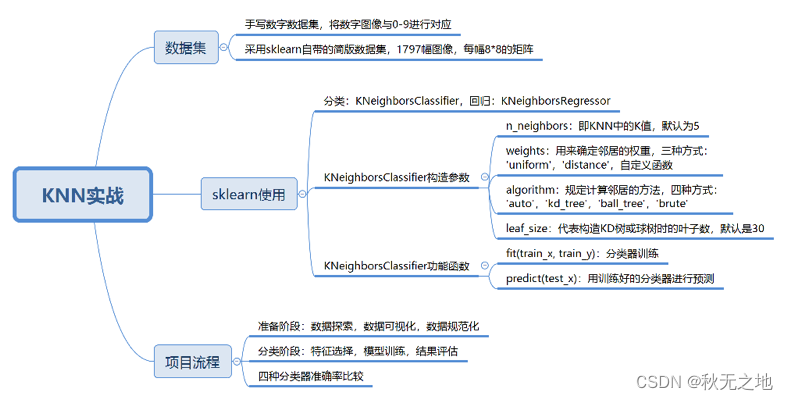
KNN(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬、关注🤝,关注必回关
上一篇文章已经跟大家介绍过《KNN(上):数据分析 | 数据挖掘 | 十大算法之一》,相信大家对KNN(上)都有一个基本的认识。下面我讲一下,KNN(下):数据分析 | 数据挖掘 | 十大算法之一
KNN 实际上是计算待分类物体与其他物体之间的距离,然后通过统计最近的 K 个邻居的分类情况,来决定这个物体的分类情况。
一、如何在 sklearn 中使用 KNN
在 Python 的 sklearn 工具包中有 KNN 算法。KNN 既可以做分类器,也可以做回归。如果是做分类,你需要引用:
from sklearn.neighbors import KNeighborsClassifier如果是做回归,你需要引用:
from sklearn.neighbors import KNeighborsRegressor从名字上你也能看出来 Classifier 对应的是分类,Regressor 对应的是回归。一般来说如果一个算法有 Classifier 类,都能找到相应的 Regressor 类。比如在决策树分类中,你可以使用 DecisionTreeClassifier,也可以使用决策树来做回归 DecisionTreeRegressor。
好了,我们看下如何在 sklearn 中创建 KNN 分类器。
这里,我们使用构造函数 KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’, leaf_size=30),这里有几个比较主要的参数,我分别来讲解下:
1.n_neighbors:即 KNN 中的 K 值,代表的是邻居的数量。K 值如果比较小,会造成过拟合。如果 K 值比较大,无法将未知物体分类出来。一般我们使用默认值 5。
2.weights:是用来确定邻居的权重,有三种方式:
- weights=uniform,代表所有邻居的权重相同;
- weights=distance,代表权重是距离的倒数,即与距离成反比;
- 自定义函数,你可以自定义不同距离所对应的权重。大部分情况下不需要自己定义函数。
3.algorithm:用来规定计算邻居的方法,它有四种方式:
- algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择 auto;
- algorithm=kd_tree,也叫作 KD 树,是多维空间的数据结构,方便对关键数据进行检索,不过 KD 树适用于维度少的情况,一般维数不超过 20,如果维数大于 20 之后,效率反而会下降;
- algorithm=ball_tree,也叫作球树,它和 KD 树一样都是多维空间的数据结果,不同于 KD 树,球树更适用于维度大的情况;
- algorithm=brute,也叫作暴力搜索,它和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低。
4.leaf_size:代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度。
创建完 KNN 分类器之后,我们就可以输入训练集对它进行训练,这里我们使用 fit() 函数,传入训练集中的样本特征矩阵和分类标识,会自动得到训练好的 KNN 分类器。然后可以使用 predict() 函数来对结果进行预测,这里传入测试集的特征矩阵,可以得到测试集的预测分类结果。
二、如何用 KNN 对手写数字进行识别分类
手写数字数据集是个非常有名的用于图像识别的数据集。数字识别的过程就是将这些图片与分类结果 0-9 一一对应起来。完整的手写数字数据集 MNIST 里面包括了 60000 个训练样本,以及 10000 个测试样本。如果你学习深度学习的话,MNIST 基本上是你接触的第一个数据集。
今天我们用 sklearn 自带的手写数字数据集做 KNN 分类,你可以把这个数据集理解成一个简版的 MNIST 数据集,它只包括了 1797 幅数字图像,每幅图像大小是 8*8 像素。
好了,我们先来规划下整个 KNN 分类的流程:

整个训练过程基本上都会包括三个阶段:
- 数据加载:我们可以直接从 sklearn 中加载自带的手写数字数据集;
- 准备阶段:在这个阶段中,我们需要对数据集有个初步的了解,比如样本的个数、图像长什么样、识别结果是怎样的。你可以通过可视化的方式来查看图像的呈现。通过数据规范化可以让数据都在同一个数量级的维度。另外,因为训练集是图像,每幅图像是个 8*8 的矩阵,我们不需要对它进行特征选择,将全部的图像数据作为特征值矩阵即可;
- 分类阶段:通过训练可以得到分类器,然后用测试集进行准确率的计算。
好了,按照上面的步骤,我们一起来实现下这个项目。
首先是加载数据和对数据的探索:
# 加载数据
digits = load_digits()
data = digits.data
# 数据探索
print(data.shape)
# 查看第一幅图像
print(digits.images[0])
# 第一幅图像代表的数字含义
print(digits.target[0])
# 将第一幅图像显示出来
plt.gray()
plt.imshow(digits.images[0])
plt.show()运行结果:
(1797, 64)
[[ 0. 0. 5. 13. 9. 1. 0. 0.][ 0. 0. 13. 15. 10. 15. 5. 0.][ 0. 3. 15. 2. 0. 11. 8. 0.][ 0. 4. 12. 0. 0. 8. 8. 0.][ 0. 5. 8. 0. 0. 9. 8. 0.][ 0. 4. 11. 0. 1. 12. 7. 0.][ 0. 2. 14. 5. 10. 12. 0. 0.][ 0. 0. 6. 13. 10. 0. 0. 0.]]
0
我们对原始数据集中的第一幅进行数据可视化,可以看到图像是个 8*8 的像素矩阵,上面这幅图像是一个“0”,从训练集的分类标注中我们也可以看到分类标注为“0”。
sklearn 自带的手写数字数据集一共包括了 1797 个样本,每幅图像都是 8*8 像素的矩阵。因为并没有专门的测试集,所以我们需要对数据集做划分,划分成训练集和测试集。因为 KNN 算法和距离定义相关,我们需要对数据进行规范化处理,采用 Z-Score 规范化,代码如下:
# 分割数据,将25%的数据作为测试集,其余作为训练集(你也可以指定其他比例的数据作为训练集)
train_x, test_x, train_y, test_y = train_test_split(data, digits.target, test_size=0.25, random_state=33)
# 采用Z-Score规范化
ss = preprocessing.StandardScaler()
train_ss_x = ss.fit_transform(train_x)
test_ss_x = ss.transform(test_x)然后我们构造一个 KNN 分类器 knn,把训练集的数据传入构造好的 knn,并通过测试集进行结果预测,与测试集的结果进行对比,得到 KNN 分类器准确率,代码如下:
# 创建KNN分类器
knn = KNeighborsClassifier()
knn.fit(train_ss_x, train_y)
predict_y = knn.predict(test_ss_x)
print("KNN准确率: %.4lf" % accuracy_score(test_y, predict_y))运行结果:
KNN准确率: 0.9756好了,这样我们就构造好了一个 KNN 分类器。之前我们还讲过 SVM、朴素贝叶斯和决策树分类。我们用手写数字数据集一起来训练下这些分类器,然后对比下哪个分类器的效果更好。代码如下:
# 创建SVM分类器
svm = SVC()
svm.fit(train_ss_x, train_y)
predict_y=svm.predict(test_ss_x)
print('SVM准确率: %0.4lf' % accuracy_score(test_y, predict_y))
# 采用Min-Max规范化
mm = preprocessing.MinMaxScaler()
train_mm_x = mm.fit_transform(train_x)
test_mm_x = mm.transform(test_x)
# 创建Naive Bayes分类器
mnb = MultinomialNB()
mnb.fit(train_mm_x, train_y)
predict_y = mnb.predict(test_mm_x)
print("多项式朴素贝叶斯准确率: %.4lf" % accuracy_score(test_y, predict_y))
# 创建CART决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(train_mm_x, train_y)
predict_y = dtc.predict(test_mm_x)
print("CART决策树准确率: %.4lf" % accuracy_score(test_y, predict_y))运行结果如下:
SVM准确率: 0.9867
多项式朴素贝叶斯准确率: 0.8844
CART决策树准确率: 0.8556这里需要注意的是,我们在做多项式朴素贝叶斯分类的时候,传入的数据不能有负数。因为 Z-Score 会将数值规范化为一个标准的正态分布,即均值为 0,方差为 1,数值会包含负数。因此我们需要采用 Min-Max 规范化,将数据规范化到[0,1]范围内。
好了,我们整理下这 4 个分类器的结果。

