【办公自动化】在Excel中按条件筛选数据并存入新的表(文末送书)

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python处理Excel
二、在Excel中按条件筛选数据并存入新的表
三、往期推荐
四、文末推荐与福利
一、Python处理Excel
-
Python处理Excel的好处
1.批量操作:当要处理众多Excel文件时,例如出现重复性的手工劳动,那么使用Python就可以实现批量扫描文件、自动化进行处理,利用代码代替手工重复劳动,实现自动化,是Python第一个比Excel强大的地方
2.大型文件,当Excel文件超过几十兆、甚至上百兆时,打开文件很慢、处理文件更加慢,这时候若使用Python,会发现处理几十兆、几百兆甚至几GB都是没有问题的
3.当使用Excel进行复杂的计算时,会使用VBA,但是VBA本身是过时并且复杂的语言,Python是当前最简单且容易实现的一门语言,用Python能够处理比VBA难度更高的业务逻辑
4.Python是通用语言,不仅可以处理Excel,使用Python就可以得到很多额外的功能,例如:爬虫、发布网页的Web服务、与数据库进行连接、同时结合word和PPT进行处理、加入定时任务处理、人工智能分析等,各种额外的功能,这是Excel和VBA所不具备的
-
Python处理Excel主要有三大类库
1.pandas:是Python领域非常重要的,用于数据分析和可视化的类库,在处理Excel中,90%可以利用pandas类库就可以搞掂,利用pandas就可以读取Excel、处理Excel和输出Excel,但是pandas也有缺点,就是无法做到格式类,例如Excel中合并单元、大量复杂的样式(看起来很精美)的时候,用pandas无法搞掂,此时,依然是使用pandas结合openyxl、xlwings来搞掂需求
2.openpyxl:若电脑上未安装office时,也可以使用openpyxl,这个类型可以运行在linux上,并且也可以实现操作大部分Excel格式和样式的功能,使用它配合pandas,也可以完成大部分场景的需求
3.xlwings:比openyxl更加强大,只能运行在Windows或者Mac系统,并且该系统中必须安装了office才能运行,xlwings的原理,就是基于当前系统已经安装好的office软件,来进行功能的拓展来操作Excel
-
使用pandas的时候,经常会结合其他类库,来完成更加复杂的功能
-
requests, bs4:可以完成爬虫的功能
-
flask:可以做网页,把表格展示在网页上
-
Matplotlib:读取表格后,进行可视化
-
sklearn:进行复杂的数据分析时,也可以结合机器学习Sklearn把读取的Excel数据,进行数据分析和机器学习
-
Python-docx:也可以结合Python-docx类库,实现Excel和word的互通
-
smtplib:也可以使用smtplib,讲Excel数据发送邮件出去
-
-
开发环境
操作系统:使用windows, mac都可以
Python版本:系统中需要安装Python3.6以上的版本,Python2已经过期不建议使用,Python3.6以前的版本功能相对弱,最好就是采用Python3.6以上的版本
开发工具:有两个可以选择,jupyter notebook,是个网页编辑器,可以运行Python,常常用于交互性、探索性的开发;pycharm,用于成熟脚本,或者web服务的一些开发;这两个工具可以随意选择。
二、在Excel中按条件筛选数据并存入新的表
技术工具:
Python版本:3.9
代码编辑器:jupyter notebook
老板想要看去年每月领料数量大于1000的数据。手动筛选并复制粘贴出来,需要重复操作12次,实在太麻烦了,还是让Python来做吧。磨刀不误砍柴工,先整理一下思路:
1. 读取原表,将数量大于1000的数据所对应的行整行提取(如同在excel表中按数字筛选大于1000的)
2. 将提取的数据写入新的Excel表
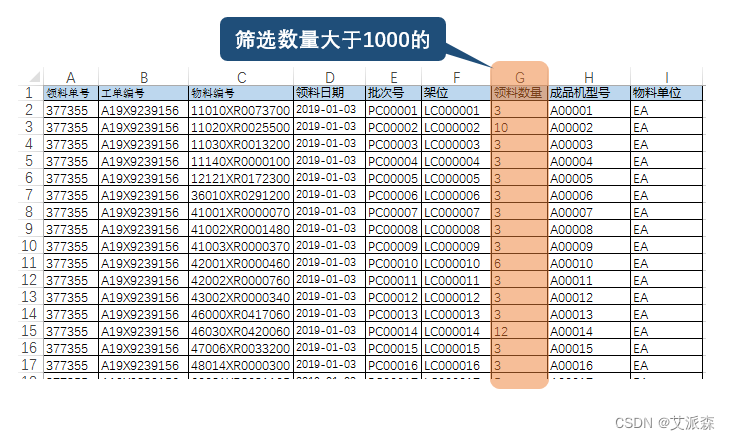
#1.获取满足条件的数据
from openpyxl import load_workbook
wb = load_workbook("每月物料表.xlsx")
data = {} #储存所有工作表中满足条件的数据,以工作表名称为键
sheet_names = wb.sheetnames
for sheet_name in sheet_names:ws = wb[sheet_name]qty_list = []#获取G列的数据,并用enumrate给其对应的元素编号for row in range(2,ws.max_row+1):qty = ws['G'+str(row)].valueqty_list.append(qty)qty_idx = list(enumerate(qty_list)) #用于编号#判断数据是否大于1000,然后返回大于1000的数据所对应的行数row_idx = [] #用于储存数量大于1000所对应的的行号for i in range(len(qty_idx)):if qty_idx[i][1] > 1000:row_idx.append(qty_idx[i][0]+2)#获取满足条件的数据 data_morethan1K = []for i in row_idx:data_morethan1K.append(ws['A'+str(i)+":"+'I'+str(i)])data[sheet_name]=data_morethan1K 以上,我们把满足条件的12个月的数据提取并存入字典`data`,其键为对应的月份,比如“1月”,值就是满足条件的各行的数据。我们把“每月物料表”的G列对应的数据提取,存入列表`qty_list`,其中前10个数据是如下这样的。
