python爬虫基于管道持久化存储操作
文章目录
- 基于管道持久化存储操作
- scrapy的使用步骤
- 1.先转到想创建工程的目录下:cd ...
- 2.创建一个工程
- 3.创建之后要转到工程目录下
- 4.在spiders子目录中创建一个爬虫文件
- 5.执行工程
- setting文件中的参数
- 基于管道持久化存储的步骤:
- 持久化存储1:保存到本地txt文档。
- 1. 数据解析
- 2. 在item类中定义相关的属性
- 3. 将解析的数据封装存储到item类型的对象
- 4. 将item类型的对象提交给管道进行持久化存储的操作
- 5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 6. 在配置文件中开启管道
- 运行结果:
- 持久化存储2:保存到数据库中。
- 前言
- 安装mysql
- 安装navicat
- 使用终端操作数据库
- 如何使用navicat新建数据库&新建表
- 1234步与持久化存储1完全相同。
- 5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 6. 在配置文件中开启管道
- 运行结果
- 后记:
基于管道持久化存储操作
这个也是在基于scrapy框架的基础上实现的,所以scrapy的基本使用命令也是需要遵从的
scrapy的使用步骤
1.先转到想创建工程的目录下:cd …
2.创建一个工程
scrapy startproject 工程名 (XXPro:XXproject)
3.创建之后要转到工程目录下
cd 工程名
4.在spiders子目录中创建一个爬虫文件
这里不需要切换目录,在项目目录下即可。
www.xxx.com是要爬取的网站。
scrapy genspider 爬虫文件名 www.xxx.com
5.执行工程
在pycharm中直接执行是不管用的,无效。应该再在终端中执行
scrapy crawl 爬虫文件名 # 执行的是爬虫文件
setting文件中的参数
项目下有一个settings文件,里面的文件介绍如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False#显示指定类型的日志信息 而不显示其他乱七八糟的
LOG_LEVEL = 'ERROR'# 设置用户代理 浏览器类型
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"# 取消注释改行,意味着开启管道存储。
# 300表示优先级,数值越小优先级越高
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,
}基于管道持久化存储的步骤:
1. 数据解析
2. 在item类中定义相关的属性
3. 将解析的数据封装存储到item类型的对象
4. 将item类型的对象提交给管道进行持久化存储的操作
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
6. 在配置文件中开启管道
持久化存储1:保存到本地txt文档。
这个并不是很难。主要是理清他的思路是什么。
在工程目录下的爬虫文件(这里是weibo.py)写好保证能够爬取到信息之后,主要是将管道文件写好(pipelines.py)。
