Hive【Hive(二)DML】
启动 hive 命令行:
hiveDML 数据操作
1、数据导入
1.1、向表中装载数据(load)
语法:
hive> load data [local] inpath '数据的path' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
创建一张表student:
create table student(id string,name string) row format delimited fields terminated by '\t';注意:如果不切换数据库,默认使用的是 default 数据库,并且保存路径是hdfs:///user/hive/warehouse/student/ ;如果使用了 db_hive1 ,则保存路径为:hdfs:///user/hive/warehouse/db_hive1/student/
1、加载本地文件到hive。
load data local inpath '/opt/module/hive-3.1.2/datas/student.txt' into table default.student;HDFS 下出现了我们的文件。
2、加载hdfs文件到hive。
load data inpath ‘/user/careate/student.txt’ into table student;3、覆盖式导入:
load data local inpath '/opt/module/hive-3.1.2/datas/student.txt' overwrite into table default.student;1.2、 通过查询语句向表中插入数据(Insert)
1)创建一张表
create table student1(id int, name string) row format delimited fields terminated by ‘\t’;2)基本模式插入数据
insert into table student1 values(1011,‘ldx’),(1012,‘ysy’);3)根据查询结果插入数据
insert into table student1select id, name from student where id < 1006;insert into 不会删除原表中的数据,只是追加到后面。
insert overwrite table student1select id, name from student where id < 1006;使用 insert overwrite 的话,原表中的数据被删除,被student 表中的数据覆盖。
1.3、查询语句中创建表并加载数据(As Select)
create table student3
as select id,name from student;Hive 不论是创建表还是查询数据(除了select * 都会产生 mapreduce 任务),所以执行时间不会很快。
1.4、创建时指定 location 来加载数据路径
这种方法就是我们上一篇讲的建表语句中,通过 location 关键字来指定表的数据源(其实也变相指定了我们表的存储路径),我们建表时指定了数据源路径下文件的解析方法(比如以 '\t' 为分割符号)。
create table if not exists student(id int,name string
)
row format delimitedfields terminated by '\t'
location 'hdfs:///user/hive/warehouse/student';该表一建立,我们在 hdfs 下的 /user/hive/warehouse/student/ 目录下放到文件就变成了表内容的源文件,解析方法就是以 '\t' 为分隔符。
1.5、Import 数据到指定 Hive表
import table student from '\user\hive\warehouse\export\student';数据导出
2.1、 Insert 导出
1)将查询结果导出到本地
-- 导出student表到linux本地目录
insert overwrite local directory '/opt/module/hive-3.1.2/datas'
select * from student;
-- 导出结果
-- 1001lyh
-- 1002mht
-- 1003lj
-- 1004my2)将查询结果格式化后导出到本地
-- 格式化后导出到linux本地目录
insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/student'
row format delimited fields terminated by '\t'
select * from student;
-- 格式化导出结果
-- 1001 lyh
-- 1002 mht
-- 1003 lj
-- 1004 my导出结果:

