【深度学习】ONNX模型多线程快速部署【基础】
【深度学习】ONNX模型CPU多线程快速部署【基础】
提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论
文章目录
- 【深度学习】ONNX模型CPU多线程快速部署【基础】
- 前言
- 搭建打包环境
- python多线程并发简单教程
- 基本教程
- ONNX模型多线程并发
- 打包成可执行文件
- 总结
前言
之前的内容已经尽可能简单、详细的介绍CPU【Pytorch2ONNX】和GPU【Pytorch2ONNX】俩种模式下Pytorch模型转ONNX格式的流程,本博文根据自己的学习和需求进一步讲解ONNX模型的部署。onnx模型博主将使用PyInstaller进行打包部署,PyInstaller是一个用于将Python脚本打包成独立可执行文件的工具,【入门篇】中已经进行了最基本的使用讲解。之前博主在【快速部署ONNX模型】中分别介绍了CPU模式和GPU模式下onnx模型打包成可执行文件的教程,本博文将进一步介绍在CPU模式下使用多线程对ONNX模型进行快速部署。
系列学习目录:
【CPU】Pytorch模型转ONNX模型流程详解
【GPU】Pytorch模型转ONNX格式流程详解
【ONNX模型】快速部署
【ONNX模型】多线程快速部署
【ONNX模型】Opencv调用onnx
搭建打包环境
创建一个纯净的、没有多余的第三方库和模块的小型Python环境,抛开任何pytorch相关的依赖,只使用onnx模型完成测试。
# name 环境名、3.x Python的版本
conda create -n deploy python==3.10
# 激活环境
activate deploy
# 安装onnx
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
# 安装GPU版
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnxruntime-gpu==1.15.0
# 下载安装Pyinstaller模块
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pyinstaller
# 根据个人情况安装包,博主这里需要安装piilow
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Pillow
python多线程并发简单教程
多线程是一种并发编程的技术,通过同时执行多个线程来提高程序的性能和效率。python的内置模块提供了两个内置模块:thread和threading,thread是源生模块,是比较底层的模块,threading是扩展模块,是对thread做了一些封装,可以更加方便的被使用,所以只需要使用threading这个模块就能完成并发的测试。
基本教程
python3.x中通过threading模块有两种方法创建新的线程:通过threading.Thread(Target=executable Method)传递给Thread对象一个可执行方法(或对象);通过继承threading.Thread定义子类并重写run()方法。下面给出了俩种创建新线程方法的例子,读者可以运行一下加深理解。
- 普通创建方式:threading.Thread进行创建多线程
import threading import timedef myTestFunc():# 子线程开始print("the current threading %s is runing" % (threading.current_thread().name))time.sleep(1) # 休眠线程# 子线程结束print("the current threading %s is ended" % (threading.current_thread().name))# 主线程 print("the current threading %s is runing" % (threading.current_thread().name)) # 子线程t1创建 t1 = threading.Thread(target=myTestFunc) # 子线程t2创建 t2 = threading.Thread(target=myTestFunc)t1.start() # 启动线程 t2.start()t1.join() # join是阻塞当前线程(此处的当前线程时主线程) 主线程直到子线程t1结束之后才结束 t2.join() # 主线程结束 print("the current threading %s is ended" % (threading.current_thread().name)) - 自定义线程:继承threading.Thread定义子类创建多线
import threading import timeclass myTestThread(threading.Thread): # 继承父类threading.Threaddef __init__(self, threadID, name, counter):threading.Thread.__init__(self)self.threadID = threadIDself.name = name# 把要执行的代码写到run函数里面,线程在创建后会直接运行run函数def run(self):print("the current threading %s is runing" % (self.name))print_time(self.name,5*self.threadID)print("the current threading %s is ended" % (self.name))def print_time(threadName, delay):time.sleep(delay)print("%s process at: %s" % (threadName, time.ctime(time.time())))# 主线程 print("the current threading %s is runing" % (threading.current_thread().name))# 创建新线程 t1 = myTestThread(1, "Thread-1", 1) t2 = myTestThread(2, "Thread-2", 2)# 开启线程 t1.start() t2.start()# 等待线程结束 t1.join() t2.join()print("the current threading %s is ended" % (threading.current_thread().name))
ONNX模型多线程并发
博主采用的是基础教程中普通创建方式创建新线程:将推理流程单独指定成目标函数,而后创建线程对象并指定目标函数,同一个推理session被分配给多个线程,多个线程会共享同一个onnx模型,这是因为深度学习模型的参数通常存储在模型对象中的共享内存中,并且模型的参数在运行时是可读写的,每个线程可以独立地使用模型对象执行任务,并且线程之间可以共享模型的状态和参数。
import onnxruntime as ort
import numpy as np
from PIL import Image
import time
import datetime
import sys
import os