你能看出来 KNN 的准确率还是不错的,和 SVM 不相上下。
你可以自己跑一遍整个代码,在运行前还需要 import 相关的工具包(下面的这些工具包你都会用到,所以都需要引用):
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt代码中,我使用了 train_test_split 做数据集的拆分,使用 matplotlib.pyplot 工具包显示图像,使用 accuracy_score 进行分类器准确率的计算,使用 preprocessing 中的 StandardScaler 和 MinMaxScaler 做数据的规范化。
三、总结
今天我带你一起做了手写数字分类识别的实战,分别用 KNN、SVM、朴素贝叶斯和决策树做分类器,并统计了四个分类器的准确率。在这个过程中你应该对数据探索、数据可视化、数据规范化、模型训练和结果评估的使用过程有了一定的体会。在数据量不大的情况下,使用 sklearn 还是方便的。
如果数据量很大,比如 MNIST 数据集中的 6 万个训练数据和 1 万个测试数据,那么采用深度学习 +GPU 运算的方式会更适合。因为深度学习的特点就是需要大量并行的重复计算,GPU 最擅长的就是做大量的并行计算。
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。
相关文章:
KNN(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

Servlet开发-session和cookie理解案例-登录页面
项目展示 进入登录页面,输入正确的用户名和密码以后会自动跳到主页 登录成功以后打印用户名以及上次登录的时间,如果浏览器和客户端都保存有上次登录的信息,则不需要登录就可以进入主页 编码思路 1.首先提供一个登录的前端页面&…...
Polygon Miden:扩展以太坊功能集的ZK-optimized rollup
1. 引言 Polygon Miden定位为zkVM,定于2023年Q4上公开测试网。 zk、zkVM、zkEVM及其未来中指出,当前主要有3种类型的zkVM,括号内为其相应的指令集: mainstream(WASM, RISC-V)EVM(EVM bytecod…...

[题]宝物筛选 #单调队列优化
五、宝物筛选(洛谷P1776) 题目链接 好家伙,找到了一个之前学习多重背包优化时的错误…… 之前记的笔记还是很有用的…… #include<bits/stdc.h> using namespace std; const int N 1e5 10; int f[N]; int n, m; int v, w, s; int l…...

.NET的键盘Hook管理类,用于禁用键盘输入和切换
一、MyHook帮助类 此类需要编写指定屏蔽的按键,灵活性差。 using System; using System.Runtime.InteropServices; using System.Diagnostics; using System.Windows.Forms; using Microsoft.Win32;namespace MyHookClass {/// <summary>/// 类一/// </su…...

Anaconda Jupyter
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言An…...
Unity中Shader的前向渲染路径ForwardRenderingPath
文章目录 前言一、前向渲染路径的特点二、渲染方式1、逐像素(效果最好)2、逐顶点(效果次之)3、SH球谐(效果最差) 三、Unity中对灯光设置 后,自动选择对应的渲染方式1、ForwardBase仅用于一个逐像素的平行灯,以及所有的逐顶点与SH2、ForwardAdd用于其他所…...

