缓冲技术在嵌入式中的应用
引言
在嵌入式中,不可避免地会遇到数据的收发。
其实,数据的收发有很多情况。
总体上,分为数据的收和发:
其中,数据发送是一个主动的行为,我们对要发送数据的数量特点等都是知道的,比如我们通过串口发送数据,这时候,使用常规发送方式,或者结合使用DMA都是可以的;
相较而言,数据的接收就会麻烦一些,因为接收数据,对于用户来说是一个被动响应的行为。接收数据也有很多种情况:
1、接收定长数据;
2、接收不定长数据;
3、接收的数据是随机到来的,比如串口屏的触摸发送键值到下位机,这种情况下,触摸行为是没有任何规律的,数据之间发送的间隔一般也比较长;
4、一直不断地接收大量数据,比如单片机需要一直接收串口数据;
5、接收数据后透传出去;
6、接收数据保存起来,等待上层应用访问;
以上几种情况分别如何处理呢?
以串口为例:
首先,不管是哪种情况,只要是底层接收数据,就一定要使用缓冲技术,为什么呢?
这是因为底层数据接收的速度很快,而我们处理数据的速度没那么快,如果只是简单的一两个语句来处理,比如给变量赋个值,做个简单的判断,没什么问题,如果语句多了,比如printf,也有可能来不及处理,关于这点可以参考这篇文章:
基于串口的BLE模组CC2640R2使用总结_路溪非溪的博客-CSDN博客
那么,这些情况的缓冲有何区别呢?
1、接受定长数据相对简单,使用普通串口接收或者DMA都可以;
2、接收不定长数据,就需要使用串口中断+空闲中断或者DMA+空闲中断,仍然参考:
基于串口的BLE模组CC2640R2使用总结_路溪非溪的博客-CSDN博客
3、接收数据随机到来,因为数据接收没那么快,一次可能只接受一两帧数据,所以不需要太大的缓冲区;具体参考:F103串口和DMA配合使用总结_路溪非溪的博客-CSDN博客
4、这个情况就需要相对大一些的缓冲区,因为数据来得比较快,可能还来不及处理就被覆盖了,具体参考这篇文章:F103串口和DMA配合使用总结_路溪非溪的博客-CSDN博客
5、接收数据后透传出去,这个基本都是底层的传输,所以接收缓冲后,就可以发出去,这个参考:基于串口的BLE模组CC2640R2使用总结_路溪非溪的博客-CSDN博客
6、接收数据保存起来供上层使用,这里就有个问题,底层接收数据保存起来,上层处理速度没那么快,就需要考虑一些问题,缓冲区设置多大合适呢?多久处理一次呢?
以上提到的就是缓冲区的用法,用来解决快速的数据接收和慢速的数据处理之间不匹配的问题,具体看这张图就能理解了:
其实,这里比较麻烦的也是比较常见的情况就是上面几种情况的综合:
接受不定长数据+不断接收数据帧+保存起来供上层使用。
具体参考:F103串口和DMA配合使用总结_路溪非溪的博客-CSDN博客
串口空闲中断+DMA可以解决前两个问题,再就是接收的数据需要放在一个缓冲区里面,上层应用需要时就来拿这个数据。

考虑这种场景:
电路中有连续的电压,单片机通过AD采样数据,注意,这时候连续的数据就被离散化了,只要采样率满足采样定理,就能无失真地还原出原有信号的样子。
假如我们要采的是正弦信号的RMS值,那么就是个恒定的直流量,其中有一些波动是很正常的事情。此时,数据接收后缓存起来,缓存一些数据后做个均值滤波等等处理,然后得到一个比较稳定的值,再将这个值存在一个变量中,此时,这个变量其实刷新的速率也是很快的。到这里,其实是底层的事情。
现在,我上层需要将这些数据拿来显示在屏幕上,如果来一个数据我们就显示一个数据,那么,就强迫上层跟着下层的速度,首先跟不跟得上不说,上层这么快显示数据没有什么必要,增加数据发送的负担不说,我们人眼也识别不过来,如果底层1s刷新1000个点,那我1秒去拿10个数据来显示也可以,也就是在定时器中,每隔100ms去拿一个数据,最好调整下这个间隔以适配我们人眼的观察视觉,而且,如果不这样,底层有时因为其他干扰数据发送时快时慢,我们上层显示也会时快时慢,如果定时去取值显示,就不会受底层速度的干扰,从而实现了底层快速和上层慢速的隔离,各司其职,用缓冲区作为“中介”。
就像这样拿数据显示:
另外还有一点,如果我发数据给串口屏太多太频繁,可能会影响到同时发送的其他数据从而造成卡顿。
这里面有一点值得注意,就是,如果这样显示,那不就是有很多数据没有拿到?首先,这里拿的是个RMS值,理想上是个恒定值,而且本来就是满足采样定理所采集到的离散值,从连续到离散,本来也有很多数据没采到,但是不影响效果。

