【数据仓库设计基础(二)】维度数据模型
文章目录
- 一. 概述
- 二. 维度数据模型建模过程
- 三. 维度规范化
- 四. 维度数据模型的特点
- 五. 维度数据模型
- 1. 星型模式
- 1.1.事实表
- 1.2.维度表
- 1.3.优点
- 1.4.缺点
- 1.5.示例
- 2. 雪花模式
- 2.1.数据规范化与存储
- 2.2.优点
- 2.3.缺点
- 2.4.示例
一. 概述
维度数据模型(Dimensional modeling, DM),是一套技术和概念的集合,用于数据仓库设计。不同于关系数据模型,维度模型不一定要引入关系数据库。
根据数据仓库大师Kimball的观点,维度模型是一种支持最终用户(ing)对数据仓库进行查询的设计技术,是围绕性能和易理解性构建的。
尽管关系模型对于事务处理系统表现非常出色,但它并不是面向最终用户的。
事实与维度的概念
事实和维度是两个维度模型中的核心概念。
- 事实表示对业务数据的度量,而维度是观察数据的角度。
- 事实通常是数字类型的,可以进行聚合和计算,而维度通常是一组层次关系或描述信息,用来定义事实。
例如,销售金额是一个事实,而销售时间、销售的产品、购买的顾客、商店等都是销售事实的维度。
维度模型按照业务流程领域即主题域建立,例如进货、销售、库存、配送等。
二. 维度数据模型建模过程
星型模型:
所谓星型模式,就是以一个事实表为中心,周围环绕着多个维度表。
一般使用下面的过程构建维度模型:
选择业务流程 —> 声明粒度 —> 确认维度 —> 确认事实
这种使用四步设计法建立维度模型的过程,有助于保证维度模型和数据仓库的可用性。
1.选择业务流程
确认哪些业务处理流程是数据仓库应该覆盖的,是维度方法的基础。因此,建模的第一个步骤是描述需要建模的业务流程。例如,需要了解和分析一个零售店的销售情况,那么与该零售店销售相关的所有业务流程都是需要关注的。
2.声明粒度
确定了业务流程后,下一步是声明维度模型的粒度。
粒度用于确定事实中表示的是什么,例如,一个零售店的顾客在购物小票上的一个购买条目。
在选择维度和事实前必须声明粒度,因为每个候选维度或事实必须与定义的粒度保持一致。
从给定的业务流程获取数据时,原始粒度是最低级别的粒度。建议从原始粒度数据开始设计,因为原始记录能够满足无法预期的用户查询。
汇总后的数据粒度对优化查询性能很重要,但这样的粒度往往不能满足对细节数据的查询需求。
不同的事实可以有不同的粒度,但同一事实中不要混用多种不同的粒度。
维度模型建立完成之后,还有可能因为获取了新的信息,而回到这步修改粒度级别。
3.确认维度
设计过程的第三步是确认模型的维度。维度的粒度必须和第二步所声明的粒度一致。
维度表是事实表的基础,也说明了事实表的数据是从哪里采集来的。
典型的维度都是名词,如日期、商店、库存等。维度表存储了某一维度的所有相关数据,例如,日期维度应该包括年、季度、月、周、日等数据。
