手动实现Transformer
Transformer和BERT可谓是LLM的基础模型,彻底搞懂极其必要。Transformer最初设想是作为文本翻译模型使用的,而BERT模型构建使用了Transformer的部分组件,如果理解了Transformer,则能很轻松地理解BERT。
一.Transformer模型架构
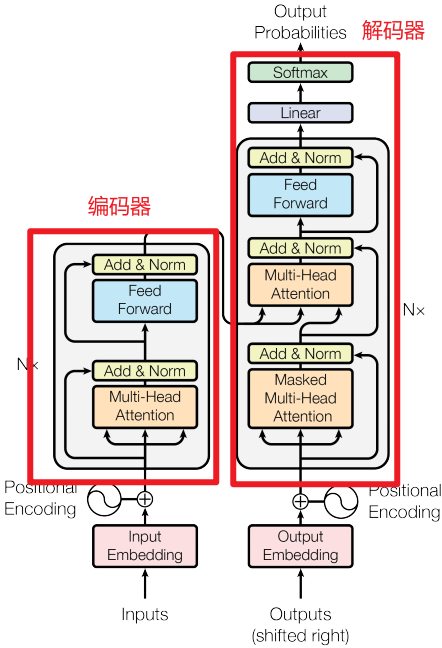
1.编码器
(1)Multi-Head Attention(多头注意力机制)
首先将输入x进行embedding编码,然后通过WQ、WK和WV矩阵转换为Q、K和V,然后输入Scaled Dot-Product Attention中,最后经过Feed Forward输出,作为解码器第2层的输入Q。
(2)Feed Forward(前馈神经网络)
2.解码器
(1)Masked Multi-Head Attention(掩码多头注意力机制)
Masked包括上三角矩阵Mask(不包含对角线)和PAD MASK的叠加,目的是在计算自注意力过程中不会注意当前词的下一个词,只会注意当前词与当前词之前的词。在模型训练的时候为了防止误差积累和并行训练,使用Teacher Forcing机制。
(2)Encoder-Decoder Multi-Head Attention(编解码多头注意力机制)
把Encoder的输出作为解码器第2层的Q,把Decoder第1层的输出作为K和V。
(3)Feed Forward(前馈神经网络)
二.简单翻译任务
1.定义数据集
这块简要介绍,主要是通过数据生成器模拟了一些数据,将原文翻译为译文,实现代码如下所示:
# 定义字典
vocab_x = '<SOS>,<EOS>,<PAD>,0,1,2,3,4,5,6,7,8,9,q,w,e,r,t,y,u,i,o,p,a,s,d,f,g,h,j,k,l,z,x,c,v,b,n,m'
vocab_x = {word: i for i, word in enumerate(vocab_x.split(','))}
vocab_xr = [k for k, v in vocab_x.items()]
vocab_y = {k.upper(): v for k, v in vocab_x.items()}
vocab_yr = [k for k, v in vocab_y.items()]
print('vocab_x=', vocab_x)
print('vocab_y=', vocab_y)# 定义生成数据的函数
def get_data():# 定义词集合words =['0','1','2','3','4','5','6','7','8','9','q','w','e','r','t','y','u','i','o','p','a','s','d','f','g','h','j','k','l','z','x','c','v','b','n','m']# 定义每个词被选中的概率p = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26])p = p / p.sum()# 随机选n个词n = random.randint(30, 48) # 生成30-48个词x = np.random.choice(words, size=n, replace=True, p=p) # words中选n个词,每个词被选中的概率为p,replace=True表示可以重复选择# 采样的结果就是xx = x.tolist()# y是由对x的变换得到的# 字母大写,数字取9以内的互补数def f(i):i = i.upper()if not i.isdigit():return ii = 9 - int(i)return str(i)y = [f(i) for i in x]# 逆序y = y[::-1]# y中的首字母双写y = [y[0]] + y# 加上首尾符号x = ['<SOS>'] + x + ['<EOS>']y = ['<SOS>'] + y + ['<EOS>']# 补PAD,直到固定长度x = x + ['<PAD>'] * 50y = y + ['<PAD>'] * 51x = x[:50]y = y[:51]# 编码成数据x = [vocab_x[i] for i in x]y = [vocab_y[i] for i in y]# 转Tensorx = torch.LongTensor(x)y = torch.LongTensor(y)return x, y# 定义数据集
class Dataset(torch.utils.data.Dataset):def __init__(self): # 初始化super(Dataset, self).__init__()def __len__(self): # 返回数据集的长度return 1000def __getitem__(self, i): # 根据索引返回数据return get_data()
然后通过loader = torch.utils.data.DataLoader(dataset=Dataset(), batch_size=8, drop_last=True, shuffle=True, collate_fn=None)定义了数据加载器,数据样例如下所示:

