pytorch第一天(tensor数据和csv数据的预处理)lm老师版
tensor数据:
import torch
import numpyx = torch.arange(12)
print(x)
print(x.shape)
print(x.numel())X = x.reshape(3, 4)
print(X)zeros = torch.zeros((2, 3, 4))
print(zeros)ones = torch.ones((2,3,4))
print(ones)randon = torch.randn(3,4)
print(randon)a = torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(a)exp = torch.exp(a)
print(exp)X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
print(X)Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
print(Y)print(torch.cat((X, Y), dim=0))#第一个括号 从外往里数第一个
print(torch.cat((X, Y), dim=1))#第二个括号 从外往里数第二个print(X == Y)#这也是个张量tosum = torch.tensor([1.0,2,3,4])
print(tosum.sum())#加起来也是tensor
print(tosum.sum().item())#这样就是取里面的数 就是一个数了
print(type(tosum.sum().item()))#打印一下类型 是float的类型a1 = torch.arange(3).reshape(3,1)
b1 = torch.arange(2).reshape(1,2)
print(a1+b1)#相加的时候 会自己填充相同的 boardcasting mechanismprint(X[-1])
print(X[1:3])X[1, 2] = 9 #修改(1,2)为9
print(X[1])#打印出那一行X[0:2] = 12 #这样的效果和X[0:2,:]=12是一样的 都是修改前两行为12
print(X)#id相当于地址一样的东西
#直接对Y操作改变了地址 增加了内存
before = id(Y)
Y = Y + X
print(id(Y) == before)
#对其元素修改操作 不增加内存 地址一样
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))#或者用+=连续操作 地址也不会变
before = id(X)
X += Y
print(id(X) == before)A = X.numpy()
print(A)
print("A现在的类型是:{}".format(type(A)))B = torch.tensor(A)
print(B)
print("B现在的类型是:{}".format(type(B)))运行结果自己对照学习了:
F:\python3\python.exe C:\study\project_1\main.py
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
torch.Size([12])
12
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
tensor([[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]]])
tensor([[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]],[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]])
tensor([[-0.8680, 1.4825, -0.1070, -1.9015],[-0.7380, -0.3838, -0.2670, -0.2649],[ 0.9945, -1.5293, 0.0398, 0.1669]])
tensor([[2, 1, 4, 3],[1, 2, 3, 4],[4, 3, 2, 1]])
tensor([[ 7.3891, 2.7183, 54.5981, 20.0855],[ 2.7183, 7.3891, 20.0855, 54.5981],[54.5981, 20.0855, 7.3891, 2.7183]])
tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]])
tensor([[2., 1., 4., 3.],[1., 2., 3., 4.],[4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]])
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]])
tensor([[False, True, False, True],[False, False, False, False],[False, False, False, False]])
tensor(10.)
10.0
<class 'float'>
tensor([[0, 1],[1, 2],[2, 3]])
tensor([ 8., 9., 10., 11.])
tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]])
tensor([4., 5., 9., 7.])
tensor([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
False
id(Z): 1801869019800
id(Z): 1801869019800
True
[[26. 25. 28. 27.][25. 26. 27. 28.][20. 21. 22. 23.]]
A现在的类型是:<class 'numpy.ndarray'>
tensor([[26., 25., 28., 27.],[25., 26., 27., 28.],[20., 21., 22., 23.]])
B现在的类型是:<class 'torch.Tensor'>进程已结束,退出代码0
csv一般的数据预处理:
import os
import pandas as pd
import torch#创造文件夹 和excel csv文件
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')#因为没有 所有会自己创建一个#打开文件 用写的方式打开
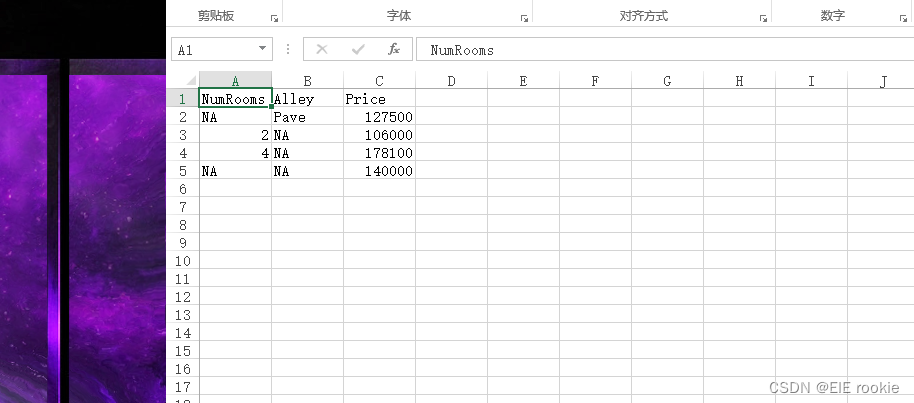
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n')f.write('NA,Pave,127500\n')f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')#打开csv文件
data = pd.read_csv(data_file)
print(data) # 0,1,2,3会从第二行开始 因为第一行一般是标题和标签inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]#裁剪0,1行 第2行舍去给input
print(inputs)
print(outputs)#name就会在下面inputs = inputs.fillna(inputs.mean())#把string的类型变成其他的均值
print(inputs)inputs = pd.get_dummies(inputs, dummy_na=True)#alley里面全是英文 应该把其编码 这就是编码的方式 是1就会为1
print(inputs)#都是数字后 就开始转换成tensor类型了
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(X)
print(y)
运行结果:
F:\python3\python.exe C:\study\project_1\data_preprocess.py NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000NumRooms Alley
0 NaN Pave
1 2.0 NaN
2 4.0 NaN
3 NaN NaN
0 127500
1 106000
2 178100
3 140000
Name: Price, dtype: int64NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaNNumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
tensor([[3., 1., 0.],[2., 0., 1.],[4., 0., 1.],[3., 0., 1.]], dtype=torch.float64)
tensor([127500, 106000, 178100, 140000])进程已结束,退出代码0
第一行代码 创造文件夹的操作和csv操作结果:

他是跑到上一个级创建的dir
ok 结束
相关文章:
pytorch第一天(tensor数据和csv数据的预处理)lm老师版
tensor数据: import torch import numpyx torch.arange(12) print(x) print(x.shape) print(x.numel())X x.reshape(3, 4) print(X)zeros torch.zeros((2, 3, 4)) print(zeros)ones torch.ones((2,3,4)) print(ones)randon torch.randn(3,4) print(randon)a …...
CSP-J第二轮试题-2021年-1.2题
文章目录 参考:总结 [CSP-J 2021] 分糖果题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 样例 #2样例输入 #2样例输出 #2 样例 #3样例输入 #3样例输出 #3 提示答案1答案2-优化 [CSP-J 2021] 插入排序题目描述输入格式输出格式样例 #1样例输入 #1样…...
怒刷LeetCode的第16天(Java版)
目录 第一题 题目来源 题目内容 解决方法 方法一:迭代 方法二:模拟 方法三:循环模拟 方法四:传递 第二题 题目来源 题目内容 解决方法 方法一:回溯 方法二:枚举优化 第三题 题目来源 题目…...
让大脑自由
前言 作者写这本书的目的是什么? 教会我们如何让大脑更好地为自己工作。 1 大脑的运行机制是怎样的? 大脑的基本运行机制是神经元之间通过突触传递信息,神经元的兴奋和抑制状态决定了神经网络的运行和信息处理,神经网络可以通过…...
Arcgis克里金插值报错:ERROR 010079: 无法估算半变异函数。 执行(Kriging)失败。
Arcgis克里金插值报错:ERROR 010079: 无法估算半变异函数。 执行(Kriging)失败。 问题描述: 原因: shape文件的问题,此图可以看出,待插值的点有好几个都超出了地理范围之外,这个不知道是坐标系配准的问…...

Docker Compose安装
title: “Docker Compose安装” createTime: 2022-01-04T19:08:1508:00 updateTime: 2022-01-04T19:08:1508:00 draft: false author: “name” tags: [“docker”,“docker-compose”] categories: [“install”] description: “测试的” docker-compose安装步骤 1.下载 u…...
机器人过程自动化(RPA)入门 7. 处理用户事件和助手机器人
在UiPath中,有两种类型的Robot用于自动化任何流程。一个是后台机器人,它在后台工作。它独立工作,这意味着它不需要用户的输入或任何用户交互。另一个是前台机器人,也被称为助理机器人。 本章介绍前台机器人。在这里,我们将了解自动化过程中通过简单按键、单击鼠标等触发事…...

