分布式并行训练(DP、DDP、DeepSpeed)
[pytorch distributed] 01 nn.DataParallel 数据并行初步
- 数据并行 vs. 模型并行
-
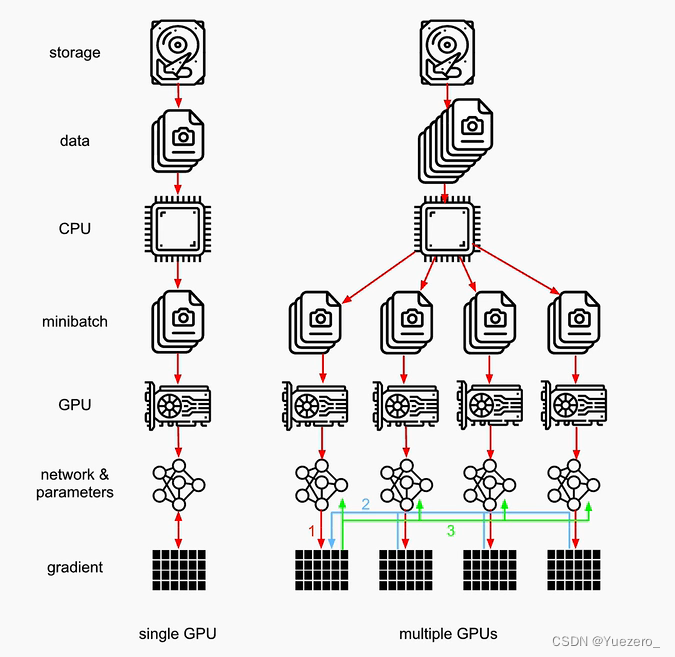
数据并行:模型拷贝(per device),数据 split/chunk(对batch切分)- 每个device上都拷贝一份完整模型,每个device分别处理1个batch的一部分(如batch_size=64, 2个device, 每device处理32个样本)
- 梯度反向传播时,每个设备上的梯度求和(
求和才是一个完整batch所有样本的loss),汇入中心设备/参数服务器(默认gpu0)对模型进行梯度优化。
-
模型并行:数据拷贝(per device),模型 split/chunk(显然是单卡放不下模型的情况下)
-
- DP => DDP
DP:nn.DataParallel(不推荐)- https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html
DDP:DistributedDataParallel(推荐)- Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel and Distributed Data Parallel.
1. 数据并行DP(nn.DataParallel)
预先定义一下Dataset和Model
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoaderclass RandomDataset(Dataset):def __init__(self, size, length):self.len = length# 100*5self.data = torch.randn(length, size)def __getitem__(self, index):# (5, )return self.data[index]def __len__(self):# 100return self.lenclass Model(nn.Module):# Our modeldef __init__(self, input_size, output_size):# 5 => 2super(Model, self).__init__()self.fc = nn.Linear(input_size, output_size)def forward(self, input):output = self.fc(input)print("\tIn Model: input size", input.size(),"output size", output.size())return outputinput_size = 5 # 模型输入数据维度(b,n) = (30, 5)
output_size = 2 # 模型输出数据维度(b,n) = (30, 2)batch_size = 30 # batch size
data_size = 100 # 数据集样本数量rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),batch_size=batch_size, shuffle=True)
# 构造优化器和损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.MSELoss()# 模拟目标值
target = torch.randn(64, 5)
step1: 并行化包裹模型
# Parameters and DataLoaders
# (5, 2)
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1: # 如果不止1张GPU # 构建数据并行模型device_ids = [0, 1] # 使用的设备ID列表# 如3张GPU,dim = 0,[30, xxx] -> [15, ...], [15, ...] on 2 GPUsmodel = nn.DataParallel(model, device_ids) # 并行化,默认使用所有device加载数据