2.定义PAD MASK函数
PAD MASK主要目的是减少计算量,如下所示:
def mask_pad(data):# b句话,每句话50个词,这里是还没embed的# data = [b, 50]# 判断每个词是不是<PAD>mask = data == vocab_x['<PAD>']# [b, 50] -> [b, 1, 1, 50]mask = mask.reshape(-1, 1, 1, 50)# 在计算注意力时,计算50个词和50个词相互之间的注意力,所以是个50*50的矩阵# PAD的列为True,意味着任何词对PAD的注意力都是0,但是PAD本身对其它词的注意力并不是0,所以是PAD的行不为True# 复制n次# [b, 1, 1, 50] -> [b, 1, 50, 50]mask = mask.expand(-1, 1, 50, 50) # 根据指定的维度扩展return mask
if __name__ == '__main__':# 测试mask_pad函数print(mask_pad(x[:1]))
输出结果shape为(1,1,50,50)如下所示:
tensor([[[[False, False, False, ..., False, False, True],[False, False, False, ..., False, False, True],[False, False, False, ..., False, False, True],...,[False, False, False, ..., False, False, True],[False, False, False, ..., False, False, True],[False, False, False, ..., False, False, True]]]])
3.定义上三角MASK函数
将上三角和PAD MASK相加,最终输出的shape和PAD MASK函数相同,均为(b, 1, 50, 50):
# 定义mask_tril函数
def mask_tril(data):# b句话,每句话50个词,这里是还没embed的# data = [b, 50]# 50*50的矩阵表示每个词对其它词是否可见# 上三角矩阵,不包括对角线,意味着对每个词而言它只能看到它自己和它之前的词,而看不到之后的词# [1, 50, 50]"""[[0, 1, 1, 1, 1],[0, 0, 1, 1, 1],[0, 0, 0, 1, 1],[0, 0, 0, 0, 1],[0, 0, 0, 0, 0]]"""tril = 1 - torch.tril(torch.ones(1, 50, 50, dtype=torch.long)) # torch.tril返回下三角矩阵,则1-tril返回上三角矩阵# 判断y当中每个词是不是PAD, 如果是PAD, 则不可见# [b, 50]mask = data == vocab_y['<PAD>'] # mask的shape为[b, 50]# 变形+转型,为了之后的计算# [b, 1, 50]mask = mask.unsqueeze(1).long() # 在指定位置插入维度,mask的shape为[b, 1, 50]# mask和tril求并集# [b, 1, 50] + [1, 50, 50] -> [b, 50, 50]mask = mask + tril# 转布尔型mask = mask > 0 # mask的shape为[b, 50, 50]# 转布尔型,增加一个维度,便于后续的计算mask = (mask == 1).unsqueeze(dim=1) # mask的shape为[b, 1, 50, 50]return mask
if __name__ == '__main__':# 测试mask_tril函数print(mask_tril(x[:1]))
输出结果shape为(b,1,50,50)如下所示:
tensor([[[[False, True, True, ..., True, True, True],[False, False, True, ..., True, True, True],[False, False, False, ..., True, True, True],...,[False, False, False, ..., True, True, True],[False, False, False, ..., True, True, True],[False, False, False, ..., True, True, True]]]])
4.定义注意力计算层
这里的注意力计算层是Scaled Dot-Product Attention,计算方程为 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V {\rm{Attention}}(Q,K,V) = {\rm{softmax}}(\frac{{Q{K^T}}}{{\sqrt {{d_k}} }})V Attention(Q,K,V)=softmax(dkQKT)V,其中 d k d_k dk等于Embedding的维度除以注意力机制的头数,比如64 = 512 / 8,如下所示:
# 定义注意力计算函数
def attention(Q, K, V, mask):"""Q:torch.randn(8, 4, 50, 8)K:torch.randn(8, 4, 50, 8)V:torch.randn(8, 4, 50, 8)mask:torch.zeros(8, 1, 50, 50)"""# b句话,每句话50个词,每个词编码成32维向量,4个头,每个头分到8维向量# Q、K、V = [b, 4, 50, 8]# [b, 4, 50, 8] * [b, 4, 8, 50] -> [b, 4, 50, 50]# Q、K矩阵相乘,求每个词相对其它所有词的注意力score = torch.matmul(Q, K.permute(0, 1, 3, 2)) # K.permute(0, 1, 3, 2)表示将K的第3维和第4维交换# 除以每个头维数的平方根,做数值缩放score /= 8**0.5# mask遮盖,mask是True的地方都被替换成-inf,这样在计算softmax时-inf会被压缩到0# mask = [b, 1, 50, 50]score = score.masked_fill_(mask, -float('inf')) # masked_fill_()函数的作用是将mask中为1的位置用value填充score = torch.softmax(score, dim=-1) # 在最后一个维度上做softmax# 以注意力分数乘以V得到最终的注意力结果# [b, 4, 50, 50] * [b, 4, 50, 8] -> [b, 4, 50, 8]score = torch.matmul(score, V)# 每个头计算的结果合一# [b, 4, 50, 8] -> [b, 50, 32]score = score.permute(0, 2, 1, 3).reshape(-1, 50, 32)return score
if __name__ == '__main__':# 测试attention函数print(attention(torch.randn(8, 4, 50, 8), torch.randn(8, 4, 50, 8), torch.randn(8, 4, 50, 8), torch.zeros(8, 1, 50, 50)).shape) #(8, 50, 32)
5.BatchNorm和LayerNorm对比
在PyTorch中主要提供了两种批量标准化的网络层,分别是BatchNorm和LayerNorm,其中BatchNorm按照处理的数据维度分为BatchNorm1d、BatchNorm2d、BatchNorm3d。BatchNorm1d和LayerNorm之间的区别,在于BatchNorm1d是取不同样本做标准化,而LayerNorm是取不同通道做标准化。
# BatchNorm1d和LayerNorm的对比
# 标准化之后,均值是0, 标准差是1
# BN是取不同样本做标准化
# LN是取不同通道做标准化
# affine=True,elementwise_affine=True:指定标准化后再计算一个线性映射
norm = torch.nn.BatchNorm1d(num_features=4, affine=True)
print(norm(torch.arange(32, dtype=torch.float32).reshape(2, 4, 4)))
norm = torch.nn.LayerNorm(normalized_shape=4, elementwise_affine=True)
print(norm(torch.arange(32, dtype=torch.float32).reshape(2, 4, 4)))
输出结果如下所示:
tensor([[[-1.1761, -1.0523, -0.9285, -0.8047],[-1.1761, -1.0523, -0.9285, -0.8047],[-1.1761, -1.0523, -0.9285, -0.8047],[-1.1761, -1.0523, -0.9285, -0.8047]],[[ 0.8047, 0.9285, 1.0523, 1.1761],[ 0.8047, 0.9285, 1.0523, 1.1761],[ 0.8047, 0.9285, 1.0523, 1.1761],[ 0.8047, 0.9285, 1.0523, 1.1761]]],grad_fn=<NativeBatchNormBackward0>)
tensor([[[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416]],[[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416],[-1.3416, -0.4472, 0.4472, 1.3416]]],grad_fn=<NativeLayerNormBackward0>)
6.定义多头注意力计算层
本文中的多头注意力计算层包括转换矩阵(WK、WV和WQ),以及多头注意力机制的计算过程,还有层归一化、残差链接和Dropout。如下所示:
# 多头注意力计算层
class MultiHead(torch.nn.Module):def __init__(self):super().__init__()self.fc_Q = torch.nn.Linear(32, 32) # 线性运算,维度不变self.fc_K = torch.nn.Linear(32, 32) # 线性运算,维度不变self.fc_V = torch.nn.Linear(32, 32) # 线性运算,维度不变self.out_fc = torch.nn.Linear(32, 32) # 线性运算,维度不变self.norm = torch.nn.LayerNorm(normalized_shape=32, elementwise_affine=True) # 标准化self.DropOut = torch.nn.Dropout(p=0.1) # Dropout,丢弃概率为0.1def forward(self, Q, K, V, mask):# b句话,每句话50个词,每个词编码成32维向量# Q、K、V=[b,50,32]b = Q.shape[0] # 取出batch_size# 保留下原始的Q,后面要做短接(残差思想)用clone_Q = Q.clone()# 标准化Q = self.norm(Q)K = self.norm(K)V = self.norm(V)# 线性运算,维度不变# [b,50,32] -> [b,50,32]K = self.fc_K(K) # 权重就是WKV = self.fc_V(V) # 权重就是WVQ = self.fc_Q(Q) # 权重就是WQ# 拆分成多个头# b句话,每句话50个词,每个词编码成32维向量,4个头,每个头分到8维向量# [b,50,32] -> [b,4,50,8]Q = Q.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)K = K.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)V = V.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)# 计算注意力# [b,4,50,8]-> [b,50,32]score = attention(Q, K, V, mask)# 计算输出,维度不变# [b,50,32]->[b,50,32]score = self.DropOut(self.out_fc(score)) # Dropout,丢弃概率为0.1# 短接(残差思想)score = clone_Q + scorereturn score
7.定义位置编码层
位置编码计算方程如下所示,其中 d m o d e l {d_{model}} dmodel表示Embedding的维度,比如512:
P E ( p o s , 2 i ) = s i n ( p o s / 10000 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 10000 2 i / d m o d e l ) \begin{array}{l} PE\left( {pos,2i} \right) = sin\left( {pos/{{10000}^{2i/{d_{model}}}}} \right) \\ PE\left( {pos,2i + 1} \right) = cos\left( {pos/{{10000}^{2i/{d_{model}}}}} \right) \\ \end{array} PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
# 定义位置编码层
class PositionEmbedding(torch.nn.Module) :def __init__(self):super().__init__()# pos是第几个词,i是第几个词向量维度,d_model是编码维度总数def get_pe(pos, i, d_model):d = 1e4**(i / d_model)pe = pos / dif i % 2 == 0:return math.sin(pe) # 偶数维度用sinreturn math.cos(pe) # 奇数维度用cos# 初始化位置编码矩阵pe = torch.empty(50, 32)for i in range(50):for j in range(32):pe[i, j] = get_pe(i, j, 32)pe = pe. unsqueeze(0) # 增加一个维度,shape变为[1,50,32]# 定义为不更新的常量self.register_buffer('pe', pe)# 词编码层self.embed = torch.nn.Embedding(39, 32) # 39个词,每个词编码成32维向量# 用正太分布初始化参数self.embed.weight.data.normal_(0, 0.1)def forward(self, x):# [8,50]->[8,50,32]embed = self.embed(x)# 词编码和位置编码相加# [8,50,32]+[1,50,32]->[8,50,32]embed = embed + self.pereturn embed
8.定义全连接输出层
与标准Transformer相比,这里定义的全连接输出层对层归一化norm进行了提前,如下所示:
# 定义全连接输出层
class FullyConnectedOutput(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Sequential( # 线性全连接运算torch.nn.Linear(in_features=32, out_features=64),torch.nn.ReLU(),torch.nn.Linear(in_features=64, out_features=32),torch.nn.Dropout(p=0.1),)self.norm = torch.nn.LayerNorm(normalized_shape=32, elementwise_affine=True)def forward(self, x):# 保留下原始的x,后面要做短接(残差思想)用clone_x = x.clone()# 标准化x = self.norm(x)# 线性全连接运算# [b,50,32]->[b,50,32]out = self.fc(x)# 做短接(残差思想)out = clone_x + outreturn out
9.定义编码器
编码器包含多个编码层(下面代码为5个),1个编码层包含1个多头注意力计算层和1个全连接输出层,如下所示:
# 定义编码器
# 编码器层
class EncoderLayer(torch.nn.Module):def __init__(self):super().__init__()self.mh = MultiHead() # 多头注意力计算层self.fc = FullyConnectedOutput() # 全连接输出层def forward(self, x, mask):# 计算自注意力,维度不变# [b,50,32]->[b,50,32]score = self.mh(x, x, x, mask) # Q=K=V# 全连接输出,维度不变# [b,50,32]->[b,50,32]out = self.fc(score)return out
# 编码器
class Encoder(torch.nn.Module):def __init__(self):super().__init__()self.layer_l = EncoderLayer() # 编码器层self.layer_2 = EncoderLayer() # 编码器层self.layer_3 = EncoderLayer() # 编码器层def forward(self, x, mask):x = self.layer_l(x, mask)x = self.layer_2(x, mask)x = self.layer_3(x, mask)return x
