在亚马逊云科技Amazon SageMaker上部署构建聊天机器人的开源大语言模型
开源大型语言模型(LLM)已经变得流行起来,研究人员、开发人员和组织都可以使用这些模型来促进创新和实验。这促进了开源社区开展合作,从而为LLM的开发和改进做出贡献。开源LLM提供了模型架构、训练过程和训练数据的透明度,使研究人员能够了解模型的工作原理,识别潜在的偏见并解决伦理问题。这些开源LLM通过向广大用户提供先进的自然语言处理(NLP)技术来构建任务关键型业务应用程序,从而使生成式人工智能大众化。GPT-NeoX、LLaMA、Alpaca、GPT4All、Vicuna、Dolly和OpenAssistant是一些受欢迎的开源LLM。
OpenChatKit是用于构建通用和专用聊天机器人应用程序的开源LLM,由Together Computer于2023年3月发布,采用Apache-2.0许可。这种模型允许开发人员对聊天机器人的行为进行更多控制,并根据聊天机器人的特定应用进行定制。OpenChatKit提供了一套工具、基础机器人和构建块,用于构建完全定制的、功能强大的聊天机器人。关键组件如下:
-
经过指令调优的LLM,针对来自EleutherAI的GPT-NeX-20B的聊天进行了微调,有超过4300万条关于100%负碳计算的指令。GPT-NeoXT-Chat-Base-20B模型基于EleutherAI的GPT-NeoX模型,并根据对话式交互的数据进行了微调。
-
自定义配方,可对模型进行微调以实现任务的高精度。
-
可扩展的检索系统,使您能够在推理时使用来自文档存储库、API或其他实时更新信息源的信息来增强机器人响应。
-
根据GPT-JT-6B微调的审核模型,旨在筛选机器人会回答哪些问题。
深度学习模型的规模和大小不断扩大,给在生成式人工智能应用中成功部署这些模型带来了障碍。为了满足低延迟和高吞吐量的要求,采用模型并行化和量化等复杂方法变得至关重要。由于缺乏对这些方法的熟练应用,许多用户在为生成式人工智能使用案例启动大型模型托管时遇到了困难。
在这篇文章中,亚马逊云科技将展示如何使用DJL Serving以及DeepSpeed和Hugging Face Accelerate等开源模型并行库,在亚马逊云科技Amazon SageMaker上部署OpenChatKit模型。使用DJL Serving,这是一种高性能的通用模型服务解决方案,由与编程语言无关的Deep Java Library(DJL)提供支持。我们将演示Hugging Face Accelerate库如何简化大型模型在多个GPU中的部署,从而减轻以分布式方式运行LLM的负担。
可扩展的检索系统
可扩展的检索系统是OpenChatKit的关键组件之一。该组件使您能够根据封闭的领域知识库定制机器人的响应。尽管LLM能够在模型参数中保留事实知识,并且在微调后可以在下游NLP任务中取得不俗的表现,但这种模型准确获取和预测封闭领域知识的能力仍然受到限制。因此,当遇到知识密集型任务时,这种模型的性能就会比任务特定架构的性能差。可以使用OpenChatKit检索系统,从外部知识来源(例如Wikipedia、文档存储库、API和其他信息源)中扩充回复中的知识。
检索系统使聊天机器人能够通过获取与特定查询相关的详细信息来获取当前信息,从而为模型生成答案提供必要的上下文。为了说明该检索系统的功能,亚马逊云科技提供了对Wikipedia文章索引的支持,并提供了示例代码,演示如何调用Web搜索API进行信息检索。按照提供的文档,您可以在推理过程中将检索系统与任何数据集或API集成,这样聊天机器人就能在回复中纳入动态更新的数据。
审核模型
审核模型在聊天机器人应用中非常重要,可用于执行内容筛选、质量控制、用户安全以及法律和合规原因。审核是一项非常困难的主观任务,在很大程度上取决于聊天机器人应用的领域。OpenChatKit提供的工具可用于控制聊天机器人应用程序,并监控输入文本提示是否有任何不当内容。审核模型提供了一个很好的基准,可以根据各种需求进行调整和定制。
OpenChatKit有一个60亿个参数的审核模型,即GPT-JT-Moderation-6B,可对聊天机器人进行控制,将输入限制在受控制的主题范围内。虽然模型本身内置了一些控制功能,但TogetherComputer还是使用Ontocord.ai的OIG-moderation数据集训练了一个GPT-JT-Moderation-6B模型。该模型与主聊天机器人同时运行,以检查用户输入和机器人回答是否包含不恰当的结果。您还可以使用该模型来检测向聊天机器人提出的任何域外问题,并在问题不属于聊天机器人的领域时进行覆盖。

