Kafka日志索引详解以及生产常见问题分析与总结
文章目录
- 1、Kafka的Log日志梳理
- 1.1、Topic下的消息是如何存储的?
- 1.1.1、 log文件追加记录所有消息
- 1.1.2、 index和timeindex加速读取log消息日志。
- 1.2、文件清理机制
- 1.2.1、如何判断哪些日志文件过期了
- 1.2.2、过期的日志文件如何处理
- 1.3、Kafka的文件高效读写机制
- 1.3.1、Kafka的文件结构
- 1.3.2、顺序写磁盘
- 1.3.3、零拷贝
1、Kafka的Log日志梳理
这一部分数据主要包含当前Broker节点的消息数据(在Kafka中称为Log日志)。这是一部分无状态的数据,也就是说每个Kafka的Broker节点都是以相同的逻辑运行。这种无状态的服务设计让Kafka集群能够比较容易的进行水平扩展。比如你需要用一个新的Broker服务来替换集群中一个旧的Broker服务,那么只需要将这部分无状态的数据从旧的Broker上转移到新的Broker上就可以了。
1.1、Topic下的消息是如何存储的?
在搭建Kafka服务时,我们在server.properties配置文件中通过log.dir属性指定了Kafka的日志存储目录。实际上,Kafka的所有消息就全都存储在这个目录下。
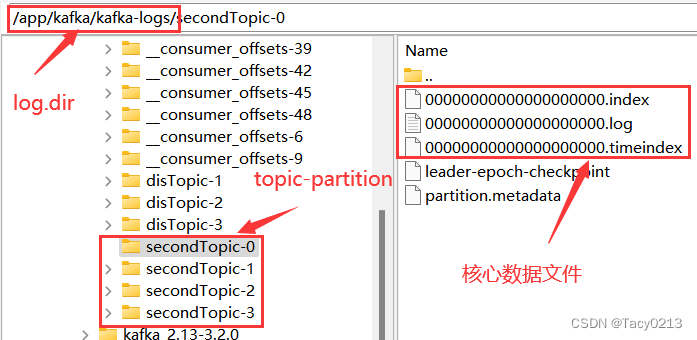
这些核心数据文件中,.log结尾的就是实际存储消息的日志文件。他的大小固定为1G(由参数log.segment.bytes参数指定),写满后就会新增一个新的文件。一个文件也成为一个segment文件名表示当前日志文件记录的第一条消息的偏移量。
.index和.timeindex是日志文件对应的索引文件。不过.index是以偏移量为索引来记录对应的.log日志文件中的消息偏移量。而.timeindex则是以时间戳为索引。
另外的两个文件,partition.metadata简单记录当前Partition所属的cluster和Topic。leader-epoch-checkpoint文件参见上面的epoch机制。
这些文件都是二进制的文件,无法使用文本工具直接查看。但是,Kafka提供了工具可以用来查看这些日志文件的内容。
#1、查看timeIndex文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
timestamp: 1661753911323 offset: 61
timestamp: 1661753976084 offset: 119
timestamp: 1661753977822 offset: 175
#2、查看index文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
offset: 61 position: 4216
offset: 119 position: 8331
offset: 175 position: 12496
#3、查看log文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1661753909195 size: 99 magic: 2 compresscodec: none crc: 342616415 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 99 CreateTime: 1661753909429 size: 80 magic: 2 compresscodec: none crc: 3141223692 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 179 CreateTime: 1661753909524 size: 80 magic: 2 compresscodec: none crc: 1537372733 isvalid: true
.......
这些数据文件的记录方式,就是我们去理解Kafka本地存储的主线。对这里面的各个属性理解得越详细,也就表示对Kafka的消息日志处理机制理解得越详细。
1.1.1、 log文件追加记录所有消息
首先:在每个文件内部,Kafka都会以追加的方式写入新的消息日志。position就是消息记录的起点,size就是消息序列化后的长度。Kafka中的消息日志,只允许追加,不支持删除和修改。所以,只有文件名最大的一个log文件是当前写入消息的日志文件,其他文件都是不可修改的历史日志。
然后:每个Log文件都保持固定的大小。如果当前文件记录不下了,就会重新创建一个log文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计其实是为了更方便进行文件映射,加快读消息的效率。
