深度学习 二:COVID 19 Cases Prediction (Regression)
Deep Learning
- 1. 回归算法思路
- 2. 代码
- 2.1 基础操作
- 2.2 定义相关函数
- 2.3.1 定义图像绘制函数
- 2.3.2 数据集加载及预处理
- 2.3.3 构造数据加载器
- 2.3.4 构建前馈神经网络(Feedforward Neural Network)模型
- 2.3.5 神经网络的训练过程
- 2.3.6 模型评估
- 2.3.7 模型测试
- 2.3.8 模型初始化
- 2.3 模型运行
1. 回归算法思路
基于3层神经网络的回归优化
2. 代码
2.1 基础操作
切换文件路径,并创建新的文件夹:
%cd /content/drive/MyDrive
#change directory to google drive
#!mkdir ML2023
#make a directory named ML2023
%cd ./ML2023
#change directory to ML2023
/content/drive/MyDrive
/content/drive/MyDrive/ML2023
查看当前路径下的文件:
!ls
covid.test.csv covid.train.csv models
显示当前文件路径:
!pwd #output the current directory
/content/drive/MyDrive/ML2023
文件下载:
# Download Data
tr_path = 'covid.train.csv' # path to training data
tt_path = 'covid.test.csv' # path to testing data!gdown --id '19CCyCgJrUxtvgZF53vnctJiOJ23T5mqF' --output covid.train.csv
!gdown --id '1CE240jLm2npU-tdz81-oVKEF3T2yfT1O' --output covid.test.csv
Downloading…
From: https://drive.google.com/uc?id=19CCyCgJrUxtvgZF53vnctJiOJ23T5mqF
To: /content/covid.train.csv
100% 2.00M/2.00M [00:00<00:00, 31.7MB/s]
Downloading…
From: https://drive.google.com/uc?id=1CE240jLm2npU-tdz81-oVKEF3T2yfT1O
To: /content/covid.test.csv
100% 651k/651k [00:00<00:00, 10.2MB/s]
导入所需要的相关包:
# Import Some Packages
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# For data preprocess
import numpy as np
import csv
import os# For plotting
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure# For feature selection
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_regression
2.2 定义相关函数
2.3.1 定义图像绘制函数
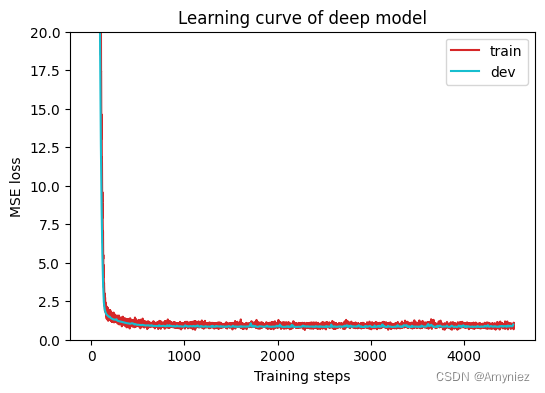
def get_device():''' Get device (if GPU is available, use GPU) '''return 'cuda' if torch.cuda.is_available() else 'cpu'def plot_learning_curve(loss_record, title=''):''' Plot learning curve of your DNN (train & dev loss) dev:development'''total_steps = len(loss_record['train']) #x_1 = range(total_steps)figure(figsize=(6, 4))plt.plot(x_1, loss_record['train'], c='tab:red', label='train')if len(loss_record['dev'])!=0:x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])] # 计算步长,保持训练集和开发集步长一致plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')plt.ylim(0.0, 20.0) # 设置纵坐标的范围,将其限制在0.0到20.0之间plt.xlabel('Training steps')plt.ylabel('MSE loss') # RMSE?plt.title('Learning curve of {}'.format(title))plt.legend()plt.show()# 绘制预测结果的散点图
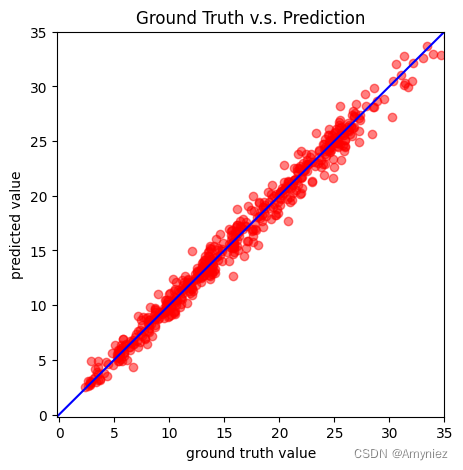
def plot_pred(dv_set, model, device, lim=35., preds=None, targets=None):# dv_set:开发集(或验证集)的数据集,包含输入特征和实际目标值。# model:训练好的深度神经网络模型,用于进行预测。# device:指定模型在哪个设备上运行,通常是CPU或GPU。# lim:横纵坐标的限制范围,默认为35。# preds:模型的预测值(可选参数),如果未提供,则会重新计算。# targets:实际目标值(可选参数),如果未提供,则会重新获取''' Plot prediction of your DNN '''if preds is None or targets is None:model.eval()preds, targets = [], []for x, y in dv_set: # x是输入特征,y是实际目标值x, y = x.to(device), y.to(device)with torch.no_grad():pred = model(x)preds.append(pred.detach().cpu())targets.append(y.detach().cpu())preds = torch.cat(preds, dim=0).numpy()targets = torch.cat(targets, dim=0).numpy()figure(figsize=(5, 5))plt.scatter(targets, preds, c='r', alpha=0.5)plt.plot([-0.2, lim], [-0.2, lim], c='b')plt.xlim(-0.2, lim)plt.ylim(-0.2, lim)plt.xlabel('ground truth value')plt.ylabel('predicted value')plt.title('Ground Truth v.s. Prediction')plt.show()
2.3.2 数据集加载及预处理
