【python学习第11节:numpy】
文章目录
- 一,numpy(上)
- 1.1基础概念
- 1.2数组的属性
- 1.3数组创建
- 1.4 类型转换
- 1.5ndarry基础运算(上)矢量化运算
- 1.6拷贝和视图
- 1.6.1完全不复制
- 1.6.2视图或浅拷贝
- 1.6.3深拷贝
- 1.7索引,切片和迭代
- 1.7.1一维数组
- 1.7.2多维数组
- 1.8形状操作
- 1.9布尔索引和花式索引
- 1.10字符串索引
- 1.11搜索匹配函数
- 1.12排序
一,numpy(上)
1.1基础概念
Numpy的数组的类称为ndarray(非动态数组),一但定义好了里面的内容可以变,但是长度不能变
1.2数组的属性
示例:
ndarray.ndim: 来获取数组的维度,维度的数量被称为rank
>>> import numpy as np
>>> x = np.array([[1,2,3],[4,5,6]])
>>> x
array([[1, 2, 3],[4, 5, 6]])
>>> x.ndim
2
>>>
ndarray.shape:来获取数组的行数,列数。
>>> import numpy as np
>>> x = np.array([[1,2,3],[4,5,6]])
>>> x
array([[1, 2, 3],[4, 5, 6]])
>>> x.shape
(2, 3)
>>>
>>>> x = np.array([1])
>>> x.shape
(1,)
>>> x = np.array([[1]])
>>> x.shape
(1, 1)
ndarray.size:来获取数组元素的总数,等于shape的元素的乘积
>>> import numpy as np
>>>> x = np.array([[1,2,3],[4,5,6]])
>>>> x.shape
(2, 3)
>>> x.size
6
ndarray.dtype:来获取数组的数据类型,它返回一个描述数组元素类型的对
>>> import numpy as np
>>> x = np.array([[1,2,3],[4,5,6]])
>>> x.dtype
dtype('int32')
>>> x = np.array([[1.1,2,3],[4,5,6]])
>>> x.dtype
>>>dtype('float64')
>>>
ndarray.itemsize:来获取数组中每个元素的字节大小(即每个元素占用的字节数)
>>> import numpy as np
>>> x = np.array([[1,2,3],[4,5,6]])
>>> x.itemsize
4
>>> x = np.array([[1.1,2,3],[4,5,6]])
>>> x.itemsize
8
ndarray.strides:来获取数组的步长,步长是描述在每个维度上移动一个元素所需的字节数
>>> import numpy as np
>>> x = np.array([[1.1,2,3],[4,5,6]])
>>> x.strides
(24, 8)#一行3个元素,每个大小8字节
>>> x = np.array([[1,2,3],[4,5,6]])
>>> x.strides
(12, 4)
>>>
1.3数组创建
说明:
使用numpy.array使用array函数从常规python列表或元组中创建数组。
>>> import numpy as np
>>> np.array([1,2,3])
array([1, 2, 3])
>>> np.array((1,2,3))
array([1, 2, 3])
>>>
数组的类型在创建的时候也可以明确指定
>>> import numpy as np
>>>> a = np.array([[1,2,3],[2,5,6]],dtype = complex)
>>> a
array([[1.+0.j, 2.+0.j, 3.+0.j],[2.+0.j, 5.+0.j, 6.+0.j]])
>>>
numpy.zeros创建一个由0组成的数组
>>> import numpy as np
>>> np.zeros((3,5))
array([[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.]])
>>>
numpy.ones创建一个由1组成的数组
>>> import numpy as np
>>> np.ones((3,5))
array([[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.]])
>>>
numpy.random提供了各种方法来生成不同分布的随机数数组
>>> import numpy as np
>>> np.random.random((3,4)) #数组中的每个数是0-1之间的
array([[0.2192252 , 0.23184818, 0.53477907, 0.94434772],[0.93001715, 0.42585838, 0.41844402, 0.38080826],[0.9451442 , 0.55833465, 0.17982058, 0.77624287]])
>>>
numpy.arange 用于创建一个等差数列的 NumPy 数组,返回的是一个数组而不是列表
numpy.arange([start],stop, [step],dtype=None)
start(可选):序列的起始值,默认为 0。
stop:序列的终止值(不包括在序列中)。
step(可选):序列中的元素之间的步长,默认为 1。
dtype(可选):生成数组的数据类型。如果未指定,则根据输入参数自动推断数据类型。
>>> import numpy as np
>>> np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(2,10,3)
array([2, 5, 8])
>>>
numpy.linspace 用于创建一个等间距的线性数列的 NumPy 数组。
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
start:数列的起始值。
stop:数列的终止值。
num(可选):生成数列的元素个数,默认为 50。
endpoint(可选):如果为 True,则包含终止值;如果为 False,则不包含终止值。默认为 True。
retstep(可选):如果为 True,则返回数列的间隔(步长)。
dtype(可选):生成数组的数据类型。如果未指定,则根据输入参数自动推断数据类型。
>>> np.linspace(0,1,6)
array([0. , 0.2, 0.4, 0.6, 0.8, 1. ])
>>>
numpy.fromfunction从给定函数创建一个数组
import numpy as np
def f(x,y):return 2*x+y
a = np.fromfunction(f,(4,4))
print(a)#执行结果
[[0. 1. 2. 3.][2. 3. 4. 5.][4. 5. 6. 7.][6. 7. 8. 9.]]