1.1.2、 index和timeindex加速读取log消息日志。
详细看下这几个文件的内容,就可以总结出Kafka记录消息日志的整体方式:
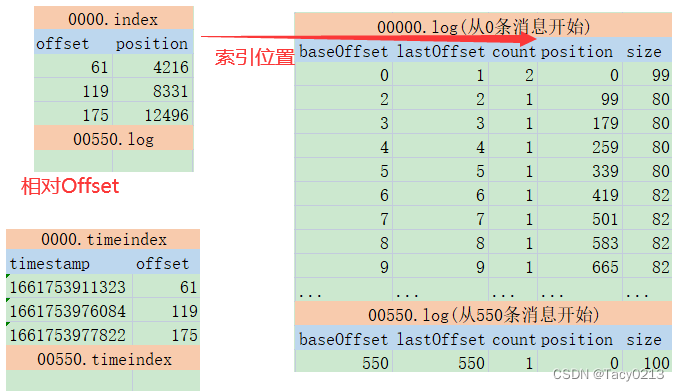
首先:index和timeindex都是以相对偏移量的方式建立log消息日志的数据索引。比如说 0000.index和0550.index中记录的索引数字,都是从0开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
然后:这两个索引并不是对每一条消息都建立索引。而是Broker每写入40KB的数据,就建立一条index索引。由参数log.index.interval.bytes定制。
log.index.interval.bytes
The interval with which we add an entry to the offset indexType: int
Default: 4096 (4 kibibytes)
Valid Values: [0,...]
Importance: medium
Update Mode: cluster-wide
index文件的作用类似于数据结构中的跳表,他的作用是用来加速查询log文件的效率。而timeindex文件的作用则是用来进行一些跟时间相关的消息处理。比如文件清理。
这两个索引文件也是Kafka的消费者能够指定从某一个offset或者某一个时间点读取消息的原因。
1.2、文件清理机制
Kafka为了防止过多的日志文件给服务器带来过大的压力,他会定期删除过期的log文件。Kafka的删除机制涉及到几组配置属性:
1.2.1、如何判断哪些日志文件过期了
log.retention.check.interval.ms:定时检测文件是否过期。默认是 300000毫秒,也就是五分钟。
log.retention.hours , log.retention.minutes, log.retention.ms 。 这一组参数表示文件保留多长时间。默认生效的是log.retention.hours,默认值是168小时,也就是7天。如果设置了更高的时间精度,以时间精度最高的配置为准。
在检查文件是否超时时,是以每个.timeindex中最大的那一条记录为准。
1.2.2、过期的日志文件如何处理
log.cleanup.policy:日志清理策略。有两个选项,delete表示删除日志文件。 compact表示压缩日志文件。
当log.cleanup.policy选择delete时,还有一个参数可以选择。log.retention.bytes:表示所有日志文件的大小。当总的日志文件大小超过这个阈值后,就会删除最早的日志文件。默认是-1,表示无限大。
压缩日志文件虽然不会直接删除日志文件,但是会造成消息丢失。压缩的过程中会将key相同的日志进行压缩,只保留最后一条。
1.3、Kafka的文件高效读写机制
这是Kafka非常重要的一个设计,同时也是面试频率超高的问题。可以分几个方向来理解。
1.3.1、Kafka的文件结构
Kafka的数据文件结构设计可以加速日志文件的读取。比如同一个Topic下的多个Partition单独记录日志文件,并行进行读取,这样可以加快Topic下的数据读取速度。然后index的稀疏索引结构,可以加快log日志检索的速度。
1.3.2、顺序写磁盘
这个跟操作系统有关,主要是硬盘结构。
对每个Log文件,Kafka会提前规划固定的大小,这样在申请文件时,可以提前占据一块连续的磁盘空间。然后,Kafka的log文件只能以追加的方式往文件的末端添加(这种写入方式称为顺序写),这样,新的数据写入时,就可以直接往直前申请的磁盘空间中写入,而不用再去磁盘其他地方寻找空闲的空间(普通的读写文件需要先寻找空闲的磁盘空间,再写入。这种写入方式称为随机写)。由于磁盘的空闲空间有可能并不是连续的,也就是说有很多文件碎片,所以磁盘写的效率会很低。
kafka的官网有测试数据,表明了同样的磁盘,顺序写速度能达到600M/s,基本与写内存的速度相当。而随机写的速度就只有100K/s,差距比加大。
1.3.3、零拷贝
零拷贝是Linux操作系统提供的一种IO优化机制,而Kafka大量的运用了零拷贝机制来加速文件读写。
传统的一次硬件IO是这样工作的。如下图所示:
相关文章:
Kafka日志索引详解以及生产常见问题分析与总结
文章目录 1、Kafka的Log日志梳理1.1、Topic下的消息是如何存储的?1.1.1、 log文件追加记录所有消息1.1.2、 index和timeindex加速读取log消息日志。 1.2、文件清理机制1.2.1、如何判断哪些日志文件过期了1.2.2、过期的日志文件如何处理 1.3、Kafka的文件高效读写机制…...

