【JUC系列-08】深入理解CyclicBarrier底层原理和基本使用
JUC系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解JMM内存模型的底层实现原理 | https://zhenghuisheng.blog.csdn.net/article/details/132400429 |
| 【二】深入理解CAS底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132478786 |
| 【三】熟练掌握Atomic原子系列基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132543379 |
| 【四】精通Synchronized底层的实现原理 | https://blog.csdn.net/zhenghuishengq/article/details/132740980 |
| 【五】通过源码分析AQS和ReentrantLock的底层原理 | https://blog.csdn.net/zhenghuishengq/article/details/132857564 |
| 【六】深入理解Semaphore底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132908068 |
| 【七】深入理解CountDownLatch底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133343440 |
| 【八】深入理解CyclicBarrier底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133378623 |
深入理解CyclicBarrier的底层原理和基本使用
- 一,深入理解CyclicBarrier的底层原理
- 1,CyclicBarrier的基本使用
- 2,CyclicBarrier的底层源码实现
- 2.1,lock加锁操作
- 2.2,条件队列入队操作
- 2.3,同步状态器state设置为0
- 2.4,条件队列Node结点阻塞
- 2.5,signalAll满足屏障条件进入下一屏障
- 2.6,条件队列结点出队
- 2.7,条件队列结点入队同步队列
- 2.8,unlock解锁
- 3,总结
一,深入理解CyclicBarrier的底层原理
在前面两篇讲述了Semaphore和CountDownLatch两个并发工具类,都是通过CLH等待队列实现的,接下来讲解第三个常用的并发工具类:CyclicBarrier ,该类与前二者不同,除了使用CLH同步等待队列 外,还用了条件等待队列来实现的,接下来详细的描述一下该类的基本语法和底层的源码实现。
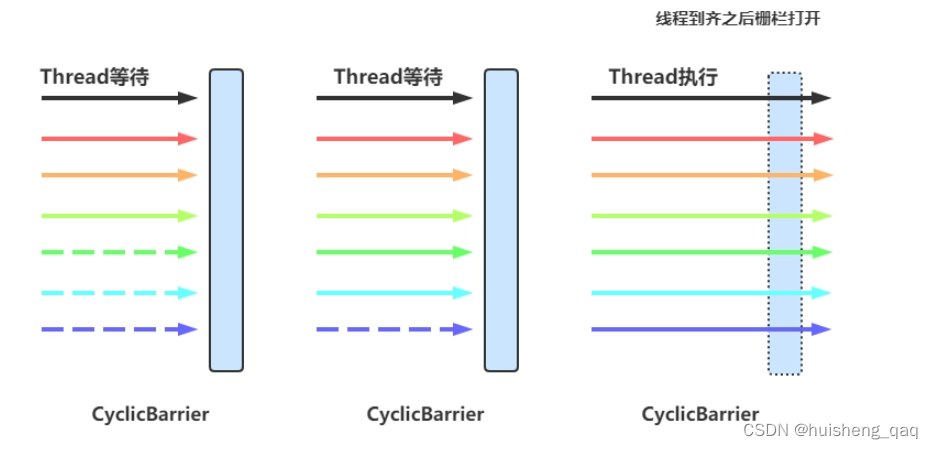
顾名思义,可以被称为循环屏障,屏障指的是可以让多个线程在满足某一个条件的时候,再全部的同时执行,有点类似于之前的内存屏障,循环指的是这个条件可以一直循环的使用
1,CyclicBarrier的基本使用
先举一个简单的例子,了解一下这个工具类是如何使用的。在此之前,先定义一个线程池,通过线程池工具类来管理线程
package com.zhs.study.util;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.*;/*** 线程池工具* @author zhenghuisheng* @date : 2023/9/27*/
public class ThreadPoolUtil {//日志级别(由高到低):fatal -> error -> warn -> info -> debug,低级别的会输出高级别的信息,高级别的不会输出低级别的信息private static final Logger log = LoggerFactory.getLogger(ThreadPoolUtil.class);//构建线程池public static ThreadPoolExecutor pool = null;//向线程池中添提交任务,将任务返回//判断核心线程数数量,阻塞队列,创建非核心线程数,拒绝策略public static <T> Future<?> submit(Runnable runnable) {//提交任务,并将任务返回Future<?> future = getThreadPool().submit(runnable);//将任务存储在hash表中return future;}/*** io密集型:最大核心线程数为2N,可以给cpu更好的轮换,* 核心线程数不超过2N即可,可以适当留点空间* cpu密集型:最大核心线程数为N或者N+1,N可以充分利用cpu资源,N加1是为了防止缺页造成cpu空闲,* 核心线程数不超过N+1即可* 使用线程池的时机:1,单个任务处理时间比较短 2,需要处理的任务数量很大*/public static synchronized ThreadPoolExecutor getThreadPool() {if (pool == null) {//获取当前机器的cpuint cpuNum = Runtime.getRuntime().availableProcessors();log.info("当前机器的cpu的个数为:" + cpuNum);int maximumPoolSize = cpuNum * 2 ;pool = new ThreadPoolExecutor(maximumPoolSize - 2,maximumPoolSize,5L, //5sTimeUnit.SECONDS,new LinkedBlockingQueue<>(), //链表无界队列Executors.defaultThreadFactory(), //默认的线程工厂new ThreadPoolExecutor.AbortPolicy()); //直接抛异常,默认异常}return pool;}
}
接下来再自定义一个线程任务类,内部定义具体的run方法的实现
package com.zhs.study.juc.aqs;
import java.util.concurrent.CyclicBarrier;/*** @author zhenghuisheng* @date : 2023/9/27*/
public class Task implements Runnable {CyclicBarrier cyclicBarrier;//通过构造方法传参,保证拿到的是同一个对象public Task(CyclicBarrier cyclicBarrier){this.cyclicBarrier = cyclicBarrier;}@Overridepublic void run() {try {System.out.println(Thread.currentThread().getName()+ "开始等待其他线程");cyclicBarrier.await();System.out.println(Thread.currentThread().getName() + "开始执行");//TODO 模拟业务处理Thread.sleep(5000);System.out.println(Thread.currentThread().getName() + "执行完毕");} catch (Exception e) {e.printStackTrace();}}