按照上面的6步走:
1. 数据解析
即爬取数据的过程
# (weibo.py爬虫文件)
# 不使用数据库,只保存到本地import scrapy
from weiboPro.items import WeiboproItem
# 导包失败:右键项目目录 => 将目标标记为 => 源代码根目录# 爬取微博失败了,返回为空。改为爬取B站了。
# 爬取B站的视频的名称和作者
class WeiboSpider(scrapy.Spider):name = "weibo"# allowed_domains = ["weibo.com"]start_urls = ["https://www.bilibili.com/"]def parse(self, response):author = []title = []div_list = response.xpath('//*[@id="i_cecream"]/div[2]/main/div[2]/div/div[1]/div')print("数据长度为", len(div_list))for div in div_list:# xpath返回的是列表,但是列表元素一定是Selector类型的对象# extract可以将Selector对象中data参数存储的字符串提取出来author = div.xpath('.//div[@class="bili-video-card__info--right"]//a/span[@class="bili-video-card__info--author"]/text()').extract() # xpath要从上一层的xpath开始找,必须在最前面加个. !!# 对列表调用extract后,将列表的每一个Selector对象中的data对应的字符串提取了出来title=div.xpath('.//div[@class="bili-video-card__info--right"]/h3/a/text()').extract()# author, title解析到的为list,将其转为str# 将列表转为字符串: .join方法author = ''.join(author)title = ''.join(title)print('当前抽取的author', author)print('当前抽取的title', title)print(len(author), len(title))# 3,4两步都在循环内,所以是每执行一次循环将item对象提交给管道并存储到本地# 3.将解析的数据封装存储到item类型的对象item = WeiboproItem()item['author'] = authoritem['title'] = title# 4. 将item类型的对象提交给管道进行持久化存储的操作yield item
2. 在item类中定义相关的属性
找到项目目录下的items.py文件,在里面定义相关的属性
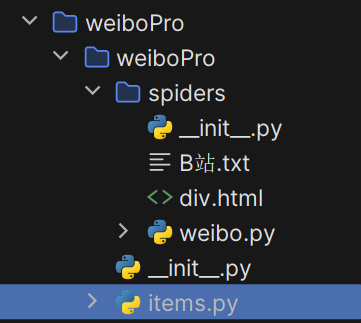
class WeiboproItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 在item类中定义相关的属性author = scrapy.Field()title = scrapy.Field()3. 将解析的数据封装存储到item类型的对象
