Elasticsearch 集群时的内部结构是怎样的?
Apache Lucene : Flush, Commit
Elasticsearch 是一个基于 Apache Lucene 构建的搜索引擎。 它利用 Lucene 的倒排索引、查询处理和返回搜索结果等功能来执行搜索。 它还扩展了 Lucene 的功能,添加分布式处理功能以支持大型数据集的搜索。 让我们看一下 Apache Lucene 的功能,这些功能使 Elasticsearch 能够执行这些角色。
Apache Lucene: Flush
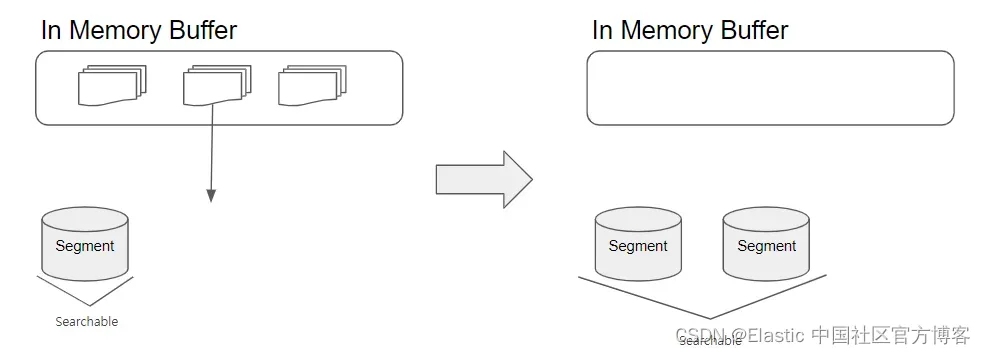
当收到文档索引请求时,Lucene 会为文档创建一个倒排索引并将其存储在内存缓冲区中。 当执行索引、更新或删除文档等操作时,Lucene 将这些更改保存在内存缓冲区中,并定期将它们刷新(flush)到磁盘。
刷新(flush)是指将索引文档从易失性内存缓冲区(例如 RAM)移动到物理段的过程。 执行刷新有以下好处:
- 改进的性能:如果索引文档存储在内存中,则每次执行搜索时都必须从内存中读取它们。 将文档刷新到磁盘可以提高搜索性能。
- 数据丢失预防:如果发生内存丢失,索引文档可能会丢失。 将文档刷新到磁盘可以防止数据丢失。
private ExternalReaderManager createReaderManager(RefreshWarmerListener externalRefreshListener) throws EngineException {boolean success = false;ElasticsearchReaderManager internalReaderManager = null;try {try {final ElasticsearchDirectoryReader directoryReader = ElasticsearchDirectoryReader.wrap(// DirectoryReader.open() !DirectoryReader.open(indexWriter),shardId);internalReaderManager = new ElasticsearchReaderManager(directoryReader);// lastCommittedSegmentInfos lastCommittedSegmentInfos = store.readLastCommittedSegmentsInfo();ExternalReaderManager externalReaderManager = new ExternalReaderManager(internalReaderManager, externalRefreshListener);success = true;return externalReaderManager;} catch (IOException e) {maybeFailEngine("start", e);try {indexWriter.rollback();} catch (IOException inner) { // iw is closed belowe.addSuppressed(inner);}throw new EngineCreationFailureException(shardId, "failed to open reader on writer", e);}} finally {if (success == false) { // release everything we created on a failureIOUtils.closeWhileHandlingException(internalReaderManager, indexWriter);}}}- DirectoryReader.open() 方法打开 DirectoryReader 来读取索引文档。 此方法检查需要刷新的段,并在必要时刷新它们。
- 代码 lastCommitedSegmentInfos = store.readLastCommissedSegmentsInfo(); 读取最后提交的段信息。 该信息用于确定哪些段需要刷新。
Apache Lucene: Commit
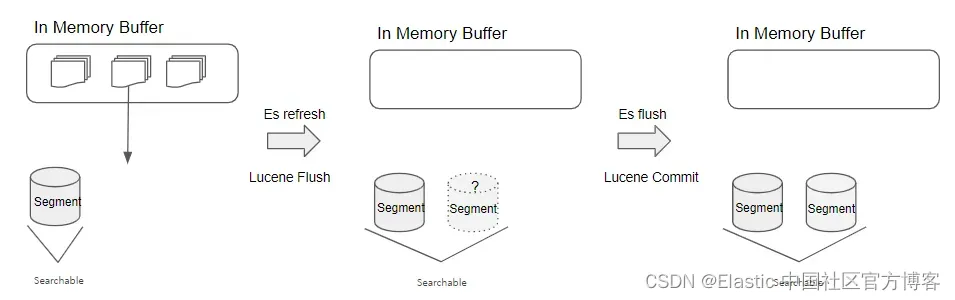
Lucene 的 flush 操作只能保证数据传输到系统的页缓存(page cache)中,但不能保证文件真正安全地写入磁盘。
因此,Lucene 会定期执行同步操作,通过 fsync 系统调用将内核系统页缓存的内容与当前写入磁盘的内容进行同步。 这个操作称为 Lucene 提交 (commit)。
什么是系统的页面缓存?
系统的页缓存是操作系统存储在内存中的数据缓存。 操作系统使用页面缓存,以便程序可以从硬盘读取数据,而不必直接访问内存。 在页面缓存中存储数据有以下好处:
- 它提高了程序性能,因为程序可以从硬盘读取数据,而无需直接访问内存。
- 它减少了磁盘读取次数,从而可以延长硬盘的使用寿命。
fsync系统调用是什么?
fsync 系统调用是用于将文件内容永久写入磁盘的系统调用。 它将文件的内容从操作系统的页面缓存复制到磁盘,然后更新磁盘上的标头(有关文件的大小、内容、格式、创建、修改日期和权限的信息)。
通过执行这些操作,Apache Lucene 确保索引文档不仅存储在操作系统的页面缓存中,而且永久存储在磁盘上,从而防止数据丢失。
更多阅读:Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南
相关文章:
Elasticsearch 集群时的内部结构是怎样的?
Apache Lucene : Flush, Commit Elasticsearch 是一个基于 Apache Lucene 构建的搜索引擎。 它利用 Lucene 的倒排索引、查询处理和返回搜索结果等功能来执行搜索。 它还扩展了 Lucene 的功能,添加分布式处理功能以支持大型数据集的搜索。 让我们看一下 Apache Luc…...