3)将查询结果格式化后导出到 HDFS(少了 local 关键字)
-- 将查询结果格式化导出到 hdfs
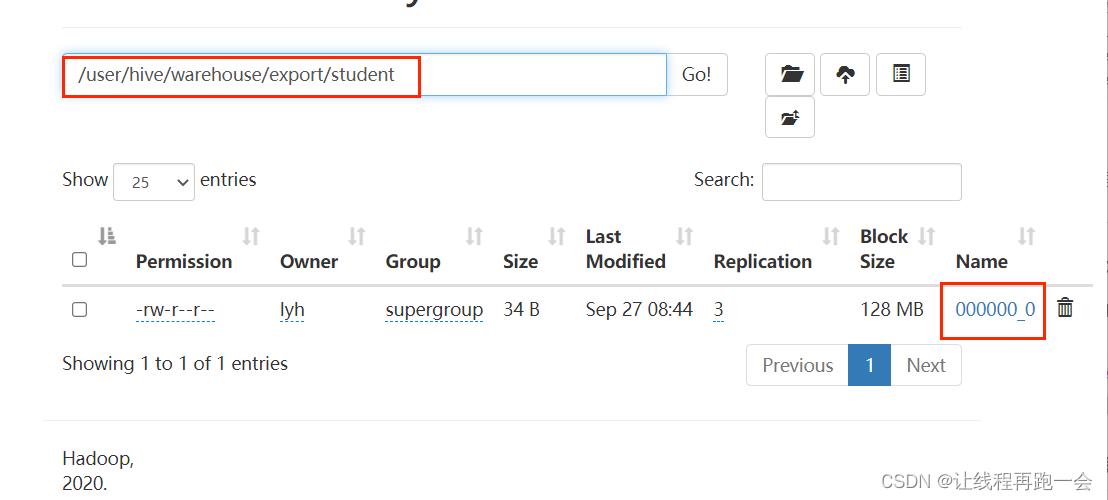
insert overwrite directory '/user/hive/warehouse/export/student'
row format delimited fields terminated by '\t'
select * from student1;注意:insert 导出,导出的目录不用自己提前创建,hive会帮我们自动创建。但是因为是 overwrite ,所以要小心导出的目录中原本存不存在数据,以免覆盖造成误删。
导出结果:
2.2、Hadoop 命令导出到本地
使用hadoop命令将我们Hive表的hdfs目录下的文件导出到本地(linux)。
hadoop fs -get /user/hive/warehouse/student/student.txt /opt/module/hive/datas/export/student.txt2.3、Hive Shell 命令导出
这里不需要进入 hive 命令行,因为我们使用了 hive -e
hive -e 'select * from default.stduent;' >> /opt/module/hive/datas/export/student1.txt导出结果:
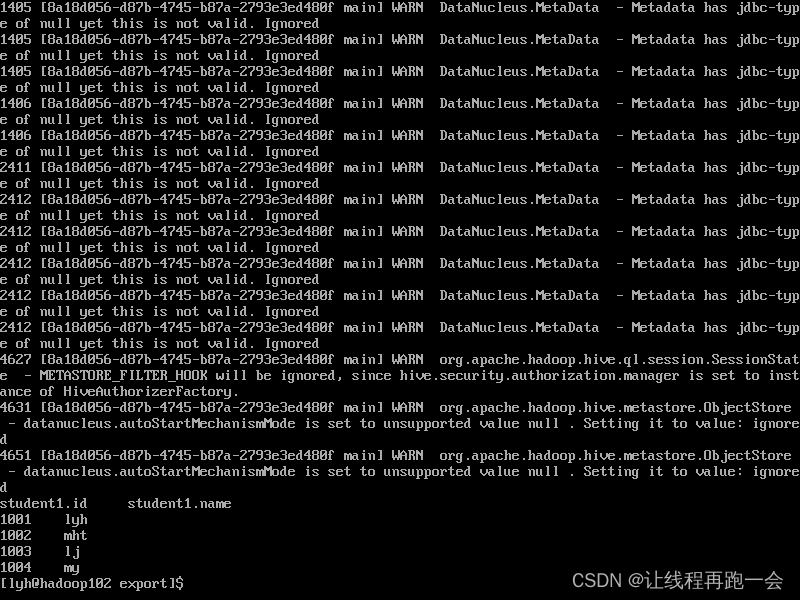 我们发现,导出的 studen2.txt 中,包含了大量的日志信息,必须通过配置日志等级才能省去它,个人感觉还是不用这种方法为好。
我们发现,导出的 studen2.txt 中,包含了大量的日志信息,必须通过配置日志等级才能省去它,个人感觉还是不用这种方法为好。
2.4、export 导出到 HDFS
-- export 导出到hdfs
export table student1 to
'/user/hive/warehouse/export/student1';导出的结果是一个 student1 目录,下面包含了两个
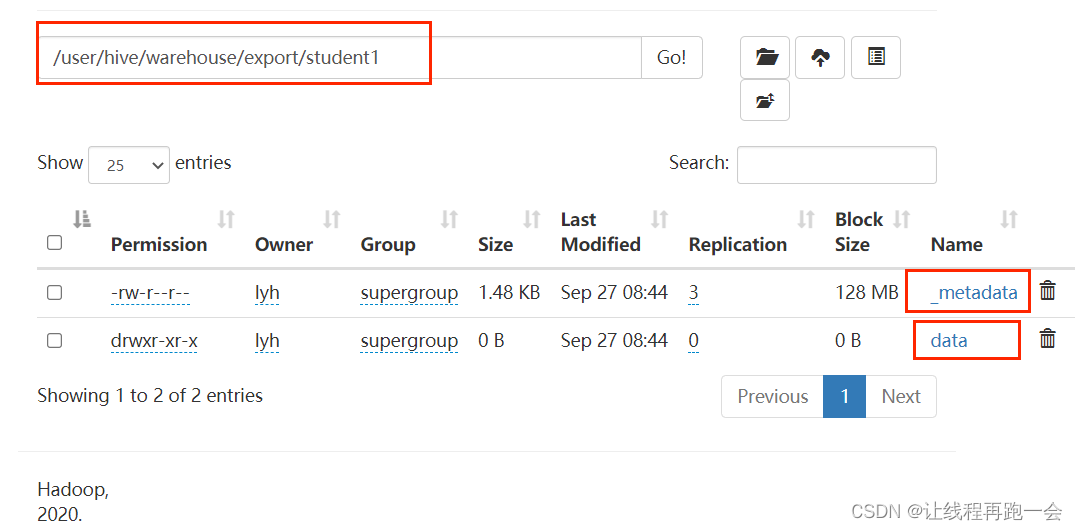
其中,_metadata 是元数据信息,而 data 是一个目录,下面存放着名为 000000_0 的文件,打开是我们该 Hive 表的内容。
1.5、Sqoop 导出
还没学 Sqoop ,以后再做更新。
相关文章:
Hive【Hive(二)DML】
启动 hive 命令行: hive DML 数据操作 1、数据导入 1.1、向表中装载数据(load) 语法: hive> load data [local] inpath 数据的path [overwrite] into table student [partition (partcol1val1,…)];(1&#x…...