到底什么是缓冲技术呢?
缓冲区可以说是计算机中的一个连接站,用于连接计算机中高速、低速运行的部件。
作用:缓冲通常用于临时存储数据,以平衡不同速度的数据传输过程之间的差异。它可以用来解决数据传输速度不匹配的问题。
工作原理:缓冲区是一个存储区域,用于暂时保存数据,待数据传输速度对齐后再将数据发送出去。在数据传输过程中,如果数据接收速度较快,数据会被存储在缓冲区中。
数据处理: 缓冲区通常不会对数据进行处理或修改,它只是临时存储数据的容器。
可以参考这个总结:
缓冲是两种不同速度设备之间的传输信息时平滑传输过程的常用手段。
引入缓冲技术的原因:
1、 为了进一步缓和CPU和I/O设备之间速度不匹配的矛盾。
2、 提高CPU与I/O设备之间的并行性。
3、 为了减少中断次数和CPU的中断处理时间。如果没有缓冲,慢速I/O设备每传一个字节就要产生一个中断,CPU必须处理该中断。如果用了缓冲技术,则慢速的I/O设备将缓冲区填满时,才向CPU发出中断,从而减少了中断次数和CPU的中断处理时间。
4、 为了解决DMA或通道方式下数据传输的瓶颈问题。DMA或通道方式都适用于成批数据传输,在无缓冲的情况下,慢速I/O设备只能一个字节一个字节的传输信息,这造成DMA方式或通道方式数据传输的瓶颈。缓冲区的设置适应了DMA或通道方式的成批数据传输方式,解决了数据传输的瓶颈问题。
这里顺便提一下,另外还有个概念叫缓存,注意区分:
作用: 缓存用于存储已经计算过或获取过的数据,以便在后续访问时能够更快地获取数据,从而提高系统的响应速度。
工作原理: 缓存会将经常访问的数据复制到更快的存储介质中,如内存,以便在后续访问时无需再从原始数据源获取。这样能够减少数据访问时间,提高性能。
数据处理:缓存中的数据通常可以根据需要进行处理,以满足特定的访问要求。例如,可以将数据库查询结果存储在缓存中,以减少数据库访问频率。
实际应用:Web浏览器使用缓存来存储已经访问过的网页,以便下次访问同一网页时能够更快地加载。
两者主要区别如下:
用途不同:缓冲主要用于平衡数据传输速度差异,而缓存主要用于提高数据访问速度。
数据处理:缓冲不对数据进行处理,只是暂时存储,而缓存可以对数据进行处理以满足特定需求。
存储介质:缓冲通常用于暂时存储数据,存储在相同或类似的介质上,而缓存通常将数据存储在更快的存储介质中,如内存。
数据类型:缓冲可以用于各种数据类型,包括传输中的数据,而缓存通常用于经常被访问的数据。
总之,缓冲和缓存在数据处理中有着不同的作用和机制,了解它们的区别有助于更好地理解在不同情况下如何使用它们来优化数据传输和访问性能。
环形缓冲区
可直接参考:
【数据结构】环形缓冲区介绍,原理讲解+代码实现。(内核__嵌入式__c语言数组)
相关文章:
缓冲技术在嵌入式中的应用
引言 在嵌入式中,不可避免地会遇到数据的收发。 其实,数据的收发有很多情况。 总体上,分为数据的收和发: 其中,数据发送是一个主动的行为,我们对要发送数据的数量特点等都是知道的,比如我们通过…...