class COVID19Dataset(Dataset):''' Dataset for loading and preprocessing the COVID19 dataset '''# target_only:一个布尔值,表示是否仅使用目标特征(在这里是最后一列)# 如果target_only为True,则只选择目标特征,否则选择一组特定的特征def __init__(self,path,mode='train',target_only=False):self.mode = mode# Read data into numpy arrayswith open(path, 'r') as fp:data = list(csv.reader(fp))data = np.array(data[1:])[:, 1:].astype(float) # 切片操作去掉第1列和行if not target_only:feats = list(range(93)) # 一共94个特征,但是需要除去最后一个特征,最后一个特征是用来预测的else:# TODO: Using 40 states & 2 tested_positive features (indices = 57 & 75)!!!# 使用硬编码feats = [40, 41, 42, 43, 57, 58, 59, 60, 61, 75, 76, 77, 78, 79] # sklean mutual infoif mode == 'test':# Testing data# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))data = data[:, feats]self.data = torch.FloatTensor(data)else:# Training data (train/dev sets)# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))target = data[:, -1]data = data[:, feats]# 整个train+dev一起mean/stdself.mean = torch.FloatTensor(data).mean(dim=0, keepdim=True) # 计算张量中每列的均值# keepdim=True保持结果的维度与输入张量相同,结果将仍然是一个包含均值的张量,但它将具有与每列相同的维度self.std = torch.FloatTensor(data).std(dim=0, keepdim=True)# Splitting training data into train & dev setsif mode == 'train':indices = [i for i in range(len(data)) if i % 5 != 0]elif mode == 'dev':indices = [i for i in range(len(data)) if i % 5 == 0]# Convert data into PyTorch tensorsself.data = torch.FloatTensor(data[indices])self.target = torch.FloatTensor(target[indices])self.dim = self.data.shape[1] # 获取数据集self.data的列数,也就是特征的数量print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'.format(mode, len(self.data), self.dim))# All subclasses should overwrite __getitem__, # supporting fetching a data sample for a given key. def __getitem__(self, index):# Returns one sample at a timeif self.mode in ['train', 'dev']:# For trainingreturn self.data[index], self.target[index]else:# For testing (no target)return self.data[index]def __len__(self):# Returns the size of the datasetreturn len(self.data)def normalization(self, mean=None, std=None):# Normalize features (you may remove this part to see what will happen)# The mean and standard variance of training data will be reused to normalize testing data.if self.mode == 'train' or self.mode =='dev':mean = self.meanstd = self.stdself.data = (self.data-mean) / stdelse:self.data = (self.data-mean) / stdreturn mean, stdZ-Score 标准化(标准差标准化): 将数据缩放到均值为0,标准差为1的标准正态分布
-
计算特征的均值(mean):
μ = 1 N ∑ i = 1 N x i \mu = \frac{1}{N} \sum_{i=1}^{N} x_i μ=N1∑i=1Nxi -
计算特征的标准差(standard deviation):
σ = 1 N ∑ i = 1 N ( x i − μ ) 2 \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} σ=N1∑i=1N(xi−μ)2 -
对每个数据点 x i x_i xi,应用以下标准化公式:
z i = x i − μ σ z_i = \frac{x_i - \mu}{\sigma} zi=σxi−μ -
数据的均值为0,即标准化后的数据集的均值接近于0。
-
数据的标准差为1,即标准化后的数据集的标准差接近于1。
-
数据的分布形状不会改变,只是尺度和位置发生了变化。
Z-Score 标准化适用于许多统计和机器学习算法,特别是对于需要计算距离或涉及梯度下降等数值计算的算法。通过标准化,可以确保不同特征的尺度不会对模型的训练产生不适当的影响,帮助模型更快地收敛并提高性能。
Min-Max 标准化(最小-最大值缩放):
-
计算特征的最小值: x min = min ( x 1 , x 2 , … , x N ) x_{\text{min}} = \min(x_1, x_2, \ldots, x_N) xmin=min(x1,x2,…,xN)
-
计算特征的最大值: x max = max ( x 1 , x 2 , … , x N ) x_{\text{max}} = \max(x_1, x_2, \ldots, x_N) xmax=max(x1,x2,…,xN)
-
对每个数据点 x i x_i xi,应用以下标准化公式:
x i ′ = x i − x min x max − x min x_i' = \frac{x_i - x_{\text{min}}}{x_{\text{max}}- x_{\text{min}}} xi′=xmax−xminxi−xmin -
σ \sigma σ 表示标准差。
-
N N N 表示数据点的总数。
-
x i x_i xi 表示数据集中的第 i 个数据点。
-
μ \mu μ 表示数据集的均值(平均值),计算方式为: μ = 1 N ∑ i = 1 N x i \mu = \frac{1}{N} \sum_{i=1}^{N} x_i μ=N1∑i=1Nxi