HTTP的请求方法,空行,body,介绍请求报头的内部以及粘包问题
目录 一、GET与POST简介 二、空行和body 三、初识请求报头以及粘包问题 四、认识请求报头剩余部分 一、GET与POST简介 GET https://www.sogou.com/HTTP/1.1 请求报文中的方法,是最常规的方法(获取资源) POST:传输实体主体的方法…...
win10 ip设置
百度安全验证...

alibaba dragonwell jdk
阿里巴巴Dragonwell8快速指南 dragonwell-project/dragonwell8 Wiki GitHub 阿里巴巴Dragonwell8用户指南 dragonwell-project/dragonwell8 Wiki GitHub 阿里巴巴Dragonwell8常见问题 dragonwell-project/dragonwell8 Wiki GitHub...
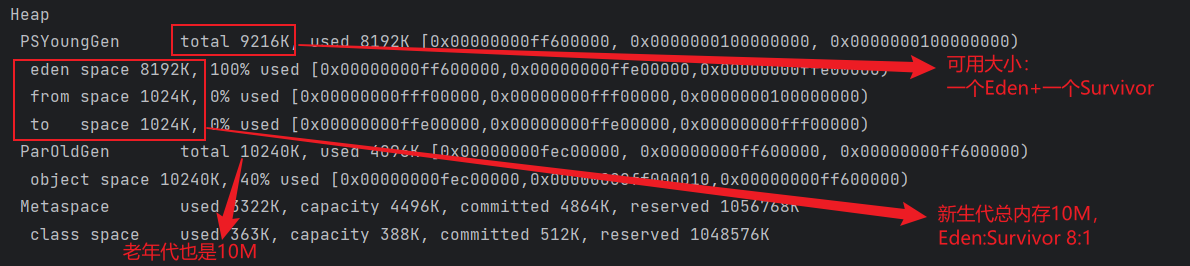
jvm内存分配与回收策略
自动内存管理 解决两个问题 自动给对象分配内存 对象一般堆上分配(而实际上也有可能经过即时编译后被拆散为标量类型并间接地在栈上分配) 新生对象通常会分配在新生代,少数情况下(例如对象大小超过一定阈值)也可能…...