}
接下来定义一个main方法执行这个代码
/*** @author zhenghuisheng* @date : 2023/9/27*/
public class CyclicBarrierDemo {//创建一个线程池static ThreadPoolExecutor threadPool = ThreadPoolUtil.getThreadPool();public static void main(String[] args) {CyclicBarrier cyclicBarrier = new CyclicBarrier(5);//创建20个线程任务for (int i = 0; i < 20; i++) {//创建任务Task task = new Task(cyclicBarrier);//提交任务threadPool.submit(task);}}
}
查看执行结果如下
14:36:50.581 [main] INFO com.zhs.study.util.ThreadPoolUtil - 当前机器的cpu的个数为:4
pool-1-thread-1开始等待其他线程
pool-1-thread-2开始等待其他线程
pool-1-thread-3开始等待其他线程
pool-1-thread-4开始等待其他线程
pool-1-thread-5开始等待其他线程
pool-1-thread-5开始执行
pool-1-thread-1开始执行
pool-1-thread-6开始等待其他线程
pool-1-thread-2开始执行
pool-1-thread-4开始执行…
主要就是当线程累加到5个之后,就会通过这个屏障执行以下的业务,如果没有达到5个,就会被阻塞着。与CountDownLatch的底层实现不同,后者是通过减法的方式实现业务,而循环屏障使用的是加法,并且循环屏障的参数是可以循环使用的,而CountDownLatch不能。
2,CyclicBarrier的底层源码实现
接下来研究一下CyclicBarrier 这个类,先查看一下这个类中的部分属性和构造方法。内部引入了ReentrantLock和trip条件队列对象,并且定义了一个重置内存屏障的对象,在构造方法中,除了引用一个正常的类加的数据之外,还引入了一个副本参数,用于循环使用
public class CyclicBarrier {//用于重置内存屏障private static class Generation {boolean broken = false;}//引入了ReentrantLock锁,因此有AQS的所有特性以及该锁的特性private final ReentrantLock lock = new ReentrantLock();//条件对象,用于构建条件等待队列private final Condition trip = lock.newCondition();//构造方法如下public CyclicBarrier(int parties, Runnable barrierAction) {if (parties <= 0) throw new IllegalArgumentException();this.parties = parties; //外部传入参数的副本,用于循环使用this.count = parties; //外部参数的个数,用于累计this.barrierCommand = barrierAction; //线程任务,优先级更高}
}
在初步的熟悉了这个类之后,还是得通过这个 await 了解底层到底第如何实现的
cyclicBarrier.await();
接下来进入这个await方法内部,在源码中,一般真正干活的方法,都是以do开头的方法
public int await() throws InterruptedException, BrokenBarrierException {try {return dowait(false, 0L); //真正干活的方法} catch (TimeoutException toe) {throw new Error(toe); // cannot happen}
}
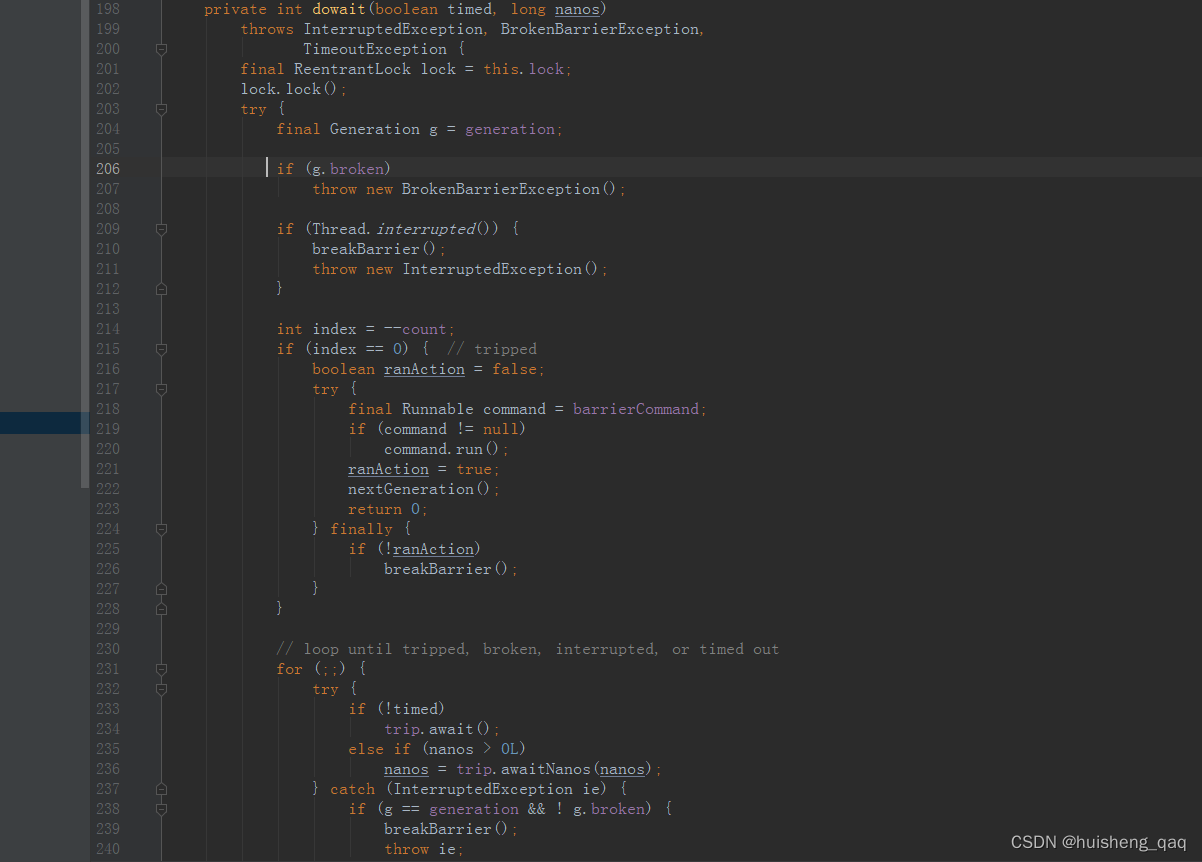
在这个 dowait 方法中,这个方法内部逻辑是比较多的,如下图,接下来会一段一段的分析这里面的方法
2.1,lock加锁操作
首先在该方法中定义了一把ReentrantLock锁,并进行了一个加锁的操作。这个操作其实也不难理解,因为在条件等待队列中,需要加锁在能阻塞,就类似于使用wait方法时,必须在外层加synchronized关键字的
final ReentrantLock lock = this.lock;
lock.lock(); //独占锁
2.2,条件队列入队操作
如在CyclicBarrier构造方法中,会有一个count用于做具体的执行操作,因此在这会有一个自减的操作,如果这个count的自减操作的值不为0,那么会继续进入下面这个for循环的自旋操作,首先会有一个trip.await方法用于条件等待队列进行入队操作
int index = --count; //自减操作
for (;;) {try {//trip是一个条件等待队列对象,调用的这个await是条件等待的入队和阻塞if (!timed) trip.await(); else if (nanos > 0L) nanos = trip.awaitNanos(nanos);} catch (InterruptedException ie) {if (g == generation && ! g.broken) {breakBarrier();throw ie;} else {Thread.currentThread().interrupt();}}if (g.broken) throw new BrokenBarrierException();if (g != generation) return index;if (timed && nanos <= 0L) {breakBarrier();throw new TimeoutException();}
}
接下来查看这个await方法的具体实现,里面首先会有一个addConditionWaiter 结点入队的操作