简历项目优化关键方法论-START
START方法论是非常著名的面试法则,经常被面试官使用的工具 Situation:情况、事情、项目需求是在什么情况下发生Task:任务,你负责的做的是什么Action:动作,针对这样的情况分析,你采用了什么行动方式Result:结果,在这样…...
TensorFlow学习1:使用官方模型进行图片分类
前言 人工智能以后会越来越发达,趁着现在简单学习一下。机器学习框架有很多,这里觉得学习谷歌的 TensorFlow,谷歌的技术还是很有保证的,另外TensorFlow 的中文文档真的很友好。 文档: https://tensorflow.google.cn/…...
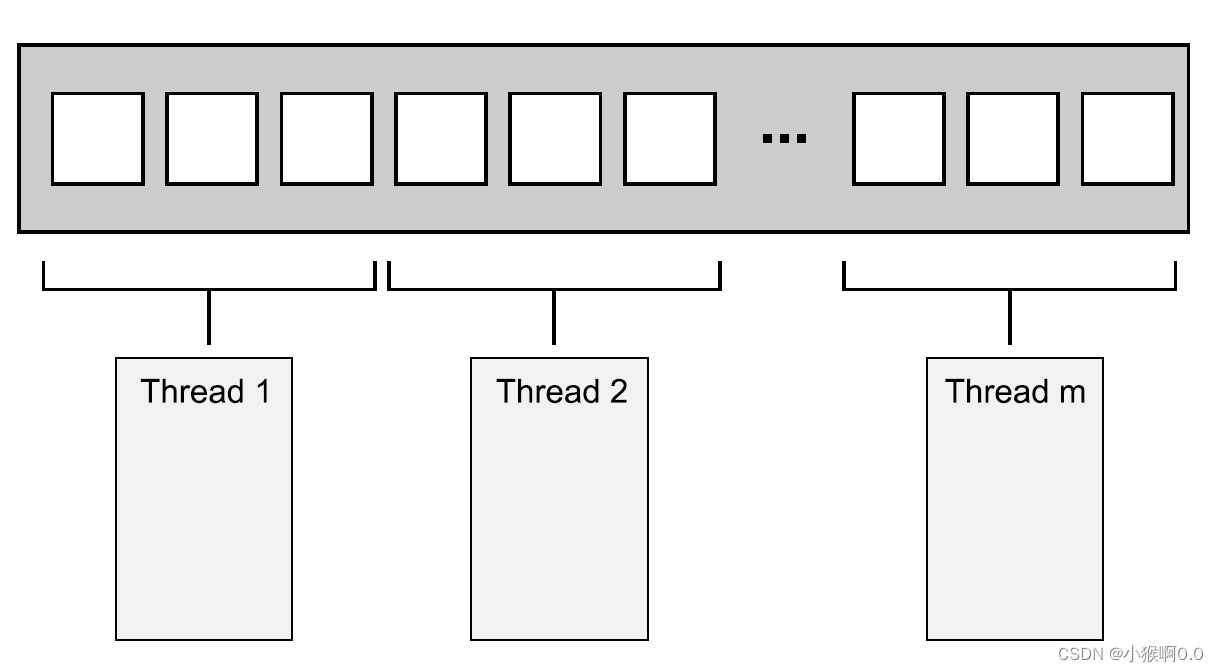
C++ 并发编程实战 第八章 设计并发代码 一
目录 8.1 在线程间切分任务 8.1.1 先在线程间切分数据,再开始处理 8.1.2 以递归方式划分数据 8.1.3 依据工作类别划分任务 