import threadingdef composed_transforms(image):mean = np.array([0.485, 0.456, 0.406]) # 均值std = np.array([0.229, 0.224, 0.225]) # 标准差# transforms.Resize是双线性插值resized_image = image.resize((args['scale'], args['scale']), resample=Image.BILINEAR)# onnx模型的输入必须是np,并且数据类型与onnx模型要求的数据类型保持一致resized_image = np.array(resized_image)normalized_image = (resized_image/255.0 - mean) / stdreturn np.round(normalized_image.astype(np.float32), 4)def check_mkdir(dir_name):if not os.path.exists(dir_name):os.makedirs(dir_name)args = {'scale': 416,'save_results': True
}
def process_img(img_list,ort_session,image_path,mask_path,input_name,output_names):for idx, img_name in enumerate(img_list):img = Image.open(os.path.join(image_path, img_name + '.jpg')).convert('RGB')w, h = img.size# 对原始图像resize和归一化img_var = composed_transforms(img)# np的shape从[w,h,c]=>[c,w,h]img_var = np.transpose(img_var, (2, 0, 1))# 增加数据的维度[c,w,h]=>[bathsize,c,w,h]img_var = np.expand_dims(img_var, axis=0)start_each = time.time()prediction = ort_session.run(output_names, {input_name: img_var})time_each = time.time() - start_each# 除去多余的bathsize维度,NumPy变会PIL同样需要变换数据类型# *255替换pytorch的to_pilprediction = (np.squeeze(prediction[3]) * 255).astype(np.uint8)if args['save_results']:Image.fromarray(prediction).resize((w, h)).save(os.path.join(mask_path, img_name + '.jpg'))def main():# 线程个数num_cores = 10# 保存检测结果的地址input = sys.argv[1]# providers = ["CUDAExecutionProvider"]providers = ["CPUExecutionProvider"]model_path = "PFNet.onnx"ort_session = ort.InferenceSession(model_path, providers=providers) # 创建一个推理sessioninput_name = ort_session.get_inputs()[0].name# 输出有四个output_names = [output.name for output in ort_session.get_outputs()]print('Load {} succeed!'.format('PFNet.onnx'))start = time.time()image_path = os.path.join(input, 'image')mask_path = os.path.join(input, 'mask')if args['save_results']:check_mkdir(mask_path)# 所有图片数量img_list = [os.path.splitext(f)[0] for f in os.listdir(image_path) if f.endswith('jpg')]# 每个线程被均匀分配的图片数量total_images = len(img_list)start_index = 0images_per_list = total_images // num_cores# 理解成线程池Thread_list = []for i in range(num_cores):end_index = start_index + images_per_listimg_l = img_list[start_index:end_index]start_index = end_index# 分配线程t = threading.Thread(target=process_img, args=(img_l,ort_session, image_path, mask_path,input_name,output_names))# 假如线程池Thread_list.append(t)# 线程执行t.start()# 这里是为了阻塞主线程for t in Thread_list:t.join()end = time.time()print("Total Testing Time: {}".format(str(datetime.timedelta(seconds=int(end - start)))))
if __name__ == '__main__':main()
线程的数量根据需求而定,不是越多越好。
打包成可执行文件
- 在cpu模式下打包可执行文件:
pyinstaller -F run_t.py
- 在gpu模式下打包可执行文件:
pyinstaller -F run_t.py --add-binary "D:/ProgramData/Anaconda3_data/envs/deploy/Lib/site-packages/onnxruntime/capi/onnxruntime_providers_cuda.dll;./onnxruntime/capi" --add-binary "D:/ProgramData/Anaconda3_data/envs/deploy/Lib/site-packages/onnxruntime/capi/onnxruntime_providers_shared.dll;./onnxruntime/capi"
详细的过程和结果此前已经讲解过了,可以查看博主的博文【快速部署ONNX模型】。图片数量较多时,对比此前的执行速度,多线程的执行速度快了俩倍以上。
总结
尽可能简单、详细的介绍ONNX模型多线程快速部署过程。
相关文章:
【深度学习】ONNX模型多线程快速部署【基础】
【深度学习】ONNX模型CPU多线程快速部署【基础】 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【深度学习】ONNX模型CPU多线程快速部署【基础】前言搭建打包环境python多线程并发简单教程基本教程ONNX模型多线程并发 打包成可执行文件总结 前…...

