写磁盘,充分利用磁盘特性
-
利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
-
采用了零拷贝技术
-
Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
-
Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
相关文章:
Kakfa高效读写数据
1.概述 无论 kafka 作为 MQ 也好,作为存储层也罢,无非就是两个功能:一是 Producer 生产的数据存到 broker,二是 Consumer 从 broker 读取数据。那 Kafka 的快也就体现在读写两个方面了,本文也是从这两个方面去剖析Kafk…...
构造函数)
C++ 类和对象(4)构造函数
C的目标之一是让使用类对象就像使用标准类型一样,但是常规的初始化语法不适用于类似类型Stock: int year 2001; struct thing {char * pn;int m; }; thing amabob {"wodget",-23}; //有效初始化 Stock hot {"Sukies Autos…...
)
数据结构————广度寻路算法 Breadth First Search(广度优先算法)
(一)基础补充 二叉树的基本定义 1)二叉树就是度不超过2的树,其每个结点最多有两个子结点 2)二叉树的结点分为左结点和右结点 代码实现二叉树 #include <stdio.h> #include <stdlib.h> struct Node {int data;struct Node* pLeft;struct Node* pRight; }…...
安卓桌面记事本便签软件哪个好用?
日常生活及工作中,很多人常常会遇到一些一闪而现的灵感,这时候拿出手机想要记录时,却找不到记录的软件。在这个快节奏的时代,安卓手机是我们日常生活不可或缺的伙伴。然而,正因为我们的生活如此忙碌,记事变…...

河北吉力宝以步力宝健康鞋引发的全新生活生态商
在当今瞬息万变的商业世界中,成功企业通常都是那些不拘泥于传统、勇于创新的先锋之选。河北吉力宝正是这样一家企业,通过打造一双步力宝健康鞋,他们以功能性智能科技穿戴品为核心,成功创造了一种结合智能康养与时尚潮流的独特产品…...

反射获取Constructor、Field、Method对象
1、获取构造器 Constructor [ ] getConstructor s ( ) 获取全部的构造器:只能获取 public 修饰的构造器 package com.csdn.pojo; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.junit.Test; import jav…...

【Netty】 ByteBuf的常用API总结
目录 一、ByteBuf介绍 二、ByteBuf创建 1.池化创建 ByteBufAllocator 2.Unpooled (非池化)创建ByteBuf 3.ByteBufUtil 操作ByteBuf 三、读取ByteBuf数据 1.get方法 2.read方法 3.set方法 4.write方法 5.索引管理 6.索引查找 7.索引查找 8.其…...

热门敏捷开发管理工具
敏捷管理研发工具可以协助团队更好地进行敏捷开发和管理。以下是几种流行的敏捷管理研发工具: Leangoo:Leangoo领歌一款永久免费的专业敏捷研发管理工具,它覆盖了敏捷项目研发全流程,包括小型团队敏捷开发,规模化敏捷…...

Java分支结构:一次不经意的选择,改变了我的一生。
👑专栏内容:Java⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、顺序结构二、分支结构1、if语句2、switch语句 好久不见!命运之轮常常在不经意间转动,有时一个看似微…...
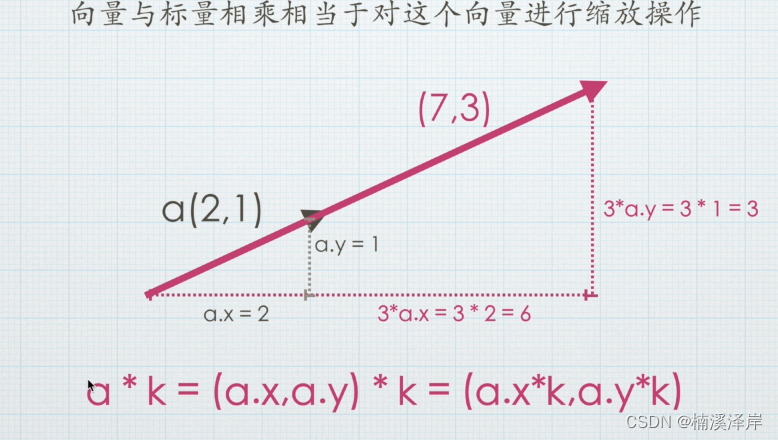
Unity中Shader需要了解的点与向量
文章目录 前言一、点和向量的区别二、向量加法减法1、向量加法2、向量减法(可以把向量减法转化为向量加法) 三、向量的模四、标量1、向量与标量的乘法 前言 Unity中Shader了解使用的…...
)
Java初始化大量数据到Neo4j中(一)
背景:我们项目第一次部署图数据库,要求我们把现有的业务数据以及关系上线第一时间初始化到Neo4j中。开发环境数据量已经百万级别。生成环境数据量更多。 我刚开始开发的时候,由于对Neo4j的了解并没有很多,第一想到的是用代码通用组…...