IoTDB 在国际数据库性能测试排行榜中位居第一?测试环境复现与流程详解第一弹!...
最近我们得知,Apache IoTDB 多项性能表现位居 benchANT 时序数据库排行榜(Time Series: DevOps)性能排行第一名!(榜单地址:https://benchANT.com/ranking/database-ranking) benchANT 位于德国&…...

react项目优化
随着项目体积增大,打包的文件体积会越来越大,需要优化,原因无非就是引入的第三方插件比较大导致,下面我们先介绍如何分析各个文件占用体积的大小。 1.webpack-bundle-analyzer插件 如果是webpack作为打包工具的项目可以使用&…...

青藏高原1-km分辨率生态环境质量变化数据集(2000-2020)
青藏高原平均海拔4000米以上,人口1300万,是亚洲九大河流的源头,为超过15亿人口提供淡水、食物和其他生态系统服务,被誉为地球第三极和亚洲水塔。然而,在该地区的人与自然的关系的研究是有限的,尤其是在精细…...
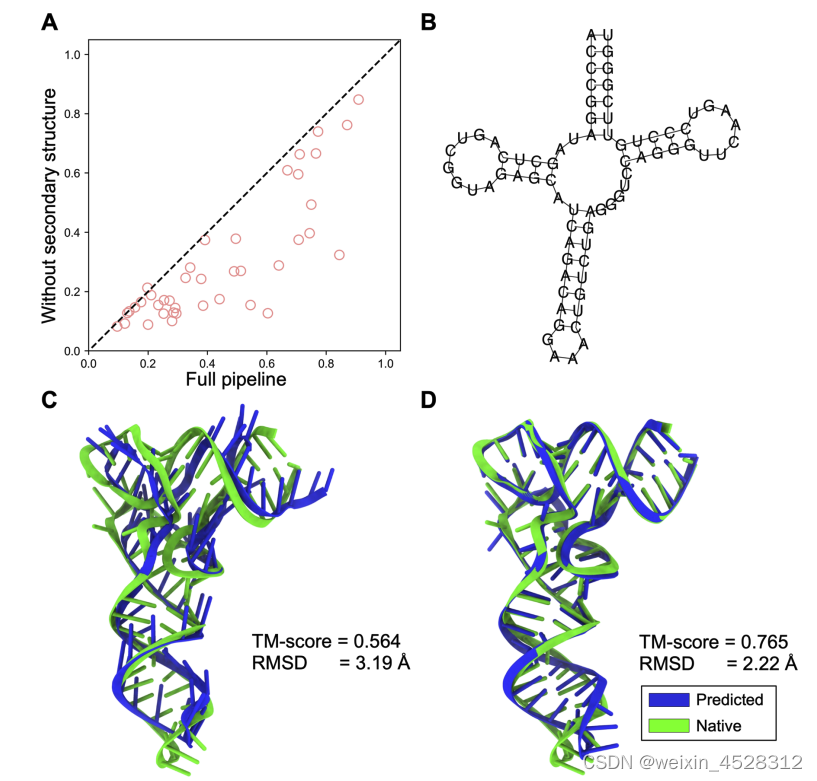
Nature Communications | 张阳实验室:端到端深度学习实现高精度RNA结构预测
RNA分子是基因转录的主要执行者,也是细胞运作的隐形功臣。它们在基因表达调控、支架构建以及催化活性等多个生命过程中都扮演着关键角色。虽然RNA如此重要,但由于实验数据的缺乏,准确预测RNA 的三维空间结构仍然是目前计算生物学面临的重大挑…...
提升您的Mac文件拖拽体验——Dropzone 4 for mac
大家都知道,在Mac上进行文件拖拽是一件非常方便的事情。然而,随着我们在工作和生活中越来越多地使用电脑,我们对于这个简单操作的需求也越来越高。为了让您的文件拖拽体验更加高效和便捷,今天我们向大家介绍一款强大的工具——Dro…...

Vue之transition组件
Vue提供了transition组件,使用户可以更便捷地添加过渡动画效果。 transition组件 transition组件也是一个抽象组件,并不会渲染出真实dom。Vue会在其第一个真实子元素上添加过渡效果。 props render 这里将render分为两部分,第一部分界定真…...