public final void await() throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();Node node = addConditionWaiter(); //结点入队int savedState = fullyRelease(node); //结点释放锁 int interruptMode = 0;while (!isOnSyncQueue(node)) { //判断是不是同步等待队列结点LockSupport.park(this); //不是则阻塞if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;}//被唤醒的结点尝试获取锁if (acquireQueued(node, savedState) && interruptMode != THROW_IE)interruptMode = REINTERRUPT;if (node.nextWaiter != null) // clean up if cancelledunlinkCancelledWaiters();if (interruptMode != 0)reportInterruptAfterWait(interruptMode);
}
这个Node对象是ConditionObject类下面声明的对象,在ConditionObject这个对象中,只对了Node结点的头指针和尾指针,因此组成这个条件等待的队列是一个由Node结点组成的单向链表,CLH同步等待队列中的Node结点和这个Condition条件等待队列的Node结点是同一个类的对象,只是实现两种队列的结构不一样。
public class ConditionObject implements Condition, java.io.Serializable {private static final long serialVersionUID = 1173984872572414699L;//定义头结点private transient Node firstWaiter;//定义尾结点private transient Node lastWaiter;...
}
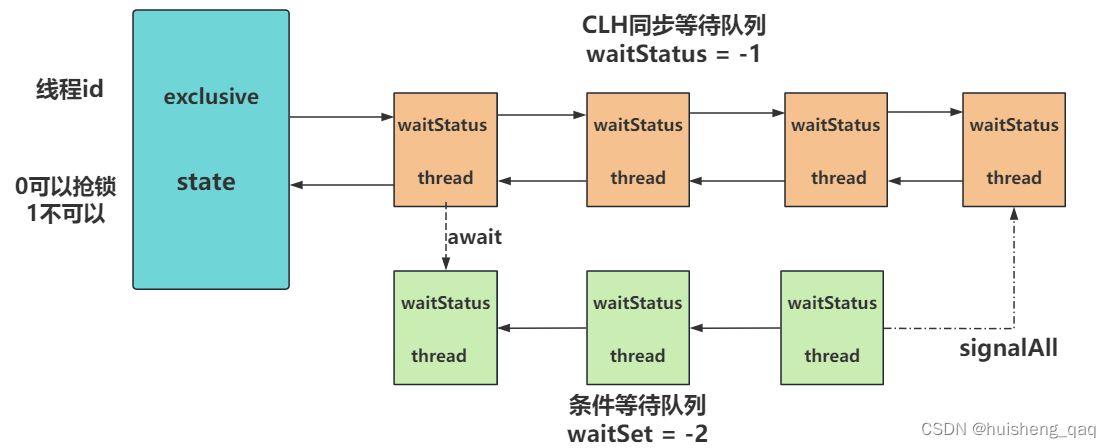
结点入队的操作如下,首先会先修改Node结点的状态为-2条件等待状态,其次会判断这个单向链表是否存在,如果存在则直接将结点加入到单向链表的尾部,如果不存在则直接将结点作为头结点。
private Node addConditionWaiter() {Node t = lastWaiter; //获取条件等待队列的尾结点// If lastWaiter is cancelled, clean out.if (t != null && t.waitStatus != Node.CONDITION) {unlinkCancelledWaiters();t = lastWaiter; //如果链表存在,则直接将结点插入到尾结点中}//设置结点的waitStatus为-2,即为条件等待状态Node node = new Node(Thread.currentThread(), Node.CONDITION);if (t == null) firstWaiter = node; //如果链表不存在,则创建链表,将头结点设置为当前结点else t.nextWaiter = node; //如果链表存在,则直接将链表接入到队尾即可lastWaiter = node; //将当前结点设置为尾结点return node;
}
2.3,同步状态器state设置为0
依旧是2.2的await方法中,会有一个 fullyRelease 方法,由于在一开始调用了lock方法,这个lock是一把独占锁,其内部也是通过CLH同步等待队列实现,因此也是通过修改state的值来让其他线程可以来抢锁,因此需要通过这个 fullyRelease 方法来实现修改状态的功能。
final int fullyRelease(Node node) {boolean failed = true;try {int savedState = getState(); //此时同步状态器的值为1if (release(savedState)) { //释放锁failed = false;return savedState;} else {throw new IllegalMonitorStateException();}} finally {if (failed)node.waitStatus = Node.CANCELLED;}
}
主要是通过这个 release(savedState) 方法来进行释放锁,最终会调用tryRelease方法,将同步状态器中的state的值设置为0,并且将exclusive的值设置为null,主要从外面进来的线程(非队列中的阻塞线程)就可以去抢锁。
protected final boolean tryRelease(int releases) {//外部传参为1,因此 1-1=0int c = getState() - releases;if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) {free = true;setExclusiveOwnerThread(null); //exclusive设置为null}setState(c); //设置为0return free;
}
2.4,条件队列Node结点阻塞
依旧是2.2的await方法中,会有一个判断当前结点是不是同步等待队列中的结点,很明显不是,因此会进入方法内部,就会有一个park方法阻塞的功能
while (!isOnSyncQueue(node)) { //判断是不是同步等待队列结点LockSupport.park(this); //不是则阻塞if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;
}
2.5,signalAll满足屏障条件进入下一屏障
如果此时的count值被减为0,那么就会跳过这个循环屏障,即可以执行这个循环屏障,并且会判断构造方法的参数中是否有这个线程任务,如果有则优先执行这个线程任务
int index = --count; //自减操作
if (index == 0) { // tripped //如果此时为0boolean ranAction = false; //设置一个标志位try {final Runnable command = barrierCommand; //获取构造方法中的这个参数if (command != null) //判断是否存在自定义的任务线程command.run(); //该线程优先级更高,可以先执行ranAction = true; nextGeneration(); //进入下一个循环屏障return 0;} finally {if (!ranAction)breakBarrier();}
}
进入下一个循环屏障的nextGeneration方法的具体实现如下,里面会有一个signalAll