2.3.3 构造数据加载器
构造数据加载器,用于训练、验证或测试机器学习模型。
# 定义函数可接受多个参数,包括数据文件路径path、数据集模式mode、批量大小batch_size、并行工作数n_jobs、
# 是否仅使用目标数据target_only以及均值和标准差的参数。
def prep_dataloader(path, mode, batch_size, n_jobs=0, target_only=False, mean=None, std=None):''' Generates a dataset, then is put into a dataloader. '''# Construct datasetdataset = COVID19Dataset(path, mode=mode, target_only=target_only) mean, std = dataset.normalization(mean, std)# 创建数据加载器对象:将数据集划分成小批量,并提供批量数据以供模型训练dataloader = DataLoader(dataset, batch_size,shuffle=(mode == 'train'), # shuffle为一个布尔值,指示是否在每个周期(epoch)之前随机打乱数据。# 通常在训练模型时设置为True,确保每个周期中的样本顺序不同。drop_last=False,num_workers=n_jobs, pin_memory=True) return dataloader, mean, std
2.3.4 构建前馈神经网络(Feedforward Neural Network)模型
class NeuralNet(nn.Module):''' A simple fully-connected deep neural network '''def __init__(self, input_dim):super(NeuralNet, self).__init__()# Define neural network here# TODO: How to modify this model to achieve better performance?# 定义了神经网络的结构,包括输入层、隐藏层和输出层。self.net = nn.Sequential(nn.Linear(input_dim, 64),nn.ReLU(),nn.Linear(64, 16),nn.ReLU(),nn.Linear(16,8),nn.ReLU(),nn.Linear(8,4),nn.ReLU(),nn.Linear(4,1) # 单个输出神经元的线性层,用于回归任务)# Mean squared error loss# reduction='mean':损失值会被平均计算self.criterion = nn.MSELoss(reduction='mean') def forward(self, x):''' Given input of size (batch_size x input_dim), compute output of the network '''return self.net(x).squeeze(1)def cal_loss(self, pred, target, l1_lambda):# target:真实的目标值# l1_lambda:L1正则化的超参数,用于控制正则化的强度''' Calculate loss '''# TODO: you may implement L2 regularization hereloss = self.criterion(pred, target)# L1 regularizationl1_reg = torch.tensor(0.).to(device)for param in model.parameters():l1_reg += torch.sum(torch.abs(param))loss += l1_lambda * l1_regreturn loss
2.3.5 神经网络的训练过程
- 设置训练超参数和优化器: 代码从配置文件中获取了训练超参数,包括最大的训练周期数(n_epochs)、优化器类型(optimizer)、以及优化器的超参数(optim_hparas)。然后,通过 PyTorch 中的 getattr 函数创建了相应类型的优化器(如 Adam、SGD 等)。
- 初始化记录器和计数器: 代码初始化了一些变量,包括损失记录器 loss_record,用于记录每个训练周期的训练和开发(验证)集损失,以及用于早停(Early Stopping)的计数器 early_stop_cnt。
- 开始训练循环: 代码进入了一个训练循环,该循环在最大训练周期数内运行,或者在出现早停情况下提前结束训练。
- 模型训练: 在每个训练周期内,代码设置模型为训练模式(model.train()),然后迭代训练数据集中的每个批次。
- 验证集评估: 每个训练周期结束后,代码使用验证集(开发集)对模型进行评估,计算验证集上的均方误差。如果验证集上的均方误差小于之前的最小值(min_mse),则保存模型参数,并重置早停计数器 early_stop_cnt。这有助于防止过拟合,并在性能改善时保存模型。
- 早停策略: 如果连续 early_stop 个训练周期内都没有性能改善(验证集损失不再降低),训练过程将提前结束。
- 训练结束: 训练结束后,代码打印出训练周期数,然后返回最小的验证集均方误差和损失记录器 loss_record。
def train(tr_set, dv_set, model, config, device):''' DNN training '''n_epochs = config['n_epochs'] # Maximum number of epochs# Setup optimizeroptimizer = getattr(torch.optim, config['optimizer'])(model.parameters(), **config['optim_hparas'])min_mse = 1000.loss_record = {'train': [], 'dev': []} # for recording training lossearly_stop_cnt = 0epoch = 0while epoch < n_epochs:model.train() # set model to training modefor x, y in tr_set: # iterate through the dataloaderoptimizer.zero_grad() # set gradient to zerox, y = x.to(device), y.to(device) # move data to device (cpu/cuda)pred = model(x) # forward pass (compute output)mse_loss = model.cal_loss(pred, y, config['l1_lambda']) # compute lossmse_loss.backward() # compute gradient (backpropagation)optimizer.step() # update model with optimizerloss_record['train'].append(mse_loss.detach().cpu().item())# After each epoch, test your model on the validation (development) set.dev_mse = dev(dv_set, model, device)if dev_mse < min_mse:# Save model if your model improvedmin_mse = dev_mseprint('Saving model (epoch = {:4d}, val_loss = {:.4f})'.format(epoch + 1, min_mse))torch.save(model.state_dict(), config['save_path']) # Save model to specified pathearly_stop_cnt = 0else:early_stop_cnt += 1epoch += 1loss_record['dev'].append(dev_mse)if early_stop_cnt > config['early_stop']:# Stop training if your model stops improving for "config['early_stop']" epochs.breakprint('Finished training after {} epochs'.format(epoch))return min_mse, loss_record
2.3.6 模型评估
def dev(dv_set, model, device):model.eval() # set model to evalutation modetotal_loss = 0for x, y in dv_set: # iterate through the dataloaderx, y = x.to(device), y.to(device) # move data to device (cpu/cuda)with torch.no_grad(): # disable gradient calculationpred = model(x) # forward pass (compute output)mse_loss = model.cal_loss(pred, y, config['l1_lambda']) # compute losstotal_loss += mse_loss.detach().cpu().item() * len(x) # accumulate losstotal_loss = total_loss / len(dv_set.dataset) # compute averaged lossreturn total_loss
2.3.7 模型测试
def test(tt_set, model, device):model.eval() # set model to evalutation modepreds = []for x in tt_set: # iterate through the dataloaderx = x.to(device) # move data to device (cpu/cuda)with torch.no_grad(): # disable gradient calculationpred = model(x) # forward pass (compute output)preds.append(pred.detach().cpu()) # collect predictionpreds = torch.cat(preds, dim=0).numpy() # concatenate all predictions and convert to a numpy arrayreturn preds
2.3.8 模型初始化
初始化训练过程中需要的设备、目录和超参数配置,以便在训练模型之前进行必要的准备工作。
device = get_device() # get the current available device ('cpu' or 'cuda')
os.makedirs('models', exist_ok=True) # The trained model will be saved to ./models/
target_only = True # TODO: Using 40 states & 2 tested_positive featuresseed = 459
np.random.seed(seed)
delta = np.random.normal(loc=0,scale = 0.000001)# TODO: How to tune these hyper-parameters to improve your model's performance?
config = {'n_epochs': 3000, # maximum number of epochs'batch_size': 270, # mini-batch size for dataloader'optimizer': 'Adam', # optimization algorithm (optimizer in torch.optim)'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)'lr': 0.003, # learning rate of Adam#'weight_decay': 1e-8 # weight decay (L2 regularization)},'l1_lambda':1e-5 + delta, # L1 regularization'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)'save_path': 'models/model.pth' # your model will be saved here
}myseed = 42069 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(myseed)
2.3 模型运行
tr_set, mean, std = prep_dataloader(tr_path, 'train', config['batch_size'], target_only=target_only)
dv_set, _, _ = prep_dataloader(tr_path, 'dev', config['batch_size'], target_only=target_only, mean=mean, std=std)
tt_set, _, _ = prep_dataloader(tt_path, 'test', config['batch_size'], target_only=target_only, mean=mean, std=std)
Finished reading the train set of COVID19 Dataset (2160 samples found, each dim = 14)
Finished reading the dev set of COVID19 Dataset (540 samples found, each dim = 14)
Finished reading the test set of COVID19 Dataset (893 samples found, each dim = 14)
model = NeuralNet(tr_set.dataset.dim).to(device) # Construct model and move to device
model_loss, model_loss_record = train(tr_set, dv_set, model, config, device)