10.定义解码器
解码器包含多个解码层(下面代码为3个),1个解码层包含2个多头注意力计算层(1个掩码多头注意力计算层和1个编解码多头注意力计算层)和1个全连接输出层,如下所示:
class DecoderLayer(torch.nn.Module):def __init__(self):super().__init__()self.mhl = MultiHead() # 多头注意力计算层self.mh2 = MultiHead() # 多头注意力计算层self.fc = FullyConnectedOutput() # 全连接输出层def forward(self, x, y, mask_pad_x, mask_tril_y):# 先计算y的自注意力,维度不变# [b,50,32] -> [b,50,32]y = self.mhl(y, y, y, mask_tril_y)# 结合x和y的注意力计算,维度不变# [b,50,32],[b,50,32]->[b,50,32]y = self.mh2(y, x, x, mask_pad_x)# 全连接输出,维度不变# [b,50,32]->[b,50,32]y = self.fc(y)return y
# 解码器
class Decoder(torch.nn.Module) :def __init__(self):super().__init__()self.layer_1 = DecoderLayer() # 解码器层self.layer_2 = DecoderLayer() # 解码器层self.layer_3 = DecoderLayer() # 解码器层def forward(self, x, y, mask_pad_x, mask_tril_y):y = self.layer_1(x, y, mask_pad_x, mask_tril_y)y = self.layer_2(x, y, mask_pad_x, mask_tril_y)y = self.layer_3(x, y, mask_pad_x, mask_tril_y)return y
11.定义Transformer主模型
Transformer主模型计算流程包括:获取一批x和y之后,对x计算PAD MASK,对y计算上三角MASK;对x和y分别编码;把x输入编码器计算输出;把编码器的输出和y同时输入解码器计算输出;将解码器的输出输入全连接输出层计算输出。具体实现代码如下所示:
# 定义主模型
class Transformer(torch.nn.Module):def __init__(self):super().__init__()self.embed_x = PositionEmbedding() # 位置编码层self.embed_y = PositionEmbedding() # 位置编码层self.encoder = Encoder() # 编码器self.decoder = Decoder() # 解码器self.fc_out = torch.nn.Linear(32, 39) # 全连接输出层def forward(self, x, y):# [b,1,50,50]mask_pad_x = mask_pad(x) # PAD遮盖mask_tril_y = mask_tril(y) # 上三角遮盖# 编码,添加位置信息# x=[b,50]->[b,50,32]# y=[b,50]->[b,50,32]x, y =self.embed_x(x), self.embed_y(y)# 编码层计算# [b,50,32]->[b,50,32]x = self.encoder(x, mask_pad_x)# 解码层计算# [b,50,32],[b,50,32]->[b,50,32]y = self.decoder(x, y, mask_pad_x, mask_tril_y)# 全连接输出,维度不变# [b,50,32]->[b,50,39]y = self.fc_out(y)return y
12.定义预测函数
预测函数本质就是根据x得到y的过程,在预测过程中解码器是串行工作的,从<SOS>开始生成直到结束:
# 定义预测函数
def predict(x):# x=[1,50]model.eval()# [1,1,50,50]mask_pad_x = mask_pad(x)# 初始化输出,这个是固定值# [1,50]# [[0,2,2,2...]]target = [vocab_y['<SOS>']] + [vocab_y['<PAD>']] * 49 # 初始化输出,这个是固定值target = torch.LongTensor(target).unsqueeze(0) # 增加一个维度,shape变为[1,50]# x编码,添加位置信息# [1,50] -> [1,50,32]x = model.embed_x(x)# 编码层计算,维度不变# [1,50,32] -> [1,50,32]x = model.encoder(x, mask_pad_x)# 遍历生成第1个词到第49个词for i in range(49):# [1,50]y = target# [1, 1, 50, 50]mask_tril_y = mask_tril(y) # 上三角遮盖# y编码,添加位置信息# [1, 50] -> [1, 50, 32]y = model.embed_y(y)# 解码层计算,维度不变# [1, 50, 32],[1, 50, 32] -> [1, 50, 32]y = model.decoder(x, y, mask_pad_x, mask_tril_y)# 全连接输出,39分类#[1,50,32]-> [1,50,39]out = model.fc_out(y)# 取出当前词的输出# [1,50,39]->[1,39]out = out[:,i,:]# 取出分类结果# [1,39]->[1]out = out.argmax(dim=1).detach()# 以当前词预测下一个词,填到结果中target[:,i + 1] = outreturn target
13.定义训练函数
训练函数的过程通常比较套路了,主要是损失函数和优化器,然后就是逐个epoch和batch遍历,计算和输出当前epoch、当前batch、当前学习率、当前损失、当前正确率。如下所示:
# 定义训练函数
def train():loss_func = torch.nn.CrossEntropyLoss() # 定义交叉熵损失函数optim = torch.optim.Adam(model.parameters(), lr=2e-3) # 定义优化器sched = torch.optim.lr_scheduler.StepLR(optim, step_size=3, gamma=0.5) # 定义学习率衰减策略for epoch in range(1):for i, (x, y) in enumerate(loader):# x=[8,50]# y=[8,51]# 在训练时用y的每个字符作为输入,预测下一个字符,所以不需要最后一个字# [8,50,39]pred = model(x, y[:, :-1]) # 前向计算# [8,50,39] -> [400,39]pred = pred.reshape(-1, 39) # 转形状# [8,51]->[400]y = y[:, 1:].reshape(-1) # 转形状# 忽略PADselect = y != vocab_y['<PAD>']pred = pred[select]y = y[select]loss = loss_func(pred, y) # 计算损失optim.zero_grad() # 梯度清零loss.backward() # 反向传播optim.step() # 更新参数if i % 20 == 0:# [select,39] -> [select]pred = pred.argmax(1) # 取出分类结果correct = (pred == y).sum().item() # 计算正确个数accuracy = correct / len(pred) # 计算正确率lr = optim.param_groups[0]['lr'] # 取出当前学习率print(epoch, i, lr, loss.item(), accuracy) # 打印结果,分别为:当前epoch、当前batch、当前学习率、当前损失、当前正确率sched.step() # 更新学习率
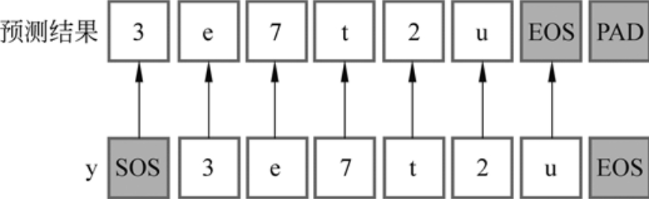
其中,y和预测结果间的对应关系,如下所示:
参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]第13章:手动实现Transformer-简单翻译任务
[3]第13章:手动实现Transformer-两数相加任务
相关文章:
手动实现Transformer
Transformer和BERT可谓是LLM的基础模型,彻底搞懂极其必要。Transformer最初设想是作为文本翻译模型使用的,而BERT模型构建使用了Transformer的部分组件,如果理解了Transformer,则能很轻松地理解BERT。 一.Transformer模型架构 1…...

