消息中间件(二)——kafka
文章目录
- Apache Kafka综述
- 什么是消息系统?
- 点对点消息类型
- 发布-订阅消息类型
- 什么是Kafka?
- 优点
- 关键术语
- Kafka基本原理
- 用例
Apache Kafka综述
在大数据中,会使用到大量的数据。面对这些海量的数据,我们一是需要做到能够收集这些数据,其次是要能够分析和处理这些海量数据。在此过程中,需要一套消息系统。
Kafka专门为分布式高吞吐量系统设计。作为一个消息代理的替代品,Kafka往往做的比其他消息中间件做的更好。
与其他消息队列产品相比,它主要有以下优点:
- 吞吐量高
- 内置分区
- 复制能力
- 固有的容错能力
因此,Kafka非常适合大规模的消息处理应用。
什么是消息系统?
消息系统负责将数据从一个应用传递到另一个应用,应用就可以专注于数据,而不用担心数据如何共享。分布式消息传递基于可靠消息队列的概念。消息在客户端应用程序和消息传递系统之间异步排队。
有两种类型的消息模式可用:
- 点对点模式
- 订阅-发布模式(pub-sub),也是最常用的一种消息模式
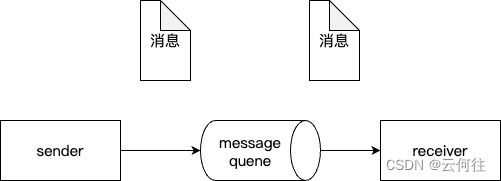
点对点消息类型
在点对点的消息传递类型中,所有的消息都保留在消息队列中。一个或多个消费者可以消耗队列中的消息,但特定的消息只能有最多一个消费者消费。一旦消费者消费了队列中的消息,该消息将会在消息队列中消失。
点对点消息系统最典型的例子是订单处理系统,其中每个订单将有由订单处理器处理,但多个订单处理器也可以同时工作。
发布-订阅消息类型
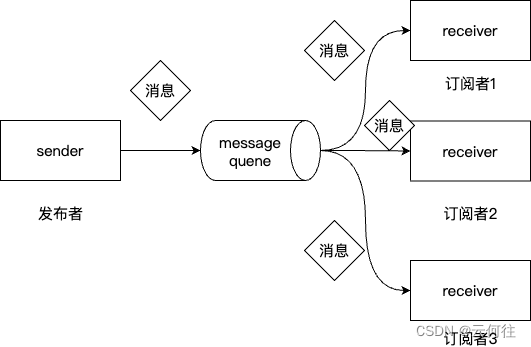
在发布-订阅系统中,消息被保留在各个主题中。
与点对点系统不同的是,一个订阅者可以订阅一个或多个不同主题中的消息并使用这些主题中的所有消息。
在发布-订阅系统中,消息的生产者称为发布者,消息的使用者称为订阅者。
一个现实的例子是dish天线电视,它发布不同的渠道和主题,如运动、音乐、电影等,任何人都可以订阅自己需要的主题集,并接收到订阅主题的消息。
什么是Kafka?
Kafka is a distributed,partitioned,replicated commit logservice.
- Apache Kafka 是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使你能够将消息从一个端点传递到另一个端点。
- Kafka 适合离线和在线消息消费。
- Kafka 消息保留在磁盘上,并在群集内复制以防止数据丢失。
- Kafka 构建在 ZooKeeper 同步服务之上。 它与 Apache Storm 和 Spark 非常好地集成,用于实时流式数据分析。
优点
- 可靠性
Kafka是分布式、分区复制、可容错的 - 可扩展性
消息传递系统可以轻松扩缩容,不用关机 - 耐用性
Kafka使用“分布式提交日志”,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。 - 高性能
Kafka无论是发布还是订阅消息的吞吐量都是很高的。即使存储了很多TB的消息,还是能够保证高性能。
Kafka非常快,并且能保证零停机和零数据丢失
关键术语
- 生产者和消费者:Productor & Customer
在Kafka中,消息的发布者称为生产者Productor,消息的接受和使用者称为消费者Customer - broker:
Kafka消息队列集群中有很多台server,每一台server都可以存储消息,这每一台server都可以称做是Kafka的一个实例,也称为broker - 主题:topic
一个topic中会保存同一类的消息,相当于对消息进行分类。productor在向Custom发送消息的时候,需要指定topic,也就是制定了该消息属于哪一分类。 - 分区:partition