private void nextGeneration() {// signal completion of last generationtrip.signalAll();// set up next generationcount = parties; //副本重置、复原generation = new Generation();
}
通过下图可以更加直观的分析流程,通过await将Node结点加入到队列,并让结点阻塞,那么可以直接通过这个signalAll方法将结点从同步等待队列中唤醒,但是唤醒之后结点的状态还是-2,因此需要解决park的唤醒,还是得加入到同步等待队列中,通过同步等待队列的唤醒机制,将状态改成-1,才能去抢锁,才能最终的释放锁和唤醒线程。
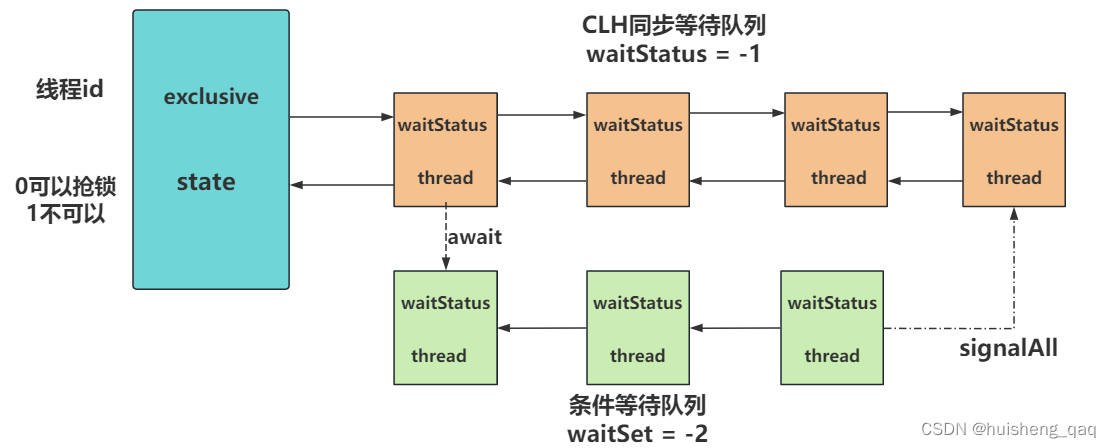
因此继续分析这个signalAll方法,其实现如下,具体的唤醒方法在doSignalAll中实现,并且首先唤醒的是头结点
public final void signalAll() {if (!isHeldExclusively())throw new IllegalMonitorStateException();Node first = firstWaiter; //将头结点获取if (first != null)doSignalAll(first);
}
2.6,条件队列结点出队
里面首先会将条件队列的头结点和尾结点置为null,随后通过first结点执向头结点,随后将头结点的下一个结点也置为空,此时头结点出队。随后通过dowhile的方式,会将所有的结点遍历一遍,此时所有的结点出队
private void doSignalAll(Node first) {lastWaiter = firstWaiter = null; //将头结点和尾结点全部置为null do {Node next = first.nextWaiter;first.nextWaiter = null; //将头结点的下一个结点也置为nulltransferForSignal(first);first = next; } while (first != null);
}
2.7,条件队列结点入队同步队列
由于只有同步队列中才能去唤醒线程,因此只能将出队的队列加入到同步等待队列中,因此查看这个transferForSignal方法底层的具体实现。此时会先修改结点的状态,改成0,其次会有一个结点的enq入队操作,前面几篇都有写这个具体实现。
final boolean transferForSignal(Node node) {//将结点的-2条件状态改成0默认状态if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))return false;//随后结点入队操作Node p = enq(node);//获取结点的状态int ws = p.waitStatus; //如果当前结点的前驱结点为-1,则唤醒if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))LockSupport.unpark(node.thread); return true;
}
入队的操作依旧是那些,双向链表不存在则创建,存在则直接将结点加入,随后修改状态为-1可被唤醒状态,随后结点阻塞,详细可以看前面三篇文章
2.8,unlock解锁
在所有流程走完之后,会在finally里面有一个解锁的方法
lock.unlock();
此时结点已经从条件队列中入队到同步等待队列中,此时条件等待队列的结点都是处于阻塞的,并且状态都为-1,因此需要通过这个unlock方法,去对里面的对象进行唤醒和出队的功能,内部最终会调用这个unpark这个方法
LockSupport.unpark(s.thread);
在被唤醒之后,又会调用这个acquireQueued 进行一个获取锁的功能,这里的抢锁时之际通过cas获取锁的
acquireQueued()
获取锁之后,进入同步队列的结点出队。(同步队列的具体实现看前两篇,写烂了…)
setHead(node);
p.next = null; // help GC
failed = false;
通过unlock方法,可以不断的出队和唤醒下一个线程,这样就能将进入同步队列的条件队列结点给全部唤醒,这样就可以执行参数定义为n个线程了。
3,总结
在整个流程中,可以发现在刚进入是需要加lock获取锁,在await方法中,当结点进入条件队列之后有会释放锁,然后在条件队列结点进入同步队列时又会去抢锁,然后在执行完毕时又会释放锁,总共会有两次加锁和解锁的过程
第一次lock获取锁:配合await使用
第一次await释放锁:将state的值置为0,允许外部线程和同步队列线程结点抢锁
第二次获取锁:条件队列结点进入同步队列时,抢锁成功执行逻辑,失败进入同步队列阻塞
第二次unlock释放锁:同步队列执行完逻辑之后,需要唤醒同步队列中阻塞的结点
循环屏障是通过ReentrantLock和条件队列配合使用的,ReentrantLock中底层通过AQS实现,因此满足了同步队列和条件队列的同时使用。
整个流程可以总结如下:
首先可以在循环屏障中定义一个参数用于表示需要满足的条件,随后线程会调用这个await方法,先通过lock进行一个加锁操作,随后结点会进入条件等待队列,此时结点的状态为-2,在结点阻塞之后,会将同步状态器的state值改成0,锁就进行了释放,此时就会允许外部的线程进行一个抢锁的操作;
当满足这个循环屏障的条件的时候,此时就会进入下一个循环屏障,那么就需要将条件队列的结点进行一个出队的操作,由于唤醒线程只有在同步队列中实现,因此还要将结点加入到同步队列中,入队时又会有一个cas锁的操作,如果抢锁成功,则执行逻辑,如果抢锁失败,则加入到同步队列中并阻塞,当获取锁成功之后,需要结点出队并且唤醒同步队列中被阻塞的结点,因此需要调用最终的unlock方法
相关文章:
【JUC系列-08】深入理解CyclicBarrier底层原理和基本使用
JUC系列整体栏目 内容链接地址【一】深入理解JMM内存模型的底层实现原理https://zhenghuisheng.blog.csdn.net/article/details/132400429【二】深入理解CAS底层原理和基本使用https://blog.csdn.net/zhenghuishengq/article/details/132478786【三】熟练掌握Atomic原子系列基本…...
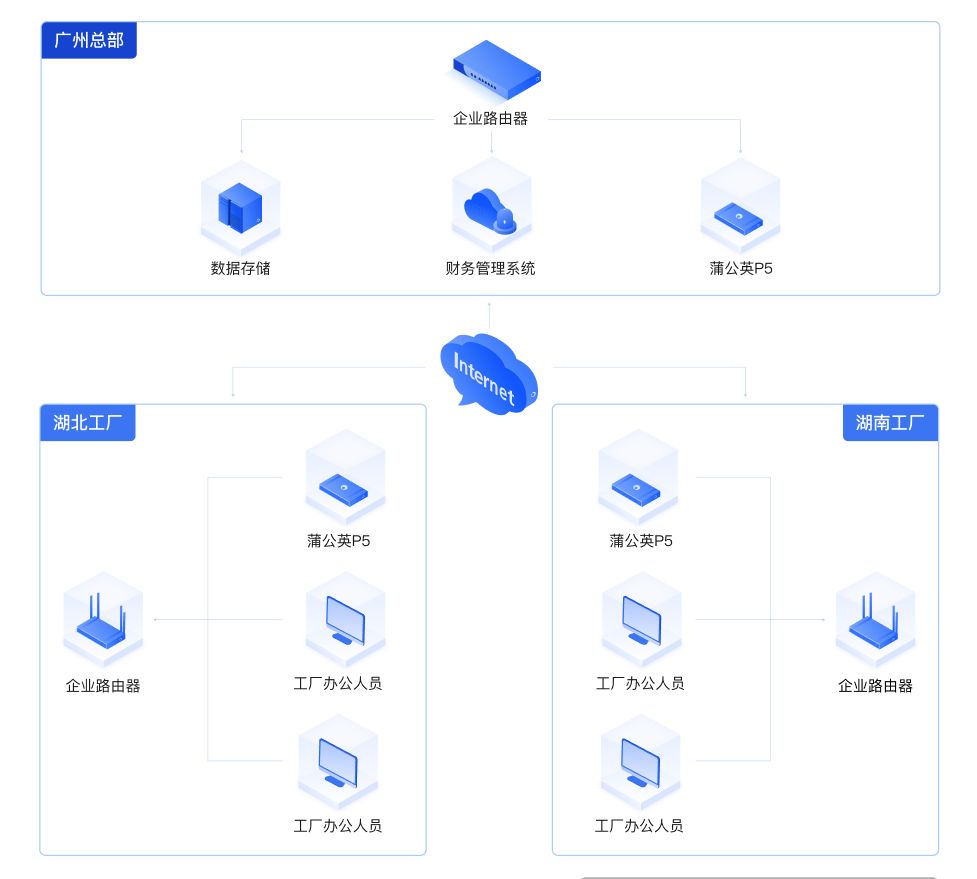
企业专线成本高?贝锐蒲公英轻松实现财务系统远程访问
在办公及信息系统领域,许多企业纷纷采用金蝶等财务管理软件来提升运营效率。以某食品制造企业为例,该企业总部位于广州,并拥有湖北仙桃工厂、广州从化工厂和湖南平江工厂三大生产基地。为提高管理效率,该企业在广州总部局域网内部…...