可扩展检索系统使用案例
虽然可以在各行各业应用这种技术来构建生成式人工智能应用程序,但在本篇文章中,将讨论金融行业的使用案例。检索式增强生成功能可用于金融研究,自动生成有关特定公司、行业或金融产品的研究报告。通过从内部知识库、财务档案、新闻报道和研究论文中检索相关信息,您可以生成综合报告,总结重要洞察、财务指标、市场趋势和投资建议。您可以使用此解决方案来监控和分析财经新闻、市场情绪和趋势。
解决方案概览
使用OpenChatKit模型构建聊天机器人并将这种模型部署到SageMaker上的步骤如下:
-
下载聊天基础模型GPT-NeoXT-Chat-Base-20B,并将模型构件打包上传到Amazon Simple Storage Service(Amazon S3)。
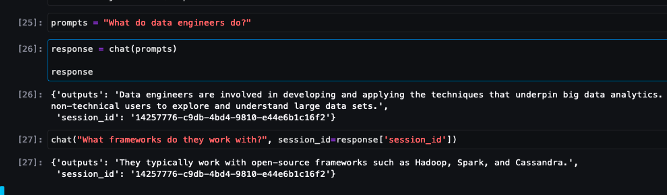
-
使用SageMaker大型模型推理(LMI)容器,配置属性,并设置自定义推理代码来部署该模型。
-
配置模型并行技术,并在DJL Serving属性中使用推理优化库。我们将使用Hugging Face Accelerate作为DJL Serving的引擎。此外,我们还定义了张量并行配置来对模型进行分区。
-
创建SageMaker模型和端点配置,然后部署SageMaker端点。
您可以通过在GitHub存储库中运行笔记本来继续操作。
下载OpenChatKit模型
首先,下载OpenChatKit基础模型。使用huggingface_hub,并使用snapshot_download下载模型,这将下载给定版本的整个存储库。同时进行下载,以便加快进度。
DJL Serving属性
可以使用SageMaker LMI容器托管带有自定义推理代码的大型生成式人工智能模型,而无需提供自己的推理代码。在没有对输入数据进行自定义预处理或对模型预测进行后处理的情况下,这种方法非常有用。您也可以使用自定义推理代码部署模型。在这篇文章中,亚马逊云科技将演示如何使用自定义推理代码部署OpenChatKit模型。
SageMaker要求模型构件采用tar格式。使用以下文件创建每个OpenChatKit模型:serving.properties和model.py。
serving.properties配置文件向DJL Serving指明了要使用哪些模型并行化和推理优化库。其中包含以下参数:
-
engine——DJL要使用的引擎。
-
option.entryPoint——Python文件或模块的入口点。这应该与使用的引擎一致。
-
option.s3url——将此参数设置为包含模型的S3存储桶的URI。
-
option.modelid——如果想从huggingface.co下载模型,可以将option.modelid设置为一个预训练模型的模型ID,该模型托管在huggingface.co上的模型存储库中。容器使用此模型ID在huggingface.co上下载相应的模型存储库。
-
option.tensor_parallel_degree——将此参数设置为DeepSpeed需要对模型进行分区的GPU设备数量。该参数还可以控制DJL Serving运行时每个模型启动的Worker数量。例如,如果我们有一台配备8个GPU的计算机,并创建八个分区,那么每个模型将有一个Worker来处理请求。有必要调整并行度,并确定给定模型架构和硬件平台的最佳值。亚马逊云科技将这种能力称为推理适应并行性。
OpenChatKit模型
OpenChatKit基础模型实现包含以下四个文件:
model.py——此文件实现了OpenChatKit GPT-NeoX主模型的处理逻辑。此文件接收推理输入请求,加载模型,加载Wikipedia索引,并提供响应。model.py使用以下关键类:
-
OpenChatKitService——此类处理GPT-NeoX模型、Faiss搜索和对话对象之间的数据传递。WikipediaIndex和Conversation对象经过初始化,输入的聊天会话被发送到索引,以便从Wikipedia中搜索相关内容。如果没有提供用于在Amazon DynamoDB中存储提示信息的ID,此类还会为每次调用生成唯一ID。
-
ChatModel——此类加载模型和tokenizer并生成响应。此类使用tensor_parallel_degree处理多个GPU之间的模型分区,并配置dtypes和device_map。提示信息将传递给模型以生成响应。为生成操作配置了停止标准StopWordsCriteria,以便在推理时只生成机器人响应。
-
ModerationModel——在ModerationModel类中使用两种审核模型:输入模型,用于向聊天模型表明输入不适合覆盖推理结果;输出模型,用于覆盖推理结果。使用以下可能的标签对输入提示和输出响应进行分类:
-
随意
-
需要谨慎
-
需要干预(这被标记为由模型控制)
-
可能需要谨慎
-
也许需要谨慎
wikipedia_prepare.py——此文件用于下载和准备Wikipedia索引。在此案例中,亚马逊云科技使用Hugging Face数据集上提供的Wikipedia索引。要在Wikipedia文档中搜索相关文本,需要从Hugging Face下载索引,因为其他地方没有打包索引。wikipedia_prepare.py文件负责在导入时处理下载。在运行推理的多个进程中,只有一个进程可以克隆存储库。其余的则要等到文件出现在本地文件系统中。
wikipedia.py——此文件用于在Wikipedia索引中搜索与上下文相关的文档。输入查询经过标记化处理,并使用mean_pooling创建嵌入内容。亚马逊云科技计算查询嵌入与Wikipedia索引之间的余弦相似度距离指标,以检索与上下文相关的Wikipedia句子。
conversation.py——此文件用于在DynamoDB中存储和检索对话线程,以便传递给模型和用户。conversation.py改编自开源OpenChatKit存储库。此文件负责定义存储人类和模型之间对话轮次的对象。这样,模型就能为对话保留一个会话,让用户可以参考以前的信息。由于SageMaker端点调用是无状态的,因此需要将此对话存储在端点实例外部的位置。启动时,如果DynamoDB表不存在,实例会创建该表。然后,会根据端点生成的session_id键将对话的所有更新存储在DynamoDB中。任何带有会话ID的调用都将检索关联的对话字符串,并根据需要进行更新。
使用自定义依赖项构建LMI推理容器
索引搜索使用Facebook的Faiss库进行相似性搜索。由于基本LMI映像中不包含该库,因此需要调整容器以安装该库。以下代码定义了一个Dockerfile,用于从源代码中安装Faiss以及机器人端点所需的其他库。使用sm-docker实用程序从Amazon SageMaker Studio构建映像,并将映像推送到Amazon Elastic Container Registry(Amazon ECR)。
DJL容器没有安装Conda,因此需要从源代码克隆和编译Faiss。要安装Faiss,需要安装使用BLAS API和Python支持的依赖项。安装这些软件包后,Faiss配置为使用AVX2和CUDA,然后再使用安装的Python扩展进行编译。
之后会安装pandas、fastparquet、boto3和git-lfs,因为下载和读取索引文件时需要它们。
创建模型
现在在AmazonECR中有了Docker映像,可以继续为OpenChatKit模型创建SageMaker模型对象。使用GPT-JT-Moderation-6B部署GPT-NeoXT-Chat-Base-20B输入和输出审核模型。
配置端点
接下来,亚马逊云科技为OpenChatKit模型定义端点配置。使用ml.g5.12xlarge实例类型部署模型。
部署端点
最后,使用在前面步骤中定义的模型和端点配置创建端点。
从OpenChatKit模型运行推理
现在是向模型发送推理请求并获取响应的时候了。我们传递输入文本提示和模型参数,例如temperature、top_k和max_new_tokens。聊天机器人响应的质量取决于指定的参数,因此建议根据这些参数对模型性能进行基准测试,以找到适合您使用案例的最佳设置。输入提示首先发送到输入审核模型,然后将输出发送到ChatModel以生成响应。在这一步中,模型使用Wikipedia索引检索与模型上下文相关的部分,以此作为从模型获取特定领域响应的提示。最后,将模型响应发送到输出审核模型以检查分类情况,然后返回响应。
清理
按照清理部分中的说明删除作为本文一部分预置的资源,以避免不必要的费用。
总结
在这篇文章中,讨论了开源LLM的重要性,以及如何在SageMaker上部署OpenChatKit模型来构建新一代聊天机器人应用程序。亚马逊云科技讨论了OpenChatKit模型的各种组件、审核模型,以及如何使用Wikipedia等外部知识源进行检索式增强生成(RAG,Retrieval Augmented Generation)工作流程。可以在GitHub notebook中找到分步说明。
相关文章:
在亚马逊云科技Amazon SageMaker上部署构建聊天机器人的开源大语言模型
开源大型语言模型(LLM)已经变得流行起来,研究人员、开发人员和组织都可以使用这些模型来促进创新和实验。这促进了开源社区开展合作,从而为LLM的开发和改进做出贡献。开源LLM提供了模型架构、训练过程和训练数据的透明度ÿ…...