每个topic都划分为多个partition,每个partition在存储层面都是一个append log文件。任何写进某partition的消息都会被追加在一个log文件的尾部。
分区的意义:Kafka基于文件进行存储,当文件内容过大的时候,很容易达到单个磁盘的上限。使用分区进行存储,一个分区存储一个文件,保证单个文件不会过大的情况下,还能将数据存在不同的broker = Kafka server上,从而实现了负载均衡,能够承载更多的消费者 - 偏移量:offset
一个分区存储一个文件,而消息在文件中的位置就称为是偏移量offset,offset的字符类型为long长字符类型,它可以唯一标记一条消息。由于Kafka并没有提供额外的消息索引机制,因此文件只能顺序读写,所以Kafka基本不允许对消息进行“随机读写”。
小结Kafka:
- 是基于发布-订阅的分布式消息队列
- 面向大数据,消息存储在topic中,而每个topic会分为多个patition分区;
- 消息存储在磁盘中,每个partition分区对应一个磁盘上的一个文件来存储消息,消息的写入就是在log文件后追加内容,文件可以在集群内复制防止丢失;
- 即使消息被消费,消息也不会立刻消失,可以通过配置以实现自动删除来释放空间
- Kafka依赖分布式协调服务zookeeper,适合离线/在线消息的消费,与storm/spark等实时流式数据处理工具常常结合使用。
Kafka基本原理
-
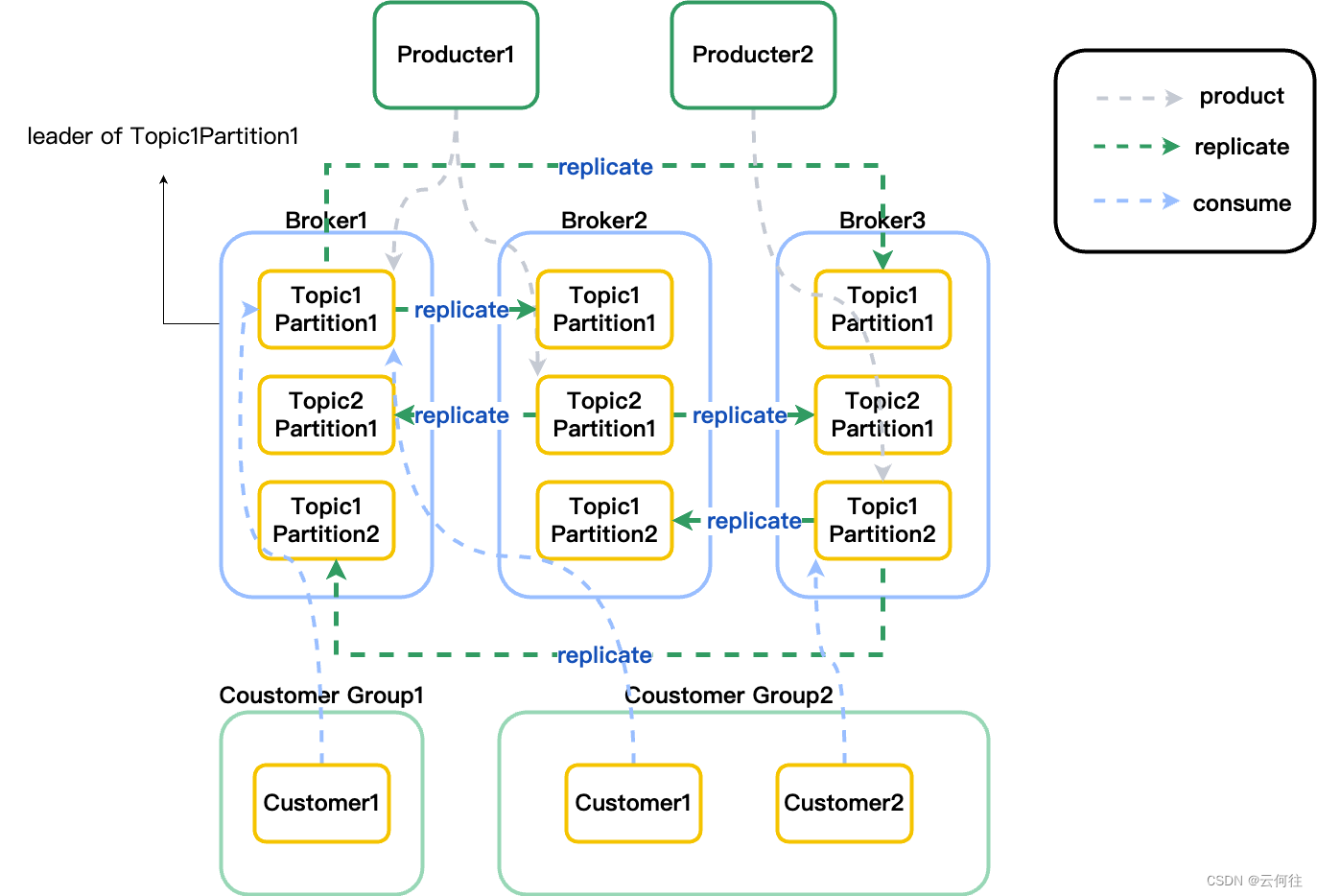
分布式和分区:distributed、partitioned
Kafka是一个分布式的发布-订阅消息队列,主要体现在哪些方面?
体现在大量的数据被保存在磁盘上,但单个磁盘的容量是有限的,于是消息被生产者生产的时候分为不同的topic主题来保存,每个topic又被分为多个partition分区,而每个partition分区对应一个文件,以文件的方式来保存消息数据,每个文件又可以被保存在不同的broker上,这样就实现了Kafka集群来分布式存储消息队列。
另外,每个partition都有一定的副本,可以备份到不同的borker上,从而提高可用性。
总的来说就是,一个topic对应的多个partition上的文件分散保存在集群的多个不同broker上,存储的方式是一个partition对应一个文件,每个broker负责存储在自己机器上的每个文件的读写。 -
副本:replicated
Kafka可以通过配置指定partition的备份个数(replicas),每个partition将会被备份到多台机器上,提高了可用性,备份数量通过配置文件可以指定。
实质上,冗余备份在分布式系统中很常见。
有副本的存在,就会涉及到同一个文件的多个副本如何管理和调度。
Kafka设置了“leader机制”,每个partition选举一个broker作为leader,用来负责对该分区的读写,其余broker则作为follower,只需简单地和leader同步即可。如果原来的leader失效,partition则会选举新的broker成为leader。
至于如何选取 leader,实际上如果我们了解 ZooKeeper,就会发现其实这正是 Zookeeper 所擅长的,Kafka 使用 ZK 在 Broker 中选出一个 Controller,用于 Partition 分配和 Leader 选举。
实际上,作为leader的server,承担了整个分区的所有读写请求,负担是比较大的。从整体考虑,有多少个partition就有多少个leader,Kafka将leader分摊到不同的broker上,也算是整体上的一种负载均衡。 -
Kafka数据流处理
(1)数据产生方式:produce
生产者写入消息数据可以指定4个参数,分别为topic,partition,key,value。其中topic和value(要写入的数据)必须指定,而key和partition是可选的。