leetcode456 132 Pattern
给定数组,找到 i < j < k i < j < k i<j<k,使得 n u m s [ i ] < n u m s [ k ] < n u m s [ j ] nums[i] < nums[k] < nums[j] nums[i]<nums[k]<nums[j] 最开始肯定想着三重循环,时间复杂度 O ( n 3 )…...

WordPress外贸建站Astra免费版教程指南(2023)
在WordPress的外贸建站主题中,有许多备受欢迎的主题,如AAvada、Astra、Hello、Kadence等最佳WordPress外贸主题,它们都能满足建站需求并在市场上广受认可。然而,今天我要介绍的是一个不断颠覆建站人员思维的黑马——Astra主题。 …...

Vue之ElementUI实现登陆及注册
目录 编辑 前言 一、ElementUI简介 1. 什么是ElementUI 2. 使用ElementUI的优势 3. ElementUI的应用场景 二、登陆注册前端界面开发 1. 修改端口号 2. 下载ElementUI所需的js依赖 2.1 添加Element-UI模块 2.2 导入Element-UI模块 2.3 测试Element-UI是否能用 3.编…...

网络代理的多面应用:保障隐私、增强安全和数据获取
随着互联网的发展,网络代理在网络安全、隐私保护和数据获取方面变得日益重要。本文将深入探讨网络代理的多面应用,特别关注代理如何保障隐私、增强安全性以及为数据获取提供支持。 1. 代理服务器的基本原理 代理服务器是一种位于客户端和目标服务器之间…...
字节一面:深拷贝浅拷贝的区别?如何实现一个深拷贝?
前言 最近博主在字节面试中遇到这样一个面试题,这个问题也是前端面试的高频问题,我们经常需要对后端返回的数据进行处理才能渲染到页面上,一般我们会讲数据进行拷贝,在副本对象里进行处理,以免玷污原始数据,…...
协议-TCP协议-基础概念02-TCP握手被拒绝-内核参数-指数退避原则-TCP窗口-TCP重传
协议-TCP协议-基础概念02-TCP握手被拒绝-TCP窗口 参考来源: 《极客专栏-网络排查案例课》 TCP连接都是TCP协议沟通的吗? 不是 如果服务端不想接受这次握手,它会怎么做呢? 内核参数中与TCP重试有关的参数(两个) -net.ipv4.tc…...
PDF文件压缩软件 PDF Squeezer mac中文版软件特点
PDF Squeezer mac是一款macOS平台上的PDF文件压缩软件,可以帮助用户快速地压缩PDF文件,从而减小文件大小,使其更容易共享、存储和传输。PDF Squeezer使用先进的压缩算法,可以在不影响文件质量的情况下减小文件大小。 PDF Squeezer…...

VS+Qt+opencascade三维绘图stp/step/igs/stl格式图形读取显示
程序示例精选 VSQtopencascade三维绘图stp/step/igs/stl格式图形读取显示 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《VSQtopencascade三维绘图stp/step/igs/stl格式图形读取显示》编写…...

如何在Ubuntu中切换root用户和普通用户
问题 大家在新装Ubuntu之后,有没有发现自己进入不了root用户,su root后输入密码根本进入不了,这怎么回事呢? 打开Ubuntu命令终端; 输入命令:su root; 回车提示输入密码; 提示&…...
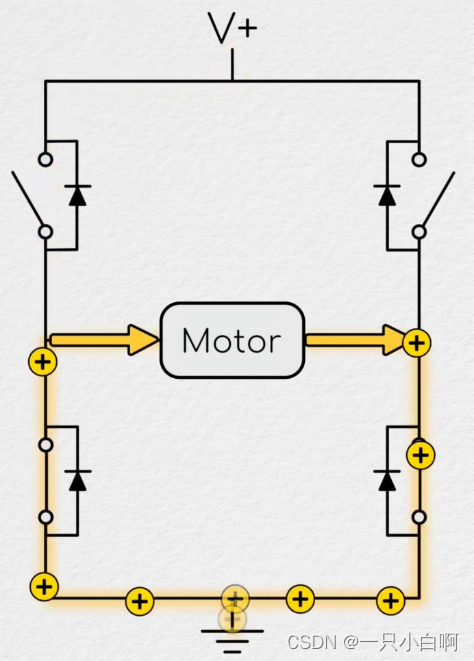
从零开始之了解电机及其控制(10)空间矢量理论
与一维数字转子位置不同,电流和电压都是二维的。可以在矩形笛卡尔平面中考虑这些尺寸。 用旋转角度和幅度来描述向量 虽然电流命令的幅度和施加的电压是进入控制器的误差项的函数,它们施加的角度是 d-q 轴方向的函数,因此也是转子位置的函数。…...
PSINS工具箱学习(一)下载安装初始化、SINS-GPS组合导航仿真、习惯约定与常用变量符号、数据导入转换、绘图显示
原始 Markdown文档、Visio流程图、XMind思维导图见:https://github.com/LiZhengXiao99/Navigation-Learning 文章目录 一、前言二、相关资源三、下载安装初始化1、下载PSINSyymmdd.rar工具箱文件2、解压文件3、初始化4、启动工具箱导览 四、习惯约定与常用变量符号1…...
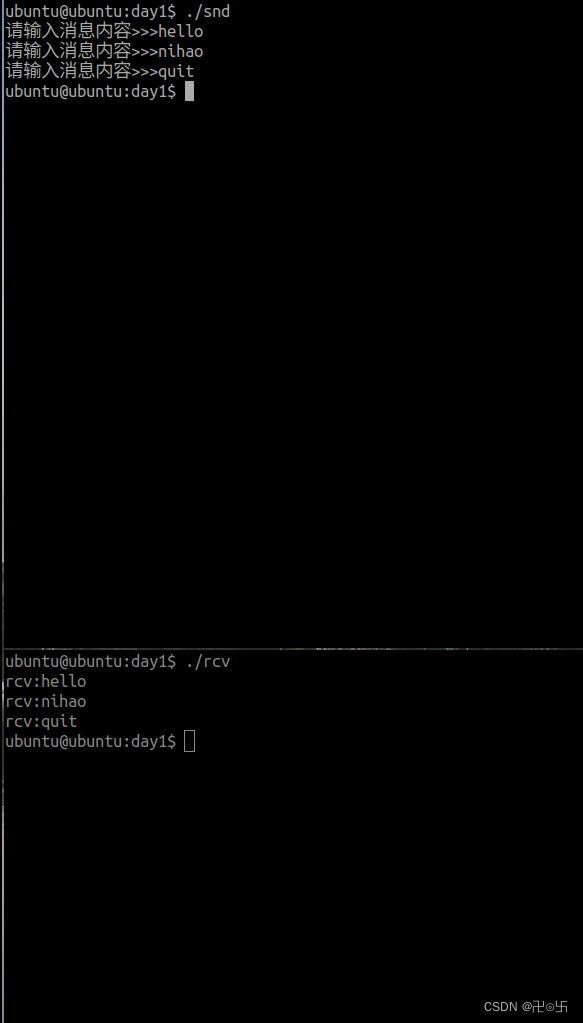
国庆day1---消息队列实现进程之间通信方式代码,现象
snd: #include <myhead.h>#define ERR_MSG(msg) do{\fprintf(stderr,"__%d__:",__LINE__);\perror(msg);\ }while(0)typedef struct{ long msgtype; //消息类型char data[1024]; //消息正文 }Msg;#define SIZE sizeof(Msg)-sizeof(long)int main…...