plot_learning_curve(model_loss_record, title='deep model')
del model
model = NeuralNet(tr_set.dataset.dim).to(device)
ckpt = torch.load(config['save_path'], map_location='cpu') # Load your best model
model.load_state_dict(ckpt)
if len(dv_set) > 0:plot_pred(dv_set, model, device) # Show prediction on the validation set
def save_pred(preds, file):''' Save predictions to specified file '''print('Saving results to {}'.format(file))with open(file, 'w') as fp:writer = csv.writer(fp)writer.writerow(['id', 'tested_positive'])for i, p in enumerate(preds):writer.writerow([i, p])preds = test(tt_set, model, device) # predict COVID-19 cases with your model
save_pred(preds, 'COVID-19 pred.csv') # save prediction file to COVID-19 pred.csv
相关文章:
深度学习 二:COVID 19 Cases Prediction (Regression)
Deep Learning 1. 回归算法思路2. 代码2.1 基础操作2.2 定义相关函数2.3.1 定义图像绘制函数2.3.2 数据集加载及预处理2.3.3 构造数据加载器2.3.4 构建前馈神经网络(Feedforward Neural Network)模型2.3.5 神经网络的训练过程2.3.6 模型评估2.3.7 模型测…...

UG\NX二次开发 信息窗口的4种输出方式 NXOpen::ListingWindow::DeviceType
文章作者:里海 来源网站:《里海NX二次开发3000例专栏》 简介 UG\NX二次开发 信息窗口的4种输出方式 NXOpen::ListingWindow::DeviceType 信息窗口的输出类型 enum NXOpen::ListingWindow::DeviceType 枚举值描述 DeviceTypeWindow0输出将写入“信息”窗口DeviceTypeFile1输出…...