借多线程分离关注点需防范两大风险 在线程间按流程划分任务 8.2 影响并发性能的因素 8.2.1 处理器的数量 8.2.2 数据竞争和缓存兵乓…...
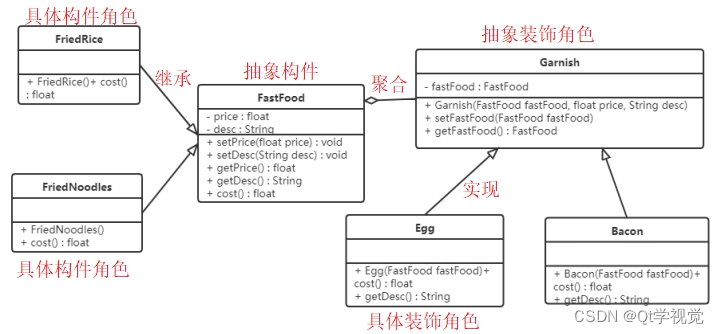
设计模式8、装饰者模式 Decorator
解释说明:动态地给一个对象增加一些额外的职责。就扩展功能而言,装饰模式提供了一种比使用子类更加灵活的替代方案 抽象构件(Component):定义一个抽象接口以规范准备收附加责任的对象 具体构件(ConcreteCom…...
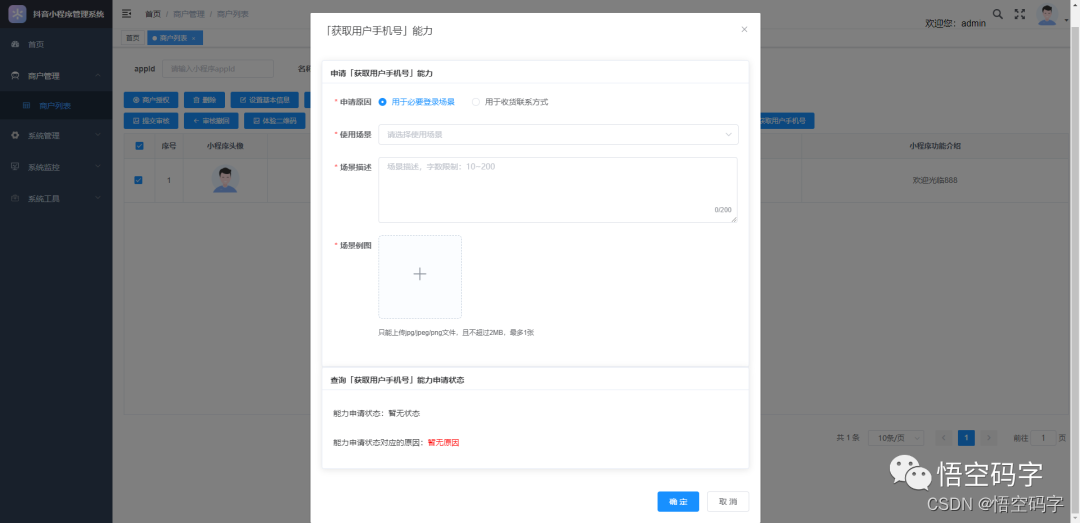
抖音开放平台第三方代小程序开发,一整套流程
大家好,我是小悟 抖音小程序第三方平台开发着力于解决抖音生态体系内的小程序管理问题,一套模板,随处部署。能尽可能地减少服务商的开发成本,服务商只用开发一套小程序代码作为模板就可以快速批量的孵化出大量的商家小程序。 第…...