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)model= 指传入的模型device_ids=None,- 参与训练的 GPU 有哪些,device_ids=gpus,默认None是使用全部device;
output_device=None- 指定中心设备(参数服务器),用于汇总梯度的 GPU 是哪个,output_device=gpus[0]
dim=0- 从那一维度进行数据切分,默认batch维度
- 在执行 forward/backward 之前,使用 DataParallel 将 model 复制到 device_ids 指定设备上,进行数据并行处理。
model.to('cuda:0')- 不同的是tensor的to(device)是在device上生成一个拷贝,不改变原来cpu上的tensor;而model是直接将原model转移到gpu上。
step2:加载到device0
设置中心设备(参数服务器),用于反向传播时的梯度汇总,一般指定cuda:0
# 将模型从cpu放在gpu 0上
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
step3:forward前向传播
模型forward时,将data_loader加载的一个batch的数据进行切分,送入不同device的模型进行计算,再将结果合并输出。
for data in rand_loader:# input_var can be on any device, including CPUinput = data.to(device)
# input = dataoutput = model(input)print("Outside: input size", input.size(),"output_size", output.size())
"""In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
"""
step4:反向传播梯度聚合
loss.backward()分别在每个device上计算loss的梯度,average_gradients(model)将梯度聚合到中心设备/参数服务器(cuda:0)上,进行梯度优化
# 在每个设备上进行前向传播和梯度计算loss = criterion(output, target)loss.backward()# 对各个设备上的梯度进行求和average_gradients(model)# 使用原始设备模型进行梯度优化optimizer.step()
2. 分布式数据并行DDP(nn.parallel.DistributedDataParallel)
multiple GPUs in a single machine/server/node:单机多卡
- 分布式数据并行时,模型(model parameters)/优化器(optimizer states)每张卡都会拷贝一份(replicas)
- DDP 始终在卡间维持着模型参数和优化器状态的同步一致性在整个训练过程中;
- Data Parallel,一个batch的数据通过 DistributedSampler 切分split 分发到不同的 gpus 上
- 此时虽然模型/optimizer 相同,但因为每个device的数据输入不同,导致 loss 不同,反向传播时计算到的梯度也会不同
- 此时 ddp 通过 ring all-reduce algorithm ,保证每个batch step结束后不同卡间model/optimizer 的同步一致性
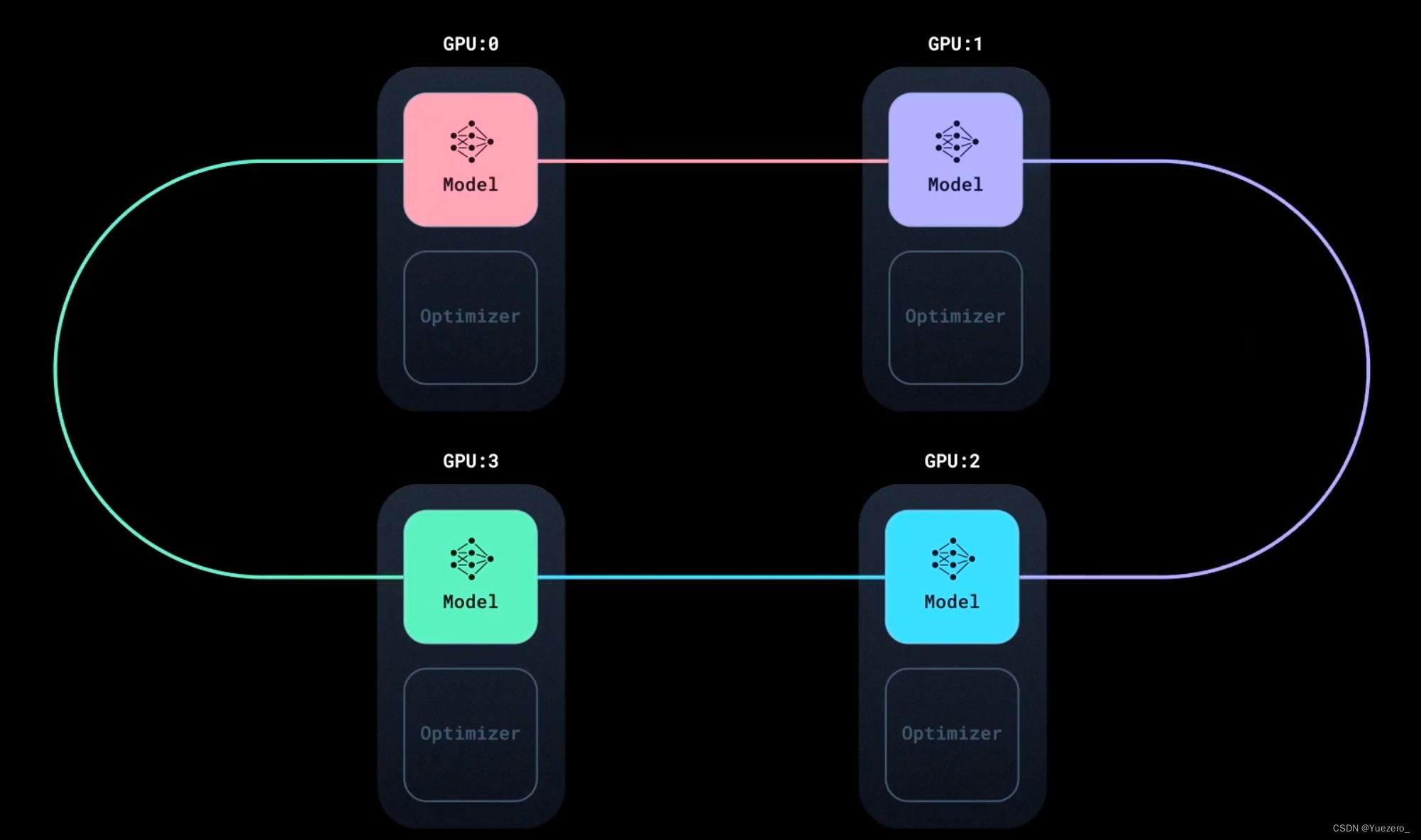
- 如上图所示,Ring all-reduce algorithm
- 首先会将所有的 gpu cards 连成一个 ring环
- 其同步过程,不需要等待所有的卡都计算完一轮梯度,
- 经过这个同步过程之后,所有的卡的 models/optimizers 就都会保持一致的状态;
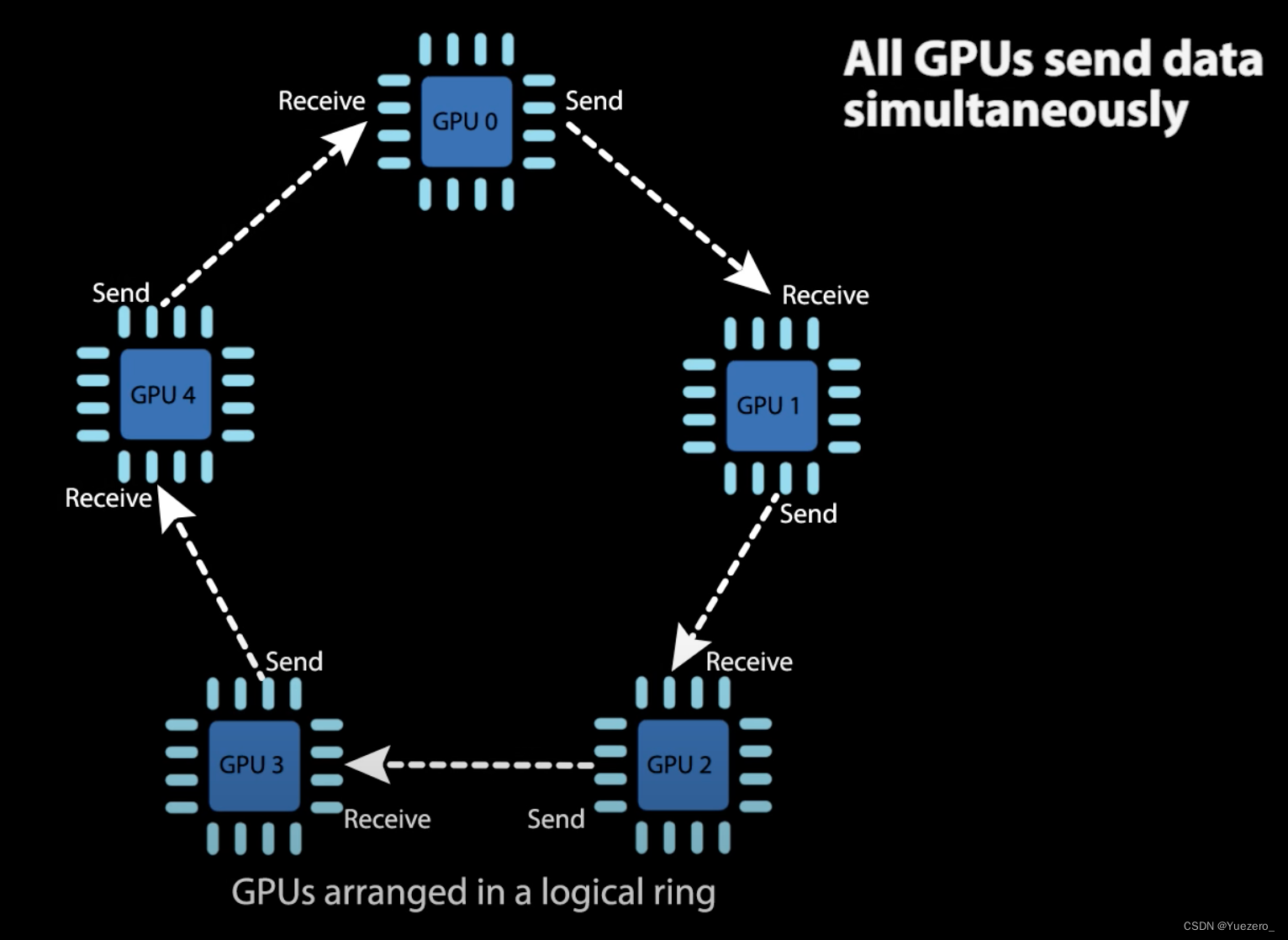
- Ring all-reduce algorithm 计算和同步的几个过程
- 红线:GPUs 分别计算损失(forward)和梯度(backward)
- 蓝线:梯度的聚合到中心device/参数服务器上(gpu0)
- 绿线:(模型/优化器)参数的更新及广播(broadcast);
其实参数服务器可以是一个GPU0,也可以是CPU,也可以是所有GPU:

但将数据发送到GPU0会成为device通信的瓶颈:
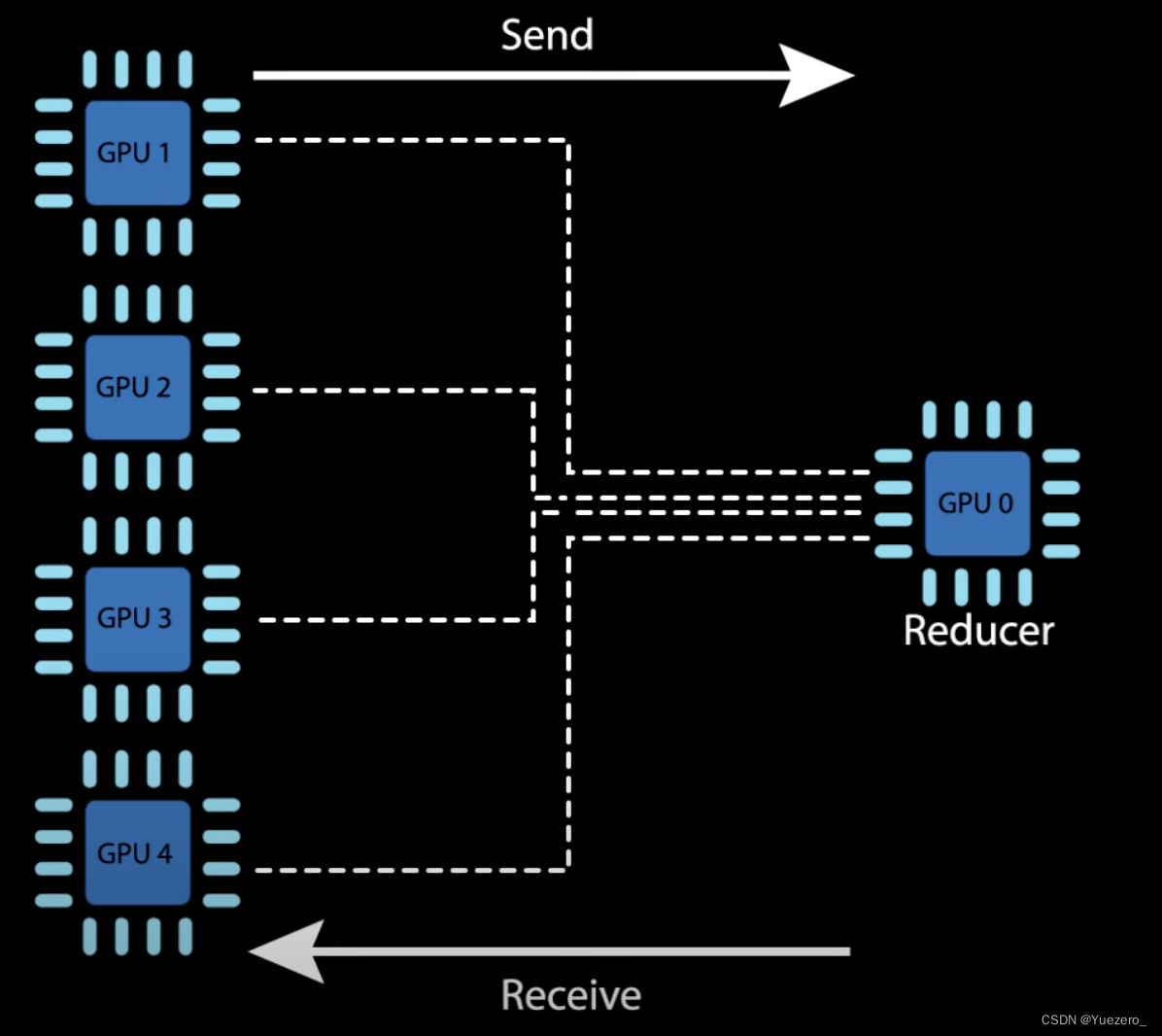
所以采用环形的梯度聚合方式更加高效:
DDP基本概念
-
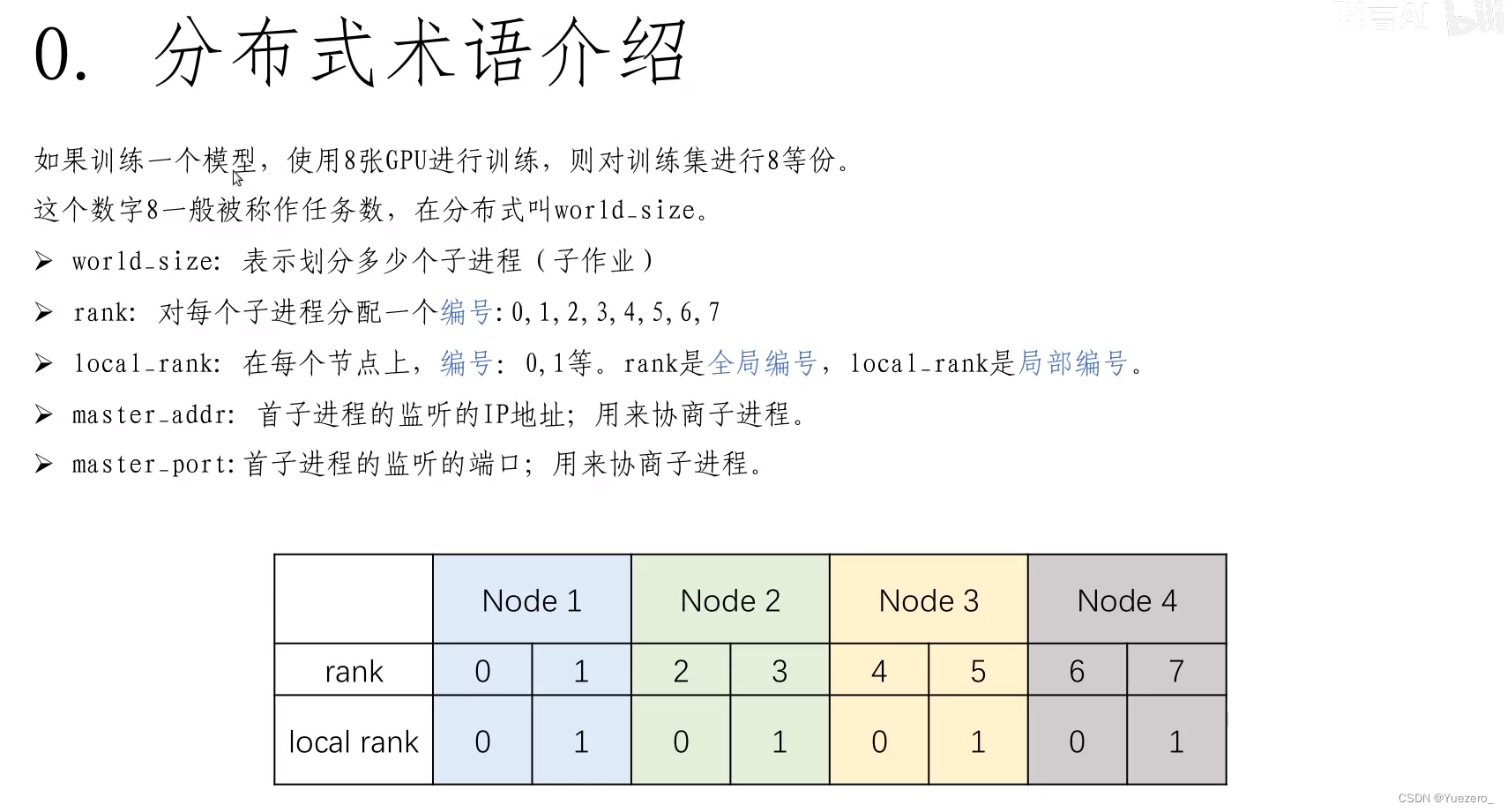
world:
- world 表示包含所有进程的组(所有gpu的集合)。
- 每个进程通常对应一个 GPU, world 中的进程可以相互通信,这使得使用分布式数据并行(Distributed Data Parallel, DDP)进行训练成为可能。
-
world_size(gpu个数/进程个数):
- world_size 表示分布式训练环境中的总进程数/gpu数。
- 每个进程都会被分配一个唯一的标识符(rank),从 0 到 world_size-1。
-
rank(进程标识符):
rank是分配给world中每个进程的唯一标识符,用于标识每个进程在分布式训练中的角色。local rank是分配个单个node中每个进程的标识符,world中可能有多个node。
-
node(节点):
- node 可以理解为一个服务器,代表着物理设备上的一个实体。
- 在多机分布式训练中,每台机器被视为一个节点,节点之间需要进行通信。
- 例如,如果有2 个node/server,每个 node/server/machine 各有4张卡(4 gpus)。total_world_size = 2(节点数) * 4(每个节点的 GPU 数量)= 8,
rank的取值范围为 [0, 1, 2, 3, 4, 5, 6, 7],local_rank的取值范围为 [0, 1, 2, 3],[0, 1, 2, 3] 分别对应着不同的节点上的进程。
-
All to one:聚合过程(reduce),所有GPU(model和optiminizer状态)汇聚到参数服务器;
-
one to All:广播过程(broadcast),参数服务器广播到所有GPU;
torchrun
torchrun运行分布式train.py脚本,nproc-per-node设置每个node服务器上的gpu个数(一般是1个服务器),ddp_gpus_torchrun.py脚本名称,--max_epochs 5 --batch_size 32脚本参数。
!torchrun --nproc-per-node=2 ddp_gpus_torchrun.py --max_epochs 5 --batch_size 32
实现batch_size不变的情况下,对step的切分:
(如单卡情况下,data_len=1024,batch_size=32,则一个gpu的step=1024/32=32)
(多卡情况下2个gpu,data_len=1024,batch_size=32,则每个gpu的step=(1024/32)/2=32/2=16)
step1:导入相关的包
import os
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoaderimport torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler # 分发数据
from torch.nn.parallel import DistributedDataParallel as DDP # 包装model使之数据并行
from torch.distributed import init_process_group, destroy_process_group
step2:ddp_setup函数
这个函数用于设置分布式训练的环境。它调用了init_process_group函数来初始化进程组,使用的通信backend后端是nccl(NVIDIA Collective Communication Library),然后使用torch.cuda.set_device函数,根据环境变量设置当前进程使用的GPU设备。
def ddp_setup():"""Args:rank: Unique identifier of each processworld_size: Total number of processes"""# rank 0 process
# os.environ["MASTER_ADDR"] = "localhost"
# os.environ["MASTER_PORT"] = "12355"# nccl:NVIDIA Collective Communication Library # 分布式情况下的,gpus 间通信init_process_group(backend="nccl")torch.cuda.set_device(int(os.environ['LOCAL_RANK']))
step3:Trainer类
这个类定义了一个模型训练的封装器。在初始化方法中,它接收一个模型backend、一个训练数据加载器train_dataloader、一个优化器train_dataloader作为参数,并将模型移动到GPU上,然后使用DistributedDataParallel对模型进行包装,以实现数据并行。(model先放cuda再DDP封装)
_run_batch方法实现了一次批量的训练过程,包括前向传播、计算损失、反向传播和更新参数。_run_epoch方法用于遍历整个训练集进行训练,self.train_dataloader.sampler.set_epoch(epoch)是用于设置数据加载器的epoch,以保证每个GPU在每个epoch开始时加载的数据都是不同的。train方法则用于控制训练的总体流程。
class Trainer:def __init__(self, model: torch.nn.Module, train_dataloader: DataLoader, optimizer: torch.optim.Optimizer, ) -> None:self.gpu_id = int(os.environ['LOCAL_RANK'])self.model = model.to(self.gpu_id)self.train_dataloader = train_dataloaderself.optimizer = optimizerself.model = DDP(model, device_ids=[self.gpu_id])def _run_batch(self, xs, ys):self.optimizer.zero_grad()output = self.model(xs)loss = F.cross_entropy(output, ys)loss.backward()self.optimizer.step()def _run_epoch(self, epoch):batch_size = len(next(iter(self.train_dataloader))[0])print(f'[GPU: {self.gpu_id}] Epoch: {epoch} | Batchsize: {batch_size} | Steps: {len(self.train_dataloader)}')self.train_dataloader.sampler.set_epoch(epoch)for xs, ys in self.train_dataloader:xs = xs.to(self.gpu_id)ys = ys.to(self.gpu_id)self._run_batch(xs, ys)def train(self, max_epoch: int):for epoch in range(max_epoch):self._run_epoch(epoch)