4.确认事实
它是和系统的业务用户密切相关的。大部分事实表的度量都是数字类型的,可累加,可计算,如成本、数量、金额等。
三. 维度规范化
对维度的规范化(又叫雪花化),可以起到去除冗余属性的作用。
规范化后,一个维度会对应多个维度表。实际上,在很多情况下,维度规范化后的结构等同于一个低范式级别的关系型结构。
设计维度数据模型时,会因为如下原因而不对维度做规范化处理:
- 规范化会增加表的数量,使结构更复杂。
- 不可避免的多表连接,使查询更复杂。
- 不适合使用位图索引。
- 查询性能原因。分析型查询不适合使用第三范式:分析型查询需要聚合计算或检索很多维度值,此时第三范式的数据库会遭遇性能问题。如果需要的仅仅是操作型报表,可以使用第三范式,因为操作型系统的用户需要看到更细节的数据。
规范化的争议
总体来说,当多个维度共用某些通用的属性时,做规范化会是有益的。例如,客户和供应商都有省、市、区县、街道等地理位置的属性,此时分离出一个地区属性就比较合适,因为这减少了数据冗余。
四. 维度数据模型的特点
- 易理解
在维度模型中,信息按业务种类或维度进行分组,这会提高信息的可读性,也方便了对于数据含义的解释。关系模型中,数据被分布到多个离散的实体中,对于一个简单的业务流程,可能需要很多表联合在一起才能表示。
2. 高性能
维度模型更倾向于非规范化,因为这样可以优化查询的性能。
介绍关系模型时多次提到,规范化的实质是减少数据冗余,以优化事务处理或数据更新的性能。
- 可扩展。
维度模型是可扩展的。由于维度模型允许数据冗余,因此当向一个维度表或事实表中添加字段时,不会像关系模型那样产生巨大的影响。这种新增可以是单纯地向表中增加新的数据行而不改变表结构,也可以是在现有表上增加新的属性。
基于数据仓库的查询和应用不需要过多改变就能适应表结构的变化,老的查询和应用会继续工作而不会产生错误的结果。
但是对于规范化的关系模型,由于表之间存在复杂的依赖关系,改变表结构前一定要仔细考虑。
五. 维度数据模型
1. 星型模式
星型模式是维度模型最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。
- 星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维度表。
- 星型模式的物理模型像一颗星星的形状,中心是一个事实表,围绕在事实表周围的维度表表示星星的放射状分支,这就是星型模式这个名字的由来。
星型模式将业务流程分为事实和维度。
- 事实包含业务的度量,是定量的数据,如销售价格、销售数量、距离、速度、重量等是事实。
- 维度是对事实数据属性的描述,如日期、产品、客户、地理位置等是维度。
避免蜈蚣模式