【Vue2和Vue3的双向绑定区别】
Vue2和Vue3的双向绑定区别 vue2 双向绑定原理vue3 双向绑定原理Vue2和Vue3的双向绑定存在以下区别: vue2 双向绑定原理 Vue2 双向绑定的实现主要依赖于 Object.defineProperty() 方法和观察者模式,其中 Object.defineProperty() 方法用于定义属性的 get…...
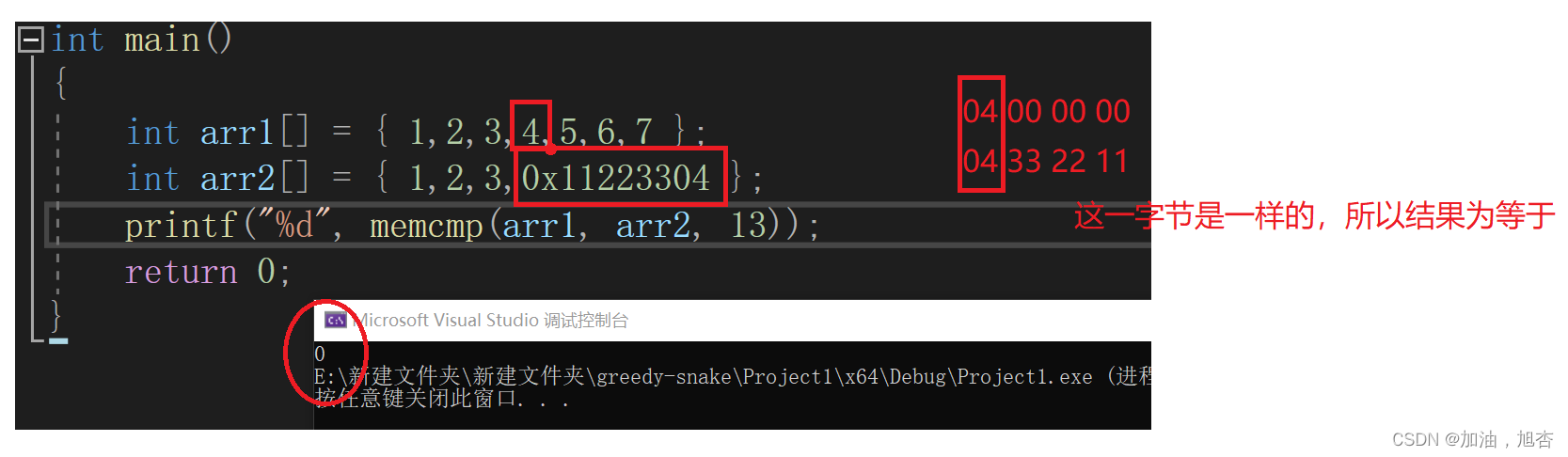
【再识C进阶3(下)】详细地认识字符分类函数,字符转换函数和内存函数
前言 💓作者简介: 加油,旭杏,目前大二,正在学习C,数据结构等👀 💓作者主页:加油,旭杏的主页👀 ⏩本文收录在:再识C进阶的专栏…...
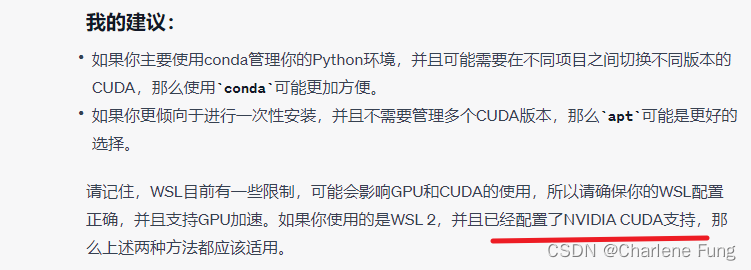
windows WSL配置cuda,pytorch和jupyter notebook
机器配置 GPU: NVIDIA Quadro K2000 与 NVIDIA 驱动程序捆绑的CUDA版本 但按照维基百科的描述,我的GPU对应的compute capability3.0,允许安装的CUDA最高只支持10.2,如下所示。 为什么本地会显示11.4呢?对此,GPT是这…...