4. 将item类型的对象提交给管道进行持久化存储的操作
3,4两步在1.中已经体现,具体代码为:
# 3.将解析的数据封装存储到item类型的对象item = WeiboproItem()item['author'] = authoritem['title'] = title# 4. 将item类型的对象提交给管道进行持久化存储的操作yield item
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
在这里重写了父类的两个方法:open_spider()和close_spider()方法。
open_spider()方法在开始爬虫时被调用一次,close_spider()方法在爬虫结束时被调用一次。这样实现了yield多次时,只打开关闭一次文件。
process_item()是将得到的item对象中的数据保存到本地。
# pipelines.py 管道文件
class WeiboproPipeline:fp = Nonedef open_spider(self, spider):# 重写父类的方法,只在开始爬虫时被调用一次print("开始爬虫")self.fp = open('./B站.txt', 'w', encoding='utf-8')def process_item(self, item, spider):author = item['author']title = item['title']print("当前写入的是:" + author + ":" + title + "\n")self.fp.write(author + ":" + title + "\n")return itemdef close_spider(self, spider):# 重写父类的方法,在爬虫结束时被调用一次print("结束爬虫")self.fp.close()
6. 在配置文件中开启管道
打开项目weiboPro路径下的settings.py文件,将ITEM_PIPELINES字典取消注释,即可开启管道。
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,
}
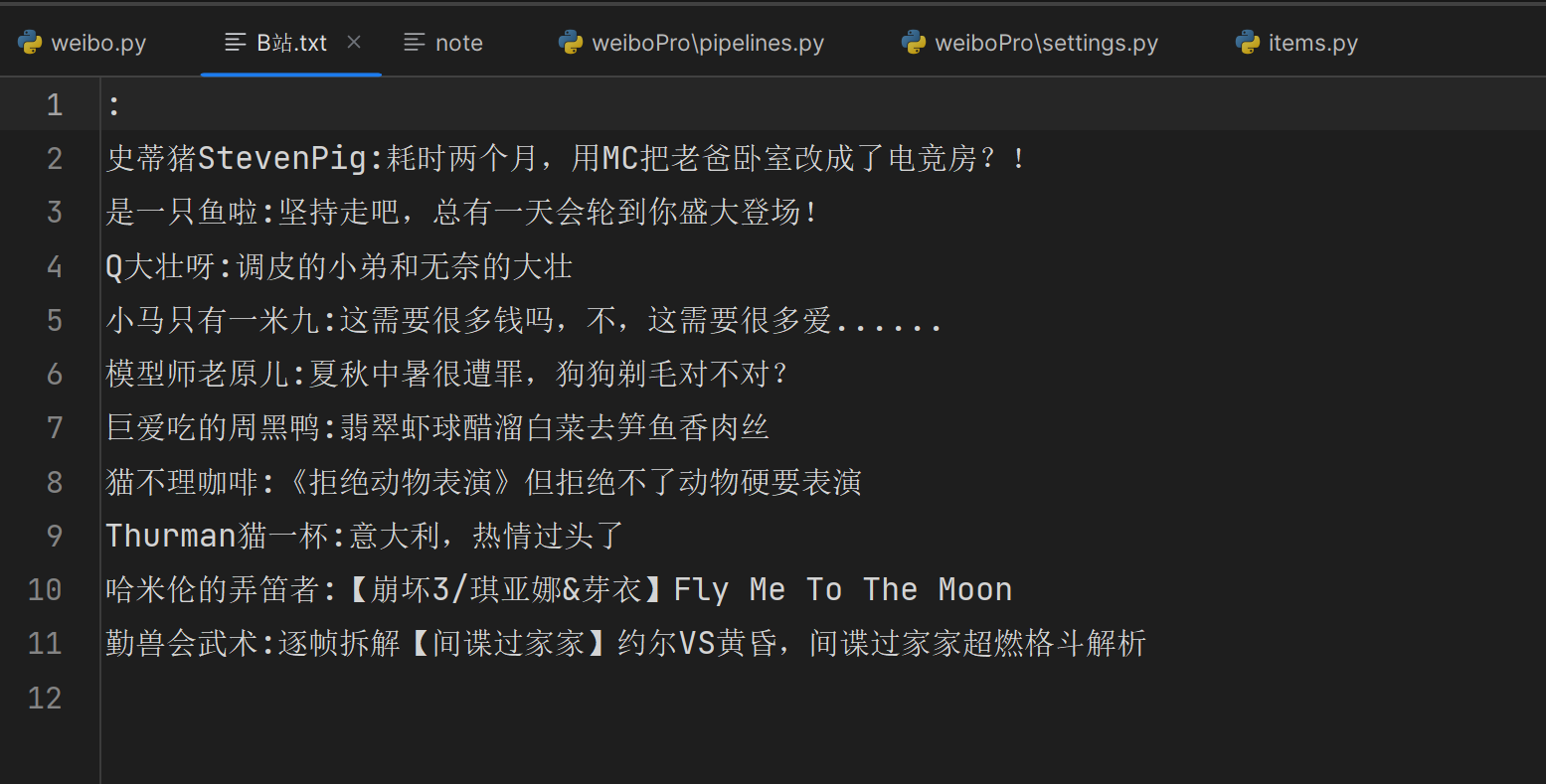
运行结果:
运行结束之后,会在本地生成B站.txt文件,其中包含爬取的author和title
持久化存储2:保存到数据库中。
前言
安装mysql
安装navicat
这里需要安装mysql,我还另外安装了navicat。安装好mysql之后,要新建连接,按照步骤操作即可。
使用终端操作数据库
这里需要mysql库。这个库是用来对数据库进行远程连接的,所以必须要有打开的数据库,打开的表才可以。
如何使用navicat新建数据库&新建表
建立好之后,再按照上面的6步按部就班来就可以。
1234步与持久化存储1完全相同。
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