mavn打包时如何把外部依赖加进去?
一、添加依赖: <dependency><groupId>com.dm</groupId><artifactId>DmJdbcDriver</artifactId><version>18</version><scope>system</scope><systemPath>${project.basedir}/lib/DmJdbcDriver18.jar</systemP…...

爬虫代理请求转换selenium添加带有账密的socks5代理
爬虫代理请求转换selenium添加带有账密的socks5代理。 一、安装三方库 二、使用方法 1、在cmd命令行输入: 2、给selenium添加代理 最近因为工作需要,需要selenium添加带有账密的socks5代理,贴出一个可用的方法。 把带有账密的socks5代理&am…...

Redis 如何实现数据不丢失的?
Redis 实现数据不丢失的关键在于使用了多种持久化机制,以确保数据在内存和磁盘之间的持久性。以下是 Redis 实现数据不丢失的主要方法: 快照(Snapshot)持久化: Redis 使用快照持久化来定期将内存中的数据写入磁盘。快照是一个数据库状态的副本,包含了所有键和与其相关联的…...

[高等数学]同济版高等数学【第七版】上下册教材+习题全解PDF
laiyuan 「高等数学 第7版 同济大学」 https://www.aliyundrive.com/s/5fpFJb3asYk 提取码: 61ao 通过百度网盘分享的文件:同济版高数教材及… 链接:https://pan.baidu.com/s/1gyy-GMGjwguAjYijrpC8RA?pwdyhnr 提取码:yhnr 高等数学相关: The Ca…...

【面试题精讲】Java超过long类型的数据如何表示
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址[1] 面试题手册[2] 系列文章地址[3] 在 Java 中,如果需要表示超过 long 类型范围的数据,可以使用 BigInteger 类…...
)
Shapiro-Wilk正态性检验(Shapiro和Wilk于1965年提出)
Shapiro-Wilk正态性检验是一种用于确定数据集是否服从正态分布的统计方法。它基于Shapiro和Wilk于1965年提出的检验统计量。以下是其基本原理和用途: 基本原理: 零假设(Null Hypothesis):Shapiro-Wilk检验的零假设是数…...
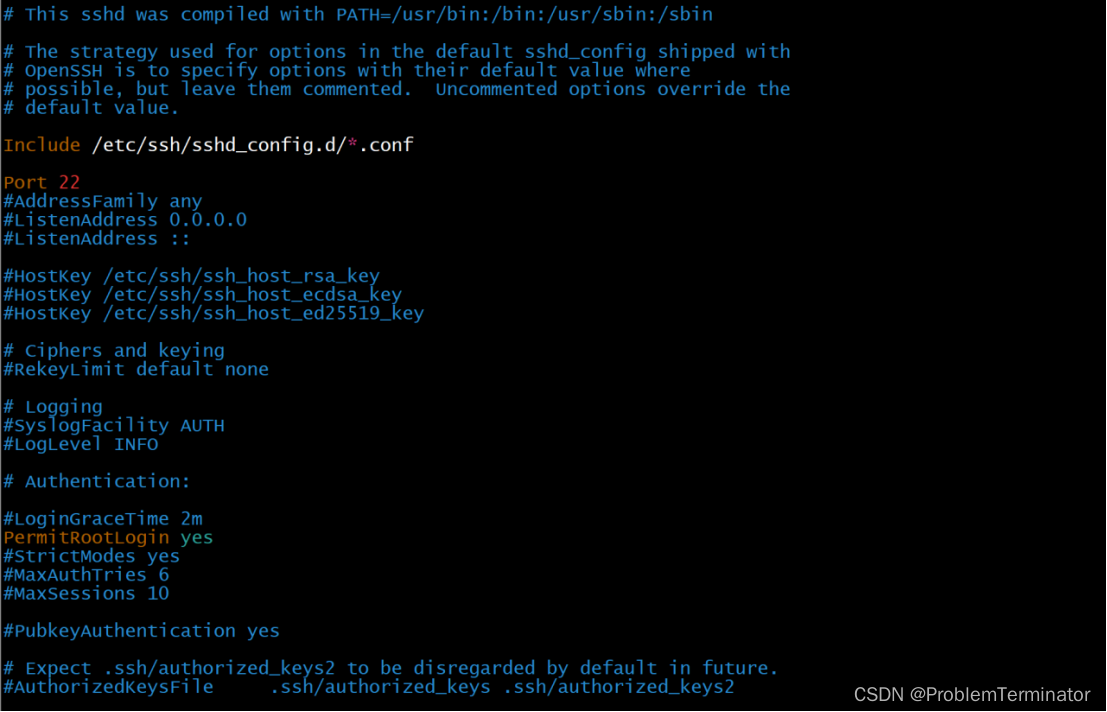
debian设置允许ssh连接
解决新debian系统安装后不能通过ssh连接的问题。 默认情况下,Debian系统不开启SSH远程登录,需要手动安装SSH软件包并设置开机启动。 > 设置允许root登录传送门:debian设置允许root登录 首先检查/etc/ssh/sshd_config文件是否存在。 注意…...