qty_list[:10]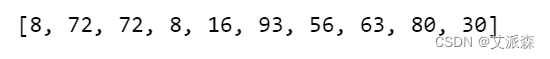
然后需要使用`enumerate`函数给这个列表的数据加上索引,以便在跟1000比大小的时候定位满足条件的那些数据的对应在Excel表中的行数。加上索引之后的列表是如下这样的,索引从0开始累加。
qty_idx[:10]
然后,再新建一个列表`row_idx`,用于储存“领料数量”大于1000的数据所对应的行号。此处用到`if`语句进行判断,只将“领料数量”大于1000的数据所对应的行号加上2存入列表。为什么要加2,是因为`range`函数是从0开始取的,然后工作表首行是字段名,第二行开始才是数据。如下结果显示了满足条件的数据对应的行数。
row_idx[:5]
然后新建列表`data_morethan1K`用于存储以上行号对应的整行数据。比如`ws['A1:I1']`就指第一行从A列到I列的所有单元格数据。最后将数据存入`data`字典中。数据结构如下所示。
data_morethan1K[1]
data['1月'] 
len(data['1月']) 
data['1月'][0][0][1].value ![]()
数据提取完成后,就可以开始写入数据了。打开模板,按月从`data`字典中提取数据。并根据数据结构找到层级关系,将其中的各行的数据写入各单元格。写完之后,设置一下字号、边框即对齐方式,保存数据。到此收工!
#2.写入获取的数据
from openpyxl.styles import Border, Side, PatternFill, Font, GradientFill, Alignment
thin = Side(border_style="thin", color="000000")#定义边框粗细及颜色wb = load_workbook("模板.xlsx")
ws = wb.active
for month in data.keys():ws_new = wb.copy_worksheet(ws) #复制模板中的工作表ws_new.title=month #将每个月的数据条数逐个取出并写入新的工作表for i in range(len(data[month])): #按数据行数计数,每行数据对应9列,所以每行需分别写入9个单元格ws_new.cell(row=i+2,column=1).value=data[month][i][0][0].valuews_new.cell(row=i+2,column=2).value=data[month][i][0][1].valuews_new.cell(row=i+2,column=3).value=data[month][i][0][2].valuews_new.cell(row=i+2,column=4).value=data[month][i][0][3].value.date()ws_new.cell(row=i+2,column=5).value=data[month][i][0][4].valuews_new.cell(row=i+2,column=6).value=data[month][i][0][5].valuews_new.cell(row=i+2,column=7).value=data[month][i][0][6].valuews_new.cell(row=i+2,column=8).value=data[month][i][0][7].valuews_new.cell(row=i+2,column=9).value=data[month][i][0][8].value#设置字号,对齐,缩小字体填充,加边框#Font(bold=True)可加粗字体for row_number in range(2, ws_new.max_row+1):for col_number in range(1,10):c = ws_new.cell(row=row_number,column=col_number)c.font = Font(size=10)c.border = Border(top=thin, left=thin, right=thin, bottom=thin)c.alignment = Alignment(horizontal="left", vertical="center",shrink_to_fit = True)
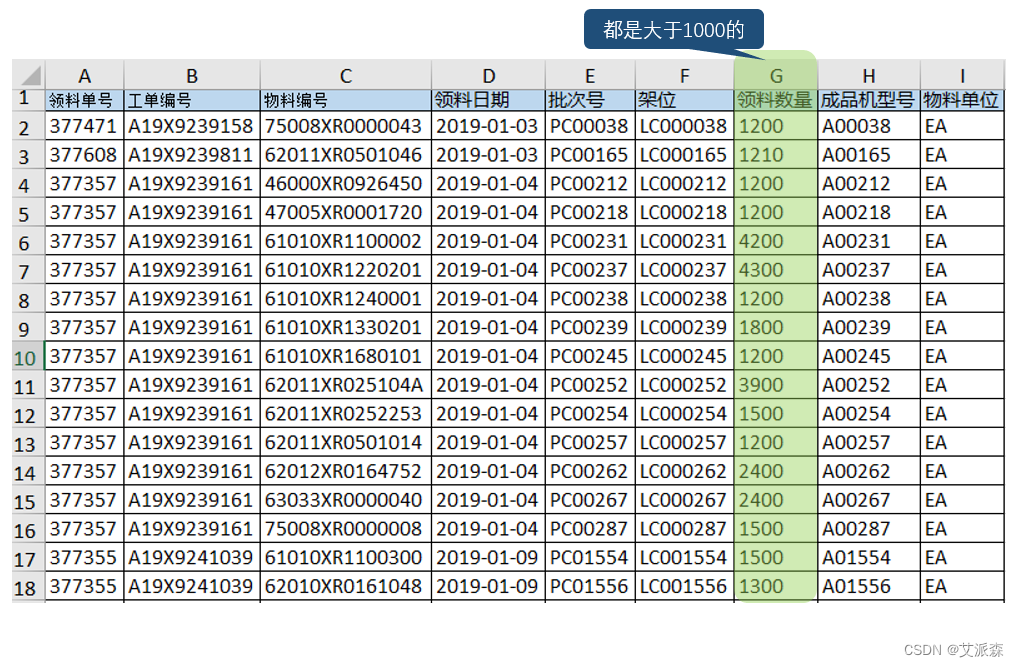
wb.save("每月(大于1K).xlsx")华丽的结果如下:
三、往期推荐
Python提取pdf中的表格数据(附实战案例)
使用Python自动发送邮件
Python操作ppt和pdf基础
Python操作word基础
Python操作excel基础
使用Python一键提取PDF中的表格到Excel
使用Python批量生成PPT版荣誉证书
使用Python批量处理Excel文件并转为csv文件
四、文末推荐与福利
《ChatGPT进阶:提示工程入门》免费包邮送出3本!