numpy.eye 用于创建一个单位矩阵
numpy.eye(N, M=None, k=0, dtype=float, order=‘C’)
N:矩阵的行数(或数组的维度)。
M(可选):矩阵的列数。如果未指定,则默认与行数 N 相等。
k(可选):对角线的偏移量。默认为 0,表示主对角线。正值表示位于主对角线上方的对角线,负值表示位于主对角线下方的对角线。
dtype(可选):生成数组的数据类型。
order(可选):数组的存储顺序。可以是 ‘C’(按行存储)或 ‘F’(按列存储)。默认为 ‘C’。
>>> import numpy as np
>>> np.eye(4)
array([[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.],[0., 0., 0., 1.]])
>>> np.eye(4,k=1)
array([[0., 1., 0., 0.],[0., 0., 1., 0.],[0., 0., 0., 1.],[0., 0., 0., 0.]])
>>> np.eye(4,k=-1)
array([[0., 0., 0., 0.],[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.]])
>>>
1.4 类型转换
numpy.astype可以实现类型转换(创建一个新的对象,原对象的类型不变)
>>> import numpy as np
>>> a = np.array([1,2,3],dtype = float)
>>> a
array([1., 2., 3.])
>>> b = a.astype(int)
>>> b
array([1, 2, 3])
>>> b.dtype
dtype('int32')
>>> a.dtype
dtype('float64')
>>>
矩阵之间的点乘
>>> a = np.floor(10*np.random.random((3,3)))
>>> a
array([[3., 8., 8.],[8., 2., 7.],[1., 3., 7.]])
>>> b = np.floor(10*np.random.random((3,3)))
>>> b
array([[5., 7., 1.],[9., 3., 7.],[1., 5., 8.]])
>>> a.dot(b)
array([[ 95., 85., 123.],[ 65., 97., 78.],[ 39., 51., 78.]])
>>>
1.5ndarry基础运算(上)矢量化运算
矢量:既有大小,又有方向
标量:只有大小,没有方向
矢量与标量相乘
>>> import numpy as np
>>> a = np.array([1,2,3]) #创建一个1维的数组(向量)
>>> b = a*2 #b等于矢量*标量
>>> a
array([1, 2, 3])
>>> b
array([2, 4, 6]) #对矢量里面的每个值都跟标量乘一下,相当于‘广播’
>>>
矢量与标量相加
>>> a
array([1, 2, 3])
>>> a+2
array([3, 4, 5])
矢量与矢量相加
>>> a
array([1, 2, 3])
>>> b = a+2
>>> b
array([3, 4, 5])
>>> a + b
array([4, 6, 8])
>>> a
array([1, 2, 3])
>>> c
array([1, 2])
>>> a+c
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (3,) (2,)
>>> c = np.array([1])
>>> c
array([1])
>>> a+c
array([2, 3, 4])
>>>
矢量与矢量相乘
>>> a
array([1, 2, 3])
>>> c
array([1, 2, 5])
>>> a*c
array([ 1, 4, 15])
array([1])
>>> a
array([1, 2, 3])
>>> a*c
array([1, 2, 3])
>>> c = np.array([1,2])
>>> a*c
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: operands could not be broadcast together with shapes (3,) (2,)
>>>
广播规则:
1,维度数较少的数组会在其维度前面自动填充1,直到维度数与另一个数组相同。这样,两个数组的维度会匹配。
2,如果两个数组在某个维度上的大小相等,或者其中一个数组在该维度上的大小为1,那么这两个数组在该维度上是兼容的。
3,如果两个数组在所有维度上都兼容,即满足维度匹配的条件,那么它们可以进行广播。
4,在进行广播时,数组会沿着维度大小为1的维度进行复制,以使其与另一个数组具有相同的形状。
1.6拷贝和视图
1.6.1完全不复制
简单赋值不会创建数组对象或其数据的拷贝
>>> import numpy as np
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = a
>>> b
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b is a
True
>>>
1.6.2视图或浅拷贝
不同的数组对象可以共享相同的数据。view方法创建一个新数组对象,通过该对象可看到相同的数据
>>> import numpy as np
>>> a = np.array([1,2,3,4])
>>> a
array([1, 2, 3, 4])
>>> b = a.view()
>>> b
array([1, 2, 3, 4])
>>> b is a
False
>>> a[1]
2
>>> a[1] = 7
>>> a