回调地狱的产生=>Promise链式调用解决
常见的异步任务包括网络请求、文件读写、定时器等。当多个异步任务之间存在依赖关系,需要按照一定的顺序执行时,就容易出现回调地狱的情况。例如,当一个网络请求的结果返回后,需要根据返回的数据进行下一步的操作,这时…...
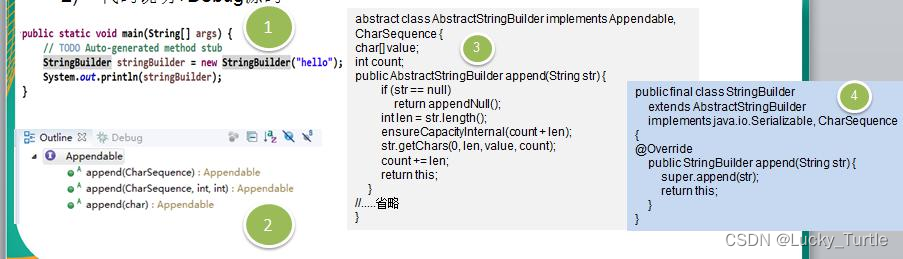
【设计模式】六、建造者模式
文章目录 需求介绍角色应用实例建造者模式在 JDK 的应用和源码分析java.lang.StringBuilder 中的建造者模式 建造者模式的注意事项和细节 需求 需要建房子:这一过程为打桩、砌墙、封顶房子有各种各样的,比如普通房,高楼,别墅&…...
SpringBoot 可以同时处理多少请求
一、前言 首先,在Spring Boot应用中,我们可以使用 Tomcat、Jetty、Undertow 等嵌入式 Web 服务器作为应用程序的运行容器。这些服务器都支持并发请求处理的能力。另外,Spring Boot 还提供了一些配置参数,可以对 Web 服务器进行调…...
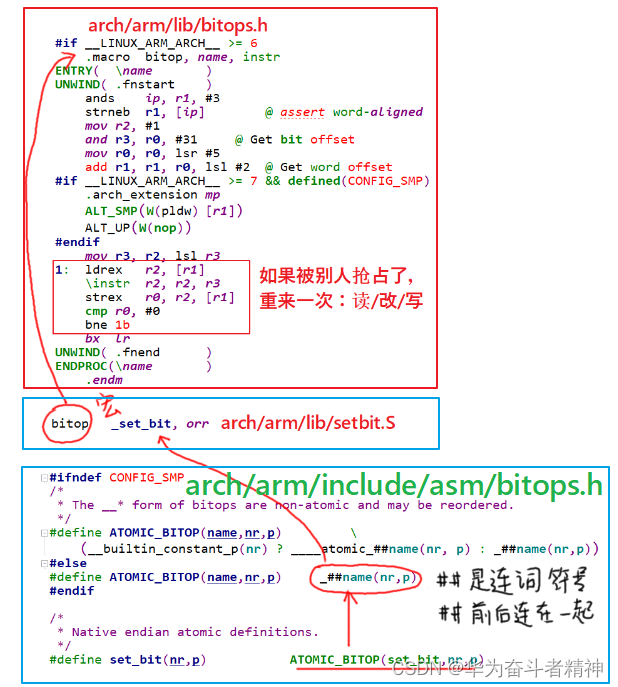
嵌入式Linux应用开发-驱动大全-第一章同步与互斥②
嵌入式Linux应用开发-驱动大全-第一章同步与互斥② 第一章 同步与互斥②1.3 原子操作的实现原理与使用1.3.1 原子变量的内核操作函数1.3.2 原子变量的内核实现1.3.2.1 ATOMIC_OP在 UP系统中的实现1.3.2.2 ATOMIC_OP在 SMP系统中的实现 1.3.3 原子变量使用案例1.3.4 原子位介绍1…...
EasyExcel的源码流程(导入Excel)
1. 入口 2. EasyExcel类继承了EasyExcelFactory类,EasyExcel自动拥有EasyExcelFactory父类的所有方法,如read(),readSheet(),write(),writerSheet()等等。 3. 进入.read()方法,需要传入三个参数(文件路径…...
基于 jasypt 实现spring boot 配置文件脱敏
前言 在项目构建过程中,保护敏感信息的安全性至关重要,为了提高系统的安全性能,我们采用了Jasypt来对配置文件中的敏感信息进行加密处理,以确保系统的机密信息不被轻易泄露。 步骤 添加Maven依赖 首先,我们需要添加…...
Python——ASCII编码与Unicode(UTF-8,UTF-16 和 UTF-32)编码
Python3 Python——ASCII编码与Unicode(UTF-8,UTF-16 和 UTF-32)编码 文章目录 Python3一、编码与编码格式二、ASCII编码与UTF-8编码(UTF-16 和 UTF-32编码)三、ASCII 字符串和 Unicode 字符串 最近看Python程序的文件…...