【C语言经典100例题-66】(用指针解决)输入3个数a,b,c,按大小顺序输出。
代码: #include<stdio.h> #define _CRT_SECURE_NO_WARNINGS 1//VS编译器使用scanf函数时会报错,所以添加宏定义 swap(p1, p2) int* p1, * p2; {int p;p *p1;*p1 *p2;*p2 p; } int main() {int n1, n2, n3;int* pointer1, * pointer2, * point…...

【STM32 CubeMX】移植u8g2(一次成功)
文章目录 前言一、下载u8g2源文件二、复制和更改文件2.1 复制文件2.2 修改文件u8g2_d_setup文件u8g2_d_memory 三、编写oled.c和oled.h文件3.1 CubeMX配置I2C3.2 编写文件oled.holed.c 四、测试代码main函数测试代码 总结 前言 在本文中,我们将介绍如何在STM32上成…...

华为云智能化组装式交付方案 ——金融级PaaS业务洞察及Web3实践的卓越贡献
伴随信息技术与金融业务加速的融合,企业应用服务平台(PaaS)已从幕后走向台前,成为推动行业数字化转型的关键力量。此背景下,华为云PaaS智能化组装式交付方案闪耀全场,在近日结束的华为全联接大会 2023上倍受…...
)
Halcon Image相关算子(二)
(1) dyn_threshold(OrigImage, ThresholdImage : RegionDynThresh : Offset, LightDark : ) 功能:从输入图像中选择像素满足阈值条件的那些区域。 图形输入参数:OrigImage:原始图像; 图形输入参数:ThresholdImage&a…...

Rust 多线程编程
一个进程一定有一个主线程,主线程之外创建出来的线程称为子线程 多线程编程,其实就是在主线程之外创建子线程,让子线程和主线程并发运行,完成各自的任务。 Rust语言支持多线程编程。 Rust语言标准库中的 std::thread 模块用于多线…...

JavaScript高阶班之ES6 → ES11(八)
JavaScript高阶班之ES6 → ES11 1、ES6新特性1.1、let 关键字1.2、const关键字1.3、变量的解构赋值1.3.1、数组的解构赋值1.3.2、对象的解构赋值 1.4、模板字符串1.5、简化对象写法1.6、箭头函数1.7、函数参数默认值1.8、rest参数1.9、spread扩展运算符1.9.1、数组合并1.9.2、数…...

网页中嵌套网页制作方法
<!DOCTYPE html> <html> <head> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <meta charset"UTF-8"> <title>网页搜索</title> <style> body { ba…...
)
系统集成项目管理总结(笔记)
系统集成项目管理总结 基础知识 第一章 信息化知识 第二章 信息系统服务管理 第三章 系统集成专业技术 第四章 项目管理一般知识 第五章 立项管理 第六章 整体管理 第七章 范围管理 第八章 进度管理 第九章 成本管理 第十章 质量管理 第十一章 人力资源管理 第十二…...