array([1, 7, 3, 4])
>>> b
array([1, 7, 3, 4])
>>> a.flags.owndata
True
>>> b.flags.owndata
False
>>>
1.6.3深拷贝
copy方法生成数组及其数据的完整拷贝。
>>> b = a.copy()
>>> b
array([1, 2, 3, 4])
>>> a
array([1, 2, 3, 4])
>>> b is a
False
>>> b[1] = 13
>>> b
array([ 1, 13, 3, 4])
>>> a
array([1, 2, 3, 4])
>>>
1.7索引,切片和迭代
1.7.1一维数组
一维数组可以索引,切片和迭代,非常类似列表和其他Python序列。
1.7.2多维数组
import numpy as np
def f(x,y):return 2*x+y
a = np.fromfunction(f,(4,4),dtype=int)
'''
[[0 1 2 3][2 3 4 5][4 5 6 7][6 7 8 9]]'''
得到某个具体行具体列元素的值
print(a[2][3])
7 #a中第2行3列元素的值
得到某一行的值
print(a[2])
[4 5 6 7] #第二行的值
print(a[1:3][1])
[4 5 6 7] #在索引到的(1-2)行中的第一行(前面有一个第0行)
print(a[1][1:3])
[3 4] #索引的第一行中的(1-2)的元素
print(a[-1])
[6 7 8 9] #输出最后一行
得到某一列的值
print(a[:,1])
[1 3 5 7] #第一列的值
print(a[1:3,1])
[3 5] #第一列中的(1-2)元素的值1.8形状操作
先创建一个4*4的数组a,再变形(不会直接操作再原对象上,而是产生一个新对象)
import numpy as np
def f(x,y):return 2*x+y
a = np.fromfunction(f,(4,4),dtype=int)
print(a)
'''
[[0 1 2 3][2 3 4 5][4 5 6 7][6 7 8 9]]'''
变成1维
print(a.ravel())
[0 1 2 3 2 3 4 5 4 5 6 7 6 7 8 9]
重新指定形状,但是总数要不变
print(a.reshape(2,8)) #2*8 == 4*4
[[0 1 2 3 2 3 4 5][4 5 6 7 6 7 8 9]]
转置
print(a.T)
[[0 2 4 6][1 3 5 7][2 4 6 8][3 5 7 9]]
轴交换
第一个维度表示两个二维子数组的索引,第二个维度表示每个二维子数组中的行索引,第三个维度表示每个二维子数组中的列索引。第一个维度表示两个二维子数组的索引,第二个维度表示每个二维子数组中的行索引,第三个维度表示每个二维子数组中的列索引。
[2 3]的前两个索引是(0,1)
[4 5]的前两个索引是(1,0)
交换完后就是输出的结果
import numpy as np
a = np.arange(8).reshape(2,2,2)
print(a)
[[[0 1][2 3]][[4 5][6 7]]]
m = a.swapaxes(0,1) #将第一个轴和第二个轴交换m[y][z][k] = k[x][y][z]
print(m)
[[[0 1][4 5]][[2 3][6 7]]]
1的三个轴是(0,0,1)轴0和轴2交换之后是(1,0,0)
4的三个轴是(1,0,0)轴0和轴2交换之后是(0,0,1)
所以1和4交换了位置,其他的类似
print(a)
[[[0 1][2 3]][[4 5][6 7]]]m = a.swapaxes(0,2)
print(m)
[[[0 4][2 6]][[1 5][3 7]]]
垂直拼装两个数组
首先列数肯定得相同
>>> import numpy as np
>>> a = np.floor(10*np.random.random((2,3))) #np.floor是向下取整的意思
>>> a
array([[6., 4., 2.],[4., 7., 5.]])
>>> b = np.floor(10*np.random.random((3,3)))
>>> b
array([[7., 1., 3.],[4., 5., 2.],[4., 2., 2.]])
>>> np.vstack((a,b))
array([[6., 4., 2.],[4., 7., 5.],[7., 1., 3.],[4., 5., 2.],[4., 2., 2.]])
>>>
水平拼装两个数组
>>> import numpy as np
>>> a = np.floor(10*np.random.random((2,3)))
>>> a
array([[6., 4., 2.],[4., 7., 5.]])
>>> b = np.floor(10*np.random.random((2,3)))
>>> b
array([[3., 9., 4.],[7., 2., 5.]])
>>> np.hstack((a,b))
array([[6., 4., 2., 3., 9., 4.],[4., 7., 5., 7., 2., 5.]])
>>>
垂直切割数组
>>> a = np.floor(10*np.random.random((4,12)))
>>> a
array([[2., 1., 2., 7., 6., 9., 0., 9., 3., 1., 2., 3.],[0., 0., 1., 9., 3., 5., 5., 9., 7., 1., 2., 1.],[5., 0., 3., 1., 3., 0., 1., 7., 6., 1., 6., 0.],[0., 1., 3., 2., 4., 8., 6., 7., 5., 3., 8., 7.]])