vscode交叉编译cmake工程,toolchains设置
在 Visual Studio Code 中编译 CMake 项目时,使用自定义工具链(toolchains)可以很有用,特别是当你需要交叉编译或使用不同的编译器时。以下是在 Visual Studio Code 中使用自定义工具链的一般步骤,以aarch64的嵌入式为…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【优化算法】季节优化算法(SOA)(附MATLAB代码实现)
前言 世界上许多地方一年有四个季节:春、夏、秋、冬。每个季节的天气都不一样。随着天气的变化,生物,尤其是树木会改变它们的行为来适应天气。森林中的每一个个体都被称为一棵树。在满足终止条件之前,森林中的树木通过类似于自然界树木生命周期的四种操作:更新、竞争、播种…...
DevOps持续集成与交付
概述 Jenkins是一个支持容器化部署的、使用Java运行环境的开源软件,使用Jenkins平台可以定制化不同的流程与任务、以自动化的机制支持DevOps领域中的CI与CD,在软件开发与运维的流程中自动化地执行软件工程项目的编译、构建、打包、测试、发布以及部署&a…...
)
lambda的使用案例(1)
lambda的使用案例 1、分组转换为map Map<String, List<IdaasUserInfoVO>> map userWithOrgVOS1.stream().collect(Collectors.groupingBy(IdaasUserInfoVO::getOrgId));2、map循环 map.forEach(this::saveOrUpdateUser); private void saveOrUpdateUser(String …...
nodejs+vue装修公司CRM系统设计elementui
第3章 系统分析 5 3.1 需求分析 5 3.2 系统可行性分析 5 3.2.1技术可行性:技术背景 5 3.2.2经济可行性 6 3.2.3操作可行性: 6 3.3 项目设计目标与原则 6 3.4系统流程分析 7 3.4.1操作流程 7 3.4.2添加信息流程 8 3.4.3删除信息流程 9 第4章 系统设计 11 …...
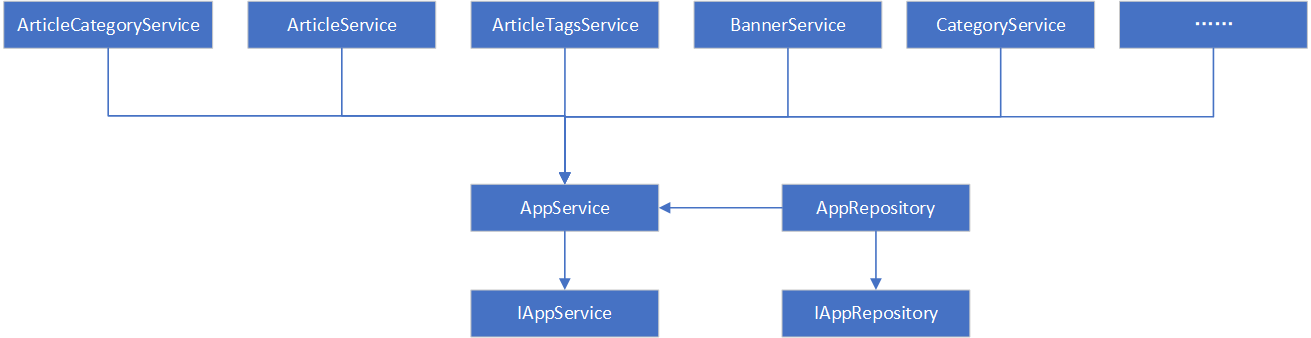
开源博客项目Blog .NET Core源码学习(3:数据库操作方式)
开源博客项目Blog采用SqlSugar模块连接并操作数据库,本文学习并记录项目中使用SqlSugar的方式和方法。 首先,数据库连接信息放在了App.Hosting项目的appsettings.json中DbConfig节,支持在DbConfig节配置多个数据库连接信息,以…...