【51单片机】10-蜂鸣器
1.蜂鸣器的原理 这里的“源”不是指电源。而是指震荡源。 也就是说,有源蜂鸣器内部带震荡源,所以只要一通电就会叫。 而无源内部不带震荡源,所以如果用直流信号无法令其鸣叫。必须用2K~5K的方波去驱动它。 有源蜂鸣器往往比无源的贵ÿ…...

26377-2010 逆反射测量仪 知识梳理
声明 本文是学习GB-T 26377-2010 逆反射测量仪. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了逆反射测量仪的术语和定义、结构与分类、技术要求、计量学特性、试验方法、检验规 则以及标志、包装、运输与贮存。 本标准适用于…...
css实现渐变电量效果柱状图
我们通常的做法就是用echarts来实现 比如 echarts象形柱图实现电量效果柱状图 接着我们实现进阶版,增加渐变效果 echarts分割柱形图实现渐变电量效果柱状图 接着是又在渐变的基础上,增加了背景色块的填充 echarts实现渐变电量效果柱状图 其实思路是一…...
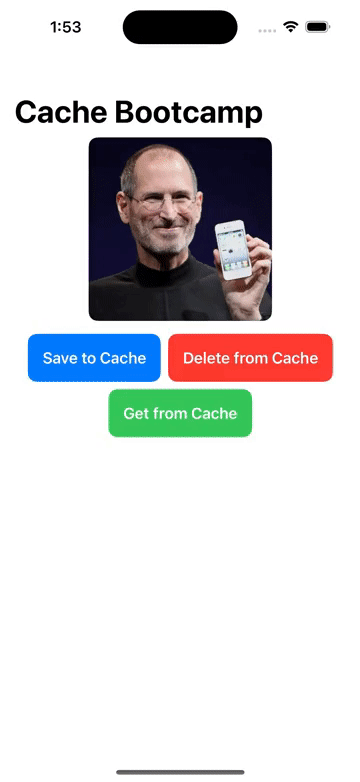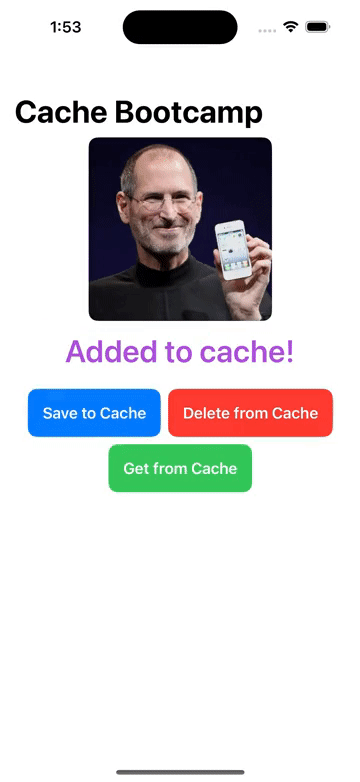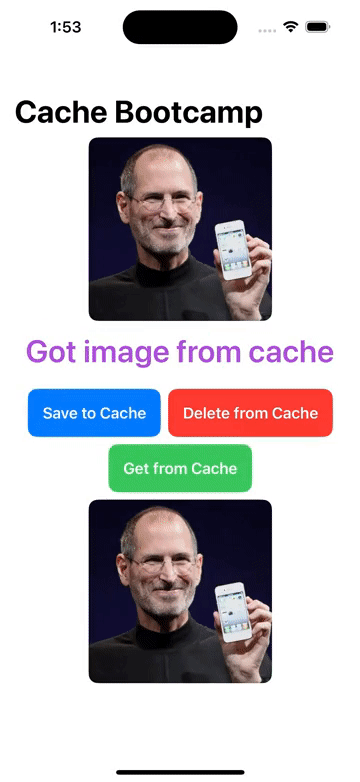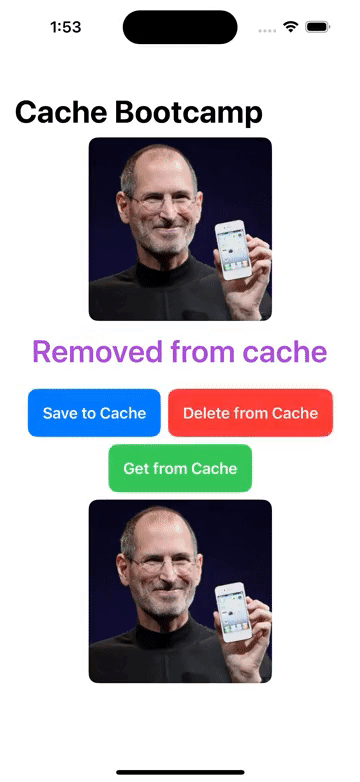
FileManager/本地文件增删改查, Cache/图像缓存处理 的操作
1. FileManager 本地文件管理器,增删改查文件 1.1 实现 // 本地文件管理器 class LocalFileManager{// 单例模式static let instance LocalFileManager()let folderName "MyApp_Images"init() {createFolderIfNeeded()}// 创建特定应用的文件夹func cr…...