Python 同、异步HTTP客户端封装:性能与简洁性的较量
一、前言 引入异步编程趋势:Python的异步编程正变得越来越流行。在过去,同步的HTTP请求已经不足以满足对性能的要求。异步HTTP客户端库的流行:目前,有许多第三方库已经实现了异步HTTP客户端,如aiohttp和httpx等。然而…...

无代码赋能数字化,云表搭桥铺路链接“数据孤岛”
什么是信息孤岛 企业数字化转型过程中,信息孤岛是一个突出的问题。这种情况发生的原因是,企业内部使用了多种应用软件,时间一长,员工在不同的系统中积累了大量的企业数据资产。然而,由于这些系统之间的数据无法互通&am…...
无需公网IP,实现公网SSH远程登录MacOS【内网穿透】
目录 前言 1. macOS打开远程登录 2. 局域网内测试ssh远程 3. 公网ssh远程连接macOS 3.1 macOS安装配置cpolar 3.2 获取ssh隧道公网地址 3.3 测试公网ssh远程连接macOS 4. 配置公网固定TCP地址 4.1 保留一个固定TCP端口地址 4.2 配置固定TCP端口地址 5. 使用固定TCP端…...

网络爬虫学习笔记 1 HTTP基本原理
HTTP原理 ~~~~~ HTTP(Hyper Text Transfer Protocol,超文本传输协议)是一种使用最为广泛的网络请求方式,常见于在浏览器输入一个地址。 1. URI和URL URL(Universal Resource Locator,统一资源定位器&…...
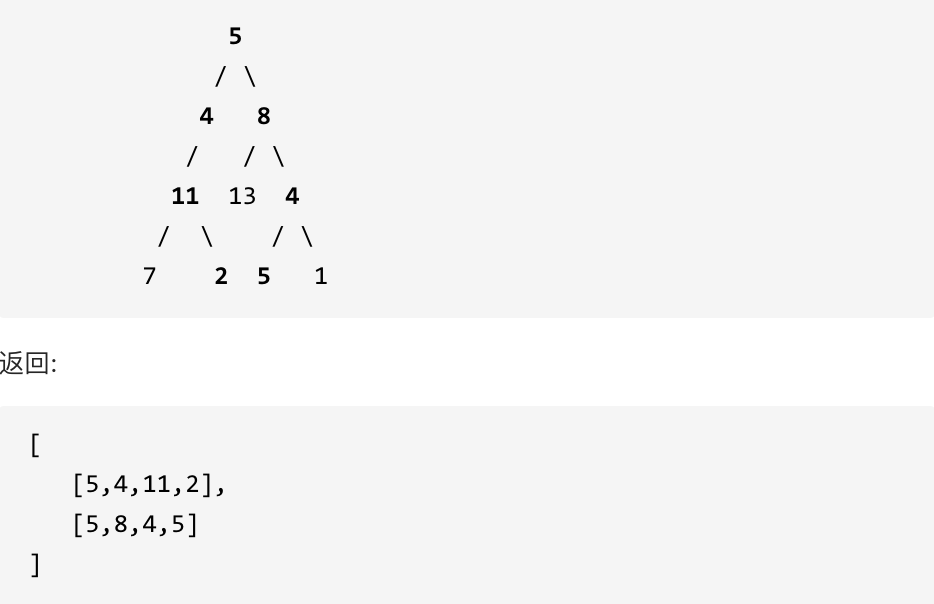
113. 路径总和ii
力扣题目链接(opens new window) 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。 说明: 叶子节点是指没有子节点的节点。 示例: 给定如下二叉树,以及目标和 sum 22, 在路径总和题目的基础上&…...
百度APP iOS端包体积50M优化实践(六)无用方法清理
一、前言 百度APP包体积经过一期优化,如无用资源清理,无用类下线,Xcode编译相关优化,体积已经有了明显的减少。但是优化后APP包体积在iPhone11上仍有350M的空间占用。与此同时百度APP作为百度的旗舰APP,业务迭代非常多…...
)
MySQL了解视图View (视图篇 一)
视图View是什么? MySQL的视图是一种虚拟表,它是基于一个或多个表的查询结果构建而成的。视图并不实际存储数据,而是根据定义的查询逻辑动态生成结果。 ----------------------------------- 视图的特点: - 虚拟表:…...