step4:MyTrainDataset类
这个类定义了一个自定义的训练数据集。在初始化方法中,它接收一个大小参数,并生成一组随机的数据样本。__len__方法返回数据集的大小,__getitem__方法用于获取指定索引处的数据样本。
class MyTrainDataset(Dataset):def __init__(self, size):self.size = sizeself.data = [(torch.rand(20), torch.rand(1)) for _ in range(size)]def __len__(self):return self.sizedef __getitem__(self, index):return self.data[index]
step5:main函数
这个函数是程序的主函数。在函数内部,首先调用了ddp_setup函数来设置分布式训练的环境。
然后创建了一个自定义的训练数据集和相应的数据加载器,以及一个线性模型和一个优化器。DistributedSampler是PyTorch提供的一个分布式采样器,用于确保每个进程加载的数据都是不同的且顺序随机。sampler对象被传入训练数据集的构造函数,可以通过数据加载器(如torch.utils.data.DataLoader)的sampler参数指定。在每个进程中,DistributedSampler会根据进程ID和进程数量,将整个训练数据集划分成多个部分,并为每个进程提供其应加载的数据索引。这样,在分布式训练过程中,每个进程只会加载自己负责的数据部分,避免了数据重复加载。
接下来,创建了一个Trainer对象,并调用其train方法进行模型训练。最后调用destroy_process_group函数销毁进程组。
def main(max_epochs: int, batch_size: int):ddp_setup()train_dataset = MyTrainDataset(2048)train_dataloader = DataLoader(train_dataset, batch_size=batch_size, pin_memory=True, shuffle=False, # batch input: split to each gpus (且没有任何 overlaping samples 各个 gpu 之间)sampler=DistributedSampler(train_dataset))model = torch.nn.Linear(20, 1)optimzer = torch.optim.SGD(model.parameters(), lr=1e-3)trainer = Trainer(model=model, optimizer=optimzer, train_dataloader=train_dataloader)trainer.train(max_epochs)destroy_process_group()
step6:解析命令行参数并运行主函数
在这个步骤中,首先使用argparse模块解析命令行参数,包括最大训练周期数max_epochs和批量大小batch_size。然后调用main函数,并将解析后的参数传递给它进行模型训练。
if __name__ == '__main__':import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--max_epochs', type=int, help='Total epochs to train the model')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()# world_size = torch.cuda.device_count()main(args.max_epochs, args.batch_size)
3. 模型并行
- 数据并行是切数据(scattering inputs and gathering outputs),模型并行是切模型(shards);
模型并行:单卡放不下一份模型;- 将一份大模型,不同的层切分到不同的卡上,forward时串行执行;
Huggingface实现
- device_map:
Huggingface支持自动实现模型并行- device_map参数的取值
["auto", "balanced", "balanced_low_0", "sequential"] auto的模型分割优先级:GPU(s) > CPU (RAM) > Disk
- device_map参数的取值
如下,如果有两种gpu,device_map="auto"使模型的layers的parameter分别加载到两张gpu上(各一半):
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
model = LlamaForCausalLM.from_pretrained("decapoda-research/llama-7b-hf",load_in_8bit=True,device_map="auto",
)
for i, para in enumerate(model.named_parameters()):
# print(f'{i}, {para[0]}\t {para[1].device} \t{para[1].dtype}')print(f'{i}, \t {para[1].device} \t{para[1].dtype}')`
to(device)实现
pytorch模拟模型并行原理:分别用to(device),将不同的层加载到不同的gpu上,forward时将parameter也加载到对应gpu。
import torch
import torch.nn as nn
import torch.optim as optimclass ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.net1 = torch.nn.Linear(10000, 10).to('cuda:0')self.relu = torch.nn.ReLU()self.net2 = torch.nn.Linear(10, 5).to('cuda:1')def forward(self, x):# 卡间串行执行x = self.net1(x.to('cuda:0')))x = self.net2(self.relu(x.to('cuda:1'))return x
进行一个batch的train:每个batch_size=20样本,5分类
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)optimizer.zero_grad()
outputs = model(torch.randn(20, 10000))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
4. Deepspeed
DeepSpeed:炼丹小白居家旅行必备【神器】
技术栈
术语:其实和前面DDP的概念一样。
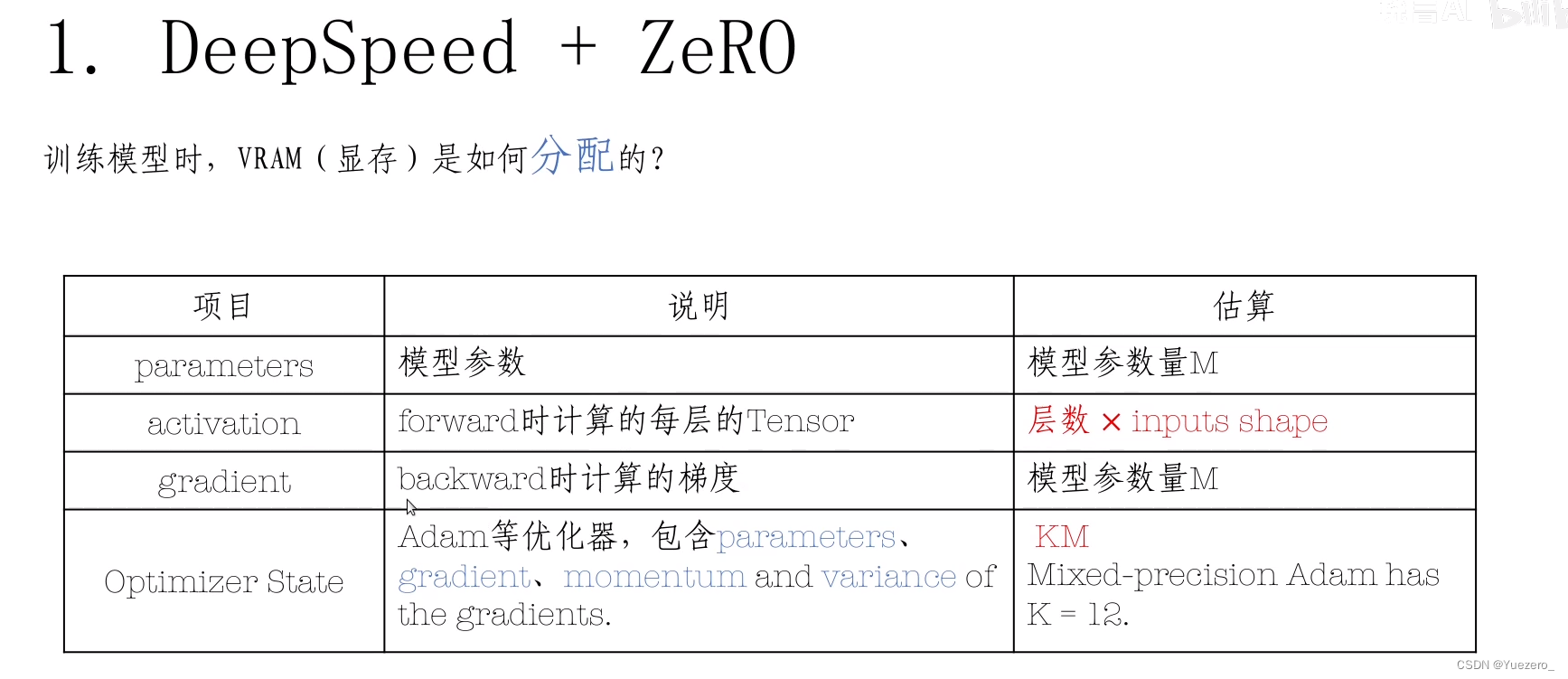
Train的数据4部分组成:model模型参数、backward的梯度gradient、optimizer优化器参数、forward的数据tensor
Deepspeed、ZeRO技术方案:分发Partitioning(按gpu数量N等分数据)、卸载Offload(不用的数据放入CPU)、模型并行Pipeline(模型参数按层切分到不同gpu上)