vue中使用富文本编辑器
vue中使用富文本编辑器(wangEditor) wangEditor官网地址:https://www.wangeditor.com/ 使用示例 <template><div class"app-container"><div class"box"><div class"editor-tool">&l…...
13.(开发工具篇github)如何在GitHub上上传本地项目
一:创建GitHub账户并安装Git 二:创建一个新的仓库(repository) 三、拉取代码 git clone https://github.com/ainier-max/myboot.git git clone git@github.com:ainier-max/myboot.git四、拷贝代码到拉取后的工程 五、上传代码 (1)添加所有文件到暂存...

vue3中状态适配
写一个函数,在函数中定义一个对象 用于存放键值对,最后返回指定状态所对应的的值,即对象[指定状态] 的 对象的值。 在模板中把状态传入 // vue3 setup语法糖中 const formatXXXState (xxxState)>{const stateMap {键1: 值1,键2: 值2,.…...
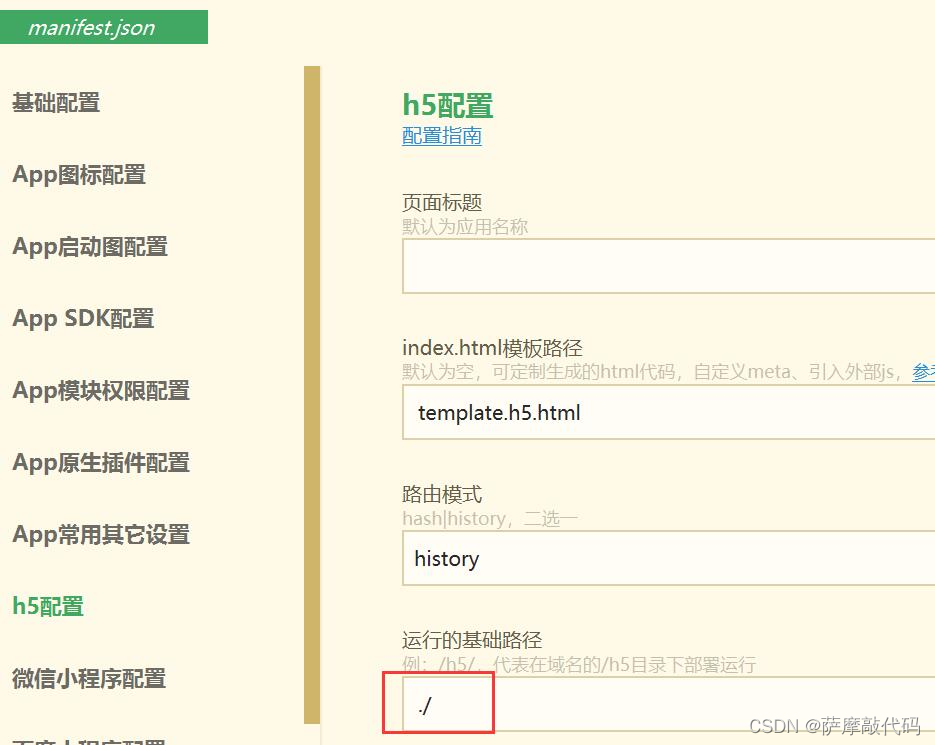
uniapp h5 端 router.base设置history后仍有#号
manifest.json文件设置: "h5": { "router": { "base": "./", "mode": "history" }, }按相对路径发行时路由模式强制为hash模式,不支持history模式(两者相悖)…...