自学——网络安全——黑客技术
想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客!!! 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队…...
k8s部署gin-vue-admin框架、gitlab-ci、jenkins pipeline 、CICD
测试环境使用的jenkins 正式环境使用的gitlab-ci 测试环境 创建yaml文件 apiVersion: v1 kind: ConfigMap metadata:name: dtk-go-tiktok-admin-configlabels:app.kubernetes.io/name: dtk-go-tiktok-adminapp.kubernetes.io/business: infrastructureapp.kubernetes.io/run…...
【SpringBoot项目】SpringBoot+MyBatis+MySQL电脑商城
在b站听了袁老师的开发课,做了一点笔记。 01-项目环境搭建_哔哩哔哩_bilibili 基于springboot框架的电脑商城项目(一)_springboot商城项目_失重外太空.的博客-CSDN博客 项目环境搭建 1.项目分析 1.项目功能:登录、注册、热销…...
互联网医院|互联网医院系统引领医疗科技新风潮
互联网的迅速发展已经改变了人们的生活方式,而医疗领域也不例外。近年来,互联网医院应运而生,为患者和医生提供了更便捷、高效的医疗服务。本文将深入探讨互联网医院的系统特点、功能以及未来的发展方向,为您展现医疗行业的新时代…...

Mock安装及应用
1、安装 npm install mockjs 2、Mock.Random属性 该属性是一个工具类,用于生成各种随机数据。它提供的方法如下: Basic: boolean,natural,integer,float,character,string,range,date,time,datetime,now; Image: image,dataImage; Color: color; Text: p…...