这里的管道文件中的每一个管道类(如持久化存储1的WeiboproPipeline)对应将一组数据存储到一个平台或者载体中。上面的是保存到本地,所以我们还需要将再写一个类来将数据持久化存储到数据库中。
我也有好多东西不理解为什么要这么写
# 管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPileLine:# 每写一个管道类要将这个类写到settings.py的ITEM_PIPELINES中。connect = Nonecursor = Nonedef open_spider(self, spider):# 重写父类的方法,在爬虫开始时调用一次# 创建连接:pymysql.Connectself.connect = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='liu1457154996', db='bzhan', charset='utf8') # db表示数据库的名称,我上面创建的数据库名称叫bzhan,即上图中的绿色圆柱def process_item(self, item, spider):# 创建游标self.cursor = self.connect.cursor()try:self.cursor.execute('INSERT INTO bzhan (author, title) VALUES ("%s", "%s")' % (item['author'], item['title'])) # 这里的bzhan是bzhan数据库下的表的名称self.connect.commit()print("成功写入数据库", item['author'], item['title'])except Exception as e:print(e)self.connect.rollback()return itemdef close_item(self, spider):self.cursor.close() # 关闭游标self.connect.close() # 关闭连接
6. 在配置文件中开启管道
在上面的基础上开启mysqlPileLine管道。
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,"weiboPro.pipelines.mysqlPileLine": 301,
}
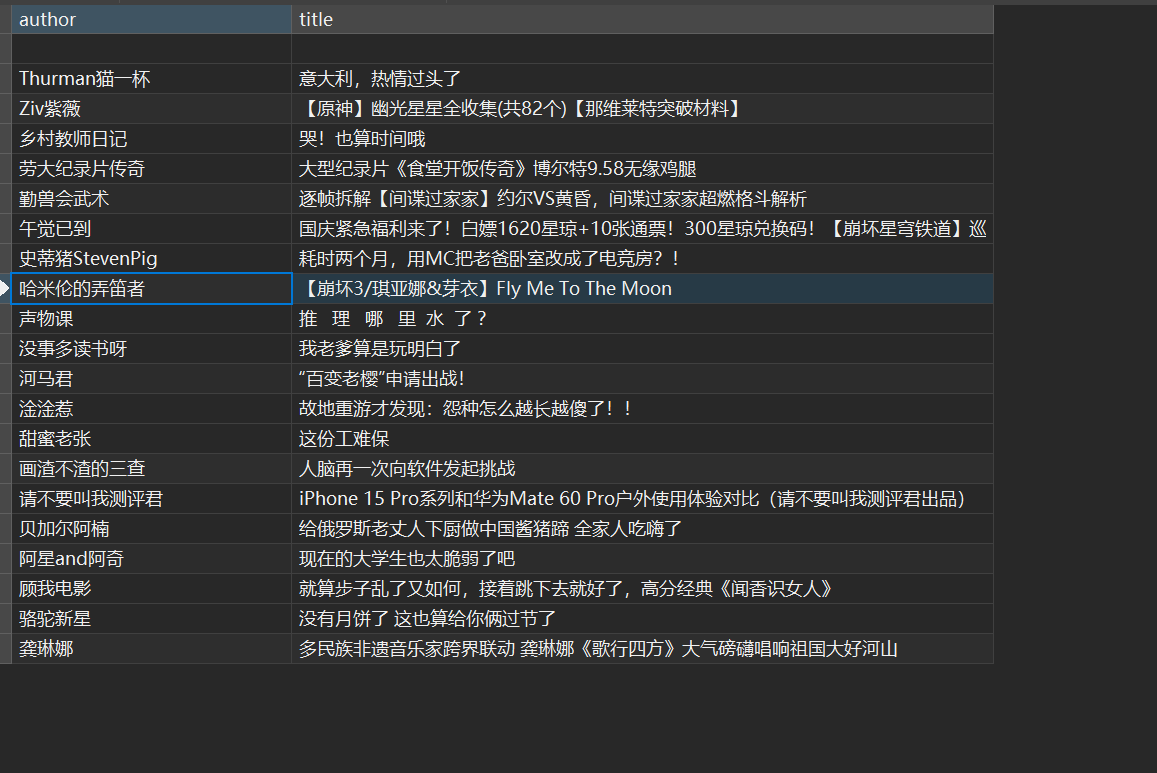
运行结果
在终端中输入scrapy crwal weibo后,得到数据库中的结果如下:
后记:
- 面试题:将爬取到的数据一份存储到本地一份存储到数据库,如何实现?
- 管道文件中一个管道类对应的是将数据存储到一种平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接受
- process_item中的return item表示将item传递给下一个即将被执行的管道类
相关文章:
python爬虫基于管道持久化存储操作
文章目录 基于管道持久化存储操作scrapy的使用步骤1.先转到想创建工程的目录下:cd ...2.创建一个工程3.创建之后要转到工程目录下4.在spiders子目录中创建一个爬虫文件5.执行工程setting文件中的参数 基于管道持久化存储的步骤:持久化存储1:保…...