>>> np.hsplit(a,3) #垂直切三刀
[array([[2., 1., 2., 7.],[0., 0., 1., 9.],[5., 0., 3., 1.],[0., 1., 3., 2.]]), array([[6., 9., 0., 9.],[3., 5., 5., 9.],[3., 0., 1., 7.],[4., 8., 6., 7.]]), array([[3., 1., 2., 3.],[7., 1., 2., 1.],[6., 1., 6., 0.],[5., 3., 8., 7.]])]
把3,4,5列切割出来
>>> np.hsplit(a,(3,6))
[array([[2., 1., 2.],[0., 0., 1.],[5., 0., 3.],[0., 1., 3.]]), array([[7., 6., 9.],[9., 3., 5.],[1., 3., 0.],[2., 4., 8.]]), array([[0., 9., 3., 1., 2., 3.],[5., 9., 7., 1., 2., 1.],[1., 7., 6., 1., 6., 0.],[6., 7., 5., 3., 8., 7.]])]
水平切割数组
>>> a = np.floor(10*np.random.random((4,12)))
>>> a
array([[2., 1., 2., 7., 6., 9., 0., 9., 3., 1., 2., 3.],[0., 0., 1., 9., 3., 5., 5., 9., 7., 1., 2., 1.],[5., 0., 3., 1., 3., 0., 1., 7., 6., 1., 6., 0.],[0., 1., 3., 2., 4., 8., 6., 7., 5., 3., 8., 7.]])
>>> np.vsplit(a,2)
[array([[2., 1., 2., 7., 6., 9., 0., 9., 3., 1., 2., 3.],[0., 0., 1., 9., 3., 5., 5., 9., 7., 1., 2., 1.]]), array([[5., 0., 3., 1., 3., 0., 1., 7., 6., 1., 6., 0.],[0., 1., 3., 2., 4., 8., 6., 7., 5., 3., 8., 7.]])]
>>>
把1,2行切割出来
>>> np.vsplit(a,(1,3))
[array([[2., 1., 2., 7., 6., 9., 0., 9., 3., 1., 2., 3.]]), array([[0., 0., 1., 9., 3., 5., 5., 9., 7., 1., 2., 1.],[5., 0., 3., 1., 3., 0., 1., 7., 6., 1., 6., 0.]]), array([[0., 1., 3., 2., 4., 8., 6., 7., 5., 3., 8., 7.]])]
>>>
1.9布尔索引和花式索引
布尔索引:使用布尔数组作为索引
相当于一个过滤的作用
>>> a = np.array([1,2,3,4,5,6])
>>> b = np.array([True,False,True,False,True,False])
>>> a[b]
array([1, 3, 5])
>>> a[b==False]
array([2, 4, 6])
>>> a >= 3
array([False, False, True, True, True, True])
>>>
花式索引:使用整数数组作为索引
(0,0) (1,0) (0,2)
>>> a = np.floor(10*np.random.random((2,4)))
>>> a
array([[3., 6., 5., 6.],[2., 3., 7., 2.]])
>>> a[[0,1,0],[0,0,2]]
array([3., 2., 5.])
>>>
1.10字符串索引
>>> x = np.array([('zwt',10,20),('qwe',1,2)],dtype=[('name','S10'),('age','i4'),('score','i4')])
>>> x
array([(b'zwt', 10, 20), (b'qwe', 1, 2)],dtype=[('name', 'S10'), ('age', '<i4'), ('score', '<i4')])
>>> x['name']
array([b'zwt', b'qwe'], dtype='|S10')
>>> x['score']
array([20, 2])
>>>
1.11搜索匹配函数
where函数
np.where(condition[, x, y])
condition:一个布尔数组或条件表达式,指定要检查的条件。
x:可选参数,满足条件的元素的替代值。默认情况下,返回满足条件的元素的索引。
y:可选参数,不满足条件的元素的替代值。默认情况下,返回满足条件的元素的索引
>>> import numpy as np
>>> arr = np.array([1, 2, 3, 4, 5])
>>> arr
array([1, 2, 3, 4, 5])
>>> indices = np.where(arr > 2)
>>> indices
(array([2, 3, 4], dtype=int64),)
>>> indices = np.where(arr > 2, 1, 0)
>>> indices
array([0, 0, 1, 1, 1])
>>>
1.12排序
使用sort对数组/数组某一维度进行就地排序(会修改数组本身)
默认对最后一个轴进行排序,也可以选择对其他轴排序
>>> a = np.floor(10*np.random.random((3,3)))
>>> a
array([[4., 3., 9.],[8., 5., 7.],[8., 3., 7.]])
>>> a.sort()
>>> a
array([[3., 4., 9.],[5., 7., 8.],[3., 7., 8.]])
>>> a.sort(0)
>>> a
array([[3., 4., 8.],[3., 7., 8.],[5., 7., 9.]])
>>>
相关文章:

【python学习第11节:numpy】
文章目录 一,numpy(上)1.1基础概念1.2数组的属性1.3数组创建1.4 类型转换1.5ndarry基础运算(上)矢量化运算1.6拷贝和视图1.6.1完全不复制1.6.2视图或浅拷贝1.6.3深拷贝 1.7索引,切片和迭代1.7.1一维数组1.7…...