wdb_2018_2nd_easyfmt
wdb_2018_2nd_easyfmt Arch: i386-32-little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x8047000)32位只开了NX 这题get到一点小知识(看我exp就知道了 int __cdecl __noreturn main(int argc, const char…...
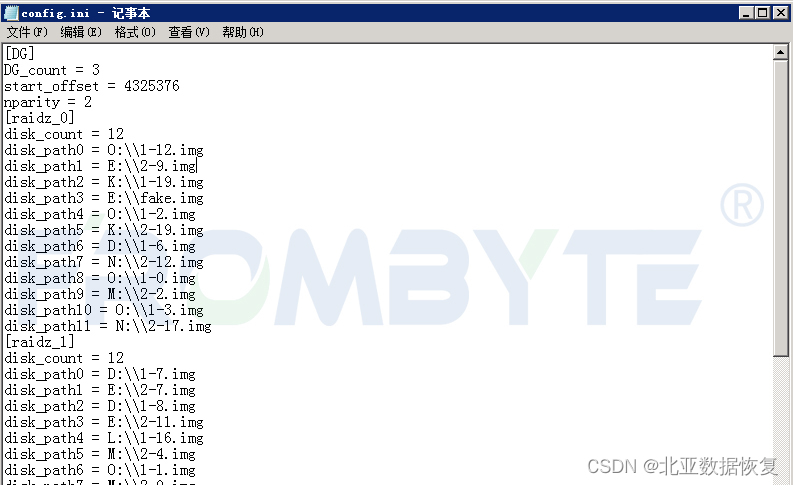
服务器数据恢复-zfs下raidz多块磁盘离线导致服务器崩溃的数据恢复案例
服务器数据恢复环境: 一台服务器共配备32块硬盘,组建了4组RAIDZ,Windows操作系统zfs文件系统。 服务器故障: 服务器在运行过程中突然崩溃,经过初步检测检测没有发现服务器存在物理故障,重启服务器后故障依…...
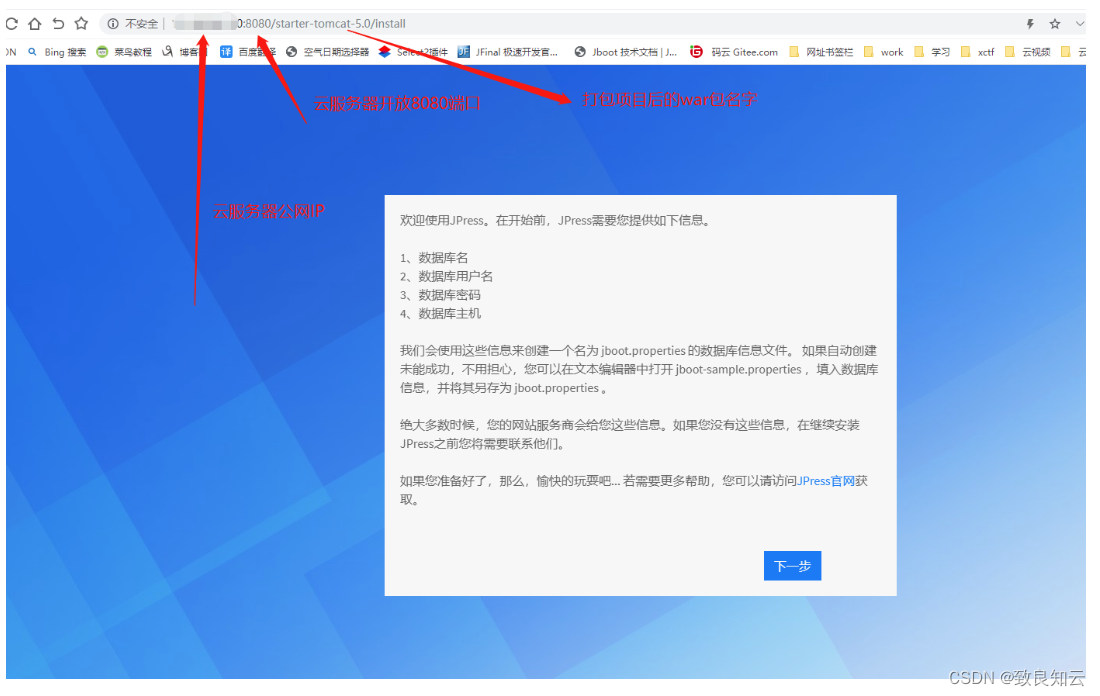
云服务器 CentOS7 操作系统上安装Jpress (Tomcat 部署项目)
1、xShell 和 xftp 下载安装(略) https://www.xshell.com/zh/free-for-home-school/2、xftp 连接云服务器 xftp 新建连接 3、JDK 压缩包下载 下载 jdk1.8 注:此处 CentOS7 是64位,所以下载的是:Linux x64…...
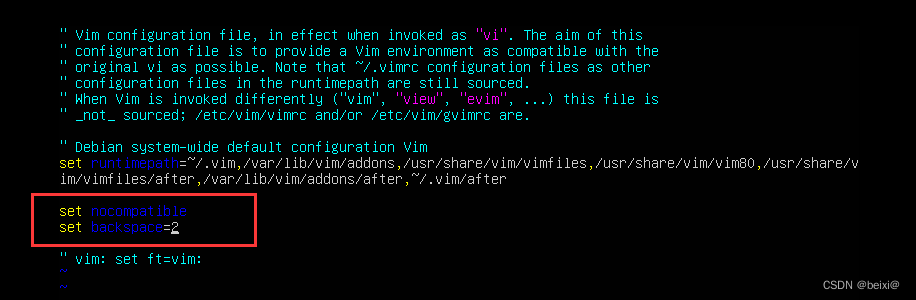