在linux下预览markdown的方法,转换成html和pdf
背景 markdown是一种便于编写和版本控制的格式,但却不便于预览——特别是包含表格等复杂内容时,单纯的语法高亮是远远不够的——这样就不能边预览边调整内容,需要找到一种预览方法。 思路 linux下有个工具,叫pandoc,…...
AIOT入门指南:探索人工智能与物联网的交汇点
AIOT入门指南:探索人工智能与物联网的交汇点 1. 引言 随着技术的快速发展,人工智能(AI)和物联网(IoT)已经成为当今最热门的技术领域。当这两个领域交汇时,我们得到了AIOT - 一个结合了AI的智能…...
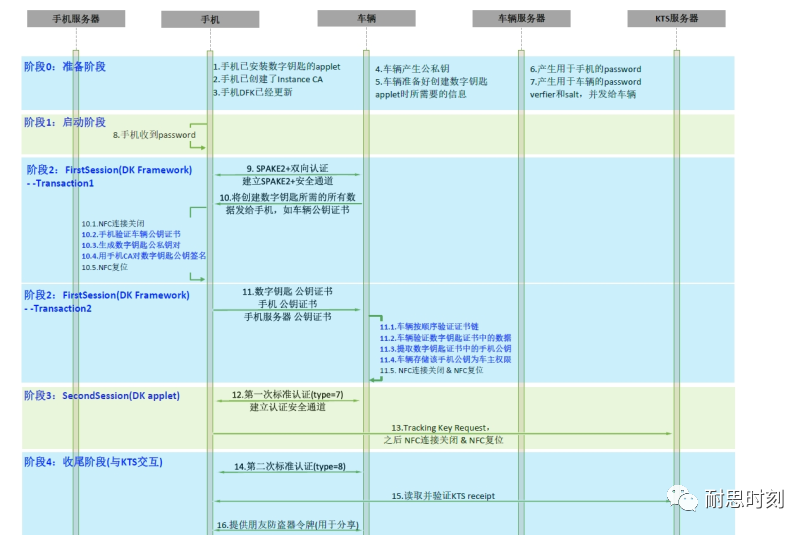
CCC数字钥匙设计【NFC】 --车主配对流程介绍
1、车主配对流程介绍 车主配对流程可以通过车内NFC进行,若支持UWB测距,也可以通过蓝牙/UWB进行,本文主要介绍通过NFC进行车主配对的流程。 整个配对流程相对较为复杂,本文主要梳理整体的步骤流程,其中的每个细节流程未…...
一站式开源持续测试平台 MerterSphere 之测试跟踪操作详解
一、MeterSphere平台介绍 MeterSphere是一站式的开源持续测试平台,遵循 GPL v3 开源许可协议,涵盖测试跟踪、接口测试、UI 测试和性能测试等功能,全面兼容JMeter、Selenium 等主流开源标准,有效助力开发和测试团队充分利用云弹性进…...

自然语言处理状况简介
一、说明 自然语言处理已经进入大模型时代,然而从业人员必须了解整个知识体系、发展过程、知识结构,应用范围等一系列知识。本篇将报道此类概况。 二、自然语言处理简介 自然语言处理,或简称NLP,是处理和转换文本的计算机科学学科…...
python爬虫基于管道持久化存储操作
文章目录 基于管道持久化存储操作scrapy的使用步骤1.先转到想创建工程的目录下:cd ...2.创建一个工程3.创建之后要转到工程目录下4.在spiders子目录中创建一个爬虫文件5.执行工程setting文件中的参数 基于管道持久化存储的步骤:持久化存储1:保…...

【MySQL】数据类型(二)
文章目录 一. char字符串类型二. varchar字符串类型2.1 char和varchar比较 三. 日期和时间类型四. enum和set类型4.1 set的查询 结束语 一. char字符串类型 char (L) 固定长度字符串 L是可以存储的长度,单位是字符,最大长度是255 MySQL中的字符ÿ…...