Eclipse 主网即将上线迎空投预期,Zepoch 节点或成受益者?
目前,Zepoch 节点空投页面中,模块化 Layer2 Rollup 项目 Eclipse 出现在其空投列表中。 配合近期 Eclipse 宣布了其将由 SVM 提供支持的 Layer2 主网架构,并将在今年年底上线主网的消息后,不免引发两点猜测:一个是 Ecl…...
 | 输入输出)
JavaSE | 初识Java(四) | 输入输出
基本语法 System.out.println(msg); // 输出一个字符串, 带换行 System.out.print(msg); // 输出一个字符串, 不带换行 System.out.printf(format, msg); // 格式化输出 println 输出的内容自带 \n, print 不带 \n printf 的格式化输出方式和 C 语言的 printf 是基本一致的 代码…...

车牌超分辨率:License Plate Super-Resolution Using Diffusion Models
论文作者:Sawsan AlHalawani,Bilel Benjdira,Adel Ammar,Anis Koubaa,Anas M. Ali 作者单位:Prince Sultan University 论文链接:http://arxiv.org/abs/2309.12506v1 内容简介: 1)方向:图像超分辨率技术…...
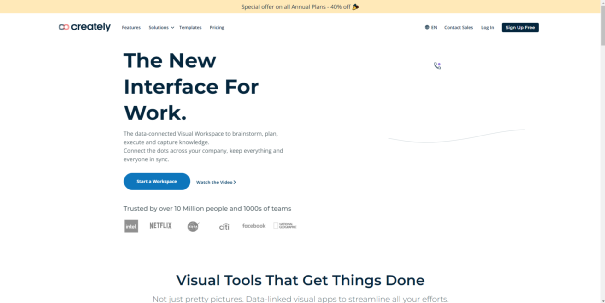
如何制作在线流程图?6款在线工具帮你轻松搞定
流程图,顾名思义 —— 用视觉化的方式来描述一种过程或流程。它可以应用于各种领域,从业务流程,算法,到计算机程序等。然而,在创建流程图时,可能会遇到许多问题或者困惑,如缺乏专业的设计技能&a…...

反SSDTHOOK的另一种思路-0环实现自己的系统调用
反SSDTHOOK的另一种思路-0环实现自己的系统调用 大家都知道我们在应用层使用系统api除了gdi相关的都会走中断门或者systementer进0环然后在走ssdt表去执行0环的函数 这也就导致了ssdthook可以挡下大部分的api调用,那如果我们进0环走另外一条路线的话不通过ssdt就可…...
)
Certbot签发和续费泛域名SSL证书(通过DNS TXT记录来验证域名有效性)
我们在使用let’s encrypt获取免费的HTTPS证书的时候,let’s encrypt需要对域名进行验证,以确保域名是你自己的 之前用默认的文件验证方式总有奇怪的问题导致失败,我也是很无奈,于是改用验证DNS-TXT记录的方式来验证,而…...

PY32F003F18之RTC
一、RTC振荡器 PY32F003F18实时时钟的振荡器是内部RC振荡器,频率为32.768KHz。它也可以使用HSE时钟,不建议使用。HAL库提到LSE振荡器,但PY32F003F18实际上没有这个振荡器。 缺点:CPU掉电后,需要重新配置RTCÿ…...

redis主从从,redis-7.0.13
redis主从从,redis-7.0.13 下载redis安装redis安装redis-7.0.13过程报错1、没有gcc,报错2、没有python3,报错3、[adlist.o] 错误 127 解决安装报错安装完成 部署redis 主从从结构redis主服务器配置redis启动redis登录redisredis默认是主 redi…...

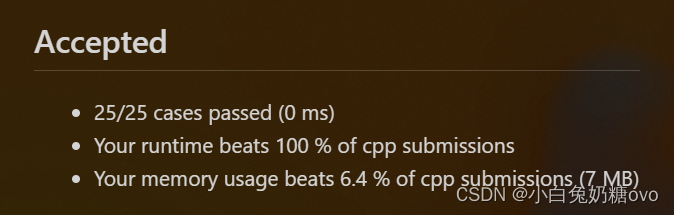
力扣-338.比特位计数
Idea 直接暴力做法:计算从0到n,每一位数的二进制中1的个数,遍历其二进制的每一位即可得到1的个数 AC Code class Solution { public:vector<int> countBits(int n) {vector<int> ans;ans.emplace_back(0);for(int i 1; i < …...
【Leetcode】 17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits "23" 输出&…...
洛谷P1102 A-B 数对题解
目录 题目A-B 数对题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示传送门 代码解释亲测 题目 A-B 数对 题目背景 出题是一件痛苦的事情! 相同的题目看多了也会有审美疲劳,于是我舍弃了大家所熟悉的 AB Problem,改用 …...