一起来看看UI设计流程详解吧!通俗易懂
UI设计2023 通俗易懂的UI设计流程详解 首先,大家要明确一下范围:一般分为新产品的从0-1和已有产品上新的模块或功能的从0-1,这两个方向的环节和产出物会有比较大的区别。其实在UI设计师介入之前,我们是需要去了解一些大的方向和…...

TikTok营销成功秘籍:ROI指标的黄金法则
在当今数字营销领域,TikTok已经崭露头角,成为了品牌和营销者们争相追逐的热门平台。 然而,要在TikTok上取得成功,不仅需要创意和内容,还需要精确的ROI(投资回报率)指标来衡量和优化你的营销策略…...
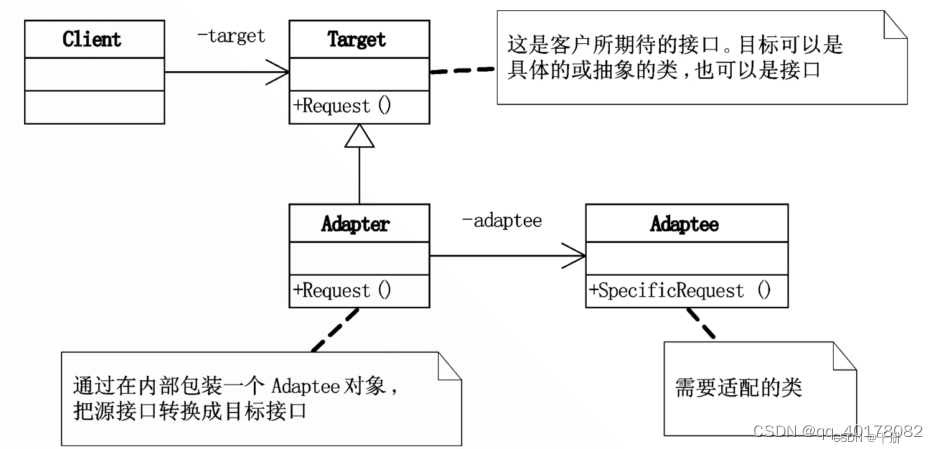
17.适配器模式(Adapter)
意图:将一个类的接口转换为Client希望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类在一起工作。 UML图 Target:定义Client使用的与特定领域相关的接口。 Client:与符合Target接口的对象协同工作。 Adaptee…...