使用applescript自动化trilium的数学公式环境
众所周知,trilium什么都好,就是对数学公式的支持以及markdown格式的导入导出功能太拉了,而最拉的时刻当属把这两个功能结合起来的时候:导入markdown文件之后,原来的数学公式全没了,需要一个一个手动用ctrlm…...
idea中maven项目打包成jar,报错没有主清单属性解决方法
使用idea自带的打包可能会出现一下问题 在pom.xml中引入下面的依赖,即可解决 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><executions&…...

Caddy Web服务器深度解析与对比:Caddy vs. Nginx vs. Apache
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
基于PHP+MySQL的家教平台
摘要 设计和实现基于PHP的家教平台是一个复杂而令人兴奋的任务。这个项目旨在为学生、家长和教师提供一个便捷的在线学习和教授平台。本文摘要将概述这个项目的关键方面,包括用户管理、课程管理、支付处理、评价系统、通知系统和安全性。首先,我们将建立…...

吉利微型纯电,5 万元的快乐
熊猫骑士作为一款主打下层市场的迷你车型,吉利熊猫骑士剑指宝骏悦也,五菱宏光 MINI 等热门选手。 9 月 15 日,吉利熊猫骑士正式上市,售价为 5.39 万,限时优享价 4 .99 万元。价格和配置上对这个级别定位的战略车型有一…...