【MySQL】数据类型(二)
文章目录 一. char字符串类型二. varchar字符串类型2.1 char和varchar比较 三. 日期和时间类型四. enum和set类型4.1 set的查询 结束语 一. char字符串类型 char (L) 固定长度字符串 L是可以存储的长度,单位是字符,最大长度是255 MySQL中的字符ÿ…...

基于Matlab实现连续模型求解方法
本文介绍了如何使用Matlab实现连续模型求解方法。首先,我们介绍了连续模型的概念,并明确了使用ODE和PDE求解器来求解常微分方程和偏微分方程的步骤。然后,我们通过一个简单的例子演示了如何将问题转化为数学模型,并使用Matlab编写…...

Tomcat 与 JDK 对应版本关系
对应关系 Tomcat版本 jdk版本11.0.x JDK 21及以后10.1.x JDK11及以后10.0.xJDK1.8及以后9.0.x JDK1.8及以后8.5.xJDK1.7及以后8.0.x JDK1.7及以后 查看对应关系方法: 登陆Tomcat官网:Apache Tomcat - Welcome! 结果:...
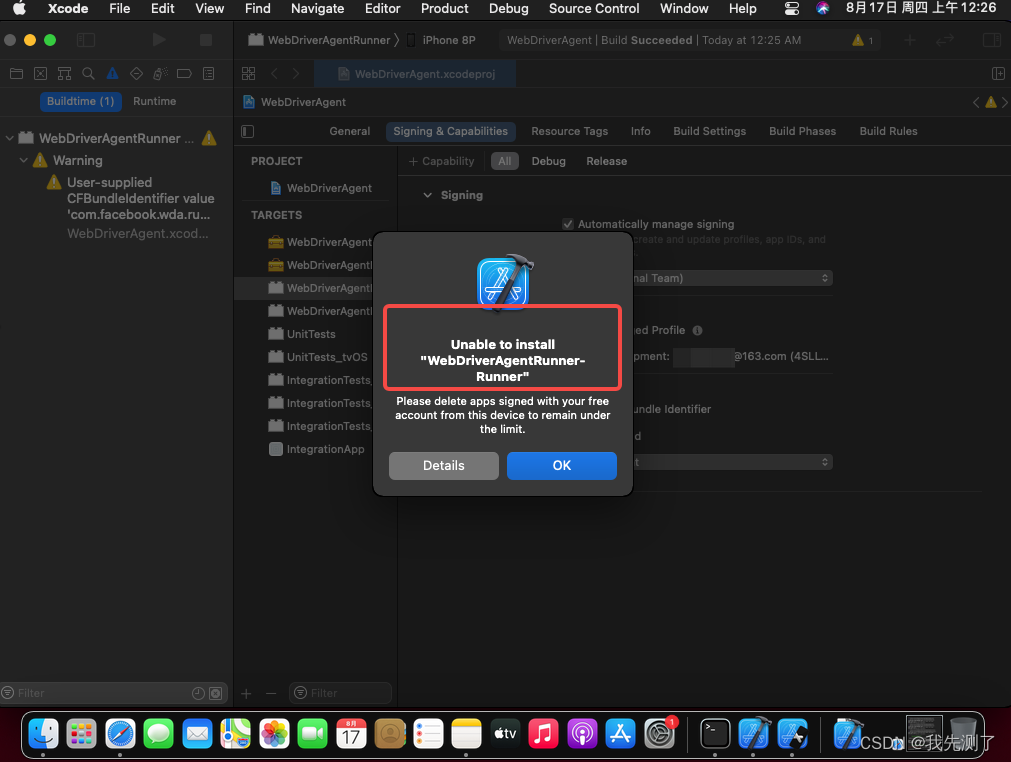
iOS自动化测试方案(二):Xcode开发者工具构建WDA应用到iphone
文章目录 一、环境准备1.1、软件环境1.2、硬件环境1.3、查看版本 二、安装WDA过程2.7、构建失败,这类错误有很多,比如在选择开发者账号后,就会提示:Failed to register bundle identifier表示应用唯一注册失败2.9、第二个错误,完全…...
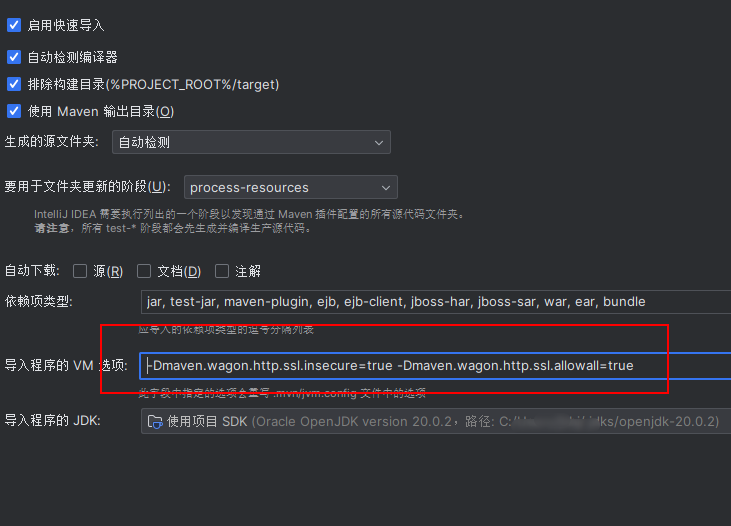
IDEA的Maven换源
前言 IDEA是个好东西,但是使用maven项目时可能会让人很难受,要么是非常慢,要么直接下载不了。所以我们需要给IDEA自带maven换源,保证我们的下载速度。 具体操作 打开IDEA安装路径,然后打开下面的文件夹 plugins\m…...
步进电机只响不转
我出现问题的原因是相位线接错。 我使用的滑台上示17H的步进电机,之前用的是57的步进电机。 57步进电机的相位线是A黑、A-绿、B红、B-蓝。 17步进电机的相位线是A红、A-绿、B黑、B-蓝。 这两天被一个问题困扰了好久,在调试步进电机开发板的时候电机发生…...