vue中 css scoped原理
Vue中css的逻辑是先放子组件,然后放父组件,所以同样的css类名,子组件会被父组件覆盖 html 如下 子被父覆盖 scoped是通过给组件加hash值,锁定组件。 父子组件均scoped的情况下,子仍会覆盖 还是被覆盖了 如何避免被…...
)
tf.compat.v1.global_variables()
tf.global_variables tf.global_variables() 是 TensorFlow 1.x 中的一个函数,它返回图中所有的全局变量。在 TensorFlow 2.x 中,这个函数已经被移除了,取而代之的是 tf.compat.v1.global_variables()。 然而,在 TensorFlow 2.x …...

登录注册实现
一、前端页面注册到Vue 1.创建登录和注册组件 <template><div>login</div></template><script> export default {name: HomeView,data() {return {}},methods: {}, } </script><template><div>register</div></tem…...

Push rejected: Push to origin/master was rejected
Push rejected: Push to origin/master was rejected 原因:推拒绝:推送到起源/主人被拒绝 解决方案如下: 方案1: 1.在Idea打开终端 方案2: 1、在对应项目文件里打开 Git Bash 然后依次输入: git pull …...

在线OJ项目核心思路
文章目录 在线OJ项目核心思路1. 项目介绍2.预备知识理解多进程编程为啥采用多进程而不使用多线程?标准输入&标准输出&标准错误 3.项目实现题目API实现相关实体类定义新增/修改题目获取题目列表 编译运行编译运行流程 4.统一功能处理 在线OJ项目核心思路 1. 项目介绍 …...

Spring MVC:数据绑定
Spring MVC 数据绑定数据类型转换数据格式化数据校验 附 数据绑定 数据绑定,指 Web 页面上请求和响应的数据与 Controller 中对应处理方法上的对象绑定(即是将用户提交的表单数据绑定到 Java 对象中)。 过程如下: ServletRequest…...
STM32CubeMX学习笔记-USB接口使用(HID按键)
STM32CubeMX学习笔记-USB接口使用(HID按键) 一、USB简介1.1 USB HID简介 二、新建工程1. 打开 STM32CubeMX 软件,点击“新建工程”2. 选择 MCU 和封装3. 配置时钟4. 配置调试模式 三、USB3.1 参数配置3.2 引脚配置3.3 配置时钟3.4 USB Device…...

C#,数值计算——Ranq2的计算方法与源程序
1 文本格式 using System; namespace Legalsoft.Truffer { /// <summary> /// Backup generator if Ranq1 has too short a period and Ran is too slow.The /// period is 8.5E37. Calling conventions same as Ran, above. /// </summary> …...