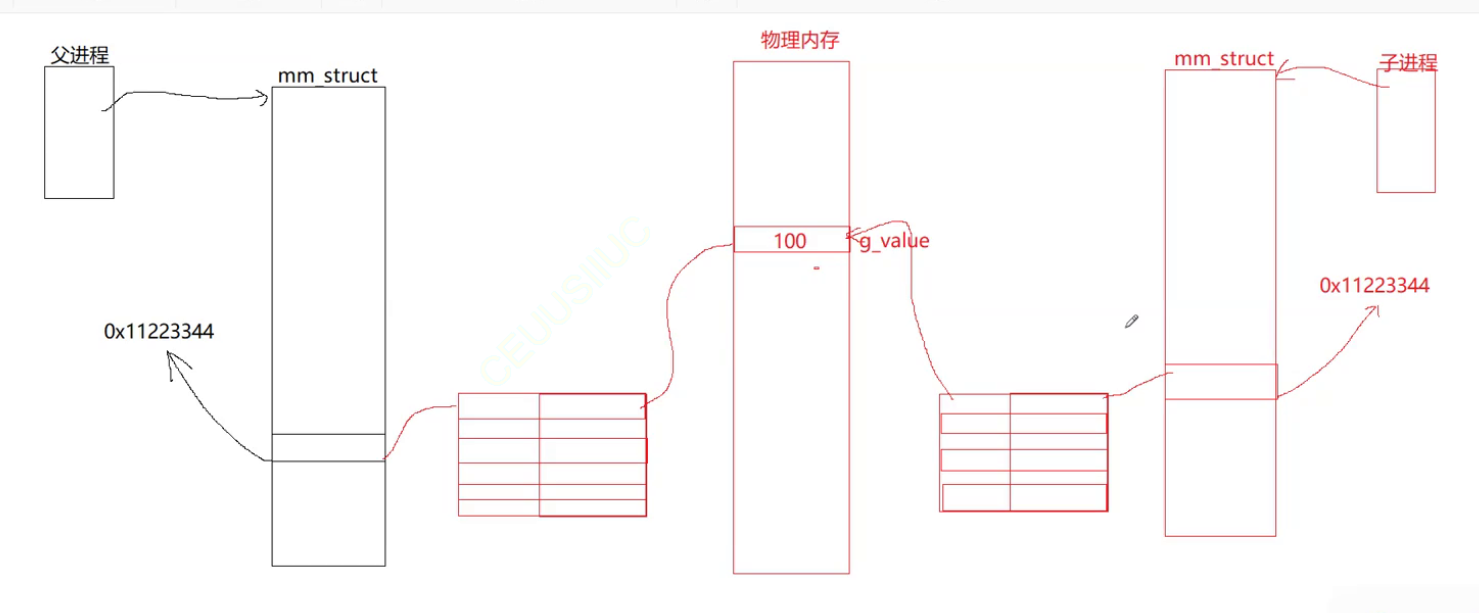
【Linux进行时】进程地址空间
进程地址空间 例子引入: 我们在讲C语言的时候,老师给大家画过这样的空间布局图,但是我们对它不了解 我们写一个代码来验证Linux进程地址空间 #include<stdio.h> #include<assert.h> #include<unistd.h> int g_value100; …...
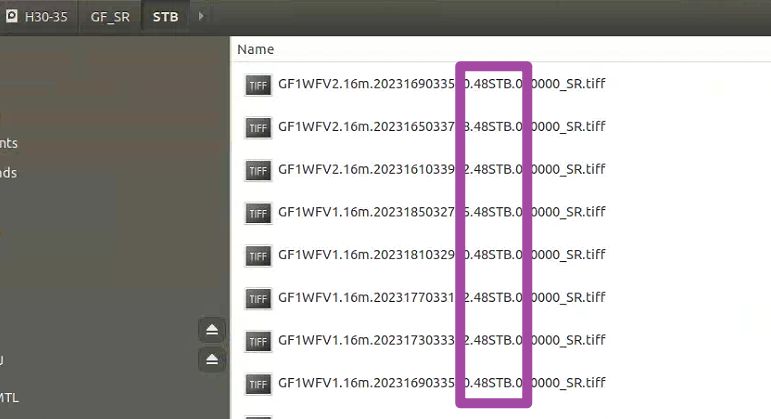
批量将文件名称符合要求的文件自动复制到新文件夹:Python实现
本文介绍基于Python语言,读取一个文件夹,并将其中每一个子文件夹内符合名称要求的文件加以筛选,并将筛选得到的文件复制到另一个目标文件夹中的方法。 本文的需求是:现在有一个大的文件夹,其中含有多个子文件夹&#x…...