QT--Opencv下报错Mat/imwrite/imread找不到文件
像file not found这类错误 原因是编程系统找不到所指库文件,以此为例,排查自己的每个位置是否有误 1. .pro文件 添加opencv动态库 INCLUDEPATH /usr/include \/usr/include/opencv4 \/usr/include/opencv4/opencv2LIBS /usr/lib/aarch64-linux-gnu…...
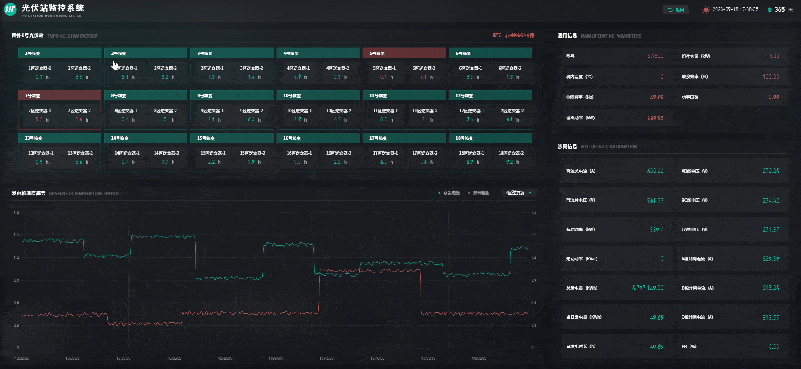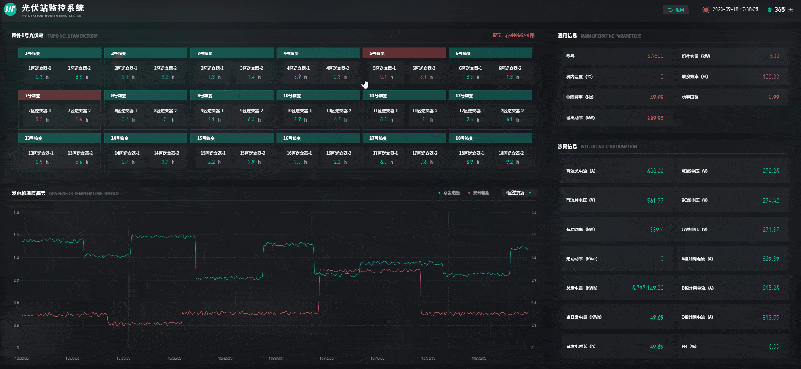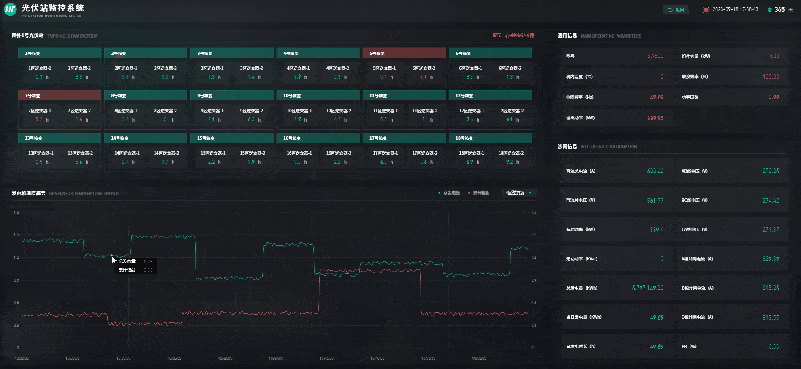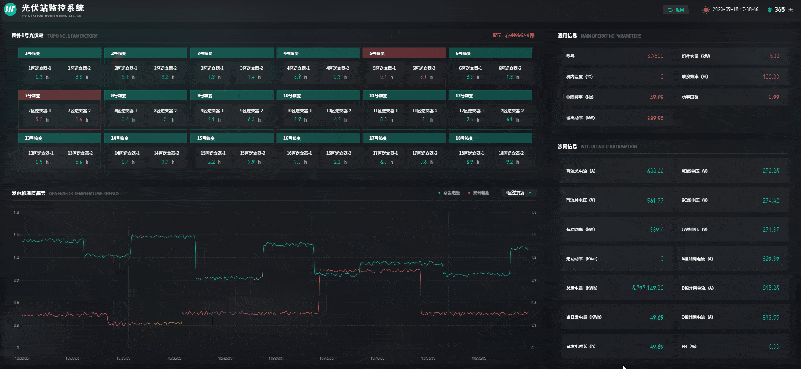
风光储一体化能源中心 | 数字孪生智慧能源
自“双碳”目标提出以来,我国能源产业不断朝着清洁低碳化、绿色化的方向发展。其中,风能、太阳能等可再生能源在促进全球能源可持续发展、共建清洁美丽世界中被寄予厚望。风能、太阳能具有波动性、间歇性、随机性等特点,主要通过转化为电能再…...
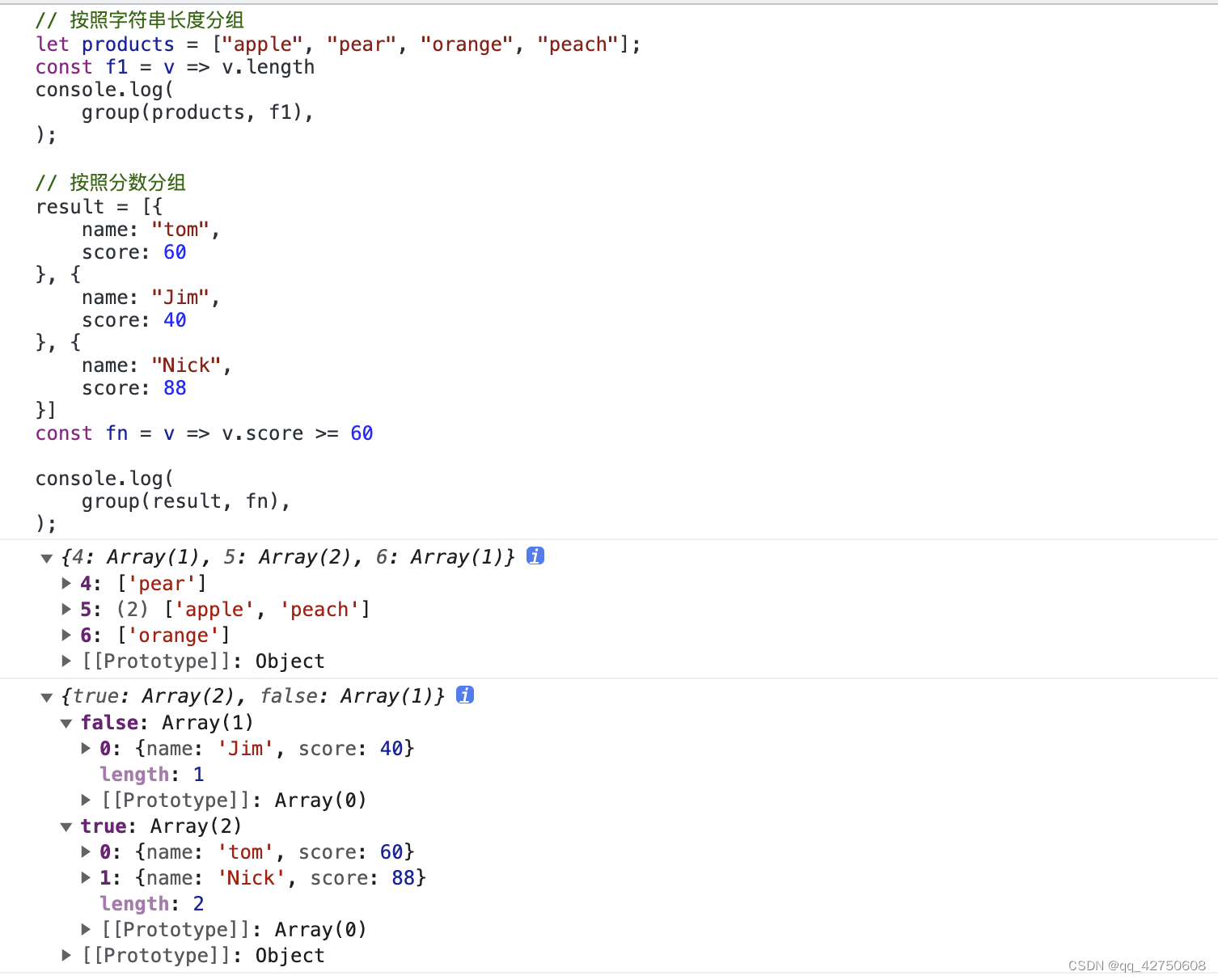
JavaScript数组分组