C/C++ 数据结构 - 链表
1.单链表 https://blog.csdn.net/qq_36806987/article/details/79858957 1 #include<stdio.h>2 #include<stdlib.h>3 4 /*结构体部分*/5 typedef struct Node6 {7 int data; //数值域8 struct Node *next; //指针域9 }N;10 11 N *Init() //初始化单…...
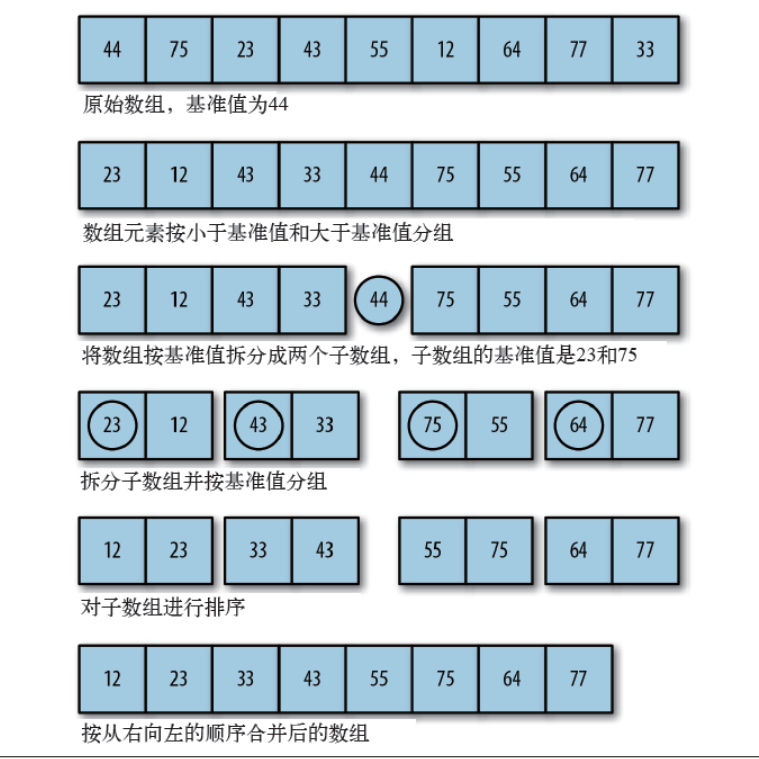
【算法基础】一文掌握十大排序算法,冒泡排序、插入排序、选择排序、归并排序、计数排序、基数排序、希尔排序和堆排序
目录 1 冒泡排序(Bubble Sort) 2 插入排序(Insertion Sort) 3 选择排序(Selection Sort) 4. 快速排序(Quick Sort) 5. 归并排序(Merge Sort) 6 堆排序 …...
:指定数组元素的特定属性进行搜索)
javascript二维数组(3):指定数组元素的特定属性进行搜索
js中对数组, var data [{“name”: “《西游记》”, “author”: “吴承恩”, “cat”: “A级书刊”, “num”: 3},{“name”: “《三国演义》”, “author”: “罗贯中”, “cat”: “A级书刊”, “num”: 8},{“name”: “《红楼梦》”, “author”: “曹雪芹”,…...

使用Qt进行HTTP通信的方法
文章目录 1 HTTP协议简介1.1 HTTP协议的历史和发展1.2 HTTP协议的特点1.3 HTTP的工作过程1.4 请求报文1.5 响应报文 2 使用Qt进行HTTP通信2.1 Qt的HTTP通信类2.2 HTTP通信过程 3 JSON3.1 cJSON库简介3.2 cJSON库的设计思想和数据结构3.3 cJSON库的使用方法 1 HTTP协议简介 1.1…...

第45节——页面中修改redux里的数据
一、什么是action 在 Redux 中,Action 是一个简单的 JavaScript 对象,用于描述对应应用中的某个事件(例如用户操作)所发生的变化。它包含了一个 type 属性,用于表示事件的类型,以及其他一些可选的数据。 …...
)
软考 系统架构设计师系列知识点之软件架构风格(2)
接前一篇文章:软考 系统架构设计师系列知识点之软件架构风格(1) 这个十一注定是一个不能放松、保持“紧”的十一。由于报名了全国计算机技术与软件专业技术资格(水平)考试,11月4号就要考试,因此…...

【C++11】Lambda 表达式:基本使用 和 底层原理
文章目录 Lambda 表达式1. 不考虑捕捉列表1.1 简单使用介绍1.2 简单使用举例 2. 捕捉列表 [ ] 和 mutable 关键字2.1 使用方法传值捕捉传引用捕捉 2.2 捕捉方法一览2.3 使用举例 3. lambda 的底层分析 Lambda 表达式 书写格式: [capture_list](parameters) mutabl…...

【网络安全---ICMP报文分析】Wireshark教程----Wireshark 分析ICMP报文数据试验
一,试验环境搭建 1-1 试验环境示例图 1-2 环境准备 两台kali主机(虚拟机) kali2022 192.168.220.129/24 kali2022 192.168.220.3/27 1-2-1 网关配置: 编辑-------- 虚拟网路编辑器 更改设置进来以后 ,先选择N…...