上网行为监管软件(上网行为管理软件通常具有哪些功能)
在我们的日常生活中,互联网已经成为了我们获取信息、交流思想、进行工作和娱乐的重要平台。然而,随着互联网的普及和使用,网络安全问题也日益突出,尤其是个人隐私保护和网络行为的规范。在这个背景下,上网行为审计软件…...

C#中的for和foreach的探究与学习
一:语句及表示方法 for语句: for(初始表达式;条件表达式;增量表达式) {循环体 }foreach语句: foreach(数据类型 变量 in 数组或集合) {循环体 }理解 1.从程序逻辑上理解,foreach是通过指针偏移实现的(最初在-1位置,每循环一次,指针就便宜一个单位),而for循环是通...
【ES6知识】Promise 对象
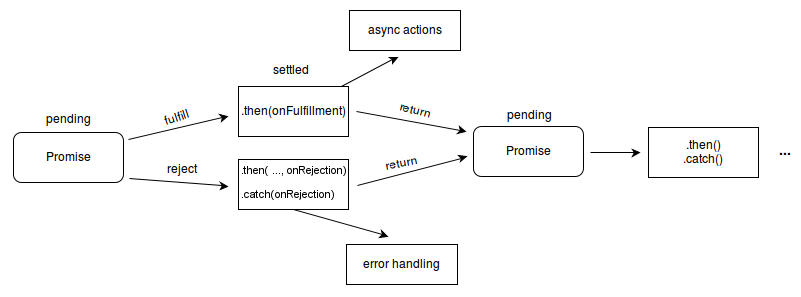
文章目录 1.1 概述1.2 静态方法1.3 实例方法1.4 Promise 拒绝事件 1.1 概述 Promise 对象用于表示一个异步操作的最终完成(或失败)及其结果值。是异步编程的一种解决方案(可以解决回调地狱问题)。 一个 Promise 对象代表一个在这…...

【Git】配置SSH密钥实现Git操作免密
背景 在使用Git推送代码的时候,会默认需要输入密码。如果经常推送代码,那就需要经常输入密码,比较繁琐。所以Git也提供了免密登录的功能。 Git本身支持两种协议对远程Git仓库进行访问:HTTPS、SSH。两种方式有一定的区别…...

AI能给百融云带来什么?
一大堆有关ChatGPT的利好消息出现之后,市场的反应难得的跟投资者预期站在了一起,AIGC也终于有了跑赢CPO的苗头。二级市场的逻辑不用重复,毕竟AI已经炒了大半年,但有没有发现一个问题?就是在不知不觉中,AI应…...
AI创作系统ChatGPT商业运营版源码+AI绘画/支持GPT联网提问/支持Midjourney绘画+Prompt应用+支持国内AI提问模型
一、AI创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧&am…...

vue.draggable拖拽,项目中三个表格互相拖拽的实例操作,前端分页等更多小技巧~
vue.draggable中文文档 - itxst.com官网在这里,感兴趣的小伙伴可以看看。 NPM或yarn安装方式 yarn add vuedraggable npm i -S vuedraggable UMD浏览器直接引用JS方式 <script src"https://www.itxst.com/package/vue/vue.min.js"></script&…...