数组分组: 含义: 数据按照某个特性归类 1. reducefn(cur, index)作为对象的key,值为按照fn筛选出来的数据 // 利用reduce分组 function group(arr, fn) {// 不是数组if (!Array.isArray(arr)) {return arr}// 不是函数if (typeof fn ! function) {throw new TypeError(fn…...
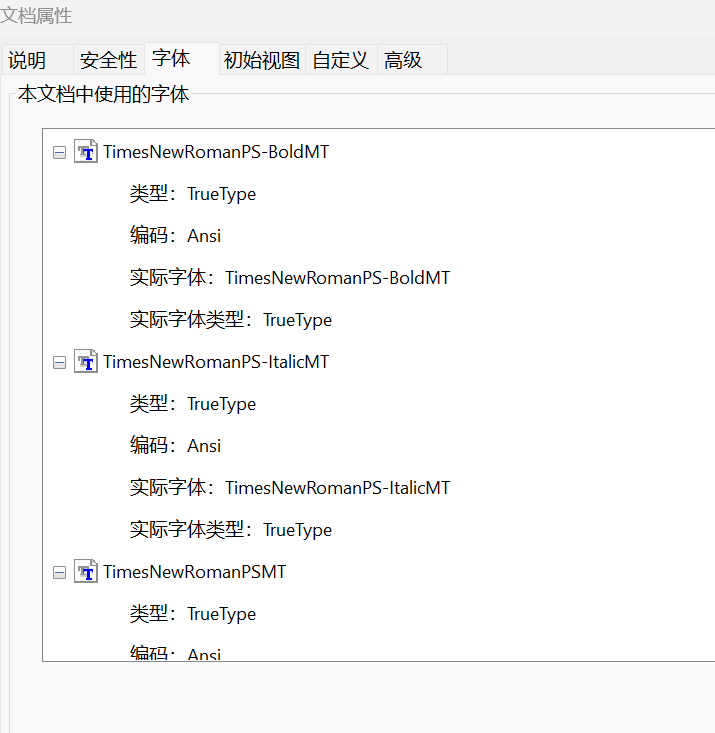
IEEE PDF eXpress系统报错:TimesNewRoman PS-BoldMT, ItalicMT, PSM
问题: IEEE PDF eXpress系统报错:Errors: Font TimesNewRomanPS-BoldMT, TimesNewRomanPS-ItalicMT, TimesNewRomanPSMT is not embedded (137x on pages 2-6) 答案: 主要原因是PDF的字体嵌入问题,可以看到下图中没有报错中的字体…...
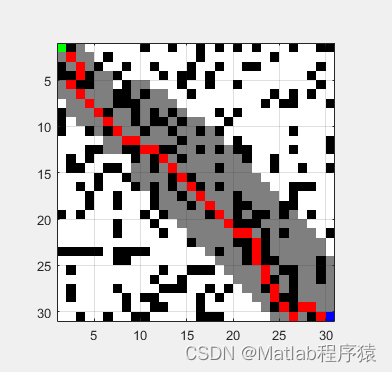
【MATLAB源码-第40期】基于matlab的D*(Dstar)算法栅格路径规划仿真。