Gitee使用方法
Gitee是一个基于 Git 的代码托管和协作平台,具有免费、稳定等特点,并且能够与国内的Gitee社区、码云等服务相结合使用。 以下是使用Gitee的主要步骤: 注册账号:访问Gitee官网,点击“注册”按钮,填写注册信…...
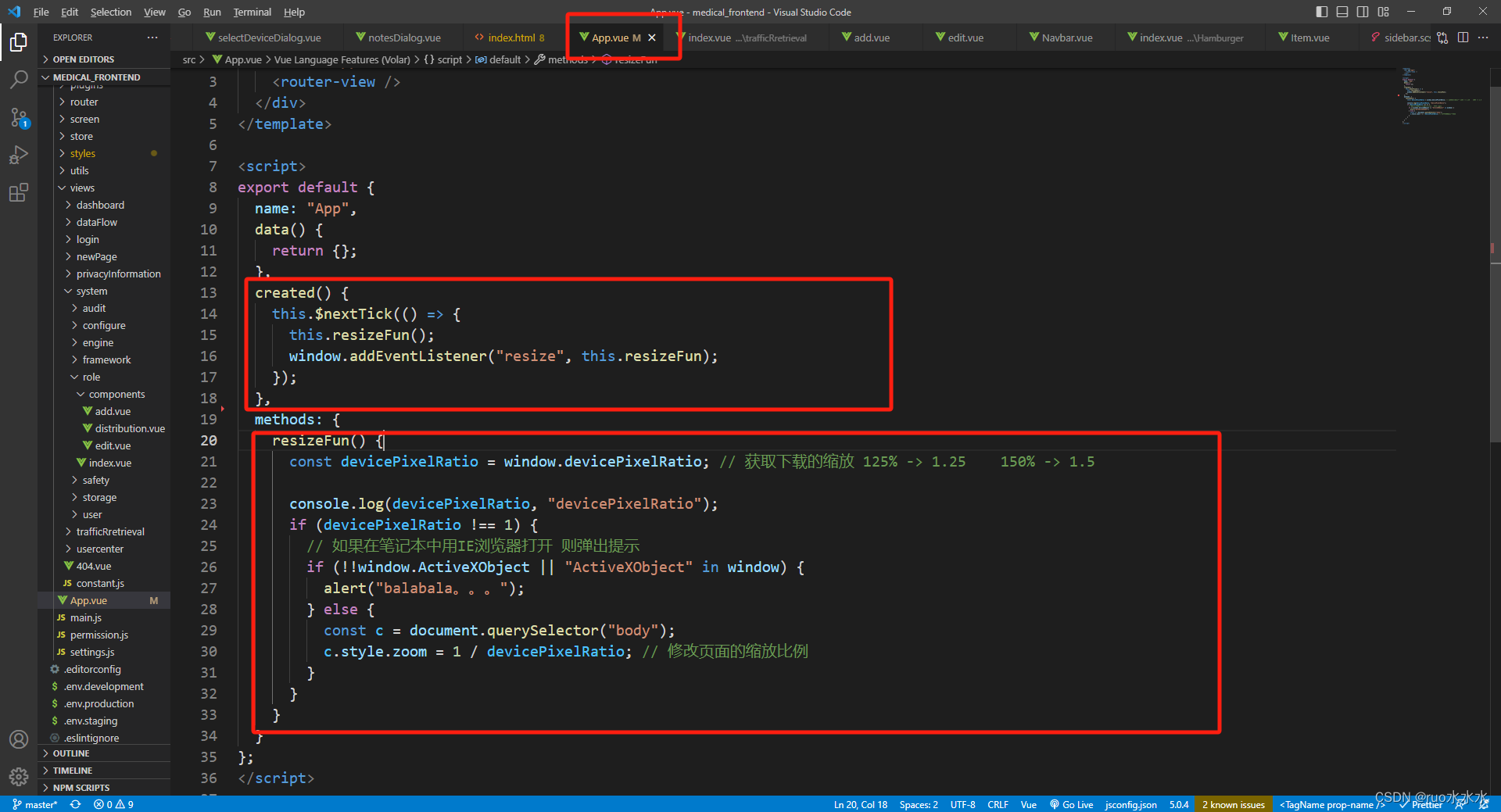
前端适配笔记本缩放125%,150%导致页面错乱问题
由于前端在开发时使用的都是标准ui设计图,基本都是按照所以1920*1080, 而小屏幕笔记本由于分辨率高,所以导致的显示元素变小,因此很多笔记本的默认显示都是放大125%或者150%。 如果页面比较简单就让多余的空白单边扩展,…...

多线程的学习中篇下
volatile 关键字 volatile 能保证内存可见性 volatile 修饰的变量, 能够保证 “内存可见性” 示例代码: 运行结果: 当输入1(1是非O)的时候,但是t1这个线程并沿有结束循环, 同时可以看到,t2这个线程已经执行完了,而t1线程还在继续循环. 这个情况,就叫做内存可见性问题 ~~ 这…...

贪心算法-拼接字符串使得字典顺序最小问题
题目1 给定一个由字符串组成的数组strs,必须把所有字符串拼接起来,返回所有可能的拼接结果中,字典序最小的结果 思路:对数组排序,排序规则是对ab和ba的字符串进行比较大小,返回较小的顺序放到数组中最后将…...