一个含有很多维度表的星型模式有时被称为蜈蚣模式。蜈蚣模式的维度表往往只有很少的几个属性,这样可以简化对维度表的维护,但查询数据时会有更多的表连接,严重时会使模型难于使用,因此在设计中应该尽量避免蜈蚣模式。
1.1.事实表
事实表记录了特定事件的数字化考量,一般由数字值和指向维度表的外键组成。
注意:通常会把事实表的粒度级别设计得比较低,使得事实表可以记录很原始的操作型事件,但这样做的负面影响是累加大量记录可能会更耗时。
事实表有以下三种类型
● 事务事实表。记录特定事件的事实,如销售。
● 快照事实表。记录给定时间点的事实,如月底账户余额。
● 累积事实表。记录给定时间点的聚合事实,如当月的总的销售金额。
没有含义的代理键
一般需要给事实表设计一个代理键作为每行记录的唯一标识。代理键是由系统生成的主键,它不是应用数据,没有业务含义,对用户来说是透明的。
1.2.维度表
维度表的每条记录包含有大量用于描述事实数据的属性字段。
维度表可以定义各种各样的特性,以下是几种最常用的维度表:
- 时间维度表。描述星型模式中记录的事件所发生的时间,具有所需的最低级别的时间粒度。数据仓库是随时间变化的数据集合,需要记录数据的历史,因此每个数据仓库都需要一个时间维度表。
- 地理维度表。描述位置信息的数据,如国家、省份、城市、区县、邮编等。
- 产品维度表。描述产品及其属性。
- 人员维度表。描述人员相关的信息,如销售人员、市场人员、开发人员等。
- 范围维度表。描述分段数据的信息,如高级、中级、低级等。
维度表的代理键
通常给维度表设计一个单列、整型数字类型的代理键,映射业务数据中的主键。业务系统中的主键本身可能是自然键,也可能是代理键。
自然键指的是由现实世界中已经存在的属性组成的键,如身份证号就是典型的自然键。
1.3.优点
星型模式是非规范化的,在星型模式的设计开发过程中,不受应用于事务型关系数据库的范式规则的约束。
星型模式的优点如下:
- 简化查询。查询数据时,星型模式的连接逻辑比较简单,而从高度规范化的事务模型查询数据时,往往需要更多的表连接。
- 简化业务报表逻辑。与高度规范化的模式相比,由于查询更简单,因此星型模式简化了普通的业务报表(如每月报表)逻辑。
- 获得查询性能。星型模式可以提升只读报表类应用的性能。
- 快速聚合。基于星型模式的简单查询能够提高聚合操作的性能。
- 便于向立方体(?)提供数据。星型模式被广泛用于高效地建立OLAP立方体,几乎所有的OLAP系统都提供ROLAP模型(关系型OLAP),它可以直接将星型模式中的数据当作数据源,而不用单独建立立方体结构。
1.4.缺点
星型模式的主要缺点是不能保证数据完整性。
一次性地插入或更新操作可能会造成数据异常,而这种情况在规范化模型中是可以避免的。星型模式的数据装载,一般都是以高度受控的方式,用批处理或准实时过程执行的,以此来抵消数据保护方面的不足。
星型模式的另一个缺点是对于分析需求来说不够灵活。
它更偏重于为特定目的建造数据视图,因此实际上很难进行全面的数据分析。