对于一条记录,要先对其进行序列化,再按照topic和partition,发送到对应的队列中去。如果没有指定partition,有两种情况:
-
指定key,按照key进行哈希,同一个key的消息进一个partition
-
未指定key, round-robin进行partition的选择
producer将会和topic下的每个partiton leader保持socket连接,消息由producer直接发送给broker。
其中partition leader的身份在zookeeper中已经注册,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更事件,因此可以准确知道leader是谁。
producer端采用异步发送,先将一部分的消息存在客户端的buffer里,并将其分批发送给broker,小数据io很多会增加整体网络的延迟,批量延迟发送实际上是提供了网络效率。
(2)数据消费过程:custome -
对于消费者,不是以单独形式存在的,每个消费者都属于一个消费群租customer group,一个group包含多个consumer。需要注意的是,消费者的订阅topic行为都是以customer group的形式来订阅的,发送到topic的消息,只会被订阅该topic的每个group中的每个customer消费。
-
如果说所有的customer都有共同的group,那么就像是一个点对点的消息系统;如果每个消费者都属于不同的group,那么消息会广播给所有的消费者。
-
实际上消息是根据partition来分的,一个partition只能被消费组里的一个消费者消费,但是可以多个不同的消费组消费,消费组里的每个消费者是关联到一个partition的;因此有一个说法:对同一个topic,同一个group中不能有多于partitions个数的customer同时消费,否则某些customer将无法得到消息。
-
同一个消费组的两个customer不能同时消费一个partition
-
partition 中的消息只有一个 consumer 在消费,且不存在消息状态的控制,也没有复杂的消息确认机制,可见katka broker 端是相当轻量级的。当消息被 consumer 接收之后,需要保存 Offset 记录消费到哪,以前保存在ZK中,由于 ZK 的写性能不好,以前的解决方法都是Consumer 每隔一分钟上报一次,在0.10 版本后,Kafka 把这个Offset 的保存,从ZK 中剥离,保存在一个名叫 consumeroffsets topic 的Topic 中,由此可见consumer 客户端也很轻量级
用例
Kafka可以在很多场景中使用,以下列出一些用例:
- 指标
Kafka通常用于操作监控数据。这涉及到聚合来自分布式应用程序的统计信息,以产生操作数据的集中馈送。 - 日志聚合解决方案
可用于跨组织收集多个服务的日志,且以标准格式提供给多个服务器。 - 流处理
流行的框架(如Storm和Spark Streaming)从主题中读取数据,对其进行处理,并将处理后的数据写入新主题,供用户和应用程序使用。 Kafka的强耐久性在流处理的上下文中也非常有用。
相关文章:
消息中间件(二)——kafka
文章目录 Apache Kafka综述什么是消息系统?点对点消息类型发布-订阅消息类型 什么是Kafka?优点关键术语Kafka基本原理用例 Apache Kafka综述 在大数据中,会使用到大量的数据。面对这些海量的数据,我们一是需要做到能够收集这些数据…...
量化交易全流程(四)
本节目录 数据准备(数据源与数据库) CTA策略 数据源: 在进行量化分析的时候,最基础的工作是数据准备,即收集数据、清理数据、建立数据库。下面先讨论收集数据的来源,数据来源可分为两大类:免…...