Linux--互斥锁
一、与互斥锁相关api **互斥量(mutex)**从本质上来说是一把锁。在访问共享资源前对互斥量进行加锁,在访问完成后释放互斥量。对互斥量进行枷锁后,任何其他试图再次对互斥量加锁的线程将会被阻塞直到当前线程释放该互斥锁。如果释…...

[2023.09.21]:源码已上传,供大家了解Rust Yew的前后端开发
这个资源是Rust的源代码压缩包,供大家了解Rust Yew的前后端开发。 资源中的代码非常简洁易懂,虽然离商用场景还有一段距离,但是涵盖了前端的组件搭建、事件通信和反向代理,以及后端的Restful API的路由、功能实现和数据库访问。此…...

时序分解 | Matlab实现CEEMD互补集合经验模态分解时间序列信号分解
时序分解 | Matlab实现CEEMD互补集合经验模态分解时间序列信号分解 目录 时序分解 | Matlab实现CEEMD互补集合经验模态分解时间序列信号分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现CEEMD互补集合经验模态分解时间序列信号分解 1.分解效果图 ࿰…...

AI伦理实战:从偏见、可解释性到隐私保护的工程化解决方案
1. 项目概述:当AI从实验室走向现实,我们面临什么?几年前,我还在实验室里为一个模型的准确率提升0.5个百分点而兴奋不已。那时,“伦理”这个词,对我们这些埋头调参的工程师来说,似乎还停留在哲学…...

从CANdb++到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换
从CANdb到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换 在汽车电子和嵌入式系统开发中,DBC文件作为CAN总线通信的"字典",承载着整车网络通信的核心协议。对于刚接触汽车网络通信的工程师来说,面对DBC文件中密…...
)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列) 在电机控制、电源管理等工业应用中,硬件级的保护机制往往比软件响应更加可靠。STM32F4系列的高级定时器TIM1提供的互补PWM输出与刹车功能,正是为…...

Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践 对于有稳定大模型调用需求的开发者或团队而言࿰…...

PEX8796实战解析:从芯片特性到PCIe扩展设计的关键考量
1. PEX8796芯片基础认知与核心特性 第一次拿到PEX8796这颗PCIe交换芯片时,我盯着密密麻麻的引脚图发了半小时呆。作为PLX(现已被博通收购)的经典产品,这颗芯片在工业控制、服务器扩展等领域已经默默服役了十余年。实测中发现&…...

DDrawCompat:让经典DirectX游戏在Windows 11重获新生的技术桥梁
DDrawCompat:让经典DirectX游戏在Windows 11重获新生的技术桥梁 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/…...

开源量化分析平台Fin-Maestro:十大核心模块构建个人交易决策系统
1. 项目概述:一个为独立交易者打造的量化分析工具箱 如果你和我一样,在股票和加密货币市场里摸爬滚打了好些年,那你一定经历过这样的阶段:面对海量的K线图、财务数据和市场新闻,感觉信息过载,决策时总是犹…...

Arm编译器嵌入式C/C++库架构与优化实践
1. Arm编译器嵌入式C/C库核心架构解析在嵌入式系统开发中,Arm编译器提供的C/C库是实现高效、可靠应用的基础设施。这些库函数针对Arm架构进行了深度优化,特别是在内存管理、信号处理和浮点运算等关键功能上。让我们先来看看这个库的核心架构设计。Arm编译…...

从零搭建知识图谱:我是如何用Neo4j和neosemantics处理Wikidata RDF数据的
从零搭建知识图谱:我是如何用Neo4j和neosemantics处理Wikidata RDF数据的 第一次接触Wikidata的RDF数据时,我被它庞大的规模和复杂的结构震撼到了。作为一个长期从事数据科学工作的研究者,我深知将这些半结构化数据转化为可操作的知识图谱需要…...

全球化技术团队协作:跨越文化差异的沟通与管理实践
1. 从“理所当然”到“文化自觉”:全球化职场的思维转型在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年,我参与过跨国项目,也带过分布在全球各地的团队。一个深刻的体会是,我们这些搞技术的࿰…...