lenovo联想笔记本电脑ThinkPad X13 AMD Gen2(20XH,20XJ)原装出厂Windows10系统镜像
联想原厂Win10系统,自带所有驱动、出厂主题壁纸、系统属性联想LOGO专属标志、Office办公软件、联想电脑管家等预装程序 链接:百度网盘 请输入提取码 提取码:dolg 适用于型号:20XL,20XJ,20XG,21A1,20XK,20XH,20XF,21A0 所需要…...
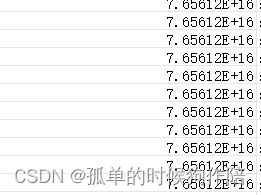
php导出cvs,excel打开数字超过16变科学计数法
今天使用php导出cvs,在excel中打开,某一个字段是数字,长度高于16位结果就显示科学计数法 超过15位的话从第16位开始就用0代替了 查询了半天总算解决了就是在后面加上"\t" $data[$key][1] " ".$value[1]."\t";…...

CSS 模糊效果 CSS 黑白效果 CSS调整亮度 对比度 饱和度 模糊效果 黑白效果反转颜色
CSS 模糊效果 CSS 黑白效果 CSS调整亮度 饱和度 模糊效果 黑白效果 实现 调整亮度 饱和度 模糊效果 黑白效果 使用 filter1、模糊2、亮度3、对比度4、饱和度5、黑白效果6、反转颜色7、组合使用8、 filer 完整参数 实现 调整亮度 饱和度 模糊效果 黑白效果 使用 filter 1、模糊…...

蓝桥杯 题库 简单 每日十题 day11
01 质数 质数 题目描述 给定一个正整数N,请你输出N以内(不包含N)的质数以及质数的个数。 输入描述 输入一行,包含一个正整数N。1≤N≤10^3 输出描述 共两行。 第1行包含若干个素数,每两个素数之间用一个空格隔开&…...
dart flutter json 转 model 常用库对比 json_serializable json_model JsonToDart
1.对比 我是一个初学者,一直跟着教材用原生的json,最近发现实在太麻烦了.所以搜索了一下,发现真的有很多现成的解决方案. 网页 https://app.quicktype.io/?ldart 这个是测试下来最好用的 有很多选项,可以使用 json_serializable 也可以不使用 json_serializable 这是推荐最…...