Excel·VBA日期时间转换提取正则表达式函数
标准日期转换 Function 标准日期(ByVal str$) As DateDim pat$, result$arr Array("(\d{4}).*?(\d{1,2}).*?(\d{1,2})", "(\d{4}).*?(\d{1}).*?(\d{1,2})")If Len(str) < 8 Then pat arr(1) Else pat arr(0)With CreateObject("vbscript.r…...
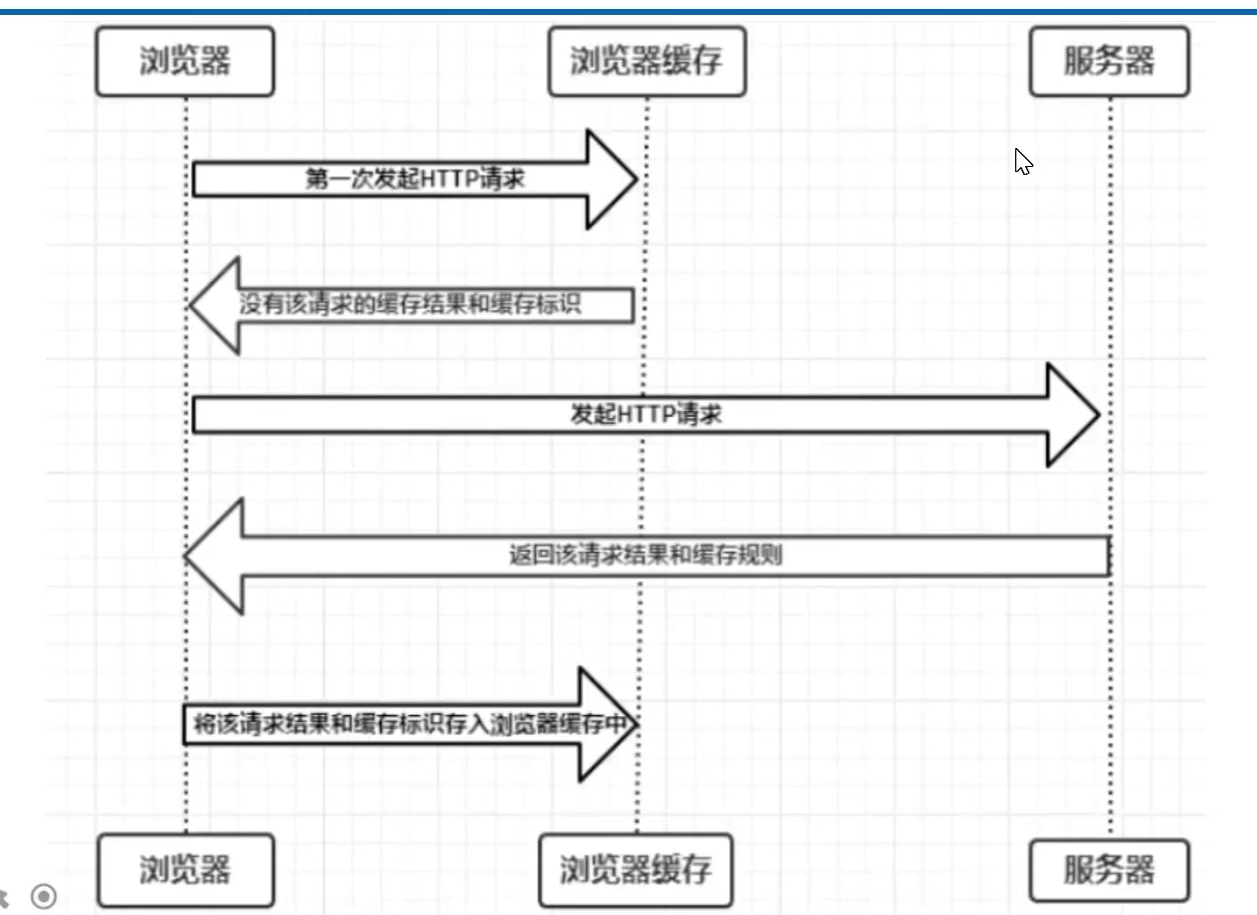
Django中的缓存
Django中的缓存 缓存的定义 定义: 缓存是-类可以更快的读取数据的介质统称,也指其它可以加快数据读取的存储方式。一般用来存储临时数据,常用介质的是读取速度很快的内存 意义:视图渲染有一定成本,数据库的频繁查询过高;所以对于低频变动的页…...