星型模式不能自然地支持业务实体的多对多关系,需要在维度表和事实表之间建立额外的桥接表。
1.5.示例
假设有一个连锁店的销售数据仓库,记录销售相关的日期、商店和产品,其星型模式如图2-3所示。
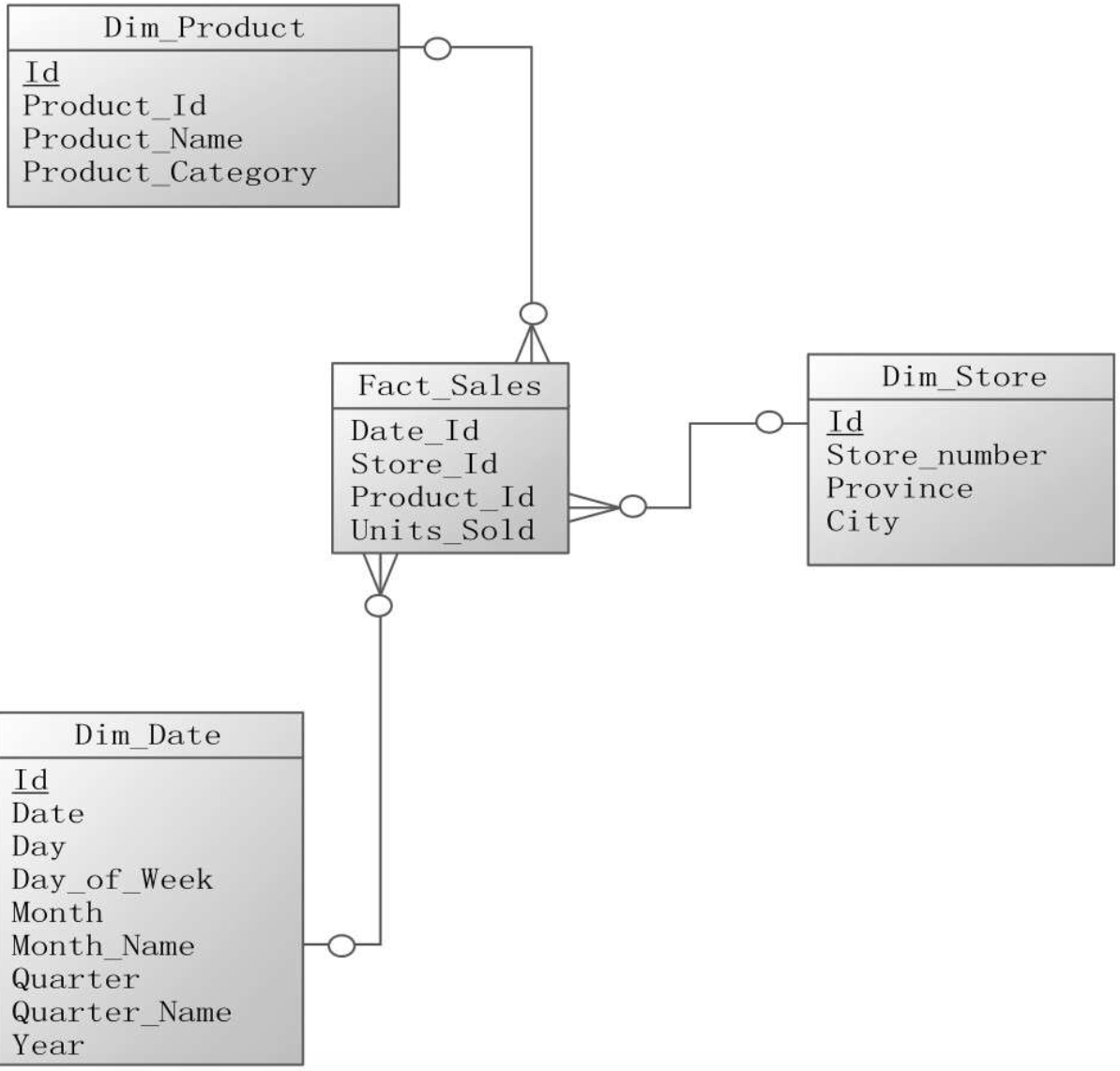
Fact_Sales是唯一的事实表,Dim_Date、Dim_Store和Dim_Product是三个维度表。
每个维度表的Id字段是它们的主键。事实表的Date_Id、Store_Id、Product_Id三个字段构成了事实表的联合主键,同时这个三个字段也是外键,分别引用对应的三个维度表的主键。
Units_Sold是事实表的唯一一个非主键列,代表销售量,是用于计算和分析的度量值。维度表的非主键列表示维度的附加属性。
查询2015年各个城市的手机销量是多少。
select s.city as city, sum(f.units_sold)from fact_sales finner join dim_date d on (f.date_id = d.id)inner join dim_store s on (f.store_id = s.id)inner join dim_product p on (f.product_id = p.id)where d.year = 2015 and p.product_category = 'mobile'group by s.city;
2. 雪花模式
与星型模式相同,雪花模式也是由事实表和维度表所组成。
所谓的“雪花化”就是将星型模式中的维度表进行规范化处理 当所有的维度表完成规范化后,就形成了以事实表为中心的雪花型结构,即雪花模式。
将维度表进行规范化的具体做法是,把低基数的属性从维度表中移除并形成单独的表。
基数指的是一个字段中不同值的个数,如主键列具有唯一值,所以有最高的基数,而像性别这样的列基数就很低。
星型模式和雪花模式都是建立维度数据仓库或数据集市的常用方式,适用于加快查询速度比高效维护数据的重要性更高的场景。这些模式中的表没有特别的规范化,一般都被设计成一个低于第三范式的级别。
2.1.数据规范化与存储
规范化的过程就是将维度表中重复的组分离成一个新表,以减少数据冗余的过程。 正因为如此,规范化不可避免地增加了表的数量。在执行查询的时候,不得不连接更多的表。但是规范化减少了存储数据的空间需求,而且提高了数据更新的效率。
一个事实
从存储空间的角度看,典型的情况是维度表比事实表小很多。这就使得雪花化的维度表相对于星型模式来说,在存储空间上的优势没那么明显了。
两种模型数据冗余举例:
- 假设在220个区县的200个商场,共有100万条销售记录。
星型模式的设计会产生1,000,200(事实表100万与维度表200个商场)条记录,每个区县信息作为商场的一个属性,显式地出现在商场维度表中。