内容简介:
《ChatGPT进阶:提示工程入门》是一本面向所有人的提示工程工具书,旨在帮助你掌握并有效利用以ChatGPT为代表的AI工具。学习完《ChatGPT进阶:提示工程入门》后,你将能够自如地将ChatGPT运用在生活和专业领域中,成为ChatGPT进阶玩家。
《ChatGPT进阶:提示工程入门》共分为9章,内容涵盖三个层次:介绍与解读、入门学习、进阶提升。第1~2章深入介绍与剖析了ChatGPT与提示工程,并从多个学科的角度探讨了提示工程学科。第3~5章演示了ChatGPT的实际运用,教你如何使用ChatGPT解决自然语言处理问题,并为你提供了一套可操作、可重复的提示设计框架,让你能够熟练驾驭ChatGPT。第6~9章讲解了来自学术界的提示工程方法,以及如何围绕ChatGPT进行创新;此外,为希望ChatGPT进行应用开发的读者提供了实用的参考资料,并介绍了除ChatGPT之外的其他选择。
《ChatGPT进阶:提示工程入门》聚焦ChatGPT的实际应用,可操作,可重复,轻松易读却不失深度。无论你是对ChatGPT及类似工具充满好奇,还是期待将其转化为生产力。编辑推荐:
系统:全面剖析ChatGPT应用技巧,带你从小白变身ChatGPT应用专家。
实用:内含开箱即用的“提示公式”,聚焦ChatGPT实际应用。
有思路,有办法,能落地:带你将ChatGPT真正转化为生产力,开启AI驱动的工作流程。
简单易读:深入浅出,循序渐进,内含60 个示例,适合初学者和进阶读者。
深度:理论结合实际,涵盖提示工程学科深度讨论,授人以鱼更授人以渔。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-10-05 20:00:00
京东购买链接:https://item.jd.com/14098844.html
当当网购买链接:http://product.dangdang.com/29612772.html
名单公布时间:2023-10-05 21:00:00
相关文章:
【办公自动化】在Excel中按条件筛选数据并存入新的表(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
)
第三章:最新版零基础学习 PYTHON 教程(第十一节 - Python 运算符—Python 中的any与all)
Any 和 All 是 python 中提供的两个内置函数,用于连续的与/或。Any如果任何一项为 True,则返回 true。如果为空或全部为 false,则返回 False。Any 可以被认为是对所提供的可迭代对象进行 OR 操作的序列。它会短路执行,即一旦知道结果就停止执行。 句法: any(iterable) 函…...
Pytorch单机多卡分布式训练
Pytorch单机多卡分布式训练 数据并行: DP和DDP 这两个都是pytorch下实现多GPU训练的库,DP是pytorch以前实现的库,现在官方更推荐使用DDP,即使是单机训练也比DP快。 DataParallel(DP) 只支持单进程多线程…...