step1:deepspeed初始化
# init distributed
deepspeed.init_distributed()
加载参数local_rank
def parse_arguments():import argparseparser = argparse.ArgumentParser(description='deepspeed training script.')parser.add_argument('--local_rank', type=int, default=-1,help='local rank passed from distributed launcher')# Include DeepSpeed configuration argumentsparser = deepspeed.add_config_arguments(parser)args = parser.parse_args()return args
step2:deepspeed封装模型和数据集
deepspeed.initialize()封装model和dataset,相当于将模型和数据集交给deepspeed进行托管,engine就是deepspeed封装后的model,其他返回值同样都是deepspeed封装过的。(其中optimizer和lr_scheduler 后面是用不到的),我们只需要模型engine和数据加载器training_dataloader。
还要传入一个deepspeed的配置文件deepspeed_config。
# init model
model = MyClassifier(3, 100, ch_multi=128)
# init dataset
ds = MyDataset((3, 512, 512), 100, sample_count=int(1e6))# init engine
engine, optimizer, training_dataloader, lr_scheduler = deepspeed.initialize(args=args,model=model,model_parameters=model.parameters(),training_data=ds,config=deepspeed_config,
)
# load checkpoint
engine.load_checkpoint("./data/checkpoints/MyClassifier/")
step3:训练
在使用DeepSpeed进行分布式训练时,通常不需要手动调用optimizer.zero_grad()来清零梯度。DeepSpeed会自动处理梯度累积和梯度清零的操作,无需手动调用zero_grad()。
当使用DeepSpeed进行分布式训练时,一般会在engine.backward(loss)之后调用engine.step()来执行梯度更新操作。在engine.step()中,DeepSpeed会执行优化器的step()方法来更新模型参数,并在必要的时候自动清零梯度,以便进行下一轮的反向传播。
engine.train()for step, (data, label) in enumerate(training_dataloader):step += 1data= data.to(device=engine.device, dtype=torch.float16) # xlabel = label.to(device=engine.device, dtype=torch.long).reshape(-1) # y# 不需要梯度清零optimizer.zero_grad()outputs = engine(data) # forwardloss = F.cross_entropy(outputs, label )engine.backward(loss)engine.step()
单机节点node多卡gpu运行
deepspeed \--launcher_args "source ${PWD}/setup_env.sh" \--hostfile hostfile \deepspeed_script.py \--deepspeed \--deepspeed_config "$PWD/deepspeed_config.json"
deepspeed_config.json
{"train_micro_batch_size_per_gpu": 1,"gradient_accumulation_steps": 1,"optimizer": {"type": "Adam","params": {"lr": 0.001,"betas": [0.8,0.999],"eps": 1e-08,"weight_decay": 3e-07}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": 0,"warmup_max_lr": 0.001,"warmup_num_steps": 1000}},"activation_checkpointing": {"partition_activations": true,"cpu_checkpointing": true,"contiguous_memory_optimization": false,"number_checkpoints": null,"synchronize_checkpoint_boundary": false,"profile": true},"fp16": {"enabled": true,"auto_cast": false,"loss_scale": 0,"initial_scale_power": 16,"loss_scale_window": 1000,"hysteresis": 2,"consecutive_hysteresis": false,"min_loss_scale": 1},"zero_optimization": {"stage": 3,"offload_param": {"device": "cpu","pin_memory": true},"offload_optimizer": {"device": "cpu","pin_memory": true},"contiguous_gradients": true,"overlap_comm": true}
}
相关文章:
分布式并行训练(DP、DDP、DeepSpeed)
[pytorch distributed] 01 nn.DataParallel 数据并行初步 数据并行 vs. 模型并行 数据并行:模型拷贝(per device),数据 split/chunk(对batch切分) 每个device上都拷贝一份完整模型,每个device分…...