leetcode做题笔记154. 寻找旋转排序数组中的最小值 II
已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums [0,1,4,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,4]若旋转 7 次࿰…...
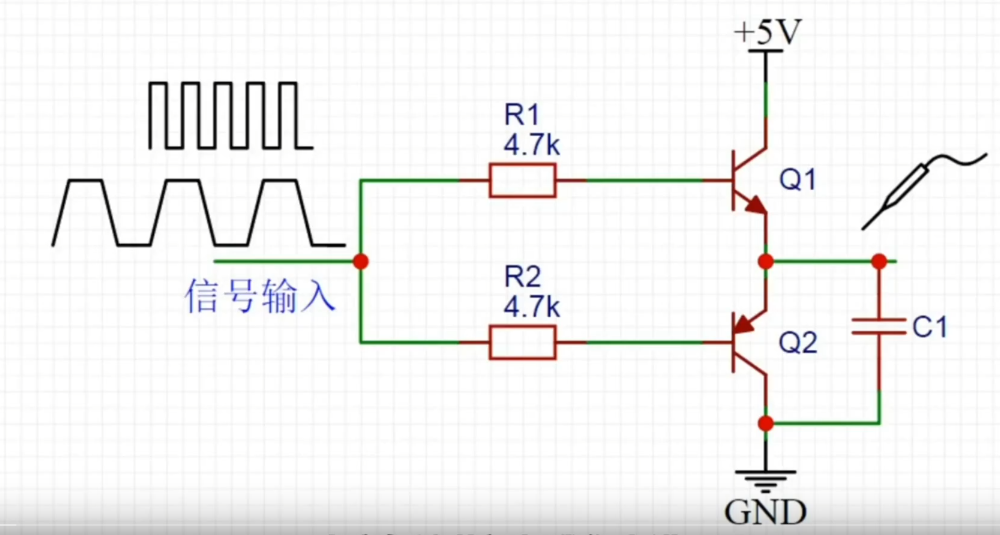
什么是推挽电路?
推挽电路原理: 可以简单理解为推和拉; 此电路总共用到两个元器件,对应图中的Q1----NPN三极管,Q2----PNP三极管,两个电阻R1和R2起到限流的作用;两个三极管的中间对应信号的输出。 下面就举例说明是如何工作的…...
:窗口的使用,处理函数的使用)
208.Flink(三):窗口的使用,处理函数的使用
目录 一、窗口 1.窗口的概念 2.窗口的分类 (1)按照驱动类型分 (2)按照窗口分配数据的规则分类 3.窗口api概览 (1)按键分区(Keyed)和非按键分区(Non-Keyed) *1)按键分区窗口(Keyed Windows) *2)非按键分区(Non-Keyed Windows) (2)代码中窗口API的调…...