1、算法描述 D*算法路径规划 D*算法(Dynamic A*)是A*算法的一种变种,主要用于在地图中的障碍物信息发生变化时重新计算路径,而不需要从头开始。该算法适用于那些只有部分信息已知的环境中。 工作原理: 1. D*算法首先…...
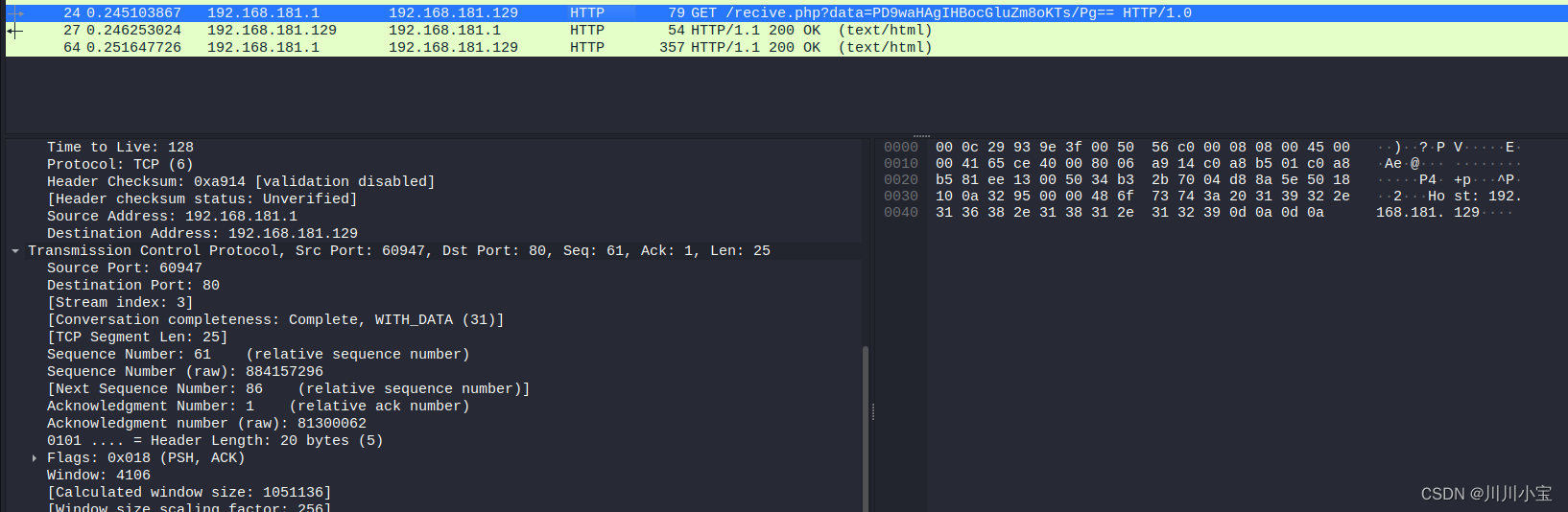
Pikachu-xxe (xml外部实体注入漏洞)过关笔记
Pikachu-xxe过关笔记 有回显探测是否有回显file:///协议查看本地系统文件php://协议查看php源代码(无法查看当前网页代码,只能看别的)http://协议爆破开放端口(两者的加载时间不同) 无回显第一步第二步第三步 运行结果…...
Unity实现设计模式——责任链模式
Unity实现设计模式——责任链模式 责任链模式定义:将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。 在职责链模式中&…...
Java中String转换为double类型
这次的java作业是写一个数字转换的小项目,其中从输入框中获取的是String类型,但是要进行数字操作,此时要用到很多操作String类型数据的方法了。 从javafx输入框中获取到String类型后,首先是要判断是否能转换为数字或者小数形式&a…...