如何给Nginx配置访问IP白名单
一、Nginx配置访问IP白名单 有时部署的应用需要只允许某些特定的IP能够访问,其他IP不允许访问,这时,就要设置访问白名单; 设置访问白名单有多种方式: 1.通过网络防火墙配置,例如阿里云/华为云管理平台 2.…...

【VIM】VIM配合使用的工具
6-1 课程总结-vim虐我千百遍,我待 vim 如初恋_哔哩哔哩_bilibili...
git你学“废”了吗?——git本地仓库的创建
git你学“废”了吗?——git本地仓库的创建😎 前言🙌初识gitgit 本地仓库的创建1、基于centos7环境下 git的下载2、设置自己的用户名和邮箱 查看.git中的结构区分清楚版本库和工作区 查看git中的相关内容查看仓库的状态 总结撒花💞…...
)
用Python+OpenCV搞定热红外与可见光图像自动对齐(附完整代码与避坑指南)
PythonOpenCV实战:热红外与可见光图像自动配准全流程解析 引言 在工业检测、安防监控、医疗诊断等领域,热红外与可见光图像的融合分析正成为关键技术。两种成像模式各具优势:可见光图像色彩丰富、细节清晰,而热红外图像则能揭示物…...

NOMA实战:从叠加编码到SIC解码的链路级仿真解析
1. NOMA技术基础与核心原理 NOMA(非正交多址接入)是5G通信中的一项关键技术,它彻底改变了传统正交多址技术(如OFDMA)的资源分配方式。我第一次接触NOMA时,最让我惊讶的是它竟然主动引入干扰来提升频谱效率—…...

Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验
Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验 【免费下载链接】steam-deck-windows-usermode-driver A windows usermode controller driver for the steam deck internal controller. 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck…...

单元幕墙组装检验标准
单元幕墙组装检验标准 1 范围 本标准规定了沈阳远大企业集团单元幕墙组装的检验项目、检验方法、检验工具、质量评定方法。 本标准适用于单元幕墙板块的组装检验。 2 规范性引用文件 下列文件中的条款通过本标准的引用而成为本标准的条款,凡是注日期的引用文件,其随后所…...

基于LangChain与本地LLM构建私有化知识库问答系统实践
1. 项目概述:从零构建一个垂直领域的知识库与问答系统最近在整理个人技术资料时,我遇到了一个非常典型的问题:手头积累了大量来自不同渠道的电子书、技术文档、知乎专栏文章以及各种开源项目的README,内容虽然优质,但过…...

Lyrebird语音变声器完整指南:从安装到高级使用技巧
Lyrebird语音变声器完整指南:从安装到高级使用技巧 【免费下载链接】lyrebird 🦜 Simple and powerful voice changer for Linux, written with Python & GTK 项目地址: https://gitcode.com/gh_mirrors/lyr/lyrebird Lyrebird是一款专为Linu…...

开源本地AI API网关:统一管理Ollama等模型,简化LLM应用开发
1. 项目概述:一个开源的本地AI API网关最近在折腾本地大语言模型(LLM)的朋友,估计都遇到过类似的烦恼:模型装好了,界面也跑起来了,但想把它集成到自己的应用里,或者想用一套统一的接…...

如何彻底解决Windows电脑自动锁屏问题:终极鼠标模拟工具使用指南
如何彻底解决Windows电脑自动锁屏问题:终极鼠标模拟工具使用指南 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and f…...

TestDisk PhotoRec:专业级数据恢复工具,拯救你的宝贵数据
TestDisk & PhotoRec:专业级数据恢复工具,拯救你的宝贵数据 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾经不小心删除了重要的工作文档?是否遇到过硬盘分区…...

LuaDec51终极指南:3步快速掌握Lua 5.1字节码反编译
LuaDec51终极指南:3步快速掌握Lua 5.1字节码反编译 【免费下载链接】luadec51 Lua Decompiler for Lua version 5.1 项目地址: https://gitcode.com/gh_mirrors/lu/luadec51 LuaDec51是一个强大的Lua 5.1字节码反编译工具,能够将编译后的Lua字节码…...