在规范化的雪花模式中,会额外建立一个区县维度表,该表有220条记录,总的记录数是1,000,420(1,000,000+200+220)。在这种特殊情况下,星型模式所需的空间反而比雪花模式要少。
- 如果商场有10,000个,情况就不一样了,星型模式的记录数是1,010,000,雪花模式的记录数是1,010,220,从记录数上看,还是雪花模型多。但是,星型模式的商场表中会有10,000个冗余的区县属性信息,而在雪花模式中,商场表中只有10,000个区县的主键,而需要存储的区县属性信息只有220个,当区县的属性很多时,会大大减少数据存储占用的空间。
有些数据库开发者采取一种折中的方式,底层使用雪花模型,上层用表连接**建立视图(? 怎么建立)**模拟星型模式。这种方法既通过对维度的规范化节省了存储空间,同时又对用户屏蔽了查询的复杂性。但是当外部的查询条件不需要连接整个维度表时,这种方法会带来性能损失。
2.2.优点
星型模式是雪花模式的一个特例(维度没有多个层级)。某些条件下,雪花模式更具优势:
- 一些**OLAP(有哪些?)**多维数据库建模工具专为雪花模型进行了优化。
- 规范化的维度属性节省存储空间。
2.3.缺点
雪花模型的主要缺点是维度属性规范化增加了查询的连接操作和复杂度。相对于平面化的单表维度,多表连接的查询性能会有所下降。
2.4.示例
如下是星型模式规范化后的雪花模式。日期维度分解成季度、月、周、日期四个表。产品维度分解成产品分类、产品两个表。由商场维度分解出一个地区表。
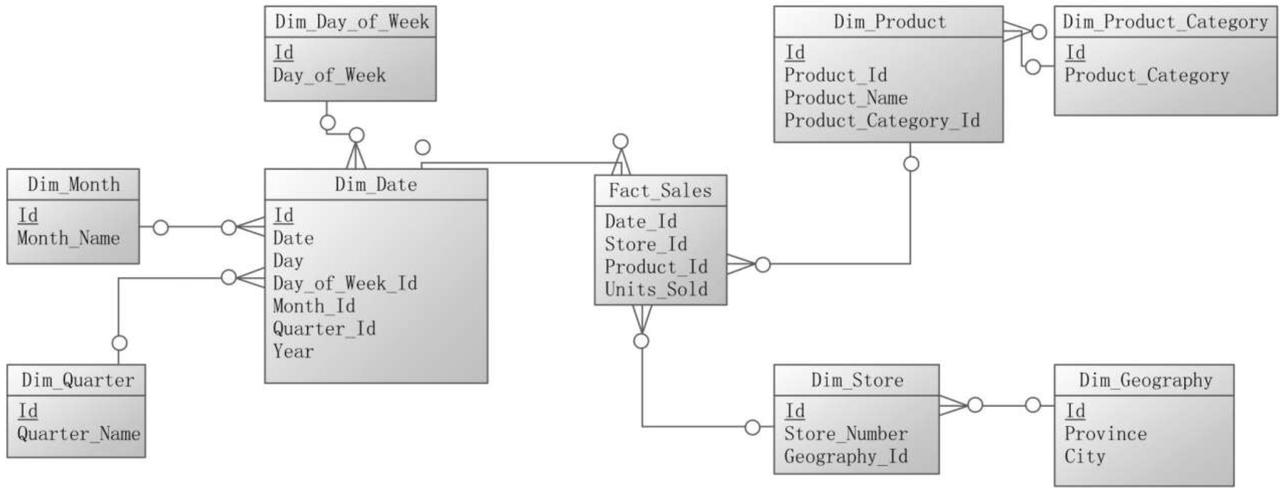
如星型模型查询效果一致的sql:
selectg.city, sum(f.units_sold)fromfact_sales finner joindim_date d onf.date_id = d.idinner joindim_store s onf.store_id = s.idinner joindim_geography g ons.geography_id = g.idinner joindim_product p onf.product_id = p.idinner joindim_product_category c onp.product_category_id = c.idwhered.year= 2015 andc.product_category = 'mobile'group byg.city;
参考:《Hadoop构建数据仓库实战》
相关文章:
【数据仓库设计基础(二)】维度数据模型
文章目录 一. 概述二. 维度数据模型建模过程三. 维度规范化四. 维度数据模型的特点五. 维度数据模型1. 星型模式1.1.事实表1.2.维度表1.3.优点1.4.缺点1.5.示例 2. 雪花模式2.1.数据规范化与存储2.2&#x…...