idea 如何在命令行快速打开项目
背景 在命令行中从git仓库检出项目,如何在该命令行下快速用idea 打开当前项目,类似vscode 可以通过在项目根目录下执行 code . 快速打开当前项目。 步骤 以macos 为例 vim /usr/local/bin/idea 输入如下内容 #!/bin/sh open -na "IntelliJ IDE…...

YOLOV8-DET转ONNX和RKNN
目录 1. 前言 2.环境配置 (1) RK3588开发板Python环境 (2) PC转onnx和rknn的环境 3.PT模型转onnx 4. ONNX模型转RKNN 6.测试结果 1. 前言 yolov8就不介绍了,详细的请见YOLOV8详细对比,本文章注重实际的使用,从拿到yolov8的pt检测模型&…...

数量关系 --- 方程
目录 一、代入排除法 例题 练习 二、数字特性 例题 练习 整除特性 例题 倍数特性 普通倍数 因子倍数 比例倍数 例题 练习 三、方程法 例题 练习 四、 不定方程(组) 例题 练习 一、代入排除法 例题 素数:…...

【C语言 模拟实现strlen函数的三种方法】
C语言程序设计笔记---022 C语言之模拟实现strlen函数1、介绍strlen函数2、模拟strlen函数的三种方法2.1、计数器法模拟实现strlen函数2.2、递归法模拟实现strlen函数2.3、指针减指针法模拟实现strlen函数 3、结语 C语言之模拟实现strlen函数 前言: 通过C语言字符串…...