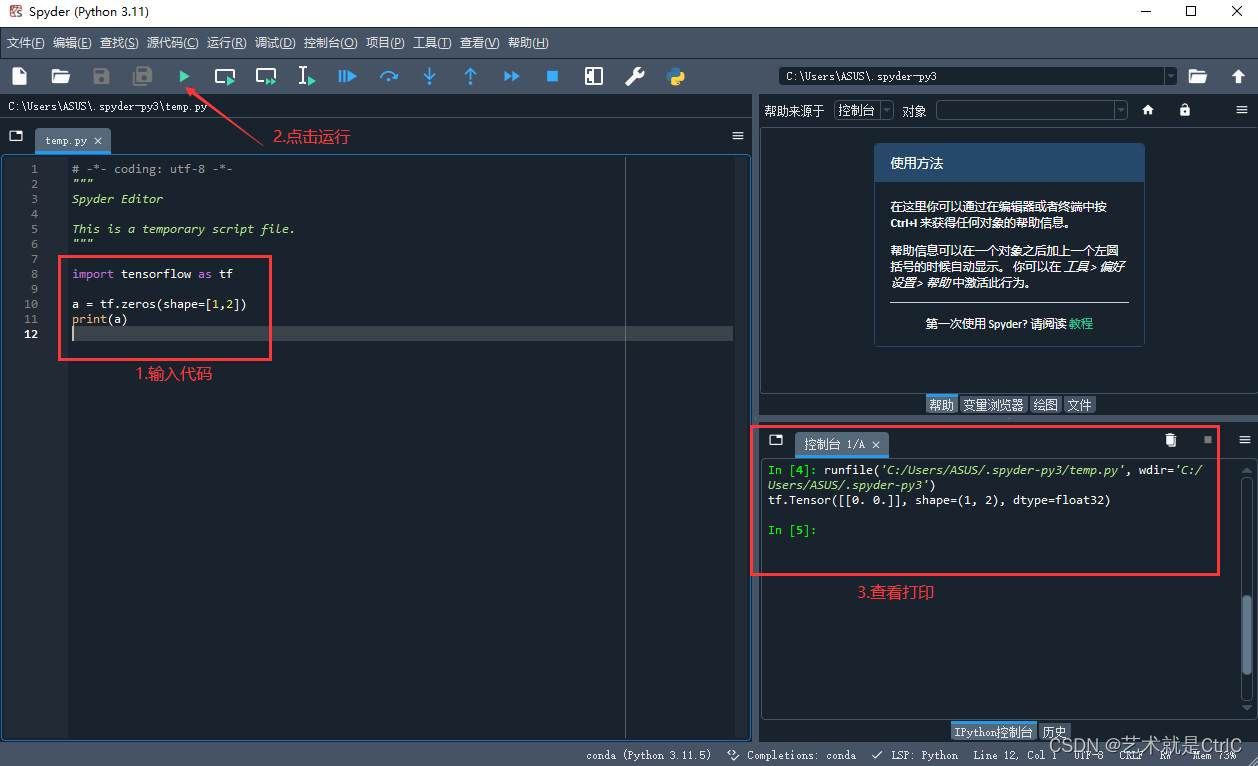
TensorFlow入门(一、环境搭建)
一、下载安装Anaconda 下载地址:http://www.anaconda.comhttp://www.anaconda.com 下载完成后运行exe进行安装 二、下载cuda 下载地址:http://developer.nvidia.com/cuda-downloadshttp://developer.nvidia.com/cuda-downloads 下载完成后运行exe进行安装 安装后winR cmd进…...
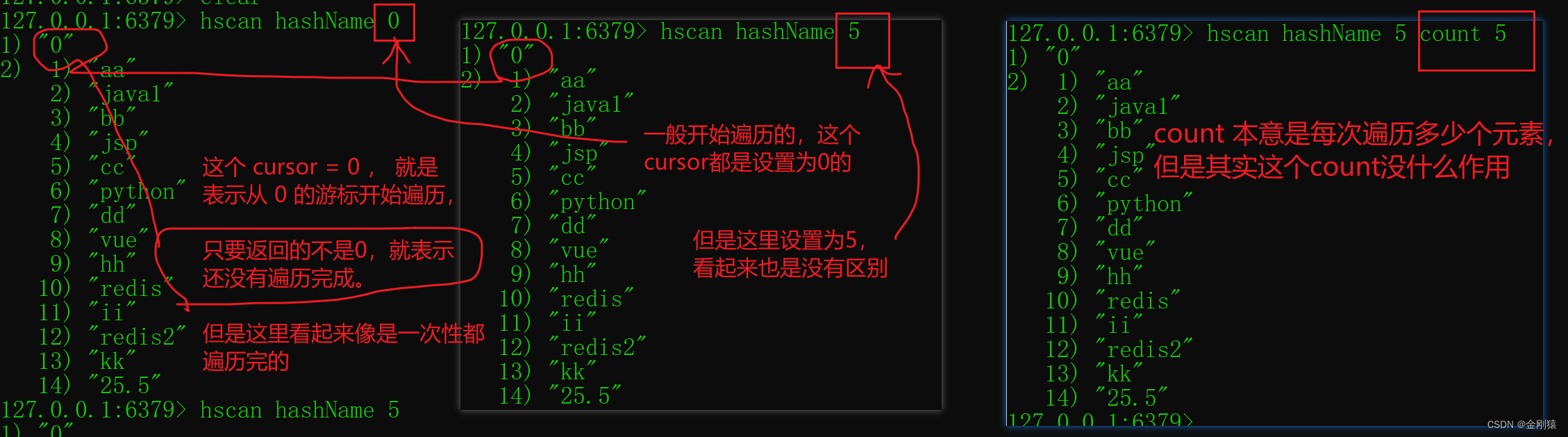
90、Redis 的 value 所支持的数据类型(String、List、Set、Zset、Hash)---->Hash 相关命令
本次讲解要点: Hash 相关命令:是指value中的数据类型 启动redis服务器: 打开小黑窗: C:\Users\JH>e: E:>cd E:\install\Redis6.0\Redis-x64-6.0.14\bin E:\install\Redis6.0\Redis-x64-6.0.14\bin>redis-server.exe red…...