nginx启用了自动目录列表功能的安全漏洞修复方法
一、前言 最近被扫描到安全漏洞,说是nginx启用了自动目录列表功能,现象就是访问http://localhost/file就能看到服务器上的目录 二、修复方法 1.把nginx.conf中的autoindex on改为autoindex off location /file {alias /myuser/userfile/file;autoi…...

vector向量类使用
向量是最简单的 STL 容器,其数据结构与数组相似,占据着一个连续的内存块。 由于内存位置是连续的,所以向量中的元素可以随机访问,访问向量中任何一个元素的时间也是固定的。存储空间的管理是自动的,当要将一个元素插入…...

【Java 进阶篇】MySQL多表查询:内连接详解
MySQL是一种强大的关系型数据库管理系统,允许您在多个表之间执行复杂的查询操作。本文将重点介绍MySQL中的多表查询中的一种重要类型:内连接(INNER JOIN)。内连接用于检索满足两个或多个表之间关联条件的行,它能够帮助…...
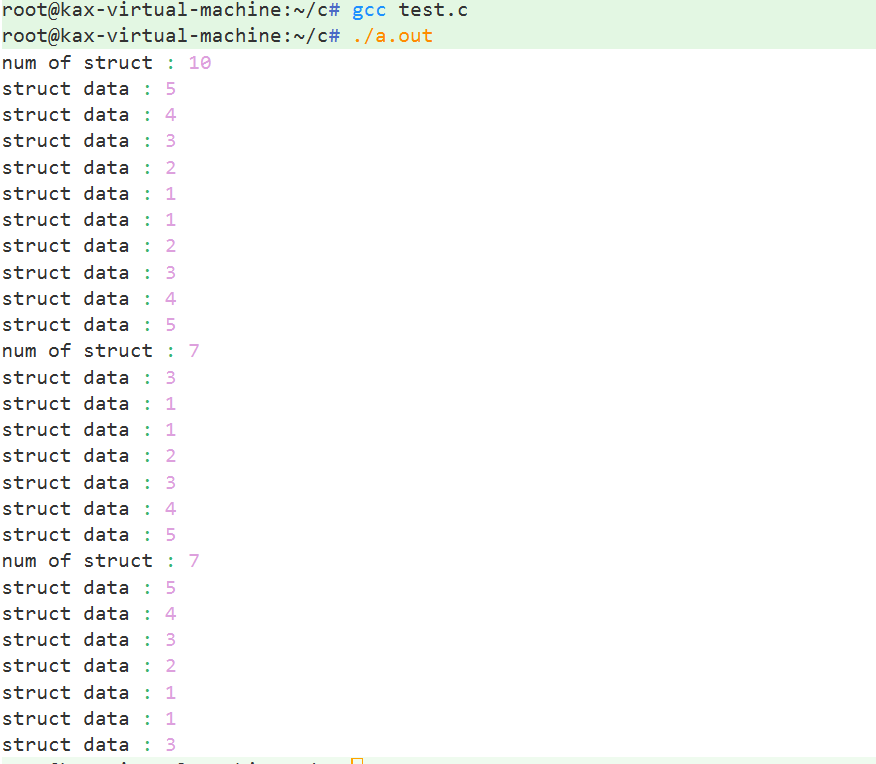
C理解(四):链表
本文主要探讨单链表与双链表相关知识。 linux内核链表(include/linux/list.h) 内核链表中纯链表封装,纯链表的各种操作函数(节点创建、插入、删除、遍历),纯链表内嵌在驱动结构体中,实现驱动的创建、插入、删除、遍历等 单链表 单链表链表头插…...
新手教程,蛋糕小程序的搭建流程一网打尽
作为一名新手,想要搭建一个蛋糕小程序可能会觉得有些困惑。但是,不用担心!今天我将为大家详细介绍蛋糕小程序的搭建流程,并带大家一步步完成。 首先,我们需要登录乔拓云网的后台。在登录成功后,点击进入商城…...