【数据结构】排序算法(一)—>插入排序、希尔排序、选择排序、堆排序
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.直接插入排序 2.希尔排序 3.直接选择排…...
基于JAVA+SpringBoot的新闻发布平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着科技的飞速发展和…...

Java实现word excel ppt模板渲染与导出及预览 LibreOffice jodconverter
Java Office 一、文档格式转换 文档格式转换是office操作中经常需要进行一个操作,例如将docx文档转换成pdf格式。 java在这方面有许多的操作方式,大致可以分为内部调用(无需要安装额外软件),外部调用(需…...

【通意千问】大模型GitHub开源工程学习笔记(2)
使用Transformers来使用模型 如希望使用Qwen-chat进行推理,所需要写的只是如下所示的数行代码。请确保你使用的是最新代码,并指定正确的模型名称和路径,如Qwen/Qwen-7B-Chat和Qwen/Qwen-14B-Chat 这里给出了一段代码 from transformers import AutoModelForCausalLM, Aut…...

MQ - 35 四款MQ的架构设计与实现的对比
文章目录 导图概述RabbitMQ顺序消息定时和延时消息事务消息优先级队列死信队列WebSocketRocketMQ顺序消息定时和延时消息事务消息死信队列消息查询根据 Offset 查询消息根据时间戳查询消息据消息 ID 查询消息SchemaKafka顺序消息幂等事务消息消息查询...
spring6-IOC容器
IOC容器 1、IoC容器1.1、控制反转(IoC)1.2、依赖注入1.3、IoC容器在Spring的实现 2、基于XML管理Bean2.1、搭建子模块spring6-ioc-xml2.2、实验一:获取bean①方式一:根据id获取②方式二:根据类型获取③方式三ÿ…...