基于Matlab实现连续模型求解方法
本文介绍了如何使用Matlab实现连续模型求解方法。首先,我们介绍了连续模型的概念,并明确了使用ODE和PDE求解器来求解常微分方程和偏微分方程的步骤。然后,我们通过一个简单的例子演示了如何将问题转化为数学模型,并使用Matlab编写…...

Tomcat 与 JDK 对应版本关系
对应关系 Tomcat版本 jdk版本11.0.x JDK 21及以后10.1.x JDK11及以后10.0.xJDK1.8及以后9.0.x JDK1.8及以后8.5.xJDK1.7及以后8.0.x JDK1.7及以后 查看对应关系方法: 登陆Tomcat官网:Apache Tomcat - Welcome! 结果:...
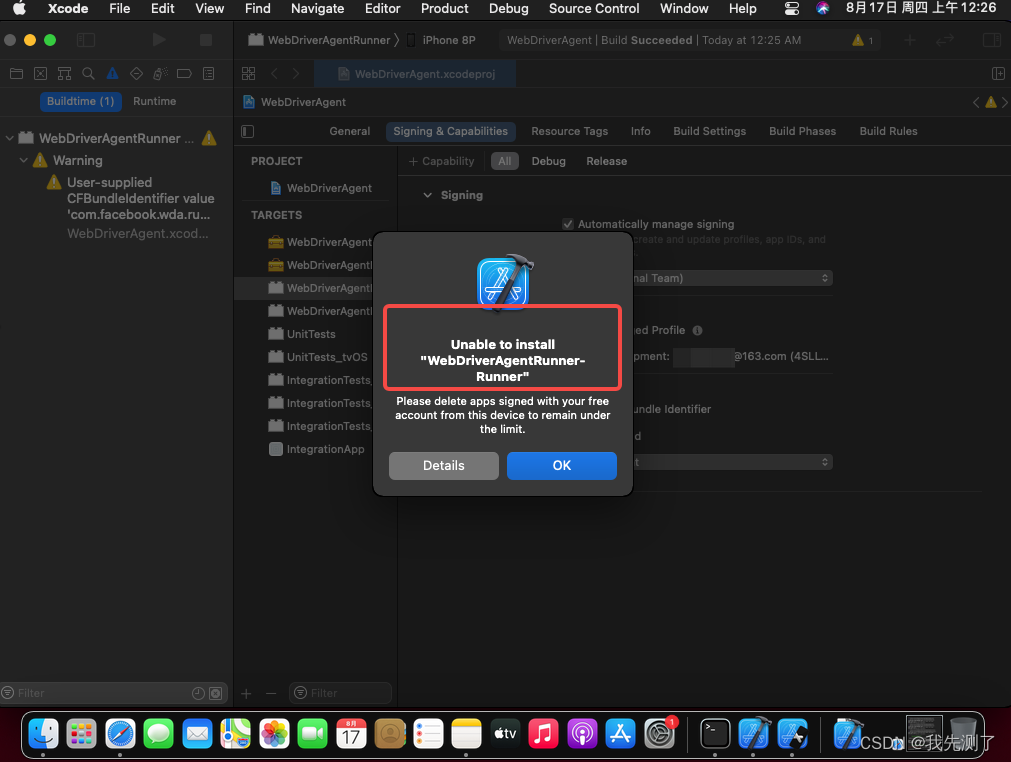
iOS自动化测试方案(二):Xcode开发者工具构建WDA应用到iphone