MySQL数据库与表管理《三国志》为例
在数据库管理中,一个典型的应用场景是游戏数据的存储和管理。以经典游戏《三国志》为例,该游戏具有多个角色、任务、装备等元素,如何有效地存储和管理这些数据就成为了一个问题。 本文将通过《三国志》的实例,详细解释如何在MySQL中进行数据库和表的管理。 文章目录 《三国…...

D. Jellyfish and Mex - DP
题面 分析: 题目最终需要达到MEX位0,也就是从最开始的MEX变成0后m的最小值,可以设 d p i dp_i dpi表示当前MEX为 i i i时,m的最小值,那么就可以根据前一个状态推出后一个状态,也就是假如当前MEX是 i i …...

奥斯卡·王尔德
奥斯卡王尔德 奥斯卡王尔德(Oscar Wilde,1854年10月16日—1900年11月30日),出生于爱尔兰都柏林,19世纪英国(准确来讲是爱尔兰,但是当时由英国统治)最伟大的作家与艺术家之一…...

IDEA常用快捷键大全
整理了一些IDEA开发常用的快捷键: 快捷键组合实现效果psvm Tab键 / main Tab键public static void main(String[] args)sout Tab键System.out.println()Ctrl X删除当前行Ctrl D复制当前行AltInsert(或右键Generate)生成代码(如get,set方法,构造函数等)CtrlAltT…...

Java之多线程的综合练习二
练习六:多线程统计并求最大值 需求: 在上一题基础上继续完成如下需求: 每次抽的过程中,不打印,抽完时一次性打印(随机) 在此次抽奖过程中,抽奖箱1总共产生了6个奖项。 分别为:10,20,100,50…...
selenium下载安装 -- 使用谷歌驱动碰到的问题
安装教程参考: http://c.biancheng.net/python_spider/selenium.html 1. 谷歌浏览器和谷歌驱动版本要对应(但是最新版本谷歌对应的驱动是没有的,因此要下载谷歌历史其他版本): 谷歌浏览器历史版本下载: https://www.chromedownloads.net/chrome64win/谷歌浏览器驱动下载: http:…...

开放式耳机怎么选择、300之内最好的耳机推荐
开放式耳机凭借不入耳、不伤耳、安全更舒适的佩戴体验,得到了越来越多音乐爱好者和专业人士的青睐。开放式耳机不需要插入耳道,在佩戴时可以更加自然和轻松,减少了长时间佩戴引起的不适感,而且不会完全隔绝外界声音,用…...

git密码提交切换SSH提交
git保存密码 每次登录都要输入密码是显示繁琐,好在git提供了保存密码的功能。 在本地工程文件夹下,.git目录,保存以下配置。 [credential] helper store或者 在git bash命令行,执行命令 git config credential.helper store如…...

数字乡村包括哪些方面?数字乡村应用介绍
数字乡村是指利用物联网、数字化和智能化技术,借助现代数字智能产品、高效信息服务和物联网基础设施,以提高农村居民生活质量,助力拓展经济发展前景。 创建数字村庄有助于缩小城乡社区之间的差距,保障每个人都能平等地享受科技发展…...
-架构)
弹性资源组件elastic-resource设计(一)-架构
简介 弹性资源组件提供动态资源能力,是分布式系统关键基础设施,分布式datax,分布式索引,事件引擎都需要集群和资源的弹性资源能力,提高伸缩性和作业处理能力。 本文介绍弹性资源组件的设计,包括架构设计和详细设计,指导开发人员代码开发 关键词 作业管理器/资源管理器/…...

C/C++笔试面试真题
C/C++笔试面试真题 1、堆和栈的区别 1、栈由系统自动分配,而堆是人为申请开辟; 2、栈获得的空间较小,而堆获得的空间较大; 3、栈由系统自动分配,速度较快,而堆一般速度比较慢; 4、栈是连续的空间,而堆是不连续的空间。 2、什么是野指针?产生的的原因? 野指针的指向的…...

【Vue3】兄弟组件传参
1. 借助父组件传参 A 组件派发一个事件,修改 flag 的值,先传递给父组件,然后由父组件传递给 B 组件。 缺点:必须由 App.vue 处理中间逻辑。 A.vue <template><div class"A"><h1>A组件</h1>…...