Linux- fg命令 bg命令
fg fg是Unix-like操作系统(如Linux和macOS)中的一个shell内建命令,用于将后台作业带到前台执行。这个命令常用于与bg(后台执行)命令和jobs(列出当前作业)命令一起,进行shell中的作业…...

leetcode第362场周赛
2873. 有序三元组中的最大值 I 核心思想:由于这题数据范围比较小,直接枚举i,j,k即可。 2874. 有序三元组中的最大值 II 核心思想:这题是在2873题目的基础上将数据范围进行了增加,意味着我们需要对上面的代码进行优化。两种优化方…...
图神经网络GNN(一)GraphEmbedding
DeepWalk 使用随机游走采样得到每个结点x的上下文信息,记作Context(x)。 SkipGram优化的目标函数:P(Context(x)|x;θ) θ argmax P(Context(x)|x;θ) DeepWalk这种GraphEmbedding方法是一种无监督方法,个人理解有点类似生成模型的Encoder过程…...
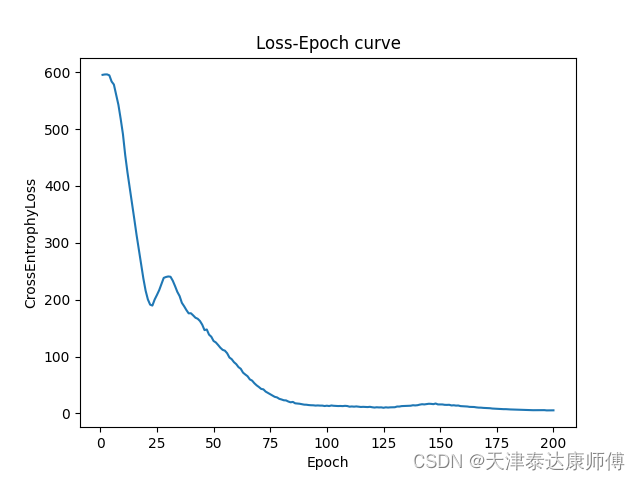
多目标平衡优化器黏菌算法(MOEOSMA)求解CEC2020多模式多目标优化
多目标平衡优化器黏菌算法(MOEOSMA)比现有的多目标黏菌算法具有更好的优化性能。在MOEOSMA中,动态系数用于调整勘探和开采趋势。采用精英存档机制来促进算法的收敛性。使用拥挤距离法来保持Pareto前沿的分布。采用平衡池策略模拟黏菌的协同觅…...
快速开发微信小程序之一登录认证
一、背景 记得11、12年的时候大家一窝蜂的开始做客户端Android、IOS开发,我是14年才开始做Andoird开发,干了两年多,然后18年左右微信小程序火了,我也做了两个小程序,一个是将原有牛奶公众号的功能迁移到小程序&#x…...
和Mapper映射文件(XXXMapper.xml)模板)
Mybatis配置文件(mybatis-config.xml)和Mapper映射文件(XXXMapper.xml)模板
配置文件 ${dirver} ---> com.mysql.jdbc.Driver ${url} ---> jdbc:mysql://localhost:3306/数据库名 <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""h…...
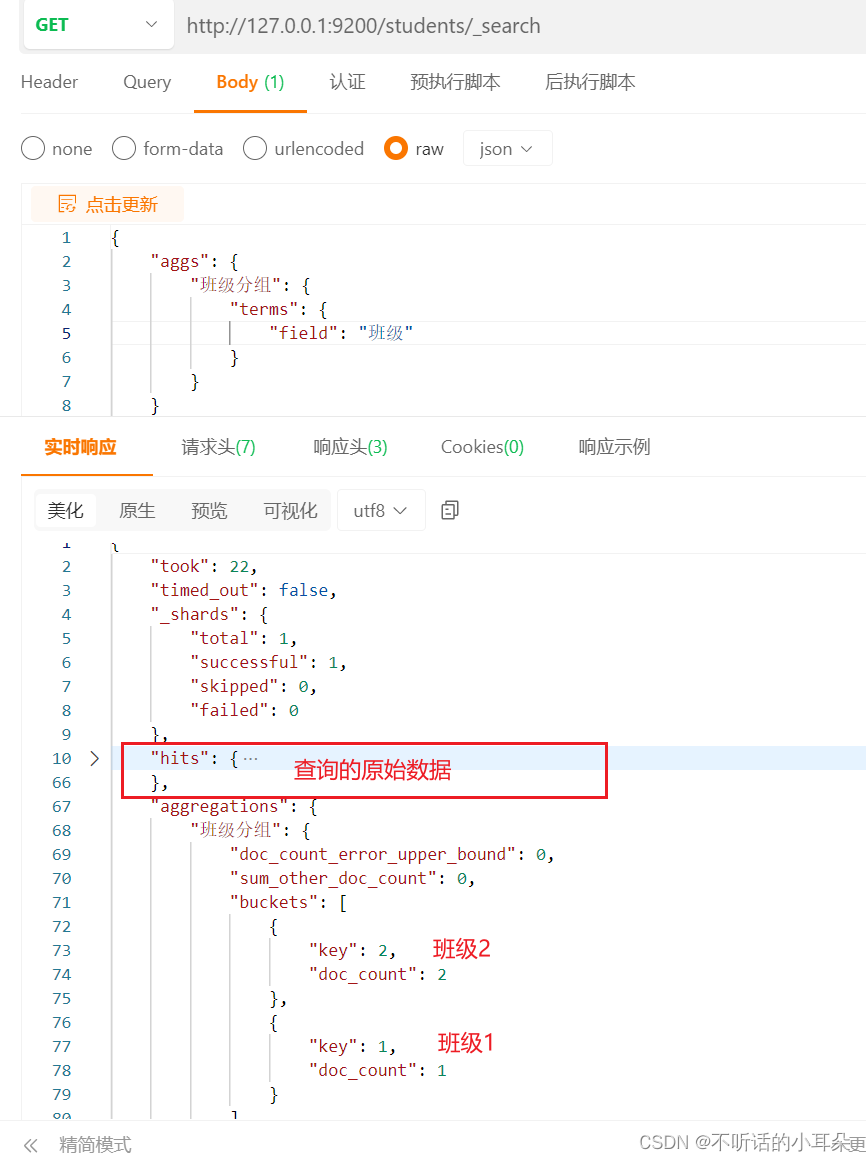
4. 条件查询
首先区分下match,match_phrase,term, 参考:https://zhuanlan.zhihu.com/p/592767668?utm_id0 1、全量查询分页指定source 示例:请求地址为http://127.0.0.1:9200/students/_search,请求体为: {"query":…...