【Docker】Docker的应用包含Sandbox、PaaS、Open Solution以及IT运维概念的详细讲解
前言 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。 📕作者简介:热…...

Java Applet基础
Java Applet基础 目录 Java Applet基础 Applet的生命周期 "Hello, World" Applet: Applet 类 Applet的调用 获得applet参数 指定applet参数 应用程序转换成Applet 事件处理 显示图片 播放音频 applet是一种Java程序。它一般运行在支持Java的Web浏览器内。因…...
【记录】IDA|IDA怎么查看当前二进制文件自动分析出来的内存分布情况(内存范围和读写性)
IDA版本:7.6 背景:我之前一直是直接看Text View里面的地址的首尾地址来判断内存分布情况的,似乎是有点不准确,然后才想到IDA肯定自带查看内存分布情况的功能,而且很简单。 可以通过View-Toolbars-Segments,…...

Discord集成Claude智能体:极简Docker容器化部署与安全实践
1. 项目概述:一个为Discord量身定制的Claude智能体运行栈 如果你和我一样,既想在日常工作的Discord频道里无缝调用Claude这样的强大AI助手,又对复杂、臃肿的Bot框架感到头疼,那么 nanoclaw-discord 这个项目可能就是你在找的答…...

Flutter 告别 Rosetta:揭秘 iOS 工具链原生适配 M 芯片的“折腾”史
如果你是 macOS 用户,一定对 Apple Silicon(M1/M2/M3)的性能赞不绝口。但在光鲜的背后,很多底层开发工具其实一直在靠 Rosetta 2 偷偷「苟延残喘」。今天,我们通过复盘近期 Flutter 官方的一个核心 PR,来看…...

从零构建开源任务管理中枢:TaskWing部署、插件化与自动化实战
1. 项目概述:从零到一,打造你的个人任务管理中枢如果你和我一样,每天被各种待办事项、项目进度、临时想法和会议记录搞得焦头烂额,那么你肯定不止一次地想过:有没有一个工具,能真正“懂”我,能把…...

基于MCP的AI智能体:自动化与优化亚马逊DSP广告实战指南
1. 项目概述:用AI智能体管理亚马逊DSP广告如果你正在寻找一种更高效、更智能的方式来管理亚马逊需求方平台(Amazon DSP)的广告活动,那么这个项目可能就是为你准备的。作为一个在程序化广告领域摸爬滚打了十多年的从业者࿰…...
)
基于微信小程序的民宿短租系统(30292)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

CQDs-PEG/Biotin/@SiO2/Polymer,PEG修饰碳量子点的特性
中英文名称: CQDs-PEG,PEG修饰碳量子点 CQDs-Biotin,生物素偶联碳量子点 CQDsSiO2,二氧化硅包覆碳量子点 CQDsPolymer,聚合物包覆碳量子点 碳量子点(Carbon Quantum Dots, CQDs)作为一类新型零维…...

[已解决]Vscode插件Keil Assistant连接Keil后出现的头文件路径无法寻找问题
问题详情 按照网络上的教程按照并且配置好vscode的Keil Assistant插件后,成功打开了Keil工程并且编译成功。但是头文件无法跳转,以及出现红色波浪线报错。 解决方法 在.vscode\c_cpp_properties.json中添加以下两行路径: "includePath&q…...

FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼
FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...

HTML5 教程
HTML5 教程 引言 HTML5,作为现代网页开发的核心技术之一,自从推出以来就受到了广泛的关注和认可。它不仅改进了原有的HTML特性,还引入了新的元素和API,使得网页设计和开发更加高效、强大。本教程旨在为您提供一个全面的HTML5学习路径,帮助您快速掌握HTML5的基础知识和高…...
)
CTR预估实战:DeepFM模型在Criteo数据集上的调参避坑指南(附PyTorch代码)
DeepFM模型在Criteo数据集上的调优实战:从79%到81% AUC的进阶之路 当CTR预估模型的AUC指标卡在79%的瓶颈时,真正的挑战才刚刚开始。本文将以工业级数据集Criteo为战场,分享如何通过系统化的调参策略和特征工程技巧,将DeepFM模型的…...