我开源了一个加密算法仓库,支持18种算法!登录注册业务可用!
文章目录 仓库地址介绍安装用法SHA512HMACBcryptScryptAESRSAECC 仓库地址 仓库地址:https://github.com/palp1tate/go-crypto-guard 欢迎star和fork! 介绍 此存储库包含用 Go 编写的全面的密码哈希库。该库支持多种哈希算法,它允许可定制…...
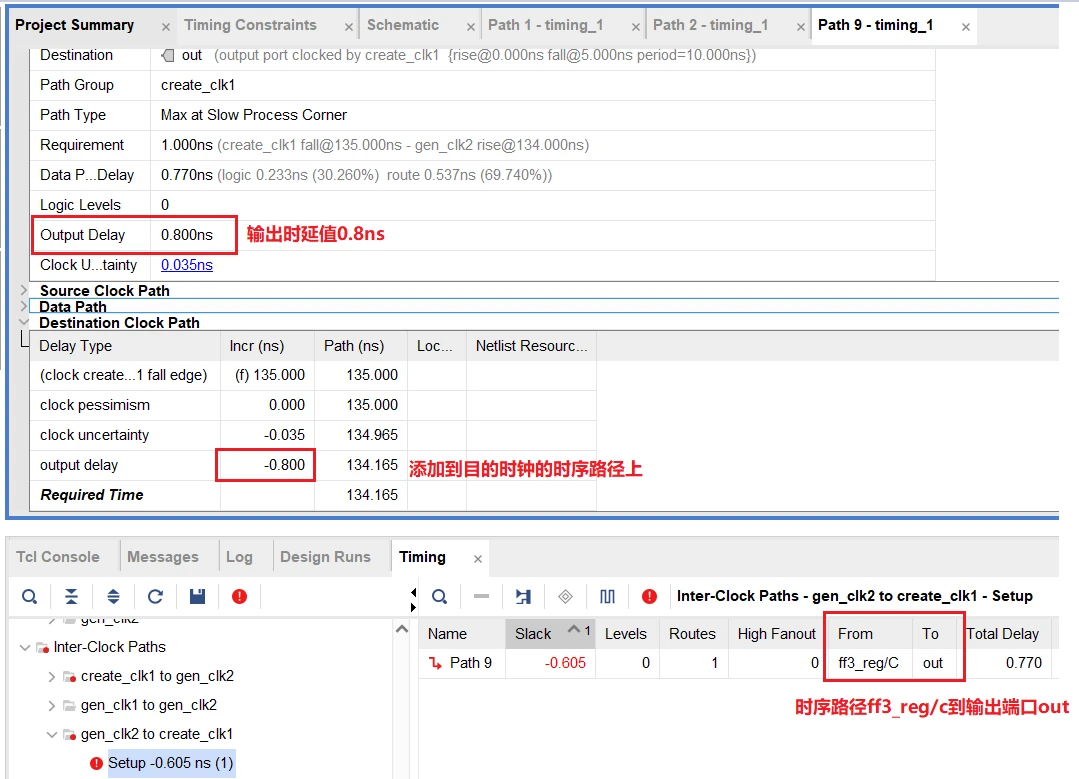
FPGA设计时序约束二、输入延时与输出延时
目录 一、背景 二、set_input_delay 2.1 set_input_delay含义 2.2 set_input_delay参数说明 2.3 使用样例 三、set_output_delay 3.1 set_output_delay含义 3.2 set_output_delay参数说明 3.3 使用样例 四、样例工程 4.1 工程代码 4.2 时序报告 五、参考资料 一、…...
电阻的基础与应用
文章目录 电阻的基础与应用电阻的介绍与分类电阻介绍电阻的分类碳膜/金属膜电阻厚膜/薄膜电阻功能性电阻(光敏/热敏/压敏)特殊电阻(绕线电阻/水泥电阻/铝壳电阻) 电阻的主要厂家与介绍国外厂家VISHAY(威世)KOA(兴亚)Kyocera(京瓷)…...

5.html表格
<table><tr><th>列1标题</th><th>列2标题</th><th>列3标题</th></tr><tr><td>行1列1</td><td>行1列2</td><td>行1列3</td></tr><tr><td>行2列1</td>…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...