【VIM】初步认识VIM-2
2-6 Vim 如何搜索替换_哔哩哔哩_bilibili 1-6行将self改成this 精确替换quack单词为交...
《HelloGitHub》第 90 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 https://github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 …...
(与flink的结合)--Flink 中hudi clean操作)
Apache Hudi初探(五)(与flink的结合)--Flink 中hudi clean操作
背景 本文主要是具体说说Flink中的clean操作的实现 杂说闲谈 在flink中主要是CleanFunction函数: Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.writeClient FlinkWriteClients.createWriteClient(conf,…...

stream对list数据进行多字段去重
方法一: //根据sj和name去重 List<NursingHandover> testList list.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getj() ";" o.getName() ";&…...
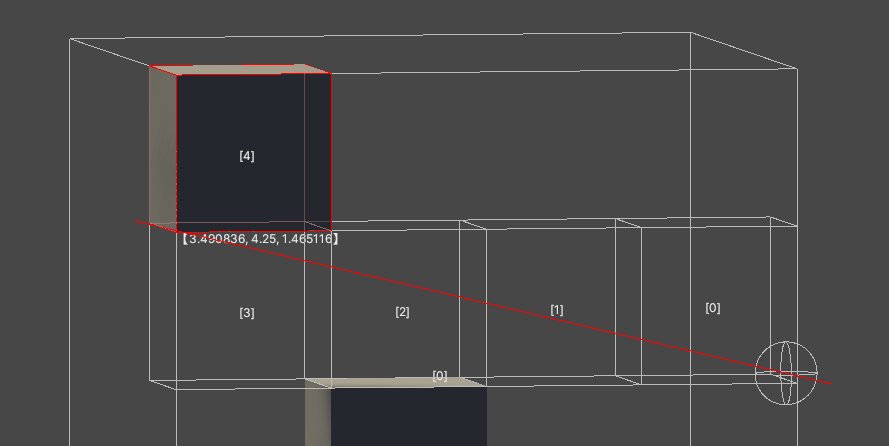
一种基于体素的射线检测
效果 基于体素的射线检测 一个漏检的射线检测 从起点一直递增指定步长即可得到一个稀疏的检测 bool Raycast(Vector3 from, Vector3 forword, float maxDistance){int loop 6666;Vector3 pos from;Debug.DrawLine(from, from forword * maxDistance, Color.red);while (loo…...