不同埋深地下管线的地质雷达响应特征分析
不同埋深地下管线的地质雷达响应特征分析 前言 以混凝土管线为例,建立了不同埋深(70cm、100cm、130cm)地下管线的二维模型,进行二维地质雷达正演模拟,分析不同材质管线的地质雷达响应特征。 文章目录 不同埋深地下管…...
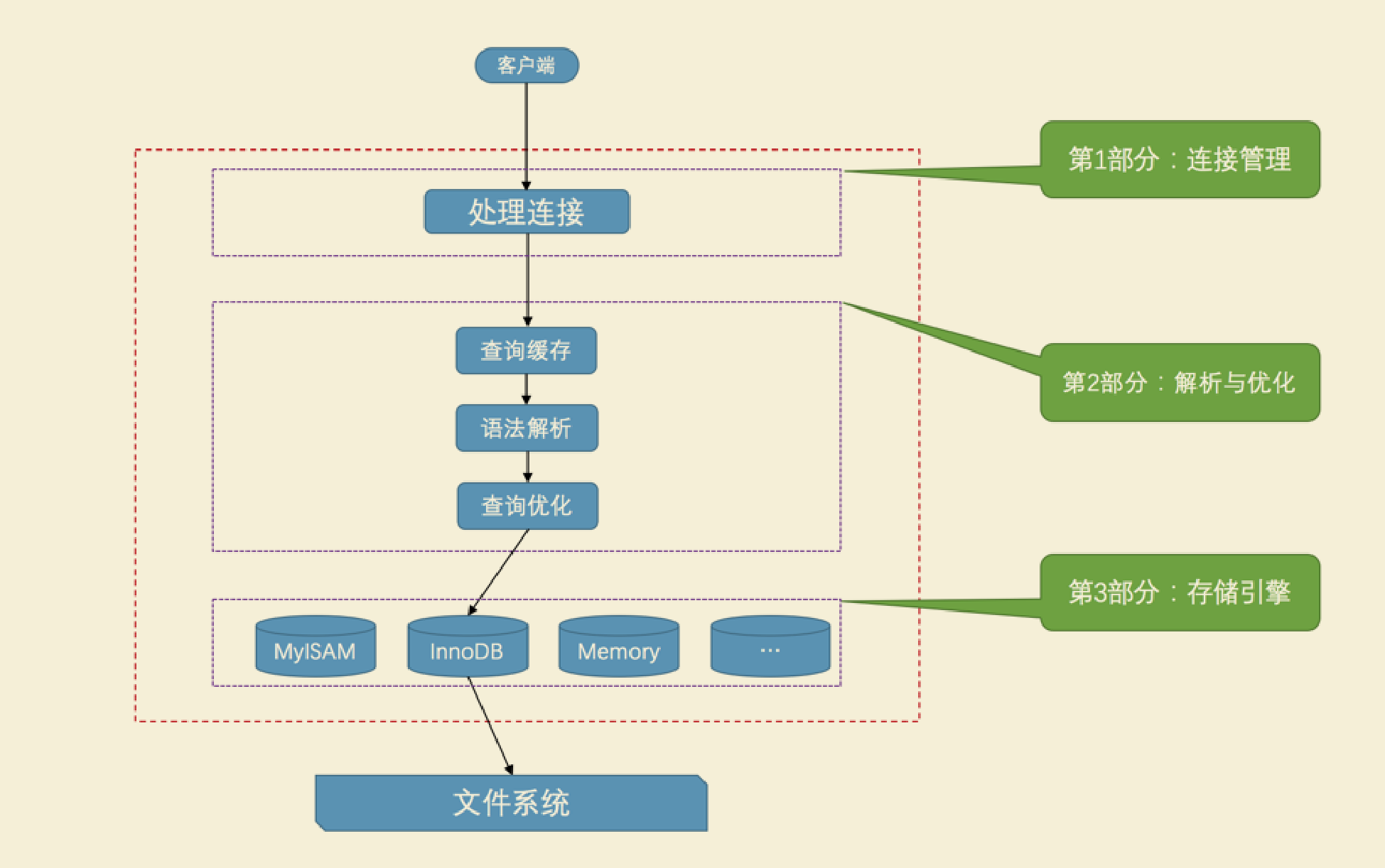
重新认识mysql
title: “重新认识mysql” createTime: 2022-03-06T15:52:4108:00 updateTime: 2022-03-06T15:52:4108:00 draft: false author: “ggball” tags: [“mysql”] categories: [“db”] description: “” 文章目录 title: "重新认识mysql" createTime: 2022-03-06T15:…...
系统集成|第十九章(笔记)
目录 第十九章 风险管理19.1 风险管理的概述及相关概念19.2 主要过程19.2.1 规划风险管理19.2.2 识别风险19.2.3 实施定性风险分析19.2.4 实施定量风险分析19.2.5 规划风险应对19.2.6 控制风险 上篇:第十八章、安全管理 下篇:第二十章、收尾管理 第十九…...