Python 编程基础 | 第二章-基础语法 | 2.4、while 语句
一、while 语句 1、循环语句 Python 编程中 while 语句用于循环执行程序,其基本形式为: while 判断条件(condition):执行语句(statements)……例如: count 0 while (count < 9):print(count)count 1while 语句时还有另外两个…...

Qt Charts简介
文章目录 一.图标类型Charts分类1.折线图和样条曲线图2.面积图和散点图3.条形图4.饼图5.误差棒图6.烛台图7.极坐标图 二.坐标轴Axes类型分类三.图例四.图表的互动五.图表样式主题 一.图标类型Charts分类 图表是通过使用系列类的实例并将其添加到QChart或ChartView实例来创建的…...

MinGW、GCC、GNU和MSVC是什么?有什么区别?
在C和C开发中,常常会遇到MinGW、GCC、GNU和MSVC这些术语。本教程将向您解释它们的含义以及它们之间的区别,帮助您更好地理解这些常见的编译工具和开发环境。 MinGW(Minimalist GNU for Windows): MinGW是一个开源的软件…...

引入easyExcel后,导致springboot项目无法开启tomcat
报错信息: Caused by: java.lang.annotation.IncompleteAnnotationException: org.terracotta.statistics.Statistic missing element type at sun.reflect.annotation.AnnotationInvocationHandler.invoke(AnnotationInvocationHandler.java:81) at com.sun.proxy…...
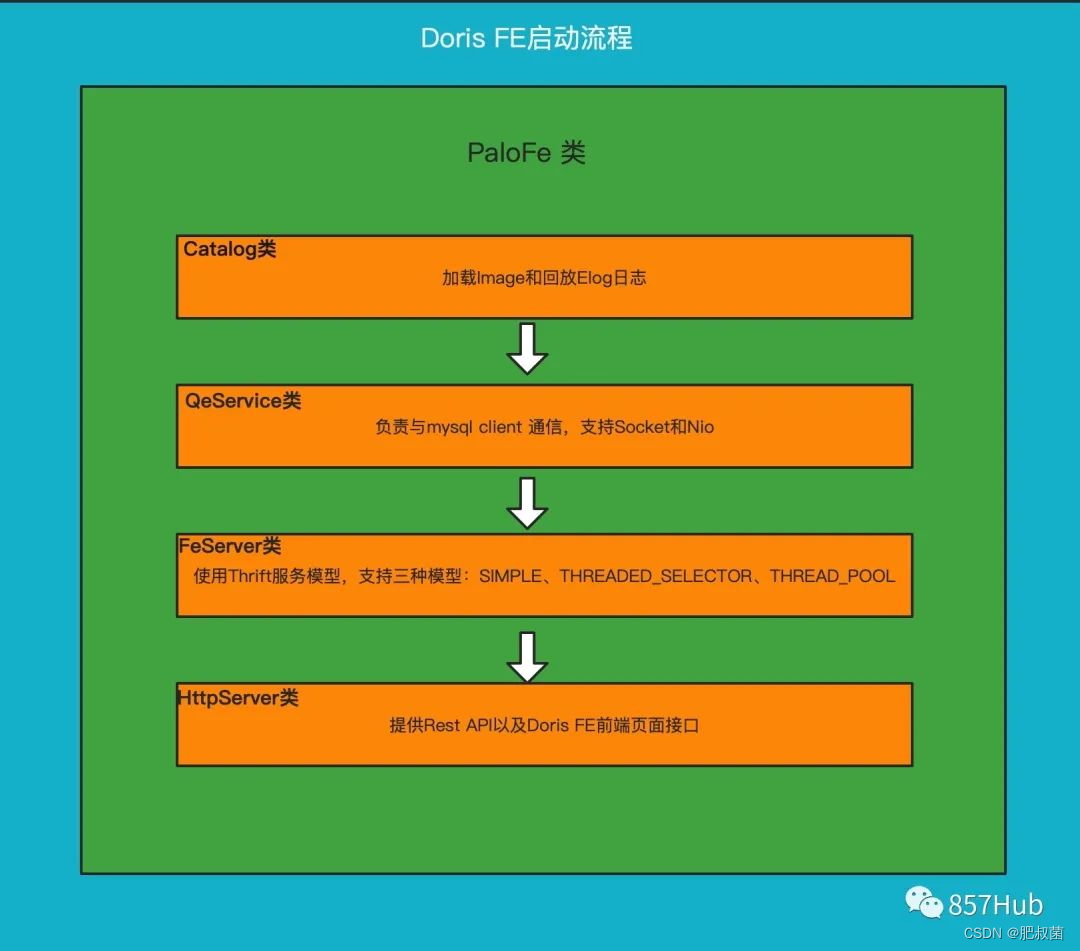
Doris数据库FE——启动流程源码详细解析
Doris中FE主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。代码路径:doris/fe/fe-core/src/main/java/org/apache/doris/DorisFE.java 环境检查 在启动FE的时候,主要做环境检查。检查一些启动时必要的环境变量以及初始化配置…...