Flutter笔记:滚动之-无限滚动与动态加载的实现(GetX简单状态管理版)
Flutter笔记 无限滚动与动态加载的实现(GeX简单状态管理版) 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq…...

前端架构师之02_ES6_高级
1 类和继承 1.1 class类 JavaScript 语言中,生成实例对象的传统方法是通过构造函数。 // ES5 创建对象 // 创建一个类,用户名 密码 function User(name,pass){// 添加属性this.name name;this.pass pass; } // 用 原型 添加方法 User.prototype.sho…...

VScode多文件编译/调试配置
之前都是在Visual Studio写C/C,最近想换到VScode,折腾半天把launch.json和tasks.json配好了(虽然不懂为什么,但确实能用了),在此做个记录。 参考资料:1,2,3 环境&#…...
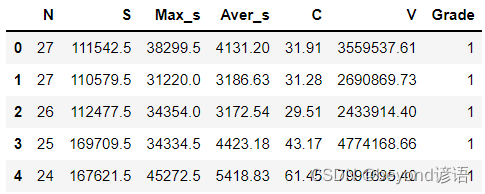
K折交叉验证——cross_val_score函数使用说明
在机器学习中,许多算法中多个超参数,超参数的取值不同会导致结果差异很大,如何确定最优的超参数?此时就需要进行交叉验证的方法,sklearn给我们提供了相应的cross_val_score函数,可对数据集进行交叉验证划分…...
2023.09.30使用golang1.18编译Hel10-Web/Databasetools的windows版
#Go 1.21新增的 log/slog 完美解决了以上问题,并且带来了很多其他很实用的特性。 本次编译不使用log/slog 包 su - echo $GOPATH ;echo $GOROOT; cd /tmp; busybox wget --no-check-certificate https://go.dev/dl/go1.18.linux-amd64.tar.gz;\ which tar&&am…...

React简介
react作为前端主流框架之一,因其语法接近原生JavaScript语法而广受欢迎。其生态丰富,常用的就有react-router、react-redux等插件,还有与其匹配的UI组件库antd。而且其还有用于移动端开发的react-native库,因此,react值…...
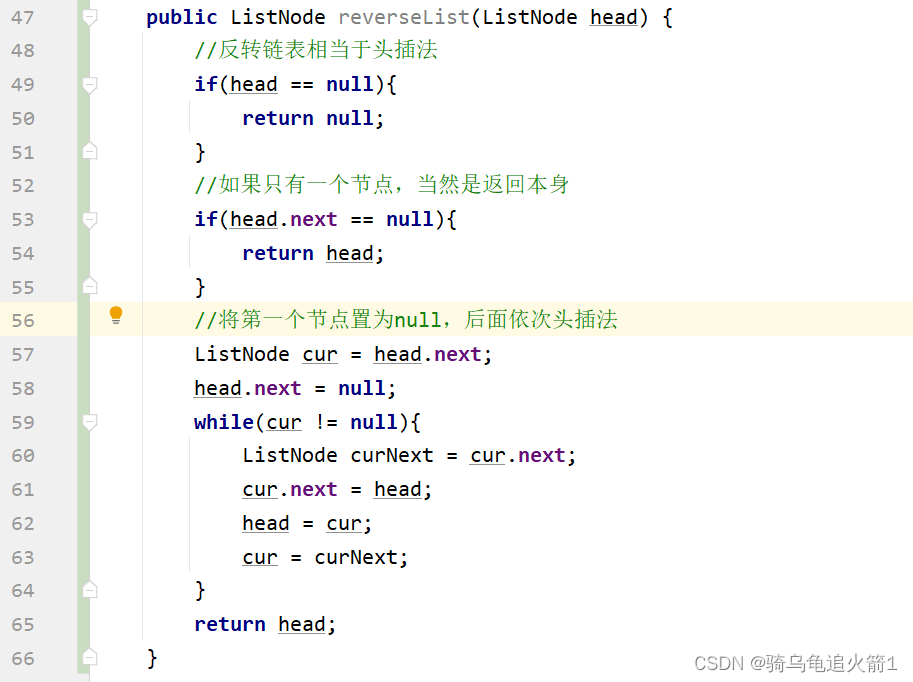
链表经典面试题(一)
面试题 1.反转链表的题目2.反转链表的图文分析3.反转链表的代码实现 1.反转链表的题目 2.反转链表的图文分析 我们在实现反转链表的时候,是将后面的元素变前面,前面的元素变后面,那么我们是否可以理解为,用头插法的思想来完成反转链表呢&…...

体验亚马逊的 CodeWhisperer 感觉
CodeWhisperer 是亚马逊推出的辅助编程工具,在程序员写代码时,它能根据其内容生成多种代码建议。 CodeWhisperer 目前已支持近10几种语言,我是用 java 语言,用的开发工具是 idea,说一下我用的情况。 亚马逊云科技开发…...