文章目录 一、环境准备1.1、软件环境1.2、硬件环境1.3、查看版本 二、安装WDA过程2.7、构建失败,这类错误有很多,比如在选择开发者账号后,就会提示:Failed to register bundle identifier表示应用唯一注册失败2.9、第二个错误,完全…...
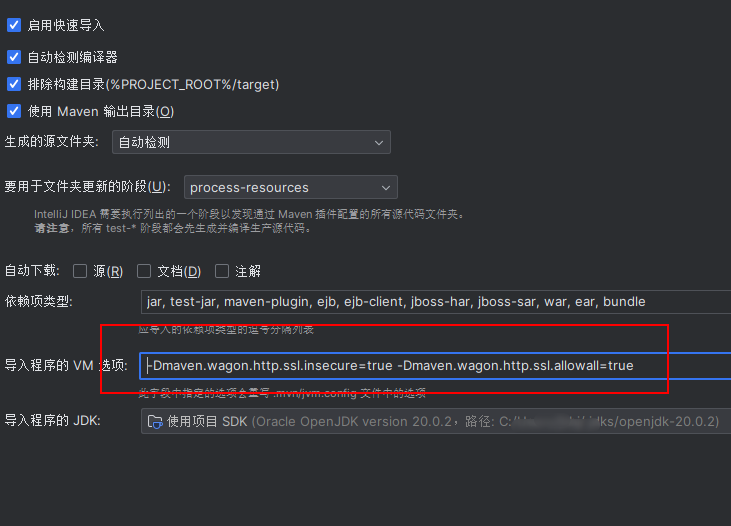
IDEA的Maven换源
前言 IDEA是个好东西,但是使用maven项目时可能会让人很难受,要么是非常慢,要么直接下载不了。所以我们需要给IDEA自带maven换源,保证我们的下载速度。 具体操作 打开IDEA安装路径,然后打开下面的文件夹 plugins\m…...
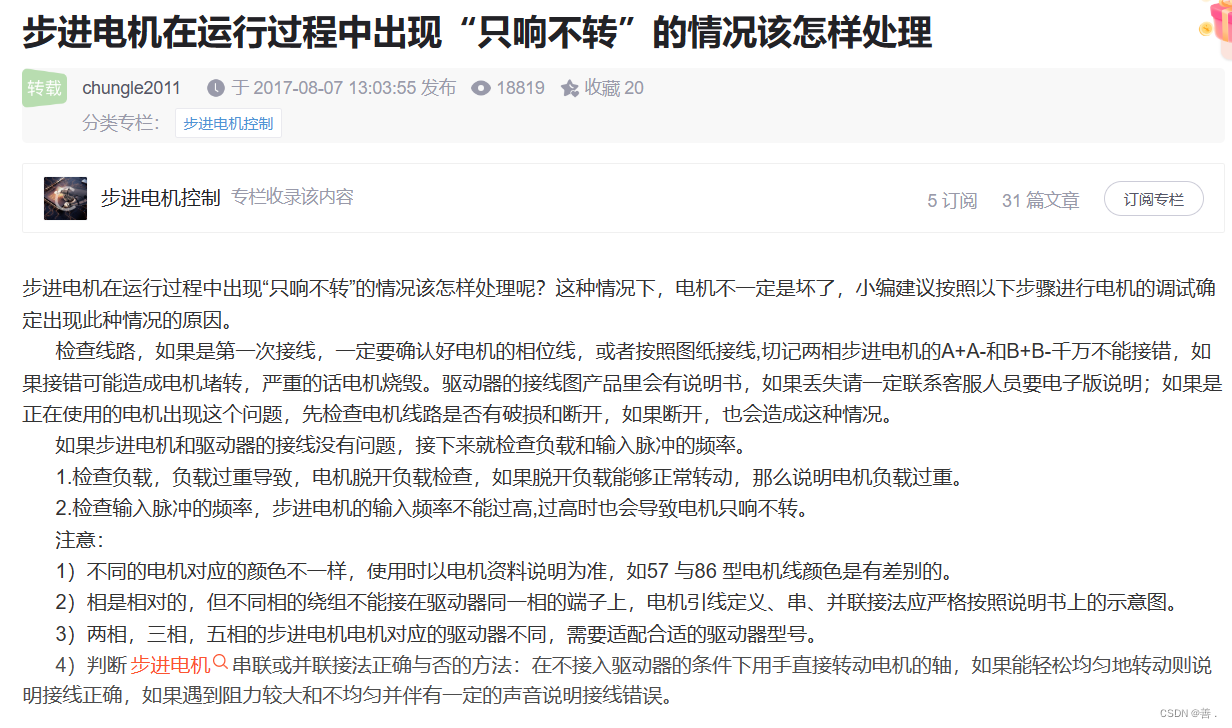
步进电机只响不转
我出现问题的原因是相位线接错。 我使用的滑台上示17H的步进电机,之前用的是57的步进电机。 57步进电机的相位线是A黑、A-绿、B红、B-蓝。 17步进电机的相位线是A红、A-绿、B黑、B-蓝。 这两天被一个问题困扰了好久,在调试步进电机开发板的时候电机发生…...