asp.net coremvc+efcore增删改查
下面是一个使用 EF Core 在 ASP.NET Core MVC 中完成增删改查的示例: 创建一个新的 ASP.NET Core MVC 项目。 安装 EF Core 相关的 NuGet 包。在项目文件 (.csproj) 中添加以下依赖项: <ItemGroup><PackageReference Include"Microsoft…...

Java基础面试,什么是面向对象,谈谈你对面向对象的理解
前言 马上就要找工作了,从今天开始一天准备1~2道面试题,来打基础,就从Java基础开始吧。 什么是面向对象,谈谈你对面向对象的理解? 谈到面向对象,那就不得不谈到面向过程。面向过程更加注重的是完成一个任…...
Ubuntu系统初始设置
更换国内源 安装截图工具 安装中文输入法 安装QQ 参考: 安装双系统win10Ubuntu20.04LTS(详细到我自己都害怕) 引导方式磁盘分区方法UEFIGPTLegancyMBR 安装网络助手 sudo apt install net-tools 安装VS Code 使用从官网下载.deb安装包…...

焕新古文化传承之路,AI为古彝文识别赋能
目录 1 古彝文与古典保护 2 古文识别的挑战 2.1 西文与汉文OCR 2.2 古彝文识别难点 3 合合信息:古彝文保护新思路 3.1 图像矫正 3.2 图像增强 3.3 语义理解 3.4 工程技巧 4 总结 1 古彝文与古典保护 彝文指的是云南、贵州、四川等地的彝族人使用的文字&am…...

毛玻璃动画交互效果
效果展示 页面结构组成 从上述的效果展示页面结构来看,页面布局都是比较简单的,只是元素的动画交互比较麻烦。 第一个动画交互是两个圆相互交错来回运动。第二个动画交互是三角绕着圆进行 360 度旋转。 CSS 知识点 animationanimation-delay绝对定位…...

Audio2Face的工作原理
预加载一个3D数字人物模型(Digital Mark),该模型可以通过音频驱动进行面部动画。 用户上传音频文件作为输入。 将音频输入馈送到预训练的深度神经网络中。 Audio2Face加载预制的3d人头mesh 3D数字人物面部模型由大量顶点组成,每个顶点都有xyz坐标。 深度神经网络输入音频特征,…...