服务断路器_Resilience4j线程池隔离实现
线程池隔离配置修改YML文件 resilience4j:thread-pool-bulkhead: instances:backendA:# 最大线程池大小maxThreadPoolSize: 4# 核心线程池大小coreThreadPoolSize: 2# 队列容量queueCapacity: 2编写controller /*** 测试线程池服务隔离* return*/Bulkhead(name "backe…...

原神启动原神启动原神启动原神启动
测试游戏抽卡场景是确保玩家可以正常抽取虚拟物品或角色的重要部分。以下是一些可能的游戏抽卡场景的测试用例示例: 1.正常抽卡流程: 2.测试用户是否能够成功进行一次或多次抽卡操作。 3.确保每次抽卡后,用户收到相应的物品或角色。 4.抽卡…...

开发环境准备:Python、Node.js、Docker与Git
从“环境搞了两天”到“半小时开箱即用”,一个老油条的环境配置血泪史前几天团队来了个新同事,应届生,看着简历上写着“熟悉Python、Node.js、Docker、Git”。我心想,挺好,基本功扎实。然后给了他一个新电脑࿰…...

AI代码智能体突破电话验证瓶颈:从环境模拟到混合架构的实战方案
1. 项目概述:当代码智能体遇上“电话验证墙”最近在折腾Claude这类AI代码助手做自动化任务时,我发现一个挺有意思的瓶颈:它们经常在需要电话验证(Phone Verification)的环节上“卡壳”。这可不是个小问题,想…...

告别机械生硬感:我熬夜实测了4款英文降AI工具,教你搞定结构级优化
最近不少学弟学妹跟我倒苦水,说查重率好不容易降下来了,结果偏偏卡在了英文降ai率上,眼看交稿DDL越来越近,心里特别着急。 我太懂这种感受了,我当时也因为英文降aigc率踩过不少坑,自己连夜纯手动改&#x…...

收藏!AI时代程序员薪资分化严重?3个月转型AI工程,求职成功率提升60%!
文章指出AI时代程序员薪资两极分化,顶级AI人才年薪破亿,而普通开发者求职困难。文章强调这不是行业寒冬,而是结构性变革。建议程序员提升AI工程能力,转型AI工程师,成功案例显示求职成功率提升60%,薪资涨幅3…...

ios蓝牙开发
一、蓝牙基本概念蓝牙:BLE (Bluetooth Low Energy/低功耗蓝牙),一般应用苹果的官方框架基于 <CoreBluetooth/CoreBluetooth.h> 框架进行开发。中心设备:用于扫描周边蓝牙外设的设备,比如我们上面所说的中心者模式࿰…...

Latte文本到视频生成实战:打造个性化AI视频的终极指南
Latte文本到视频生成实战:打造个性化AI视频的终极指南 【免费下载链接】Latte [TMLR 2025] Latte: Latent Diffusion Transformer for Video Generation. 项目地址: https://gitcode.com/gh_mirrors/la/Latte Latte是一款基于TMLR 2025研究成果的文本到视频…...

rust-rdkafka社区生态与最佳实践:知名项目使用案例分享
rust-rdkafka社区生态与最佳实践:知名项目使用案例分享 【免费下载链接】rust-rdkafka A fully asynchronous, futures-based Kafka client library for Rust based on librdkafka 项目地址: https://gitcode.com/gh_mirrors/ru/rust-rdkafka rust-rdkafka是…...
)
毫米波雷达ADAS实战:TI AWR1843芯片上的信号处理链优化心得(附FFT与CFAR配置要点)
毫米波雷达ADAS实战:TI AWR1843芯片上的信号处理链优化心得 在智能驾驶领域,毫米波雷达因其全天候工作能力和稳定的测距测速性能,成为ADAS系统的核心传感器之一。德州仪器(TI)的AWR1843作为一款高度集成的毫米波雷达So…...

对比按需计费与TokenPlan在长期项目中的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与TokenPlan在长期项目中的成本体感差异 在长期运行的AI项目中,成本控制是一个持续优化的过程。不同的计费…...

AI应用治理平台ZLAR:从网关到统一架构的演进与实践
1. 项目概述:从单一工具到统一平台的演进最近在折腾AI应用开发,特别是涉及到多模型调用、安全审计和策略执行这块,发现很多开源项目都是“各自为政”。比如,你需要一个网关来管理AI模型的访问,又需要一个独立的日志系统…...