使用select实现服务器并发
select函数介绍: select 函数是一个用于在一组文件描述符上进行异步I/O多路复用的系统调用。它可以同时监视多个文件描述符,等待其中任何一个文件描述符准备就绪,然后进行相应的操作。 以下是select函数的原型: #include <…...

【Python】基于OpenCV人脸追踪、手势识别控制的求实之路FPS游戏操作
【Python】基于OpenCV人脸追踪、手势识别控制的求实之路FPS游戏操作 文章目录 手势识别人脸追踪键盘控制整体代码附录:列表的赋值类型和py打包列表赋值BUG复现代码改进优化总结 py打包 视频: 基于OpenCV人脸追踪、手势识别控制的求实之路FPS游戏操作 手…...

力扣 -- 718. 最长重复子数组
解题步骤: 参考代码: class Solution { public:int findLength(vector<int>& nums1, vector<int>& nums2) {int m nums1.size();int n nums2.size();//多开一行,多开一列vector<vector<int>> dp(m 1, ve…...
)
MP、MybatisPlus、联表查询、自定义sql、Constants.WRAPPER、ew (二)
描述: 给定一个id列表,更新对应列表中动物的年龄,使得年龄都较少一岁。 要求:使用条件构造器构造条件。 mapper: void updateAnimalAge(Param(Constants.WRAPPER) Wrapper<Animal> wrapper, Param("age&qu…...

Ubuntu服务器安全性提升:修改SSH默认端口号
在Ubuntu服务器上,SSH(Secure Shell)是一种至关重要的远程连接工具。它提供了一种安全的方式来远程连接和管理计算机系统,通过加密通信来确保数据的保密性和完整性。SSH协议广泛用于计算机网络中,用于远程管理、文件传…...

十七,IBL-打印各个Mipmap级别的hdr环境贴图
预滤波环境贴图类似于辐照度图,是预先计算的环境卷积贴图,但这次考虑了粗糙度。因为随着粗糙度的增加,参与环境贴图卷积的采样向量会更分散,导致反射更模糊,所以对于卷积的每个粗糙度级别,我们将按顺序把模…...

7、Docker网络
docker网络模式能干嘛? 容器间的互联和通信以及端口映射 容器IP变动时候可以通过服务名直接网络通信而不受到影响 docker 网络模式采用的是桥接模式,当我们创建了一个容器后docker网络就会帮我们创建一个虚拟网卡,这个虚拟网卡和我们的容器网…...
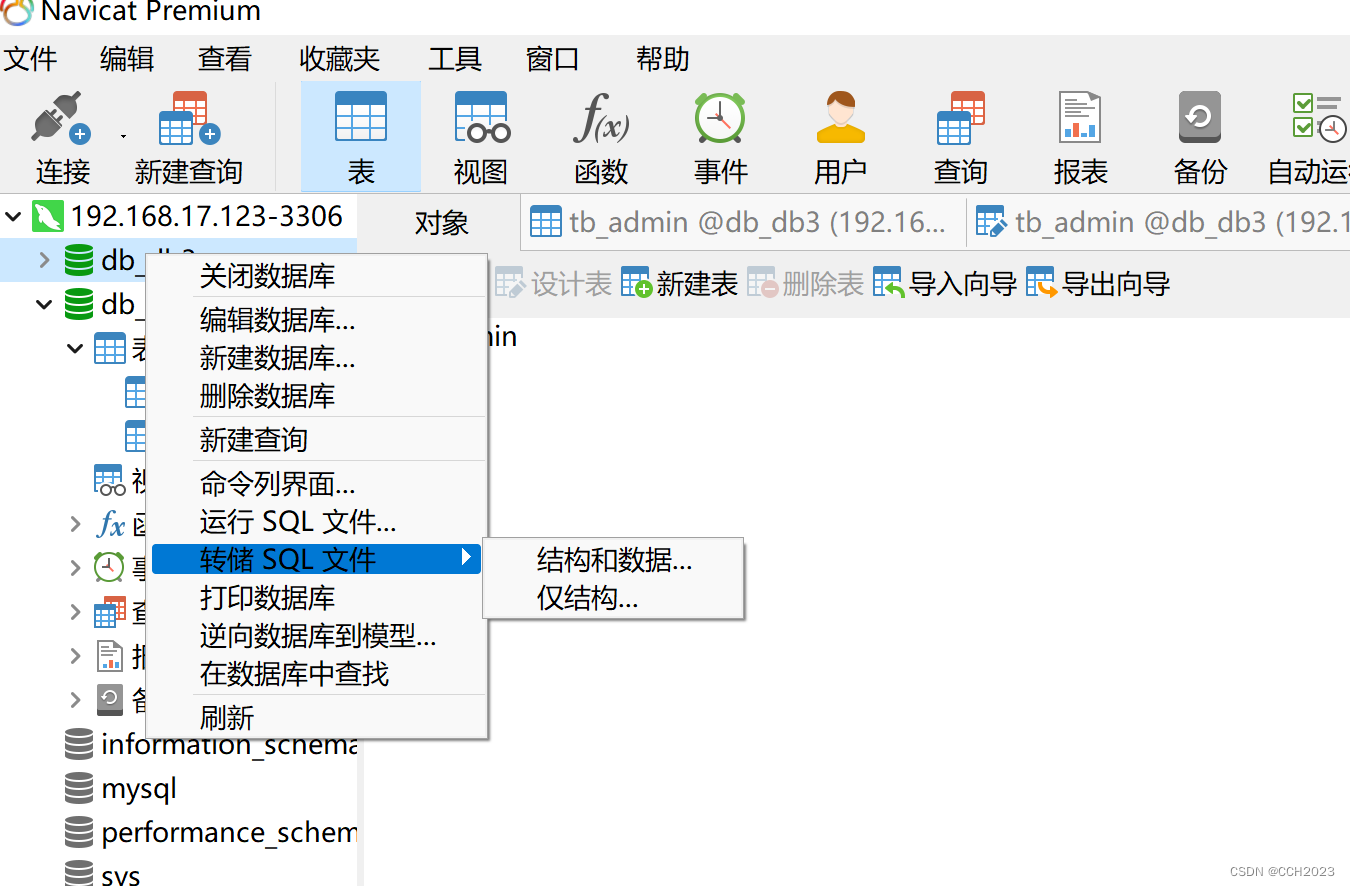
MySQL学习笔记23
逻辑备份: 1、回顾什么是逻辑备份? 逻辑备份就是把数据库、数据表或者数据进行导出,导出到一个文本文件中。 2、逻辑备份工具: mysqldump:提供全库级、数据库级别以及表级别的数据备份。 mysqldumpbinlogÿ…...