【面试题】2023前端面试真题之JS篇
前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 表妹一键制作自己的五星红旗国庆头像,超好看 世界上只有一种真正的英雄主义,那就是看清生活的真相之后,依然热爱生活。…...
Mysql 分布式序列算法
接上文 Mysql分库分表 1.分布式序列简介 在分布式系统下,怎么保证ID的生成满足以上需求? ShardingJDBC支持以上两种算法自动生成ID。这里,使用ShardingJDBC让主键ID以雪花算法进行生成,首先配置数据库,因为默认的注…...

Windows/Linux双系统卸载Ubuntu
参考:双系统下完全卸载ubuntu...

asp.net core mvc 视图组件viewComponents
ASP.NET Core MVC 视图组件(View Components)是一种可重用的 UI 组件,用于在视图中呈现某些特定的功能块,例如导航菜单、侧边栏、用户信息等。视图组件提供了一种将视图逻辑与控制器解耦的方式,使视图能够更加灵活、可…...

如何保持终身学习
文章目录 2.1. 了解你的大脑2.2 学习是对神经元网络的塑造2.3 大脑的一生 3.学习的心里基础3.1 固定思维与成长思维3.2 我们为什么要学习 4. 学习路径4.1 构建知识模块4.2 大脑是如何使用注意力的4.3 提高专注力4.4 放松一下,学的更好4.5 巩固你的学习痕迹4.6 被动学…...
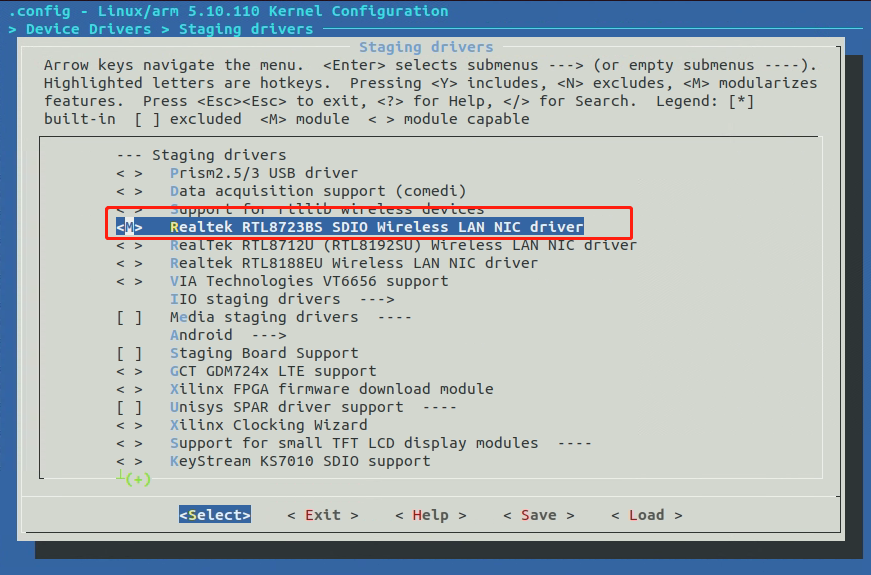
【RV1103】RTL8723bs (SD卡形状模块)驱动开发
文章目录 前言硬件分析Luckfox Pico的SD卡接口硬件原理图LicheePi zero WiFiBT模块总结 正文Kernel WiFi驱动支持Kernel 设备树支持修改一:修改二: SDK全局配置支持 wifi全局编译脚本支持编译逻辑拷贝rtl8723bs的固件到文件系统的固定目录里面去 上电后手…...

LeetCode 周赛上分之旅 #49 再探内向基环树
⭐️ 本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 和 BaguTree Pro 知识星球提问。 学习数据结构与算法的关键在于掌握问题背后的算法思维框架,你的思考越抽象,它能覆盖的问题域就越广,理解难度…...

kubernetes-v1.23.3 部署 kafka_2.12-2.3.0
文章目录 [toc]构建 debian 基础镜像部署 zookeeper配置 namespace配置 gfs 的 endpoints配置 pv 和 pvc配置 configmap配置 service配置 statefulset 部署 kafka配置 configmap配置 service配置 statefulset 这里采用的部署方式如下: 使用自定义的 debian 镜像作为…...