400G DR4 QSFP-DD光模块:数据中心应用全攻略
在当今数字化时代,对于企业和供应商来说,高速数据传输至关重要。随着对更快数据传输的需求不断攀升,400G DR4 QSFP-DD光模块已经成为高速网络的最新解决方案。本文将全面介绍400G DR4 QSFP-DD光模块在数据中心应用中的优势和技术规范。 什么…...

自动驾驶:路径规划概述
自动驾驶:路径规划概述 全局路径规划Dijkstra算法A*算法RRT(随机快速探索树)算法PRM(概率路线图)算法 局部路径规划DWA(动态窗口法)算法TEB(时间弹性带)算法Lattice Plan…...
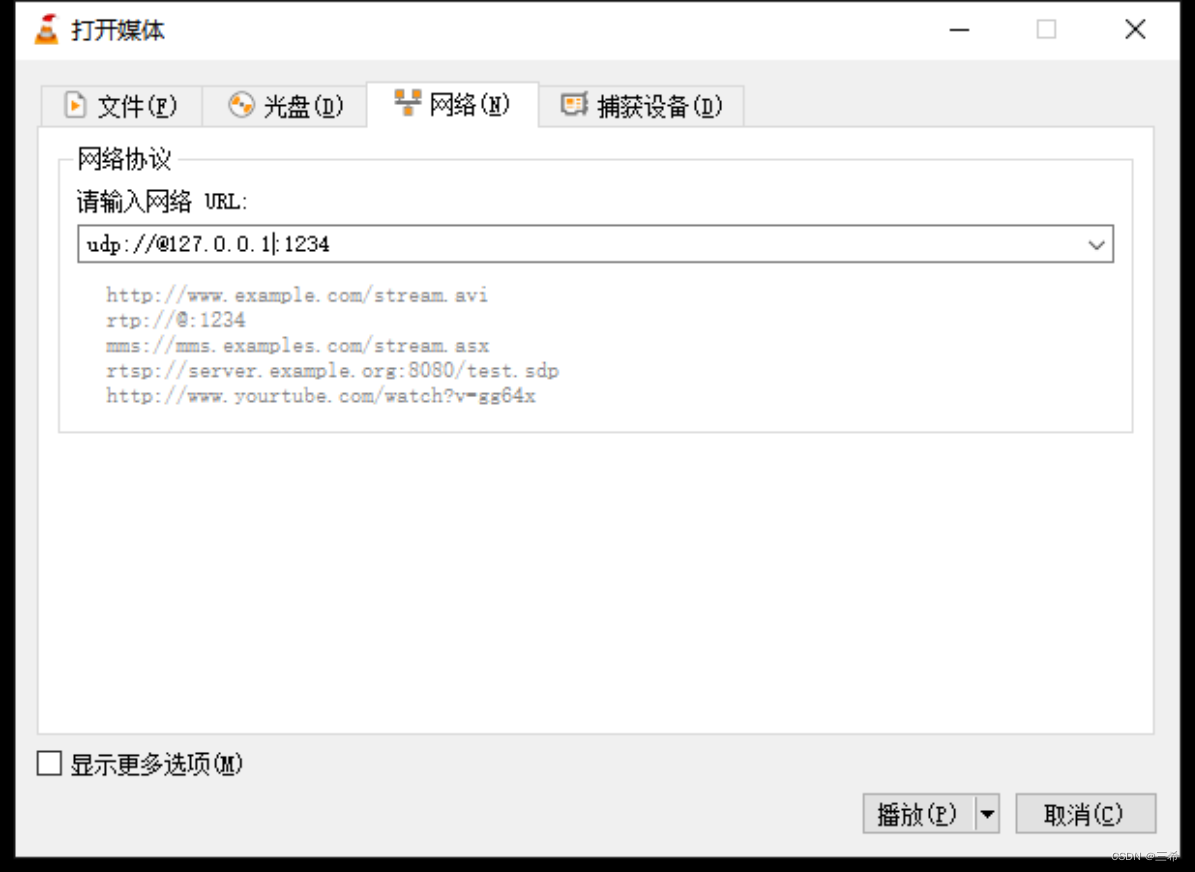
vlc将本地文件推流成ts实时流
推流 打开vlc ,打开 媒体----打开网络串流 选择文件选项卡,打开本地文件 点击添加,选择本地的mp3文件 选择串流 点击下拉框,选择udp,点击右边的【添加】按钮 输入媒体流输出地址,点击【下一个】 选择正确的…...
C# 自定义控件库之Lable组合控件
1、创建类库 2、在类库中添加用户控件(Window窗体) 3、控件视图 4、后台代码 namespace UILib {public partial class DeviceInfoV : UserControl{public DeviceInfoV(){InitializeComponent();ParameterInitialize();}#region 初始化private void Par…...