【多媒体技术与实践】音频信息获取和处理——编程题汇总
1:音频信息数据量计算 已知采样频率(单位KHz)、量化位数、声道数及持续时间(单位分钟),求未压缩时的数据量(单位MB). 例如: 输入: 22.05 16 2 3 ÿ…...
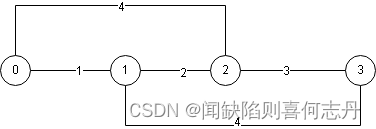
堆优化迪氏最短单源路径原理及C++实现
时间复杂度 O(ElogE),E是边数。适用与稀疏图。 使用前提 边的权为正。可以非连通,非连通的距离为-1。 原理 优选队列(小根堆)记录两个数据:当前点到源点距离,当前点。先处理距离小的点;如果…...

Leetcode202. 快乐数
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1࿰…...

【MySQL】MySql常见面试题总结
目录 一、什么是sql注入 二、sql语句的执行流程 三、内连接和外连接的区别 四、Union和Union All 有什么区别 五、MySql如何取差集 六、DELETE和TRUNCATE有什么区别 七、count(*)和count(1)的区别 八、MyISAM和InnoDB的区…...

【Java 进阶篇】JDBC PreparedStatement 详解
在Java中,与关系型数据库进行交互是非常常见的任务之一。JDBC(Java Database Connectivity)是Java平台的一个标准API,用于连接和操作各种关系型数据库。其中,PreparedStatement 是 JDBC 中一个重要的接口,用…...
)
公交查询|智能公交|公交线路查询|基于SprinBoot+vue智能公交系统(源码+数据库+文档)
公交查询|智能公交|公交线路查询系统 目录 基于SprinBootvue智能公交系统 一、前言 二、系统设计 三、系统功能设计 1用户模块实现 2管理员服务端模块实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介…...

LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制
LeRobot:开源机器人学习的终极指南 - 从零到真实世界的AI机器人控制 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot LeRobo…...

汽车芯片市场深度解析:从电动化、智能化到供应链变革
1. 汽车芯片行业:短期阵痛与长期增长的辩证观最近和几个在车厂和Tier 1供应商做研发的老朋友聊天,大家普遍的感觉是:冰火两重天。一边是终端市场感觉“卷”得厉害,销量波动、价格战不停;另一边,研发部门的芯…...
)
别再折腾Windows了!用Mac或Linux搞定ACM LaTeX模板的字体难题(附保姆级配置流程)
跨平台LaTeX写作:为什么macOS和Linux是ACM模板的最佳选择 第一次接触ACM LaTeX模板的研究人员,往往会在字体兼容性问题上耗费大量时间——特别是Windows用户。当你反复尝试安装Libertine字体、解决各种编译错误时,是否想过问题可能出在操作系…...

跨境直播里,为什么很多团队设备很强,画面却依旧不稳定?
做跨境直播的人,基本都会经历一个阶段:疯狂升级设备。更贵的相机更强的显卡更高规格的采集卡更多灯光但实际开播后:直播依旧掉帧OBS 占用异常推流延迟增加画面偶发模糊音视频不同步很多时候,问题并不是设备性能不够。而是…...

PiliPlus:如何用第三方B站客户端解锁终极观影体验?
PiliPlus:如何用第三方B站客户端解锁终极观影体验? 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 你是否厌倦了官方B站客户端的广告轰炸?是否想要更纯净、更流畅的观影体验?P…...

基于RAG与MCP协议构建实时新闻AI助手:newsmcp项目实战解析
1. 项目概述:一个让AI“读新闻”的智能工具最近在折腾AI应用开发的朋友,可能都绕不开一个核心问题:如何让大语言模型(LLM)获取并理解最新的、模型训练数据之外的信息?比如,你想让ChatGPT帮你分析…...

独立开发者如何利用 Taotoken 的模型广场为不同产品功能匹配合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的模型广场为不同产品功能匹配合适模型 对于独立开发者而言,运营多个小型产品是常态。这…...

10分钟学会Appium:移动端自动化测试的终极指南
10分钟学会Appium:移动端自动化测试的终极指南 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til Appium是一款功能强大的开源移动端自动化测试工具,支持iOS和Android平台,让开发者和测试…...

从零构建现代桌面应用导航:PyQt-Fluent-Widgets导航组件实战指南
从零构建现代桌面应用导航:PyQt-Fluent-Widgets导航组件实战指南 【免费下载链接】PyQt-Fluent-Widgets A fluent design widgets library based on C Qt/PyQt/PySide. Make Qt Great Again. 项目地址: https://gitcode.com/gh_mirrors/py/PyQt-Fluent-Widgets …...