【Linux】Linux远程访问Windows下的MySQL数据库
1.建立Windows防火墙规则 首先需要开放windows防火墙,针对3306端口单独创建一条规则,允许访问。 打开windows安全中心防火墙与保护,点击高级设置 进入之后,点击入站规则,新建一条规则 新建端口入站规则 端口填写330…...

android安卓core tombstone .pb
Tombstone原理分析_内核工匠的博客-CSDN博客 android tombstone分析_tombstone 分析_良知犹存的博客-CSDN博客 Tombstone简介 当一个native程序开始执行时,系统会注册一些连接到debuggerd的signal handlers。针对进程出现的不同的异常状态,Linux kernel…...
)
手把手教你用Gstreamer和V4L2在Zynq MPSoC上搭建视频流Pipeline(HDMI IN to DP OUT)
从HDMI到DP:Zynq MPSoC视频流处理全链路实战指南 当你的Zynq MPSoC开发板已经完成硬件设计,Petalinux系统也顺利启动,却发现HDMI输入的视频信号无法正确显示在DP接口的显示器上——这种"最后一公里"的集成问题往往最令人抓狂。本文…...

写论文软件哪个好?2026 实测:真文献 + 实证图表 + 全流程,虎贲等考 AI 才是毕业论文通关王
每到毕业季,“写论文软件哪个好” 就成为本硕生最纠结的问题。市面上工具看似繁多,却大多藏着隐患:通用 AI 编造文献、无实证支撑;小众工具功能碎片化、格式混乱;传统软件效率低、无智能辅助…… 选错软件,…...

微通道液冷散热:六类强化结构深度解析
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 💌公众号:莱歌数字(B站同名) 📱个人微信:yanshanYH 211、985硕士,从业16年 从…...

ESLyric-LyricsSource:Foobar2000高级逐字歌词同步解决方案技术指南
ESLyric-LyricsSource:Foobar2000高级逐字歌词同步解决方案技术指南 【免费下载链接】ESLyric-LyricsSource Advanced lyrics source for ESLyric in foobar2000 项目地址: https://gitcode.com/gh_mirrors/es/ESLyric-LyricsSource ESLyric-LyricsSource 是…...

从零到一:联想小新Air14 2020锐龙版Windows 10重装实战指南
1. 为什么需要重装系统? 最近有不少朋友跟我吐槽,说用了两年的联想小新Air14 2020锐龙版越来越卡,开机要等半天,打开个文档都要转圈圈。这种情况我太熟悉了,作为一个帮朋友修过不下20台同款机型的老司机,我…...

XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析
XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-…...

CANN/asc-devkit单核形状API文档
SetSingleShape 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode…...

FanControl终极指南:如何5分钟掌控Windows电脑风扇噪音与散热
FanControl终极指南:如何5分钟掌控Windows电脑风扇噪音与散热 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

别再只会用传统插值了!深入浅出图解DuDoNet双域网络,如何同时修复Sinogram和CT图像
双域网络革命:从DuDoNet到DuDoNet的医学影像伪影消除实战 医学影像领域长期被金属伪影问题困扰——当患者体内存在金属植入物时,CT扫描图像会出现辐射状条纹和带状阴影,严重影响诊断准确性。传统解决方案如同用创可贴处理内伤:图像…...

AI-Trader 智能交易效果全景展示
在交易的世界里,最让人焦虑的往往不是亏损本身,而是面对瞬息万变的盘面时那种“无能为力”的滞后感。很多开发者或量化爱好者都经历过这样的时刻:深夜盯着 K 线图,明明看到了突破信号,等手动敲完代码或点击鼠标时&…...