保姆级教程:用EEGLAB搞定脑电数据预处理,从导入到ICA去伪迹全流程避坑
零基础EEGLAB脑电预处理全流程:从数据导入到ICA去伪迹实战指南 当你第一次打开EEGLAB界面,面对密密麻麻的菜单选项和看似复杂的参数设置,是否感到无从下手?作为脑电研究的第一步,数据预处理的质量直接决定后续分析的可…...
)
蓝叠模拟器抓包难题?用Proxifier+ Fiddler搞定HTTPS请求(保姆级图文教程)
蓝叠模拟器HTTPS抓包实战:Proxifier与Fiddler深度配置指南 在移动应用开发与安全测试领域,抓包分析是必不可少的技能。然而当遇到蓝叠模拟器这类特殊环境时,许多开发者发现常规的代理设置方法完全失效——因为蓝叠根本没有提供网络配置界面。…...

3种方法打造企业级Windows Syslog监控系统
3种方法打造企业级Windows Syslog监控系统 【免费下载链接】visualsyslog Syslog Server for Windows with a graphical user interface 项目地址: https://gitcode.com/gh_mirrors/vi/visualsyslog 你是否曾因网络设备日志分散而难以定位故障?当路由器、防火…...

Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南
Efficient-KAN:突破传统神经网络瓶颈的Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 深…...

Java开发者收藏必看:转型AI领域,解锁高薪职业新机遇!
本文探讨了Java开发者向AI领域转型的可行性、优势及所需知识。文章指出,Java开发者具备转型AI的独特优势,AI领域岗位需求旺盛且薪资高于Java开发。转型者需补充数学、Python等知识,并通过实践项目积累经验。掌握AI技术能显著提升个人竞争力&a…...

SDR++终极指南:如何快速掌握跨平台软件定义无线电
SDR终极指南:如何快速掌握跨平台软件定义无线电 【免费下载链接】SDRPlusPlus Cross-Platform SDR Software 项目地址: https://gitcode.com/GitHub_Trending/sd/SDRPlusPlus SDR软件定义无线电是一款开源的跨平台SDR软件,以其轻量级架构和直观界…...

WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码
WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码 【免费下载链接】WpfDesigner The WPF Designer from SharpDevelop 项目地址: https://gitcode.com/gh_mirrors/wp/WpfDesigner 还在为复杂的WPF界面设计而烦恼吗?W…...

5分钟掌握Typora插件:从文件管理小白到高效写作达人的3步法
5分钟掌握Typora插件:从文件管理小白到高效写作达人的3步法 【免费下载链接】typora_plugin Typora plugin. Feature enhancement tool | Typora 插件,功能增强工具 项目地址: https://gitcode.com/gh_mirrors/ty/typora_plugin 你是否曾在Typora…...

CTFshow F5杯 逆向与隐写实战解析 超详细
1. CTFshow F5杯逆向与隐写技术全景解析 去年参加F5杯时,我对着那道LSB隐写题折腾到凌晨三点。当终于从图片噪点中提取出flag那一刻,突然理解了什么叫做"数字世界的考古学"。逆向工程和隐写术就像侦探破案,需要同时具备技术功底和发…...

当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身
当大模型认不出一个具体名字:MiniMax 回答失灵,问题未必只在模型本身 围绕“为什么 MiniMax 大模型无法识别马嘉祺是谁”的一次能力拆解:真正暴露的,往往是知识覆盖、检索策略与风控边界的耦合问题 直接回答 先给结论。 如果 Mi…...