macOS - 使用 chromedriver
文章目录 下载对应的 chromedriver 下载 Chrome https://www.google.com/chrome/ 查看 版本 下载对应的 chromedriver http://chromedriver.storage.googleapis.com/index.html https://chromedriver.chromium.org/downloads 移动 sudo mv chromedriver /usr/local/bin/ $ c…...
项目进展(四)-双电机均可驱动,配置模拟SPI,调平仪功能初步实现!
一、前言 截止到今天,该项目也算实现基本功能了,后续继续更新有关32位ADC芯片相关的内容,今天对驱动芯片做一个总结,也对模拟SPI做一点总结吧 二、模拟SPI 由于模拟SPI还是得有四种模式(CPOL和CPHA组合为四种),下面…...
)
《学术小白学习之路13》基于DTM和主题共现网络——实现主题时序演化网络分析(数据代码在结尾)
《学术小白学习之路13》基于DTM和主题共现网络实现主题演化网络分析 一、数据导入二、数据预处理2.1分词2.2 向量化三、DTM建模3.1 主题一致性检验3.2主题建模四、计算主题的相似度4.1获取文档主题分布4.2 时期分组4.3相似度计算4.3.1第一时期和第二时期的对比4.3.2第二时期与第…...

实验三十三、三端稳压器 LM7805 稳压性能的研究
一、题目 LM7805 输出电压、电压调整率、电流调整率以及输出纹波电压的研究。 二、仿真电路 电路如图1所示。集成稳压芯片采用 LM7805CT。 三、仿真内容 (1)测量图1(a)LM7805CT 的电压调整率,测量条件为 I O 50…...
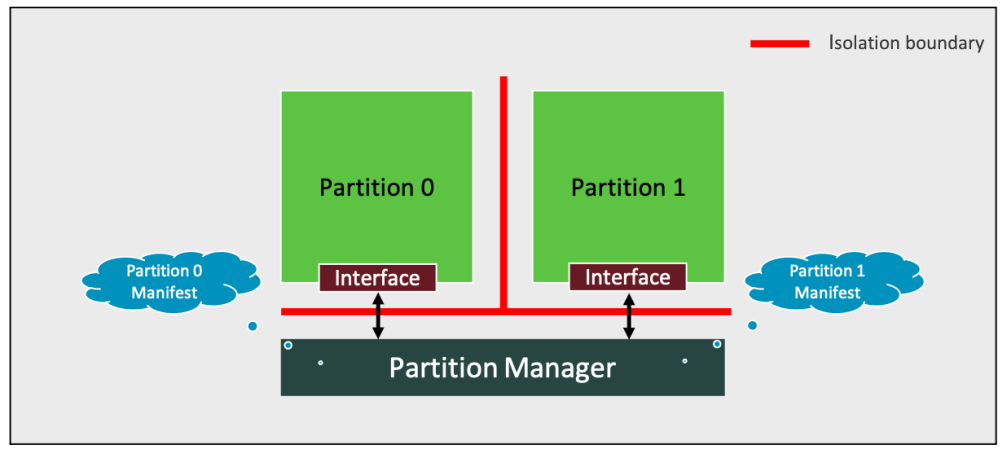
第三章 软件架构
固件框架由如下所示的构建块组成,如上图所示。 隔离边界。分区接口。分区。分区清单。分区管理器。以下各小节详细描述了这些构建块。 3.1 隔离边界 该框架定义了两种类型的隔离边界。 1、逻辑隔离边界,可用于以下情况: (1)通过一个由 IMPLEMENTATION DEFINED 机制定义…...

怎么保护苹果手机移动应用程序ipa中文件安全?
目录 前言 1. 对敏感文件进行文件名称混淆 2. 更改文件的MD5值 3. 增加不可见水印处理 3. 对html,js,css等资源进行压缩 5. 删除可执行文件中的调试信息 前言 ios应用程序存储一些图片,资源,配置信息,甚至敏感数…...

中秋节快乐
中秋节快乐,国庆节快乐...
【记录文】Android自定义Dialog实现圆角对话框
圆角的dialog还是蛮常用的,demo中正好用上了 自定义Dialog,代码中可以设置指定大小与位置 /*** author : jiangxue* date : 2023/9/25 13:21* description :圆角的矩形*/internal class RoundCornerView(context: Context,view: Int, StyleRes theme…...

架构案例2022(四十二)
促销管理系统 某电子商务公司拟升级其会员与促销管理系统,向用户提供个性化服务,提高用户的粘性。在项目立项之初,公司领导层一致认为本次升级的主要目标是提升会员管理方式的灵活性,由于当前用户规模不大,业务也相对…...

kafka 集群搭建 常用命令
1、集群搭建: <1> 将kafka 压缩包解压到某一目录 tar -zxvf kafka_2.12-3.5.1.tgz <2> 修改节点配置文件 vim config/server.properties broker.id0 log.dirs/tmp/kafka-logs <3> 将安装好的kafka 分发到其他服务器 scp -r kafka_2.12-2.4…...
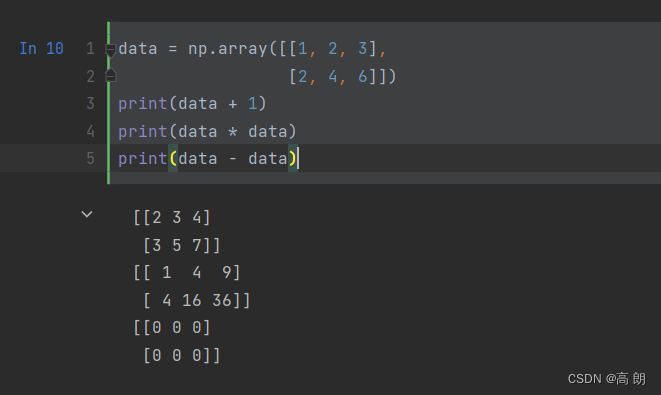
【python】numpy库
文章目录 简单介绍功能示例代码 简单介绍 NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。大多数提供科学计算的包都是用NumPy的数组作为构建基础。 NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy…...
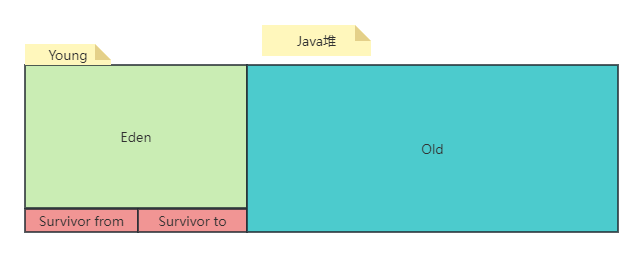
jvm垃圾收集算法
简介 由于《分代收集理论》和不同垃圾收集算法,Java堆应该被划分为不同区域,一般至少会把Java堆划分为新生代(Young Generation)和老年代(Old Generation)两个区域。 垃圾收集器可以只回收其中某一个或者…...
 白皮书)
Arm机密计算架构技术(Armv9 CCA) 白皮书
1. 概述 在本篇文章中,我们将介绍机密计算(Confidential Computing)在现代计算平台中扮演的角色,并解释机密计算的原理。然后我们将说明 Arm 机密计算架构 (Arm CCA) 如何在 Arm 计算平台中实现机密计算。 看完本文后,您将能够: 定义机密计算描述复杂的系统信任链了解R…...