利用Docker安装Protostar
文章目录 一、Protostar介绍二、Ubuntu下安装docker三、安装Protostar 一、Protostar介绍 Protostar是一个免费的Linux镜像演练环境,包含五个系列共23道漏洞分析和利用实战题目。 Protostar的安装有两种方式 第一种是下载镜像并安装虚拟机https://github.com/Exp…...

go基础语法10问
1.使用值为 nil 的 slice、map会发生啥 允许对值为 nil 的 slice 添加元素,但对值为 nil 的 map 添加元素,则会造成运行时 panic。 // map 错误示例 func main() {var m map[string]intm["one"] 1 // error: panic: assignment to entry i…...

SpringCloud + SpringGateway 解决Get请求传参为特殊字符导致400无法通过网关转发的问题
title: “SpringCloud SpringGateway 解决Get请求传参为特殊字符导致400无法通过网关转发的问题” createTime: 2021-11-24T10:27:5708:00 updateTime: 2021-11-24T10:27:5708:00 draft: false author: “Atomicyo” tags: [“tomcat”] categories: [“java”] description: …...

vim基本操作
功能: 命令行模式下的文本编辑器。根据文件扩展名自动判别编程语言。支持代码缩进、代码高亮等功能。使用方式:vim filename 如果已有该文件,则打开它。 如果没有该文件,则打开个一个新的文件,并命名为filename 模式…...
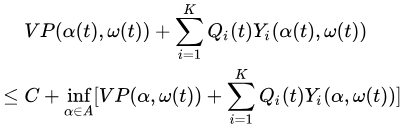
Drift plus penalty 漂移加惩罚Part1——介绍和工作原理
文章目录 正文Methodology 方法论Origins and applications 起源和应用How it works 它是怎样工作的The stochastic optimization problem 随机优化问题Virtual queues 虚拟队列The drift-plus-penalty expression 漂移加惩罚表达式Drift-plus-penalty algorithmApproximate sc…...

(四)动态阈值分割
文章目录 一、基本概念二、实例解析 一、基本概念 基于局部阈值分割的dyn_threshold()算子,适用于一些无法用单一灰度进行分割的情况,如背景比较复杂,有的部分比前景目标亮,或者有的部分比前景目标暗;又比如前景目标包…...

jvm介绍
1. JVM是什么 JVM是Java Virtual Machine的缩写,即咱们经常提到的Java虚拟机。虚拟机是一种抽象化的计算机,有着自己完善的硬件架构,如处理器、堆栈等,具体有什么咱们不做了解。目前我们只需要知道想要运行Java文件,必…...

QQ音乐加密文件解密终极指南:qmcdump工具完全使用教程
QQ音乐加密文件解密终极指南:qmcdump工具完全使用教程 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

动态加载数据库微信支付配置
在Java后端应用中,动态加载存储在数据库中的微信支付配置,是实现多商户、多环境支付或配置热更新的核心需求。这避免了将API密钥、商户号等敏感信息硬编码在配置文件或代码中,提升了系统的灵活性与安全性。核心实现思路是:构建一个…...

功率MOSFET工作原理与电力电子应用解析
1. 功率MOSFET基础概念解析 功率MOSFET(金属氧化物半导体场效应晶体管)是现代电力电子系统的核心开关器件。与普通MOSFET不同,功率MOSFET专为处理高电压(通常>60V)和大电流(>1A)而设计。其…...

为什么92%的实时数仓项目在2025Q4突然转向AI原生平台?——奇点大会12家头部企业联合验证数据披露
更多请点击: https://intelliparadigm.com 第一章:AI原生实时计算平台:2026奇点智能技术大会流批一体实践 在2026奇点智能技术大会上,新一代AI原生实时计算平台正式发布,其核心突破在于将大模型推理调度、向量流式计算…...

基于DGX OpenClaw Stack构建本地AI智能体:从硬件调优到生产部署
1. 项目概述:一站式本地AI智能体栈如果你和我一样,对把大语言模型(LLM)真正“养”在自己的硬件上,构建一个功能完整、数据私有的智能助手有执念,那么你很可能已经踩过不少坑了。从选模型、搭服务、配工具链…...

为AI智能体构建持久化记忆系统:Shang Tsung项目实战解析
1. 项目概述:为AI智能体注入“灵魂”与“第二大脑”如果你和我一样,长期与各类AI智能体(Agent)打交道,无论是基于Claude Code、OpenClaw,还是其他本地化部署的LLM工具,你一定经历过那种令人沮丧…...

WarcraftHelper:魔兽争霸3兼容性修复终极解决方案
WarcraftHelper:魔兽争霸3兼容性修复终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争霸3在现代Windows系…...

JimuReport积木报表 — 实战API数据源动态参数与分页优化
1. 为什么API分页总让人头疼? 做过报表开发的朋友应该都遇到过这样的场景:后台接口明明提供了分页参数,但报表工具里就是没法正常翻页。要么点了下一页数据没变化,要么直接报错。我在第一次用JimuReport对接API数据源时࿰…...

3大核心技术解密:LeagueAkari本地自动化工具架构设计与实战指南
3大核心技术解密:LeagueAkari本地自动化工具架构设计与实战指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款…...

从DRM驱动看mmap:图解内存分配与映射的‘时机’与‘方式’如何影响性能
从DRM驱动看mmap:图解内存分配与映射的‘时机’与‘方式’如何影响性能 在图形驱动开发领域,内存管理始终是性能优化的关键战场。当你在调试一块高端显卡的DRM(Direct Rendering Manager)驱动时,是否曾遇到过这样的困惑…...