【CSS 中 link 和@import 的区别】
<link> 和 import 都可以用于引入 CSS 文件,但是两者有以下区别: 加载时间:<link> 标签在页面加载时同时加载,而 import 是在页面加载后才开始加载。 兼容性:<link> 标签可以被所有的浏览器正确解释…...
笔记二:odoo搜索、筛选和分组
一、搜索 1、xml代码 <!--搜索和筛选--><record id"view_search_book_message" model"ir.ui.view"><field name"name">book_message</field><field name"model">book_message</field><field…...
)
Xilinx VCU方案深度体验:除了低延时,开发者还需要面对这些挑战(GStreamer/FPGA/稳定性)
Xilinx VCU方案实战解析:低延时光环下的工程化挑战 在专业视频处理领域,低延时编解码一直是皇冠上的明珠。Xilinx Zynq UltraScale MPSoC凭借其VCU硬核确实交出了一份漂亮的参数答卷——4K60帧H.265编解码仅2帧延时的成绩单。但当我们真正将其引入工业视…...

终点亦是起点
小端AI经过8个月的反复打磨,不仅领先外国顶级水平,而且功能稳定,我也永久保持纯本地运行100%开源,如今已超过30万下载,不管未来百万还是千万用户,绝不开会员,献给国家的申明永久有效,…...

别再死记硬背公式了!用‘能量流动’视角图解RLC二阶电路,轻松理解零输入响应
能量流动视角:用物理直觉破解RLC二阶电路零输入响应之谜 想象一下,你手中握着一个透明的能量沙漏。上层的沙子(电能)缓缓流入下层(磁能),又因为重力作用回弹,形成有节奏的流动——这…...
)
Sora 2 + After Effects 24.4终极联动教程:含LUT自动映射、运动追踪反哺、动态遮罩同步(附独家.jsx插件)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与After Effects 24.4深度整合概览 Adobe After Effects 24.4 正式引入对 OpenAI Sora 2 模型输出格式的原生支持,标志着生成式视频工作流首次在专业后期平台中实现端到端闭环。该整…...

基于本地AI的语音转文字工具OpenWhisp:隐私优先的离线生产力方案
1. 项目概述:一个完全本地的语音转文字工具 作为一个长期在效率工具和本地AI应用领域折腾的开发者,我一直在寻找一个能让我彻底摆脱网络延迟和隐私顾虑的语音输入方案。市面上的云服务要么有订阅费,要么有数据上传的隐忧,直到我看…...

RCX自定义主题和外观设置:如何打造个性化的云管理界面
RCX自定义主题和外观设置:如何打造个性化的云管理界面 【免费下载链接】rcx Rclone for Android 项目地址: https://gitcode.com/gh_mirrors/rc/rcx RCX作为一款功能强大的Android云管理工具,不仅提供了全面的Rclone功能支持,还允许用…...

线束工程化实践:从设计到测试的自动化工具链与开源资源
1. 项目概述:从“Awesome”清单到工程化实践在开源世界里,“Awesome”系列清单就像一个个精心整理的藏宝图,指引着开发者们快速找到某个领域内的优质资源。今天要聊的这个项目fastbeast2023-netizen/awesome-harness-engineering,…...

D2DX:让《暗黑破坏神2》在现代电脑上完美运行的终极方案
D2DX:让《暗黑破坏神2》在现代电脑上完美运行的终极方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为《…...

技能图谱探索器:从数据建模到交互可视化的全栈实现
1. 项目概述:一个技能图谱的探索工具最近在GitHub上看到一个挺有意思的项目,叫nitzzzu/openclaw-skills-explorer。光看名字,openclaw和skills-explorer这两个词就挺有画面感的。我第一反应是,这应该是一个用来探索、梳理或可视化…...

知识图谱与量化LLM协同架构解析与应用
1. 知识图谱与量化LLM协同架构解析在自然语言处理领域,知识图谱(KG)与大型语言模型(LLM)的协同正展现出独特价值。这种架构的核心在于发挥两者的互补优势:KG提供结构化、可验证的语义网络,而LLM…...