springcloud之自我介绍
写在前面 在这篇文章 中我们分析了单体应用的问题,以及用来解决这些问题的解决的方案微服务,并接着看了微服务需要考虑的各种,如服务调用,负载均衡,服务治理,链路追踪,分布式事务,等…...
机器学习之神经网络的层次
文章目录 神经网络组成神经网络根据结构分类神经网络的信号传递 神经网络组成 大脑是一个巨大的神经元网络,所以神经网络是一个节点网络。根据节点的连接方式,可以创建多种神经网络。最常用的神经网络类型之一采用了如图所示的节点分层结构 正方形节点组…...
力扣每日一题(+日常水几道题)
每日一题1333. 餐厅过滤器 - 力扣(LeetCode) 简单的按规则排序,去除几个不满足的条件然后排序返回即可 #include<algorithm> class Solution { public:vector<int> filterRestaurants(vector<vector<int>>& restaurants, …...

交互式CLI开发指南:基于Node.js构建智能命令行工具
1. 项目概述:一个能“对话”的命令行工具如果你和我一样,每天有大量时间泡在终端里,那你肯定对传统的命令行交互模式又爱又恨。爱的是它的高效和强大,恨的是它那冷冰冰的、非对即错的交互方式。输入一个命令,要么成功&…...

从英特尔与阿里云合作看软硬件协同、数据安全与异构计算实践
1. 从一次行业盛会看巨头合作的底层逻辑2017年杭州云栖大会,对于当时关注云计算和大数据技术走向的从业者来说,是一个重要的风向标。英特尔数据中心事业部的高管Robert C. Hays与阿里巴巴集团副总裁周靖人同台,这本身就是一个强烈的信号。当时…...

从个人会用AI到企业真正变强:收藏这份AI升级指南
文章指出,虽然员工开始使用AI工具提升个人效率,但企业整体能力并未因此增强。企业AI升级的关键在于将AI融入流程、业务、协作和组织,而非仅仅停留在工具使用层面。文章强调AI应进入企业运行结构,从个人动作转变为企业能力…...

Termux SSH服务从安装到外网访问全攻略:用手机IP和ngrok实现随时随地远程控制
Termux SSH服务外网访问实战:手机变身24小时远程服务器的完整方案 在咖啡馆修改代码时突然需要调用家里手机存储的某个配置文件,出差途中想检查一下家中树莓派设备的运行状态,或是深夜突发灵感想启动卧室智能设备的某个自动化流程——这些场景…...

从零到实战:用STM32F4的CAN总线做一个简易的‘车载仪表盘’数据收发Demo
从零到实战:用STM32F4的CAN总线构建车载仪表盘数据交互系统 当你坐进一辆现代汽车,仪表盘上跳动的转速、车速、油量数据背后,是CAN总线在默默协调着各个电子控制单元(ECU)的通信。本文将带你用两块STM32F407开发板,亲手搭建一个微…...

具身单月狂揽了200亿?!
点击下方卡片,关注“具身智能之心”公众号具身智能领域的投资人,现在大概是全中国最焦虑、也最亢奋的一群人。刚刚过去的4月,这个赛道丢下了两颗足以震动行业的“深水炸弹”:它石智航官宣完成4.55亿美金Pre-A轮融资,一…...

为AI助手打造企业级FTP/SFTP操作引擎:告别重复脚本,实现智能文件部署
1. 项目概述:为AI助手量身打造的FTP/SFTP操作引擎如果你和我一样,经常让AI助手(比如Claude、Cursor、Windsurf)帮忙写代码、部署项目,那你肯定遇到过这个让人哭笑不得的场景:AI能帮你从零开始配置一台VPS&a…...

Next.js SEO优化实战:用next-seo库高效管理元标签与结构化数据
1. 项目概述:SEO 优化的现代 React 解决方案 如果你正在用 Next.js 开发一个需要被搜索引擎收录的网站,比如企业官网、博客或者电商平台,那么“SEO”这个词一定让你又爱又恨。爱的是,它意味着流量和用户;恨的是&#…...

基于MCP协议与SearXNG构建AI智能体私有化搜索接口
1. 项目概述:一个为AI智能体打造的“搜索引擎接口”最近在折腾AI智能体(Agent)开发的朋友,可能都听说过MCP(Model Context Protocol)这个协议。简单来说,它就像给AI智能体装上了一套标准化的“插…...

在Hermes Agent项目中配置Taotoken作为自定义模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中配置Taotoken作为自定义模型供应商的详细步骤 对于使用Hermes Agent框架的开发者而言,接入不同的…...