【Linux】完美解决ubuntu18.04下vi不能使用方向键和退格键
今天在刚安装完ubuntu18.04,发现在使用vi命令配置文件时使用方向键并不能移动光标,而是出现一堆奇怪的英文字母,使用退格键也不能正常地删除内容,用惯了CentOS的我已经感觉到ubuntu没有centos用着丝滑,但是没办法&…...
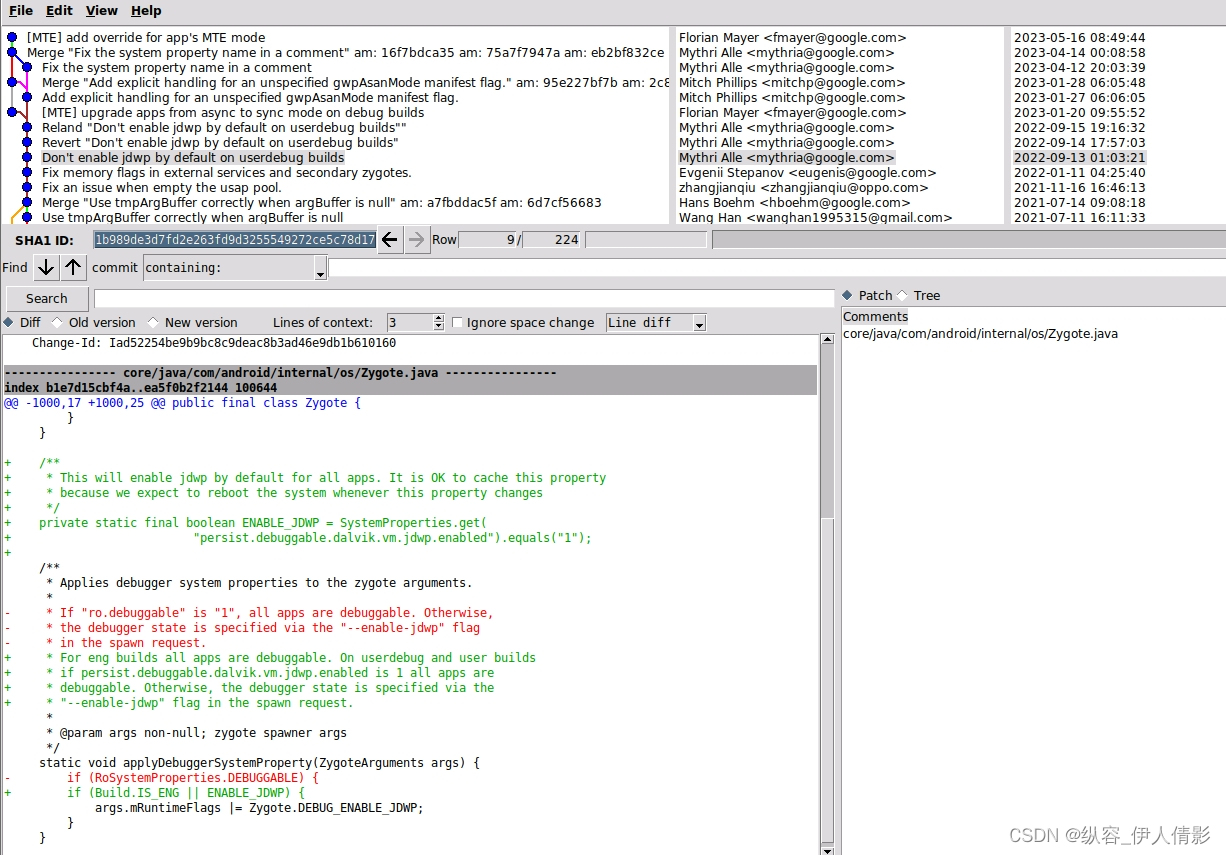
Android studio “Layout Inspector“工具在Android14 userdebug设备无法正常使用
背景描述 做rom开发的都知道,“Layout Inspector”和“Attach Debugger to Android Process”是studio里很好用的工具,可以用来查看布局、调试系统进程(比如setting、launcher、systemui)。 问题描述 最进刚开始一个Android 14…...
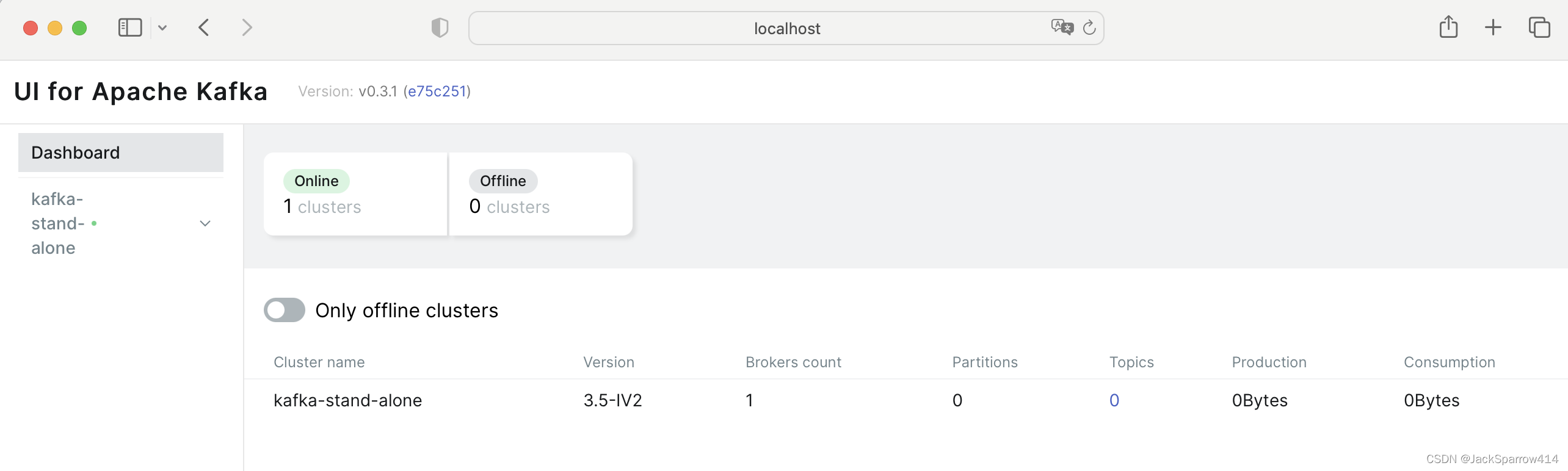
Kafka(一)使用Docker Compose安装单机Kafka以及Kafka UI
文章目录 Kafka中涉及到的术语Kafka镜像选择Kafka UI镜像选择Docker Compose文件Kafka配置项说明KRaft vs Zookeeper和KRaft有关的配置关于Controller和Broker的概念解释Listener的各种配置 Kafka UI配置项说明 测试Kafka集群Docker Compose示例配置 Kafka中涉及到的术语 对于…...