Java基础---第十篇
系列文章目录 文章目录 系列文章目录一、说说Java 中 IO 流二、 Java IO与 NIO的区别(补充)三、java反射的作用于原理一、说说Java 中 IO 流 Java 中 IO 流分为几种? 按照流的流向分,可以分为输入流和输出流; 按照操作单元划分,可以划分为字节流和字符流; 按照流的角色…...
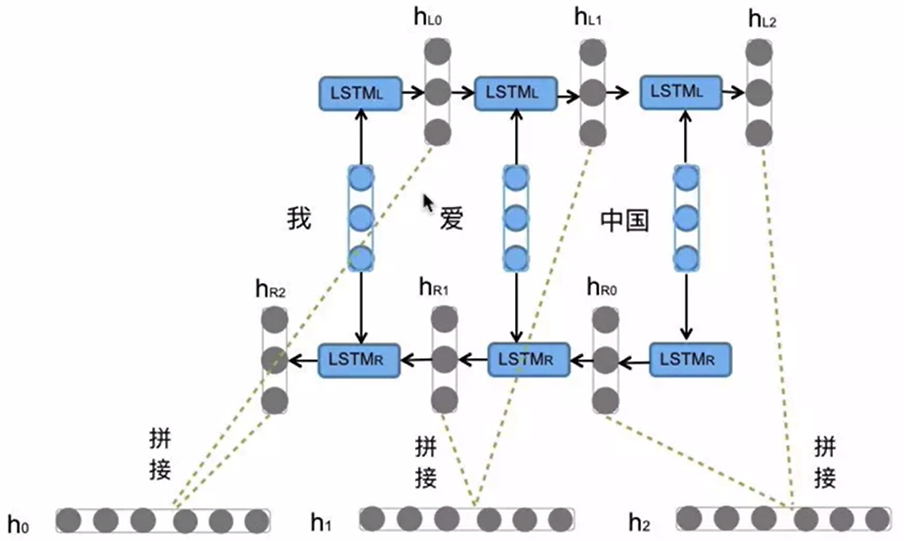
NLP 03(LSTM)
一、LSTM LSTM (Long Short-Term Memory) 也称长短时记忆结构,它是传统RNN的变体,与经典RNN相比: 能够有效捕捉长序列之间的语义关联缓解梯度消失或爆炸现象 LSTM的结构更复杂,它的核心结构可以分为四个部分去解析: 遗忘门、输入门、细胞状态、输出门 LSTM内部结构…...