位置编码器
目录 1、位置编码器的作用 2、代码演示 (1)、使用unsqueeze扩展维度 (2)、使用squeeze降维 (3)、显示张量维度 (4)、随机失活张量中的数值 3、定义位置编码器类,我…...
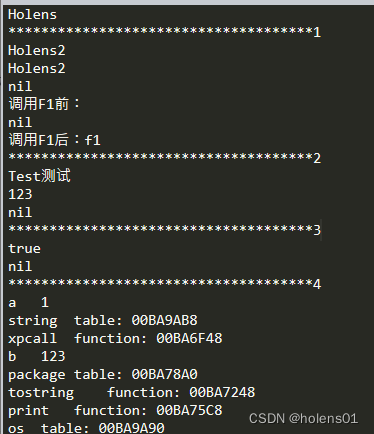
Lua多脚本执行
--全局变量 a 1 b "123"for i 1,2 doc "Holens" endprint(c) print("*************************************1")--本地变量(局部变量) for i 1,2 dolocal d "Holens2"print(d) end print(d)function F1( ..…...
Spirng Cloud Alibaba Nacos注册中心的使用 (环境隔离、服务分级存储模型、权重配置、临时实例与持久实例)
文章目录 一、环境隔离1. Namespace(命名空间):2. Group(分组):3. Services(服务):4. DataId(数据ID):5. 实战演示:5.1 默…...

Anthropic新模型Mythos号称擅查漏洞,扫描curl代码却仅确认1个低危问题
Mythos高调亮相,扫描结果却令人意外 近期,Anthropic推出的AI安全分析模型Mythos引发广泛关注,该公司宣称其在发现源代码安全漏洞方面表现出色,甚至因此暂缓公开发布。然而,当Mythos扫描全球最广泛使用的开源命令行HTTP…...

在Node.js后端服务中集成Taotoken调用多模型API实战
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型API实战 构建需要AI能力的Web服务时,后端开发者常面临模型选型、API接入复…...

分布式架构实战:全平台矩阵管理系统的技术实现与性能优化
前言在数字化运营进入全域竞争的今天,多平台账号集群管理已成为企业与开发者的核心技术挑战。传统单体架构的矩阵工具普遍存在算力弹性不足、账号关联风险高、跨平台适配复杂、AI 能力割裂等问题,导致 90% 以上的自研矩阵系统最终以失败告终。本文基于生…...

Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析
Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一款高性能的Adobe ExtendScript二进制格式(JSXBIN&#…...
)
深入浅出MCP:从零开始的完整学习指南(保姆级教程)
手把手带你理解MCP是什么、怎么用、如何开发,每个步骤都有详细说明 写在前面 很多朋友看完MCP的介绍还是一头雾水:“这到底是什么?跟我有什么关系?我该怎么用?” 别急,这篇文章我会用最通俗的方式&#x…...

别再复制粘贴了!手把手教你封装一个可复用的Qt文本编辑器核心组件类
从零封装高复用Qt文本编辑器核心类:工程化实践指南 在Qt开发中,文本编辑器是最常见的功能需求之一。许多开发者习惯将所有逻辑堆砌在MainWindow类中,导致代码臃肿、难以维护和复用。本文将带你从工程化角度重构文本编辑器,将其核心…...
原理、影响与防护策略全解析)
FPGA单粒子翻转(SEU)原理、影响与防护策略全解析
1. 是什么在“骚扰”我的FPGA?——深入解析单粒子翻转作为一名在电子设计领域摸爬滚打了十几年的工程师,我经手过不少高可靠性的项目,从地面通信基站到近地轨道的载荷设备都有涉及。在这些项目中,有一个幽灵般的问题总是如影随形&…...

如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南
如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容…...

602 游戏平台 — 做玩家喜爱、信任的游戏平台!
602 游戏是2013 年上线的老牌正规页游平台,十年稳定运营,始终以 “玩家喜爱、信任”为核心,主打传奇类精品页游 ,三端互通✅ 平台核心优势(为什么玩家信任)正规合规,账号安全:文网文…...

怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略
怎样3步掌握桌面自动化:智能鼠标键盘录制工具完整攻略 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo Keymouse…...