网络知识点之-MSTP平台
本文章已收录至《网络》专栏,点进右上角专栏图标可访问本专栏 多业务传送平台(MSTP)技术是指基于SDH平台,同时实现TDM、ATM、以太网等业务的接入、处理和传送,提供统一网管的多业务传送平台。 MSTP充分利用SDH技术,特别是保护恢复…...

36种阀体混线全自动智能分拣方案|3D视觉+机器人柔性制造实践
一、项目背景与行业痛点在高端流体控制设备制造领域,阀体、阀盖的精密分拣是保障产品质量的核心环节。随着工业设备向小型化、高精度方向发展,客户对阀体组件加工误差的控制要求持续提升,传统生产模式面临显著瓶颈:1. 人工分拣效率…...

深度清理工具openclaw-uninstaller:跨平台卸载与Node.js生态清理指南
1. 项目概述:为什么我们需要一个专门的卸载工具?在软件开发和日常使用中,卸载一个应用程序听起来像是一个简单的“删除”操作,但实际情况往往复杂得多。尤其是那些功能强大、深度集成到系统中的工具,比如涉及3D重建、A…...

人工智能的“意识”争论:它真的能理解吗,还是只是在模仿?—— 一个软件测试从业者的专业解构
2026年的今天,当你在测试环境中输入一条模糊的需求描述,大模型瞬间生成了逻辑严密、边界清晰的测试用例时,你是否曾在某一瞬间恍惚:它真的“懂”我在测什么吗?还是仅仅在进行一场华丽的概率模仿?关于人工智…...

UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术
UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAssetGUI是…...

Axon:极简AI代理命令行工具,无缝集成自动化工作流
1. 项目概述:一个极简主义的AI代理命令行工具如果你和我一样,对市面上那些动辄需要复杂环境配置、依赖一大堆库、启动缓慢的AI代理工具感到疲惫,那么Axon的出现,绝对会让你眼前一亮。它不是一个运行在后台的守护进程,也…...

横空出世!IDEA最强MyBatis插件来了,功能很全!
最近更新了IDEA 2026.1这个版本,发现之前使用的MyBaitsX这个插件没有兼容,启动就报错!于是就改用了MyBatisCodeHelper-Pro这个插件,体验了一把,提示很全,还有方便的MyBaits日志转SQL面板,这里分…...
)
VMware 17 Pro 中 Ubuntu 虚拟机共享 Windows 文件夹(完美踩坑版)
前言 很多小伙伴在使用 VMware 虚拟机时,都会遇到一个头疼的问题:如何在主机和虚拟机之间快速传递文件? 使用 U 盘拷贝?来回插拔太麻烦;用 scp 命令传文件?对于新手来说又有点门槛。其实,VMware…...

如何使用日志实现业务全链路追踪
在现代分布式系统架构中,一个业务请求往往需要经过多个服务节点的协同处理,涉及网关、微服务、数据库、缓存、消息队列等多个组件。传统的日志记录方式通常局限于单个服务或模块,难以还原一个完整请求的流转路径,给问题排查、性能…...

基于MCP协议与向量检索,为AI编程助手构建跨会话持久记忆
1. 项目概述:为AI编程助手构建持久记忆如果你和我一样,日常重度依赖Cursor、Claude Code、Windsurf这类AI编程助手,那你一定遇到过这个让人头疼的场景:昨天在Cursor里花了半小时跟AI解释清楚了一个复杂模块的业务逻辑和设计思路&a…...

Flink:Keyed State vs Operator State 原理与实践
一、引言在 Flink 实时计算的世界里,流处理的本质可以概括为公式:实时流处理 业务逻辑 状态(State)。无论是窗口聚合、双流 Join 还是复杂的 CEP 模式匹配,都离不开状态管理。Flink 提供了两种基本的状态类型&#x…...