想入行5G网络优化工程师?这6个求职陷阱你必须知道
5G网络优化工程师由于其入职门槛低,需求高,成为了不少想转行的人关注的岗位。 但对于刚入行的小白来说,求职路上往往布满陷阱。 作为一名行业接触过一些内幕的过来人,总结了6条找工作的核心建议,希望能帮大家少走弯路…...

Claude官方Skills推荐
Claude官方skills仓库提供了17个skills### 创意设计类 (5个) #### 1. algorithmic-art - 算法艺术生成器**一句话简介**:使用 p5.js 创建带种子随机数和参数探索的算法艺术 **触发条件**:代码艺术、生成艺术、算法艺术、流场、粒子系统#### 2. canvas-de…...

深度解析Windows微信自动化:Wechaty Puppet XP零成本架构设计与实战指南
深度解析Windows微信自动化:Wechaty Puppet XP零成本架构设计与实战指南 【免费下载链接】puppet-xp Wechaty Puppet WeChat Windows Protocol 项目地址: https://gitcode.com/gh_mirrors/pu/puppet-xp 在即时通讯自动化领域,Windows平台微信机器…...
)
SEO_2024年最新SEO策略与趋势深度解析(162 )
<h1 id"2024seo">2024年最新SEO策略与趋势深度解析</h1> <h2 id"seo">前言:SEO的重要性不减速</h2> <p>在数字化时代,网络已成为信息传播、商业营销和客户互动的重要平台。搜索引擎优化(S…...

项目管理工具怎么选?8款主流产品测评与选型建议
项目管理工具怎么选?真正需要比较的,不只是功能多少,而是它是否适合团队的协作方式、项目复杂度和管理阶段。本文围绕场景匹配、流程灵活性、信息沉淀、管理视图和落地成本,对8款主流项目管理工具做一轮顾问式测评。引言很多企业在…...

基于Spring AI的MCP服务开发实战指南
1. Spring AI与MCP服务初探 第一次接触Spring AI框架时,我就被它简洁优雅的API设计所吸引。作为Spring生态中专门为AI应用开发提供的工具集,它让Java开发者能够像开发普通Web应用一样轻松构建AI服务。而MCP(Model Calling Protocol࿰…...

I2CLCD驱动库:HD44780字符屏的I²C轻量级嵌入式适配方案
1. I2CLCD库概述:面向嵌入式系统的字符型LCD IC适配驱动I2CLCD是一个轻量级、可移植的C语言驱动库,专为将标准HD44780兼容的字符型LCD(如1602、2004)通过IC总线接入MCU而设计。其核心价值在于消除并行接口对GPIO资源的高占用&…...

基于Matlab的11种图像清晰度评价指标:直接可运行,联系我
基于matlab图像清晰度评价指标。 一共11种。 程序已调通,可直接运行。 需要直接联系。 基于matlab图像清晰度评价指标。 一共11种。 程序已调通,可直接运行。 需要直接联系。 图像剃度的清晰度评价(EOG, Roberts, Tenengrad, Brenner,Variance, Laplace,…...
)
从Flask裸奔到MCP标准落地:7步迁移指南+自动转换脚本(已验证支撑日均50万次Agent调用)
第一章:Python MCP 服务器开发模板概览与核心价值Python MCP(Model-Controller-Protocol)服务器开发模板是一套面向协议驱动微服务架构的轻量级开发框架,专为快速构建符合 MCP 规范的 AI 工具集成后端而设计。它抽象了协议适配、会…...

别再手动写RTL了!用Vivado FIR Compiler IP核5分钟搞定一个低通滤波器
5分钟极速部署:用Vivado FIR Compiler IP核实现专业级低通滤波器 在FPGA信号处理领域,滤波器设计往往需要耗费工程师大量时间在RTL编码和验证上。但今天,我们将颠覆这一传统工作流程——通过Vivado的FIR Compiler IP核,即使没有深…...