从理论到实践:基于离散时间LQR的车辆运动学路径跟踪算法详解
1. 车辆路径跟踪的核心挑战 想象一下你正在玩遥控赛车游戏,手指在方向盘上微调方向,试图让车辆完美沿着赛道中心线行驶。这个看似简单的操作背后,其实隐藏着控制理论中经典的路径跟踪问题。在实际的自动驾驶或辅助驾驶系统中,工程…...

ExplorerPatcher:三分钟打造你的专属Windows界面
ExplorerPatcher:三分钟打造你的专属Windows界面 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界面感到困扰…...

从入门到精通:泉盛UV-K5/K6开源固件的无线通信革命
从入门到精通:泉盛UV-K5/K6开源固件的无线通信革命 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 想象一下,你手中的百元…...

FanControl深度解析:解锁Windows风扇控制的专业级配置哲学
FanControl深度解析:解锁Windows风扇控制的专业级配置哲学 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

5分钟掌握直播间数据抓取:Live Room Watcher终极指南
5分钟掌握直播间数据抓取:Live Room Watcher终极指南 【免费下载链接】live-room-watcher 📺 可抓取直播间 弹幕, 礼物, 点赞, 原始流地址等 项目地址: https://gitcode.com/gh_mirrors/li/live-room-watcher Live Room Watcher是一款基于Java开发…...

FastAPI新手快速入门
一、认识FastAPI1.什么是apiapi接口其实就是应用程序器对外提供操作数据的入口,这个入口可以是函数、方法或者url接口当客户端调用入口,应用程序会执行对应代码操作,完成相对应的功能(应用服务器只负责对外提供统一API,…...

开发者技能日志工具:用CLI与SQLite构建个人技术成长追踪系统
1. 项目概述:一个技能日志记录器的诞生 最近在整理自己的技术栈和项目经验时,我遇到了一个很多开发者都有的痛点:学了那么多东西,做了那么多项目,但真要写简历或者回顾成长路径时,记忆总是模糊的。今天学了…...

3个秘籍解锁百度网盘提取码:告别繁琐搜索的智能解决方案
3个秘籍解锁百度网盘提取码:告别繁琐搜索的智能解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在深夜急需下载学习资料,却被一个简单的提取码困住?或者在工作汇报前&#…...

Yeti性能优化技巧:10个方法提升威胁情报处理效率
Yeti性能优化技巧:10个方法提升威胁情报处理效率 【免费下载链接】yeti Your Everyday Threat Intelligence 项目地址: https://gitcode.com/gh_mirrors/ye/yeti Yeti是一个强大的威胁情报平台,专门为网络安全团队设计,旨在连接CTI&am…...

GoAmzAI:开源AI工具箱如何自动化内容创作与分发工作流
1. 项目概述:一个面向内容创作者的AI驱动工具集最近在和一些做内容运营和自媒体的朋友聊天,发现大家普遍面临一个痛点:内容创作的效率瓶颈。无论是写一篇深度文章、策划一个视频脚本,还是管理多个平台的账号,从灵感到最…...