Python集成开发环境(IDE):WingPro for Mac
WingPro for Mac是一款Python集成开发环境(IDE)软件,它提供了一系列强大的工具和功能,帮助Python开发人员提高开发效率和质量。 WingPro for Mac拥有直观的用户界面和强大的调试器,可以帮助用户快速定位问题和修复错误…...

[Machine learning][Part3] numpy 矢量矩阵操作的基础知识
很久不接触数学了,machine learning需要用到一些数学知识,这里在重温一下相关的数学基础知识 矢量 矢量是有序的数字数组。在表示法中,矢量用小写粗体字母表示。矢量的元素都是相同的类型。例如,矢量不包含字符和数字。数组中元…...

【中秋国庆不断更】HarmonyOS对通知类消息的管理与发布通知(上)
一、通知概述 通知简介 应用可以通过通知接口发送通知消息,终端用户可以通过通知栏查看通知内容,也可以点击通知来打开应用。 通知常见的使用场景: 显示接收到的短消息、即时消息等。显示应用的推送消息,如广告、版本更新等。显示…...

基于国产可控硅LTH16-08的电风扇无极调速方案设计与实践
1. 项目概述:当可控硅遇上电风扇 最近在帮一个做小家电的朋友优化一款电风扇的电路板,核心需求是想实现一个无极调速功能,让风扇的风量可以从微风到强风平滑过渡,而不是传统的三档或五档机械开关。这个需求听起来简单,…...

3步解决游戏手柄兼容性问题:XOutput完全指南
3步解决游戏手柄兼容性问题:XOutput完全指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否遇到过这样的尴尬时刻?心爱的旧手柄在最新游戏里毫无反应,或者新买…...
)
信通院:人工智能模数共振体系研究报告(2026年)
这份由中国信通院与中车工业研究院 2026 年 5 月发布的《人工智能模数共振体系研究报告(2026 年)》,聚焦数据与模型双向共振,系统阐释模数共振体系内涵、核心要素、能力支撑、协同机制并给出落地建议,为 AI 与实体经济…...

uView 2.0插件开发指南:如何扩展自定义组件与工具函数
uView 2.0插件开发指南:如何扩展自定义组件与工具函数 【免费下载链接】uView2.0 uView UI,是全面兼容nvue的uni-app生态框架,全面的组件和便捷的工具会让您信手拈来,如鱼得水 项目地址: https://gitcode.com/gh_mirrors/uv/uVi…...

免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南
免费开源鼠标连点器:5分钟上手跨平台自动化点击完整指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ࿰…...
: 对象引用、可变性和垃圾回收 - 深复制循环引用内存安全机制解析)
《流畅的Python》读书笔记07(补充03): 对象引用、可变性和垃圾回收 - 深复制循环引用内存安全机制解析
Python的copy.deepcopy()函数在处理循环引用时,通过内部的备忘录(memo)字典机制来打破无限递归,确保复制过程能够正确终止。这个memo字典本身的设计就考虑了内存管理的安全性,在正常情况下不会导致内存泄漏。其核心机制…...

深入剖析Golang环境搭建:从基础配置到高效开发实践
1. 项目概述:为什么Golang环境搭建值得深究?如果你刚接触Go语言,可能会觉得“环境搭建”不就是下载、安装、配个变量吗?网上教程一搜一大把,五分钟搞定。但作为一名在多个生产环境中部署过Go服务的老兵,我必…...

零基础学 Web 安全 20256最全系统入门攻略
“未知攻,焉知防”——真正的安全始于理解攻击者的思维 在日益数字化的世界中,Web安全工程师已成为企业防护体系的“数字盾牌”。本文将提供一条清晰的进阶路径,助你在2025年的网络安全领域脱颖而出。 一、认知篇:理解安全本质 …...

Java SSRF漏洞深度解析:从URLConnection安全风险到多层防御实战
1. 项目概述:从两个看似简单的API说起在Java开发中,URLConnection和openStream()这两个方法几乎是每个开发者入门网络编程时最早接触的API。它们简单、直观,几行代码就能实现从网络获取数据的功能。然而,正是这种“简单易用”的特…...

别再手动画图了!用Mermaid+Markdown在VSCode里5分钟搞定UML设计文档
用文本驱动设计:现代开发者的UML高效实践指南 在技术文档中清晰表达系统设计是每个开发者的必修课。传统UML工具往往需要频繁切换鼠标键盘,拖拽调整元素位置,保存后再手动插入文档——这种工作流不仅低效,更让设计文档与代码库脱节…...