使用select实现服务器并发
select函数介绍: select 函数是一个用于在一组文件描述符上进行异步I/O多路复用的系统调用。它可以同时监视多个文件描述符,等待其中任何一个文件描述符准备就绪,然后进行相应的操作。 以下是select函数的原型: #include <…...

终极指南:如何用TrollInstallerX快速解锁iOS系统自由
终极指南:如何用TrollInstallerX快速解锁iOS系统自由 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 想要打破iOS系统的限制,安装更多个性化应用…...

10分钟打造专业级科研图表:SciencePlots终极美化指南
10分钟打造专业级科研图表:SciencePlots终极美化指南 【免费下载链接】SciencePlots Matplotlib styles for scientific plotting 项目地址: https://gitcode.com/gh_mirrors/sc/SciencePlots 还在为科研论文中的图表不够专业而烦恼吗?SciencePlo…...

米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源
米哈游游戏字体库终极指南:轻松获取11款精美架空文字字体资源 【免费下载链接】HoYo-Glyphs Constructed scripts by HoYoverse 米哈游的架空文字 项目地址: https://gitcode.com/gh_mirrors/ho/HoYo-Glyphs 想要为你的设计作品注入《原神》、《崩坏…...

三周、1.81倍、百亿:中国AI的压制性时刻
调用量飙升、百亿美元涌入、智能体密集落地——过去七天,中国AI正在改写全球游戏规则。与此同时,内容创作者的“AI红利窗口”也正在打开。连续三周,中国AI压住美国5月18日,OpenRouter最新数据显示,5月11日至17日当周&a…...

Unity渐变透明效果实现原理与生产级方案
1. 这不是调个Alpha值那么简单:为什么90%的Unity透明效果都“假”得明显 在Unity项目里做淡入淡出,很多人第一反应就是 renderer.material.color new Color(1,1,1,0.5f) ——改个alpha完事。我刚入行那会儿也这么干,直到上线前被美术揪着耳…...

STM32 SysTick中断:嵌入式系统时间管理的核心原理与实战应用
1. 项目概述:为什么SysTick中断是STM32开发的基石在STM32的嵌入式开发世界里,无论你是刚入门的新手,还是已经做过几个项目的熟手,有一个功能你几乎无法绕开,那就是SysTick——系统滴答定时器。你可能在HAL库的初始化代…...

AI MV 工具评测指南 2026:多模态音视频自动生成系统
AI MV 工具评测指南 2026:多模态音视频自动生成系统 适用读者:需要批量生产音乐可视化内容的自媒体创作者、社交媒体运营者、短视频内容创作者一、技术定义与核心功能 AI MV 工具是实现音频到视频自动转化的多模态生成系统。其工作原理是:输入…...
)
保姆级教程:用Ansys Zemax从零设计一个汽车HUD(附挡风玻璃反射优化技巧)
从零开始用Ansys Zemax设计汽车HUD:避坑指南与实战技巧 在汽车智能化浪潮中,抬头显示系统(HUD)正从高端车型的选配逐渐成为主流配置。对于光学工程师而言,掌握HUD设计能力已成为职业发展的关键技能。本文将带你从零开始…...

工业眼睛:11 老手血泪Tips + 新手避坑清单
11 老手血泪Tips + 新手避坑清单 上回聊完机器视觉给工厂安了“眼睛”,AI让它升级成“火眼金睛”,数据闭环一接,生产线直接会自己挑毛病。今天不整高大上的理论,来点真刀真枪的干货——11条老手血泪Tips(全是师傅们用命换来的教训,踩坑踩到哭),外加新手避坑清单(直接…...

华为MetaERP在全球化部署方面具有以下显著优势
华为MetaERP在全球化部署方面具有以下显著优势:1. 全栈自主技术,无“卡脖子”风险根技术自主可控:MetaERP基于华为自主研发的欧拉操作系统、高斯数据库、昇腾AI算力等全栈技术栈,完全摆脱对西方ERP系统的依赖,满足全球…...