时序预测 | MATLAB实现POA-CNN-BiLSTM鹈鹕算法优化卷积双向长短期记忆神经网络时间序列预测
时序预测 | MATLAB实现POA-CNN-BiLSTM鹈鹕算法优化卷积双向长短期记忆神经网络时间序列预测 目录 时序预测 | MATLAB实现POA-CNN-BiLSTM鹈鹕算法优化卷积双向长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现POA-CNN-BiLSTM鹈鹕算…...

【知识点】增量学习、在线学习、离线学习的区别
参考链接:https://www.6aiq.com/article/1613258706447?p1&m0 离线学习 常见的学习方式,一次性将所有数据参与进训练。 离线学习完成了目标函数的优化将不会在改变了离线学习需要一次提供整个训练集时间和空间成本效率低发生数据变更或模型漂移需…...

c++ 学习 之 运算符重载 之 前置++和后置++
前言 int a1;cout << (a) << endl;cout << a << endl;int b1;cout << (b) << endl; // 这个是错误的cout << b << endl;上面样例中, 前置 返回的是引用,所以a 的值变成了3 后置 返回的不是可以改变的…...

K8s Kubelet 垃圾回收机制
前言 Kubelet 垃圾回收(Garbage Collection)是一个非常有用的功能,它负责自动清理节点上的无用镜像和容器。Kubelet 每隔 1 分钟进行一次容器清理,每隔 5 分钟进行一次镜像清理(截止到 v1.15 版本,垃圾回收间隔时间还都是在源码中固化的,不可自定义配置)。如果节点上已…...
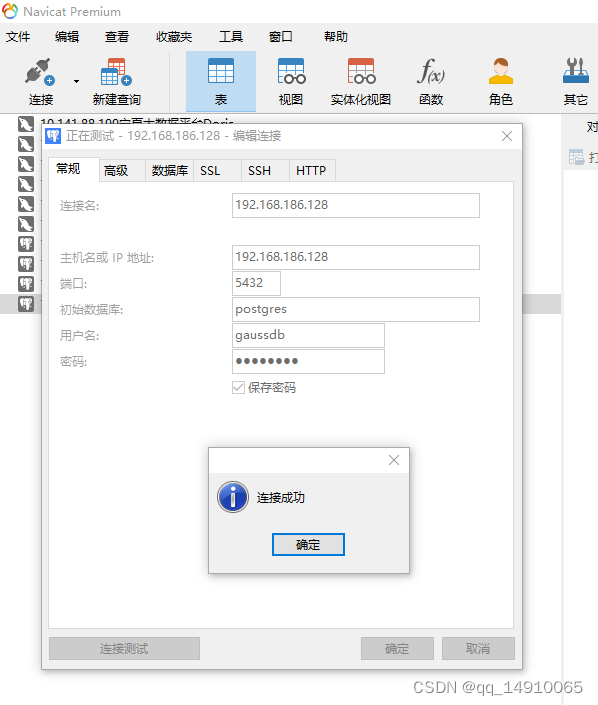
docker安装高斯数据库openGauss数据库
1.创建容器 #创建数据没有挂在的容器 docker run --name opengauss --privilegedtrue -d -e GS_PASSWORDEnmo123 -p 8090:5432 enmotech/opengauss:latest 2. 进入容器,并切换omm用户,使用gsql连接高斯数据库 [rootansible ~]# docker ps -a CONTAIN…...

新手学习:ArcGIS 提取SHP 路网数据、节点
新手学习:ArcGIS 提取SHP 路网数据、节点 参考连接 OSM路网提取道路节点 ArcGIS:如何创建地理数据库、创建要素类数据集、导入要素类、表? 1. 导入开源路网SHP文件 2. 在交点处打断路网数据 未打断路网数据 有一些路径很长,…...
性能测试 —— Tomcat监控与调优:Jconsole监控
JConsole的图形用户界面是一个符合Java管理扩展(JMX)规范的监测工具,JConsole使用Java虚拟机(Java VM),提供在Java平台上运行的应用程序的性能和资源消耗的信息。在Java平台,标准版(Java SE平台)6,JConsole的已经更新到目前的外观…...
)
从‘密码长度’到‘任意代码执行’:手把手复现攻防世界int_overflow靶场(附Python3 EXP)
从密码长度到系统控制:整数溢出漏洞实战攻防全解析 在网络安全领域,整数溢出漏洞往往因其隐蔽性而被开发者忽视,却可能成为攻击者打开系统大门的金钥匙。本文将带您深入一个典型场景:如何通过精心构造的密码输入,从简单…...

数据血缘是什么?怎么建设数据血缘?
今年跟十几个企业老板聊AI落地,发现大家都有一个共识:不上AI是等死,乱上AI是找死。为什么?因为AI这玩意儿就像顶级厨师,食材不新鲜、来历不明,做出来的菜照样能毒倒一片。这里的食材,就是数据。…...

【NotebookLM新闻传播研究权威指南】:20年传媒技术专家亲授AI驱动的新闻生产新范式
更多请点击: https://kaifayun.com 第一章:NotebookLM新闻传播研究导论 NotebookLM 是 Google 推出的基于大型语言模型的实验性研究助手,专为信息整合、溯源验证与知识重构设计。其核心能力在于对用户上传的文档(PDF、TXT、网页…...

从开题到终稿,9 款 AI 毕业论文工具横评:okbiye 领衔,帮你告别熬夜改稿循环
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 论文季的深夜,你是不是也对着空白文档反复刷新浏览器?开题报告被导师打回三次、文献综述东拼西凑逻辑不通、终稿排版…...

gptree:为AI生成项目结构报告,提升代码分析与协作效率
1. 项目概述与核心价值最近在整理个人项目和代码库时,我遇到了一个几乎所有开发者都会头疼的问题:项目越做越多,文件夹嵌套越来越深,README写得再好,时间一久也记不清某个具体功能的实现细节藏在哪个文件的哪个角落里。…...

终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位
终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

2025届毕业生推荐的AI辅助论文网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下,学术研究越发受到人们的重视,在此种背景状况之下,论…...

3步解锁Figma中文界面:设计师效率翻倍的终极指南
3步解锁Figma中文界面:设计师效率翻倍的终极指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼?每次操作都要在大脑中翻译一遍&am…...

开源MCP服务器集合OpenClaw:模块化AI工具链的架构与实践
1. 项目概述:当开源AI工具链遇上“机械爪”如果你最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)与现实世界或复杂工具进行交互的项目,那么你很可能已经接触过“MCP”(Model Context Protocol&…...

基于httpx的异步HTTP客户端xcapy:提升开发效率与代码健壮性
1. 项目概述:一个为现代网络应用量身定制的HTTP客户端库在开发网络应用时,HTTP客户端是我们与外部世界沟通的桥梁。从调用一个公开的API接口,到抓取网页数据,再到构建微服务间的通信,一个稳定、高效且易于使用的HTTP客…...